Kafka 深度剖析:架构演进、核心概念与设计精髓
目录
一、Kafka是什么?
1.1 简介
1.2 核心作用
二、为什么选择 Kafka
2.1 Kafka优势
2.2 对比其他消息队列
三、Kafka核心架构:从Zookeeper到KRaft的演进
3.1 传统架构(依赖Zookeeper)
3.2 现代架构(KRaft模式)
四、核心概念详解
4.1 Producer(生产者)
4.2 Topic与Partition
4.3 Replica与ISR机制
4.4 消费者组与Offset:消息的消费规则
4.5 Broker(代理) & Cluster(集群)
五、工作原理:消息"从生产到消费"的全流程
5.1 消息生产流程
5.2 Broker存储机制
5.3 消息消费流程
六、Kafka 核心特性的实现原理
6.1. 高吞吐的秘密:顺序读写 + 零拷贝
6.2. 高可用的保障:副本机制 + Leader 选举
七、Kafka 的典型应用场景
八、总结:Kafka 的设计精髓
一、Kafka是什么?
1.1 简介
简单来说,Kafka是一个分布式、高吞吐量、可持久化的发布-订阅消息系统。我们可以用“数据物流中心”的比喻理解其角色:
-
生产者(发送方):像快递寄件人,源源不断地将“包裹(消息)”送到物流中心;
-
Kafka(物流中心):接收包裹,按“目的地(Topic)”分拣存储,具备大容量(磁盘持久化)和高可靠性(永不丢件);
-
消费者(接收方):像快递收件人,随时到物流中心取走属于自己的包裹并处理。
1.2 核心作用
| 核心作用 | 简单解释 | 生活比喻 |
|---|---|---|
| 解耦 | 数据发送方和接收方互不依赖,通过Kafka中转 | 寄件人和收件人不需要见面,通过快递站中转 |
| 缓冲 | 应对流量高峰,避免系统被冲垮 | 像水库一样蓄水,防洪抗旱 |
| 异步处理 | 发送方无需等待接收方处理完成 | 寄件后无需等待收件人签收,可继续做其他事 |
二、为什么选择 Kafka
2.1 Kafka优势
对比 RabbitMQ、RocketMQ 等其他消息队列,Kafka 的核心优势在于:
- 超高吞吐:单机可轻松支持每秒数十万条消息的读写,适合海量数据场景;
- 持久化可靠:消息默认持久化到磁盘,支持数据回溯(重新消费历史消息);
- 分布式高可用:基于集群和副本机制,单个节点故障不影响整体服务;
- 低延迟:消息从生产到消费的延迟可控制在毫秒级,满足实时性需求。
2.2 对比其他消息队列
为了更直观地理解 Kafka 的定位,以下是它与另外两种流行消息队列(RabbitMQ, RocketMQ)的关键特性对比:
| 特性 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 吞吐量 | 极高 (10万+/秒) | 中等 (万级/秒) | 高 (10万+/秒) |
| 消息持久化 | 强 (顺序写磁盘,高效) | 支持 (但影响性能) | 强 (基于 CommitLog) |
| 延迟 | 毫秒级 | 微秒级 (轻量级最优) | 毫秒级 |
