transformers + peft 框架大模型微调
教程来源:datawhale:llm-preview
一、微调的意义
- 高度自定义的复杂任务
- 具有较高门槛的垂直领域任务(例如金融领域)
- 对响应时间、算力要求较高的任务,无法使用大体量 LLM,需要用较小的 LLM 完成高难度任务(无法进行全参数微调)
二、准备阶段
!pip install -q datasets pandas peft
from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen3-4B-Instruct-2507', cache_dir='/root/autodl-tmp/model', revision='master')
三、SFT
将输入和输出同时给模型,让他根据输出不断去拟合从输入到输出的逻辑,类似于将问题和答案同时给模型,让模型基于答案学习解决问题的过程。
数据格式:
{"instruction":"将下列文本翻译成英文:","input":"今天天气真好","output":"Today is a nice day!"
}
LLaMA 的 SFT 格式:
### Instruction:\n{{content}}\n\n### Response:\n
其中,content为指令+用户输入
举个例子:
输入:### Instruction:\n将下列文本翻译成英文:今天天气真好\n\n### Response:\n
输出:### Instruction:\n将下列文本翻译成英文:今天天气真好\n\n### Response:\nToday is a nice day!
任务:要求 LLM 扮演甄嬛,以甄嬛的语气、风格与用户对话
微调数据集可以在此处下载:
https://github.com/KMnO4-zx/huanhuan-chat/blob/master/dataset/train/lora/huanhuan.json
数据集示例:
{"instruction": "这个温太医啊,也是古怪,谁不知太医不得皇命不能为皇族以外的人请脉诊病,他倒好,十天半月便往咱们府里跑。","input": "","output": "你们俩话太多了,我该和温太医要一剂药,好好治治你们。"
}
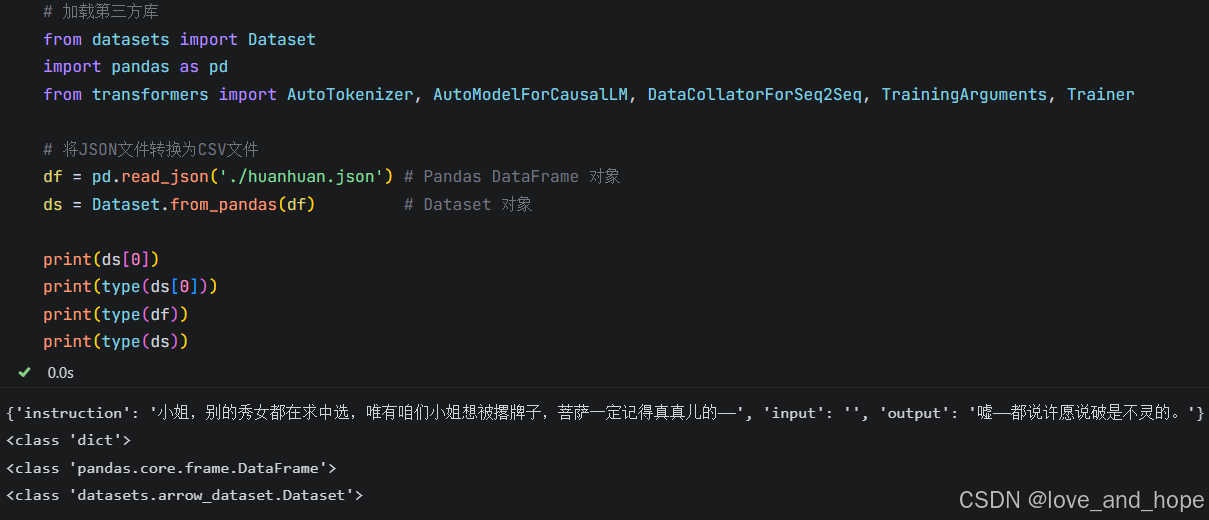
加载数据
# 加载第三方库
from datasets import Dataset
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer# 将JSON文件转换为CSV文件
df = pd.read_json('./huanhuan.json') # Pandas DataFrame 对象
ds = Dataset.from_pandas(df) # Dataset 对象print(ds[0])
print(type(ds[0]))
