java集合进阶
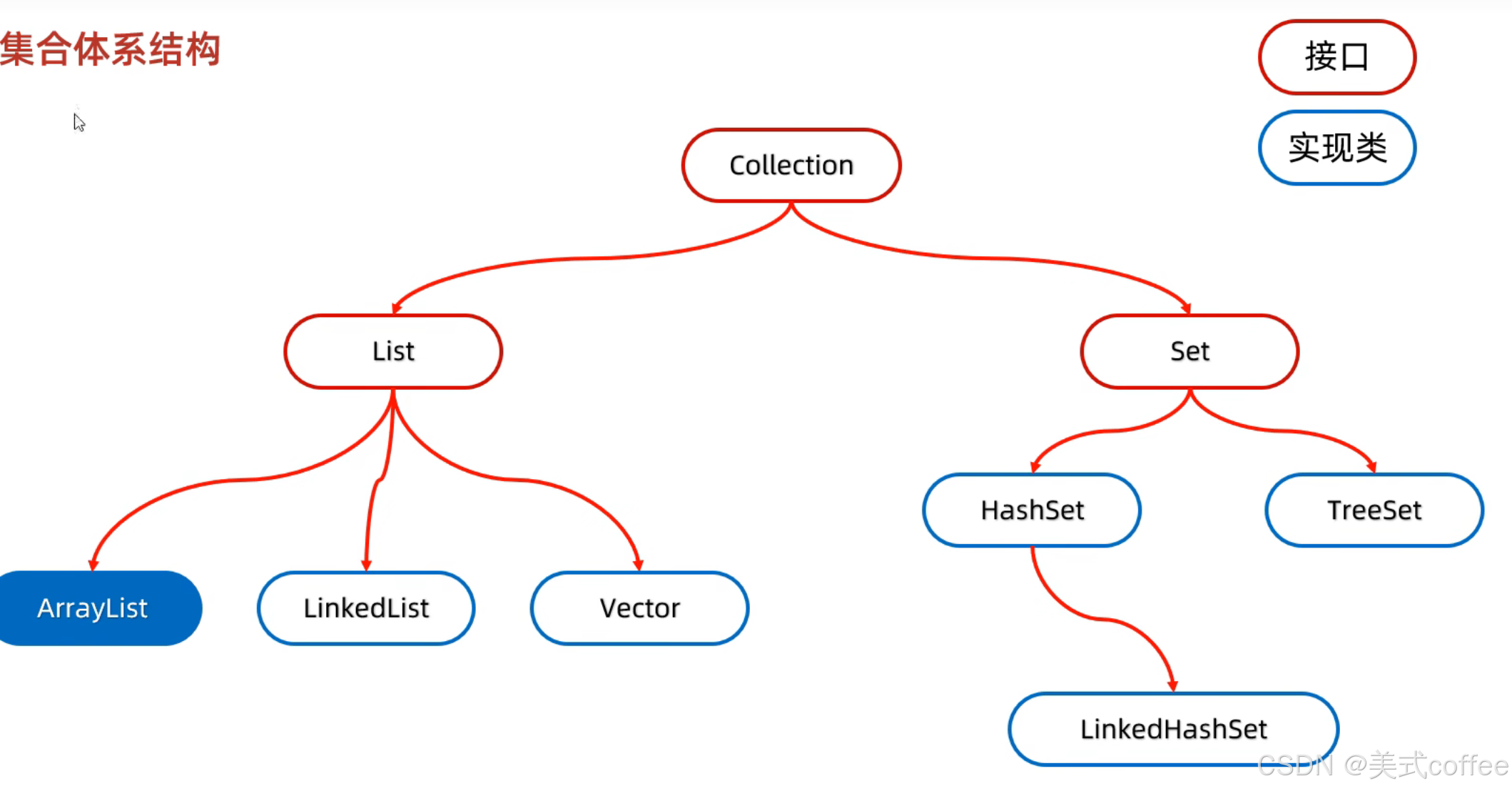
集合体系结构
Collection集合
List
数据结构
ArrayList
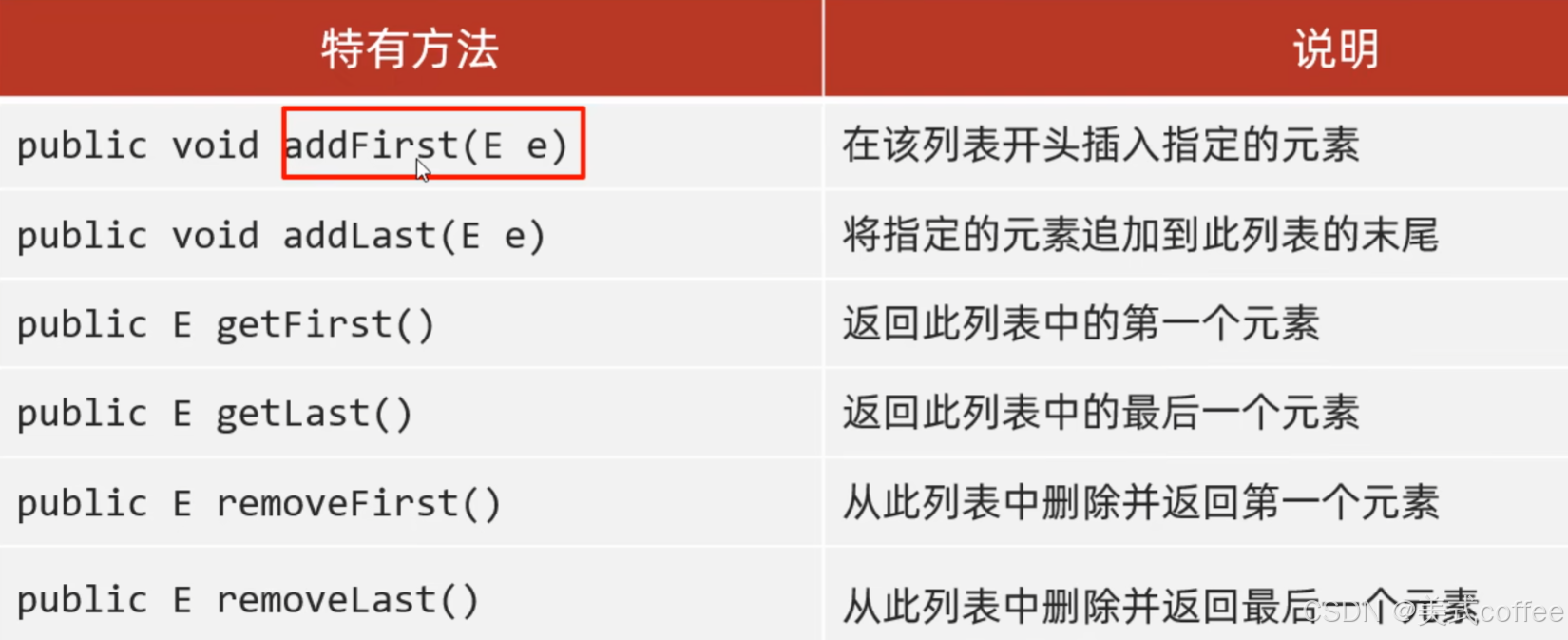
LinkedList
泛型深入
数据结构树
Set系列集合
HashSet
LinkedHashSet
TreeSet
集合体系结构
- 单列集合:在添加数据时,每次添加一个数据
List系列集合:添加的元素是有序、可重复、有索引
Set系列集合:添加的元素是无序、不重复、无索引
有序:存进去和取出来的顺序是一样的
- 双列集合:在添加数据时,每次添加一对数据
Collection
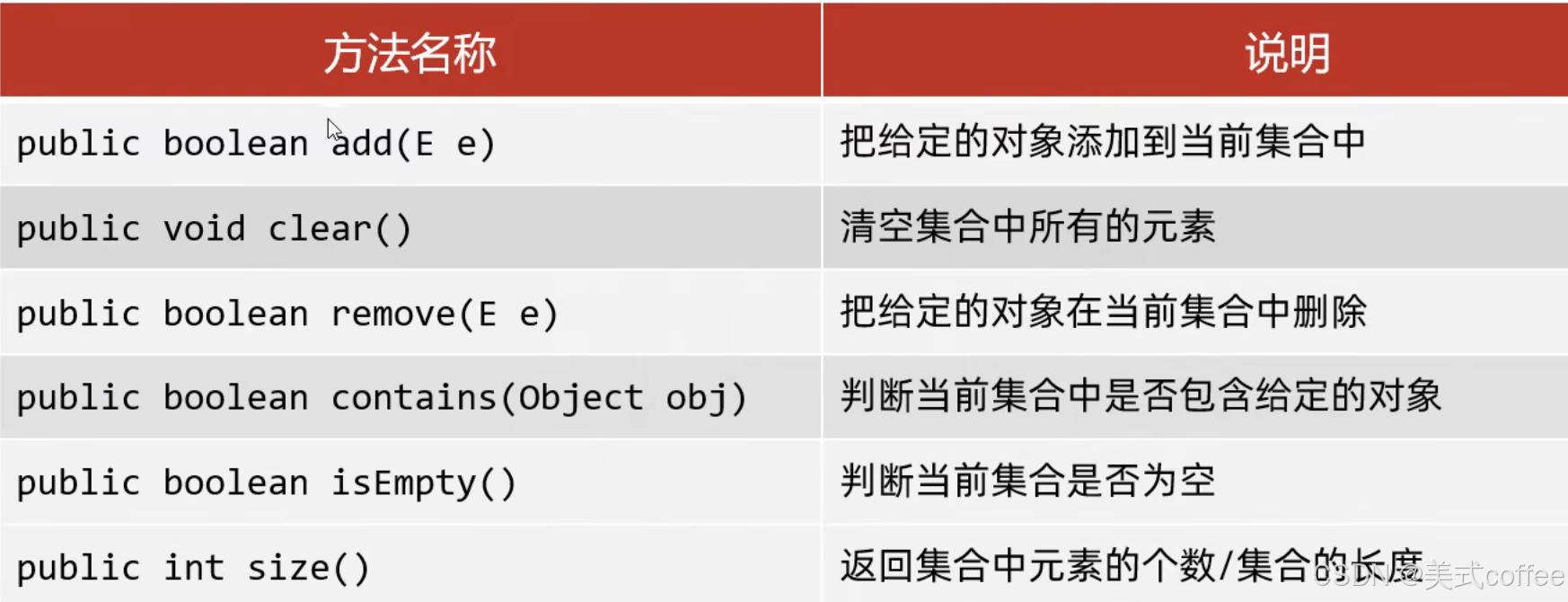
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。
迭代器遍历
迭代器不依赖索引
迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式。
Collection集合获取迭代器

Iterator中常用方法

细节注意:
- 报错NoSuchElementException
- 迭代器遍历完毕,指针不会复位
- 循环中只能用一次next方法
- 迭代器遍历时,不能用集合的方法进行增加或者删除
- 如果我实在要删除:那么可以用迭代器提供的remove方法进行删除。
增强for遍历
所有的单列集合和数组才能用增强for进行遍历。

