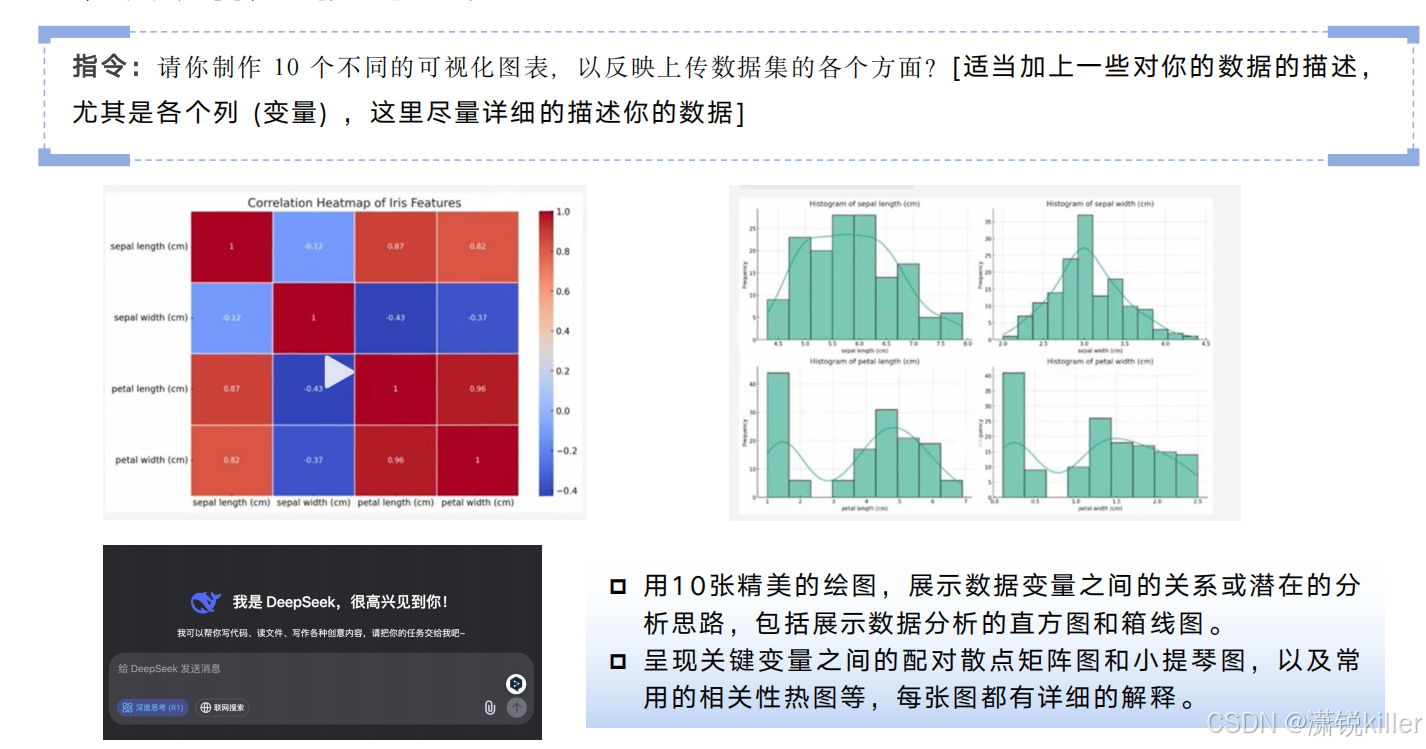
DeepSeek入门学习
参考文档:DeepSeek(人工智能企业)_百度百科
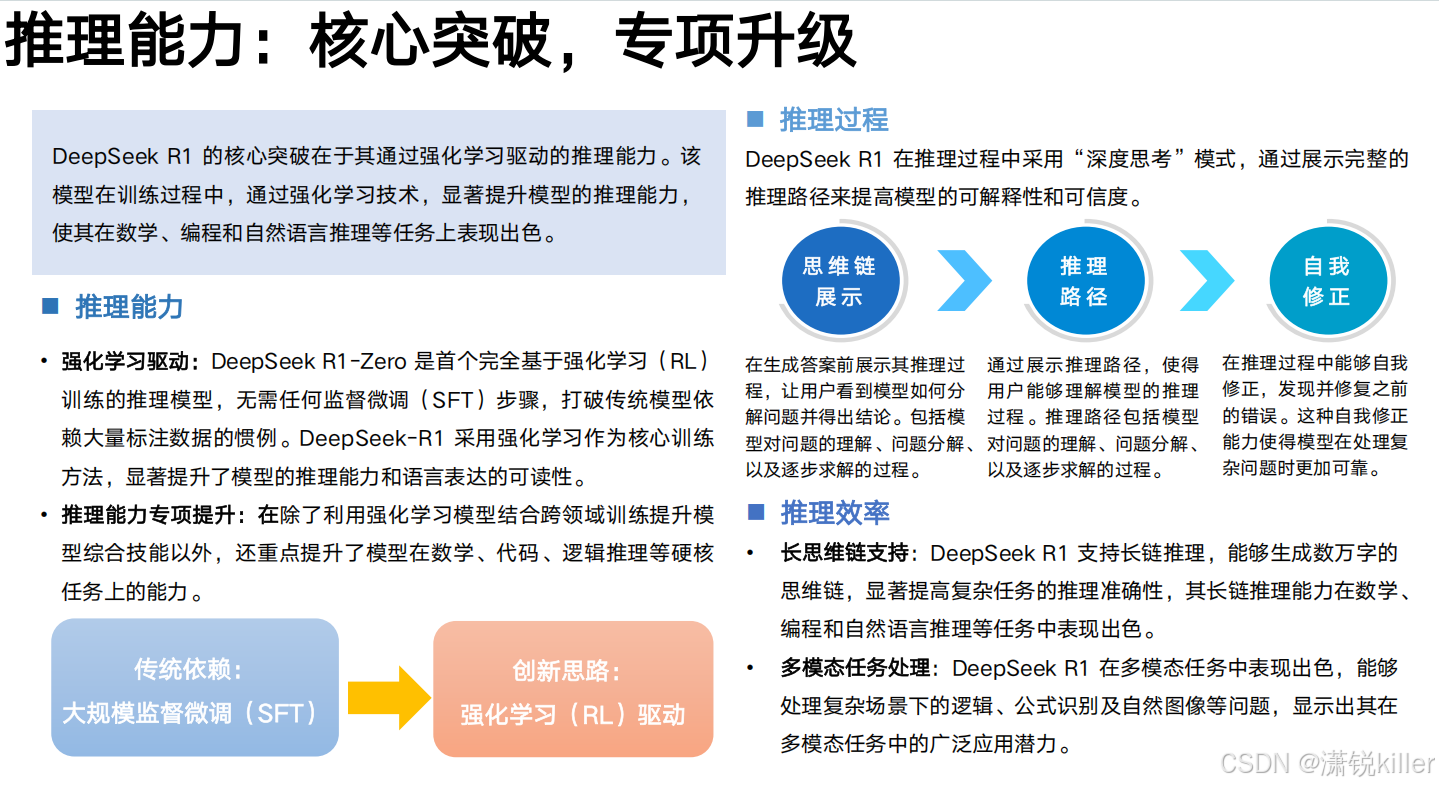
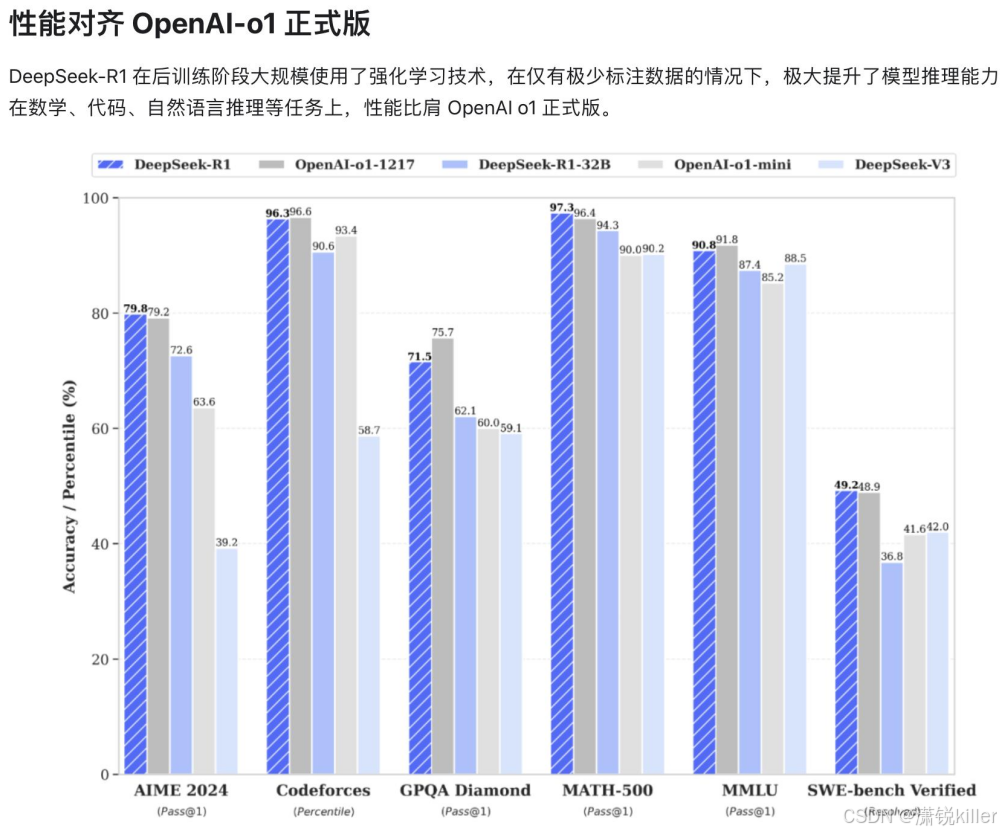
DeepSeek-R1 凭借创新的强化学习技术实现重大突破。在极少量标注数据的基础上,通过深度优化的后训练阶段,显著提升了模型的推理能力。在数学运算、代码生成、自然语言推理等核心领域,其表现均达到了与 OpenAI o1 正式版相当的水平。





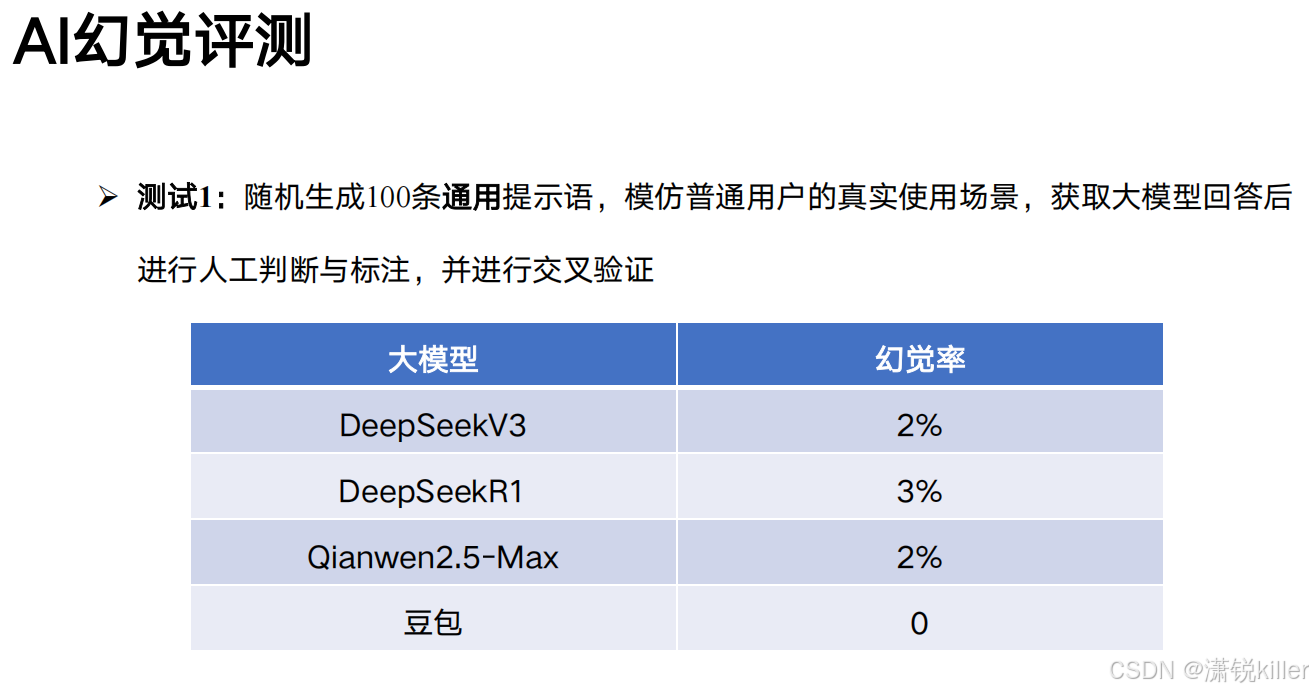
深度搜索有服务器繁忙的情况
模型爆火
2025年1月下旬,DeepSeek的R1模型发布后的一周内,DeepSeek刷屏美国各大主流媒体和社交网站。其中一部分原因为,TMT Breakout在与网友的讨论中,隐隐将英伟达周五下跌的原因指向DeepSeek的爆火。即R1的成功可能削弱了市场对英伟达AI芯片需求的预期,导致交易员做空英伟达股票,进而引发股价下跌。 [12]1月22日,美国媒体Business Insider报道称,DeepSeek-R1模型秉承开放精神,完全开源,为美国AI玩家带来了麻烦。开源的先进AI可能挑战那些试图通过出售技术赚取巨额利润的公司。
2025年1月28日凌晨,DeepSeek在GitHub平台发布了Janus-Pro多模态大模型,进军文生图领域。
2025年1月30日消息,微软CEO纳德拉在电话会上强调,DeepSeek R1模型目前已可通过微软的AI平台Azure AI Foundry和GitHub获取,并且很快就能在Copilot+电脑上运行。纳德拉称DeepSeek“有一些真的创新”,AI成本下降是趋势:“缩放定律(Scaling Law)在预训练和推理时间计算中不断积累。多年来,我们已经看到了AI训练和推理方面的效率显著提高。在推理方面,我们通常看到每一代硬件的性价比提高2倍以上,每一代模型的性价比提高10倍以上。”
