HRPC在Polaris存储系统中的应用
摘要
通信是分布式系统的基石。本文旨在介绍Polaris分布式存储系统的专用通信机制HRPC。介绍HRPC作为系统的一个基础组件,是如何结合系统内存池管理,协程等其他组件,为存储系统上层应用打造一个高效的低时延高并发高带宽的通信框架。
HRPC是什么
HRPC是Polaris分布式存储系统用于消息传输的专用网络通信模块。HRPC将上层多种类型请求消息进行封装,使用RDMA进行快速数据传输。HRPC对业务层提供了简单易用的高效异步消息通信接口,同时屏蔽了底层网络不同传输层的差异。在支持RDMA等较新网络传输技术的同时,也兼容传统的TCP网络。以下是HRPC在系统中的位置:
RDMA简介
分布式存储通过网络将各个独立的存储节点互联组成集群,并通过网络对外提供服务。网络是影响分布式集群整体性能的一个重要因素。数据读写、复制、恢复、再平衡等关键行为,以及各组件间各端口的心跳检测和通信,无一不受到网络的影响。随着节点网络带宽的提升,尤其是进入100G+的时代,传统的TCP/IP软硬件架构及应用存在着网络传输和数据处理的延迟过大、存在多次数据拷贝和中断处理、以及复杂的TCP/IP协议处理等问题。为了解决传统TCP/IP协议在网络传输时所引入的较高时延和对服务器资源的过度消耗等问题,采用RDMA技术是当下一种理想的选择。
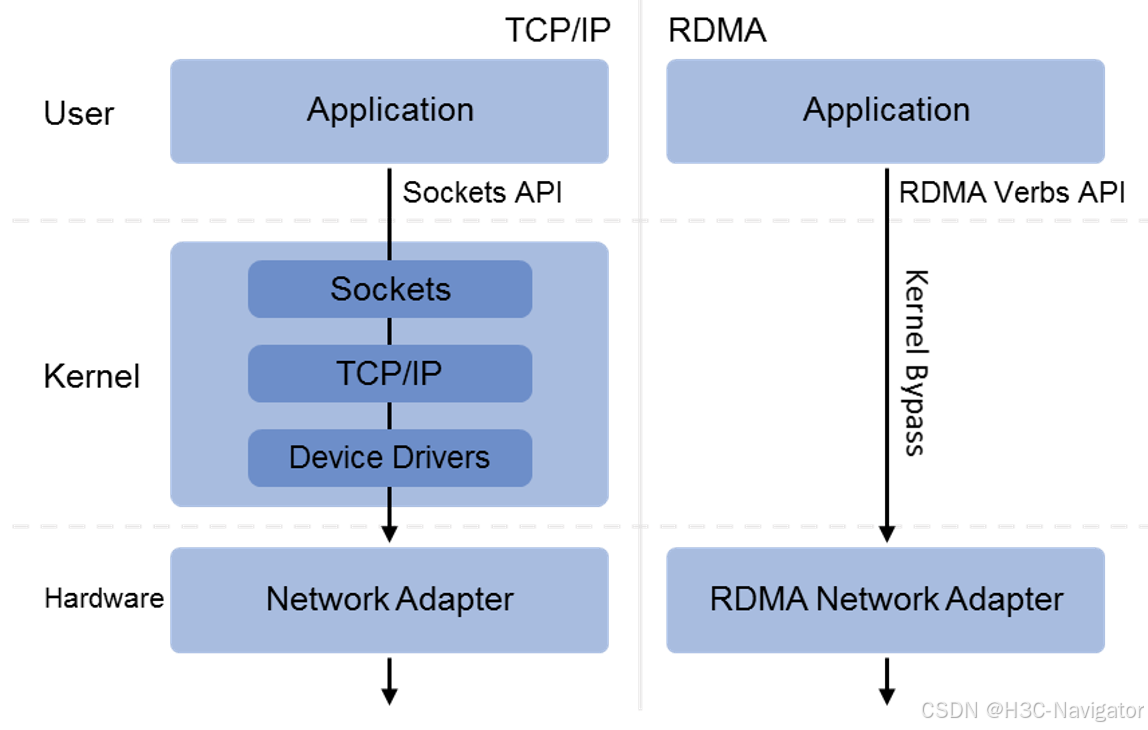
RDMA(Remote Direct Memory Access,远程直接内存访问)是一种为了解决网络传输中服务器端数据处理延迟而产生的技术。RDMA技术实现了在网络传输过程中两个节点之间数据缓冲区数据的直接传递。在本节点可以直接将数据通过网络传送到远程节点的内存中,具备零拷贝、内核旁路和CPU卸载三个标志性的技术特点,数据平面工作由RDMA硬件网卡完成,同时做到了高带宽、低时延、低CPU开销。下图是TCP/IP和RDMA的IO栈流程差异示意图:
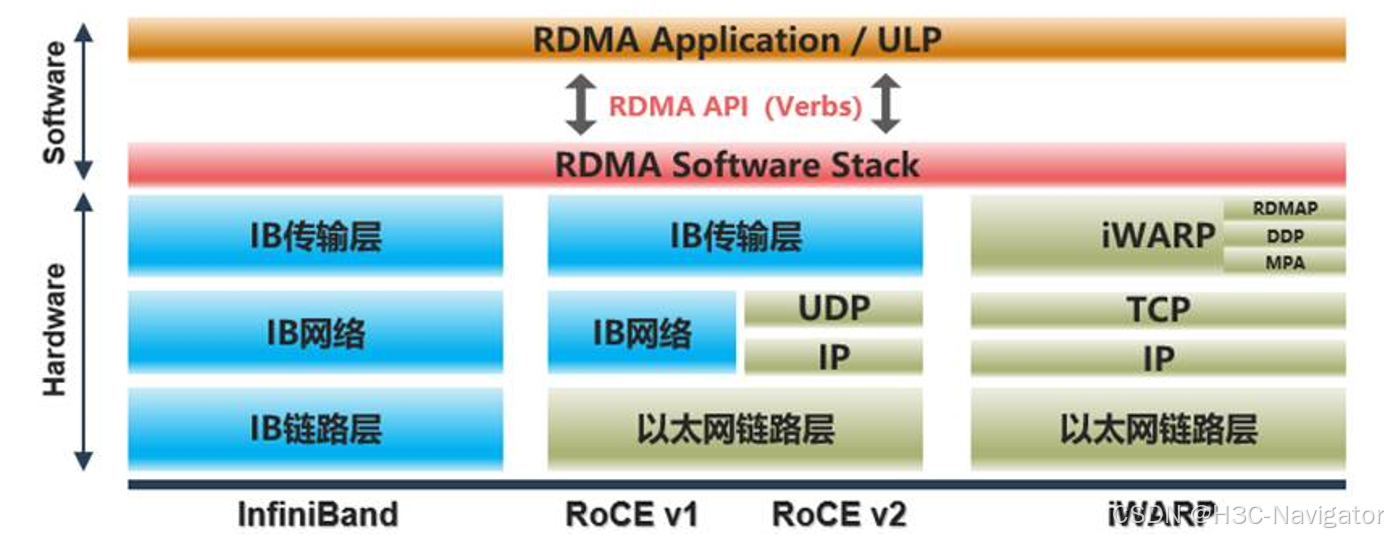
当前RDMA技术的实现方式主要有InfiniBand、RoCE、iWARP三种:
• IB(InfiniBand):基于InfiniBand 架构的RDMA 技术,由IBTA(InfiniBand Trade Association)
提出。InfiniBand是专为RDMA设计的网络,主要应用在HPC领域,其有一整套完整的框架和链路层到传输层规范,架构较为封闭,需要用专用的硬件设备搭建一套独立的组网。