修改增强for中的变量,不会改变集合中原本的数据
Lambda表达式遍历

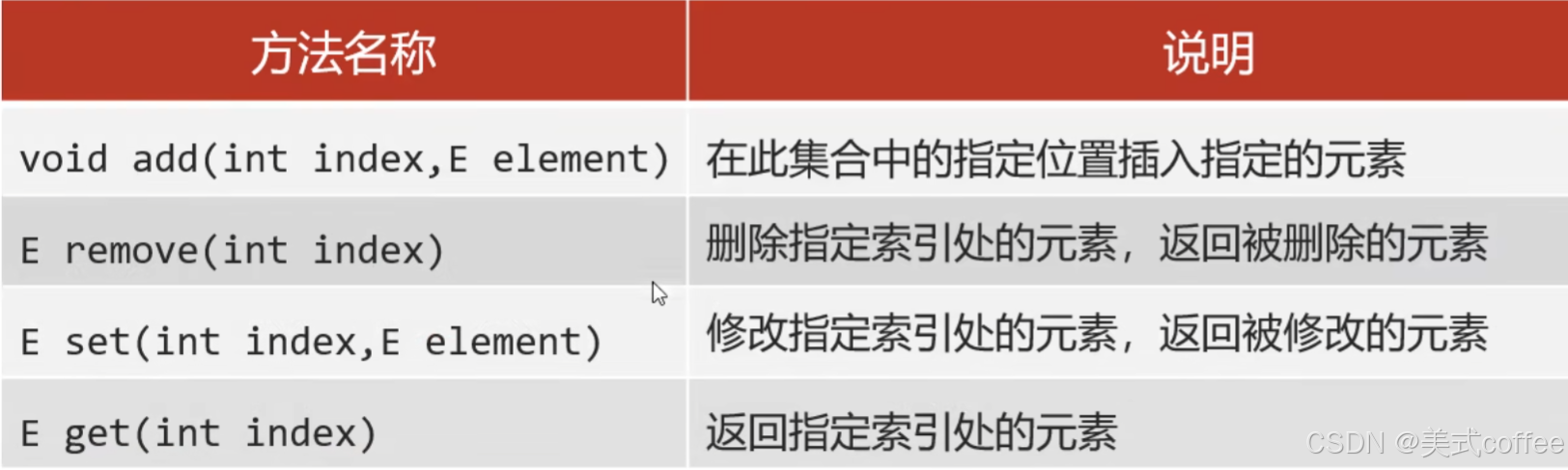
List
List集合的特点
- 有序:存和取的元素顺序一致
- 有索引:可以通过索引操作元素
- 可重复:存储的元素可以重复’
- Collection的方法List都继承了

List集合遍历
- 迭代器遍历:在遍历的过程中需要删除元素,请使用迭代器
- 列表迭代器遍历:在遍历的过程中需要添加元素,请使用列表迭代器
- 增强for遍历
- Lambda表达式遍历
- 普通for遍历
数据结构
计算机存储、组织数据的方式
是指数据相互之间是以什么方式排列在一起的。
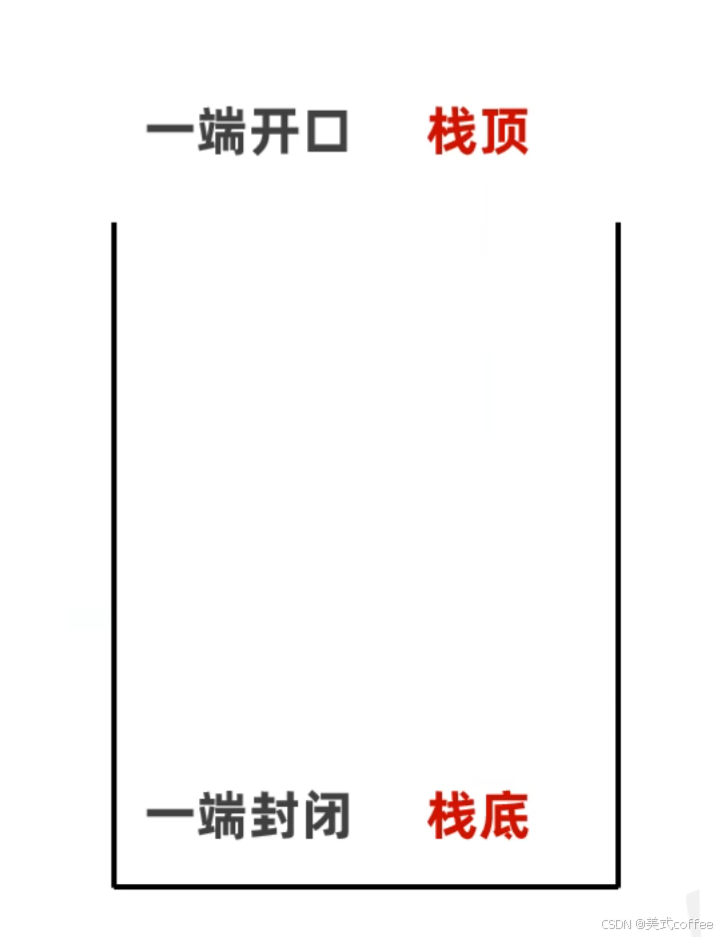
数据进入栈模型的过程称为:压/进栈
数据离开栈模型的过程称为:弹/出栈
栈
后进先出,先进后出
队列
先进先出,后进后出
数据从后端进入队列模型的过程称为:入队列
数据从前端离开队列模型的过程称为:出队列

数组
数组是一种查询快,增删慢的模型
- 查询速度快::查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中是连续存储的)
- 删除效率低:要将原始数据删除,同时后面每个数据前移
- 添加效率极低:添加位置后的每个数据后移,再添加元素。
链表
链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址。
链表查询慢,无论查询哪个数据都要从头开始找,