2025年1月31日,英伟达宣布DeepSeek-R1模型登陆NVIDIA NIM。同一时段内,亚马逊和微软也接入DeepSeek-R1模型。英伟达称,DeepSeek-R1是最先进的大语言模型。
2025年1月,DeepSeek的出现,打破了“大模型”、美国股市的神话,还颠覆了传统“大模型需要大算力”无可匹敌的美国主流地位,进一步挑战了“巨型数据集”作为人工智能成功的唯一途径的普遍认知。
2025年2月消息,DeepSeek-R1大模型一键部署至腾讯云「HAI」上,开发者仅需3分钟就能接入调用。 2月,DeepSeek获顶级域名ai.com认可。 2月消息,居然智家数智化业务板块全线接入DeepSeek,包括V3和R1版本,并启动私有化部署。
2025年2月,深圳市生态环境局罗湖管理局在生态环境治理领域取得突破,成功完成DeepSeek-R1模型的应用。 [160]2月,黄山AI旅行助手全面接入DeepSeek大模型。 [162]同月,茂名荔枝产业大数据平台宣布完成人工智能大模型DeepSeek的本地化部署,推动实现荔枝生产管理“AI精准指导”和“数据驱动决策”,病虫害诊断从人工经验判断转向AI秒级分析,准确率提升至95%,生产效率提升30%。
deepseek-chat模型优惠期结束,调用价格已变更为每百万输入tokens 2元,每百万输出tokens 8元。
2025年2月26日,DeepSeek宣布开源DeepGEMM。 [175]同日下午,DeepSeek在其API(接口)平台上发布提醒信息称,北京时间每日00:30-08:30为错峰时段,API调用价格大幅下调:DeepSeek-V3降至原价的50%,DeepSeek-R1降至25%,在该时段调用享受更经济更流畅的服务体验。
