[论文阅读] 人工智能 + 软件工程 | 当传统调试遇上LLM:CodeHinter为新手程序员打造专属辅助工具
当传统调试遇上LLM:CodeHinter为新手程序员打造专属辅助工具
论文信息
- 论文原标题:CodeHinter: Guiding Novice Programmers in Debugging with Traditional Techniques and Large Language Models
- 主要作者及研究机构:新加坡科技与设计大学(Singapore University of Technology and Design, SUTD)团队
- APA引文格式:Authors. (2025). CodeHinter: Guiding Novice Programmers in Debugging with Traditional Techniques and Large Language Models. arXiv preprint arXiv:2509.21067.
一段话总结
为解决新手程序员调试时过度依赖AI、难以独立排查语义错误的问题,新加坡科技与设计大学团队设计了VS Code扩展工具CodeHinter。该工具融合传统故障定位技术(FauxPy)与LLM(GPT-4o),通过端到端测试、错误定位、提示测验、打印语句插入等引导式功能,推动新手主动参与调试。以10名本科生为对象的实验显示,CodeHinter的SUS可用性评分达75/100(高于对比工具SID的65/100),整体满意度89/100,其中端到端测试和错误定位是最受认可的功能,为AI辅助编程工具的“个性化设计”提供了实践依据。
思维导图
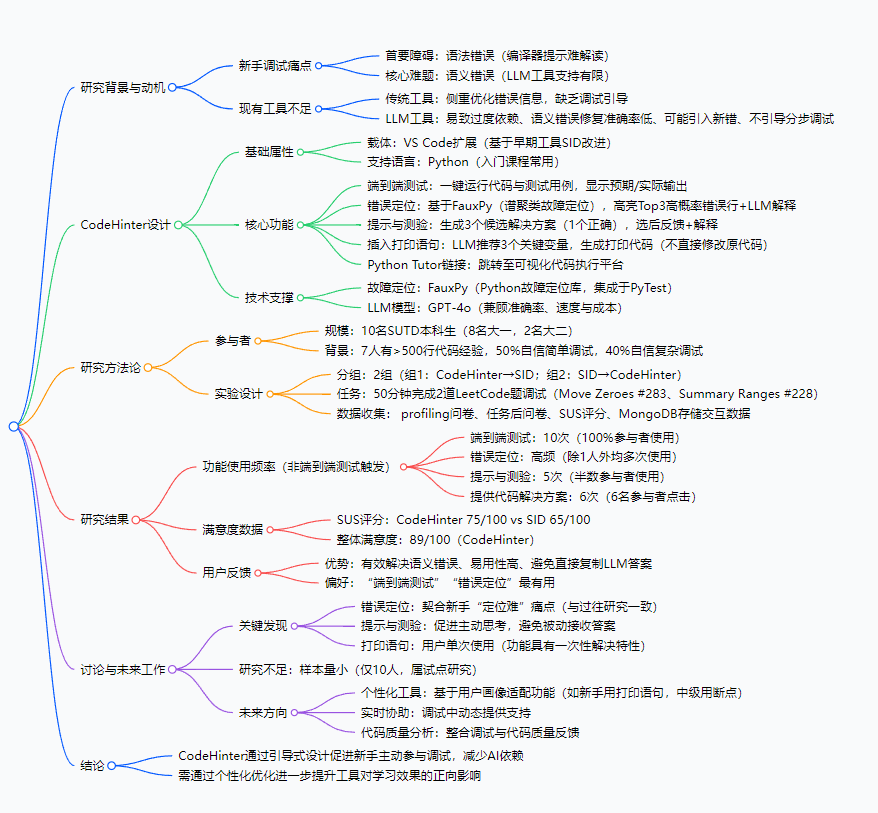
研究背景
对新手程序员来说,调试可能是比写代码更头疼的事——就像刚学做饭的人,不仅要学炒菜步骤,还得搞懂“盐放多了”“火太大糊锅”这些问题怎么排查。
具体来看,新手调试有两大拦路虎:语法错误和语义错误。语法错误比如少个分号、变量名拼写错,编译器会给提示,但这些提示对新手来说像“天书”,比如Python的SyntaxError: invalid syntax,新手可能盯着报错行看半天也找不到问题;更难的是语义错误——代码能跑但结果不对,比如想把数组里的0移到末尾,结果非零元素顺序全乱了,这种时候编译器“沉默是金”,新手只能靠“瞎猜”或直接搜AI答案。
而现有工具要么“帮不上忙”,要么“帮过了头”:传统调试工具只给错误信息,不教怎么一步步找问题;ChatGPT这类LLM工具虽然能给解决方案,但往往直接甩一个完整代码块,新手复制粘贴完还是不懂自己错在哪,久而久之养成“伸手党”习惯,独立调试能力根本没提升。就像学数学时直接看答案,下次遇到同类题还是不会做。
正是看到这种“AI辅助反而阻碍学习”的矛盾,研究团队才决定设计一款既能用AI帮忙,又能逼着新手主动思考的调试工具——CodeHinter。
创新点
CodeHinter的核心创新在于**“引导而非替代”**,跳出了“要么纯手动、要么全AI”的怪圈,主要有三个亮点:
