苏州做网站建设seo排名如何优化
1. Spark-SQL是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
Hadoop与Spark的对比
Hadoop的局限性
Hadoop无法处理结构化数据,导致一些项目无法推进。
例如,MySQL中的数据是结构化的,Hadoop无法直接处理。
Spark的出现
Spark解决了Hadoop无法处理结构化数据的问题。
Spark推出了Spark SQL模块,专门用于处理结构化数据。
Spark SQL的特点
数据兼容性
Spark SQL不仅兼容Hadoop,还可以从RDD文件和真实文件中获取数据。
未来版本将支持RDBMS数据和NoSQL数据。
性能优化
Spark SQL引入了cost model,对查询进行动态评估,获取最佳物理计划。
组件扩展方面,Spark SQL的语法解析器、分析器和优化器都可以重新定义和扩展。
Spark SQL的使用
什么是DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。
DataFrame 与 RDD 的主要区别:前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。
创建DataFrame
使用SparkSession对象读取数据文件,创建DataFrame。
DataSet 是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。
DataSet的优点:
- DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
- 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
- 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
- DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
- DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
创建 DataFrame
在 spark 的 bin/data 目录中创建 user.json 文件
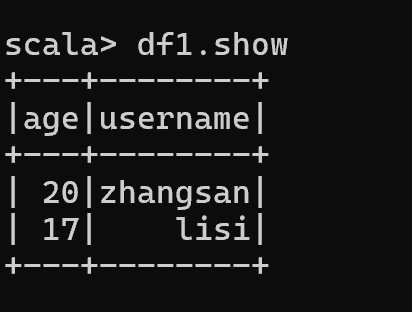
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
读取 json 文件创建 DataFrame
val df1 = spark.read.json("E:\\software\\spark\\spark-3.0.0-bin-hadoop3.2\\bin\\data\\user.json")(此处要选择正确的路径)

SQL语法
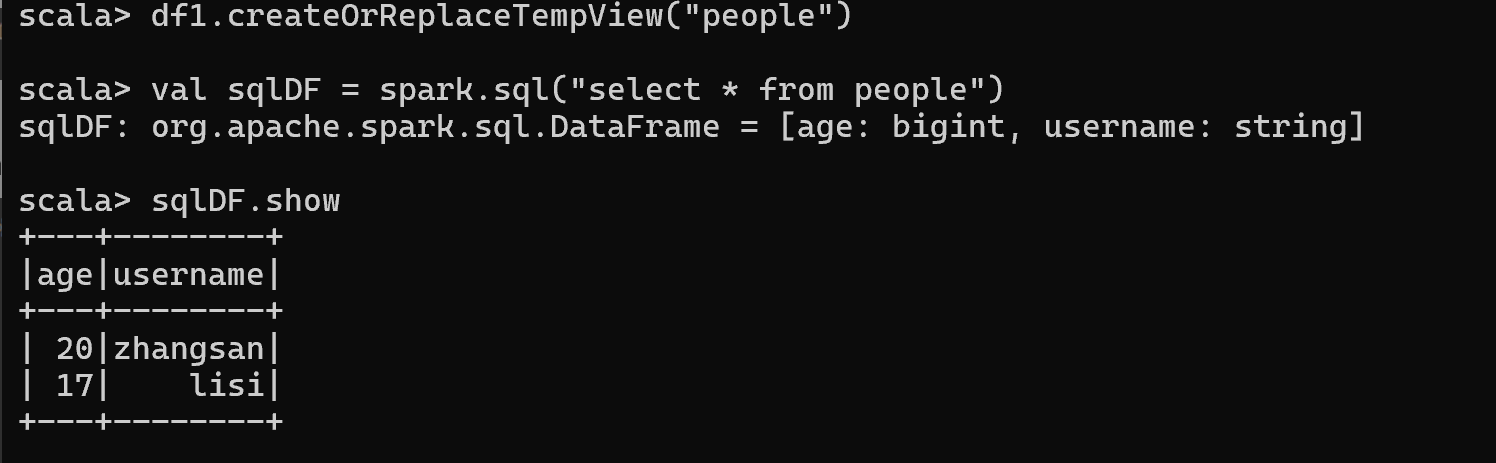
Spark SQL支持SQL语句查询,需要创建临时视图或全局视图。
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要
有临时视图或者全局视图来辅助
示例
1.读取 JSON 文件创建 DataFrame
val df1 = spark.read.json("E:\\software\\spark\\spark-3.0.0-bin-hadoop3.2\\bin\\data\\user.json")

2.对 DataFrame 创建一个临时表
DSL语法
1.创建一个 DataFrame
val df = spark.read.json("data/user.json")
2.查看 DataFrame 的 Schema 信息
-
df.printSchema
3.只查看"username"列数据
-
df.select("username").show()
-
4.查看"username"列数据以及"age+1"数据
-
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
df.select($"username",$"age" + 1).show
-
5."age"大于"18"的数据
-
df.filter($"age">18).show
-
6.按照"age"分组,查看数据条数
-
df.groupBy("age").count.show
-
RDD与DataFrame的转换
-
那么需要引入 import spark.implicits._ 这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
RDD转DataFrame
使用toDF()函数将RDD转换为DataFrame。
DataFrame转RDD
使用rdd属性将DataFrame转换为RDD。
示例代码展示了如何遍历DataFrame并获取具体数据。
解决类加载报错的方法
检查对象名是否一致:确保对象名和类名一致。
设置根目录:将当前代码设为根目录,确保右击设置成功。
创建和转换DataSet
根据样例类创建DataSet:使用case class定义样例类,添加数据后转换为DataSet。
根据RDD创建DataSet:通过RDD映射后使用toDS方法转换。
RDD与DataSet的转换:RDD使用toDS转换为DataSet,DataSet使用toDF转换为DataFrame。
RDD、DataFrame和DataSet的关系与区别
共性:
分布式弹性数据集:三者都是Spark平台下的分布式数据集。
惰性机制:转换操作不会立即执行,只有在行动算子触发时才执行。
自动缓存:根据Spark内存自动缓存运算,支持分区概念。
模式匹配:可以使用模式匹配获取字段值和类型。
区别:
RDD:主要用于机器学习库MLLIB,不支持Spark SQL操作。
DataFrame:每一行的类型固定为ROW,需要解析才能获取字段值。
DataSet:强类型数据集合,每一行的数据类型明确,可以直接获取字段值。
RDD、DataFrame和DataSet的相互转换
RDD转换为DataFrame和DataSet:使用toDF和toDS方法。
DataFrame转换为RDD和DataSet:使用rdd方法和as方法。
DataSet转换为DataFrame和RDD:使用toDF方法和rdd方法。