主要产品
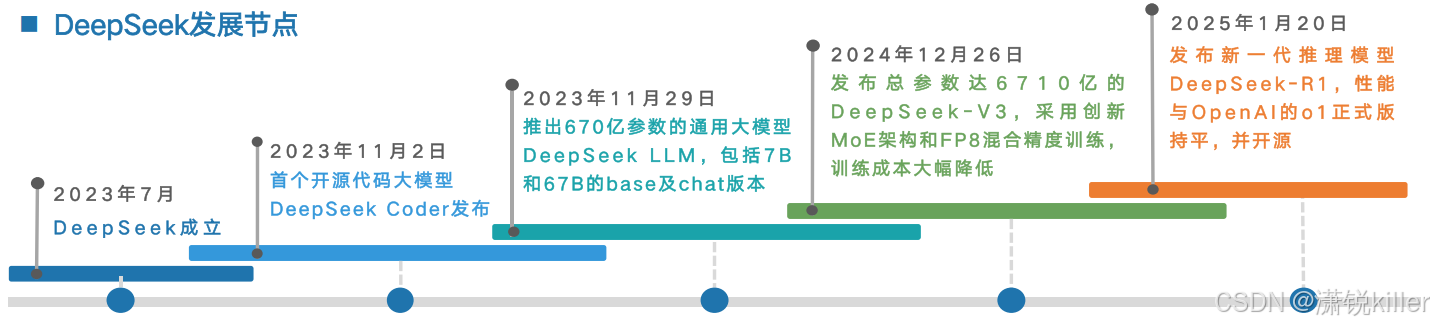
2024年1月5日,发布DeepSeek LLM,这是深度求索的第一个大模型。DeepSeek LLM包含670亿参数,从零开始在一个包含2万亿token的数据集上进行了训练,数据集涵盖中英文。全部开源DeepSeek LLM 7B/67B Base和DeepSeek LLM 7B/67B Chat,供研究社区使用。DeepSeek LLM 67B Base在推理、编码、数学和中文理解等方面超越了Llama2 70B Base。DeepSeek LLM 67B Chat在编码和数学方面表现出色。它还展现了显著的泛化能力,在匈牙利国家高中考试中取得了65分的成绩。当然,它还精通中文:DeepSeek LLM 67B Chat在中文表现上超越了GPT-3.5。
2024年1月25日,发布DeepSeek-Coder,DeepSeek Coder由一系列代码语言模型组成,每个模型均从零开始在2万亿token上训练,数据集包含87%的代码和13%的中英文自然语言。代码模型尺寸从1B到33B版本不等。每个模型通过在项目级代码语料库上进行预训练,采用16K的窗口大小和额外的填空任务,以支持项目级代码补全和填充。DeepSeek Coder在多种编程语言和各种基准测试中达到了开源代码模型的最先进性能。
2024年2月5日,发布DeepSeekMath,DeepSeekMath以DeepSeek-Coder-v1.5 7B为基础,继续在从Common Crawl中提取的数学相关token以及自然语言和代码数据上进行预训练,训练规模达5000亿token。DeepSeekMath 7B在竞赛级MATH基准测试中取得了51.7%的优异成绩,且未依赖外部工具包和投票技术,接近Gemini-Ultra和GPT-4的性能水平。
