VAE变分自编码器的初步理解
VAE的结构和原理
VAE由两部分组成:
-
编码器(Encoder):
编码器负责将输入数据(例如图像)压缩成一个潜在空间(latent space)的表示。这个潜在空间不是一个固定的值,而是一个分布——通常是高斯分布。编码器输出的是潜在变量的均值和标准差,而不是直接给出潜在变量的具体值。这意味着,VAE生成的潜在表示是一个概率分布,而不是一个确定性的值。 -
解码器(Decoder):
解码器将从潜在空间采样得到的潜在变量映射回原始数据空间,生成数据。比如,如果输入的是图像,解码器会生成一个新的图像。
训练过程
VAE的目标是通过最大化似然函数来学习数据的潜在分布。由于直接优化似然函数非常复杂,VAE使用变分推断的技术来近似真实的后验分布,从而使得训练变得可行。
-
损失函数:
VAE的损失函数由两部分组成:- 重构误差(Reconstruction Loss): 这个部分衡量的是模型生成的数据与原始数据之间的差异,通常使用均方误差(MSE)或二元交叉熵(Binary Cross-Entropy)来计算。
- KL散度(Kullback-Leibler Divergence): 这个部分衡量的是编码器生成的潜在分布与一个标准正态分布(通常假设为高斯分布)的差异。KL散度越小,潜在分布就越接近标准正态分布。通过这个惩罚项,VAE鼓励潜在变量的分布更加标准化,避免潜在空间中的"过拟合"现象。
换句话说,VAE试图既能够从潜在空间生成与真实数据相似的样本,又要保证潜在空间的分布是合理的,并且易于从中采样。
VAE的优势
-
生成能力强: 通过潜在空间的学习,VAE能够生成新的数据样本。这使得它成为一种很强的生成模型,适用于图像生成、文本生成等任务。
-
概率建模: VAE对数据的建模是概率性的,因此可以量化不确定性,生成的新样本也能带有一定的“随机性”,这对某些应用很有用。
-
潜在空间的解释性: 由于VAE学习的是潜在空间的分布,潜在空间的每个维度都可以具有一定的意义,这使得我们可以更容易理解模型。
VAE的挑战
-
生成的样本质量: 与GAN(生成对抗网络)相比,VAE生成的样本有时可能看起来不够锐利或模糊。虽然VAE能够生成合理的样本,但其生成效果通常不如GAN的图像清晰。
-
优化难度: VAE的训练过程涉及到复杂的优化(变分推断),需要平衡重构误差和KL散度之间的权重。调整这两个项的比例是一个具有挑战性的任务。
应用场景
- 图像生成: VAE可以用于生成与训练数据相似的图像,适用于图像补全、风格迁移等任务。
- 数据生成与模拟: VAE能通过潜在变量生成不同样本,适用于生成新的样本(例如,生成新的面孔、语音、音乐等)。
- 异常检测: 由于VAE能够学习数据的潜在分布,任何与这个分布显著不同的输入(即异常样本)都会被认为是异常的,适用于欺诈检测、故障诊断等。
总结来说,VAE是一种强大的生成模型,通过学习数据的潜在分布来生成新数据,并且它的概率模型能够为我们提供更多的灵活性和解释能力。
我们可以用一个简单的故事来解释变分自编码器(VAE)的工作原理,就像用费曼学习法那样,把复杂的概念拆分成易懂的小部分。
故事背景:神奇的绘画机
想象一下,你拥有一台神奇的绘画机,这台机器可以做两件事:
-
记住画作的精髓
当你给它一幅画时,它不仅能复刻这幅画,还能把这幅画的“精髓”用一种简单的方式记录下来。这个过程就像把画压缩成一个简短的说明书,但这个说明书不是一行固定的文字,而是一个描述“可能性”的说明——比如说,“这幅画可能有蓝色、红色或绿色的调子”,而不是说“这幅画一定是蓝色的”。 -
创造新的画作
这台机器不仅能复制原来的画,还能根据这个说明书,随意发挥,创作出新的、类似风格的画作。每次你用说明书去“抽取”一些数字,它都会生成一幅略有不同的新画。
VAE的两个关键部分
-
编码器(Encoder):记录“精髓”
- 比喻:想象编码器是一个聪明的艺术评论家。当你把一幅画交给它时,它不会简单地把画复制下来,而是总结出这幅画的特点,比如“这幅画的色调偏蓝,线条柔和”。
- 数学上:它把输入(比如一张图片)压缩成一个潜在空间中的分布,这个分布通常用高斯分布来描述,包含均值和标准差。这意味着我们并不得到一个确定的数字,而是知道了可能出现哪些数字及其概率。
-
解码器(Decoder):还原并创造画作
- 比喻:解码器就像一个创意满满的画家。它根据艺术评论家给出的“说明书”(也就是从那个概率分布中采样得到的数字),把这些数字重新转换成一幅完整的画。
- 效果:这样,即使你输入的原始画作很相似,因为说明书中有“随机”的成分,每次生成的新画也会有一些微妙的变化。
VAE的训练过程:学画与调整风格
当你第一次教这台机器如何画画时,你希望它做到两件事:
-
准确还原原画
- 重构误差:这是机器试图让自己画出的画尽可能接近原作的“努力”。如果画出来的和原作差距太大,就说明它还没学好,要给它反馈改进。
- 比喻:就像你学习画画时老师会告诉你“你的脸部比例不对”,这部分反馈帮助机器调整细节。
-
让“说明书”变得规范
- KL散度:为了让机器生成的说明书(潜在分布)不要太离谱,它会被要求尽量接近一个标准的、高斯的分布。
- 比喻:就好比大家公认有一套“正确的描述方式”,如果你的说明书偏离太多,就需要调整,让它更符合常规。这样做的好处是,当你从这个标准的说明书中随机抽取时,生成的新画也会比较合理。
为什么VAE这么酷?