-
技术融合:传统工具+LLM双剑合璧
不像纯LLM工具靠“猜”错误,CodeHinter先用传统的FauxPy故障定位技术(就像用检测仪精准找电路故障)算出错误概率最高的3行代码,再让GPT-4o解释这些行可能错在哪,既保证定位准确性,又用自然语言降低理解门槛。 -
引导式交互:让新手“动脑子”而非“抄答案”
当检测到错误时,它不直接给正确代码,而是出一道“选择题”——给3个候选解决方案(只有1个对),新手选完后会收到反馈和解释。这种设计就像老师讲题时先提问,再讲解,逼着新手主动分析自己的错误。 -
新手友好的功能适配
研究发现新手更习惯用“打印语句”看变量值,而非专业的“断点调试”,所以CodeHinter专门设计了“插入打印语句”功能:GPT-4o推荐关键变量,生成打印代码,新手只需手动粘贴到原代码里——既简化了操作,又让新手清楚“为什么要看这个变量”,而不是盲目加打印。
研究方法和思路
CodeHinter的研发和验证分两大步,就像先设计一款产品,再找用户测试好不好用:
第一步:工具设计(把“引导式调试”落地成功能)
- 选载体和技术:基于VS Code做扩展(因为新手常用VS Code),支持Python(入门主流语言);故障定位用FauxPy(Python生态成熟的故障定位库),LLM选GPT-4o(平衡准确率、速度和成本)。
- 设计核心功能:围绕“测试-定位-提示-验证”的调试流程,做了5个模块:
- 端到端测试:一键运行代码和测试用例,直接显示“预期输出vs实际输出”,比如“想得到[1,3,0,0],结果得到[0,1,3,0]”;
- 错误定位:用FauxPy算出错误概率最高的3行,高亮显示并让GPT-4o解释“这行可能错在没保存非零元素的原始顺序”;
- 提示与测验:给3个候选修复方案,比如“方案A:用sort排序;方案B:遍历数组时保存非零元素再补0;方案C:直接反转数组”,新手选完告诉你对不对,再讲为什么;
- 插入打印语句:推荐“当前遍历的元素值”“非零元素的索引”等关键变量,生成
print("当前元素:", num)这样的代码; - Python Tutor链接:跳转至代码可视化平台,像“慢动作”一样看代码执行过程。
第二步:实验验证(看工具对新手到底有没有用)
- 找参与者:10名新加坡科技与设计大学本科生,8个大一(刚学完入门编程)、2个大二,其中7人有500行以上代码经验,但一半人对复杂调试没信心——典型的“有基础但调试弱”的新手群体。
- 设计实验:把10人分成2组,一组先用法CodeHinter调试,再用早期工具SID;另一组反过来,避免“先入为主”的偏见。每人50分钟内完成2道LeetCode题调试:“移动零”和“汇总区间”,这两道题语义错误场景多,适合测试工具效果。
- 收集数据:通过前置问卷了解参与者背景,后置问卷收集满意度,同时用数据库记录他们点了哪些功能、用了多少次,最后用SUS(系统可用性量表)给工具打分(满分100,68分以上算良好)。
主要成果和贡献
CodeHinter的实验结果可以用“功能受欢迎、用户超满意”来概括,具体成果如下:
| 评估维度 | 具体内容 |