ArrayList
底层原理
- 利用空参创建的集合,在底层创建一个默认长度为0的数组(elementData)
- 添加第一个元素时,底层会创建一个新的长度为10的数组(默认null)
- 存满时,会扩容1.5倍
- 如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准


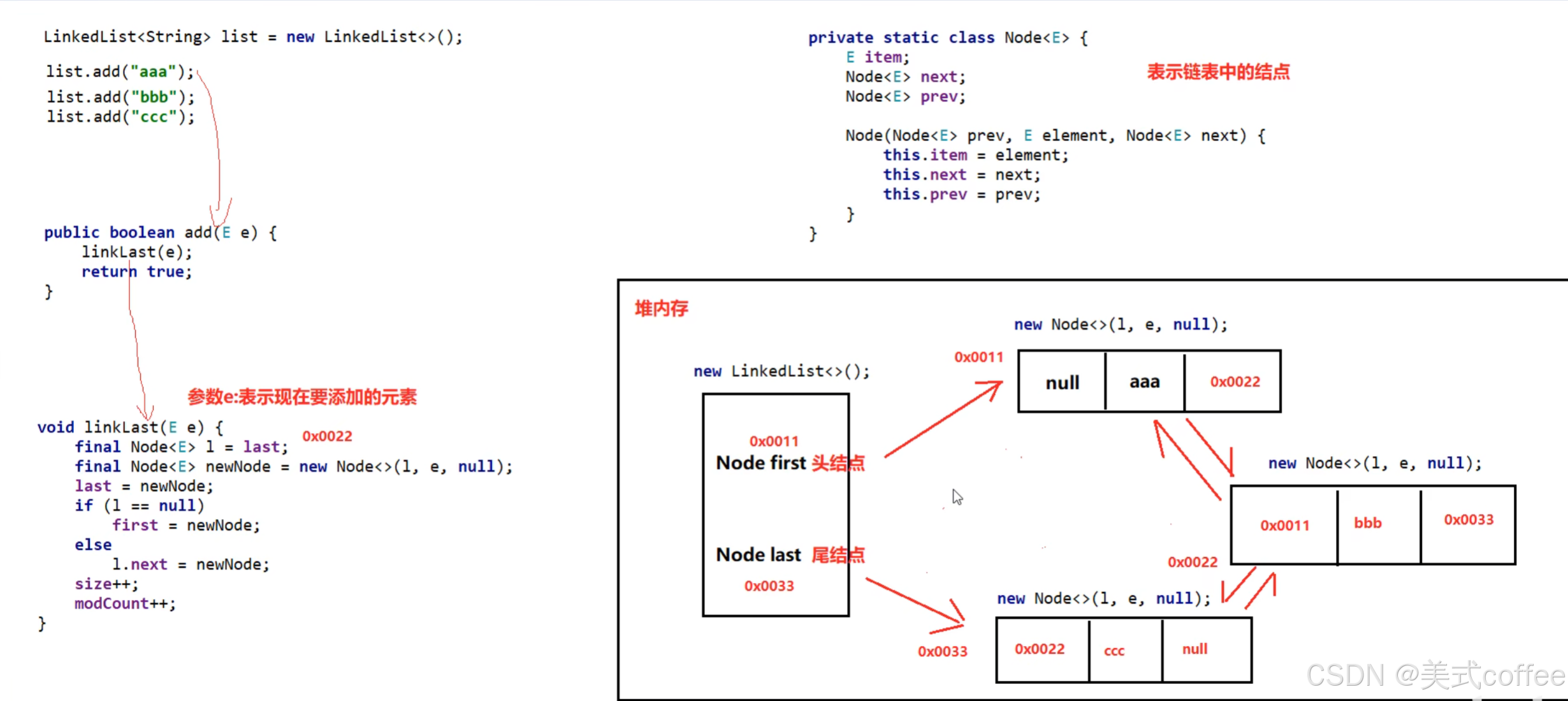
LinkedList
底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
底层源码
迭代器底层

泛型深入
泛型:是IDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型的格式:<数据类型>
注意:
泛型只能支持引用数据类型,
指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型,
如果不写泛型,类型默认是Object
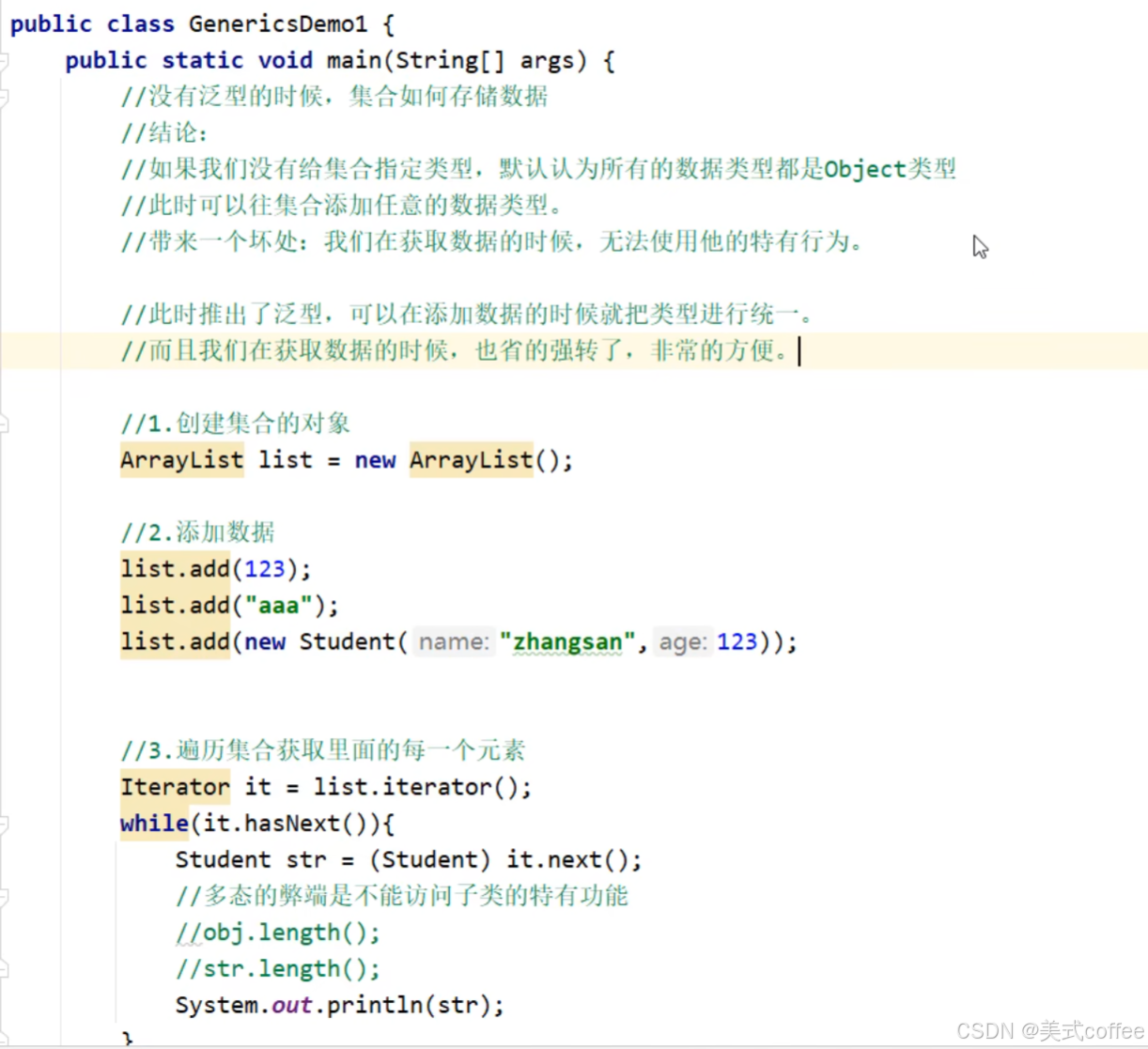
扩展知识点:Java中的泛型是伪泛型
泛型很多地方进行定义
- 类后面–泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
格式:修饰符 class 类名<类型>{}
此处E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型,可以写成:T、E、K、V等

