group scheduling
为什么要有组调度
Linux是支持多用户、多session的。如果只是提供基于任务实体的调度,那么试想一下,用户A有1个任务,而用户B有3个任务。很显然,用户B将得到更多的CPU占用率。这在某种程度上来说是不公平。甚至极端情况下,用户B可能有100个任务,从而导致系统卡顿,而用户A只有一个任务,也不得不跟着卡顿。这就即为不合理了。这就诞生了group scheduling,即将每个用户(或者session)的所有任务归为一组,以group作为调度单位,去竞争cpu份额。这样就会更加合理!
如何进行组调度
数据结构关系
描述这种group的数据结构名为"task_group",属于cgroup架构的cpu子系统。它既不是同一进程的线程构成的thread group,也不是load balance中以CPU为单位的sched_group,它是task group。
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity **se;
struct cfs_rq **cfs_rq;
unsigned long shares;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
struct task_group *parent;
struct cfs_bandwidth cfs_bandwidth;
...
};
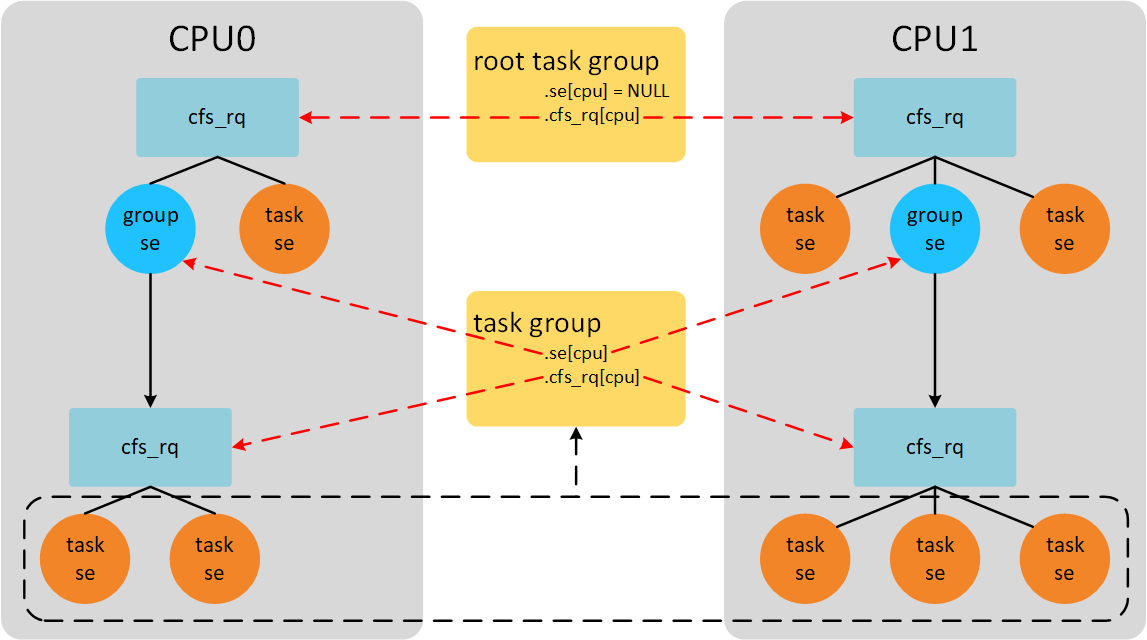
- 从调度的层面,task group作为一个调度单位,和其他的task/task group一起参与CPU份额的分配,因此task group也以"sched_entity"形式参与调度,由"task_group->se[cpu]"指向。