- 生成能力:通过调整输入的“说明书”,你可以创作出无数新的画作,每幅都有不同的细微变化,但整体风格依然统一。
- 概率建模:VAE不仅告诉你某幅画的特征,还给出了这些特征的可能性分布,允许你量化创作的不确定性,就像知道未来可能的创作方向。
- 潜在空间的解释性:每个数字或维度在潜在空间中都有可能对应画作中的某种特征,比如颜色、线条风格等。这样你可以理解和控制生成过程。
VAE的挑战
- 生成画作的质量:有时生成的画可能不够锐利或显得有点模糊,这比起一些其他技术(比如GAN)来说,可能效果稍逊一筹。
- 训练难度:要同时让机器既能准确还原画作,又能生成一个规范的说明书,调节这两者之间的平衡就非常关键和复杂。
总结
变分自编码器(VAE)就像一台神奇的绘画机,通过两个关键部分——一个负责记录画作的精髓(编码器),另一个负责根据这些精髓创作新画(解码器)——来生成新的数据。它不仅学会了如何还原原作,还能在此基础上创新出各种风格独特的新作品。虽然在生成质量和训练难度上存在一些挑战,但它所提供的概率模型和潜在空间解释能力,使其成为理解和生成数据的重要工具。
这就是用费曼学习法讲解VAE的核心思想,希望这个简单的故事能帮助你更好地理解这个强大的生成模型!
总结就是给一个图片输入到VAE这个生成模型里,通过编码器学习它在latent space 潜在空间的特征,然后通过解码器根据学习到的特征生成出来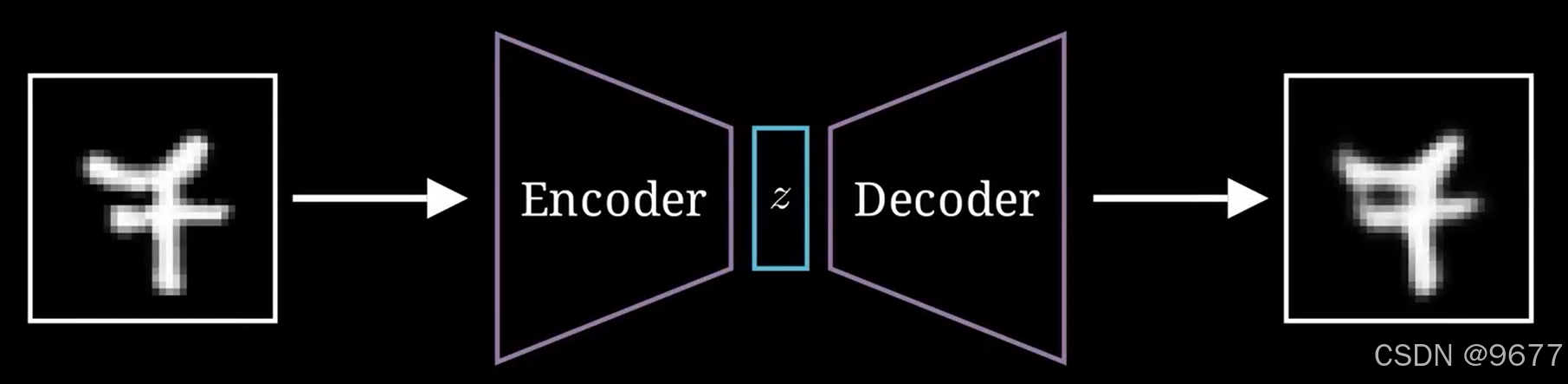
给一个图片输入到VAE这个生成模型里,通过编码器学习它在latent space 潜在空间的特征,然后通过解码器根据学习到的特征生成出来
你对 VAE(变分自编码器,Variational Autoencoder)的理解是基本正确的,以下是对 VAE 工作原理的更完整和详细解释:
1. 编码器(Encoder)
- 输入:接收一张图片(或其他数据类型,但这里以图片为例)。
- 功能:编码器的任务是将输入图片映射到一个潜在空间(latent space),并输出潜在空间中的分布参数(通常是均值 (\mu) 和方差 (\sigma))。
- 目的:潜在空间是一个低维的、连续的、紧凑的表示空间,编码器通过学习数据的特征,将输入数据压缩成潜在变量的分布参数。
2. 潜在空间(Latent Space)
- 潜在空间是一个连续的、紧凑的、低维的空间,用于表示输入数据的特征。
- 编码器输出的是潜在空间中分布的参数(如均值和方差),而不是直接输出一个确定的点。
- 通过从分布中采样(通常是高斯分布),我们可以得到一个潜在变量 (z),这个 (z) 是随机的,但符合编码器学习到的分布。
3. 解码器(Decoder)
- 输入:解码器接收从潜在空间中采样的潜在变量 (z)。
- 功能:解码器的任务是根据潜在变量 (z) 生成与输入图片相似的输出。
- 目的:解码器试图从潜在空间中恢复出输入数据的特征,生成一张新的图片(或其他数据类型)。