| 分布式高可用 | 副本+KRaft/ZK,容错性强 | 镜像队列,扩展性一般 | 主从架构,支持异地多活 |
| 主要应用场景 | 日志/流处理、大数据管道 | 业务解耦、即时通信 | 金融交易、分布式事务 |
三、Kafka核心架构:从Zookeeper到KRaft的演进
Kafka的架构设计围绕"高可用、高吞吐"目标展开,经历了从依赖Zookeeper到内置KRaft协议的重要演进。
3.1 传统架构(依赖Zookeeper)
Kafka 2.8.0之前版本的架构核心依赖Zookeeper,由四大组件构成:
-
Producer(生产者):负责发送消息到集群,支持批量发送和压缩优化;
-
Broker(代理节点):存储消息的服务器,集群由多个Broker组成,每个Broker管理部分Topic分区;
-
Consumer(消费者):从Broker读取消息,通过消费者组实现负载均衡;
-
Zookeeper:分布式协调中心,负责元数据管理(Broker/Topic列表)、Controller选举、健康监测。
3.2 现代架构(KRaft模式)
Kafka 3.0+推出KRaft(Kafka Raft Metadata)模式,彻底摆脱Zookeeper依赖,核心改进如下:
-
元数据自管理:通过Raft协议将元数据存储在内部Topic
__cluster_metadata中; -
Controller增强:部分Broker兼任Controller角色,通过Raft实现Leader选举和元数据同步;
-
性能优化:启动时间缩短50%+,元数据操作延迟从秒级降至毫秒级。
四、核心概念详解
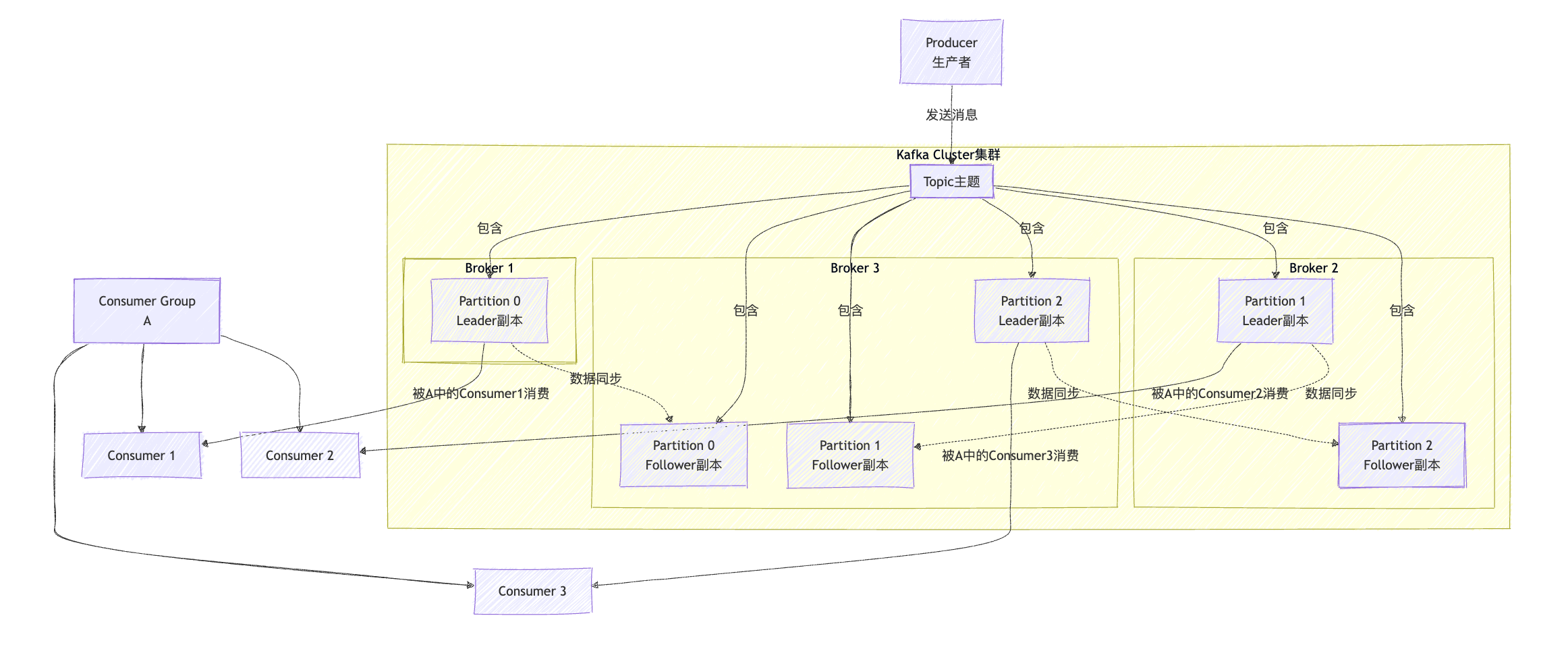
4.1 Producer(生产者)
- 角色:向Kafka的Topic发送消息的客户端。
- 工作原理:
(1)序列化:生产者发送的 “业务对象”(如订单对象)需先序列化为字节流(Kafka 只传输二进制数据),常用的序列化方式有 JSON、Avro、Protobuf 等。
(2)分区策略:决定消息发送到 Topic 的哪个 Partition,默认有 3 种策略:
策略 原理 轮询(Round-Robin) 若消息无 Key,生产者按顺序轮流发送到各个 Partition,实现负载均衡。 按 Key 哈希 若消息带 Key(如订单 ID),Kafka 通过 hash(Key) % 分区数计算 Partition,相同 Key 的消息会发送到同一个 Partition(保证同 Key 消息的顺序性)指定 Partition 生产者直接指定消息的 Partition ID - ACK 机制:消息可靠性控制
生产者发送消息后,可通过acks参数设置 “消息确认级别”,平衡可靠性与性能:
acks=0:生产者发送消息后不等待确认,直接返回成功(最快,但可能丢失消息);acks=1:仅 Leader 副本接收消息并确认,Follower 未同步完成(较快,Leader 故障可能丢失消息);acks=-1(或all):Leader 和所有 ISR(同步副本集)中的 Follower 都接收消息后才确认(最可靠,性能略低)。
