【完整源码+数据集+部署教程】痤疮特征分割系统: yolov8-seg-p2
背景意义
研究背景与意义
痤疮作为一种常见的皮肤疾病,影响着全球数以亿计的人群,尤其是青少年和年轻成年人。其发病机制复杂,主要与皮脂腺的过度活跃、毛囊角化异常、细菌感染以及炎症反应等因素密切相关。痤疮不仅对患者的身体健康造成影响,更在心理层面引发诸多问题,如自尊心下降、社交障碍等。因此,针对痤疮的早期诊断与治疗显得尤为重要。近年来,随着计算机视觉和深度学习技术的迅猛发展,基于图像处理的痤疮特征分析逐渐成为研究热点。
在这一背景下,基于改进YOLOv8的痤疮特征分割系统应运而生。YOLO(You Only Look Once)系列模型以其高效的实时目标检测能力和良好的准确性而受到广泛关注。YOLOv8作为该系列的最新版本,进一步提升了模型的性能,特别是在小目标检测和实例分割方面。通过对YOLOv8的改进,能够更好地适应痤疮特征的复杂性和多样性,从而实现对不同类型痤疮的精确分割与识别。
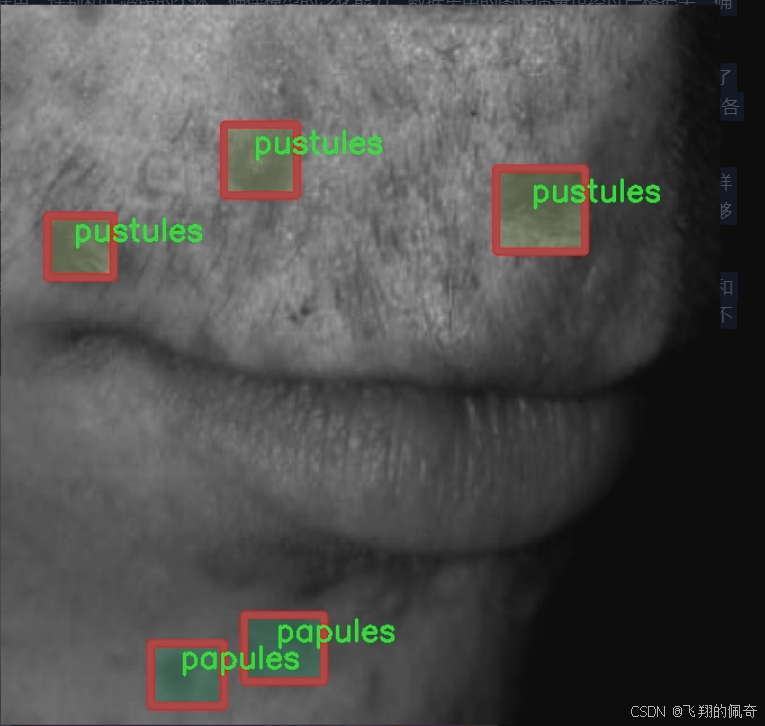
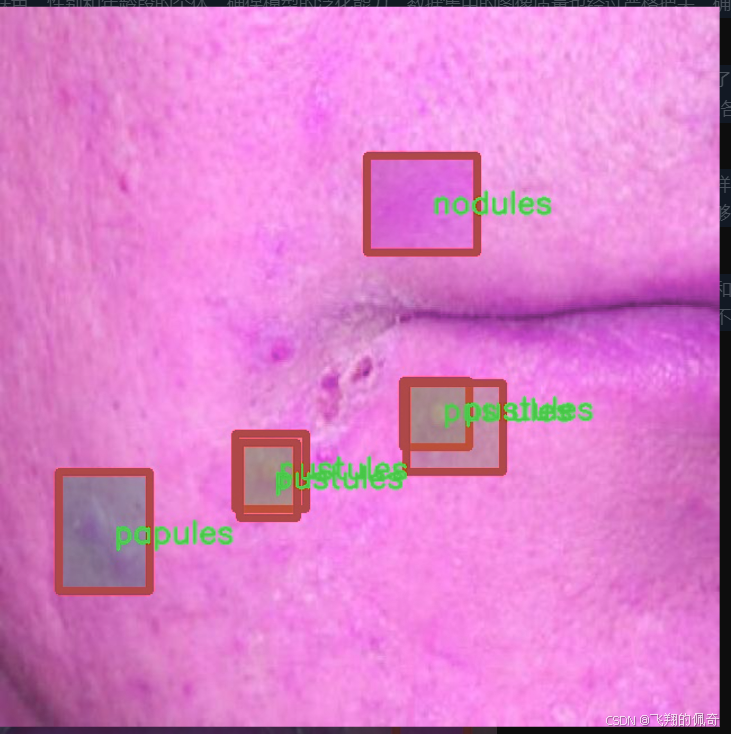
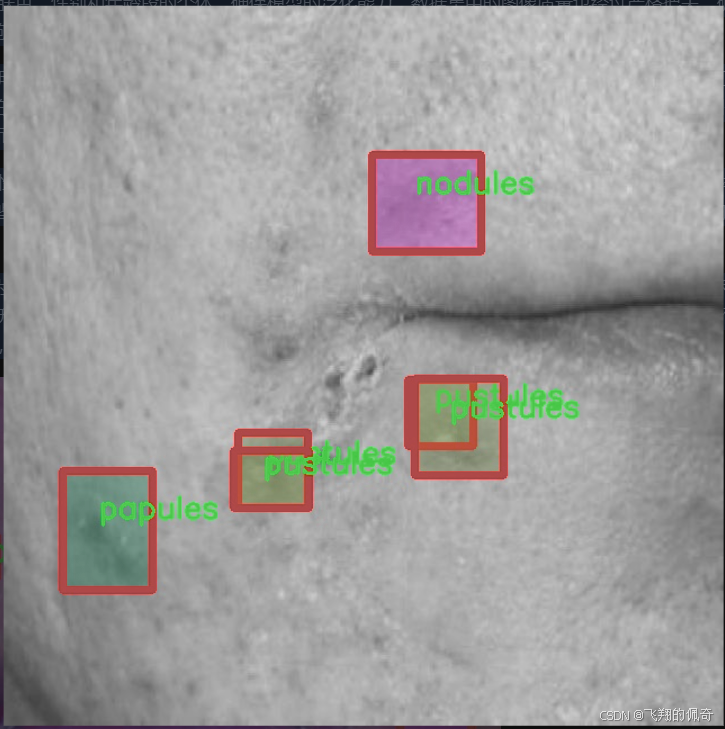
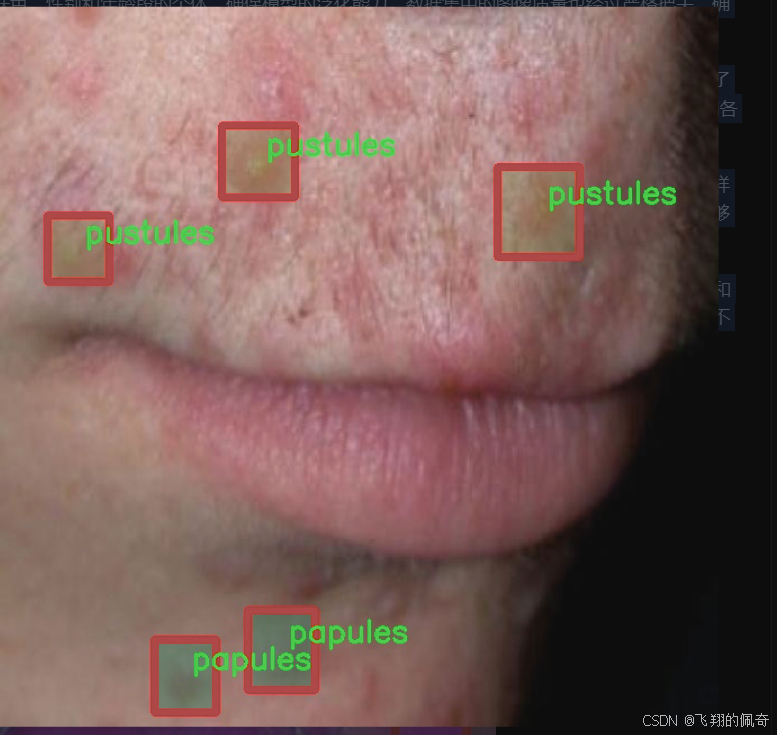
本研究所使用的数据集“AcnePut-In”包含1200张图像,涵盖了六种不同类型的痤疮特征,包括黑头、暗斑、结节、丘疹、脓疱和白头。这些类别的划分不仅反映了痤疮的不同病理特征,也为后续的特征分析和治疗方案提供了重要依据。通过对这些特征的准确分割,能够为临床医生提供更为直观的痤疮状态评估,进而制定个性化的治疗方案。
在痤疮的研究中,图像分割技术的应用具有重要的理论和实践意义。首先,通过对痤疮特征的精确分割,可以有效提高病变区域的识别率,减少误诊率,进而提升临床诊断的准确性。其次,基于深度学习的分割模型能够实现自动化处理,减少人工干预,提高工作效率,尤其在大规模筛查和监测中具有显著优势。此外,痤疮特征的分割结果还可以为后续的病理分析、疗效评估和新药研发提供数据支持。
综上所述,基于改进YOLOv8的痤疮特征分割系统不仅具有重要的学术价值,还在实际应用中展现出广阔的前景。通过对痤疮特征的深入研究与分析,能够为改善患者的生活质量、推动皮肤病学的研究进展提供有力支持。未来,随着技术的不断进步和数据集的不断丰富,基于深度学习的痤疮特征分割系统有望在临床应用中发挥更大的作用,为痤疮的早期诊断和个性化治疗开辟新的路径。
图片效果
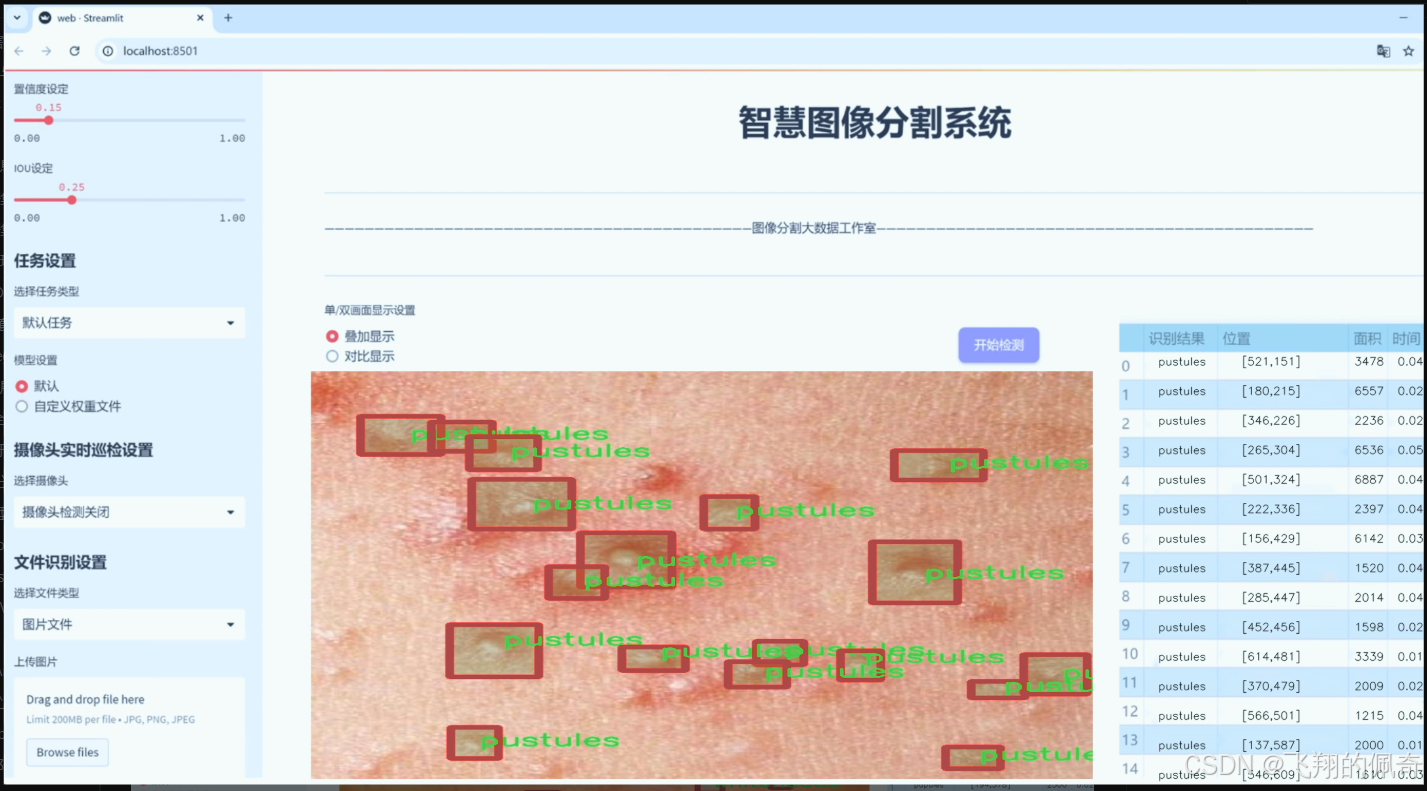
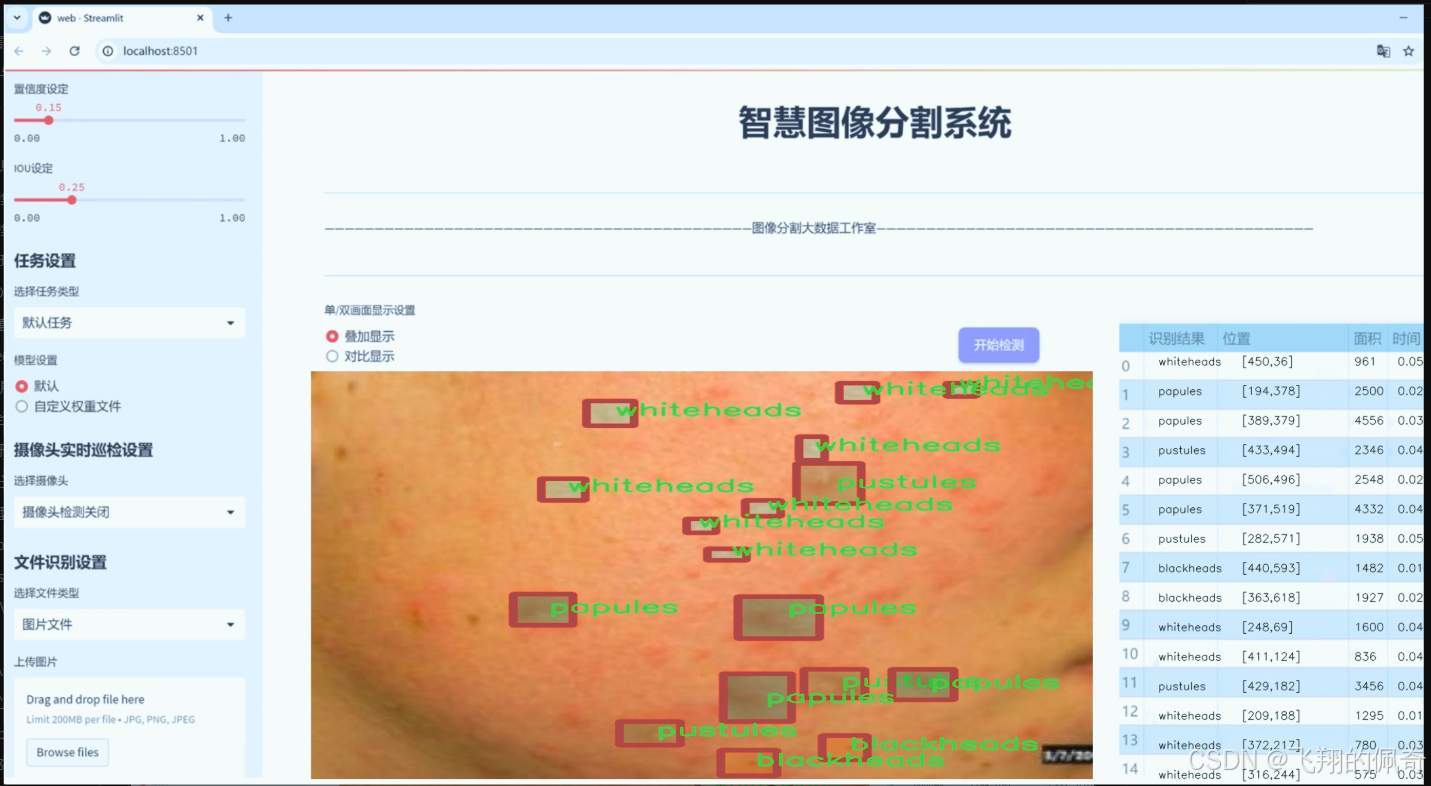
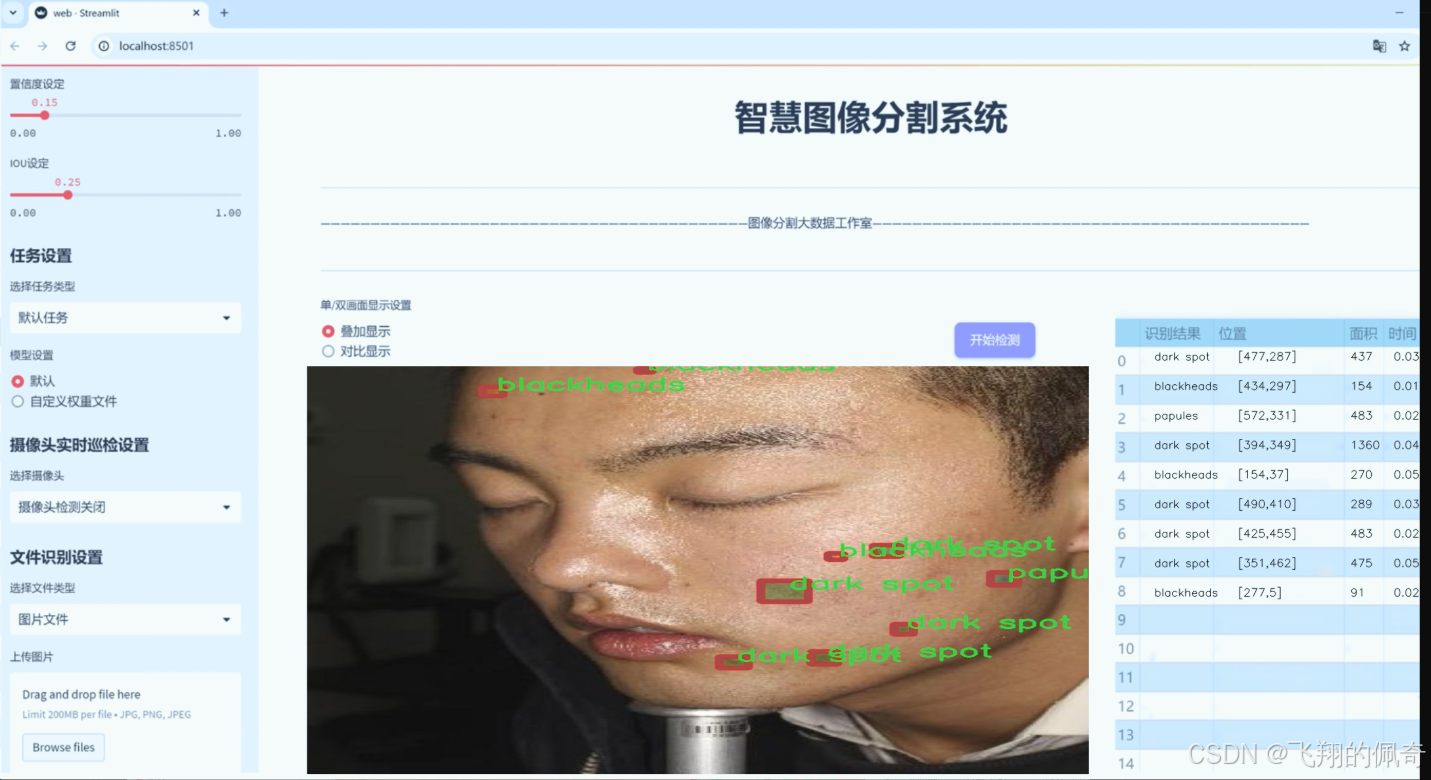
数据集信息
数据集信息展示
在本研究中,我们使用了名为“AcnePut-In”的数据集,旨在改进YOLOv8-seg模型在痤疮特征分割任务中的表现。该数据集专门为痤疮相关的皮肤特征提供了丰富的标注信息,包含六个主要类别,分别是黑头、暗斑、结节、丘疹、脓疱和白头。这些类别涵盖了痤疮的不同表现形式,使得模型能够在多样化的痤疮特征中进行有效的学习和识别。