print(type(df))
print(type(ds))
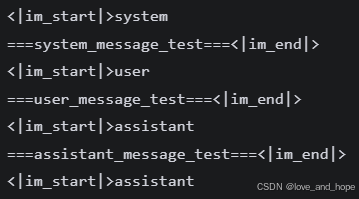
设置tokenizer,观察chat_template格式
# 加载模型 tokenizer
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507', trust_remote=True)# 打印一下 chat template
messages = [{"role": "system", "content": "===system_message_test==="},{"role": "user", "content": "===user_message_test==="},{"role": "assistant", "content": "===assistant_message_test==="},
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True
)
print(text)
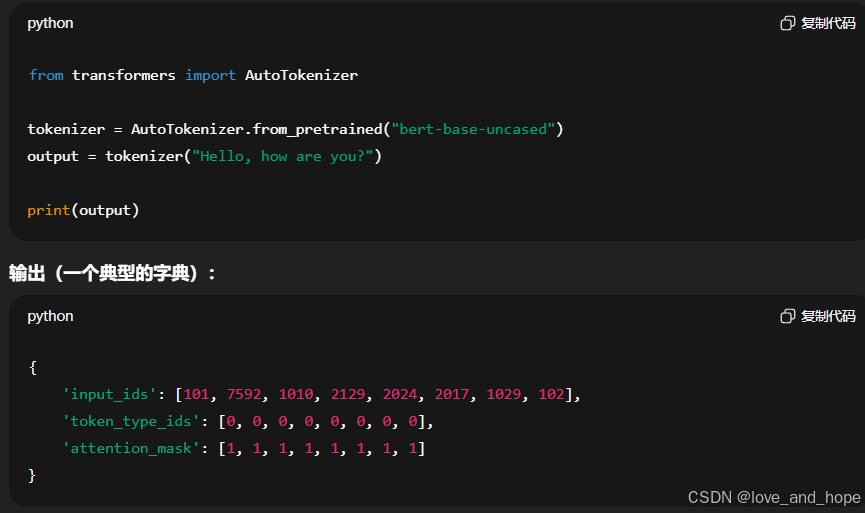
封装处理数据集函数
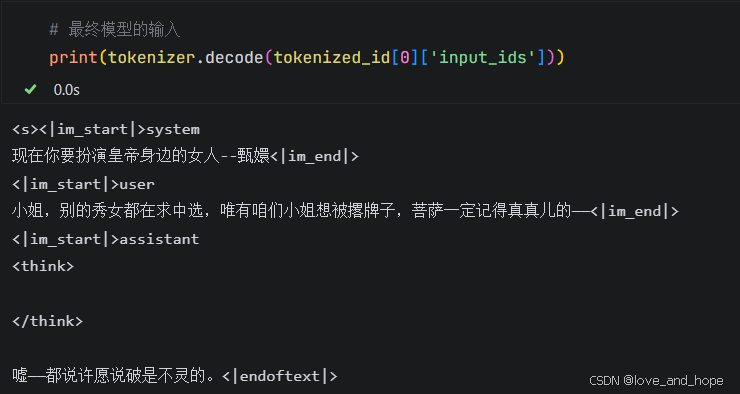
def process_func(example): #example为一个字典MAX_LENGTH = 1024 # 设置最大序列长度为1024个tokeninput_ids, attention_mask, labels = [], [], [] # 初始化返回值'''input_ids:拼接后的输入 token IDs,包含了 instruction 和 response 部分。attention_mask:指定哪些位置需要被模型关注(1 表示关注,0 表示不关注),这里 instruction 和 response 都会被模型关注,填充部分(pad_token_id)通常不被关注。labels:模型训练时用作目标的 token IDs。instruction 部分用 -100 填充,表示模型不需要对这部分预测;response 部分用实际的 token IDs 填充,表示模型要预测的目标输出。'''# 适配chat_templateinstruction = tokenizer(f"<s><|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n" f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n" f"<|im_start|>assistant\n<think>\n\n</think>\n\n", add_special_tokens=False )# <s>表示文本的开始response = tokenizer(f"{example['output']}", add_special_tokens=False)# 