4.2 Topic与Partition
- Topic(主题):消息的逻辑分类,类似"文件夹",生产者向Topic发送消息,消费者从Topic读取消息。
- Partition(分区):Topic的物理分片,每个Topic包含多个Partition,消息被分散存储在不同Partition中。
- 分区的核心价值:
(1)并行扩展:多个Partition可分布在不同Broker,实现读写并行。
(2)顺序保证:单个Partition内的消息严格按照发送顺序存储,满足事务性场景需求。
4.3 Replica与ISR机制
- Replica(副本):为保证数据可靠性,每个Partition可配置多个副本(Replica),分为Leader和Follower:
(1)Leader副本:处理所有读写请求,是Partition的"主节点"。
(2)Follower副本:实时同步Leader的数据,当Leader故障时通过选举成为新Leader。
- ISR(In-Sync Replicas,同步副本集):所有与Leader保持数据同步的副本(包括Leader本身)组成ISR。只有ISR中的副本才有资格被选为新Leader,这是Kafka保证数据一致性的核心机制。当Follower同步延迟超过阈值(
replica.lag.time.max.ms)时,会被移出ISR。
4.4 消费者组与Offset:消息的消费规则
- Offset(偏移量):消息在Partition中的唯一序号,类似“页码”,消费者通过记录Offset追踪消费进度(KRaft模式下存储在
__consumer_offsetsTopic); - 消费者组:逻辑上的订阅者,由一个或多个消费者组成,是实现“队列/发布-订阅”双模型的核心。
- 核心规则:一个分区只能被同一消费者组内的一个消费者消费,但可被多个不同消费者组消费(广播)。
两种模式对比:
(1)队列模式(负载均衡)
所有消费者在同一组,Topic消息均衡分配给组内消费者,一条消息仅被一个消费者处理。
示例:Topic(3分区)+ 消费者组G1(3消费者)→ 1消费者对应1分区。
(2)发布-订阅模式(广播)
消费者分布在不同组,每个组都能收到Topic全部消息。
示例:Topic同时被G1(统计分析)和G2(短信通知)订阅→ 消息被两个组各消费一次。
4.5 Broker(代理) & Cluster(集群)
- Broker:一个独立的Kafka服务器节点就是一个Broker。它负责接收生产者的消息,设置偏移量,持久化消息到磁盘;同时为消费者提供拉取消息的服务。
- Cluster:由多个Broker组成的集合称为集群。Kafka天生就是分布式的,集群提供高可用性和容错能力。通过分区副本机制,即使某台Broker宕机,数据也不会丢失,服务也不会中断。
五、工作原理:消息"从生产到消费"的全流程
Kafka的高吞吐能力源于其高效的消息处理流程,我们从生产者发送、Broker存储、消费者读取三个环节展开分析。
