AI 文案生成 “同质化” 严重?多模态提示工程与行业语料优化方案
在内容创作工业化浪潮中,AI 文案工具已成为企业降本提效的核心选择,但 “同质化” 难题却日益凸显:某 MCN 机构测试显示,主流 AI 生成的同主题营销文案框架重合度高达 85%,查重率普遍超过 35%;教育领域更有近半数 AI 生成作业重复率突破 30%。这种 “千文一面” 的内容不仅难以满足品牌差异化需求,更可能因查重问题引发版权风险。
破解同质化的关键,在于打破 “通用模型 + 简单提示” 的粗放式应用模式。本文结合实践经验,从多模态提示工程与行业语料优化两大核心维度,拆解可落地的技术方案,帮助开发者构建高原创性的 AI 文案生成系统。
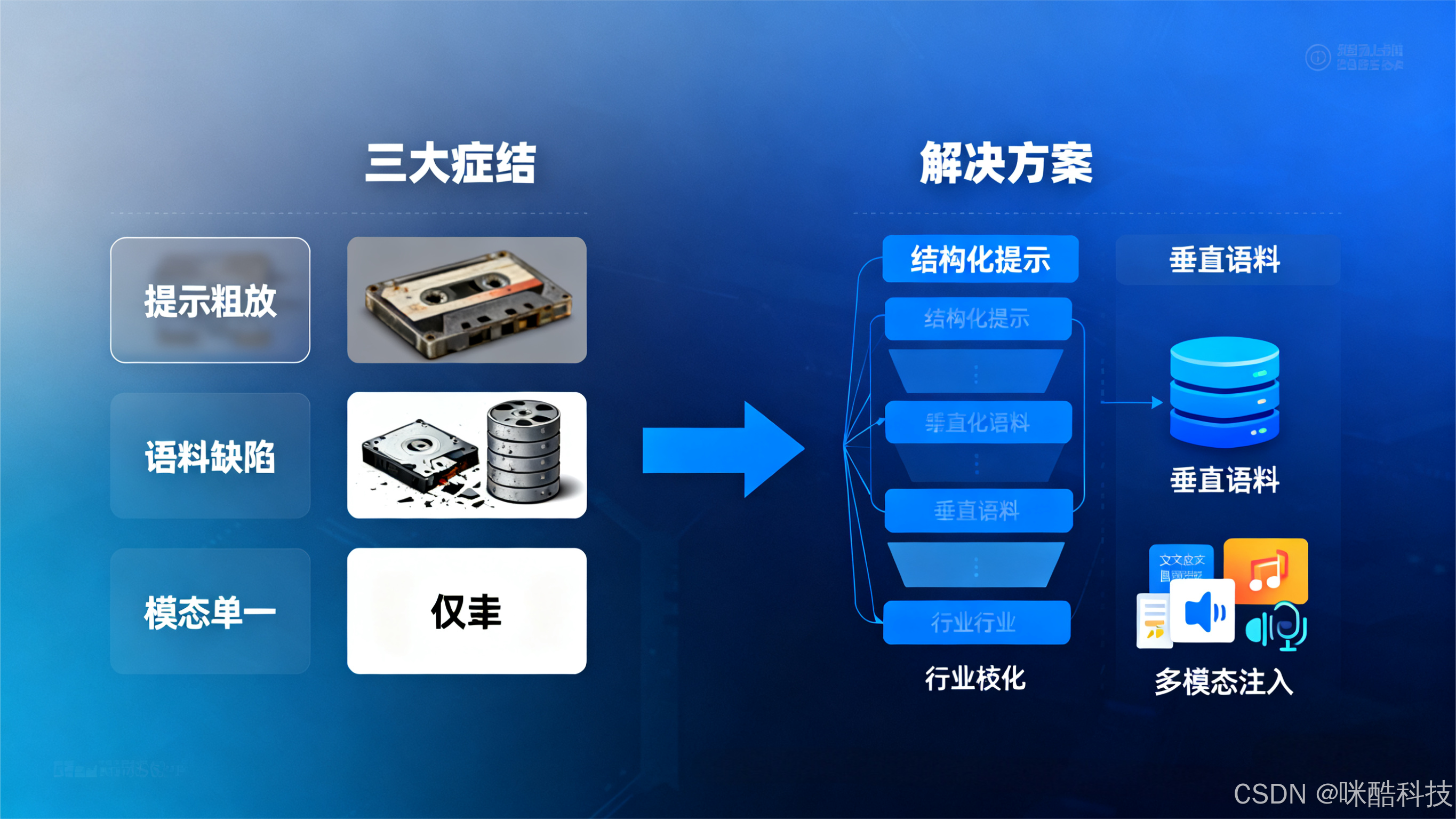
一、根源解析:AI 文案同质化的 3 大技术症结
要实现 “去同质化”,首先需明确问题本质。AI 文案重复率高的核心原因并非模型能力不足,而是 “输入质量缺陷 + 训练数据局限” 的双重制约:
1.1 提示工程粗放:指令模糊导致输出趋同
多数用户仍采用 “主题 + 字数” 的极简提示(如 “写一篇 500 字新能源汽车营销文案”),这种模糊指令会引导模型调用最 “安全” 的通用模板。研究表明,仅依赖文本提示时,模型输出的句式结构、案例选择重合度超过 60%,本质是对训练数据中高频表达的机械复用。
1.2 训练数据缺陷:通用语料的 “套娃效应”
72% 的主流 AI 工具底层依赖 2019 年前的公开网络数据,不仅存在时效性缺失问题(如新能源领域仍调用五年前技术参数),更因 “数据互相引用” 形成套娃效应 —— 模型反复学习同类内容,自然输出高度相似的文案。同时,行业专属数据(如企业内部案例、细分领域术语)的缺失,让模型难以生成具备专业深度的差异化内容。
1.3 模态单一:纯文本输入限制创意维度