- 方法上面–泛型方法
方法中形参类型不确定时
方案①:使用类名后面定义的泛型,所有方法都能用
方案②:在方法申明上定义自己的泛型,只有本方法能用
格式:修饰符<类型> 返回值类型 方法名 (类型 变量名) {}
- 接口后面–泛型接口
格式:修饰符 interface 接口名<类型>{
}
使用:
方式1:实现类给出具体类型
方式2:实现类延续泳型,创建对象时再确定
泛型的继承和通配符
- 泛型不具备继承性,但是数据具备继承性
此时,泛型里面写的是什么类型,那么只能传递什么类型的数据
弊端:利用泛型方法有一个小弊端,此时他可以接受任意的数据类型
此时我们就可以使用泛型的通配符:
?也表示不确定的类型,他可以进行类型的限定
? extends E:表示可以传递E或者E所有的子类类型
? super E :表示可以传递E或者E所有的父类类型
应员场景
1.如果我们在定义类、方法、接口的时候,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口。
2.如果类型不确定,但是能知道以后只能传递某个继承体系中的,就可以泛型的通配符
数据结构树
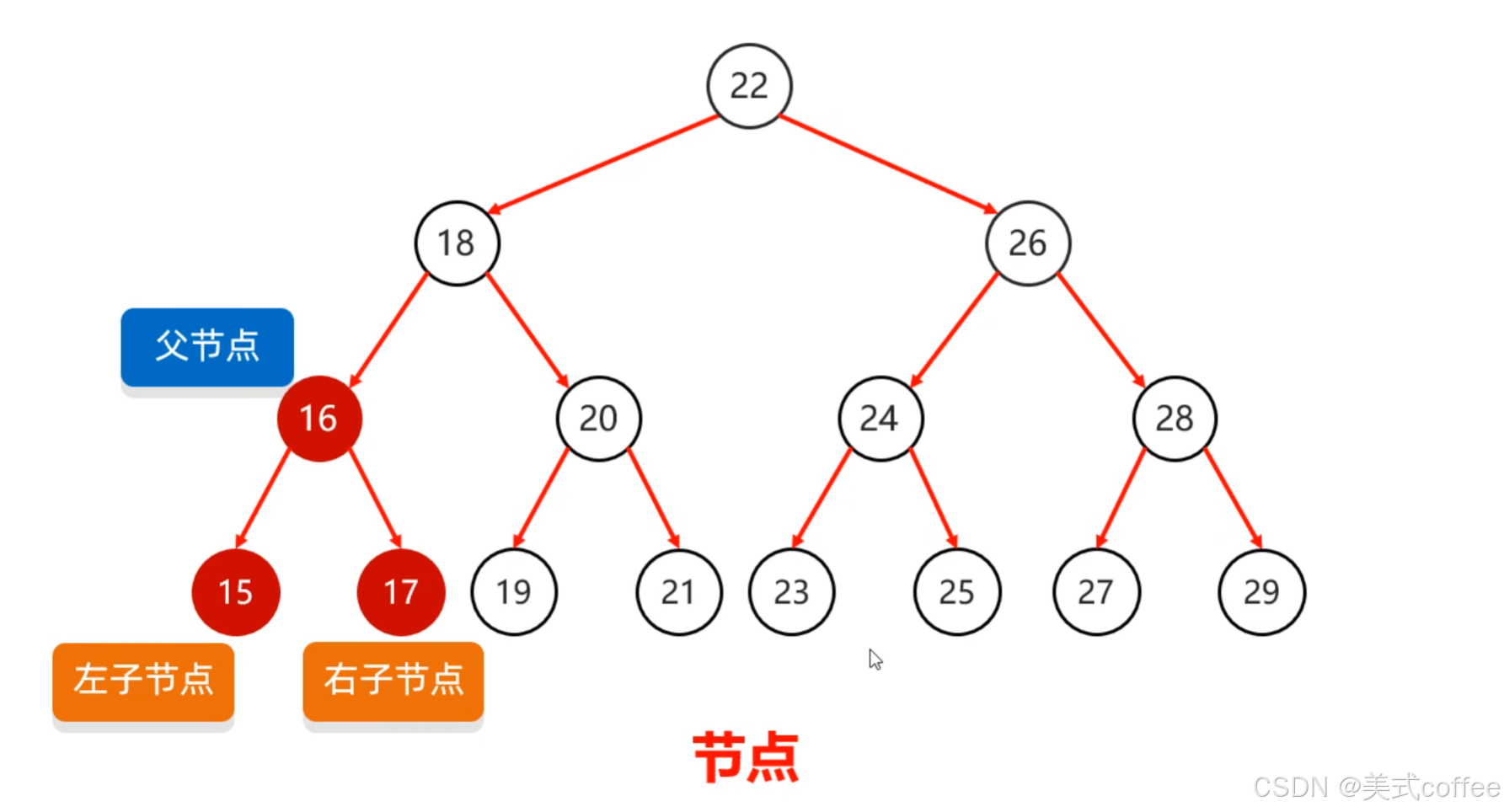
度:每一个节点的子节点数量
二叉树中,任意节点的度<=2
树高:树的总层数
根节点:最顶层的节点
二叉查找树
二叉查找树,又称二叉排序树或者二叉搜索树
- 每一个节点上最多有两个子节点
- 任意节点左子树上的值都小于当前节点
- 任意节点右子树上的值都大于当前节点
