高效IO的理解


目录
一、高效IO的需求
二、代码详细讲解
三、代码执行顺序详解
输入案例
执行流程图解
编辑
方法调用顺序详解
一、高效IO的需求
为什么有时候需要用高效IO代替Scanner?
可以通过下面这个表格来进行理解
| 场景 | Scanner | 高效IO(BufferedReader) |
| 小规模调试 | 简单易用,代码简洁 | 冗余代码多,学习成本高 |
| 大数据量输入 | 频繁IO导致超时(如ACM竞赛) | 批量读取,性能提升10倍以上 |
| 复杂数据解析 | 支持正则表达式,灵活性高 | 仅支持固定分隔符,灵活性低 |
在面对大量数据输入时,Scanner输入有时会导致超时,特别是在一些竞赛里面,像是这种时候就可以采用高效IO来解决问题
二、代码详细讲解
先给出一整个代码部分,分为Read类和main类,下面会逐步进行讲解。里面也会有学习过程的一些问题的思考。
总的来说,读取就是通过StringTokenizer方法把 输入 分割成一段段,然后system.in输入默认是字节流(英文字符),InputStreamReader把字节流转为字符流(中文,字符串),BufferedReader增加缓冲区,能够提高读取效率,详细下面会有提到。
输出是通过PrintWriter方法来进行的,system.out输出的是字节流(英文字符),InputStreamReader把字节流转为字符流(中文,字符串),BufferedReader增加缓冲区,能够提高读取效率。PrintWriter提供了更友好的输出方法。
class Read{StringTokenizer st = new StringTokenizer("");BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));String next() throws IOException {while(!st.hasMoreTokens()){st = new StringTokenizer(bf.readLine());}return st.nextToken();}String nextLine() throws IOException {return bf.readLine();}int nextInt() throws IOException {return Integer.parseInt(next());}long nextLong() throws IOException {return Long.parseLong(next());}double nextDouble() throws IOException {return Double.parseDouble(next());}
}public class demo1{public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));public static Read in = new Read();public static void main(String[] args) {// 输入代码out.close();}
}下面是分部拉进行了解,先是Read类中的2个实例对象
class Read{StringTokenizer st = new StringTokenizer("");BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
}-
StringTokenizer st
用于分割输入的字符串(默认按空格,换行符分割)。初始值为空字符串,实际使用时会动态替换为读取到的行内容
-
BufferedReader bf:
带缓冲区的字符输入流,包装了
InputStreamReader,而InputStreamReader又将System.in(字节流)转换为字符流作用:减少直接读取System.in的次数,提升效率
-
system.out 字节流输出(只输出字节,如英文字符)
-
InputStreamReader将字节流转换为字符流(中文,字符串)
-
BufferedReader:加缓冲区(把多次小量输出合并成一次大量输出,减少IO次数,提升速度)。IO输入输出
-
问题:
1.StringTokenizer是用于分割输入的字符串,那么分割后的字符串会在哪里?放在分割器里面吗?
StringTokenizer 不会一次性存储所有分割后的字符串,而是通过动态分割的方式按需生成每个token,分割后的字符串不会存放在某个显式的集合中,而是由stringTokenizer内部维护的一个指针,记录当前处理的位置。每次调用nextToken()时,它会当前位置开始开始扫描,直到遇到下一个分隔符,然后返回当前token并更新指针
分割后的字符串不存储在集合中,而是由 StringTokenizer 内部通过指针动态生成
2.二者的作用?
