Jetson Xavier NX踩坑
文章目录
- 安装中文输入法
- 查看板子配置
- 换源
- 查看jetpack版本
- 安装miniconda
- 通过pytorch部署qwen2.5-0.5B
- 通过llama.cpp部署
安装中文输入法
我拿到的Jetson Xavier NX板子上面没有输入法,第一步先把输入法给装上。
第一步:安装fcitx输入法和中文拼音输入法
sudo apt update
sudo apt install -y fcitx fcitx-pinyin fcitx-modules fcitx-config-gtk
- fcitx:输入法框架
- fcitx-pinyin:拼音输入引擎
- fcitx-config-gtk:图形化配置工具
第二步:配置环境变量
编辑用户环境变量文件:
gedit ~/.pam_environment
添加下面内容
GTK_IM_MODULE=fcitx
QT_IM_MODULE=fcitx
XMODIFIERS=@im=fcitx
第三步:重新启动
reboot
第四步:启动Fcitx并添加拼音输入法
按空格+ctrl尝试激活输入法,如果没反应手动启动fcitx
fcitx
在右上角的fcitx图标中找到configure,并添加Pinyin
使用:ctrl+空格切换中英文,ctrl+shift切换输入法
查看板子配置
查看系统基本信息
cat /etc/lsb-release
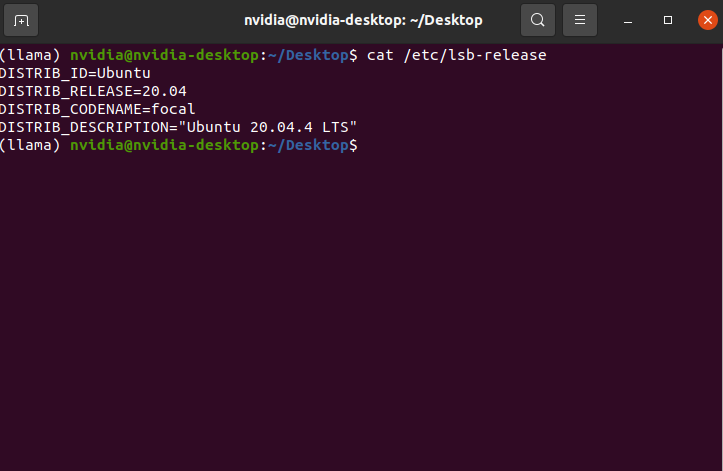
| 项目 | 值 |
|---|---|
| 操作系统 | Ubuntu 20.04.4 LTS (Focal Fossa) |
| 底层系统 | Linux for Tegra (L4T) 的 Ubuntu 20.04 版本 |
| 内核类型 | 定制版 NVIDIA 内核(基于 Linux 5.10 或更高) |
| 支持状态 | 官方支持(适用于 JetPack 5.x 或更高版本) |
查看内核相关信息
uname -a
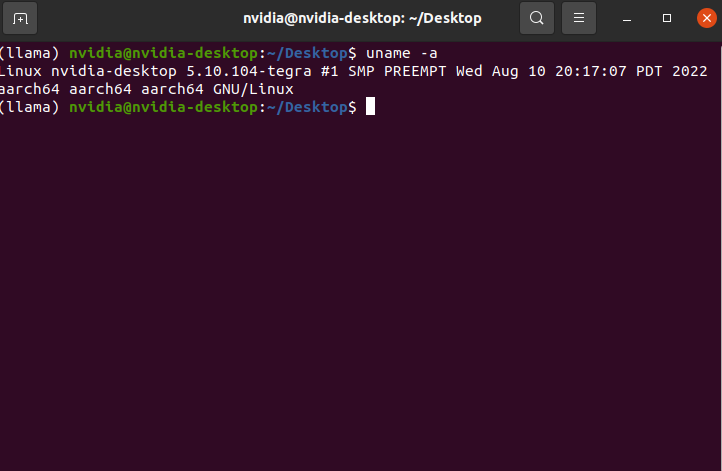
| 项目 | 值 | 说明 |
|---|---|---|
| 主机名 | nvidia-desktop | 默认开发板主机名,可自定义 |
| 内核版本 | 5.10.104-tegra | NVIDIA 定制内核,基于 Linux 5.10 |
| 架构 | aarch64 | 64 位 ARM 架构(即 arm64),正确匹配 Jetson 平台 |
| SMP | 是 | 支持多核并行(Jetson NX 有 6 核 Carmel CPU) |
| PREEMPT | 是 | 内核支持抢占,适合实时任务(如机器人控制) |
| 操作系统 | Ubuntu 20.04.4 LTS | 如前所述,基于 L4T 的 Focal 系统 |
| 编译时间 | 2022年8月10日 | 表明这是一个较早发布的 JetPack 5.0 版本 |
查看cpu信息
lscpu
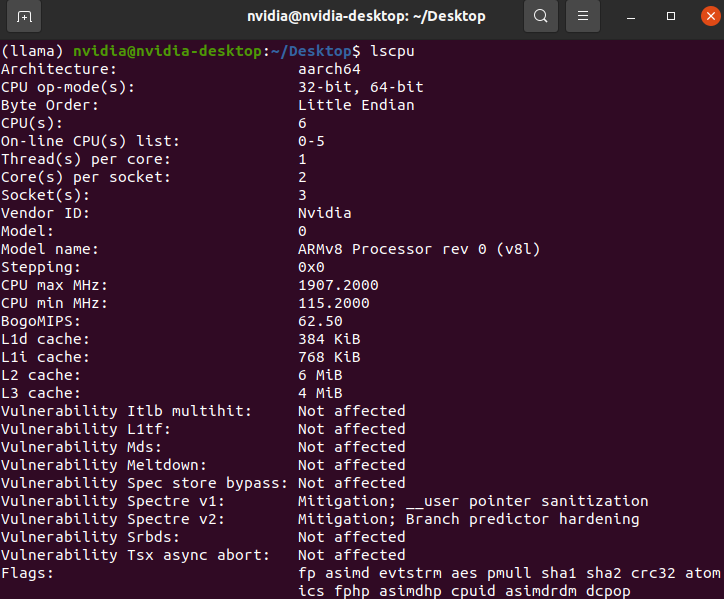
关键信息
| 项目 | 值 | 说明 |
|---|---|---|
| 架构 (Architecture) | aarch64 64位 ARM 架构(即 ARM64) | |
| CPU 核心数 (CPU(s)) | 6 | 共有 6 个逻辑 CPU 核心 |
| 线程/核 (Thread(s) per core) | 1 | 不支持超线程(SMT),每核单线程 |
| 核心/插槽 (Core(s) per socket) | 2 | 每个“插槽”有 2 个核心 |