“AcnePut-In”数据集的构建过程经过了严格的筛选和标注,确保每个类别的样本都具有代表性。黑头是痤疮中最常见的类型之一,通常表现为毛孔堵塞后形成的小黑点。暗斑则是由于炎症后色素沉着而形成的,常常影响皮肤的整体美观。结节是一种较为严重的痤疮类型,通常表现为坚硬的肿块,可能会伴随疼痛感。丘疹则是小而红的突起,通常是痤疮初期的表现。脓疱则是含有脓液的丘疹,常常伴随明显的炎症反应。最后,白头是被皮肤覆盖的闭合性粉刺,通常较难以察觉,但同样需要关注。
数据集中每个类别的样本数量经过精心设计,以确保模型在训练过程中能够接触到足够的多样性。这种多样性不仅体现在样本的数量上,还包括不同肤色、性别和年龄段的个体,确保模型的泛化能力。数据集中的图像质量也经过严格把关,确保每张图像都清晰可辨,能够有效支持特征提取和分割任务。
在数据集的标注过程中,采用了专业的皮肤科医生进行分类和标注,确保了标注的准确性和一致性。这一过程不仅提高了数据集的可信度,也为后续的模型训练提供了坚实的基础。通过这种高质量的标注,YOLOv8-seg模型能够更好地学习到各类痤疮特征的细微差别,从而在实际应用中实现更高的准确率和更好的分割效果。
此外,为了增强模型的鲁棒性,数据集还包含了一些具有挑战性的样本,例如不同光照条件下的图像、不同角度拍摄的样本以及部分模糊的图像。这些样本的引入旨在模拟真实世界中可能遇到的各种情况,使得训练出的模型在实际应用中能够更好地应对不同的场景。
总之,“AcnePut-In”数据集为改进YOLOv8-seg的痤疮特征分割系统提供了一个坚实的基础。通过对六个类别的深入研究和精细标注,我们期望能够提升模型在痤疮检测和分割任务中的表现,最终为临床应用提供更为有效的支持。这一数据集不仅是本研究的核心组成部分,也是推动痤疮相关研究向前发展的重要资源。
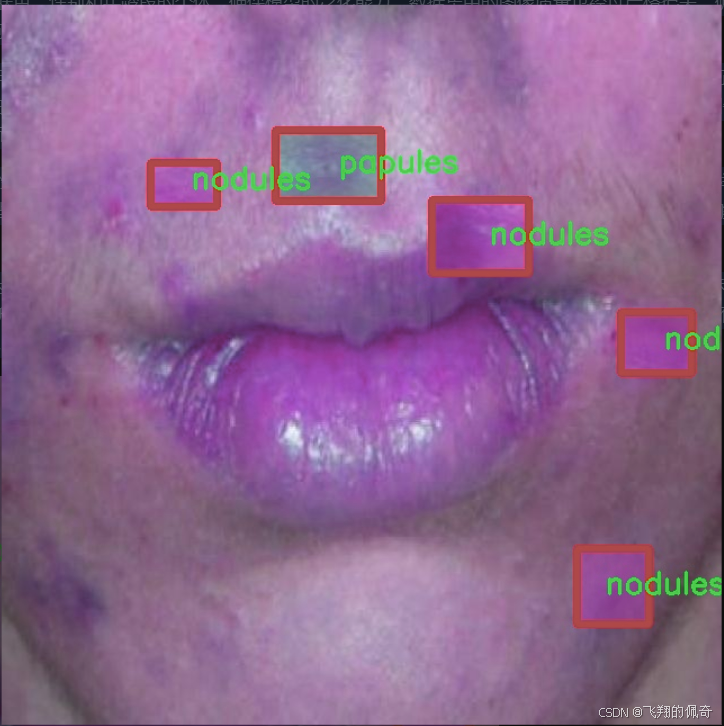
核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import os
import re
import subprocess
from pathlib import Path
from typing import Optional
import torch
from ultralytics.utils import LOGGER, ROOT
def parse_requirements(file_path=ROOT.parent / ‘requirements.txt’, package=‘’):
“”"
解析 requirements.txt 文件,忽略以 ‘#’ 开头的行及 ‘#’ 后的文本。
参数:file_path (Path): requirements.txt 文件的路径。package (str, optional): 要使用的 Python 包名,默认为空。返回:(List[Dict[str, str]]): 解析后的需求列表,每个需求为字典形式,包含 `name` 和 `specifier` 键。
"""
if package:# 如果指定了包名,则获取该包的依赖requires = [x for x in metadata.distribution(package).requires if 'extra == ' not in x]
else:# 否则读取 requirements.txt 文件requires = Path(file_path).read_text().splitlines()requirements = []