2024年3月11日,发布DeepSeek-VL,DeepSeek-VL是一个开源的视觉-语言(VL)模型,采用了混合视觉编码器,能够在固定的token预算内高效处理高分辨率图像(1024x1024),同时保持相对较低的计算开销。这一设计确保了模型在各种视觉任务中捕捉关键语义和细节信息的能力。DeepSeek-VL系列(包括1.3B和7B模型)在相同模型尺寸下,在广泛的视觉-语言基准测试中达到了最先进或可竞争的性能。
2024年5月7日,发布第二代开源Mixture-of-Experts(MoE)模型——DeepSeek-V2。DeepSeek-V2是一个强大的混合专家(MoE)语言模型,以经济高效的训练和推理为特点。它包含2360亿个总参数,其中每个token激活210亿个参数。与DeepSeek 67B相比,DeepSeek-V2不仅实现了更强的性能,同时还节省了42.5%的训练成本,将KV缓存减少了93.3%,并将最大生成吞吐量提升至5.76倍。在一个包含8.1万亿token的多样化且高质量的语料库上对DeepSeek-V2进行了预训练。在完成全面的预训练后,通过监督微调(SFT)和强化学习(RL)进一步释放了模型的潜力。评估结果验证了方法的有效性,DeepSeek-V2在标准基准测试和开放式生成评估中均取得了显著的表现。 [9]DeepSeek V2模型因在中文综合能力评测中的出色表现,且以极低的推理成本引发行业关注,被称为“AI界的拼多多”。