| 插槽数 (Socket(s)) | 3 | 总共 3 个“插槽” → 3×2 = 6 核 |
| CPU 型号 | ARMv8 Processor rev 0 (v8l) | NVIDIA Carmel 架构处理器 |
| 最大频率 | 1907.2 MHz ≈ 1.91 GHz | 最高运行频率 |
| 最小频率 | 115.2 MHz | 节能时可降频至极低功耗 |
查看内存相关信息
free -h
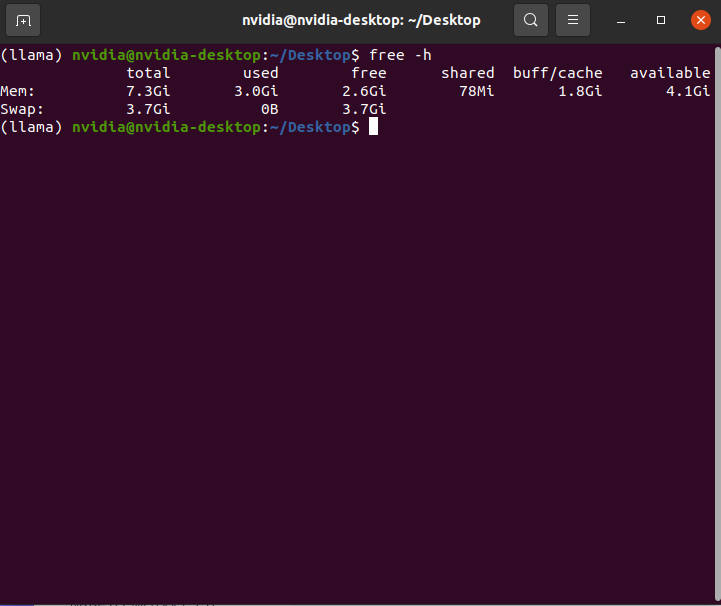
| 字段 | 含义 |
|---|---|
| total | 总内存大小(物理或 swap) |
| used | 已使用的内存(不包含 buff/cache) |
| free | 完全未被使用的内存(真正“空闲”) |
| shared | 被多个进程共享的内存(如 tmpfs、CUDA 共享内存) |
| buff/cache | 用于文件缓存和块设备缓冲的内存(可回收) |
| available | 最关键的指标! 估算的可用于启动新程序的内存(包含可回收的 cache) |
查看文件系统
df -h
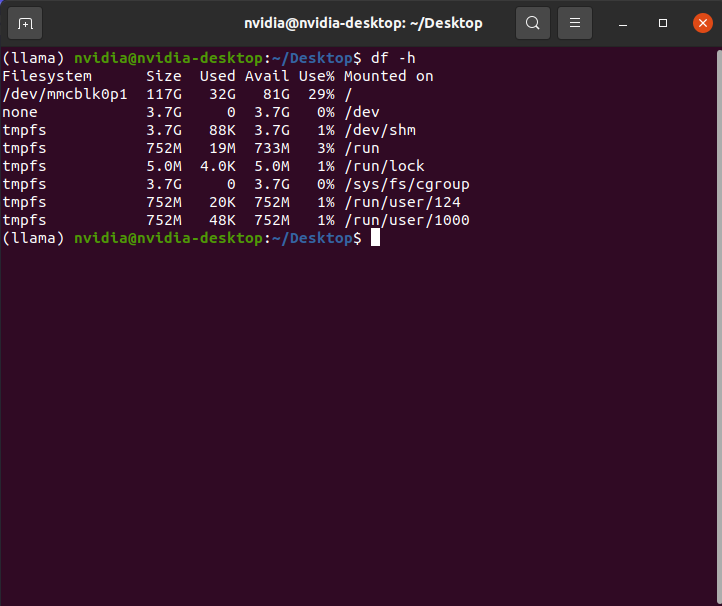
最重要的就是根文件分区
| 字段 | 值 | 含义 |
|---|---|---|
| Filesystem | /dev/mmcblk0p1 | 存储设备:eMMC 或 microSD 卡的第一个主分 |
| Size | 117G | 总容量:约 117 GB |
| Used | 32G | 已使用空间:32GB(包含系统、软件、日志等) |
| Avail | 81G | 可用空间:81GB |
| Use% | 29% | 使用率较低,状态健康 ✅ |
| Mounted on | / | 挂载为根目录(即系统的主目录) |
换源
看完了内存的信息,为了方便后面下载速度快一点,我们对ubuntu进行换源。
这里使用的是ubuntu系统,所以需要对apt(advanced package tool,高级包工具)的软件源配置文件进行相关的修改。
apt软件源配置文件在/etc/apt目录下,一般系统软件源配置文件在source.list中,同时/etc/apt目录下还会有一个source.list.d目录,这个目录是第三方如docker、vscode、nvidia设置的软件源
| 项目 | /etc/apt/sources.list | /etc/apt/sources.list.d/ |
|---|---|---|
| 类型 | 单个主配置文件 | 一个目录(文件夹) |
| 作用 | 系统默认的主软件源列表 | 第三方或额外软件源的存放目录 |
| 管理方式 | 手动编辑或系统工具修改 | 每个软件源单独成文件 |
| 典型内容 | Ubuntu 官方源、安全更新源 | Docker、Google、VS Code、NVIDIA 等第三方源 |
| 优先级 | 高(先读取) | 低(后读取,可覆盖) |
注意如果这里要换源只能换为华为云的源,因为阿里云、清华、中科大的都是x86_64架构的镜像源,只有华为云是完整支持arm64架构ubuntu的镜像站
首先需要备份一份原来的文件
sudo cp /ect/apt/souces.list /etc/apt/sources.list.bak
然后将下面的内容写进/ect/apt/souces.list文件
deb http://mirrors.huaweicloud.com/ubuntu-ports focal main universe multiverse restricted