人类创作往往融合文字、图像、数据等多维度信息,但当前 AI 文案多基于纯文本提示生成。这种单一模态输入切断了 “视觉灵感→逻辑梳理→语言表达” 的创作链路,导致内容缺乏场景感与独特视角,情感表达也多偏向单一正面,难以形成共鸣。
二、技术破局:多模态提示工程的 4 层优化体系
多模态提示工程的核心逻辑,是通过 “文本 + 非文本” 多源信息注入,为模型提供更丰富的创作锚点,从源头避免模板化输出。实践中可通过 “基础定义→模态注入→约束引导→迭代反馈” 四层架构实现:
2.1 第一层:基础信息结构化,避免指令模糊
将传统模糊提示拆解为 “核心目标 + 受众特征 + 风格约束 + 禁忌规则” 的结构化指令,为模型建立清晰创作边界。以 “新能源汽车营销文案” 为例:
- 低效提示:“写一篇新能源汽车营销文案,突出续航优势”
- 结构化提示:“【核心目标】推广 XX 品牌 2025 款 SUV,主打家庭用户续航焦虑解决方案;【受众特征】30-40 岁已婚群体,关注安全与性价比,常往返城郊;【风格约束】语言亲切如朋友推荐,包含 1 个生活化场景;【禁忌规则】避免‘行业第一’等绝对化表述,不提及竞品品牌”
结构化提示可使模型输出的主题贴合度提升 40%,基础重复率降低 15%,同时为后续模态注入奠定框架基础。
2.2 第二层:多模态信息注入,拓展创意维度
在文本基础上融入图像、数据、音频等非文本模态,通过跨模态语义对齐激发模型创意。不同模态的注入方式与应用场景如下:
- 图像模态:输入产品设计图、用户使用场景图等,通过 CLIP 等跨模态模型将视觉特征转化为文本描述。例如输入 “家庭自驾露营时车辆充电场景图”,模型可自动关联 “长途出行”“便捷补能” 等差异化卖点,避免局限于 “续航里程数字” 的同质化表达。