添加节点:小的存左边,大的存右边,一样的不存
遍历方式
- 前序遍历:从根结点开始,然后按照当前结点,左子结点,右子结点的顺序遍历
- 中序遍历:从最左边的子节点开始,然后按照左子结点,当前结点,右子结点的顺序遍历
- 后序遍历:从最左边的子节点开始,然后按照左子结点,右子结点,当前结点的顺序遍历
- 层序遍历:从根节点开始一层一层的遍历
平衡二叉树
规则:任意节点左右子树高度差不超过1
触发时机:当添加一个节点之后,该树不再是一颗平衡二叉树
旋转机制:
- 左旋:
确定支点:从添加的节点开始,不断的往父节点找不平衡的节点
步骤:
1.以不平衡的点作为支点
2.把支点左旋降级,变成左子节点
3.晋升原来的右子节点
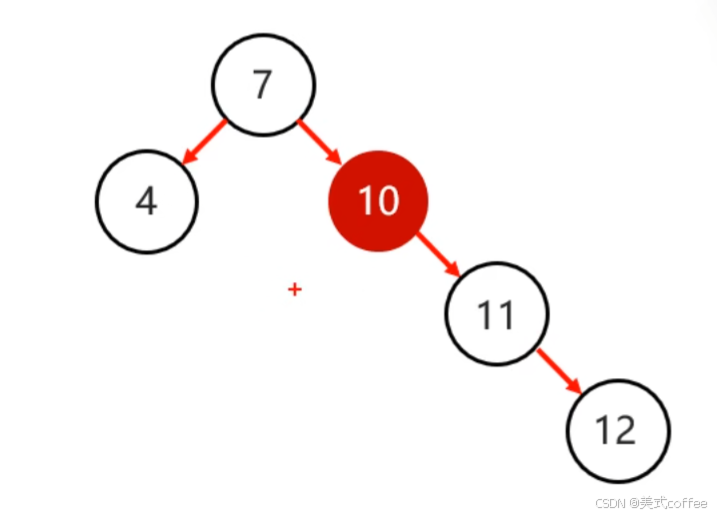
步骤:
1.以不平衡的点作为支点
2.将根节点的右侧往左拉
3.原先的右子节点变成新的父节点,并把多余的左子节点出让,给已经降级的根节点当右子节点
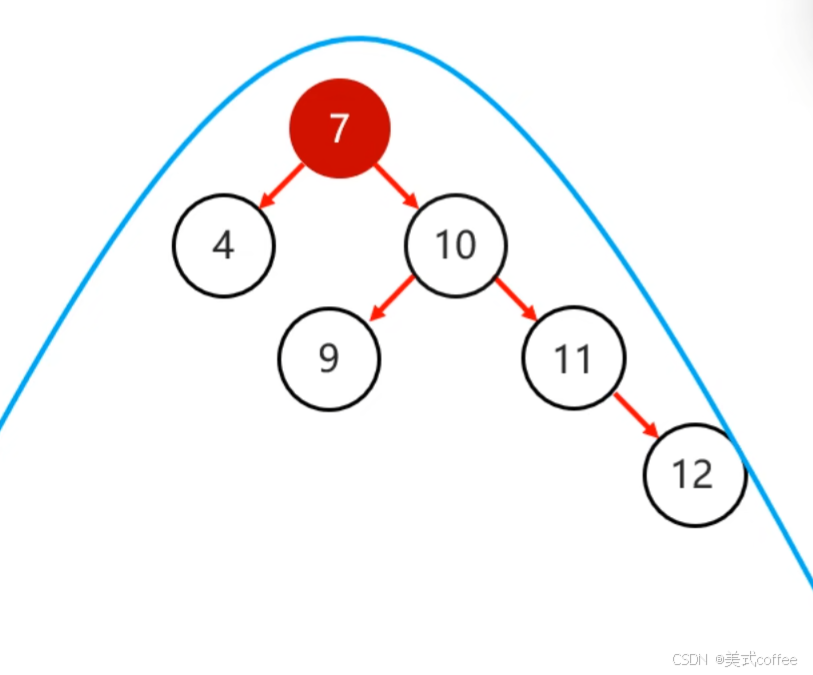
- 右旋
步骤:
1.以不平衡的点作为支点
2.把支点右旋降级,变成右子节点
3.晋升原来的左子节点
步骤:
1.以不平衡的点作为支点
2.将根节点的左侧往右拉
3.原先的左子节点变成新的父节点,并把多余的右子节点出让,给已经降级的根节点当左子节点
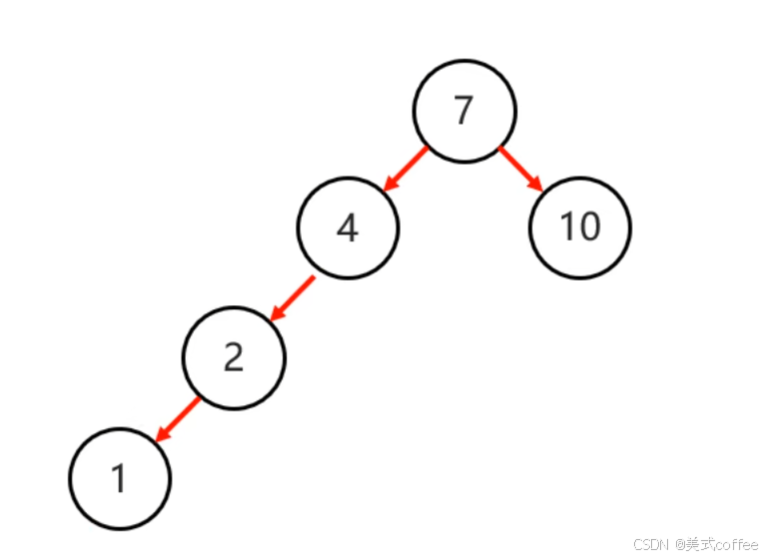
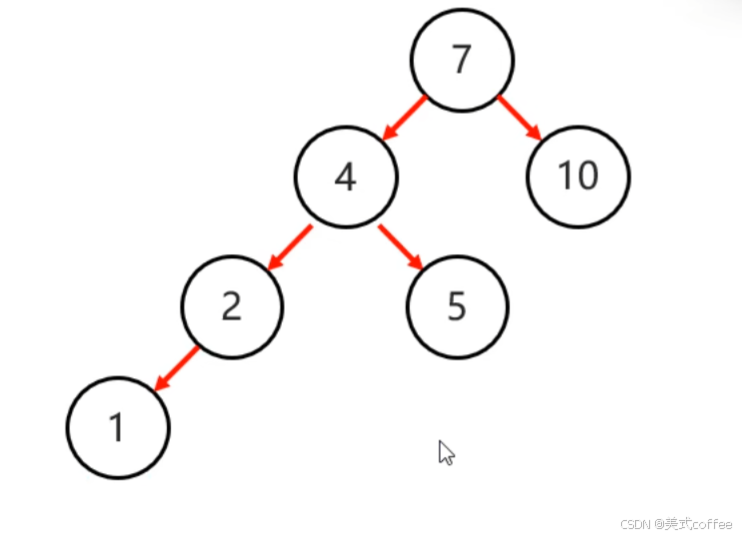
旋转的情况