2024年6月17日,发布DeepSeek-Coder-V2,DeepSeek-Coder-V2是一个开源的混合专家(MoE)代码语言模型,在代码特定任务中达到了与GPT4-Turbo相当的性能。DeepSeek-Coder-V2是从DeepSeek-V2的一个中间检查点开始,进一步预训练了额外的6万亿token,显著增强了DeepSeek-V2的编码和数学推理能力,同时在通用语言任务中保持了相当的性能。并在代码相关任务、推理能力和通用能力等多个方面都取得了显著进步。此外,DeepSeek-Coder-V2将支持的编程语言从86种扩展到338种,并将上下文长度从16K扩展到128K。在标准基准测试中,DeepSeek-Coder-V2在编码和数学基准测试中表现优异,超越了GPT4-Turbo、Claude 3 Opus和Gemini 1.5 Pro等闭源模型。
2024年12月13日,发布用于高级多模态理解的专家混合视觉语言模型——DeepSeek-VL2,DeepSeek-VL2是一个先进的大型混合专家(MoE)视觉-语言模型系列,相较于其前身DeepSeek-VL有了显著改进。DeepSeek-VL2在多种任务中展现了卓越的能力,包括但不限于视觉问答、光学字符识别、文档/表格/图表理解以及视觉定位。模型系列由三个变体组成:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分别具有10亿、28亿和45亿激活参数。与现有的开源密集模型和基于MoE的模型相比,DeepSeek-VL2在相似或更少的激活参数下实现了具有竞争力或最先进的性能。
2024年12月26日晚,AI公司深度求索(DeepSeek)正式上线全新系列模型DeepSeek-V3首个版本并同步开源。 [1-2]DeepSeek-V3在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代DeepSeek-V2.5显著提升,接近当前表现最好的模型Anthropic公司于10月发布的Claude-3.5-Sonnet-1022。