• RoCE(RDMA over Converged Ethernet):基于以太网的RDMA 技术,由IBTA 提出。
包括RoCE v1和RoCE v2。RoCE v1基于以太网链路层封装IB报文,适用于单个二层网络。由于缺乏三层路由功能,因此RoCE v1的应用较为有限。RoCE v2在RoCE v1的基础上进行了改进,采用以太网的UDP协议对IB协议报文进行封装。这使得RoCE v2具备了三层路由能力和更好的扩展性。当前RoCE v2的应用更为广泛。
• iWARP(Internet Wide Area RDMA Protocal):基于TCP/IP 协议的RDMA 技术,由IETF 标准定义。基于TCP协议实现的iWARP协议能在有损网络场景中提供比RoCE更好的可靠性。但相对的,TCP协议的连接机制和可靠性保障机制会带来大量的开销,这导致iWARP性能比RoCE和IB协议更低。
RDMA虽然是一种高效的网络传输技术,但要用好并不容易,并不是将传统socket编程接口进行简单替换即可。相比传统socket,RDMA编程更接近底层硬件。特别是在当前闪存介质普及的情况下,要完全发挥RDMA与新型存储设备的性能优势,需要从整体框架上进行RDMA适配,将IO路径上各模块联动优化才是分布式存储追求极致性能之路。
HRPC针对RDMA网络和NVMe SSD ,对IO栈上各模块进行了相应的优化设计,以实现低延迟高并发的高效通信。
IO内存零拷贝
RDMA是网卡直接在两个节点间进行数据传输。对于RDMA网卡来说,需要知道两端进行读写的内存地址,而且需要是物理地址。在RDMA技术中,这通过注册MR内存实现。简单来说,就是在RDMA传输数据前本地和远端的内存都需要注册成MR内存,此MR注册过程将告诉网卡虚拟地址和物理地址的映射关系,以及一些内存访问权限信息。
HRPC充分利用了RDMA的内存注册机制,整个IO路径过程中使用内存池中的内存,实现全流程零拷贝。内存池模块在进程初始化的时候将大页内存创建出多种粒度的memory pool,并提前注册好MR。业务模块需要发起数据传输前,按需申请需要的内存,此内存可以直接交给RDMA网卡访问。当网卡完成RDMA操作后,此块内存将直接交给业务模块使用。经过各模块处理,再通过RDMA发送出去,全程不需要对数据进行内存拷贝,减少了系统开销并大幅降低了延迟。