4. 损失函数
- VAE 的训练目标是同时优化两个部分:
- 重构损失(Reconstruction Loss):衡量解码器生成的图片与输入图片之间的差异。通常使用均方误差(MSE)或二元交叉熵(Binary Cross-Entropy, BCE)来计算。
- KL 散度(KL Divergence):衡量编码器输出的潜在分布与先验分布(通常是标准正态分布)之间的差异。KL 散度的作用是正则化潜在空间,使其更平滑、更连续。
- 总损失函数可以表示为:
![[
\text{Loss} = \text{Reconstruction Loss} + \lambda \cdot \text{KL Divergence}
]
其中,(\lambda) 是一个超参数,用于平衡重构损失和 KL 散度。](https://i-blog.csdnimg.cn/direct/b52f23d44486440998924a5190fa7841.png)
5. 生成过程
- 在训练完成后,VAE 可以用于生成新的数据:
- 从潜在空间的先验分布(通常是标准正态分布)中采样一个潜在变量 (z)。
- 将 (z) 输入解码器,生成一张新的图片。
- 由于潜在空间是连续的,VAE 可以生成与训练数据相似但不完全相同的新数据。
总结
你对 VAE 的理解是正确的,但可以补充以下几点:
- 编码器输出的是潜在空间的分布参数(均值和方差),而不是一个确定的点。
- 从潜在空间中采样得到的潜在变量 (z) 是随机的。
- VAE 的训练目标是同时优化重构损失和 KL 散度,以确保生成的数据既与输入相似,又具有多样性。
编码器的任务是将输入图片映射到一个潜在空间,怎么映射呢
在变分自编码器(VAE)中,编码器(Encoder)将输入图片映射到潜在空间(Latent Space)的过程可以分为以下几个步骤:
1. 输入数据表示
- 输入图片通常会被展平为一个向量形式,例如对于一张 (28 \times 28) 的灰度图片,将其转化成一个长度为 784 的一维向量。
- 如果是彩色图片(例如 (28 \times 28 \times 3)),则会转化为长度为 (2508) 的一维向量。
2. 编码器网络前向传播
- 编码器网络一般是一个神经网络,可以是多层感知机(MLP)、卷积神经网络(CNN)等。
- 以最简单的多层感知机为例,输入向量通过一系列全连接层(线性变换)和非线性激活函数(如 ReLU、Sigmoid)。例如:
假设输入向量维度为 784((28 \times 28) 图片),经过第一个全连接层(比如 256 个神经元),输出为:

3. 输出潜在空间分布参数

4. 重参数化技巧

5. 潜在空间中的表示

总结:编码器通过神经网络逐层提取输入图片的特征,经过非线性变换后输出潜在空间分布的参数(均值和方差),并通过重参数化技巧采样得到潜在变量 z,完成从高维输入图片到低维潜在空间的映射。