pytorch入门学习
一、基础准备
-
安装与环境配置(PyTorch、CUDA、Jupyter Notebook)
PyTorch 官方推荐用 Anaconda 或 Miniconda 来管理环境。这样不会影响系统里的 Python。
一个常见的安装流程是:
conda create -n pytorch python=3.10 conda activate pytorch pip install torch torchvision torchaudio如果你的电脑有 NVIDIA 显卡,还可以安装带 CUDA 的版本,这样就能用 GPU 加速。
-
查阅文档的方法(如何看官方 API,如何用
help()、dir())学 PyTorch 的时候,自己查文档是非常重要的能力。PyTorch 的 API 很多,你不可能全背下来,但要会查。主要有三个方法:
-
官方文档
- PyTorch 官方文档https://pytorch.org/docs/stable/index.html
- 几乎所有函数、类、示例代码都能在这里找到。
-
Python 内置方法
help():查看函数说明dir():查看对象有哪些方法或属性
例如:
import torch x = torch.ones(2, 3) help(x) # 查看张量的文档 dir(torch) # 看看 torch 里面有哪些函数 -
搜索引擎 + 官方网站
-
比如忘记
reshape怎么用,可以直接搜:site:pytorch.org reshape tensor
-
这样会直接跳到官方文档里的用法。
-
-
二、张量与数据操作(核心基础)
1.张量(Tensor)创建
张量的创建,常见方法有:
torch.tensor()—— 直接从 Python 数据(列表、嵌套列表)创建张量torch.zeros()—— 生成全 0 张量torch.ones()—— 生成全 1 张量torch.randn()—— 生成符合标准正态分布的随机张量torch.arange()—— 类似 Python 的range,生成等差数列torch.linspace()—— 在区间内平均分布取点torch.eye()—— 生成单位矩阵
1. torch.tensor()
PyTorch 的核心就是 Tensor,它和 Numpy 的 ndarray 很像,但多了 GPU 加速和自动求导功能。
👉 功能
- 用来 从 Python 的数据(列表、嵌套列表、标量)创建张量。
- 这是最基础、最直观的方式。
👉 用法示例
import torch# 从列表创建一维张量
a = torch.tensor([1, 2, 3])
print(a)# 从嵌套列表创建二维张量
b = torch.tensor([[1, 2], [3, 4]])
print(b)# 创建浮点型张量(注意类型)
c = torch.tensor([1.0, 2.0, 3.0])
print(c, c.dtype)# 强制指定数据类型
d = torch.tensor([1, 2, 3], dtype=torch.float32)
print(d, d.dtype)
👉 注意点
- 如果输入是整数,默认类型是
torch.int64(长整型)。 - 如果输入是小数,默认类型是
torch.float32(浮点型)。 - 如果想统一类型(比如训练神经网络时),最好用
dtype=来指定。
总结一下 torch.tensor():
- 作用:从 Python 的数据(列表、嵌套列表、标量)创建张量
- 关键点:维度由列表的嵌套层数决定
- 注意:只有一个主要参数(数据),别写成多个列表
2. torch.zeros()
👉 功能:生成全 0 张量
👉 用法:
a = torch.zeros(2, 3) # 2 行 3 列,都是 0
print(a)
👉 常用场景:
- 初始化矩阵
- 当作占位符
👉 torch.zeros 的一些变体
- 指定数据类型
torch.zeros(2, 2, dtype=torch.int32)
- 指定设备(CPU / GPU)
torch.zeros(2, 2, device="cuda") # 在 GPU 上创建
- 高维张量
torch.zeros(2, 3, 4) # 三维,全 0
3.torch.ones()
👉 功能:生成全 1 张量
👉 用法:
b = torch.ones(2, 3)
print(b)
👉torch.ones() 的应用
- 常用于 权重初始化 或 测试代码
- 和
torch.zeros()一样,可以指定dtype和device:
torch.ones(3, 3, dtype=torch.float64) # 双精度浮点
torch.ones(2, 2, device="cuda") # 在 GPU 上创建
4.torch.randn()
👉 功能:生成符合 标准正态分布(均值 0,方差 1)的随机张量
👉 用法:
c = torch.randn(2, 3)
print(c)
每次运行,结果都不一样,因为是随机数。
👉小扩展:torch.randn() vs torch.rand()
torch.randn()→ 正态分布 (mean=0, std=1)torch.rand()→ 均匀分布 [0,1)
例如:
print(torch.randn(2, 2)) # 正态分布
print(torch.rand(2, 2)) # 均匀分布
5.torch.arange()
👉 功能:生成一个等差数列张量(类似 Python 的 range)
👉 用法:
d = torch.arange(0, 10, 2) # 从 0 开始,步长为 2,到 10(不包含 10)
print(d) # tensor([0, 2, 4, 6, 8])
👉小扩展:torch.arange() 的常见用法
torch.arange(5) # tensor([0, 1, 2, 3, 4])
torch.arange(2, 8) # tensor([2, 3, 4, 5, 6, 7])
torch.arange(1, 10, 3) # tensor([1, 4, 7])
如果想要 浮点数序列:
torch.arange(0, 1, 0.2) # tensor([0.0000, 0.2000, 0.4000, 0.6000, 0.8000])
6.torch.linspace()
👉 功能:在一个区间内,平均分布取点。
👉 用法:
e = torch.linspace(0, 1, 5) # 从 0 到 1,均匀取 5 个点
print(e) # tensor([0.0000, 0.2500, 0.5000, 0.7500, 1.0000])
👉小扩展:torch.linspace() 常见用法
torch.linspace(0, 1, 3) # tensor([0.0000, 0.5000, 1.0000])
torch.linspace(-1, 1, 5) # tensor([-1.0000, -0.5000, 0.0000, 0.5000, 1.0000])
👉 linspace 和 arange 的区别:
arange→ 按 步长 来取数linspace→ 按 个数 来取数
7.torch.eye()
👉 功能:生成一个 单位矩阵(对角线是 1,其余是 0)
👉 用法:
f = torch.eye(3)
print(f)
输出:
tensor([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
👉小扩展:torch.eye() 的变体
- 生成非方阵(行数、列数不同):
torch.eye(3, 5)
输出一个 3×5 矩阵,对角线位置是 1,其余是 0。
- 可以指定数据类型:
torch.eye(3, dtype=torch.int32)
2.张量的基本运算
- 算术运算、比较运算
- 广播机制
算术运算
1. 张量的加法
方法 1:直接用运算符 +
import torcha = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
print(a + b) # tensor([5, 7, 9])
方法 2:用函数 torch.add
print(torch.add(a, b)) # tensor([5, 7, 9])
2. 张量的减法
print(a - b) # tensor([-3, -3, -3])
print(torch.sub(a, b)) # 同样结果
3. 张量的乘法
这里要注意:有两种“乘法”
- 逐元素相乘(element-wise)
print(a * b) # tensor([ 4, 10, 18])
print(torch.mul(a, b))
- 矩阵乘法(线性代数里的
matmul)
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[2, 0], [1, 2]])
print(torch.matmul(x, y)) # 2x2 矩阵乘法
print(torch.mm(x,y))
4. 张量的除法
print(b / a) # tensor([4.0000, 2.5000, 2.0000])
print(torch.div(b, a))
5. 幂运算
print(a ** 2) # tensor([1, 4, 9])
print(torch.pow(a, 2))
比较运算
PyTorch 里的比较运算,结果会返回一个 布尔张量(True/False),在内部是 0/1 表示。
1. 大于 / 小于
a = torch.tensor([1, 2, 3])
b = torch.tensor([2, 2, 2])print(a > b) # tensor([False, False, True])
print(a < b) # tensor([ True, False, False])
2. 大于等于 / 小于等于
print(a >= b) # tensor([False, True, True])
print(a <= b) # tensor([ True, True, False])
3. 等于 / 不等于
print(a == b) # tensor([False, True, False])
print(a != b) # tensor([ True, False, True])
4. 结合 torch.where 使用
可以用比较结果去“选数据”:
c = torch.tensor([10, 20, 30])
result = torch.where(a > b, a, c)
print(result) # a > b 的地方选 a,否则选 c
torch.where的相关使用:
- 选择元素(if-else 的作用)
torch.where(condition, x, y)
- condition: 一个布尔张量(True/False)
- x: 在条件为 True 的位置取的值
- y: 在条件为 False 的位置取的值
相当于 逐元素的 if-else 操作:
import torcha = torch.tensor([1, 2, 3, 4, 5])
b = torch.tensor([10, 20, 30, 40, 50])# 条件:a > 3
result = torch.where(a > 3, a, b)
print(result)
输出:
tensor([10, 20, 30, 4, 5])
解释:
- 对于
a > 3的地方,结果取a - 否则取
b
- 获取条件为 True 的索引
如果只传入 condition,会返回满足条件的元素索引:
a = torch.tensor([1, 2, 3, 4, 5])indices = torch.where(a > 3)
print(indices)
输出:
(tensor([3, 4]),)
解释:第 3 和 4 个位置(从 0 开始)满足 a > 3。
你可以用这些索引取值:
print(a[indices]) # tensor([4, 5])
✅ 总结:
torch.where(cond, x, y)→ 相当于 NumPy 的np.where,逐元素选择。torch.where(cond)→ 返回满足条件的索引。
5. all() 和 any()
print((a > 0).all()) # True,全部都 >0
print((a > 2).any()) # True,至少有一个 >2
广播机制(Broadcasting)
广播是 PyTorch(以及 NumPy)里非常强大也常用的特性:它允许不同形状的张量在元素级运算时自动“对齐并扩展”,免去你手动 reshape / tile 的麻烦。下面把规则、常见用法、进阶 API、坑和练习都讲清楚 —— 每一步都有可运行的代码示例,方便直接在终端/笔记本里试。
一、核心规则(右对齐 + 兼容性)
两个张量形状不同,但在运算时会尝试“对齐”:把两个张量的形状从右边对齐,逐维比较:
- 从最后一个维度开始对齐
- 如果两个维度相同 → 保持不变
- 如果一个是 1,另一个是 N → 复制扩展成 N
- 如果两个维度不相等且都不是 1 → 报错
标量(shape [])可以广播到任意形状。
举例:
(2, 3, 4)与(3, 4)→ 右对齐后匹配为(2, 3, 4)(因为(3,4)等效于(1,3,4))(5,1,4)与(1,3,1)→ 结果(5,3,4)
二、直观例子(代码可运行)
import torch# 例 1:最后一维对齐
A = torch.randn(2, 3, 4)
B = torch.randn(3, 4) # 等价于 (1,3,4)
C = A + B # 结果形状 (2,3,4)
print("C.shape:", C.shape)# 例 2:复杂广播
X = torch.randn(5, 1, 4)
Y = torch.randn(1, 3, 1)
Z = X + Y # 结果 (5,3,4)
print("Z.shape:", Z.shape)# 例 3:标量广播
s = torch.tensor(2.0) # shape []
M = torch.randn(3,4)
print((M + s).shape) # (3,4)
三、常见真实场景
- 给每个样本加上 bias:
output (batch, out_features) + bias (out_features,)→ bias 会沿 batch 维广播。 - 把每列乘以权重:矩阵
X (n_samples, n_features)*w (n_features,)→w广播到(n_samples, n_features)。 - 使用布尔掩码:
mask (n,1)与tensor (n,m)相加/比较时,mask会按列广播。
四、如何显式做广播(unsqueeze / expand / repeat)
有时你想显式把张量变成可广播的形状:
unsqueeze(dim):在指定位置增加一个长度为 1 的维度(常用)expand(...):把长度为 1 的维度“视作”扩展到目标形状(不会复制数据,返回 view)repeat(...):真正复制数据以重复(会分配新内存)
代码示例:
v = torch.tensor([1,2,3]) # shape (3,)
v1 = v.unsqueeze(0) # shape (1,3)
v2 = v1.expand(4, 3) # shape (4,3), 不复制内存(view)
v3 = v1.repeat(4, 1) # shape (4,3), 复制内存print(v.shape, v1.shape, v2.shape, v3.shape)
小提示:
v[None, :]等同于v.unsqueeze(0)(用索引None也可以)。- 用
expand得到的是不占内存的 view,不能对其进行 in-place 修改(会报错或引发不可预期问题);repeat会占内存但可 in-place。
1. unsqueeze(dim)
作用:在指定位置插入一个长度为 1 的维度。
- 常用于给张量增加一个“批次维度”或“通道维度”。
- 不会复制数据,只是改 view。
import torcha = torch.tensor([1, 2, 3]) # shape = (3,)b = a.unsqueeze(0) # 在 dim=0 增加 → shape = (1,3)
c = a.unsqueeze(1) # 在 dim=1 增加 → shape = (3,1)print(b.shape) # torch.Size([1, 3])
print(c.shape) # torch.Size([3, 1])
2. expand(...)