for line in requires:line = line.strip()if line and not line.startswith('#'):line = line.split('#')[0].strip() # 忽略行内注释match = re.match(r'([a-zA-Z0-9-_]+)\s*([<>!=~]+.*)?', line)if match:requirements.append(SimpleNamespace(name=match[1], specifier=match[2].strip() if match[2] else ''))return requirements
def check_version(current: str = ‘0.0.0’, required: str = ‘0.0.0’, name: str = ‘version’, hard: bool = False) -> bool:
“”"
检查当前版本是否满足所需版本或范围。
参数:current (str): 当前版本或包名。required (str): 所需版本或范围(以 pip 风格格式)。name (str, optional): 在警告消息中使用的名称。hard (bool, optional): 如果为 True,当需求不满足时抛出 AssertionError。返回:(bool): 如果满足需求则返回 True,否则返回 False。
"""
if not current: # 如果 current 是空字符串或 NoneLOGGER.warning(f'WARNING ⚠️ invalid check_version({current}, {required}) requested, please check values.')return True# 解析当前版本
c = parse_version(current) # '1.2.3' -> (1, 2, 3)
for r in required.strip(',').split(','):op, v = re.match(r'([^0-9]*)([\d.]+)', r).groups() # 分离操作符和版本号v = parse_version(v) # '1.2.3' -> (1, 2, 3)# 根据操作符检查版本if op == '==' and c != v:return Falseelif op == '!=' and c == v:return Falseelif op in ('>=', '') and not (c >= v):return Falseelif op == '<=' and not (c <= v):return Falseelif op == '>' and not (c > v):return Falseelif op == '<' and not (c < v):return Falsereturn True
def check_requirements(requirements=ROOT.parent / ‘requirements.txt’, exclude=(), install=True):
“”"
检查已安装的依赖是否满足要求,并尝试自动更新。