deb http://mirrors.huaweicloud.com/ubuntu-ports focal-security main universe multiverse restricted
deb http://mirrors.huaweicloud.com/ubuntu-ports focal-updates main universe multiverse restricted
deb http://mirrors.huaweicloud.com/ubuntu-ports focal-backports main universe multiverse restricted
然后需要更新一下本地软件包列表
sudo apt update
更多换源有关内容可以看这个链接换源
查看jetpack版本
jetpack是一个系统级SDK套件,是通过刷机的方式将整个linux系统(L4T)和配套的AI加速库(CUDA、cuDNN、TensoRT)。
一般Jetpack版本和L4T版本是对应的,可以通过查看L4T版本来查看Jetpack版本。
cat /etc/nv_tegra_release
R35 (release), REVISION: 1.0, GCID: 31250864, BOARD: t186ref, EABI: aarch64, DATE: Thu Aug 11 03:40:29 UTC 2022
R35.1.0对应的jetpack版本JetPack5.0.2,可以问ai,下面是对应的AI加速库。
| 组件 | 版本 |
|---|---|
| CUDA | 11.4 |
| cuDNN | 8.4.1 |
| TensorRT | 8.4.1 |
| OpenCV | 4.5.4(带 CUDA 加速) |
| VisionWorks | 1.6(已逐步弃用) |
| DeepStream | 6.1 |
| Linux Kernel | 5.10 |
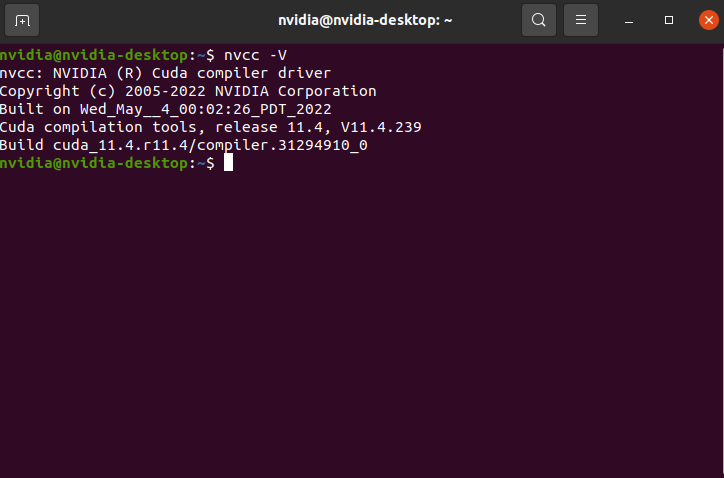
检查cuda环境变量是否配置
nvcc --version
如果是下面结果,则说明没有配置好需要重新配置
bash: nvcc: command not found
配置cuda环境变量,在.bashrc中加入下面内容
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PAT
export CUDA_ROOT=/usr/local/cuda
/usr/local文件下关于cuda的目录应该不止有一个,可以看到下图中关于cuda的,目录有三个,实际上只有cuda-11.4是实际cuda文件,另外两个都是cuda-11.4的链接,上面配置路径的时候推荐使用链接而不是实际cuda位置,因为cuda可能有多个,以后可以通过修改链接来更换不同的cuda。
添加后重新执行一下bashrc
source .bashrc
再次验证环境变量是否配置成功,显示下图内容说明cuda环境变量配置成功。
nvcc -V
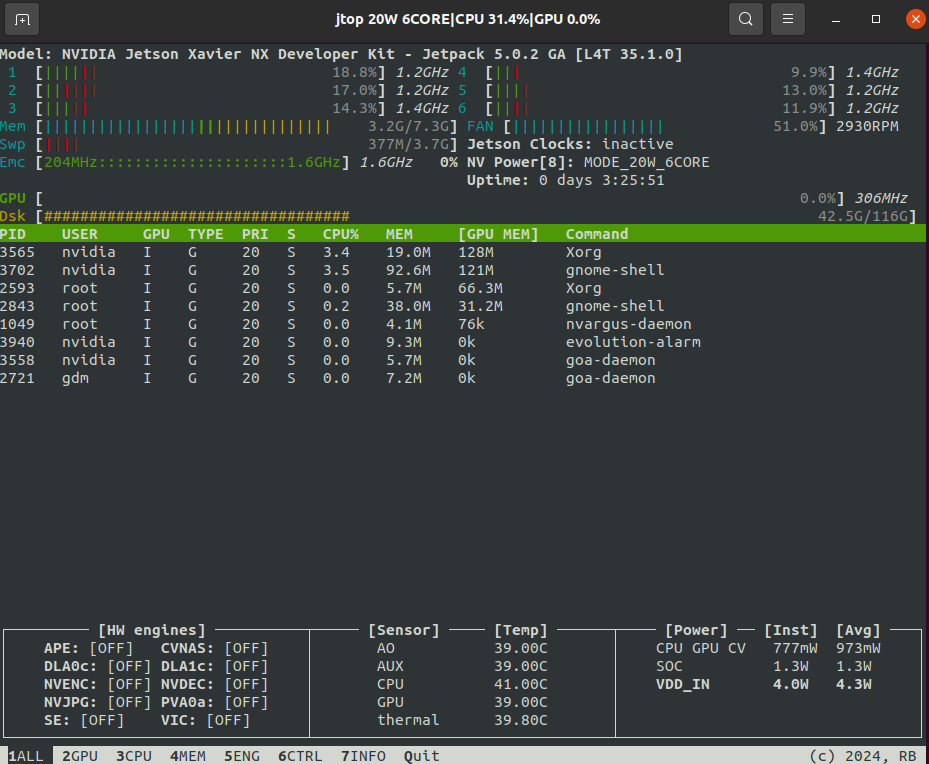
查看jetson的资源利用情况需要安装一个jtop:
pip install jetson-stats
使用直接输入
jtop
会显示:
CPU利用率、频率
GPU利用率、频率
RAM/swap使用量
EMC内存带宽
温度
功耗等一些其他内容
安装miniconda
下载安装miniconda的脚本
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-aarch64.sh
执行安装脚本
bash Miniconda3-latest-Linux-aarch64.sh
安装conda的过程中会看到如下信息:
Do you wish to update your shell profile to automatically initialize conda?
This will activate conda on startup and change the command prompt when activated.
If you'd prefer that conda's base environment not be activated on startup,run the following command when conda is activated:conda config --set auto_activate_base falseYou can undo this by running `conda init --reverse $SHELL`? [yes|no]
这段内容主要是是都将conda集成到shell中,如果选择yes,conda会在每次打开终端时自动寄过base环境,如果选择no,则conda不会自动加载,需要收到运行conda activate
如果选择yes,运行:
conda init
.bashrc中的文件会被修改,会添加一段初始化脚本,效果就是每次打开终端conda会被自动加载,同时conda命令可用,默认会进入base环境。
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/nvidia/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; theneval "$__conda_setup"
elseif [ -f "/home/nvidia/miniconda3/etc/profile.d/conda.sh" ]; then. "/home/nvidia/miniconda3/etc/profile.d/conda.sh"elseexport PATH="/home/nvidia/miniconda3/bin:$PATH"fi
fi
unset __conda_setup
# <<< conda initialize <<<
通过pytorch部署qwen2.5-0.5B
失败,Jetson上面提供的pytorch是阉割版的,尽管下载完模型后进行推理的时候依然会看不懂的错误,总之很麻烦。
首先需要安装pytorch,不能直接在终端pip install torch,这种下载的是x86版本的pytorch,我们需要的是arm版本的。
需要查询自己的jetpack版本对应的pytorch版本。
这里我的板子的jetpack是5.1.0版本的,对应的是下面这些版本。jetson版本pytorch下载链接

下载对应的whl文件后,在whl文件的目录下进行安装
pip install torch-1.13.0a0+08820cb0.nv22.07-cp38-cp38-linux_aarch64.whl
可以查看是否安装成功,打开python,然后import一下,同时查看一下cuda是否能用。如下图所示即为可用。
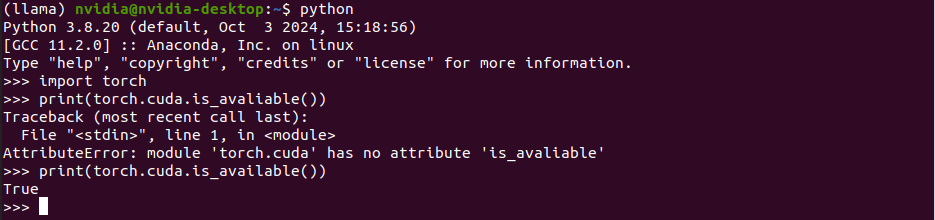
下面是安装transformers,直接pip即可(因为transformers库是纯python编写的库没有C/C++扩展),注意这里qwen2的tokenizer对transformers的版本有要求。
pip install transformers
安装后需要用huggingface的镜像网站下载模型(因为有墙)
huggingface使用镜像网站下载模型。
在终端中使用
# Linux/macOS
export HF_ENDPOINT=https://hf-mirror.com