将instructio部分和response部分的input_ids拼接,并在末尾添加eos token作为标记结束的tokeninput_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]# 注意力掩码,表示模型需要关注的位置attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]# 对于instruction,使用-100表示这些位置不计算loss(即模型不需要预测这部分)labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id] # list拼接if len(input_ids) > MAX_LENGTH: # 超出最大序列长度截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
input_ids:SFT微调模型的输入,即instruction+response
token_type_ids:这个token属于哪个句子
attention_mask:pad_token不需要被关注
# 使用上文定义的函数对数据集进行处理
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)
# map() 是 datasets 库中的一个方法,它用于对数据集中的每一行应用一个函数。传递给 map 的 process_func 是定义的函数,它会在数据集的每一行上进行处理。
# remove_columns=ds.column_names,数据集中将不再保留这些原始列,只保留你在 process_func 中返回的处理结果。
# 原来是:instruction、input、output
# 现在是:input_ids、attention_mask、labels
tokenized_id


四、高效微调-LoRA
保留初始权重,引入低秩扰动
在推理时,可通过矩阵计算直接将 LoRA 参数合并到原模型。
我们使用 peft 库来高效、便捷地实现 LoRA 微调。
提前准备
import torch
# 加载基座模型
model = AutoModelForCausalLM.from_pretrained('/root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507', device_map="auto",torch_dtype=torch.bfloat16)
# 开启模型梯度检查点能降低训练的显存占用
model.enable_input_require_grads() #它的基本思想是 在前向传播过程中不保存中间计算结果,而是在 反向传播时动态地重新计算中间结果