参数:requirements (Union[Path, str, List[str]]): requirements.txt 文件的路径,单个包要求字符串,或包要求字符串列表。exclude (Tuple[str]): 要排除的包名元组。install (bool): 如果为 True,尝试自动更新不满足要求的包。返回:(bool): 如果所有要求都满足则返回 True,否则返回 False。
"""
check_python() # 检查 Python 版本
if isinstance(requirements, Path): # 如果是 requirements.txt 文件file = requirements.resolve()assert file.exists(), f'requirements file {file} not found, check failed.'requirements = [f'{x.name}{x.specifier}' for x in parse_requirements(file) if x.name not in exclude]
elif isinstance(requirements, str):requirements = [requirements]pkgs = []
for r in requirements:match = re.match(r'([a-zA-Z0-9-_]+)([<>!=~]+.*)?', r)name, required = match[1], match[2].strip() if match[2] else ''try:assert check_version(metadata.version(name), required) # 检查版本except (AssertionError, metadata.PackageNotFoundError):pkgs.append(r)if pkgs and install: # 如果有不满足要求的包并且允许安装LOGGER.info(f"Ultralytics requirements {pkgs} not found, attempting AutoUpdate...")try:subprocess.check_output(f'pip install --no-cache {" ".join(pkgs)}', shell=True)LOGGER.info(f"AutoUpdate success ✅ installed {len(pkgs)} packages: {pkgs}")except Exception as e:LOGGER.warning(f'AutoUpdate failed ❌: {e}')return Falsereturn True
def check_python(minimum: str = ‘3.8.0’) -> bool:
“”"
检查当前 Python 版本是否满足最低要求。
参数:minimum (str): 所需的最低 Python 版本。返回:(bool): 如果满足要求则返回 True,否则返回 False。
"""
return check_version(platform.python_version(), minimum, name='Python ', hard=True)
代码说明
parse_requirements: 解析 requirements.txt 文件,返回一个包含每个依赖包名称和版本要求的列表。
check_version: 检查当前版本是否满足所需版本的要求,支持多种比较操作符。