- 左左:当根节点左子树的左子树有节点插入,导致二又树不平衡,一次右旋
- 左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡,先局部左旋,在整体右旋
- 右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡,一次左旋
- 右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡,先局部右旋,再整体左旋
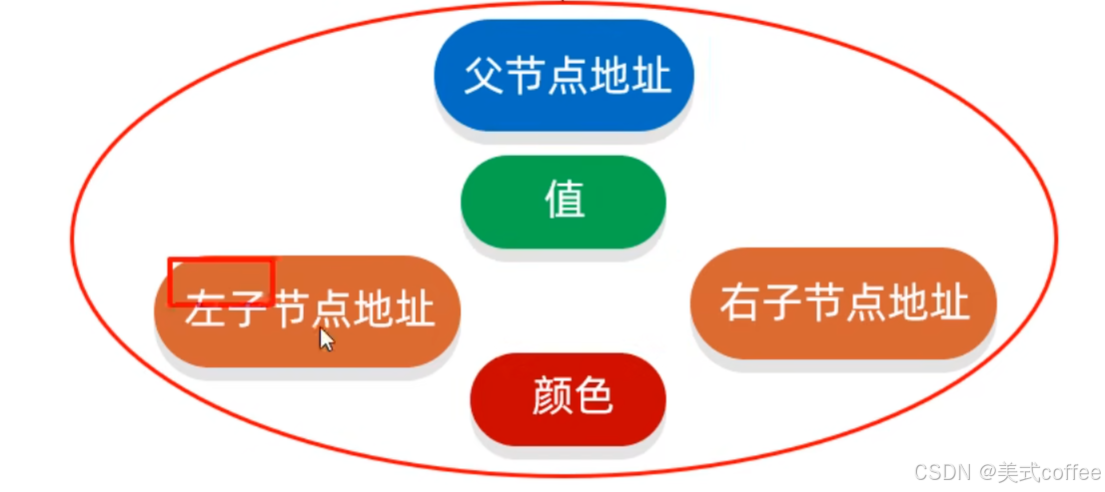
红黑树
- 红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。
- 它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色
- 一个节点可以是红或者黑;红黑树不是高度平衡的,它的平衡是通过"红黑规则"进行实现的
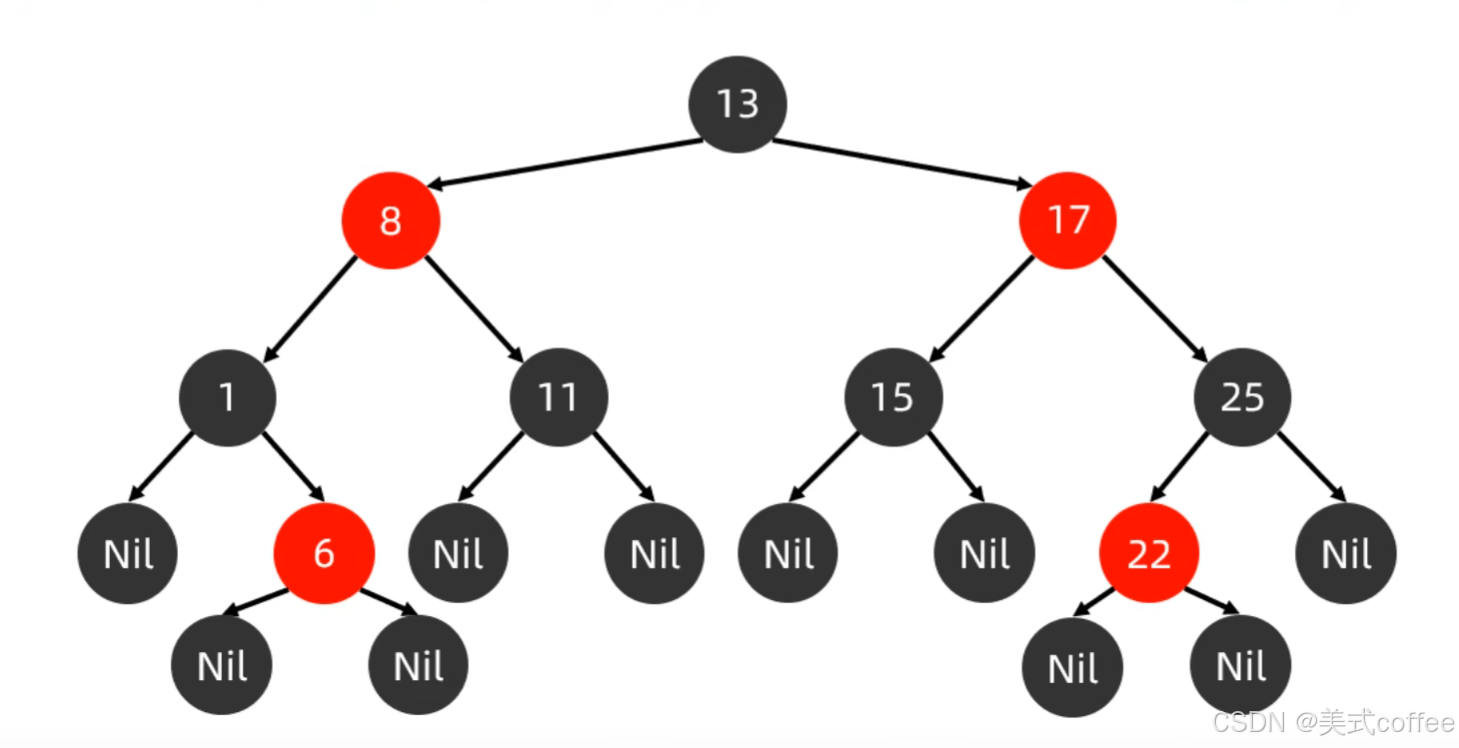
红黑规则
- 每一个节点或是红色的,或者是黑色的
- 根节点必须是黑色
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
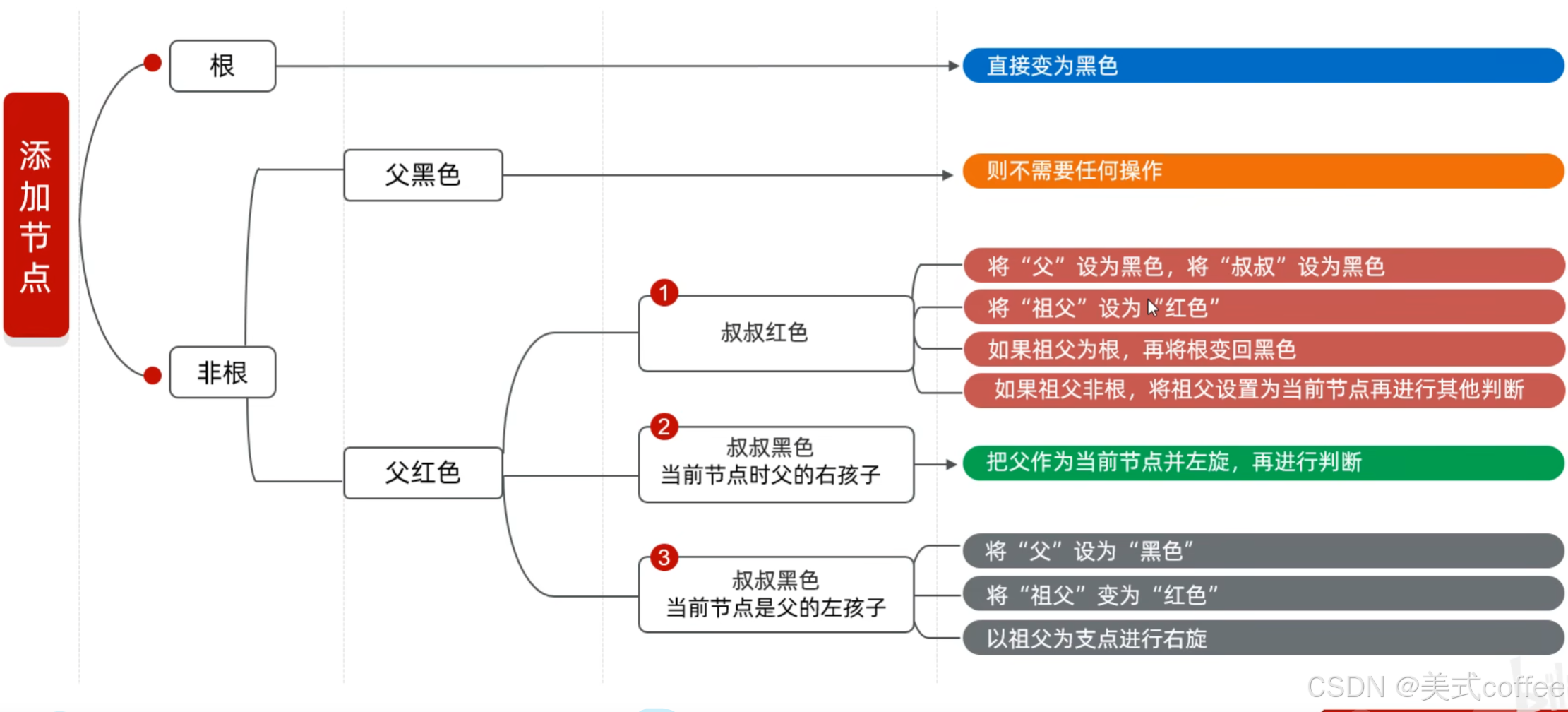
添加节点的规则
默认颜色:添加节点默认是红色的(效率高)
Set系列集合
- 无序:存取顺序不一致
- 不重复:可以去除重复