StringTokenizer 是 字符串分割工具,用于将输入的一行文本按指定分隔符(默认空格、换行符等)拆分成多个“标记”(Token),并逐个返回这些标记。
BufferedReader是字符缓冲输入流,用于高效处理读取字符数据(如文本文件,控制台输入)。
Read类中核心方法:next()
String next() throws IOException {while(!st.hasMoreTokens()){ // 如果当前分割器没有更多tokenst = new StringTokenizer(bf.readLine()); // 读取下一行,重新分割}return st.nextToken(); // 返回下一个token
}-
功能:获取下一个“单词”(以空格、换行符分隔的字符串)。
-
流程:
-
检查当前
st是否还有 token。 -
如果没有,调用
bf.readLine()读取一行输入,再用StringTokenizer分割成多个 token。 -
返回第一个 token(如输入
10 20 30,第一次返回10,第二次返回20)
-
String nextLine() throws IOException {return bf.readLine(); // 直接返回一行输入}int nextInt() throws IOException {return Integer.parseInt(next()); // 将字符串转为整数}long nextLong() throws IOException { return Long.parseLong(next()); // 转为长整数}double nextDouble() throws IOException {return Double.parseDouble(next()); // 转为浮点数}三、代码执行顺序详解
输入案例
3
10 2.5
Hello World
执行流程图解
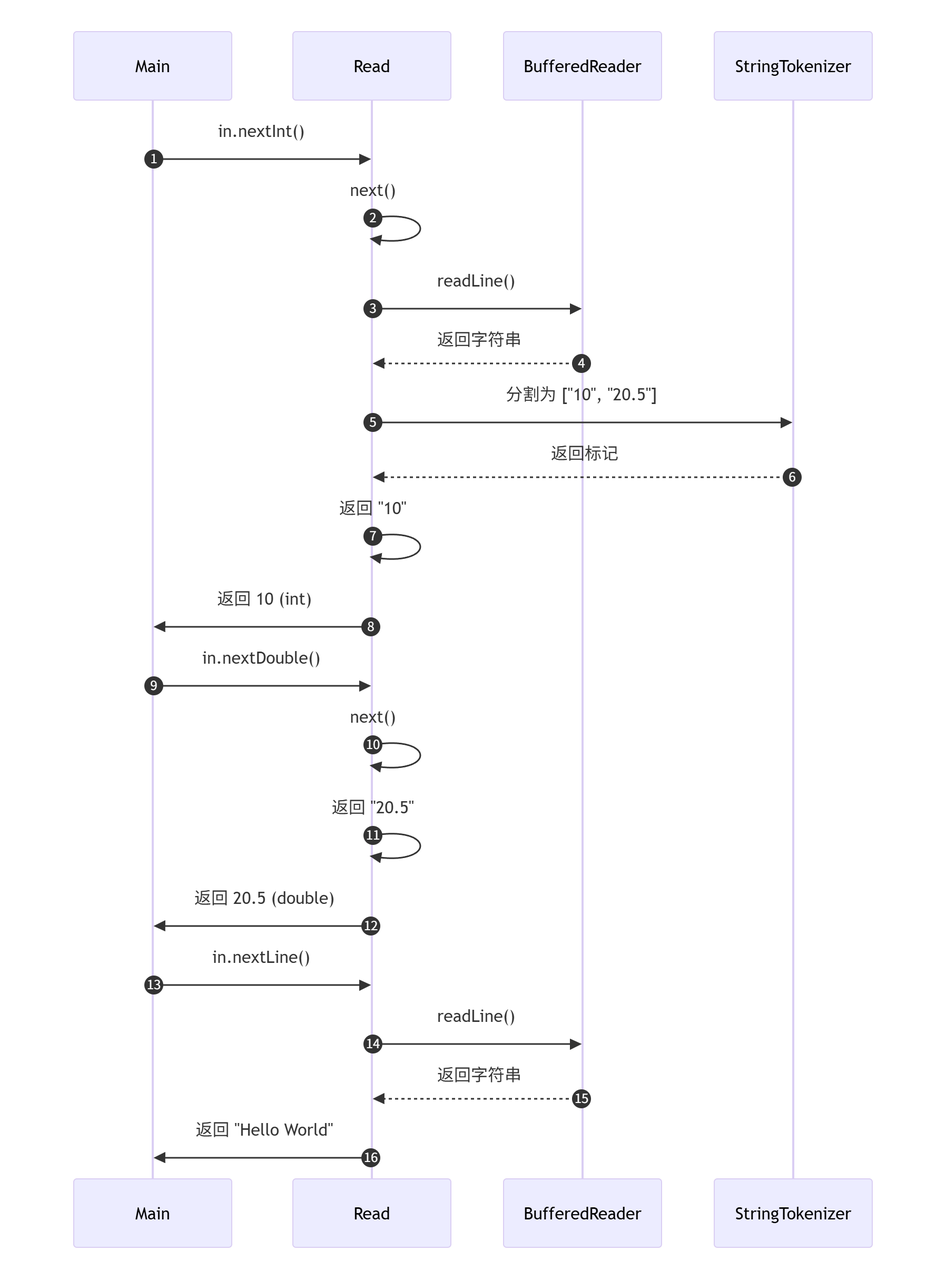
方法调用顺序详解
-
main方法执行
public static void main(String[] args) throws IOException {int n = in.nextInt(); // 步骤1double sum = 0; // 步骤2for (int i=0; i<n; i++) { // 步骤3double num = in.nextDouble(); // 步骤4sum += num;}String line = in.nextLine(); // 步骤5 } -
nextInt()方法调用链
int nextInt() throws IOException {return Integer.parseInt(next()); // 调用next() }String next() throws IOException {while (!st.hasMoreTokens()) { // 检查是否有未分割的标记st = new StringTokenizer(bf.readLine()); // 读取新行并分割}return st.nextToken(); // 返回下一个标记 }执行顺序:
-
nextInt()→ 调用next() -
next()→ 检查StringTokenizer是否有标记 -
若无标记,调用
BufferedReader.readLine()读取新行(如"10 20.5") -
用
StringTokenizer分割该行 → 生成标记["10", "20.5"]
最后的最后,一开始的代码部分要掌握的熟悉,最好能在三四分钟内容把框架给写出来