- 以CFS为例,当这个task group因为vruntime最小被选中时,还需要从这个group中再挑选其中vruntime最小的task,所以这个group也形成了一个runqueue,被"task_group->cfs_rq[cpu]"指向。
注意:
1、这里"se" 和"cfs_rq" 都是以二级指针的形式出现的,实际代表结构体数组,数组的长度为CPU的数目,这是因为一个task group往往包含多个runable的任务,而这些任务可能在多个CPU上运行。
2、调度实体有权重的概念,以权重的比例分配CPU时间。用户组同样有权重的概念,share就是task_group的权重。
下图展示了cgroup目录和task group数据结构之间的关系:
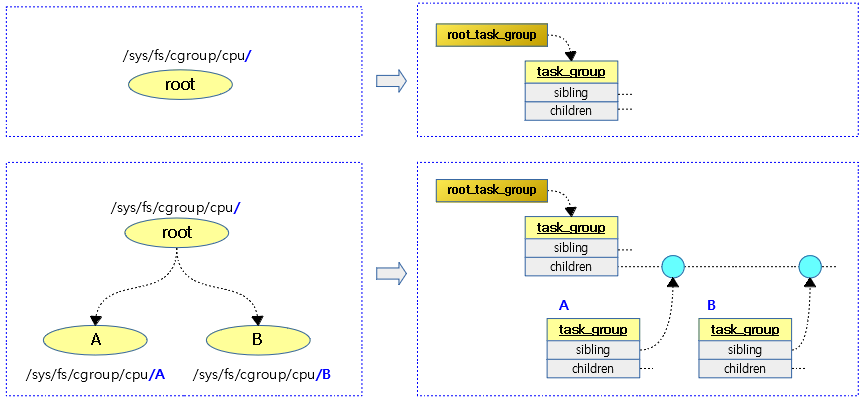
这里父task group的children成员和子task group的sibling成员是个什么关系?其实,子task_group在创建好后,online的时候,会以sibling节点加入父task_group的children链表中,形成一个兄弟链(sibling)。对子tg来说是sibling link;而对父tg来说,则都是children!链表建立之后,就方便task_group的遍历了。
下图展示了task group、schedule entity以及cfs_rq之间的关系:
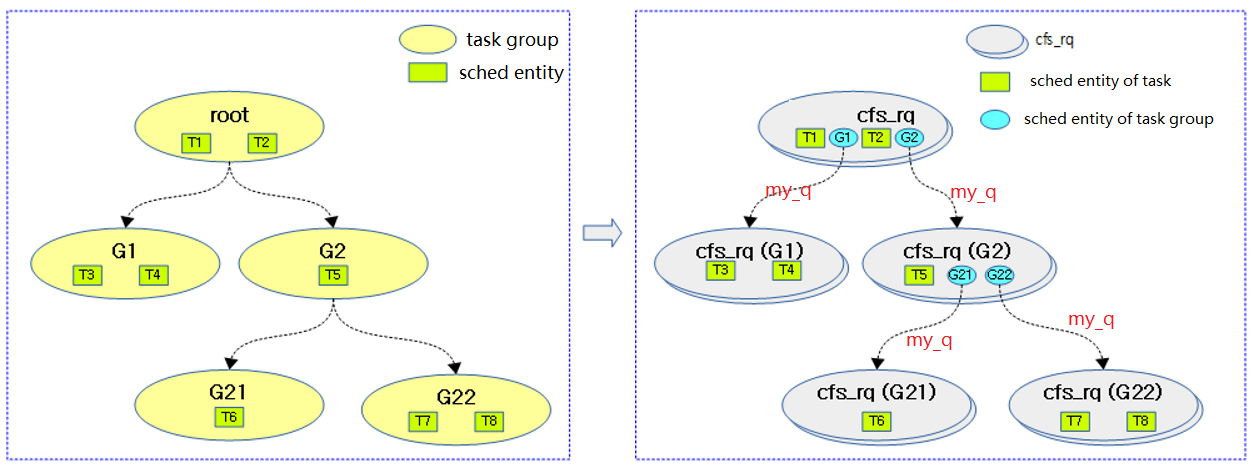
上图左,黄色椭圆表示task group;绿色的方框表示具体task的entity。
上图右,灰色椭圆表示cfs_rq,蓝色椭圆表示task group的entity,其有my_q成员指向自己task group对应该cpu的子rq。这可以区别于普通task的entity(其my_q成员为NULL)!