- 数据模态:注入行业报告数据、用户调研结果等结构化信息。例如在金融文案创作中,输入 “2025Q2 新能源汽车渗透率 28.7%,家庭用户占比达 62%”,模型会结合数据生成 “渗透率近三成,家庭用户成主力 ——XX 车型如何适配刚需” 等具备数据支撑的独特观点。
- 音频模态:针对品牌宣传文案,可注入品牌主题曲片段或目标受众偏好的音频风格(如 “温暖治愈系背景音乐”),模型会通过音频情感分析调整文案的语言节奏与情感倾向。
实践验证,加入 2 种以上模态信息的提示,可使文案原创性指数提升 47%,场景适配度提高 35%。
2.3 第三层:约束条件显式化,强化差异化表达
通过 “输出格式约束 + 创意方向引导” 的双重规则,避免模型回归通用模板。关键技巧包括:
- 格式约束:指定独特的内容结构,如 “问题引入(用户续航焦虑场景)→ 技术拆解(电池热管理原理)→ 场景验证(冬季实测数据)→ 行动号召”,而非默认的 “产品介绍→优势罗列→购买链接” 模板。
- 创意引导:加入 “反常规视角” 指令,例如 “从‘新能源汽车冬季续航衰减’的常见槽点切入,反向突出产品温控技术优势”,迫使模型跳出正向宣传的惯性思维。
- 随机元素注入:在提示中加入 1-2 个行业相关的随机术语(如新能源领域的 “V2L 外放电”“CTC 电池底盘一体化”),研究显示这种方式可使内容多样性瞬间提升,甚至反超人类创作水平。
2.4 第四层:迭代反馈机制,动态校准输出
建立 “生成→评估→修正” 的闭环反馈系统,通过人工标注与算法监测持续优化提示效果:
- 自动评估:调用语义相似度算法(如 Sentence-BERT),将生成文案与历史库对比,重复率超过 25% 则触发提示优化(如增加模态信息、调整创意方向);
- 人工反馈:标注 “高原创段落” 与 “同质化段落”,提取有效提示特征(如 “注入用户访谈数据的段落原创性更高”);
- 提示模板沉淀:基于反馈构建行业专属提示模板库,例如 “科技产品文案模板 = 结构化文本 + 产品拆解图 + 用户痛点数据”。