在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅超过了其他所有开源闭源模型。另外,在生成速度上,DeepSeek-V3的生成吐字速度从20TPS(Transactions Per Second每秒完成的事务数量)大幅提高至60TPS,相比V2.5模型实现了3倍的提升,能够带来更加流畅的使用体验。
2025年1月20日,DeepSeek正式发布DeepSeek-R1模型,并同步开源模型权重。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。 [11]DeepSeek-V3和DeepSeek-R1两款大模型,成本价格低廉,性能与OpenAI相当。
技术分析
算法原理
DeepSeek 大语言模型系以 Transformer 架构为基础,自主研发的深度神经网络模型。模型基于注意力机制,通过海量语料数据进行预训练,并经过监督微调、人类反馈的强化学习等进行对齐,构建形成深度神经网络,并增加审核、过滤等安全机制,使算法模型部署后能够根据人类的指令或者提示,实现语义分析、计算推理、问答对话、篇章生成、代码编写等任务。
算法目的
DeepSeek 大语言模型旨在通过智能问答、代码生成等应用场景为用户提供创作、工作和提效的工具。高效便捷地帮助人们获取信息、知识和灵感。
运行机制
DeepSeek 大语言模型的运行机制为用户输入文本格式的自然语言数据,产品经过预处理和违法不良信息审核后,由算法模型根据语言的统计规律、知识和对齐要求进行推理和计算,通过预测下一个最佳词语来实现文本生成,最后产品将经过审核的生成内容输出返回给用户,以响应用户的指令。