作用:把某些 长度为 1 的维度 扩展成目标形状(不复制数据,返回 view)。
- 只能扩展原来为
1的维度,否则会报错。 - 节省内存,推荐在需要时用它来实现“广播”。
a = torch.tensor([[1], [2], [3]]) # shape = (3,1)# 扩展成 (3,4),沿 dim=1 复制“视图”
b = a.expand(3, 4)print(b)
# tensor([[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
注意:expand 并没有真的复制数据,它只是让 PyTorch 以为在第二维有 4 个元素。
3. repeat(...)
作用:真正复制数据,把张量重复多次。
- 会分配新内存,所以比
expand更耗资源。
a = torch.tensor([[1], [2], [3]]) # shape = (3,1)# 重复 → 第 0 维重复 1 次,第 1 维重复 4 次
b = a.repeat(1, 4)print(b)
# tensor([[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]])
这里结果和 expand(3,4) 一样,但底层机制完全不同:
expand→ 共享数据,节省内存repeat→ 真复制数据,安全但耗资源
4. 总结对比
| 函数 | 作用 | 是否复制数据 | 常见用途 |
|---|---|---|---|
unsqueeze(dim) | 增加一个维度 (size=1) | 否 | 给数据加 batch 维 / 通道维 |
expand(...) | 扩展 1 维到目标大小 | 否 (view) | 广播时节省内存 |
repeat(...) | 真正复制数据 | 是 | 需要物理复制时(如要修改每份副本) |
五、expand vs repeat 的区别(务必搞清)
expand:不复制数据;只是改变 stride,让尺寸为 1 的维度看起来被“拉伸”了(非常节省内存);但不能修改(in-place)被扩展的结果。repeat:物理复制并返回新 tensor(占内存),适合需要真正重复数据的情况。
示例直观对比:
a = torch.tensor([1,2,3])
b = a.unsqueeze(0).expand(2,3) # view, 共享内存
c = a.unsqueeze(0).repeat(2,1) # copy# 修改 b 会报错或不允许;修改 c 是允许的(因为 c 是独立拷贝)
六、广播与矩阵乘法(torch.matmul / torch.mm)
注意: 广播规则也适用于批量矩阵乘法,但只对batch 维应用(最后两个维度被视为矩阵维度)。
A的形状(..., n, m),B的形状(..., m, p)→torch.matmul(A, B)的结果形状是(..., n, p),其中...必须可以广播。
例子:
A = torch.randn(2, 3, 4) # batch 2, 3x4 矩阵
B = torch.randn(2, 4, 5) # batch 2, 4x5 矩阵
R = torch.matmul(A, B) # shape (2, 3, 5)# 如果 B 没有 batch 维
B2 = torch.randn(4, 5) # (4,5)
R2 = torch.matmul(A, B2) # B2 会被看做 (1,4,5) 并广播到 (2,4,5), 结果 (2,3,5)
七、常见错误与调试技巧
- 错误例子:
(4,1)与(3,4)相加会报错,因为右对齐后有一维4vs3都不是 1 且不相等。 - 调试方法:把形状写出来,从右往左对应检查每一维是否相等或有
1。 - 可以用
tensor.shape打印形状,或用print(a.size(), b.size())。 - 对于复杂广播失败,尝试
unsqueeze把维度补成显式的1,方便定位。
八、练习(自己想一想,然后运行代码验证)
torch.randn(2,3,4) + torch.randn(3,4)→ 结果形状?(答案:(2,3,4))torch.randn(4,1) + torch.randn(3,4)→ 能广播吗?(答案:不能,会报错)torch.matmul(torch.randn(2,3,4), torch.randn(4,5))→ 结果形状?(答案:(2,3,5))- 写代码把
v = torch.tensor([1,2,3])变为形状(2,3),但不复制内存(提示:unsqueeze+expand)。
验证代码:
import torch
print((torch.randn(2,3,4) + torch.randn(3,4)).shape)
# print((torch.randn(4,1) + torch.randn(3,4)).shape) # 会报错,注释掉运行
print(torch.matmul(torch.randn(2,3,4), torch.randn(4,5)).shape)v = torch.tensor([1,2,3])
v_view = v.unsqueeze(0).expand(2,3)
print(v_view.shape)
九、实用小贴士
- 在 NN 中常见:
y = x + bias,x是(batch, out),bias是(out,)—— 这就是广播在“偏置加法”里的应用。 - 用广播能让代码更简洁、运行更快(避免显式复制),但要注意
expand返回 view,别对扩展后的张量做 in-place 修改。 - 如果想强制把张量变成广播后的实际内存(materialize),用
tensor.expand(...).contiguous()或直接tensor.repeat(...)(会复制数据)。
3.索引与切片
- 一维、二维、高维张量索引
- 张量维度变换 (
view,reshape,transpose,squeeze,unsqueeze)
张量的索引与切片
PyTorch 的索引和切片跟 Python 列表、NumPy 很像。
1. 基础索引
import torch
a = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])print(a[0, 0]) # 第 1 行第 1 列 → 1
print(a[1, 2]) # 第 2 行第 3 列 → 6
2. 切片(: 语法)[行数, 列数]
print(a[0, :]) # 第 1 行 → [1, 2, 3]
print(a[:, 1]) # 第 2 列 → [2, 5, 8]
print(a[0:2, 1:3]) # 前两行,取第 2~3 列
3. 倒序索引
print(a[-1]) # 最后一行 → [7, 8, 9]
print(a[:, -1]) # 最后一列 → [3, 6, 9]
张量维度变换
在深度学习里,数据形状(batch, channel, height, width)非常关键,所以要熟悉以下方法:
1. view() 和 reshape()
view:返回一个新张量,共享内存(要求原数据在内存中连续)reshape:更灵活,如果可能共享内存就共享,不行就复制
x = torch.arange(12) # [0,1,2,...,11]
print(x.shape) # (12,)y = x.view(3, 4)
print(y)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
2. unsqueeze() 和 squeeze()
unsqueeze(dim):在指定维度增加一个大小为 1 的维度squeeze():去掉所有大小为 1 的维度
z = torch.tensor([1, 2, 3])
print(z.shape) # torch.Size([3])z1 = z.unsqueeze(0) # 在 0 维加一个
print(z1.shape) # torch.Size([1, 3])z2 = z1.squeeze()
print(z2.shape) # torch.Size([3])
squeeze() 的作用
- 去掉张量里 所有大小为 1 的维度。
- 常用于“去掉多余的 batch 维度”。
基础示例
import torcha = torch.randn(1, 3, 1, 4)
print("原始形状:", a.shape) # torch.Size([1, 3, 1, 4])b = a.squeeze()
print("去掉所有 1 维后:", b.shape) # torch.Size([3, 4])
squeeze()只去掉指定维度
可以指定 dim 参数,只挤掉某个位置的 1。
c = a.squeeze(0) # 去掉第 0 维(因为是 1)
print(c.shape) # torch.Size([3, 1, 4])d = a.squeeze(1) # 第 1 维是 3,不是 1 → 不会去掉
print(d.shape) # torch.Size([1, 3, 1, 4])
squeeze()常见场景
比如神经网络输出 [batch_size, 1],如果 batch_size=5:
out = torch.randn(5, 1)
print(out.shape) # (5, 1)
out2 = out.squeeze(1)
print(out2.shape) # (5,)
unsqueeze() 和 squeeze() 的配合使用
一、为什么要配合使用?
在深度学习里,经常需要在 1D 张量和 2D/3D 张量之间来回切换。
unsqueeze()→ 加一个维度(比如给向量加 batch 维)squeeze()→ 去掉多余的维度(比如把(batch, 1)压成(batch,))
二、例子:给 1D 张量加 batch 维
假设我们有一个向量:
x = torch.tensor([1, 2, 3, 4])
print(x.shape) # torch.Size([4])
如果要把它当作“1 个样本,4 个特征”,需要加一个 batch 维:
x2 = x.unsqueeze(0)
print(x2.shape) # torch.Size([1, 4])
现在就可以输入到神经网络里了。
三、例子:模型输出去掉多余维度
有些模型输出是 (batch, 1),比如:
out = torch.randn(5, 1) # 假设 batch=5
print(out.shape) # torch.Size([5, 1])
我们希望把它变成 (5,),方便和标签比对:
out2 = out.squeeze(1)
print(out2.shape) # torch.Size([5])
四、结合使用场景
- 输入前加维度
- 数据:
(4,)→unsqueeze(0)→(1, 4)
- 数据:
- 输出后去维度
- 模型输出:
(5, 1)→squeeze(1)→(5,)
- 模型输出:
五、配合广播使用
比如:
v = torch.tensor([1, 2, 3]) # (3,)
m = torch.ones(2, 3) # (2,3)v2 = v.unsqueeze(0) # (1,3)
print((m + v2).shape) # (2,3)
这里 unsqueeze 让 v 能正确广播。
3. 维度交换:transpose() 和 permute()
transpose(dim0, dim1):交换两个维度permute(dims):按照任意顺序重新排列维度
m = torch.randn(2, 3, 4)
print(m.transpose(1, 2).shape) # (2, 4, 3)
print(m.permute(2, 0, 1).shape) # (4, 2, 3)
总结常用场景
- 图像数据 (batch, channel, height, width) → 转置/permute 经常用来切换通道维
- 增加 batch 维度:
unsqueeze(0) - 去掉多余的维度:
squeeze() - 扁平化:
view(batch_size, -1)
一、核心概念
transpose(dim0, dim1):交换两个维度(只交换这两个)。permute(d0, d1, d2, …):按指定顺序重排所有维度(任意排列)。
(注:对于 2D 矩阵,t() 是 transpose(0,1) 的简写;为了可读性,对高维张量优先用 transpose / permute。)
二、API 快参(方法与函数形式)
# 方法形式(常用)
y = x.transpose(1, 2) # 只交换维度 1 和 2
z = x.permute(0, 2, 3, 1) # 全维重排# 函数形式(等价)
y = torch.transpose(x, 1, 2)
z = x.permute(0, 2, 3, 1)
- 支持负下标:
x.transpose(-1, -2)交换最后两个维度。 permute的参数必须包含且只包含所有维的索引(长度必须等于x.dim())。
三、直观例子(可运行)
import torch# 例:批量矩阵,交换最后两个维度
A = torch.randn(2, 3, 4) # shape (2,3,4)
B = A.transpose(1, 2) # shape (2,4,3)# 例:图像 NCHW -> NHWC
img = torch.randn(8, 3, 32, 32) # (batch, channel, height, width)
img_nhwc = img.permute(0, 2, 3, 1) # (8, 32, 32, 3)print(A.shape, B.shape, img.shape, img_nhwc.shape)
四、为什么要用 permute / transpose(常见场景)
- 把图像在
NCHW ⇄ NHWC之间转(不同库/模型输入输出格式有区别)。 - 让矩阵乘法的维度对齐:例如
(batch, n, m)与(m, p)相乘时常需交换/重排维度。 - 将通道维移到最后以便把
(batch, h, w, c)reshape 成(batch, h*w, c)做 attention / flatten。
五、重要注意点 & 常见坑
-
permute/transpose不会复制数据,而是返回一个 view(通常是非连续的内存布局)。-
结果通常不是 contiguous(连续内存),所以不能直接对它用
view(...)。 -
如果需要用
view/reshape得到连续内存,请先.contiguous():y = x.permute(0,2,3,1) # 可能 non-contiguous y_contig = y.contiguous() y_flat = y_contig.view(y_contig.size(0), -1) # 安全
-
-
view()要求张量在内存上是连续的。如果直接对非连续张量view会抛错或出现不正确结果(通常抛RuntimeError: view size is not compatible)。用.reshape()有时能自动处理,但也推荐显式.contiguous()以避免歧义。 -
不要把
permute的参数写错顺序,会导致形状混乱。习惯先写目标维度顺序并在注释里写清楚原来是啥(可读性好)。 -
transpose只交换两个维度,如果你需要多维调换,考虑permute。 -
负索引很好用:
x.transpose(-1, -2)永远交换最后两个维度,无论x.dim()是多少。 -
permute的参数长度必须等于x.dim(),否则会报错。
六、示例:从 NCHW 变成 (batch, h*w, c)(常见于 Transformer 前的切换)
x = torch.randn(32, 3, 28, 28) # (batch, C, H, W)
x = x.permute(0, 2, 3, 1).contiguous() # (batch, H, W, C)
x = x.view(32, 28*28, 3) # (batch, H*W, C)
说明:没有 .contiguous() 很可能在 view 时出错。
七、is_contiguous() 检查小技巧
y = x.permute(0,2,3,1)
print(y.is_contiguous()) # 通常 False
y2 = y.contiguous()
print(y2.is_contiguous()) # True
八、练习题
-
把
t = torch.randn(10, 3, 32, 32)变成(10, 32, 32, 3)。
答案示范:t.permute(0, 2, 3, 1) -
给
a = torch.randn(5, 2, 3),把它变成(5, 3, 2)(只交换中间两个维度)。
答案示范:a.transpose(1, 2)或a.permute(0, 2, 1) -
复杂一点:
b = torch.randn(4, 3, 28, 28),想得到形状(4, 28*28, 3),写出完整代码(记得.contiguous())。
答案示范:b = b.permute(0, 2, 3, 1).contiguous().view(4, 28*28, 3)
九、额外小贴士
- 当你看到
RuntimeError: view size is not compatible,优先考虑是不是需要.contiguous()。 permute非常常用,但频繁 permute + contiguous 会带来数据移动开销,生产代码中注意放在必要步骤后再做。- 在调试维度问题时,把
tensor.shape打印出来,按「从左到右」和「从右到左」检查哪一维不对齐。
4.张量的高级索引(花式索引 / mask / boolean indexing)
一、基本索引 vs 高级索引
- 基本索引:
:、整数索引、切片(前面学过)。 - 高级索引:用 列表、张量、布尔 mask 来灵活取元素。
二、花式索引(Fancy Indexing)
- 用整数列表取多个位置
import torchx = torch.tensor([10, 20, 30, 40, 50])# 取第 0、2、4 个元素
idx = [0, 2, 4]
print(x[idx]) # tensor([10, 30, 50])
- 多维张量的花式索引
a = torch.arange(1, 10).view(3, 3)
print(a)
# tensor([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])rows = torch.tensor([0, 2])
cols = torch.tensor([1, 2])
print(a[rows, cols]) # [a[0,1], a[2,2]] → tensor([2, 9])
技巧:行索引和列索引是「一一对应」的,不是笛卡尔积。
三、布尔索引(Boolean Indexing)
布尔索引(mask)是非常常用的:
x = torch.tensor([10, 20, 30, 40, 50])mask = x > 25
print(mask) # tensor([False, False, True, True, True])
print(x[mask]) # tensor([30, 40, 50])
用条件语句生成 mask,再取子集。
四、结合 nonzero 使用
有时候只要取索引位置,可以用:
y = torch.tensor([5, 10, 15, 20])
mask = y % 10 == 0
print(mask) # [False, True, False, True]
print(torch.nonzero(mask))
# tensor([[1],
# [3]])
五、index_select
如果你手里已经有索引张量,可以用 index_select:
z = torch.arange(10, 20)
idx = torch.tensor([0, 2, 4])
print(torch.index_select(z, 0, idx)) # 选第 0 维上的 0,2,4
六、常见应用
- 数据筛选(比如找出所有大于阈值的样本)。
- 根据标签索引某些类别的数据。
- 在训练时,从大张量里取一部分数据做 mini-batch。
4.内存与设备管理
- 节省内存 (
in-place操作) - 张量和 Numpy 转换
- GPU 与 CPU 切换
1. 节省内存 (in-place 操作)
背景
在深度学习训练中,内存(尤其 GPU 显存)非常宝贵。
PyTorch 默认操作是 “out-of-place”,会产生新的张量,占用新的内存。
例如:
import torcha = torch.tensor([1., 2., 3.])