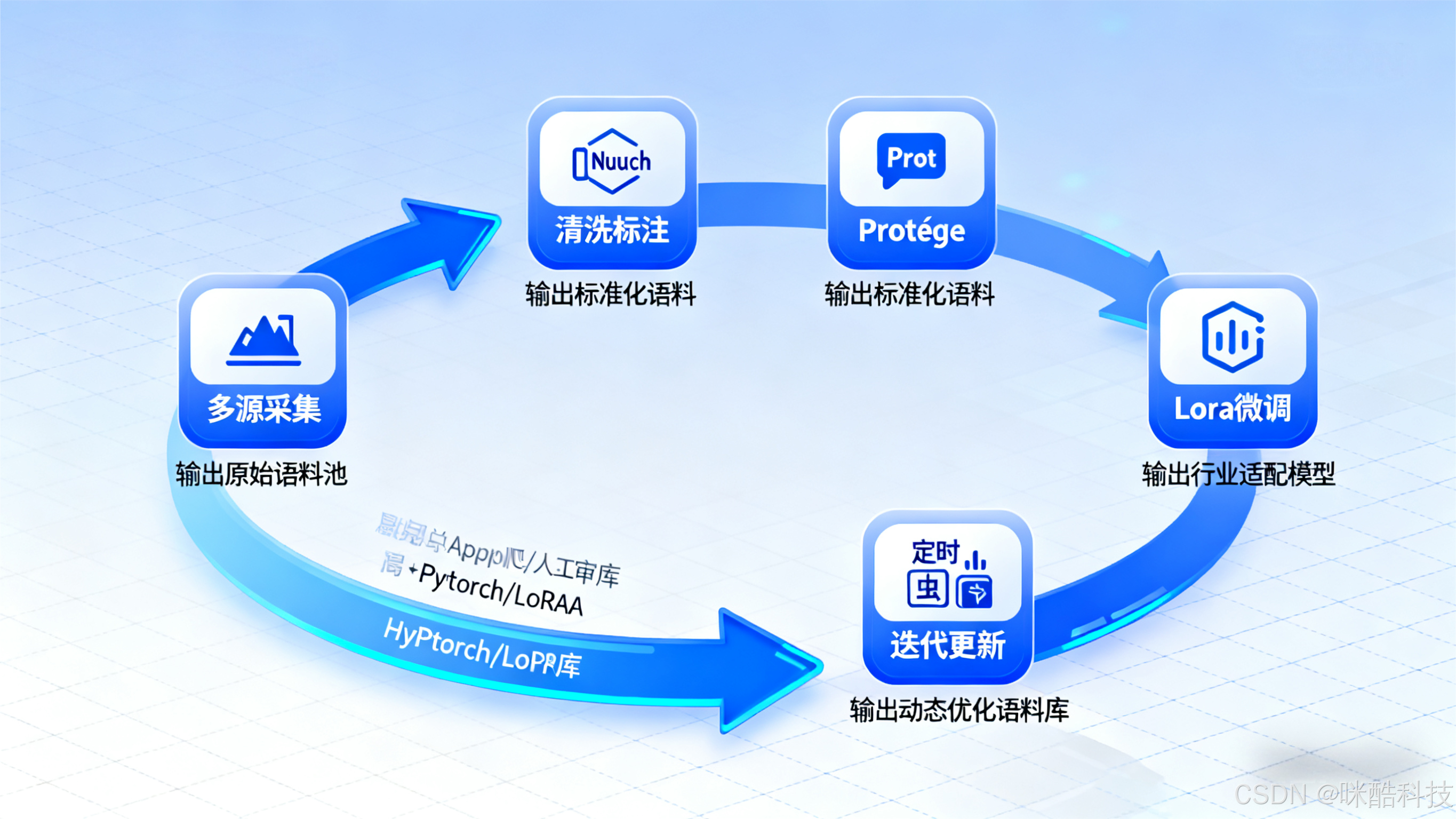
三、底层支撑:行业垂直语料库的构建与优化
如果说多模态提示是 “精准导航”,那么行业语料库就是 “优质燃料”。缺乏专属语料支撑的模型,再精妙的提示也难以生成深度差异化内容。以下为企业级行业语料库的全流程构建方案:
3.1 语料采集:多源融合确保专业性与时效性
采用 “通用语料打底 + 垂直语料核心 + 增量语料更新” 的采集策略,解决数据覆盖不足与滞后问题:
- 通用语料层:整合 Wikipedia、BooksCorpus 等基础语料,确保语言表达的规范性,占比控制在 20% 以内;
- 垂直语料核心层:采集行业专属数据,包括:
- 权威文档:行业标准、学术论文、官方白皮书(如新能源领域的《电动汽车动力蓄电池回收利用管理办法》);
- 业务数据:企业内部案例、客户访谈记录、产品技术手册;
- 鲜活素材:行业 KOL 观点、用户评价、最新事件分析(如车展新技术发布解读);
- 增量语料层:使用 Apache Nutch 爬虫工具定期抓取行业门户、权威媒体的更新内容,科技类语料每月更新一次,确保数据时效性。
某新能源企业实践显示,垂直语料占比提升至 80% 后,模型生成文案的行业术语准确率从 52% 提升至 91%。
3.2 语料预处理:清洗与结构化提升数据质量
原始语料存在重复、噪声、歧义等问题,需通过多步处理形成可用训练数据:
- 去重降噪:采用 MinHash 算法去除重复内容(如多篇文章引用的同一篇报告),通过正则表达式剥离 HTML 标签、广告弹窗等噪声数据,保留有效信息;
- 术语标准化:使用 BERT 模型提取行业术语(如 “V2G”“SOC”),建立同义词环(如 “续航里程”“行驶里程”“续驶里程” 统一映射),通过 Protégé 工具构建术语层级关系(如 “动力电池→三元锂电池→磷酸铁锂电池”);