从上图可以看出,在task group存在的情况下,cfs_rq形成了多级级联的hierarchy。调度器pick_next_task的时候,如果选中了task group的entity,则还会继续递归的从其owned的rq中挑选具体的task来执行。参照代码:
- static struct task_struct *
- pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
- {
- struct cfs_rq *cfs_rq = &rq->cfs; /* 1 */
- struct sched_entity *se;
- struct task_struct *p;
- put_prev_task(rq, prev);
- do {
- se = pick_next_entity(cfs_rq, NULL); /* 2 */
- set_next_entity(cfs_rq, se);
- cfs_rq = group_cfs_rq(se); /* 3 */
- } while (cfs_rq); /* 4 */
- p = task_of(se);
- return p;
- }
/* runqueue "owned" by this group */
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp)
{
return grp->my_q;
}
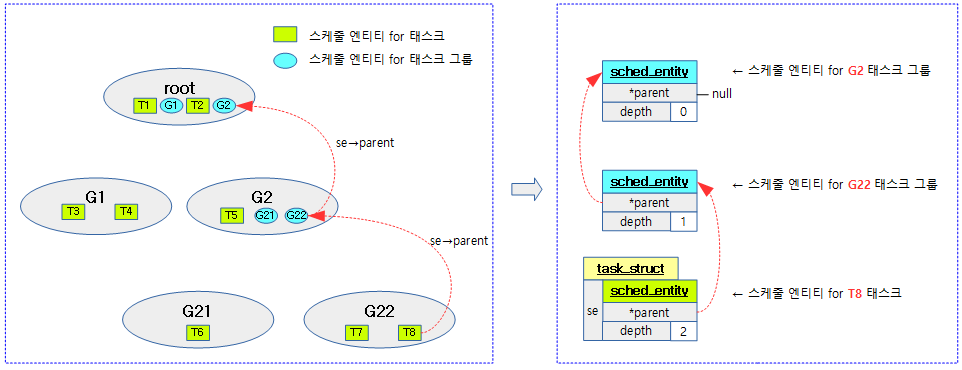
The following figure shows the parent relationship of schedule entities:
用户组的权重
每一个进程都会有一个权重,CFS调度器依据权重的大小分配CPU时间。同样task_group也不例外,前面已经提到使用share成员记录。Task group的share值,默认设置为1024(NICE_0_LOAD):
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent)
{
……
tg->shares = NICE_0_LOAD;
……
}
不过,也可以通过用户态手动修改(其中A/B为级联的两层task group):
echo 512 > /sys/fs/cgroup/cpu/A/B/cpu.shares
注意:root task group的share值(“/sys/fs/cgroup/cpu/cpu.shares”)不能通过上述方式修改!
按照前面的举例,系统有2个CPU,task_group中势必包含两个group se和与之对应的group cfs_rq。这2个group se的权重按照比例分配task_group权重。如下图所示:
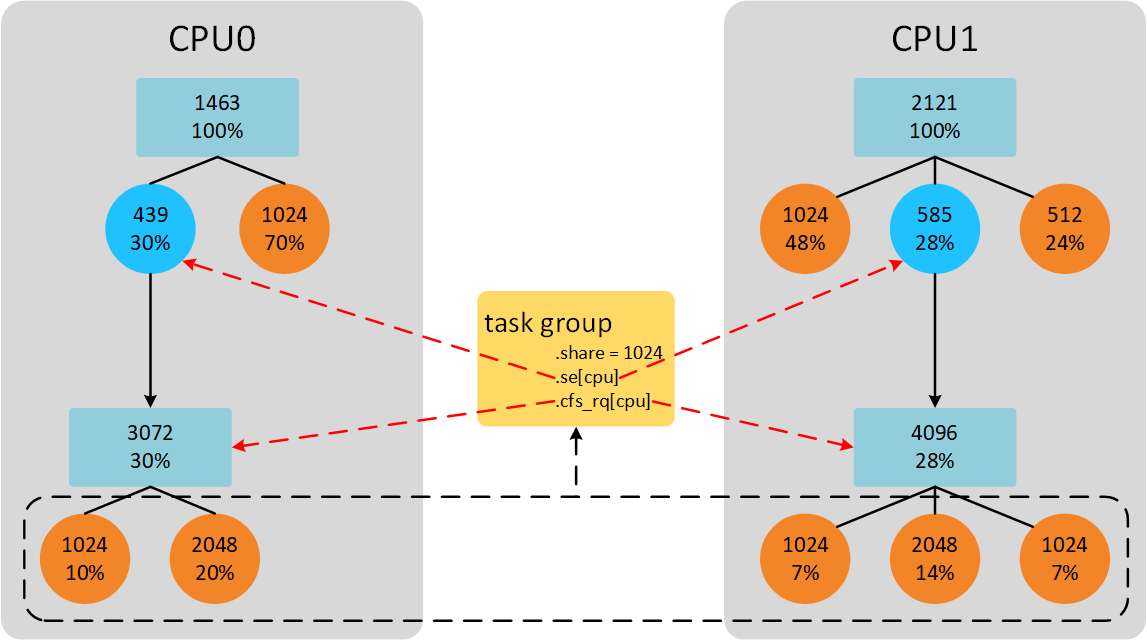
CPU0上group se下有2个task se,权重和是3072。CPU1上group se下有3个task se,权重和是4096。task_group权重是1024。因此,CPU0上group se权重是439(1024*3072/(3072+4096)),CPU1上group se权重是585(1024-439)。
注意:这里的计算group se权重的方法是最简单的方式示例,代码中实际计算公式是考虑每个group cfs_rq的负载贡献比例,而不是简单的考虑权重比例。
calc_group_shares
前面章节举例说到group se的权重计算是根据权重比例计算。但是,实际的代码并不是。当我们dequeue task、enqueue task以及task tick的时候会通过update_cfs_group()函数更新group se的权重信息。而核心的工作则在calc_group_shares()函数中。该函数内使用的计算权重的算法颇为奇怪,内核也给出了长篇的注释,用来解释这个算法,如下:
/*
* All this does is approximate the hierarchical proportion which includes that
* global sum we all love to hate.