DeepSeek 大语言模型应用于智能对话场景,服务于企业端客户,根据用户输入的文本数据,通过大语言模型生成符合用户需求的文本、代码等内容。
DeepSeek 大语言模型直接向用户或者支持开发者,提供智能对话、文本生成、语义理解、计算推理、代码生成补全等应用场景。
DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格
DeepSeek-V2 API的定价为:每百万tokens输入1元、输出2元。
DeepSeek-V3这个参数量高达671B的大模型,在预训练阶段仅使用2048块GPU训练了2个月,且只花费557.6万美元。其训练费用相比GPT-4等大模型要少得多。
DeepSeek V3整个训练过程仅用了不到280万个GPU小时。
DeepSeek-V3
DeepSeek-V3 是一个混合专家(MoE)语言模型,具有总计671亿个参数,每个 token 激活 37 亿个参数。该模型在14.8万亿个多样且高质量的tokens上进行了预训练,并通过监督微调和强化学习阶段进一步优化。
DeepSeek-V3采用FP8训练,并开源了原生FP8权重。 [14]DeepSeek-V3生成速度相比其上一代模型DeepSeek-V2.5实现了3倍的提升,但暂不支持多模态输入输出。
DeepSeek-V3的应用场景包括聊天和编码场景、多语言自动翻译、图像生成和AI绘画等。
DeepSeek V3的训练成本仅使用了2048个H800GPU,总训练GPU卡时为2788千小时(其中预训练为2664千小时),平均到每个GPU上仅为1361小时,约合56.7天。
DeepSeek v3具有 Mixture-of-Experts 架构,总参数达 671B。DeepSeek v3经过14.8万亿个不同代币的训练,并结合了多代币预测等先进技术,为AI语言建模树立了新标准。 该模型支持128K上下文窗口,提供与领先的闭源模型相当的性能,同时保持高效的推理能力。 [8]相比V2.5版本,DeepSeek-V3的生成速度提升至3倍,每秒吞吐量高达60 token。