check_requirements: 检查已安装的依赖是否满足要求,并在需要时尝试自动更新。
check_python: 检查当前 Python 版本是否满足最低要求。
这些函数是管理和检查依赖项的核心部分,确保环境中安装的库满足特定的版本要求。
这个程序文件 ultralytics/utils/checks.py 是一个用于检查和验证环境配置、依赖项和系统信息的模块,主要用于支持 Ultralytics YOLO(You Only Look Once)模型的运行和开发。以下是对文件中各个部分的详细说明。
首先,文件导入了一系列必要的库,包括标准库(如 os, platform, subprocess 等)和第三方库(如 torch, cv2, numpy 等),这些库为后续的功能提供了支持。
文件定义了多个函数,主要功能包括:
解析需求:parse_requirements 函数用于解析 requirements.txt 文件,提取出需要的依赖项,并返回一个包含依赖项名称和版本要求的字典列表。
版本解析:parse_version 函数将版本字符串转换为整数元组,方便进行版本比较。
ASCII 检查:is_ascii 函数检查字符串是否仅由 ASCII 字符组成。
图像尺寸检查:check_imgsz 函数验证图像尺寸是否为给定步幅的倍数,并在必要时进行调整。
版本检查:check_version 函数比较当前版本与所需版本,返回布尔值,指示是否满足版本要求,并可以选择抛出异常或打印警告信息。
检查最新版本:check_latest_pypi_version 函数通过访问 PyPI API 获取指定包的最新版本。
检查 pip 更新:check_pip_update_available 函数检查当前安装的包是否有更新版本可用。
字体检查:check_font 函数查找本地字体文件,如果不存在则下载到用户配置目录。
Python 版本检查:check_python 函数检查当前 Python 版本是否满足最低要求。
依赖项检查:check_requirements 函数检查已安装的依赖项是否满足要求,并在需要时尝试自动更新。
Torchvision 兼容性检查:check_torchvision 函数检查已安装的 PyTorch 和 Torchvision 版本是否兼容。
文件后缀检查:check_suffix 函数检查文件是否具有有效的后缀。
YOLOv5 文件名检查:check_yolov5u_filename 函数更新旧的 YOLOv5 文件名为新的 YOLOv5u 文件名。
文件检查:check_file 函数搜索或下载文件,并返回其路径。
YAML 文件检查:check_yaml 函数检查 YAML 文件的存在性和后缀。
图像显示检查:check_imshow 函数检查环境是否支持图像显示。
YOLO 软件和硬件检查:check_yolo 函数返回有关 YOLO 软件和硬件的摘要信息。
系统信息收集:collect_system_info 函数收集并打印系统相关信息,包括操作系统、Python 版本、内存、CPU 和 CUDA 信息。
自动混合精度检查:check_amp 函数检查 PyTorch 的自动混合精度功能是否正常。
Git 描述:git_describe 函数返回人类可读的 Git 描述信息。
打印函数参数:print_args 函数打印函数的参数信息。