然后运行下面脚本即可。
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B")
messages = [{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_dict=True,return_tensors="pt",
).to(model.device)outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
如果运行上面的脚本报错
Traceback (most recent call last):File "qwen2.5.py", line 17, in <module>outputs = model.generate(**inputs, max_new_tokens=40)File "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_contextreturn func(*args, **kwargs)File "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/transformers/generation/utils.py", line 1977, in generatesynced_gpus = (is_deepspeed_zero3_enabled() or is_fsdp_managed_module(self)) and dist.get_world_size() > 1File "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/transformers/integrations/fsdp.py", line 29, in is_fsdp_managed_moduleimport torch.distributed.fsdpFile "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/fsdp/__init__.py", line 1, in <module>from .flat_param import FlatParameterFile "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/fsdp/flat_param.py", line 32, in <module>from ._fsdp_extensions import _ext_post_unflatten_transform, _ext_pre_flatten_transformFile "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/fsdp/_fsdp_extensions.py", line 6, in <module>from torch.distributed._shard.sharded_tensor.api import ShardedTensorFile "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/_shard/__init__.py", line 1, in <module>from .api import (File "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/_shard/api.py", line 5, in <module>from torch.distributed import distributed_c10dFile "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 16, in <module>from torch._C._distributed_c10d import (