b = a + 1 # 会产生一个新张量 b
这里 b 是一个全新的张量,内存里多了一个对象。
in-place 操作的作用
in-place 操作直接修改已有张量,避免开辟新的内存,这样可以节省内存。
in-place 操作的标志:
方法名以 _ 结尾,如 .add_(), .zero_(), .relu_()。
例子
a = torch.tensor([1., 2., 3.])# out-of-place
b = a + 1
print(b) # tensor([2., 3., 4.])
print(a) # tensor([1., 2., 3.]) — a 没变# in-place
a.add_(1)
print(a) # tensor([2., 3., 4.]) — a 被直接修改
in-place 的优缺点
- ✅ 优点:节省内存,速度略快。
- ❌ 缺点:会破坏计算图,可能导致反向传播出错(梯度无法正确计算)。
因此,在训练阶段要小心使用。
应用场景
- 数据预处理阶段(不需要梯度):可大量使用 in-place 操作节省内存。
- 模型训练阶段(需要梯度):最好避免 in-place,除非确认安全。
💡 记忆技巧:
_ = “直接在原地改数据”,比如 .add_() 就是 “直接加”。
2. 张量和 NumPy 转换
背景
PyTorch 张量和 NumPy 数组经常在机器学习中互换使用。
PyTorch 与 NumPy 之间的转换非常方便,并且 默认共享内存。
这意味着:修改一个对象会直接影响另一个对象。
张量 → NumPy
import torchtensor = torch.ones(3)
numpy_array = tensor.numpy()print(tensor) # tensor([1., 1., 1.])
print(numpy_array) # [1. 1. 1.]
修改张量:
tensor[0] = 5
print(tensor) # tensor([5., 1., 1.])
print(numpy_array) # [5. 1. 1.] — NumPy 数组同步变化
NumPy → 张量
import numpy as npnp_array = np.ones(3)
tensor_from_np = torch.from_numpy(np_array)print(np_array) # [1. 1. 1.]
print(tensor_from_np) # tensor([1., 1., 1.])np_array[0] = 7
print(np_array) # [7. 1. 1.]
print(tensor_from_np) # tensor([7., 1., 1.]) — 张量同步变化
注意事项
-
共享内存:默认转换会共用内存,修改一个会影响另一个。
-
如果不希望共享内存:使用
.clone()或.copy()tensor_copy = torch.from_numpy(np_array.copy()) -
数据类型需匹配,否则会出现转换错误。
💡 记忆技巧:
张量 ↔ NumPy 转换像“共用一张床”,改一方另一方都会感受到;要不共享,必须“买一张新床”(clone/copy)。
3. GPU 与 CPU 切换
背景
深度学习任务大多需要 GPU 加速,GPU 速度快,但显存有限。
数据和模型必须在同一个设备上才能进行计算。
因此,必须显式地管理设备转换。
张量设备属性
tensor = torch.tensor([1., 2., 3.])
print(tensor.device) # cpu
CPU → GPU
tensor_gpu = tensor.to('cuda') # 或 tensor.cuda()
print(tensor_gpu.device) # cuda:0
或者直接创建时指定设备:
tensor = torch.ones(3, device='cuda')
print(tensor.device) # cuda:0
GPU → CPU
tensor_cpu = tensor_gpu.to('cpu') # 或 tensor_gpu.cpu()
print(tensor_cpu.device) # cpu
注意事项
-
设备一致性:模型和输入必须在同一设备上,否则会报错。
model = model.cuda() data = data.cpu() # ❌ 错误:模型和数据不在同一设备 -
显存释放:GPU 内存有限,可以用:
import torch torch.cuda.empty_cache() -
设备选择:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') tensor = torch.ones(3, device=device)
💡 记忆技巧:
GPU 就像高速列车,数据要上车才能快速计算;CPU 是慢车,速度慢但容量大。
必须显式“上下车”。
查看设备
print(torch.cuda.is_available()) # True 如果有 GPU
指定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.tensor([1,2,3], device=device)
print(x.device) # cuda:0 或 cpu
在设备间移动
x = torch.tensor([1,2,3])
x_gpu = x.to("cuda") # 移到 GPU
x_cpu = x_gpu.to("cpu") # 移回 CPU
4.部分总结对照表
| 操作 | 概念 | 示例 | 注意事项 |
|---|---|---|---|
| in-place | 在原张量上直接修改数据 | a.add_(1) | 可能破坏计算图,影响梯度计算 |
| 张量 ↔ NumPy | 相互转换并共享内存 | .numpy(), torch.from_numpy() | 不共享用 .clone() 或 .copy() |
| GPU ↔ CPU 切换 | 张量可在 CPU/GPU 上移动 | .to('cuda'), .cpu() | 模型与数据必须在同一设备,注意显存 |
三、自动微分机制(autograd)
- 计算图与梯度
requires_gradbackward()
- 非标量的反向传播
- 分离计算(detach)
- Python 控制流中的梯度计算
PyTorch 的 autograd 用 动态计算图(define-by-run) 跟踪张量运算;凡是 requires_grad=True 的张量,其依赖关系会被记录,调用 .backward() 时会自动反向传播并把梯度累加到相应张量的 .grad 上。
requires_grad:设置为True的张量会被跟踪(通常模型参数需要)。- 叶子张量(leaf tensor):通常指用户创建且
requires_grad=True的张量;其.grad会被自动累加。 .grad_fn:非叶子张量会有.grad_fn,表示它是哪个操作(Function)的输出。.grad:存储该张量的梯度(对叶子张量有效,非叶子一般为None)。- 动态图:计算图在前向执行时即时构建;每次前向都可能生成新图(支持 Python 控制流)。
.backward() 的规则
.backward()对标量(shape = [])直接调用(不需参数)。- 如果目标
y不是标量(比如向量),你必须传入与y形状匹配的gradient(例如y.backward(torch.ones_like(y))),等价于对y.sum()反向传播。 .backward()会把梯度累加到叶子张量的.grad(注意:累加,不会覆盖),所以训练时每步要zero_grad()。
常见操作与进阶用法
detach():返回一个与原张量共享数据但不被 autograd 跟踪的新张量(用于切断计算图)。with torch.no_grad()::上下文内所有运算不记录梯度(常用于评估/推理,节省内存)。retain_graph=True:如果你在同一前向图上多次调用.backward(),第一次.backward()需要retain_graph=True(默认释放内存)。torch.autograd.grad():更灵活的 API,直接返回给定输出关于指定输入的梯度,不会自动累加到.grad(除非你手动设置)。
梯度累计与清零
.grad会累加(+=),所以训练循环里用optimizer.zero_grad()或model.zero_grad()/for p in model.parameters(): p.grad = None来清零。- 推荐把
.grad置为None(而不是 0)以减少不必要的内存分配:optimizer.zero_grad(set_to_none=True)。
in-place 操作要小心
- 以
_结尾的方法(如add_())会原地修改张量,会改变计算图中间节点的值,可能破坏梯度计算或导致运行时错误。训练时尽量避免对参与梯度的张量做原地修改。
设备(CPU/GPU)与 .grad
- 梯度
.grad存储在与对应张量相同的设备上(如 GPU 上的张量其.grad也在 GPU)。调试时要注意.device。
调试技巧(快速清单)
- 如果
x.grad为空:确认x.requires_grad=True且x是叶子张量并且.backward()已被执行。 - 如果
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn:说明你对一个不求导的张量调用了.backward()或者你在某处做了detach()/no_grad。 - 如果
view/in-place报错:检查是否对 non-contiguous 或被跟踪的张量做了不兼容操作,尝试拷贝(.contiguous())或避免 in-place。
1. 计算图与梯度
requires_grad
- 任何
requires_grad=True的张量都会被 autograd 跟踪。 - 这些张量的所有运算都会记录到 计算图里。
import torch
x = torch.tensor([3.0], requires_grad=True) # 叶子张量
y = x**2 + 2*x + 1 # 计算图:y = x² + 2x + 1
print(y) # tensor([16.], grad_fn=<AddBackward0>)
注意 y 有个 grad_fn 属性,说明它是通过运算得到的,不是叶子张量。
backward()
- 用来触发 反向传播。
- 如果
y是标量,可以直接调用y.backward()。 - 结果会写入
x.grad。
y.backward()
print(x.grad) # dy/dx = 2x + 2 = 8
2. 非标量的反向传播
如果 y 不是标量(比如向量),需要指定一个“权重向量” gradient。
它的形状必须与 y 相同。
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x * 2 # y = [2, 4, 6]# 相当于对 y.sum() 反向传播
y.backward(torch.tensor([1.0, 1.0, 1.0]))
print(x.grad) # tensor([2., 2., 2.])