CUDA 设备计数:cuda_device_count 函数获取可用的 NVIDIA GPU 数量。
CUDA 可用性检查:cuda_is_available 函数检查环境中是否可用 CUDA。
这些函数的设计旨在确保 YOLO 模型在运行时的环境配置正确,依赖项满足要求,从而提高模型的稳定性和性能。通过这些检查,用户可以在运行模型之前确认系统的兼容性和配置的正确性。
11.4 ultralytics\data_init_.py
引入Ultralytics YOLO 🚀库,遵循AGPL-3.0许可证
从base模块导入BaseDataset类
from .base import BaseDataset
从build模块导入构建数据加载器和YOLO数据集的函数
from .build import build_dataloader, build_yolo_dataset, load_inference_source
从dataset模块导入分类数据集、语义数据集和YOLO数据集的类
from .dataset import ClassificationDataset, SemanticDataset, YOLODataset
定义模块的公共接口,允许外部访问以下类和函数
all = (
‘BaseDataset’, # 基础数据集类
‘ClassificationDataset’, # 分类数据集类
‘SemanticDataset’, # 语义分割数据集类
‘YOLODataset’, # YOLO数据集类
‘build_yolo_dataset’, # 构建YOLO数据集的函数
‘build_dataloader’, # 构建数据加载器的函数
‘load_inference_source’ # 加载推理源的函数
)
注释说明:
引入模块:代码的开头部分引入了必要的模块和类,这些模块是构建YOLO模型所需的基础组件。
all:这是一个特殊的变量,用于定义当使用from module import *时,哪些名称会被导入。这里列出了所有希望公开的类和函数,便于用户了解可用的接口。
这个程序文件是Ultralytics YOLO项目中的一个初始化文件,文件名为__init__.py,它的主要作用是定义该模块的公共接口和导入必要的类和函数。
首先,文件开头的注释部分标明了该项目是Ultralytics YOLO,并且使用了AGPL-3.0许可证。这意味着该项目是开源的,用户可以自由使用和修改,但需要遵循相应的许可证条款。
接下来,文件通过相对导入的方式引入了几个模块中的类和函数。具体来说,它从base模块中导入了BaseDataset类,从build模块中导入了build_dataloader、build_yolo_dataset和load_inference_source这三个函数,从dataset模块中导入了ClassificationDataset、SemanticDataset和YOLODataset这三个类。
最后,__all__变量定义了该模块的公共接口,列出了可以被外部导入的类和函数。这种做法有助于控制模块的可见性,确保用户只访问到模块中指定的部分,而不是所有的内部实现细节。
总的来说,这个文件的主要功能是组织和管理Ultralytics YOLO项目中的数据集相关的类和函数,为用户提供一个清晰的接口以便于使用。
11.5 ultralytics\models\sam\modules\sam.py
以下是经过简化并注释的核心代码部分:
import torch
from torch import nn
from typing import List
class Sam(nn.Module):
“”"
Sam (Segment Anything Model) 是一个用于对象分割任务的模型。它使用图像编码器生成图像嵌入,并使用提示编码器对各种输入提示进行编码。然后,这些嵌入被掩码解码器用于预测对象掩码。
“”"
def __init__(self,image_encoder: nn.Module, # 图像编码器,用于将图像编码为嵌入prompt_encoder: nn.Module, # 提示编码器,用于编码输入提示mask_decoder: nn.Module, # 掩码解码器,用于从图像嵌入和提示中预测掩码pixel_mean: List[float] = (123.675, 116.28, 103.53), # 图像归一化的均值pixel_std: List[float] = (58.395, 57.12, 57.375) # 图像归一化的标准差
) -> None:"""初始化 Sam 类以从图像和输入提示中预测对象掩码。参数:image_encoder (nn.Module): 用于编码图像的主干网络。prompt_encoder (nn.Module): 编码各种类型输入提示的模块。mask_decoder (nn.Module): 从图像嵌入和编码提示中预测掩码的模块。pixel_mean (List[float], optional): 输入图像的像素归一化均值,默认为 (123.675, 116.28, 103.53)。pixel_std (List[float], optional): 输入图像的像素归一化标准差,默认为 (58.395, 57.12, 57.375)。"""super().__init__() # 调用父类构造函数self.image_encoder = image_encoder # 初始化图像编码器self.prompt_encoder = prompt_encoder # 初始化提示编码器self.mask_decoder = mask_decoder # 初始化掩码解码器# 注册图像归一化的均值和标准差self.register_buffer('pixel_mean', torch.Tensor(pixel_mean).view(-1, 1, 1), False)self.register_buffer('pixel_std', torch.Tensor(pixel_std).view(-1, 1, 1), False)
代码说明:
导入模块:导入必要的库,包括 torch 和 nn(神经网络模块),以及 List 类型提示。
Sam 类:定义了一个名为 Sam 的类,继承自 nn.Module,用于实现对象分割模型。
构造函数 init:
接收图像编码器、提示编码器和掩码解码器作为参数,并初始化它们。
pixel_mean 和 pixel_std 用于图像的归一化处理,以提高模型的性能。
使用 register_buffer 方法注册均值和标准差,使其成为模型的一部分,但不作为模型的可学习参数。
这个程序文件定义了一个名为 Sam 的类,属于 Ultralytics YOLO 项目的一部分,主要用于对象分割任务。Sam 类继承自 PyTorch 的 nn.Module,这是构建神经网络模型的基础类。