5.1 消息生产流程
生产者→Kafka:分区策略选择→批量压缩(LZ4/Snappy算法)→按ACK级别等待确认。

5.2 Broker存储机制
Kafka采用"日志文件"的方式存储消息,核心优化包括:
-
顺序写磁盘:消息追加到Partition尾部,避免随机I/O,磁盘吞吐量接近内存级别。
-
页缓存机制:利用操作系统页缓存缓存热点数据,减少物理磁盘访问。
-
日志分段:每个Partition分为多个日志段(Log Segment),方便过期数据清理和文件管理。
5.3 消息消费流程
- 消费者组协调:组内选举一个Coordinator(协调者),负责分配Partition给消费者。
- Offset提交:消费者完成消息处理后,提交当前Offset(支持自动提交和手动提交)。
- 消费模式: 推模式(Push):Broker主动将消息推送给消费者(易造成消费者过载)。
- 拉模式(Pull):消费者主动向Broker请求消息(灵活控制消费速率,Kafka默认采用)。

六、Kafka 核心特性的实现原理
Kafka 的高吞吐、高可用等特性并非凭空而来,而是基于底层的设计优化,这里重点解析两个关键特性的实现:
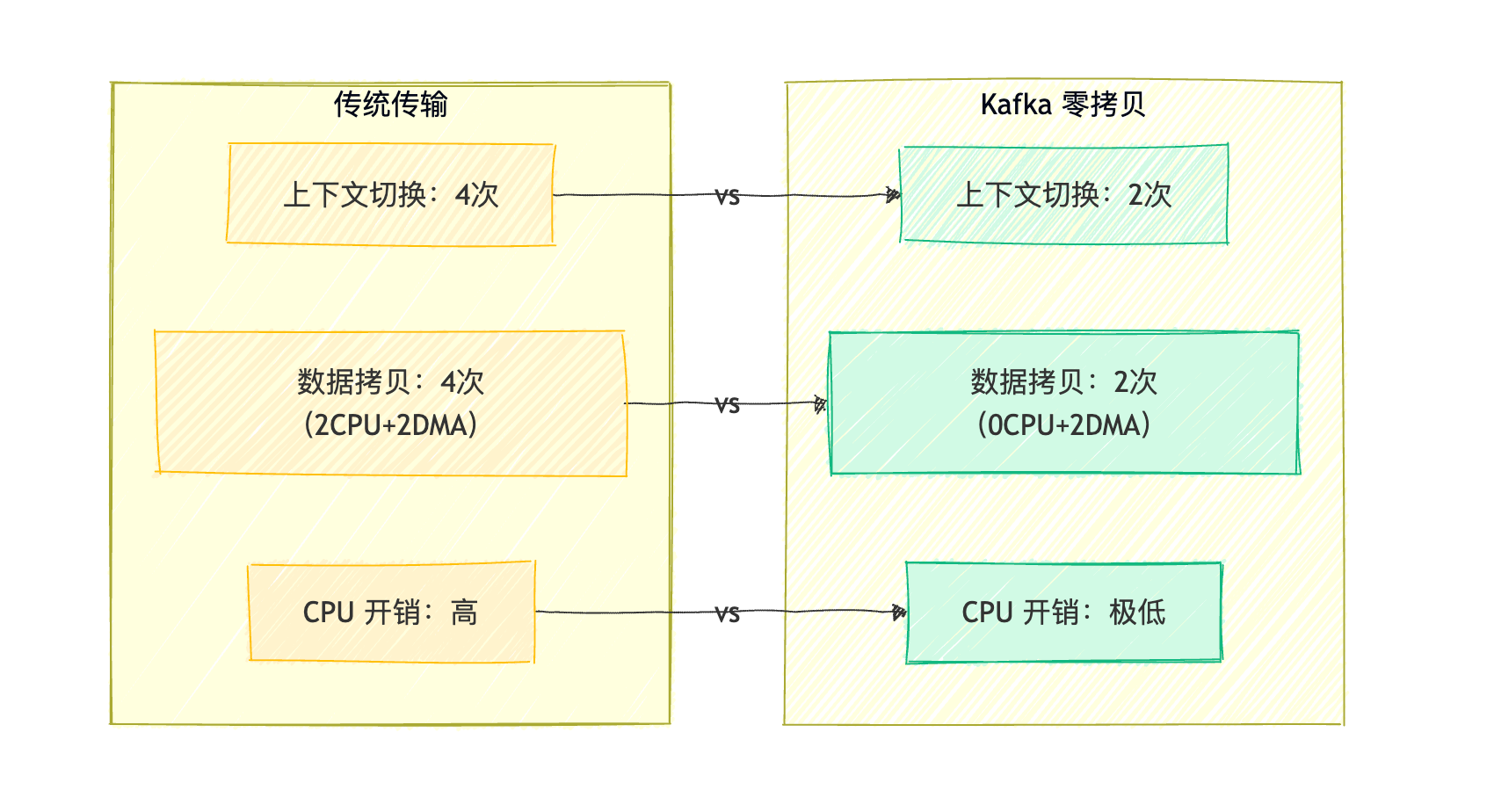
6.1. 高吞吐的秘密:顺序读写 + 零拷贝
- 顺序读写:Partition日志仅追加写入,顺序读写效率远高于随机读写(磁盘顺序读写速度接近内存);
- 零拷贝(Zero-Copy):通过Linux
sendfile系统调用,直接将磁盘文件数据发送到网络socket,跳过“磁盘→内核缓冲区→用户缓冲区→内核socket缓冲区”的多步拷贝,减少数据拷贝次数。
6.2. 高可用的保障:副本机制 + Leader 选举
- 副本同步:Follower实时从Leader同步消息,确保Leader故障时有完整备份;
- Leader选举:Leader故障时,从ISR副本中选举新Leader(优先同步进度最快的Follower),保证服务不中断。
七、Kafka 的典型应用场景
理解了 Kafka 的原理后,我们再看它在实际业务中的应用:
-
日志收集:Flume采集分布式日志→Kafka缓存→ELK栈(Elasticsearch+Logstash+Kibana)分析;
-
实时流处理:对接Flink/Spark Streaming,实时分析用户行为、设备指标(如实时推荐、异常监控);
-
系统间通信:作为异步通信中间件(如订单系统向库存、物流系统发消息);
-
数据同步:MySQL数据通过Canal同步到Kafka,再同步到Elasticsearch/Redis。
八、总结:Kafka 的设计精髓
Kafka 的成功并非偶然,其核心设计思想可归纳为 3 点:
- 简单优先:通过 “Topic-Partition - 副本” 的分层设计,平衡了复杂度与功能;
- 性能为王:基于顺序读写、零拷贝、并行处理等技术,最大化吞吐能力;
- 可靠性保障:通过 ACK 机制、副本同步、Leader 选举,确保数据不丢失、服务不中断。