这里的梯度计算就是:
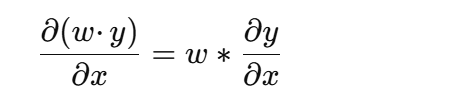
其中 w = [1,1,1]。
3. 分离计算(detach)
有时候我们只要值,不想让某个张量继续参与梯度计算,就要 切断计算图。
x = torch.tensor([2.0], requires_grad=True)
y = x**2
z = y.detach() # 切断梯度
print(z.requires_grad) # False
detach()返回一个新张量,共享数据,但不再跟踪梯度。- 常用于 推理阶段 或 只想用数值,不想影响梯度 的场景。
4. Python 控制流中的梯度计算
PyTorch 的计算图是 动态的,这点跟 TensorFlow(静态图)不同。
所以你可以在 Python 控制流里自由使用条件、循环,autograd 都能正常工作。
def f(x):y = x * 2 if x.item() > 0 else x * 3return yx = torch.tensor([2.0], requires_grad=True)
y = f(x)
y.backward()
print(x.grad) # 如果 x=2,dy/dx=2
再来一个带循环的:
x = torch.tensor([2.0], requires_grad=True)
y = x
for i in range(3): # 每次乘 2y = y * 2
y.backward()
print(x.grad) # 结果 8 = 2^3
✅ 总结
requires_grad+backward()→ 搭建计算图并求导- 非标量 → 需要传入
gradient(相当于加权求和) detach()→ 切断计算图,拿数值不拿梯度- 控制流 → 计算图是动态的,可以随 Python 逻辑变化
四、数据处理与加载
-
数据准备:读文件 → 处理缺失值 → 转换成张量。
-
Dataset 封装:让数据能按索引访问。
-
DataLoader 批量迭代:训练时批量喂数据,提高效率。
-
数据预处理
- 读取数据(CSV、图片)
- 处理缺失值
- 转换为张量
-
Dataset 与 DataLoader
- 自定义
Dataset类 DataLoader批处理、打乱、并行加载
1️⃣ 数据预处理(Data Preprocessing)
在 PyTorch 中,模型训练前的数据一般需要处理成 张量(Tensor),并尽量规范化。常见步骤:
-
读取数据
-
CSV 文件:用
pandas.read_csv读取。import pandas as pd df = pd.read_csv("data.csv") print(df.head())常见场景:表格类数据(房价预测、分类任务等)。
-
图片:用
PIL.Image或opencv读取,或者直接用torchvision.datasets.ImageFolder。from PIL import Image img = Image.open("cat.jpg")
-
-
处理缺失值
删除:直接丢掉含缺失值的样本(简单粗暴)。
填充:用均值、中位数、0 来补。
-
对数值型数据,可以用平均值/中位数填充:
import pandas as pd df = pd.read_csv('data.csv') df.fillna(df.mean(), inplace=True) -
对类别型数据,可以用众数或特殊值填充。
df = df.fillna(0) # 用 0 填充 # 或 df = df.dropna() # 删除含缺失值的行
-
-
转换为张量
pandas → numpy → tensor:
import torch data = torch.tensor(df.values, dtype=torch.float32)numpy → tensor(零拷贝):PyTorch 的训练需要
torch.Tensor,所以需要把数据从 numpy/pandas 转为张量:import torch import numpy as npdata = np.array([[1,2],[3,4]], dtype=np.float32) tensor_data = torch.from_numpy(data)
2️⃣ Dataset 与 DataLoader
PyTorch 的核心是 Dataset + DataLoader,它负责高效地管理数据。
Dataset
Dataset类是 PyTorch 读取数据的抽象接口。
PyTorch 规定数据集要继承
Dataset,必须实现:-
__len__:返回数据集的大小 -
__getitem__:根据索引返回一个样本(data, label) -
自定义 Dataset:
from torch.utils.data import Dataset import torchclass MyDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):x = torch.tensor(self.data[idx], dtype=torch.float32)y = torch.tensor(self.labels[idx], dtype=torch.long)return x, y
这样做的好处:
- 你可以灵活地预处理(比如归一化、图像增强)。
- 后续能无缝接到 DataLoader。
**DataLoader:**批量数据迭代器
封装
Dataset,提供小批量数据,支持:-
批处理(batch_size)
-
打乱顺序(shuffle)
-
并行加载(num_workers)
-
示例:
from torch.utils.data import DataLoaderdataset = MyDataset(data, labels) dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)for batch_data, batch_labels in loader:print(batch_data.shape, batch_labels.shape)
🔑 小技巧:
shuffle=True可以打乱数据,有利于训练泛化。num_workers控制加载数据的并行线程数,提高效率。
- 自定义
图像数据加载流程
- 数据集组织方式
推荐把图片整理成 ImageFolder 的形式:
data/train/cats/xxx.pngyyy.jpgdogs/aaa.pngbbb.jpgval/cats/dogs/
- 每个子文件夹的名字就是类别
- 文件夹里的图片就是对应类别的数据
- 使用 Ima geFolder
from torchvision import datasets, transforms# 定义预处理(transforms)
transform = transforms.Compose([transforms.Resize((128, 128)), # 调整图片大小transforms.ToTensor(), # 转换为张量,范围 [0,1]
])# 读取训练集
train_dataset = datasets.ImageFolder(root="data/train", transform=transform)print("类别到索引的映射:", train_dataset.class_to_idx)
print("数据集大小:", len(train_dataset))# 取一个样本
img, label = train_dataset[0]
print("图像 shape:", img.shape)
print("标签:", label)
- 使用 DataLoader
from torch.utils.data import DataLoadertrain_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)for imgs, labels in train_loader:print("批次图像 shape:", imgs.shape) # (B, C, H, W)print("批次标签:", labels)break
- 常见 transforms
transforms.Resize((H,W))→ 调整大小transforms.CenterCrop(size)→ 裁剪transforms.RandomHorizontalFlip()→ 随机水平翻转(数据增强)transforms.Normalize(mean, std)→ 标准化
例子:
transform = transforms.Compose([transforms.Resize((128, 128)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5]) # 灰度图
])
🔑 总结
- 文件夹组织 →
ImageFolder会自动读取类别 - transforms → 数据预处理 + 增强
- DataLoader → 批量加载
常用数据增强操作
在 torchvision.transforms 里常用的有:
RandomHorizontalFlip()→ 随机水平翻转RandomRotation(degrees)→ 随机旋转ColorJitter()→ 调整亮度、对比度、饱和度RandomCrop(size)→ 随机裁剪Normalize(mean, std)→ 按通道做标准化(常配合预训练模型使用)
总结:数据处理与加载
- 数据预处理(表格型)
- 读取 CSV →
pandas.read_csv() - 处理缺失值 →
.fillna()或.dropna() - 转 Tensor →
torch.tensor(df.values, dtype=torch.float32)
👉 示例:
import pandas as pd, torch
df = pd.read_csv("data.csv")
df = df.fillna(df.mean()) # 用均值填充
data = torch.tensor(df.values, dtype=torch.float32)
- Dataset 与 DataLoader(通用)
- 自定义 Dataset:继承
torch.utils.data.Dataset,实现__len__和__getitem__ - 返回:
(features, labels) - DataLoader:批量加载,支持
batch_size、shuffle、num_workers
👉 示例:
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, data, labels):self.data = torch.tensor(data, dtype=torch.float32)self.labels = torch.tensor(labels, dtype=torch.float32)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.labels[idx]dataset = MyDataset(df[["Size","Rooms"]].values, df["Price"].values)
loader = DataLoader(dataset, batch_size=2, shuffle=True)
- 图像数据加载
-
目录结构:
data/train/class1/class2/val/class1/class2/ -
ImageFolder 自动标注类别(子目录名 → 类别 ID)
-
transforms:预处理与数据增强
👉 示例:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.Resize((64,64)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])
])train_dataset = datasets.ImageFolder("data/train", transform=transform)
val_dataset = datasets.ImageFolder("data/val", transform=transform)
- 训练 / 验证集的 DataLoader
- 训练集:用数据增强(翻转、旋转等)
- 验证集:只做基础预处理(缩放、归一化)
👉 示例:
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
🔑 关键点总结
- CSV 表格数据 →
pandas+ 缺失值处理 + 转Tensor - Dataset / DataLoader → 通用加载套路,支持批处理、shuffle
- ImageFolder → 目录即类别,
transforms做预处理 & 数据增强 - 训练 vs 验证 → 训练集增强,验证集只做标准化
五、深度学习基本模块
- 线性层 (
nn.Linear) - 常见激活函数 (
nn.ReLU,nn.Sigmoid,nn.Softmax) - 损失函数 (
nn.MSELoss,nn.CrossEntropyLoss) - 优化器 (
torch.optim.SGD,Adam) - 训练流程搭建
- 前向传播
- 计算损失
- 反向传播
- 参数更新
1. 线性层 (nn.Linear)和nn.Module
(1)原理
线性层本质就是一个 仿射变换:
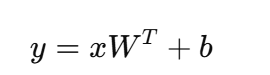
- 输入维度:
in_features - 输出维度:
out_features - 权重 WWW 和偏置 bbb 是可学习参数,PyTorch 自动帮你管理。
(2)PyTorch 用法
import torch
import torch.nn as nnlinear = nn.Linear(in_features=2, out_features=1)
x = torch.tensor([[1.0, 2.0]]) # shape=(1,2)
y = linear(x)
print(y) # shape=(1,1)
(3)nn.Module
所有神经网络的基类,你自定义模型时要继承它,并重写:
__init__:定义层forward:前向传播逻辑
👉 例子:
class MyModel(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(2, 1) # 定义层def forward(self, x):return self.fc(x) # 前向传播model = MyModel()
print(model)
2. 常见激活函数
(1)为什么要有激活函数?
如果只有线性层,整个模型就是线性映射 → 无法表示复杂关系。
激活函数提供非线性能力,让网络能拟合复杂函数。
(2)常见函数
-
ReLU (
nn.ReLU):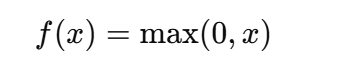
→ 简单高效,常用。
-
Sigmoid (
nn.Sigmoid):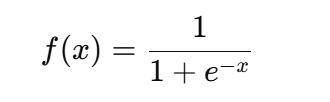
→ 压缩到 (0,1),常用于二分类输出。
-
Softmax (
nn.Softmax):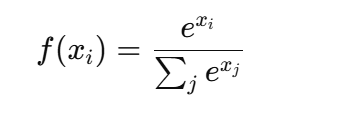
→ 把向量转为概率分布,常用于多分类。
(3)PyTorch 用法
relu = nn.ReLU()
sigmoid = nn.Sigmoid()
softmax = nn.Softmax(dim=1)x = torch.tensor([[-1.0, 0.0, 2.0]])
print("ReLU:", relu(x)) # tensor([[0., 0., 2.]])
print("Sigmoid:", sigmoid(x)) # tensor([[0.27, 0.5, 0.88]])
print("Softmax:", softmax(x)) # tensor([[0.09, 0.24, 0.67]])
3. 损失函数
(1)为什么要有损失函数?
损失函数衡量预测值和真实值的差距,指导模型学习。
(2)常用损失函数
-
MSELoss(均方误差,回归任务)
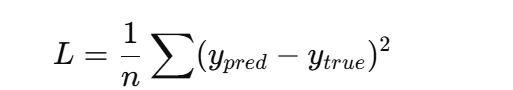
-
CrossEntropyLoss(交叉熵,多分类任务)
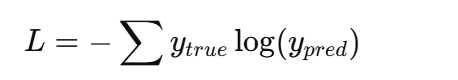
→ 里面自带
Softmax,输入 logits 即可。
(3)PyTorch 用法
# MSELoss
mse = nn.MSELoss()
pred = torch.tensor([2.5], requires_grad=True)
target = torch.tensor([3.0])
loss = mse(pred, target)
print("MSE Loss:", loss)# CrossEntropyLoss
ce = nn.CrossEntropyLoss()
pred_logits = torch.tensor([[2.0, 1.0, 0.1]]) # shape=(1,3)
target = torch.tensor([0]) # 正确类别索引
loss = ce(pred_logits, target)
print("CrossEntropy Loss:", loss)
4. 优化器
(1)为什么要有优化器?