在这个类中,首先定义了一些属性,包括 mask_threshold 和 image_format,分别用于设置掩码预测的阈值和输入图像的格式(默认为 RGB)。接下来,类的构造函数 init 接受多个参数,包括图像编码器、提示编码器和掩码解码器。这些组件分别负责将输入图像编码为特征嵌入、对各种输入提示进行编码以及根据图像和提示的嵌入预测对象的掩码。
构造函数中还包含了用于图像归一化的均值和标准差参数,默认值分别为 (123.675, 116.28, 103.53) 和 (58.395, 57.12, 57.375)。这些参数通过 register_buffer 方法注册为模型的缓冲区,这样它们就不会被视为模型的可训练参数,但仍然会在模型的状态字典中保存。
总体而言,Sam 类的设计目的是将图像和提示信息结合起来,通过一系列编码和解码过程,最终实现对图像中对象的分割。该类的实现为后续的前向传播操作提供了基础,但具体的前向计算逻辑被移到了 SAMPredictor 类中。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是一个基于Ultralytics YOLO的目标检测和图像分割系统,主要用于处理图像和视频中的对象分割任务。程序的整体架构由多个模块组成,每个模块负责特定的功能,形成一个完整的工作流。
用户界面:web.py 提供了一个交互式的Web界面,允许用户通过摄像头或上传文件进行目标检测和分割,并展示检测结果。
模型管理:ultralytics/models/yolo/segment/init.py 负责导入和组织与YOLO模型相关的功能,提供预测、训练和验证的接口。
环境检查:ultralytics/utils/checks.py 进行环境和依赖项的检查,确保系统配置正确,以支持模型的运行。
数据处理:ultralytics/data/init.py 组织和导入与数据集相关的类和函数,支持数据加载和处理。
模型定义:ultralytics/models/sam/modules/sam.py 定义了一个用于对象分割的核心模型类,负责将输入图像和提示信息结合起来进行掩码预测。
文件功能整理表
文件路径 功能描述
C:\codeseg\codenew\code\web.py 提供一个基于Streamlit的用户界面,允许用户进行目标检测和图像分割,展示检测结果。
C:\codeseg\codenew\code\ultralytics\models\yolo\segment_init_.py 导入和组织与YOLO模型相关的功能,提供预测、训练和验证的接口。
C:\codeseg\codenew\code\ultralytics\utils\checks.py 进行环境和依赖项的检查,确保系统配置正确,以支持模型的运行。
C:\codeseg\codenew\code\ultralytics\data_init_.py 组织和导入与数据集相关的类和函数,支持数据加载和处理。
C:\codeseg\codenew\code\ultralytics\models\sam\modules\sam.py 定义一个用于对象分割的核心模型类,负责将输入图像和提示信息结合起来进行掩码预测。
这个表格清晰地展示了每个文件的功能,有助于理解整个程序的架构和工作流程。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