哈尔滨公司建站模板四川省工程信息造价网
在电商采购和供应链管理中,了解供应商的工厂信息是至关重要的一步。1688 作为国内领先的 B2B 平台,提供了丰富的供应商和工厂档案信息。通过 item_get_factory API 接口,开发者可以获取工厂的详细信息,包括工厂名称、地址、联系方式、生产能力等。本文将详细介绍如何使用 Python 爬虫调用该接口,并解析返回的工厂档案信息。
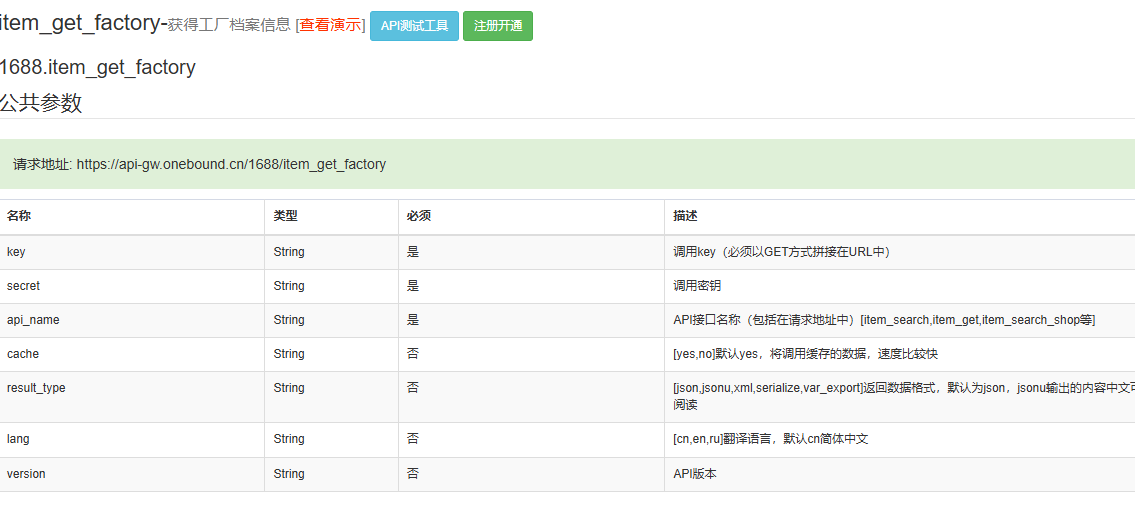
一、准备工作
(一)注册 1688 开放平台账号
访问 1688 开放平台官网,注册开发者账号并创建应用。在创建应用时,需要填写应用名称、描述等信息,并申请使用 item_get_factory 接口的权限。
(二)获取 API 密钥
完成应用创建后,平台会提供 App Key 和 App Secret,这是调用 API 接口的必要凭证。
(三)安装 Python 库
确保 Python 环境中已安装 requests 库,用于发送 HTTP 请求。如果未安装,可以通过以下命令安装:
bash
pip install requests二、调用 item_get_factory 接口
(一)构建请求参数
item_get_factory 接口需要以下参数:
-
key:App Key -
secret:App Secret -
sid:工厂或店铺的唯一标识 ID
以下是一个完整的 Python 示例代码,展示如何调用该接口并获取工厂档案信息:
Python
import requests# 替换为你的API Key和Secret
API_KEY = 'your_api_key'
API_SECRET = 'your_api_secret'# API接口地址
API_URL = 'https://api-gw.fan-b.com/1688/item_get_factory/'# 构建请求参数
def get_factory_info(api_key, api_secret, sid):params = {'key': api_key,'secret': api_secret,'sid': sid # 工厂或店铺ID}response = requests.get(API_URL, params=params)return response.json()# 测试代码
if __name__ == "__main__":sid = 'b2b-2216359427002c502b' # 示例工厂IDfactory_info = get_factory_info(API_KEY, API_SECRET, sid)if 'result' in factory_info:factory_data = factory_info['result']print(f"工厂名称: {factory_data.get('companyName', 'N/A')}")print(f"工厂地址: {factory_data.get('companyAddress', 'N/A')}")print(f"联系人: {factory_data.get('contactPerson', 'N/A')}")print(f"联系电话: {factory_data.get('contactPhone', 'N/A')}")else:print(f"请求失败,错误信息: {factory_info.get('error_msg', '未知错误')}")(二)解析返回数据
接口返回的数据通常以 JSON 格式呈现,包含工厂的详细信息。以下是返回数据的常见字段:
-
companyName:工厂名称 -
companyAddress:工厂地址 -
contactPerson:联系人 -
contactPhone:联系电话
三、返回数据说明
(一)工厂基本信息
-
companyName:工厂名称,标识工厂的主体名称。
-
companyAddress:工厂地址,提供工厂的具体地理位置信息。
-
contactPerson:联系人,负责与外界沟通和业务对接的人员。
-
contactPhone:联系电话,用于联系工厂的电话号码。
(二)其他信息
-
factoryInfo:工厂的其他详细信息,可能包含生产规模、生产能力等。
-
certifications:工厂的认证信息,如 ISO 认证等,有助于评估工厂的生产标准和质量控制。
四、数据处理与应用
获取到工厂档案信息后,可以根据需求进行进一步的数据处理和分析。例如,可以使用 pandas 库将数据保存为 CSV 文件,方便后续使用:
Python
import pandas as pd# 示例:提取工厂名称和地址
factory_data = [{"工厂名称": factory_info['result']['companyName'],"工厂地址": factory_info['result']['companyAddress']}
]
df = pd.DataFrame(factory_data)
df.to_csv('factory_info.csv', index=False, encoding='utf-8')五、注意事项
(一)遵守法律法规和网站协议
在使用 Python 爬虫获取 API 接口数据时,必须严格遵守相关法律法规和网站的使用协议。
(二)处理异常情况
在爬虫运行过程中,可能会遇到各种异常情况,如网络请求失败、数据解析错误等。需要在代码中添加异常处理机制,确保爬虫的稳定性和可靠性。
六、总结与展望
通过 Python 调用 1688 的 item_get_factory 接口,可以高效地获取工厂的详细档案信息,这些信息对于采购决策、市场分析和供应链管理具有重要意义。未来,随着技术的发展和电商平台的不断更新,开发者可以结合更多技术手段,如大数据分析和机器学习,进一步挖掘数据价值,为商业决策提供更精准的依据。
总之,合理利用 1688 的 API 接口,能够为电商从业者和市场研究人员带来极大的便利,但需始终遵循合法合规的原则。
如遇任何疑问或有进一步的需求,请随时与我私信或者评论联系。