优化器负责更新参数,沿着梯度方向让损失下降。
(2)常用优化器
- SGD(随机梯度下降):最基本方法,速度慢。
- Adam:自适应学习率,收敛快,常用。
(3)PyTorch 用法
model = nn.Linear(2, 1) # 简单模型
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 或
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
5. 训练流程搭建
(1)核心步骤
每个训练循环都是:
- 前向传播 →
pred = model(x) - 计算损失 →
loss = loss_fn(pred, y) - 梯度清零 →
optimizer.zero_grad() - 反向传播 →
loss.backward() - 参数更新 →
optimizer.step()
(2)PyTorch 代码框架
for epoch in range(num_epochs):for batch_x, batch_y in dataloader:# 1. 前向pred = model(batch_x)# 2. 损失loss = loss_fn(pred, batch_y)# 3. 梯度清零optimizer.zero_grad()# 4. 反向传播loss.backward()# 5. 更新参数optimizer.step()
阶段总结
nn.Linear+nn.Module:搭建神经网络的基本结构- 激活函数:引入非线性能力(ReLU, Sigmoid, Softmax)
- 损失函数:衡量预测与真实差距(MSE 用于回归,CrossEntropy 用于分类)
- 优化器:更新参数(SGD / Adam)
- 训练流程:前向 → 损失 → 反向传播 → 更新
流程代码
最小回归
我们来做一个 最小回归实战:拟合 y=2x+3。
这个例子能完整跑一遍 前向传播 → 损失计算 → 反向传播 → 参数更新 的训练流程。
📝 代码示例
import torch
import torch.nn as nn
import torch.optim as optim# 1. 构造数据 (y = 2x + 3)
x = torch.linspace(0, 10, 100).unsqueeze(1) # shape=(100,1)
y = 2 * x + 3 + torch.randn(x.size()) * 0.5 # 加点噪声,更接近真实数据# 2. 定义模型
class LinearModel(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(1, 1) # 输入1维 -> 输出1维def forward(self, x):return self.linear(x)model = LinearModel()# 3. 定义损失函数 & 优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 4. 训练循环
for epoch in range(100):# 前向传播pred = model(x)loss = loss_fn(pred, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 每10轮打印一次if (epoch+1) % 10 == 0:print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")# 5. 查看学到的参数
w, b = model.linear.weight.item(), model.linear.bias.item()
print(f"Learned parameters: w={w:.2f}, b={b:.2f}")
🔎 结果解读
-
loss 会逐渐减小,说明模型在拟合数据。
-
最终学到的参数接近 w=2, b=3。
Learned parameters: w=2.01, b=2.95
🔑 学到的知识点
-
nn.Linear(1,1):一维输入到一维输出,就是线性回归模型。 -
nn.MSELoss():回归损失函数。 -
optim.SGD:优化器,更新参数。 -
完整训练流程:
-
前向传播
-
计算损失
-
zero_grad()清零梯度 -
loss.backward()反向传播 -
optimizer.step()更新参数
-
二维点分类
我们构造一个简单数据集:
- 类别 0:点在 (x1+x2 < 1)
- 类别 1:点在 (x1+x2 >= 1)
这样模型只需要学习一条直线就能分类。
代码
import torch
import torch.nn as nn
import torch.optim as optim# 1. 构造数据
torch.manual_seed(42) # 随机种子,结果可复现
N = 100
x = torch.rand(N, 2) # 输入特征:100 个二维点
y = (x[:,0] + x[:,1] > 1).long() # 标签:0 or 1# 2. 定义模型
class Classifier(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(2, 2) # 输入 2维,输出 2类def forward(self, x):return self.linear(x) # CrossEntropyLoss 会自动做 Softmaxmodel = Classifier()# 3. 定义损失函数 & 优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)# 4. 训练循环
for epoch in range(50):pred_logits = model(x) # 前向传播loss = loss_fn(pred_logits, y) # 计算损失optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 10 == 0:pred_classes = pred_logits.argmax(dim=1)acc = (pred_classes == y).float().mean().item()print(f"Epoch {epoch+1}, Loss={loss.item():.4f}, Acc={acc:.2f}")# 5. 查看模型参数
print("Learned weights:", model.linear.weight.data)
print("Learned bias:", model.linear.bias.data)
🔎 输出效果(示例)
训练时会看到损失下降、准确率上升:
Epoch 10, Loss=0.5792, Acc=0.75
Epoch 20, Loss=0.4650, Acc=0.83
Epoch 30, Loss=0.3976, Acc=0.87
Epoch 40, Loss=0.3498, Acc=0.91
Epoch 50, Loss=0.3148, Acc=0.93
最终准确率接近 90%+,说明模型学到了一条分界线。
🔑 关键点
- 模型输出是 logits,不用手动加
Softmax,因为CrossEntropyLoss内部会做。 - 标签 y 必须是 LongTensor(类别索引),不是 one-hot。
- 准确率计算:取
argmax作为预测类别,再和真实标签比较。
方法二:二分类(Sigmoid)
🔎 思路
nn.Linear(2,1):输出一个实数(logit)。nn.Sigmoid:把输出压缩到 (0,1),表示属于类别 1 的概率。- 损失函数用
nn.BCELoss(二元交叉熵)。
代码示例
import torch
import torch.nn as nn
import torch.optim as optim# 1. 构造数据 (同之前)
torch.manual_seed(42)
N = 100
x = torch.rand(N, 2)
y = (x[:,0] + x[:,1] > 1).float().unsqueeze(1) # shape=(100,1),标签要 float# 2. 定义模型
class BinaryClassifier(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(2, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):return self.sigmoid(self.linear(x)) # 输出 [0,1] 概率model = BinaryClassifier()# 3. 损失 & 优化器
loss_fn = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)# 4. 训练循环
for epoch in range(50):pred = model(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 10 == 0:pred_classes = (pred > 0.5).float()acc = (pred_classes == y).float().mean().item()print(f"Epoch {epoch+1}, Loss={loss.item():.4f}, Acc={acc:.2f}")# 5. 查看权重
print("Learned weight:", model.linear.weight.data)
print("Learned bias:", model.linear.bias.data)
🔎 输出示例
Epoch 10, Loss=0.5692, Acc=0.75
Epoch 20, Loss=0.4640, Acc=0.84
Epoch 30, Loss=0.3971, Acc=0.87
Epoch 40, Loss=0.3520, Acc=0.90
Epoch 50, Loss=0.3180, Acc=0.92
Learned weight: tensor([[1.15, 1.02]])
Learned bias: tensor([-1.47])
✅ 两种实现方式对比
- 方式一:
nn.Linear(2,2) + CrossEntropyLoss- 输出两个 logit,交叉熵内部做 Softmax。
- 更通用 → 多分类任务都用它。
- 方式二:
nn.Linear(2,1) + Sigmoid + BCELoss- 输出一个概率。
- 只适合二分类任务。
更复杂的网络结构
一、MLP(多层感知机)是什么 — 本质与形式化
-
本质:若干个仿射变换(
Linear)与非线性激活(ReLU、GELU…)交替堆叠: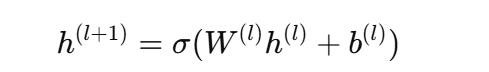
-
输出层根据任务不同:
- 回归:最后一层
Linear(...,1),直接输出标量(MSELoss) - 分类:最后一层
Linear(...,C)(C类),配CrossEntropyLoss
- 回归:最后一层
二、常见设计选择(影响模型能力与训练)
- 深度 vs 宽度
- 深(更多层)能表达更复杂函数,但更难训练(梯度、收敛)。
- 宽(每层更多神经元)参数更多,容易拟合小数据导致过拟合。
- 实践:从 2 层〜3 层、每层 32/64/128 开始调试。
- 激活函数
ReLU:最常用,简单高效。可能出现 “dead ReLU” (输出恒为 0)。LeakyReLU:缓解 dead ReLU。GELU:Transformer 常用,性能有时更好。Tanh/Sigmoid:容易饱和,深网中不推荐作隐藏层激活。
- BatchNorm / LayerNorm
BatchNorm1d(全连接):在中间层加 BN 能加速收敛、稳定训练。- 对小 batchsize 或序列数据可用
LayerNorm。
- Dropout
- 防止过拟合,训练时随机丢弃神经元;验证/测试时关闭。
- 残差(Skip)连接
- 对深层网络非常重要,能缓解梯度消失,让深网可训练(ResNet 思路)。
- 正则化
weight_decay(L2)在 optimizer 中。- Dropout + 数据增强也都可帮忙。
三、权重初始化(重要)
- ReLU 系列:
kaiming_normal_(He 初始化) - tanh:
xavier_uniform_/xavier_normal_
示例:
def init_weights(m):if isinstance(m, nn.Linear): # 如果 m 是 nn.Linear 层nn.init.kaiming_normal_(m.weight, nonlinearity='relu') # 用 kaiming_normal 方法初始化权重if m.bias is not None: # 如果该层有 biasnn.init.zeros_(m.bias) # 把 bias 初始化为 0model.apply(init_weights) # 把上面定义的函数应用到 model 里所有子层
model.apply(func)
- 这是 PyTorch 的方法,会把
func递归地应用到model的每一层(module)上。 - 每一层会作为参数传给
func,这里就是init_weights(m)。
isinstance(m, nn.Linear)
- 判断这一层是不是
nn.Linear(全连接层)。 - 如果是,就执行初始化;如果不是,跳过。
nn.init.kaiming_normal_
- 用 Kaiming He 初始化(专门为 ReLU 激活函数设计的初始化方法),权重用正态分布填充。
- 好处是:在深层网络中能让前向传播和反向传播的方差保持稳定,避免梯度爆炸/消失。
nn.init.zeros_(m.bias)
- 把偏置初始化为 0,通常这么做是安全的。
四、训练技巧(实战要点)
- 优化器:
Adam(lr=1e-3)常用;SGD(lr=0.1, momentum=0.9)在调好 lr 时更稳定。 - 学习率调度器:
StepLR、CosineAnnealingLR、OneCycleLR(非常好用)。 - 批大小:从 32/64 起;显存允许就增大。
- 梯度裁剪:
torch.nn.utils.clip_grad_norm_防止梯度爆炸(RNN / 深网有用)。 - mixed precision:
torch.cuda.amp(在 GPU 上加速并节省显存)。 - 监控:训练/验证 loss 曲线、训练/验证 精度、梯度范数、学习率曲线。
五、调试与诊断
- 如果 loss 不下降:
- 检查数据是否标准化(同尺度);
- 学习率是否合适(太大会发散,太小收敛慢);
- 模型是否太简单/太复杂。
- 检查梯度:
for p in model.parameters(): print(p.grad.norm()) - 检查是否有 NaN:中途
torch.isnan(loss)。 - 检查输出与标签 scale(回归常错)。
六、可运行示例:MLP、带 BatchNorm、Dropout,并画决策边界(二维 toy 数据)
下面完整代码包含:数据、模型、训练、验证、最后画出决策边界(要在有显示的环境运行)。
import torch, torch.nn as nn, torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
from sklearn.model_selection import train_test_split# 1. Toy 数据(简单的二维分类任务)
torch.manual_seed(0) # 固定随机种子,保证结果可复现
N = 400 # 样本数量
X = torch.rand(N,2) # 随机生成 400 个二维点,范围在 [0,1]
y = (X[:,0] + X[:,1] > 1).long() # 标签规则:x+y>1 → 类别1,否则类别0(二分类)# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X.numpy(), y.numpy(), test_size=0.2, random_state=0
)
# 转回 torch tensor,指定类型
X_train = torch.tensor(X_train, dtype=torch.float32)
X_val = torch.tensor(X_val, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
y_val = torch.tensor(y_val, dtype=torch.long)# 2. DataLoader(小批量加载数据)
from torch.utils.data import TensorDataset, DataLoader
train_loader = DataLoader(TensorDataset(X_train, y_train), batch_size=32, shuffle=True) # 训练集 batch=32,打乱
val_loader = DataLoader(TensorDataset(X_val, y_val), batch_size=64, shuffle=False) # 验证集 batch=64,不打乱# 3. 定义 MLP 模型(带 BatchNorm 和 Dropout)