# 通过下列代码即可向模型中添加 LoRA 模块
model = get_peft_model(model, config) #将 LoRA (Low-Rank Adaptation) 模块应用到给定的模型中
config

# 查看 lora 微调的模型参数
model.print_trainable_parameters()

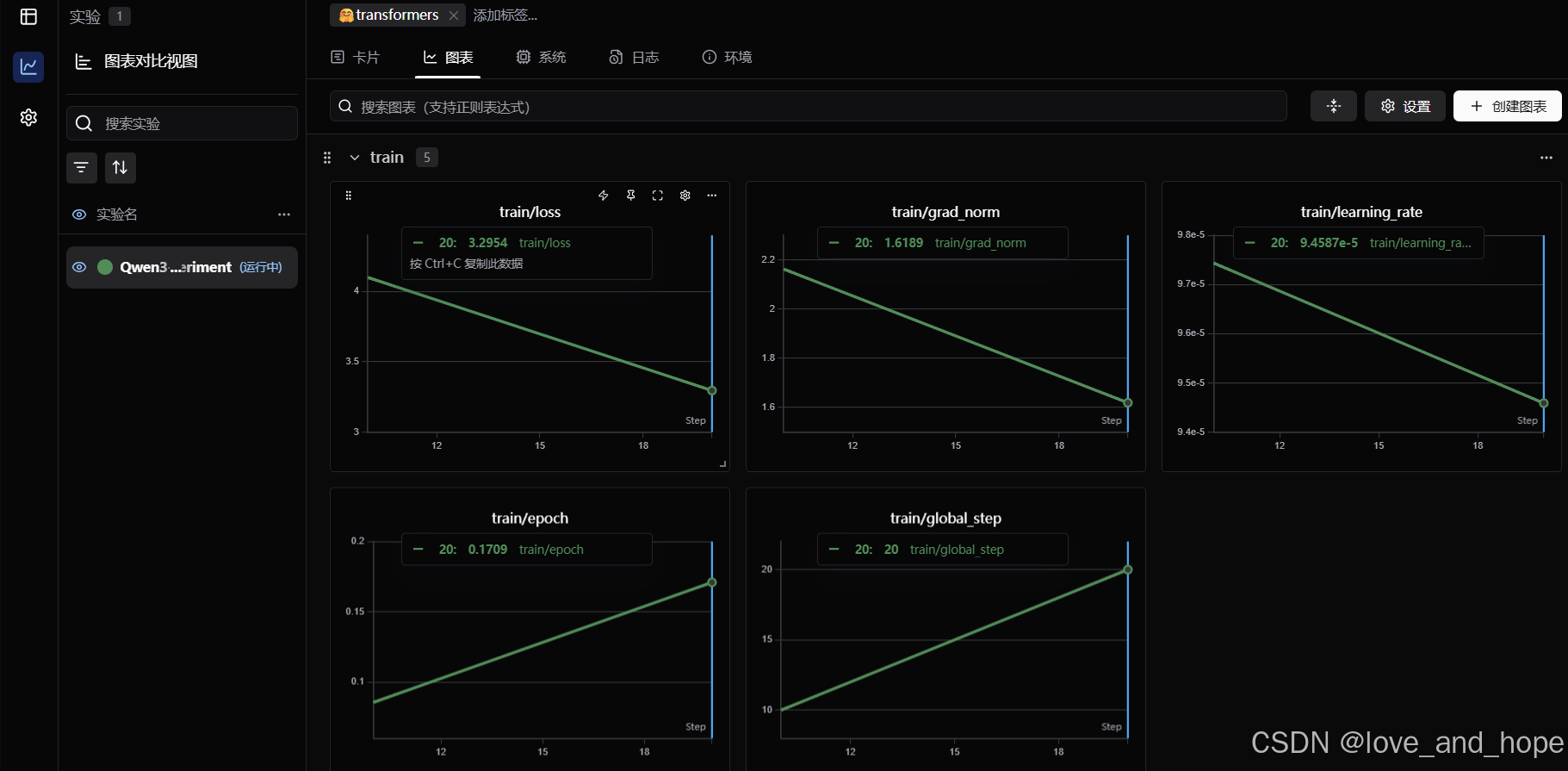
可视化swanlab下训练
swanlab 的 api key 可以通过登录官网注册账号获得:官网
# 配置 swanlab
import swanlab
from swanlab.integration.transformers import SwanLabCallbackswanlab.login(api_key='XXX', save=False)# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(project="Qwen3-4B-lora", experiment_name="Qwen3-4B-experiment"
)
from swanlab.integration.transformers import SwanLabCallback# 配置训练参数
args = TrainingArguments(output_dir="./output/Qwen3_4B_lora", # 输出目录per_device_train_batch_size=16, # 每个设备上的训练批量大小gradient_accumulation_steps=2, # 梯度累积步数logging_steps=10, # 每10步打印一次日志num_train_epochs=3, # 训练轮数save_steps=100, # 每100步保存一次模型learning_rate=1e-4, # 学习率save_on_each_node=True, # 是否在每个节点上保存模型gradient_checkpointing=True, # 是否使用梯度检查点report_to="none", # 不使用任何报告工具
)
# 然后使用 trainer 训练即可
trainer = Trainer(model=model,args=args,train_dataset=tokenized_id,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True), #这是一个针对序列到序列任务的数据处理器。它的作用是在每个批次的数据加载过程中,自动将输入和目标序列对齐并填充,使得所有序列的长度一致,从而可以批量输入到模型中#DataCollatorForSeq2Seq 确保所有输入都能以适当的形式合并成一个批次,通常是一个二维的张量,其中每一行是一个已经填充的序列。这些张量可以直接传递到模型中callbacks=[swanlab_callback]
)
# 开始训练
trainer.train()