*
* That is, the weight of a group entity, is the proportional share of the
* group weight based on the group runqueue weights. That is:
*
* tg->weight * grq->load.weight
* ge->load.weight = ----------------------------- (1)
* \Sum grq->load.weight
*
* Now, because computing that sum is prohibitively expensive to compute (been
* there, done that) we approximate it with this average stuff. The average
* moves slower and therefore the approximation is cheaper and more stable.
*
* So instead of the above, we substitute:
*
* grq->load.weight -> grq->avg.load_avg (2)
*
* which yields the following:
*
* tg->weight * grq->avg.load_avg
* ge->load.weight = ------------------------------ (3)
* tg->load_avg
*
* Where: tg->load_avg ~= \Sum grq->avg.load_avg
*
* That is shares_avg, and it is right (given the approximation (2)).
*
* The problem with it is that because the average is slow -- it was designed
* to be exactly that of course -- this leads to transients in boundary
* conditions. In specific, the case where the group was idle and we start the
* one task. It takes time for our CPU's grq->avg.load_avg to build up,
* yielding bad latency etc..
*
* Now, in that special case (1) reduces to:
*
* tg->weight * grq->load.weight
* ge->load.weight = ----------------------------- = tg->weight (4)
* grp->load.weight
*
* That is, the sum collapses because all other CPUs are idle; the UP scenario.
*
* So what we do is modify our approximation (3) to approach (4) in the (near)
* UP case, like:
*
* ge->load.weight =
*
* tg->weight * grq->load.weight
* --------------------------------------------------- (5)
* tg->load_avg - grq->avg.load_avg + grq->load.weight
*
* But because grq->load.weight can drop to 0, resulting in a divide by zero,
* we need to use grq->avg.load_avg as its lower bound, which then gives:
*
*
* tg->weight * grq->load.weight
* ge->load.weight = ----------------------------- (6)
* tg_load_avg'
*
* Where:
*
* tg_load_avg' = tg->load_avg - grq->avg.load_avg +
* max(grq->load.weight, grq->avg.load_avg)
*
* And that is shares_weight and is icky. In the (near) UP case it approaches
* (4) while in the normal case it approaches (3). It consistently
* overestimates the ge->load.weight and therefore:
*
* \Sum ge->load.weight >= tg->weight
*
* hence icky!
*/
上面注释中,有一些简写需要说明一下:
- tg——》task_group
- ge——》task_group->se[cpu]
- grq——》task_group->cfs_rq[cpu]
- \Sum 表示percpu的数据求和
其实,注释里第(1)个公式正是上一章节计算group se权重使用的公式。后面出于方便计算的目的,逐步演化为目前代码里使用的第(6)个公式。演化的过程及依据,也在英文注释里说明了,这里就不再画色添足的翻译了。其核心,就是用cfs_rq->avg.load_avg来近似替代cfs_rq->load.weight,进而也就不用计算task_group percpu cfs_rq的权重之和了,而是直接使用task_group->load_avg变量!
其他说明:
- task group中的任务还可能具有不同的属性,其中一些是普通任务,另一些是实时任务,所以"task_group"中的"se"可能位于cfs_rq上,也可能位于rt_rq上。在RT调度中,总是选择优先级最高的se来执行,那task group作为se,其优先级该如何界定呢?原则是选择group中优先级最高的任务的priority作为group的priority。
- "/proc/sys/kernel/"目录下两个参数"sched_rt_period_us" 和"sched_rt_runtime_us" ,默认值分别是1000000和950000,单位是us,因此分别是1s和0.95s,意思是在1s的时间内,实时任务至多可运行0.95s,剩下的0.05s则留给普通任务。这样设计主要是为了防止万一有实时任务失心疯地占着CPU不放,至少还可以通过普通任务的运行,尝试从这种异常中恢复。