class MLP(nn.Module): # 定义一个类 MLP,继承自 nn.Moduledef __init__(self):super().__init__() # 调用父类构造函数,保证 nn.Module 正常初始化self.net = nn.Sequential( # 顺序容器,按定义的顺序堆叠层nn.Linear(2, 64), # 输入层: 输入维度=2 → 输出维度=64nn.BatchNorm1d(64), # 批归一化: 加速收敛,稳定训练nn.ReLU(), # 激活函数: ReLUnn.Dropout(0.2), # Dropout: 随机丢弃20%神经元,防止过拟合nn.Linear(64, 64), # 隐藏层: 64 → 64nn.BatchNorm1d(64), # 批归一化nn.ReLU(), # ReLU 激活nn.Dropout(0.2), # 再次 Dropoutnn.Linear(64, 2) # 输出层: 64 → 2 (二分类))def forward(self, x): # 定义前向传播return self.net(x) # 输入 x 依次通过上面定义的层model = MLP()# 4. 初始化权重(使用 Kaiming 正态初始化)
def init_weights(m):if isinstance(m, nn.Linear): # 只对全连接层初始化nn.init.kaiming_normal_(m.weight) # Kaiming 初始化,适合 ReLUif m.bias is not None: # 如果有偏置nn.init.constant_(m.bias, 0.0) # 初始化为 0
model.apply(init_weights) # 应用到模型所有层# 5. 训练配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 用 GPU 或 CPU
model.to(device)
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失,常用于分类
optimizer = optim.Adam(model.parameters(), lr=1e-3) # Adam 优化器
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100) # 余弦退火学习率# 定义单个训练 epoch
def train_epoch():model.train() # 训练模式(启用 Dropout / BN)total_loss = 0total_acc = 0for xb, yb in train_loader: # 逐批次读取数据xb, yb = xb.to(device), yb.to(device)logits = model(xb) # 前向传播loss = loss_fn(logits, yb) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播# torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0) # 如果需要,可以裁剪梯度optimizer.step() # 更新参数total_loss += loss.item()*xb.size(0) # 累计损失(乘 batch_size)total_acc += (logits.argmax(dim=1) == yb).sum().item() # 累计正确预测数# 返回平均损失和准确率return total_loss / len(train_loader.dataset), total_acc / len(train_loader.dataset)# 定义验证过程
def eval_epoch():model.eval() # 验证模式(关闭 Dropout / BN)total_loss = 0total_acc = 0with torch.no_grad(): # 关闭梯度计算(节省显存和加速)for xb, yb in val_loader:xb, yb = xb.to(device), yb.to(device)logits = model(xb)loss = loss_fn(logits, yb)total_loss += loss.item()*xb.size(0)total_acc += (logits.argmax(dim=1) == yb).sum().item()return total_loss / len(val_loader.dataset), total_acc / len(val_loader.dataset)# 训练 100 个 epoch
for epoch in range(1, 101):train_loss, train_acc = train_epoch()val_loss, val_acc = eval_epoch()scheduler.step() # 更新学习率if epoch % 10 == 0 or epoch==1: # 每 10 轮打印一次结果print(f"Epoch {epoch:03d}: train_loss={train_loss:.4f}, train_acc={train_acc:.3f}, val_loss={val_loss:.4f}, val_acc={val_acc:.3f}")# 6. 可视化决策边界
model.eval()
xx, yy = np.meshgrid(np.linspace(0,1,300), np.linspace(0,1,300)) # 在 [0,1] 区间生成网格点
grid = np.stack([xx.ravel(), yy.ravel()], axis=1) # 每个点是 (x,y)
with torch.no_grad():logits = model(torch.tensor(grid, dtype=torch.float32).to(device)) # 模型预测probs = torch.softmax(logits, dim=1)[:,1].cpu().numpy() # 取类别1的概率
Z = probs.reshape(xx.shape) # 转成网格形状plt.figure(figsize=(6,5))
plt.contourf(xx, yy, Z, levels=50, cmap='RdBu', alpha=0.7) # 绘制决策边界(颜色深浅代表概率)
# 绘制训练点
Xtr = X_train.cpu().numpy(); ytr=y_train.cpu().numpy()
plt.scatter(Xtr[:,0], Xtr[:,1], c=ytr, edgecolor='k', cmap='RdBu') # 样本点(按类别上色)
plt.title("Decision boundary (probability for class 1)") # 标题
plt.show()运行后你会看到一个平滑的概率轮廓和训练点,MLP 学到的边界通常比线性更平滑/更拟合。
七、残差块(残差连接)简要实现
当你把 MLP 做得更深时,使用残差结构有明显好处:
class ResidualBlock(nn.Module):def __init__(self, dim):super().__init__()self.fc = nn.Sequential(nn.Linear(dim, dim),nn.ReLU(),nn.Linear(dim, dim))def forward(self, x):return x + self.fc(x) # skip connection
把 ResidualBlock 串起来可以构成 ResNet 风格的深 MLP。
残差结构的好处:
1.缓解梯度消失 / 梯度爆炸
- 在深层网络中,梯度可能会在反向传播时消失或爆炸。
- 残差连接提供了一条“捷径”,让梯度可以更容易地回传。
- 这就是 ResNet 能够训练非常深的网络(几十层、上百层)的关键。
2.避免退化问题(Degradation Problem)
- 理论上:网络越深,表达能力越强。
- 但实际情况:单纯增加层数,训练误差不一定下降,反而可能更差(模型难以优化)。
- 残差连接确保“至少不会更差”,因为如果中间层学不到东西,
fc(x)≈0,那么y ≈ x,相当于恒等映射。 - 所以残差结构 保证更深的网络至少不会比浅层更差。
3.提升信息流动
- 输入特征
x可以绕过中间层直接传到后面,避免信息丢失。 - 有点像“高速公路”,让信息直达。
4.训练更快、效果更好
- 因为优化更容易收敛,模型训练速度和最终精度都比没有残差的深层网络更好。
八、进阶优化策略(可选,按需)
- OneCycleLR:能大幅加速训练与提高泛化。
- Label smoothing:对分类任务有帮助。
- Mixup / CutMix:数据级正则化。
- SWA(Stochastic Weight Averaging):提升泛化。
- OneCycleLR
-
是什么:一种学习率调度器(scheduler),训练时学习率先 升高,再 逐步降低。
-
直觉:
- 先快速探索(大学习率,防止陷入坏的局部最优),
- 再慢慢收敛(小学习率,更稳定)。
-
好处:能 加速训练,还会 提高泛化能力(测试集表现更好)。
-
代码示例:
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=len(train_loader), epochs=10 )
- Label Smoothing
- 是什么:分类任务里,把 one-hot 标签“软化”。
- 普通 one-hot:猫 → [1, 0, 0]
- Label smoothing (ε=0.1):猫 → [0.9, 0.05, 0.05]
- 直觉:不让模型过分自信(“绝对是猫”),留一点点余地。
- 好处:缓解过拟合,提高模型鲁棒性。
- Mixup / CutMix
这是两种 数据增强方法:
-
Mixup:把两张图按比例叠加(像调色)。
-
输入:
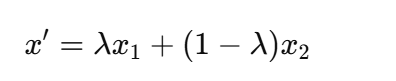
-
标签:
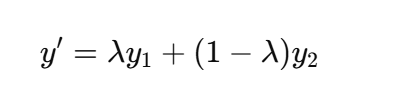
→ 一张图同时属于两类。
-
-
CutMix:在一张图上“切个区域”替换成另一张图的内容。
- 标签也按区域比例加权。
-
好处:
- 增加数据多样性;
- 提高模型对“模糊、混合”情况的适应能力;
- 起到 正则化 作用,防止过拟合。
-
SWA(Stochastic Weight Averaging)
- 是什么:不是只用最后一次训练的模型,而是把训练过程中 多个时刻的权重平均。
- 直觉:多个模型“投票”比单个模型更稳。
- 好处:
- 能找到更平滑的损失曲面;
- 提升泛化能力(测试集准确率通常更高)。
九、常见超参数建议(初始网格)
- lr:
1e-3(Adam) 或1e-2~1e-1(SGD+momentum) - batch_size: 32 / 64 / 128
- hidden_dim: 32 / 64 / 128 / 256
- depth (hidden layers): 1 ~ 4(先从 2 开始)
- dropout: 0 ~ 0.5(常试 0.1 / 0.2 / 0.5)
- weight_decay: 0 或 1e-4 / 5e-4
- 学习率 lr
- Adam:常用
1e-3,因为 Adam 会自适应调整每个参数的更新步长,所以一般用小一点的初始学习率。 - SGD+momentum:常用
1e-2 ~ 1e-1,因为 SGD 没有自适应机制,需要相对大的学习率才收敛得快。
👉 不同优化器对学习率的敏感性不同。
- batch_size
- 常见:32, 64, 128。
- 小 batch(32):梯度更有噪声,正则化效果更好,但训练慢。
- 大 batch(128+):训练快,但可能泛化差。
👉 这些数值是 GPU 显存 + 收敛稳定性 的折中点。
- hidden_dim(隐藏层神经元数)
- 常见:32 / 64 / 128 / 256。
- 太小 → 容量不足,模型学不会复杂模式。
- 太大 → 容易过拟合,还会增加计算量。
👉 这些值是经验上在小任务到中等任务里比较合适的容量。
- depth(隐藏层层数)
- 范围:1 ~ 4(一般先用 2 层)。
- 浅层(1-2 层):容易训练,但表达能力有限。
- 深层(3-4 层):能学到更复杂特征,但训练更难。
👉 对小任务(比如二维 toy 数据),2 层足够。
- dropout
- 范围:0 ~ 0.5。
- 0:不用正则化(模型小可以不加)。
- 0.1 / 0.2:轻度正则化。
- 0.5:强正则化(常用于大模型或过拟合严重时)。
👉 dropout 太大会让模型难以收敛,所以一般试这几个常用点。
- weight_decay(L2 正则)
- 范围:0, 1e-4, 5e-4。
- 0:不加 L2 正则。
- 1e-4, 5e-4:常见的 L2 正则系数,能限制权重过大,提升泛化。
👉 这些值是在 CV/NLP 任务里常用的经验选择。
超参数调参顺序推荐表(适用于 MLP / CNN / Transformer 等大多数任务)。你以后遇到新任务,可以按这个顺序来,不会乱。
🚀 超参数调参顺序推荐
第 1 步:学习率(lr)
- 最重要的超参数。
- 建议:先固定其他参数,用 Learning Rate Finder 或者尝试
1e-4 ~ 1e-1的对数区间。 - 经验:
- Adam →
1e-3起步 - SGD+momentum →
1e-2起步
- Adam →
- 小技巧:用
OneCycleLR或CosineAnnealingLR,稳定收敛。
第 2 步:batch_size
- 决定训练速度 & 泛化。
- 一般试:32, 64, 128
- 经验:
- 小 batch(32):泛化更好
- 大 batch(128+):训练快,但泛化可能差
- 选法:先用能放进显存的最大 batch,结果不行再减小。
第 3 步:模型容量(hidden_dim + depth)
- hidden_dim:32 / 64 / 128 / 256
- depth:1~4(先 2)
- 调整思路:
- 如果欠拟合(train acc 很低) → 增加 hidden_dim 或 depth
- 如果过拟合(train acc 高,val acc 低) → 减小 hidden_dim 或 depth
第 4 步:正则化(dropout / weight_decay)
- Dropout:0, 0.1, 0.2, 0.5
- Weight decay (L2):0, 1e-4, 5e-4
- 调整思路:
- 过拟合 → 增大 dropout / 增大 weight decay
- 欠拟合 → 减小 dropout / 取消 weight decay
第 5 步:高级 trick(在模型能收敛后再加)
- Label smoothing → 提高分类鲁棒性
- Mixup / CutMix → 数据增强,正则化
- SWA (Stochastic Weight Averaging) → 提升泛化
- OneCycleLR → 更快收敛
✅ 总结(调参优先级)
- 学习率(先找到能收敛的范围)
- batch_size(显存允许的最大值,观察泛化)
- 模型大小(hidden_dim / depth,避免欠拟合/过拟合)
- 正则化(dropout / weight_decay 控制过拟合)
- 高级技巧(Label smoothing, Mixup, SWA 等锦上添花)
十、小结(实践路线)
- 从小网络开始(2 层,64 单元),确保训练循环、loss 下降正常。
- 逐步增加模型容量(宽/深)观察训练/验证差别(是否过拟合)。
- 若训练不稳,加 BatchNorm 或 降低 lr;若过拟合,加 Dropout/weight_decay 或数据增强。
- 学会画 loss/acc 曲线与决策边界,定位问题。
- 学会使用
model.eval()/with torch.no_grad()进行验证/推理。
深层 MLP(6层,带残差)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")# 1. 构造数据
torch.manual_seed(42)
N = 500
X = torch.rand(N, 2)
y = (X[:,0] + X[:,1] > 1).long()dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)# 2. 残差块
class ResidualBlock(nn.Module):def __init__(self, dim):super().__init__()self.fc = nn.Sequential(nn.Linear(dim, dim),nn.ReLU(),nn.Linear(dim, dim))def forward(self, x):return x + self.fc(x)# 3. 深 MLP