|---|---|
| 功能使用率 | 端到端测试:100%参与者使用(10/10);错误定位:90%参与者使用(9/10);提示与测验:50%参与者使用(5/10) |
| 可用性评分 | SUS评分:CodeHinter 75/100,显著高于对比工具SID的65/100(68分以上为良好) |
| 整体满意度 | 89/100,远超SID的60/100,多数用户反馈“终于不用瞎猜错误了” |
| 核心贡献 | 1. 验证了“传统技术+LLM引导式设计”在新手调试中的有效性;2. 为AI辅助编程工具提供“避免过度依赖”的设计范式;3. 发现新手对“测试/定位”功能需求最高,为后续工具优化指明方向 |
这些成果的价值在于:它打破了“AI辅助编程=直接给答案”的误区,证明AI可以成为“教练”而非“代打”。对教育场景来说,CodeHinter这样的工具能让新手在调试中真正学会“排错逻辑”,而不是只会复制AI代码;对工具开发者来说,它提供了“用户画像驱动功能设计”的思路——比如新手需要简单直观的打印语句,中级用户可能需要断点调试,未来工具可以更“千人千面”。
目前论文暂未提及开源代码或数据集,后续若有更新可关注arXiv原文链接。
关键问题
-
CodeHinter和普通LLM调试工具最大的区别是什么?
普通LLM工具是“给答案”,CodeHinter是“教方法”。比如同样是“移动零”代码错误,ChatGPT直接给正确代码,而CodeHinter会先指出“第5行循环条件错了”,再给3个候选修复方案让你选,选完还解释为什么对——逼你主动思考错误原因。 -
为什么“端到端测试”和“错误定位”是最受欢迎的功能?
这两个功能精准戳中新手痛点:端到端测试让新手“一眼看到问题”(预期vs实际输出对比),不用自己手动输测试用例;错误定位帮新手“缩小排查范围”,不用从第一行代码看到最后一行,就像找东西时有了“寻宝线索”,效率大幅提升。 -
CodeHinter未来的“个性化设计”具体会怎么做?
可能会先通过问卷或交互数据给用户贴“标签”:比如“纯新手”“有基础新手”“中级用户”;然后适配功能:纯新手默认显示打印语句推荐,中级用户默认显示断点调试;甚至提示难度也会调整——新手给更具体的提示,中级用户给更抽象的引导。 -
实验样本只有10人,结果靠谱吗?
研究团队也提到这是“试点研究”,样本量小是局限,但实验设计用了“交叉分组”(两组互换工具),减少了顺序偏见;且收集了详细的交互数据(功能点击、聊天记录),用户反馈也高度一致(比如90%用错误定位功能),所以结果有一定参考价值,后续扩大样本量后会更严谨。
总结
CodeHinter通过“传统故障定位+LLM引导式交互”的设计,成功解决了新手调试时“过度依赖AI”和“不会排错”的双重问题。实验证明,它不仅可用性优于传统工具,还能真正推动新手主动思考,让AI辅助从“阻碍学习”变成“促进学习”。
未来,随着个性化功能的加入,这类“教练型”编程工具可能会成为新手学习的标配——既不用在调试中“孤军奋战”,也不会在AI的“温柔乡”里失去独立解决问题的能力。对编程教育和AI辅助工具开发来说,这无疑是一个值得深耕的方向。