ModuleNotFoundError: No module named 'torch._C._distributed_c10d'; 'torch._C' is not a package
可以找到上面报错地方 File "/home/nvidia/miniconda3/envs/llama/lib/python3.8/site-packages/transformers/generation/utils.py,把对应的内容 synced_gpus = (is_deepspeed_zero3_enabled() or is_fsdp_managed_module(self)) and dist.get_world_size() > 1注释掉就行了。
然后就可以得到运行结果了。
通过llama.cpp部署
需要先在一台电脑上将pytorch保存的模型通过llama.cpp的脚本转换成其需要的模型格式。
首先需要下载llama.cpp,并进行编译,最好不要在jetson上进行模型格式转换因为jetson板子一般算力不是很大,这个过程会很慢,可以现在其他机器上进行转换然后在把对应生成的模型文件传到jetson板子上面。
下吧llama.cpp git到本地
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
然后编译
cmake -B build -DGGML_CUDA=ON # 在 build 目錄下產生編譯檔案
cmake --build build --parallel # 平行編譯,榨乾該機器上的所有 CPU 資源
如果用apt安装cmak大概率会得到比较旧的cmake版本,导致编译失败,这时可以安装新版的cmake,具体操作如下:
下载下来cmake的安装脚本
wget https://github.com/Kitware/CMake/releases/download/v3.23.0/cmake-3.23.0-linux-x86_64.sh
然后执行这个脚本.
sudo bash ./cmake-3.23.0-linux-x86_64.sh --skip-licence --prefix=/usr# 安装过程中遇到:
# 选择1
Do you accept the license? [yn]:
# 输入 y# 选择2
By default the CMake will be installed in:"/usr/cmake-3.23.0-linux-x86_64"
Do you want to include the subdirectory cmake-3.23.0-linux-x86_64?
Saying no will install in: "/usr" [Yn]:
# 输入 n
最后在终端中输入,查看cmake是否安装成功
cmake --version
然后用llama.cpp自带的convert_hf_to_gguf.py 脚本
python convert_hf_to_gguf.py --outfile path1 path2
# python convert_hf_to_gguf.py --outfile <输出位置> <模模型所在目录>
最后运行推理脚本即可。
./build/bin/llama-cli -m ./ds-r1-distill-llama-8b/ds-r1-distill-llama-8B-Q4_0.gguf