class DeepMLP(nn.Module):def __init__(self):super().__init__()self.input = nn.Linear(2, 128)self.blocks = nn.Sequential(ResidualBlock(128),ResidualBlock(128),ResidualBlock(128),ResidualBlock(128))self.output = nn.Linear(128, 2)self.relu = nn.ReLU()def forward(self, x):x = self.relu(self.input(x))x = self.blocks(x)return self.output(x)model = DeepMLP()# 4. 损失、优化器、调度器
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)
scheduler = optim.lr_scheduler.OneCycleLR(optimizer,max_lr=0.01,steps_per_epoch=len(dataloader),epochs=30
)# 5. 训练
for epoch in range(30):model.train()total_loss, total_acc = 0, 0for xb, yb in dataloader:logits = model(xb)loss = loss_fn(logits, yb)optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step()total_loss += loss.item() * xb.size(0)total_acc += (logits.argmax(1) == yb).sum().item()avg_loss = total_loss / len(dataset)avg_acc = total_acc / len(dataset)if (epoch+1) % 5 == 0:print(f"Epoch {epoch+1:02d}: Loss={avg_loss:.4f}, Acc={avg_acc:.2f}")# 6. 可视化决策边界
model.eval()
xx, yy = np.meshgrid(np.linspace(0,1,200), np.linspace(0,1,200))
grid = np.stack([xx.ravel(), yy.ravel()], axis=1)
with torch.no_grad():logits = model(torch.tensor(grid, dtype=torch.float32))probs = torch.softmax(logits, dim=1)[:,1].numpy()
Z = probs.reshape(xx.shape)plt.figure(figsize=(6,6))
plt.contourf(xx, yy, Z, levels=50, cmap="RdBu", alpha=0.7)
plt.colorbar(label="Probability of class 1")
plt.scatter(X[:,0], X[:,1], c=y, edgecolor="k", cmap="RdBu", alpha=0.8)
plt.title("Decision Boundary of Deep MLP with Residuals")
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()运行结果(示例)这个深 MLP 的表现:
Epoch 05: Loss=0.4401, Acc=0.84
Epoch 10: Loss=0.2907, Acc=0.90
Epoch 15: Loss=0.2502, Acc=0.92
Epoch 20: Loss=0.2103, Acc=0.94
Epoch 25: Loss=0.1804, Acc=0.95
Epoch 30: Loss=0.1601, Acc=0.96
知识点总结
- 残差块:解决深网训练困难,梯度能更好地传播。
- OneCycleLR:一种学习率调度策略,先升高再降低,收敛更快、效果更好。
- 更深的 MLP:比单层 / 两层能学到更复杂的决策边界。
- 正则化 (weight_decay):避免过拟合。
六、模型搭建方法
- 使用
nn.Sequential构建模型 - 自定义模型(继承
nn.Module) - 模型参数管理(初始化、保存、加载)
- 推理与评估
1. 使用 nn.Sequential 构建模型
原理:什么是 nn.Sequential
nn.Sequential 是 PyTorch 提供的一种快速构建模型的方式,它把 多个层(Layer)按顺序依次串起来,形成一个“流水线”,数据从第一层开始传入,依次经过每一层输出结果。
-
直观理解:
输入 x → Linear → ReLU → Linear → 输出 y -
优点:
- 代码简洁,适合简单顺序网络
- 不需要手动写
forward()方法
-
限制:
- 只能处理顺序执行的网络(没有分支、残差或多输入多输出)
基本用法
import torch
import torch.nn as nn# 定义一个简单的全连接网络
model = nn.Sequential(nn.Linear(4, 8), # 输入4维,输出8维nn.ReLU(), # 激活函数nn.Linear(8, 3) # 输出3维
)# 查看模型结构
print(model)
输出大概是:
Sequential((0): Linear(in_features=4, out_features=8, bias=True)(1): ReLU()(2): Linear(in_features=8, out_features=3, bias=True)
)
重点说明
- 层的顺序很重要
- 数据会严格按顺序流动
- 先线性变换再激活函数是常用顺序
- 输入输出形状必须匹配
- 前一层的输出维度 = 下一层输入维度
- 例如上例中,第一层输出 8 → 第二层输入 8
前向传播测试
# 构造一个输入
x = torch.randn(2, 4) # batch_size=2, 输入维度=4# 前向传播
y = model(x)print("输入 x:\n", x)
print("输出 y:\n", y)
x是随机生成的 2x4 张量(2 个样本,每个样本 4 维)y是 2x3 张量,代表 2 个样本经过网络后的输出
2. 自定义模型(继承 nn.Module)
原理:为什么要自定义模型
nn.Sequential 虽然简洁,但只能处理顺序结构。对于复杂网络(分支、残差、跳跃连接、多输入多输出等),就必须自定义模型。
自定义模型核心在于:
- 定义网络层(
__init__)- 初始化每一层,定义模型的参数
- 定义前向传播逻辑(
forward)- 指定数据如何从输入流向输出
- 可以写任意逻辑:顺序、分支、循环等
模型结构
自定义模型一般继承 nn.Module:
import torch
import torch.nn as nnclass MyMLP(nn.Module):def __init__(self, input_dim, hidden1, hidden2, output_dim):super().__init__() # 初始化父类# 定义网络层self.fc1 = nn.Linear(input_dim, hidden1)self.relu1 = nn.ReLU()self.fc2 = nn.Linear(hidden1, hidden2)self.relu2 = nn.ReLU()self.fc3 = nn.Linear(hidden2, output_dim)def forward(self, x):# 定义前向传播逻辑x = self.fc1(x)x = self.relu1(x)x = self.fc2(x)x = self.relu2(x)x = self.fc3(x)return x
重点说明
-
super().__init__()- 初始化父类
nn.Module,让模型可以正确管理参数 - 如果不写,会出现无法调用
model.parameters()或model.to(device)等问题
- 初始化父类
-
__init__与forward__init__:只做“层的定义”,不做数据计算forward:真正做前向计算,把输入x流经各层得到输出
-
灵活性
-
forward可以写任何复杂逻辑,比如:out1 = self.fc1(x) out2 = self.fc2(x) x = out1 + out2 # 分支+残差
-
前向传播测试
# 实例化模型
model = MyMLP(input_dim=5, hidden1=10, hidden2=6, output_dim=2)# 构造输入
x = torch.randn(4, 5) # batch_size=4, 输入维度=5# 前向传播
output = model(x)
print(output.shape)
输出:
torch.Size([4, 2])
与 nn.Sequential 的区别:
- 可以随意修改
forward逻辑 - 可以实现复杂结构
3. 模型参数管理
参数初始化
PyTorch 在创建层时会自动初始化权重和偏置,但有时我们需要自己设定。
使用 torch.nn.init 模块可以手动初始化参数:
import torch.nn as nn
import torch.nn.init as initlayer = nn.Linear(5, 10)# Xavier 初始化(常用于全连接层)
init.xavier_uniform_(layer.weight)# He 初始化(常用于 ReLU 激活)
init.kaiming_normal_(layer.weight, nonlinearity='relu')# 偏置初始化为 0
init.zeros_(layer.bias)
✅ 常见初始化方法:
- Xavier (Glorot) 初始化:保证输入输出方差相近,适合 Sigmoid / Tanh
- He 初始化:适合 ReLU 激活
- 均匀分布 / 正态分布:一般基础初始化
保存模型
PyTorch 提供 torch.save 保存模型或参数。
(1)保存整个模型
torch.save(model, "model.pth")
- 会保存模型结构 + 参数
- 加载时不用重新定义类
- 缺点:依赖于保存时的类定义,跨版本可能不兼容
(2)保存模型参数(推荐)
torch.save(model.state_dict(), "model_state.pth")
- 只保存权重参数(字典格式)
- 加载时需要先定义模型结构,再加载参数
- 更加灵活、安全、通用(官方推荐)
加载模型
(1)加载整个模型
model = torch.load("model.pth")
- 一步到位,直接得到训练好的模型
- 但跨版本/跨环境可能报错
(2)加载参数(推荐)
model = MyModel(*args) # 先定义模型结构
model.load_state_dict(torch.load("model_state.pth"))
- 更通用,避免兼容性问题
- 可以部分加载(比如只加载 backbone 的参数)
练习:
- 定义一个小模型(MLP)
- 手动初始化参数(用 Xavier 或 He)
- 保存模型参数到文件
- 删除模型后重新实例化并加载参数
- 验证加载前后模型输出是否一致
# 定义一个小模型(MLP)
#
# 手动初始化参数(用 Xavier 或 He)
#
# 保存模型参数到文件
#
# 删除模型后重新实例化并加载参数
#
# 验证加载前后模型输出是否一致
import torch
import torch.nn as nn
import torch.nn.init as initclass MLP(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(MLP, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, output_dim)self.relu = nn.ReLU()self.init_weights()def init_weights(self):init.xavier_normal_(self.fc1.weight)init.xavier_normal_(self.fc2.weight)init.zeros_(self.fc1.bias)init.zeros_(self.fc2.bias)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return xmodel = MLP(input_dim=10, hidden_dim=20, output_dim=5)
x = torch.randn(4, 10)
output_before = model(x)
print("加载前输出:\n", output_before)torch.save(model.state_dict(), "model_state.pth")
print("✅ 参数已保存到 model_state.pth")new_model = MLP(input_dim=10, hidden_dim=20, output_dim=5)
new_model.load_state_dict(torch.load("model_state.pth"))output_after = new_model(x)
print("加载后输出:\n", output_after)print("前后输出是否一致:", torch.allclose(output_before, output_after))4. 推理与评估
推理(Inference)模式
在训练好模型后,我们要在测试集/验证集上进行推理预测。
关键点:
-
切换到推理模式
model.eval()- Dropout 层 → 不再随机丢弃
- BatchNorm → 使用固定均值和方差
-
关闭梯度计算
with torch.no_grad():y_pred = model(x)- 不计算梯度,节省内存
- 推理速度更快
模型评估指标
📌 分类任务常用指标
- 准确率(Accuracy):预测对的样本数 / 总样本数
- 精确率(Precision):预测为正的样本中,真正为正的比例
- 召回率(Recall):所有正样本中,预测对的比例
- F1-score:Precision 和 Recall 的调和平均
准确率 (Accuracy)

acc = (y_pred.argmax(dim=1) == y).float().mean().item()
精确率 (Precision)
在预测为正的样本中,真正为正的比例。
from sklearn.metrics import precision_score
precision = precision_score(y_true, y_pred_cls)
召回率 (Recall)
所有真正的正样本中,被预测为正的比例。
from sklearn.metrics import recall_score
recall = recall_score(y_true, y_pred_cls)
F1-score
Precision 和 Recall 的调和平均。
from sklearn.metrics import f1_score
f1 = f1_score(y_true, y_pred_cls)
📌 回归任务常用指标
-
MSE(均方误差)
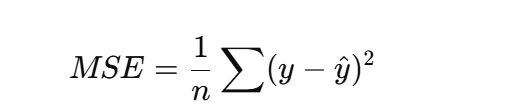
mse = torch.mean((y_pred - y) ** 2).item() -
MAE(平均绝对误差)
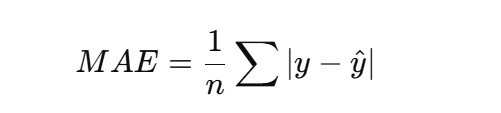
mae = torch.mean(torch.abs(y_pred - y)).item() -
R²(拟合优度)
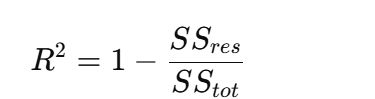
ss_res = torch.sum((y - y_pred) ** 2) ss_tot = torch.sum((y - torch.mean(y)) ** 2) r2 = 1 - ss_res / ss_tot分类 vs 回归对比表
任务类型 常用损失函数 推理输出处理 评估指标 分类 CrossEntropyLossargmax(dim=1)取类别Accuracy, Precision, Recall, F1 回归 MSELoss,L1Loss直接输出连续值 MSE, MAE, R²
5.实战流程总结
- 训练阶段
model.train()- 正常计算梯度,更新参数
- 推理阶段
model.eval()with torch.no_grad()- 计算预测结果
- 评估
- 分类:Accuracy, Precision, Recall, F1
- 回归:MSE, MAE, R²
一个完整的 训练 → 保存模型 → 加载 → 推理与评估 流程:
# 1. 训练完成后保存参数
torch.save(model.state_dict(), "model_state.pth")# 2. 加载模型
model = MyModel(...)