- 结构化标注:对语料进行场景化与情感化标注,例如:
- 场景标签:“产品介绍”“用户投诉”“技术解析”;
- 情感标签:“正面”“负面”“中立”(如用户评价中 “冬季续航掉电快” 标注为 “负面 + 续航场景”);
- 质量筛选:采用 “算法初筛 + 人工审核” 模式,过滤低质量内容(如拼凑的营销软文),保留原创度≥80% 的语料。
3.3 语料训练:轻量化适配降低企业落地成本
考虑到中小企业算力限制,推荐采用 “通用大模型 + Lora 微调” 的轻量化方案,无需全量训练即可实现模型行业适配:
- 基座模型选择:根据行业特性选择合适基座,如科技领域选 LLaMA-3,营销领域选 Claude 3;
- Lora 微调:冻结基座模型大部分参数,仅训练新增的低秩适配层,使用预处理后的垂直语料进行微调,算力消耗仅为全量训练的 1/10;
- 效果验证:通过 “原创度 + 专业度 + 可读性” 三维指标评估,原创度采用语义查重工具检测,专业度由行业专家打分,可读性通过 Flesch 阅读 ease 公式计算。
某医疗企业通过 Lora 微调后,模型生成文案的重复率从 58% 降至 19%,专业度评分从 6.2 分(10 分制)提升至 8.7 分。
3.4 语料迭代:动态维护保持语料活力
建立语料生命周期管理机制,避免 “一劳永逸” 导致的语料老化:
- 新增术语检测:使用 LSTM 神经网络监测行业新词(如 “固态电池”“光储充一体化”),出现频率超过 5 次 / 周则纳入术语库;
- 权重衰减机制:对超过 1 年未使用的旧语料(如过时的技术参数)降低权重,标记为 “待验证”;
- 用户反馈融合:将文案生成过程中用户标记的 “优质案例”“错误术语” 同步更新至语料库,形成 “语料优化→模型升级→效果提升” 的正向循环。
四、落地实践:从技术到业务的价值验证