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素
HashSet(无序、不重复、无索引)
Hashset集合底层采取哈希表存储数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
数组+链表+红黑树
哈希值
对象的整数表现形式
添加数据不是从0索引开始添加的而是通过下面这个公式计算出应存储的位置

- 根据hashcode方法算出来的int类型的整数
- 该方法定义在0bject类,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashcode方法,利用对象内部的属性值计算哈希值
哈希值特点
- 如果没有重写上hashcode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
底层原理
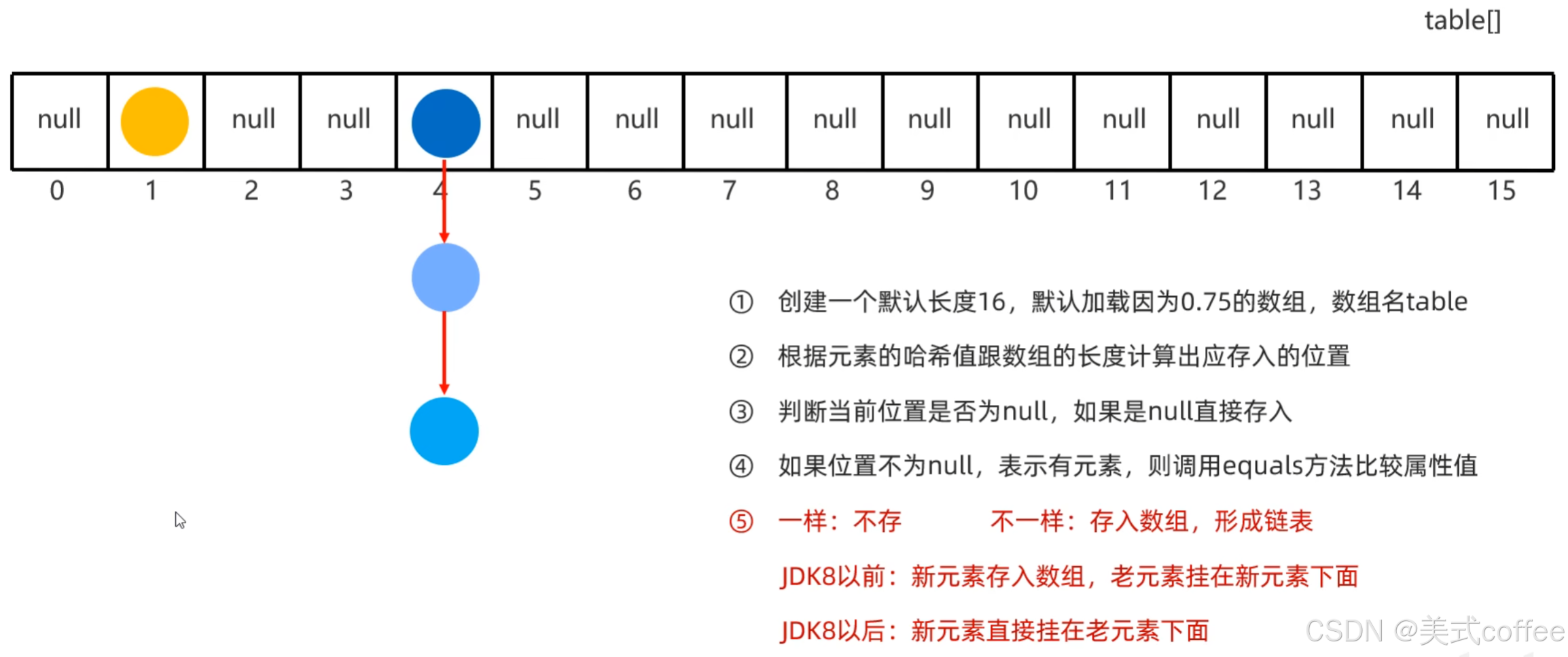
当数组存了16*0.75=12元素后,会扩容为原先的两倍
JDK8以后,当链表长度超过8而且数组长度大于等于64时自动转换为红黑树
如果集合中存储的是自定义对象,必须要重写hashcode和equals方法
重写hashcode是为了我们根据属性值计算哈希值
重写equals方法是为了比较的时候比较的对象内部的属性值
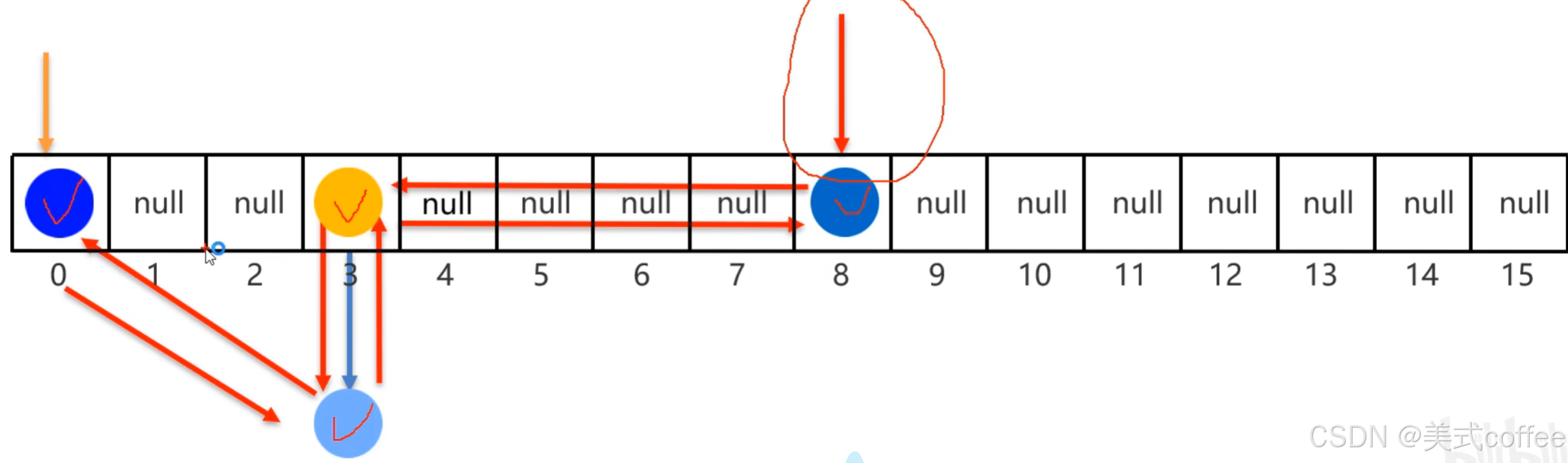
LinkedHashSet(有序、不重复、无索引)
底层原理
存储和取出的这里的有序指的是保证的元素顺序一致