DeepSeek V3技术文档提及了使用模型生成训练数据等,因此数据质量或有较大幅度提升。GPT-4 MoE使用了13万亿(1300B)token,而DeepSeek V3使用的token数量约为14.8万亿(1480B),数据量相差不大。
基准测试
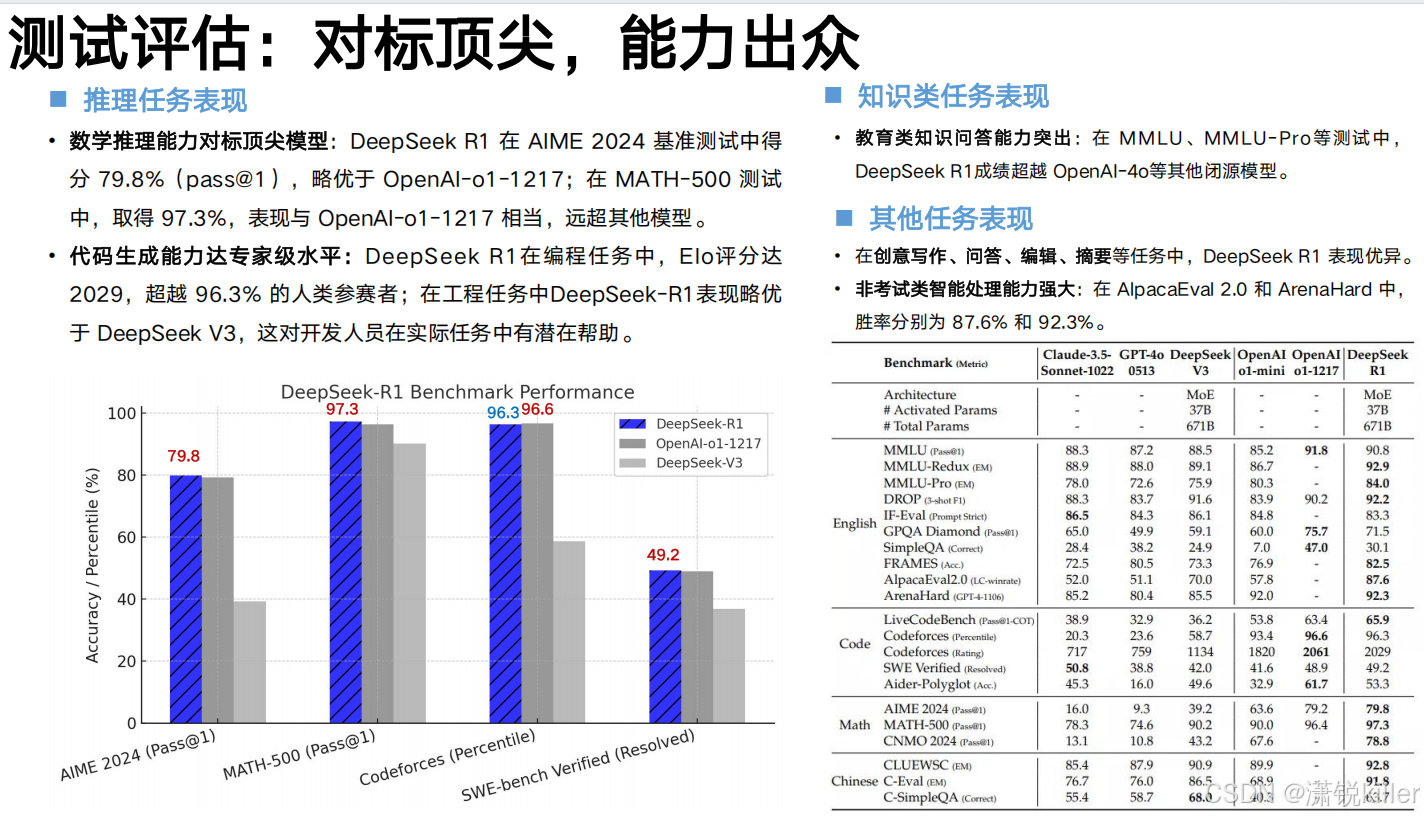
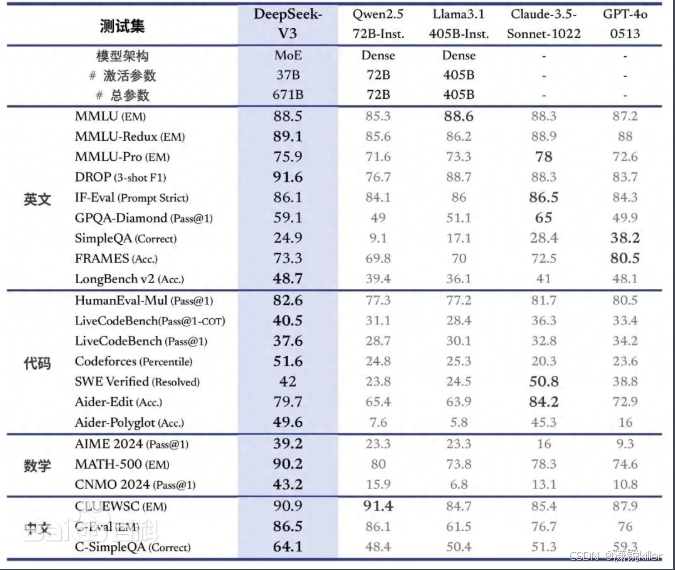
在多项基准测试中,DeepSeek-V3的成绩超越了Qwen2.5-72 B和Llama-3.1-405 B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
DeepSeek V3在长文本处理、代码生成和数学推理等多个领域都展示了顶尖的性能。特别是在中文任务和数学基准测试中,DeepSeek V3的表现尤为突出,展现了其深刻的理解和处理能力。通过算法和工程上的优化,DeepSeek V3在生成速度上实现了三倍提升,从20 TPS提高到60 TPS,极大改善了用户的交互体验和模型响应速度。
应用场景
聊天和编码场景:为开发者设计,能够理解和生成代码,提高编程效率。
多语言自动翻译:支持多达20种语言的实时翻译和语音识别,适合需要处理多种语言内容的企业用户。
图像生成和AI绘画:整合视觉理解技术,允许用户通过简单的文本描述生成高质量图像,丰富应用场景和用户创意表达的自由度。
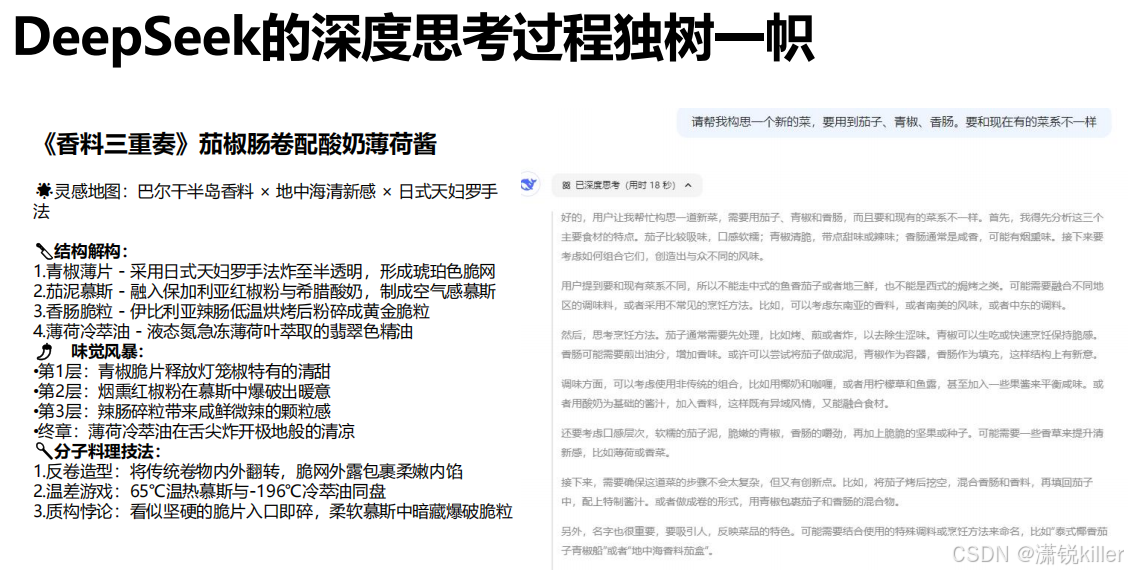
R1模型强化学习+监督微调,复杂推理表现出色但成本高;V3处理结构化任务更强,长文本也轻松。模型各有优势,得根据需求选。