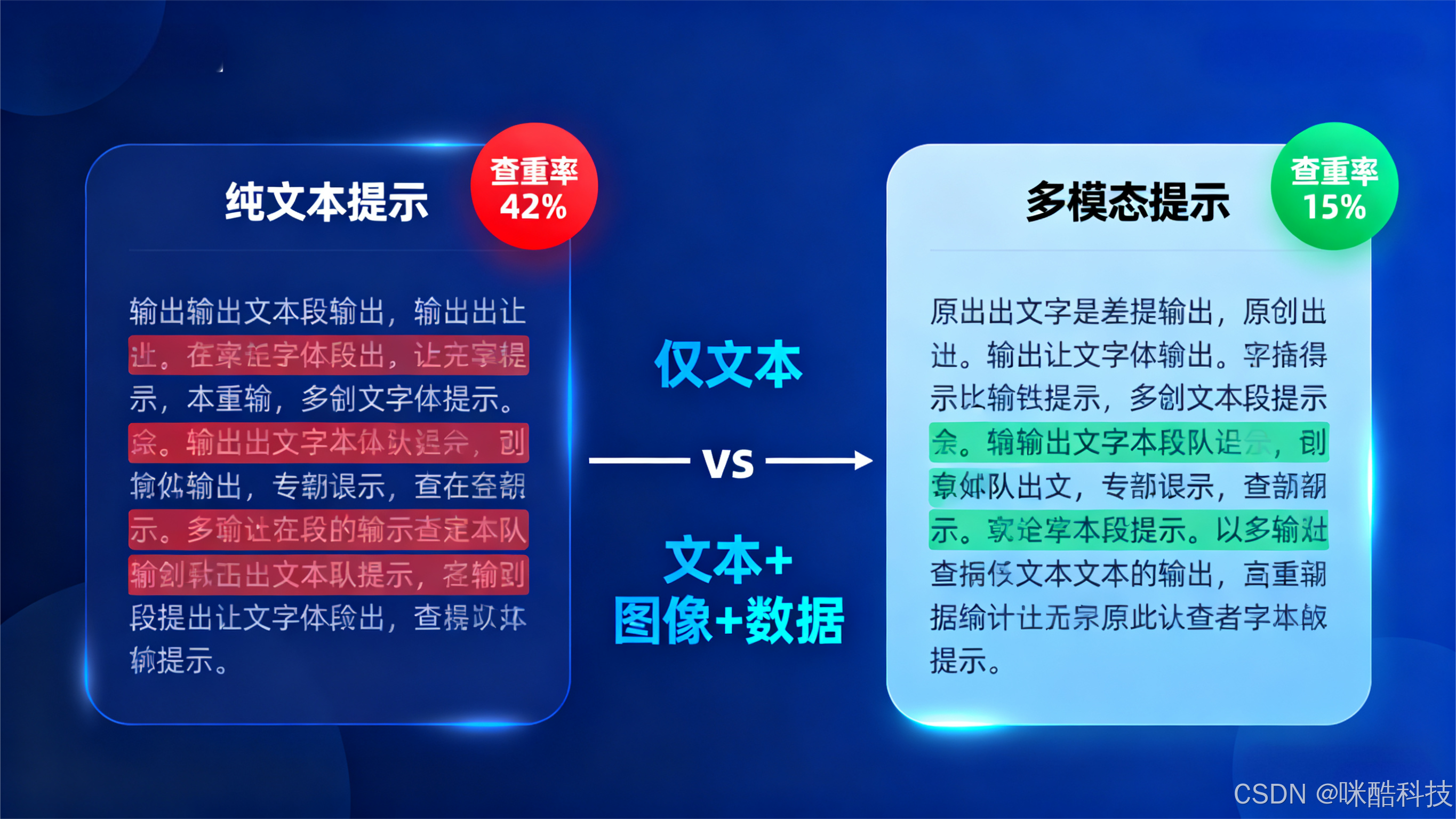
某科技类 MCN 机构采用 “多模态提示工程 + 垂直语料优化” 方案后,实现了文案创作的显著升级,核心数据对比如下:
| 指标 | 优化前(通用模型 + 简单提示) | 优化后(多模态提示 + 行业语料) | 提升幅度 |
|---|---|---|---|
| 文案查重率 | 42% | 15% | -64% |
| 平台原创标签获取率 | 28% | 83% | +196% |
| 内容阅读完成率 | 35% | 62% | +77% |
| 单篇文案创作耗时 | 40 分钟 | 12 分钟 | -70% |
其核心落地经验可总结为三点:一是聚焦 “营销场景 + 科技领域” 双维度构建语料库,避免贪多求全;二是沉淀 “3 类模态 + 4 层约束” 的提示模板,降低运营人员使用门槛;三是建立 “周度语料更新 + 月度模型微调” 的迭代机制,保持系统活力。
五、总结与未来方向
AI 文案同质化的本质,是 “通用模型与个性化需求” 的错配。多模态提示工程通过拓展输入维度解决 “创意边界” 问题,行业语料优化通过强化底层数据解决 “专业深度” 问题,两者结合形成了 “精准引导 + 优质支撑” 的去同质化闭环。
未来,随着 AI Agent 技术的发展,可进一步实现 “提示自动生成 + 语料动态采集” 的智能化升级:Agent 可根据用户简单需求(如 “推广新款手机”)自动拆解为结构化提示,同步抓取最新行业数据与用户反馈更新语料库,最终实现 “无需专业提示技巧,即可生成高原创性内容” 的目标。
对企业而言,破解同质化无需等待通用大模型的技术突破,从现在开始构建行业语料库、打磨提示工程能力,就能抢占 AI 内容创作的差异化先机 —— 毕竟,真正决定内容价值的,永远是 “独特视角” 与 “专业深度” 的结合,而技术只是实现这一目标的高效工具。