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序。
TreeSet(可排序、不重复、无索引)
可排序:按照元素的默认规则(有小到大)排序。
Treeset集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
集合默认规则
对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序
比较方式
方式一:默认排序/自然排序:Javabean类实现Comparable接口指定比较规则
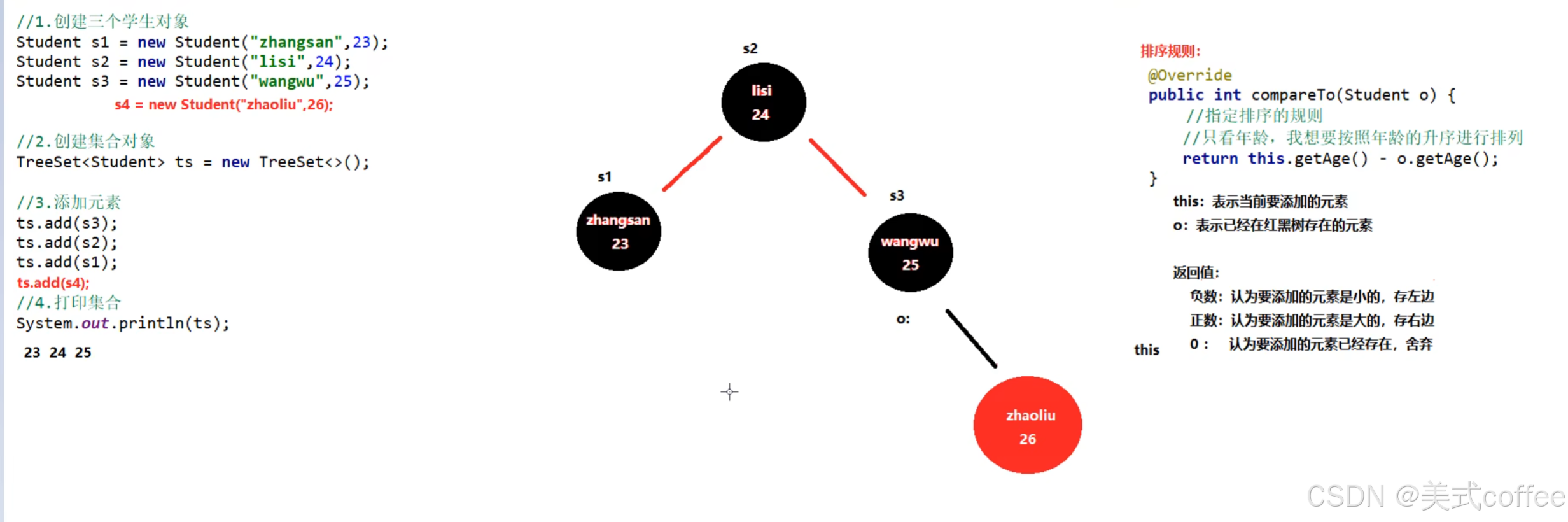
方式二:比较器排序:创建Treeset对象时候,传递比较器Comparator指定规则
同时存在以方式二为准
总结:
1.如果想要集合中的元素可重复用ArrayList集合,基于数组的。(用的最多)
2.2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询用 ,LinkedList集合,基于链表的。
3.如果想对集合中的元素去重用HashSet集合,基于哈希表的。(用的最多)
4.如果想对集合中的元素去重,而且保证存取顺序用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet
5.如果想对集合中的元素进行排序,用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。