同时,利用RDMA支持本地处理多个分散/聚集条目,即读取多个内存缓冲区并将它们作为一个流发送或获取一个流并将其写入多个内存缓冲区。memory pool内存池支持Scatter/gather entries 分散/聚集条目。 HRPC和应用模块通过传递Scatter/gather list完成不同IO粒度的内存访问。
单双边传输结合
HRPC对上层实现了基于事务的消息处理机制(Message based transactions) 。数据作为离散消息而不是作为流处理,这消除了应用程序将流分离为不同消息/事务的需要。
在使用RDMA操作数据传输时,通常有使用双边传输和单边传输两种方式。双边传输是一种消息语义,而单边传输则是内存语义。HRPC选择了更为灵活的单双边传输结合的方式。
双边传输(SEND/RECV)与传统Socket网络传输类似,发送端使用RDMA SEND发送数据,接收端使用RDMA RECV接收数据。但是在发送端发起RDMA SEND操作之前,接收端需要准备好接收数据的内存区并发起RDMA RECV操作,否则就会发送失败。因此双方需要约定一次传输最大的数据大小,一般在在创建RDMA连接时协商,接收端以该大小准备接收内存区,发送端以该大小对大请求进行切分。使用双边RDMA SEND/RECV的限制在于当请求小于约定大小时存在接收端内存浪费的现象,而请求大于约定大小时需要发送端切分多次传输并在接收端重组,增加了CPU开销和延迟。
在单双边结合的传输方式下,双边SEND/RECV用于控制类消息传输,而实际数据则是通过单边RDMA READ/WRITE来完成。在实际场景中每次需要传输的数据大小不是固定的,所以发起单边操作前需要先协商好数据长度和相应的内存区信息。 其方式为先使用双边SEND/RECV操作把待传输数据的内存地址、大小、rkey等控制信息进行传输,然后根据传输类型选择单边READ或WRITE操作完成实际数据的传输,最后使用双边SEND/RECV操作发送Reply结果。单双边结合传输的方式具有灵活适应各种大小请求的特点,尤其在传输大请求时具有明显优势,只需要一次单边操作即可将数据全部传输。
异步I/O及协程调度
分布式存储系统在节点间存在大量的消息收发过程,一个op操作需要远端告知处理结果,在等待远端回应处理结果的这段时间,本端将处于异步等待的过程。为了高效利用cpu,HRPC实现的是一套异步I/O消息收发机制。异步I/O是一种编程模型,它允许程序在等待I/O操作完成的同时继续执行其他任务,而不会被阻塞。异步I/O可以实现高效的并发处理和响应性能。同时,Polaris分布式存储IO栈均采用协程模型。HRPC和业务的协程调度机制相配合,实现了一套高效的并发处理机制。