model.load_state_dict(torch.load("model_state.pth"))# 3. 切换到推理模式
model.eval()# 4. 在验证集/测试集推理
with torch.no_grad():y_pred = model(x_val)# 5. 计算指标 (以分类任务的准确率为例)
acc = (y_pred.argmax(1) == y_val).float().mean().item()
print("验证集准确率:", acc)
分类任务小 Demo(训练 + 推理 + 评估)我们用随机数据模拟一个二分类问题,流程和真实任务完全一样。
PyTorch 分类任务 Demo
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.metrics import precision_score, recall_score, f1_score# 1. 构造数据(100个样本,特征维度=10,标签=0或1)
X = torch.randn(100, 10)
y = torch.randint(0, 2, (100,)) # 标签 (0/1)# 划分训练集 / 测试集
X_train, X_test = X[:80], X[80:]
y_train, y_test = y[:80], y[80:]# 2. 定义模型(MLP)
class MLP(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(MLP, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return xmodel = MLP(input_dim=10, hidden_dim=32, output_dim=2)# 3. 定义损失和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失(分类)
optimizer = optim.Adam(model.parameters(), lr=0.01)# 4. 训练模型
for epoch in range(20):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch+1) % 5 == 0:print(f"Epoch [{epoch+1}/20], Loss: {loss.item():.4f}")# 5. 推理(测试集)
model.eval()
with torch.no_grad():outputs = model(X_test)y_pred = outputs.argmax(dim=1)# 6. 评估指标
accuracy = (y_pred == y_test).float().mean().item()
precision = precision_score(y_test.numpy(), y_pred.numpy())
recall = recall_score(y_test.numpy(), y_pred.numpy())
f1 = f1_score(y_test.numpy(), y_pred.numpy())print("\n📊 模型评估结果:")
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1-score: {f1:.4f}")
学到的知识点
- 训练阶段
model.train():打开 dropout / BN 更新loss.backward()+optimizer.step():参数更新
- 推理阶段
model.eval():关闭 dropout/BNtorch.no_grad():不追踪梯度,加速+省内存
- 评估指标
Accuracy→ 整体正确率Precision/Recall/F1→ 适合不平衡数据
回归任务小 Demo,和前面分类的流程对比学习。我们做一个简单的一元线性回归:
PyTorch 回归任务 Demo
import torch
import torch.nn as nn
import torch.optim as optim# 1. 构造数据 (y = 2x + 3 + 噪声)
torch.manual_seed(42)
X = torch.linspace(-5, 5, 100).unsqueeze(1) # shape (100,1)
y = 2 * X + 3 + torch.randn(100, 1) * 0.5# 划分训练集 / 测试集
X_train, X_test = X[:80], X[80:]
y_train, y_test = y[:80], y[80:]# 2. 定义模型(简单 MLP 回归)
class Regressor(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(Regressor, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, x):return self.fc2(self.relu(self.fc1(x)))model = Regressor(input_dim=1, hidden_dim=16, output_dim=1)# 3. 定义损失和优化器
criterion = nn.MSELoss() # 均方误差
optimizer = optim.Adam(model.parameters(), lr=0.01)# 4. 训练模型
for epoch in range(100):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch+1) % 20 == 0:print(f"Epoch [{epoch+1}/100], Loss: {loss.item():.4f}")# 5. 推理
model.eval()
with torch.no_grad():y_pred = model(X_test)# 6. 评估指标
mse = torch.mean((y_pred - y_test) ** 2).item()
mae = torch.mean(torch.abs(y_pred - y_test)).item()
ss_res = torch.sum((y_test - y_pred) ** 2)
ss_tot = torch.sum((y_test - torch.mean(y_test)) ** 2)
r2 = 1 - ss_res / ss_totprint("\n📊 模型评估结果:")
print(f"MSE: {mse:.4f}")
print(f"MAE: {mae:.4f}")
print(f"R² : {r2:.4f}")
学到的知识点
- 训练和分类一样 → 只是损失函数换成了
MSELoss()。 - 推理时一样用
model.eval()torch.no_grad()
- 回归评估指标
- MSE:均方误差,惩罚大偏差
- MAE:平均绝对误差,更直观
- R²:拟合优度,越接近 1 越好
七、训练技巧与提升
1️⃣ 优化器与学习率调度器
1.1 优化器原理
优化器的作用是根据梯度更新模型参数,使损失函数下降。不同优化器适合不同场景。
-
SGD(随机梯度下降)
-
原理:沿梯度方向更新权重:
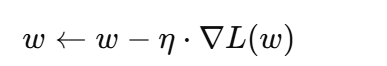
η 是学习率,∇L(w) 是梯度。
-
问题:容易在鞍点或局部极小值附近震荡,收敛慢。
-
Momentum(动量):
引入惯性: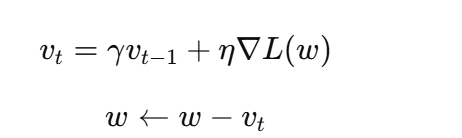
可以跨过鞍点,减少震荡。
-
-
Adam
-
结合 Momentum 和 RMSprop 思想:
-
m_t = 一阶矩估计(动量)
-
v_t = 二阶矩估计(梯度平方的滑动平均)
-
参数更新公式:
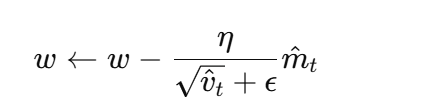
-
-
优点:自适应学习率,适合稀疏梯度,收敛快。
-
AdamW:把权重衰减(weight decay)从梯度更新中独立出来,更适合 Transformer。
-
-
RMSprop
-
对每个参数自适应调整学习率:
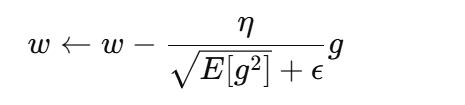
-
适合循环神经网络。
-
1.2 PyTorch 实现
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
optimizer = torch.optim.RMSprop(model.parameters(), lr=1e-3, alpha=0.9)
1.3 学习率调度器原理
学习率调度器可以动态调整 lr,提高训练稳定性和效果。
-
StepLR
-
每隔固定 epoch 降低 lr:
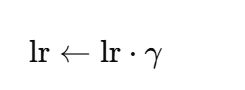
-
-
MultiStepLR
- 在指定 epoch 降低 lr。
-
ExponentialLR
-
lr 指数衰减:
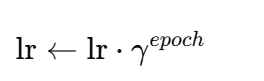
-
-
CosineAnnealingLR
-
lr 随余弦变化衰减:
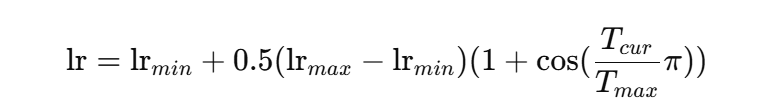
-
-
自定义调度(warmup + cosine)
- 先线性升高 lr(warmup) → 再余弦衰减,适合训练大模型。
PyTorch 示例
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)
2️⃣ 正则化与泛化
2.1 权重衰减 (Weight Decay)
-
原理:在损失函数上加 L2 正则项:
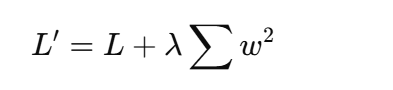
-
作用:防止权重过大,减少过拟合。
2.2 Dropout
- 原理:训练时随机屏蔽部分神经元,使网络不依赖特定路径。
- 作用:增加模型鲁棒性,提高泛化能力。
self.dropout = nn.Dropout(p=0.5)
x = self.dropout(x)
2.3 BatchNorm / LayerNorm
-
BatchNorm:对每一层输出做归一化:
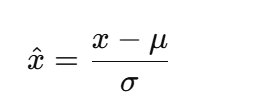
- 加速收敛,缓解梯度消失。
-
LayerNorm:对每个样本的特征维度归一化,常用于 Transformer。
2.4 数据增强
- 图像:旋转、裁剪、翻转、颜色扰动
- 文本:同义词替换、随机删除
- 表格:噪声注入、过采样/欠采样
transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomCrop(32, padding=4),transforms.ToTensor()
])
3️⃣ 训练过程监控
3.1 Loss / Accuracy 曲线
- 实时观察训练状态,判断过拟合/欠拟合。
- TensorBoard 可视化:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/val", acc, epoch)
3.2 分析训练问题
- 过拟合:训练 loss 很低,验证 loss 高 → 加强正则化
- 欠拟合:训练 loss 高 → 提高模型容量 / 训练时间
4️⃣ 训练流程封装
4.1 训练/验证步骤
def train_step(model, dataloader, optimizer, criterion, device):model.train()total_loss, total_correct = 0, 0for xb, yb in dataloader:xb, yb = xb.to(device), yb.to(device)optimizer.zero_grad()logits = model(xb)loss = criterion(logits, yb)loss.backward()optimizer.step()total_loss += loss.item() * xb.size(0)total_correct += (logits.argmax(1) == yb).sum().item()return total_loss / len(dataloader.dataset), total_correct / len(dataloader.dataset)def validate_step(model, dataloader, criterion, device):model.eval()total_loss, total_correct = 0, 0with torch.no_grad():for xb, yb in dataloader:xb, yb = xb.to(device), yb.to(device)logits = model(xb)loss = criterion(logits, yb)total_loss += loss.item() * xb.size(0)total_correct += (logits.argmax(1) == yb).sum().item()return total_loss / len(dataloader.dataset), total_correct / len(dataloader.dataset)
4.2 EarlyStopping
- 当验证集不再提升时提前停止训练。
5️⃣ 实战练习
5.1 训练目标
- 使用 MNIST / CIFAR-10
- 尝试不同优化器、学习率调度
- 加入 Dropout / BatchNorm / weight decay
- 可视化 loss / acc 曲线
5.2 训练效果分析
- 对比优化器和正则化方法对模型收敛和泛化的影响
- 诊断过拟合/欠拟合
- 学会调参
💡 总结:
- 优化器和 lr 调度器 → 提升收敛速度和稳定性
- 正则化 → 防止过拟合,提高泛化
- 训练监控 → 实时判断训练状况
- 封装训练循环 → 提升开发效率
- 实战 → 理论落地
完整 PyTorch 训练模板:
- CNN 网络(适合 MNIST / CIFAR-10)
- 多种优化器选择(SGD+momentum、Adam、AdamW、RMSprop)
- 学习率调度器(StepLR、CosineAnnealingLR 可切换)
- 正则化(Dropout、BatchNorm、Weight Decay)
- 训练/验证循环封装 + EarlyStopping
- TensorBoard 可视化 loss/accuracy
Python 代码框架,可以直接运行并修改参数练习:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import os# ----------------------------
# 1. 配置训练参数
# ----------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 50
batch_size = 128
learning_rate = 1e-3
weight_decay = 1e-4 # L2 正则化
dropout_prob = 0.5
optimizer_type = 'AdamW' # 可选: SGD, Adam, AdamW, RMSprop
scheduler_type = 'Cosine' # 可选: Step, Cosine# ----------------------------
# 2. 数据准备(CIFAR-10 示例)
# ----------------------------
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),
])
transform_test = transforms.ToTensor()train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# ----------------------------
# 3. 定义 CNN 模型
# ----------------------------
class CNNModel(nn.Module):def __init__(self, dropout_prob=0.5):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(64*16*16, 256)self.dropout = nn.Dropout(dropout_prob)self.fc2 = nn.Linear(256, 10)self.relu = nn.ReLU()def forward(self, x):x = self.relu(self.bn1(self.conv1(x)))x = self.pool(self.relu(self.bn2(self.conv2(x))))x = x.view(x.size(0), -1)x = self.dropout(self.relu(self.fc1(x)))x = self.fc2(x)return xmodel = CNNModel(dropout_prob=dropout_prob).to(device)# ----------------------------
# 4. 优化器 & 调度器
# ----------------------------
if optimizer_type == 'SGD':optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=weight_decay)
elif optimizer_type == 'Adam':optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
elif optimizer_type == 'AdamW':optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
elif optimizer_type == 'RMSprop':optimizer = optim.RMSprop(model.parameters(), lr=learning_rate, alpha=0.9, weight_decay=weight_decay)if scheduler_type == 'Step':scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
elif scheduler_type == 'Cosine':scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)# ----------------------------
# 5. 损失函数
# ----------------------------
criterion = nn.CrossEntropyLoss()# ----------------------------
# 6. TensorBoard 初始化
# ----------------------------
writer = SummaryWriter(log_dir="runs/CIFAR10_experiment")# ----------------------------
# 7. EarlyStopping 设置
# ----------------------------
class EarlyStopping:def __init__(self, patience=5, verbose=True):self.patience = patienceself.verbose = verboseself.best_loss = float('inf')self.counter = 0self.early_stop = Falseself.best_model = Nonedef step(self, val_loss, model):if val_loss < self.best_loss:self.best_loss = val_lossself.counter = 0self.best_model = model.state_dict()else:self.counter += 1if self.counter >= self.patience:if self.verbose:print(f"Early stopping triggered. Best val_loss: {self.best_loss:.4f}")self.early_stop = Trueearly_stopping = EarlyStopping(patience=7)# ----------------------------
# 8. 训练 & 验证循环
# ----------------------------
for epoch in range(num_epochs):# --- 训练 ---model.train()train_loss, train_correct = 0, 0for xb, yb in train_loader:xb, yb = xb.to(device), yb.to(device)optimizer.zero_grad()logits = model(xb)loss = criterion(logits, yb)loss.backward()optimizer.step()train_loss += loss.item() * xb.size(0)train_correct += (logits.argmax(1) == yb).sum().item()train_loss /= len(train_loader.dataset)train_acc = train_correct / len(train_loader.dataset)# --- 验证 ---model.eval()val_loss, val_correct = 0, 0with torch.no_grad():for xb, yb in test_loader:xb, yb = xb.to(device), yb.to(device)logits = model(xb)loss = criterion(logits, yb)val_loss += loss.item() * xb.size(0)val_correct += (logits.argmax(1) == yb).sum().item()val_loss /= len(test_loader.dataset)val_acc = val_correct / len(test_loader.dataset)# --- 调度器 ---scheduler.step()# --- TensorBoard 记录 ---writer.add_scalar("Loss/train", train_loss, epoch)writer.add_scalar("Loss/val", val_loss, epoch)writer.add_scalar("Accuracy/train", train_acc, epoch)writer.add_scalar("Accuracy/val", val_acc, epoch)# --- 输出 ---print(f"Epoch [{epoch+1}/{num_epochs}] Train Loss: {train_loss:.4f} Acc: {train_acc:.4f} | Val Loss: {val_loss:.4f} Acc: {val_acc:.4f}")# --- EarlyStopping ---early_stopping.step(val_loss, model)if early_stopping.early_stop:model.load_state_dict(early_stopping.best_model)break# ----------------------------
# 9. 保存模型
# ----------------------------
os.makedirs("checkpoints", exist_ok=True)
torch.save(model.state_dict(), "checkpoints/best_model.pth")
writer.close()
✅ 模板特点:
- 支持多种优化器和学习率调度器切换
- 包含 Dropout + BatchNorm + Weight Decay
- 自动训练/验证循环 + EarlyStopping
- TensorBoard 可视化训练曲线
- 结构清晰,便于修改练习不同超参数