协程(ULT)是一种比线程更加轻量级的存在,协程可以理解为一个特殊的函数,这个函数可以在某个地方挂起去执行别的函数,并且可以返回挂起处继续执行。一个线程内可以由多个协程来交互运行,但是多个协程的运行是串行的,也就是说同一时刻只有一个协程在运行。当一个协程运行时,其它的协程会被挂起。协程不被操作系管理,而是在用户态执行,完全由程序所控制,根据调度策略,通过协作(而不是抢占)来进行切换。在IO密集型场景下,协程的调度开销比线程小,能够快速实现调度,尽可能的提升CPU利用率。因此,很适合当前这种异步编程模型。下一代存储基于多核CPU,利用多线程+协程的方式,充分利用CPU,可以获得极高的性能。
NUMA亲和
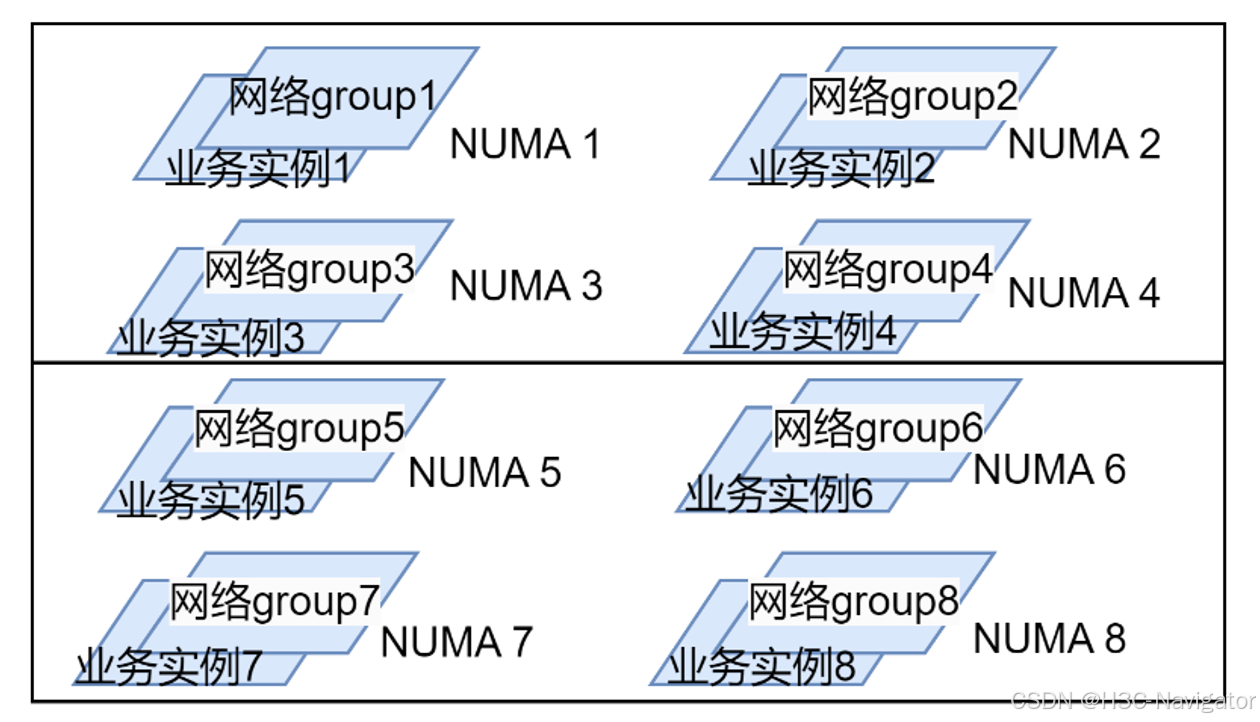
现代服务器基本上都具备多NUMA架构。在多NUMA架构中,每个NUMA具有本地内存,也可以访问跨NUMA内存。访问本地内存比访问其他NUMA内存时延更低,开销更小,因此对内存的访问效率会直接影响存储系统的性能。HRPC采用分组技术,每个分组创建1组独立的网络分组资源,包括RDMA连接资源,网络线程资源等。有2种粒度的分组策略:
策略1:每个NUMA上创建1组独立的网络分组资源。
策略2:每个物理CPU创建1组独立的网络分组资源。
网络分组创建后,上层业务实例可以根据自己的实例数,均分这些网络分组。跟某个网络分组关联的所有业务实例将和对应的网络资源运行在同一个NUMA里,如图,以8个NUMA为例:
总结
RDMA的编程模式与传统TCP/IP相比有很大的不同,不管是内存使用机制,还是数据操作逻辑都发生了很大的变化。使用RDMA可以减少在内核协议栈处理和内存拷贝等开销,从而大幅降低数据在网络上传输的延迟,但实际数据访问需要经过软件栈多个模块的处理,这其中可能存在数据拷贝和同步等开销,当存储设备的访问延迟和网络传输延迟都达到10us级别时,这些软件栈上的开销对整体性能的影响变得愈发明显。
从TCP/IP网络通信切换到RDMA通信不仅仅是数据收发网络接口的简单替换,而是需要进行整体的软件架构的优化设计,使IO路径上各模块契合RDMA的特点整体联动,才能充分发挥RDMA的优势,并与NVMe SSD等高性能低延迟设备结合,取得存储性能的突破。HRPC作为Polaris分布式存储的高性能通信框架,不仅在网络传输上,在IO内存拷贝,CPU调度等方面也都做了大量的优化。为Polaris分布式存储实现高性能奠定了坚实的基础。