LangChain核心组件之---Chain(链)
LangChain核心组件之---Chain(链)
- 一、背景
- 二、chain 的核心特性
- 三、chain-基础链
- 3.1. LLMchain简单链
- 3.2. SequentialChain顺序链
- 3.3. RouterChain路由链
- 3.4. TransformChain转换链
- 四、合并文档链
- 4.1 stuff链
- 4.2 refine链
- 4.3 MapReduce链
- 4.4 MapRerank链
- 五、控制流
- 5.1 条件分支
- 5.2 自定义逻辑
- 5.3 并行执行
- 六、 实战场景
- 七、Chain 总结
一、背景
在 LangChain 的世界里,所有组件(Prompt、Model、Retriever)都是 “Runnable(可运行对象)”—— 而 Chain 就是把这些 Runnable 按逻辑顺序连接起来的 “管线”。
举个简单的例子:
- 单步操作:用 Prompt 模板生成问题→用 Model 回答(
prompt | model); - 多步流程:用 Retriever 查知识库→用 Prompt 整合上下文→用 Model 生成回答(
retriever | prompt | model)。
之前的示范例子中,我们需要写很多代码才能实现一个RAG的问答系统,但是使用chain 可以更加简洁实现。
二、chain 的核心特性
LangChain 的 Chain 组件核心价值在于提供标准化的流程串联方式,同时解决手动编码串联组件时可能遇到的复杂性和扩展性问题。它的优势体现在以下几个方面:
- 简化多步骤流程的组织
当需要串联多个组件(如 “加载文档→分割→生成嵌入→检索→调用 LLM→格式化输出”)时,手动编码需要处理组件间的数据传递、异常处理、状态维护等细节。而 Chain 通过统一的接口(如 run()、invoke() 方法)封装了这些逻辑,让开发者可以用更少的代码实现复杂流程。
例如,一个简单的 “文档检索 + 回答” 流程,用 RetrievalQA 链只需几行代码。
- 内置最佳实践与灵活性平衡
LangChain 提供了多种预定义链(如 LLMChain、SequentialChain、MapReduceChain 等),这些链内置了行业最佳实践。例如:
SequentialChain支持按顺序传递多个步骤的输出(甚至跨步骤传递特定键值);MapReduceChain自动处理大文档的分块处理→汇总逻辑。
同时,链的模块化设计允许你自定义每个环节(如替换提示词模板、修改输出解析器),兼顾了便捷性和灵活性。
- 与生态无缝集成
Chain
天然支持与 LangChain 的其他组件(如 Agent、Memory、Tool)集成。例如,给链添加记忆功能时,只需传入 memory 参数,无需手动处理对话历史的存储和拼接。
- 可扩展性与可维护性
当流程复杂度增加(如添加分支逻辑、条件判断)时,基于 Chain 的代码结构更清晰,便于调试和迭代。例如,RouterChain 可以根据输入动态选择不同的子链处理,比手动用 if-else 串联更易维护。
三、chain-基础链
Chain基类
作用:作为所有链式结构的抽象基类,定义了链式调用的标准接口,统一了组件协作的规范,是实现复杂工作流的基础。
| 方法名 | 描述 | 参数说明 | 返回值类型 |
|---|---|---|---|
invoke | 同步执行链式逻辑(推荐的标准调用方式),处理单个输入并返回结果 | input(输入字典)、config(配置选项) | 字典(含输出结果) |
batch | 同步批量处理多个输入,效率优于循环调用invoke | inputs(输入字典列表)、config(配置) | 列表(多个输出结果) |
stream | 同步流式返回结果(适用于大模型实时输出,逐块返回) | input(输入字典)、config(配置) | 生成器(流式数据) |
astream | 异步流式返回结果(异步场景下的流式输出) | input(输入字典)、config(配置) | 异步生成器 |
abatch | 异步批量处理多个输入(异步场景下的批量调用) | inputs(输入字典列表)、config(配置) | 列表(多个输出结果) |
ainvoke | 异步执行链式逻辑(异步场景下的单个输入处理) | input(输入字典)、config(配置) | 字典(含输出结果) |
相关子类

| 子类名称 | 说明(是什么) | 核心功能 |
|---|---|---|
LLMChain | 最基础的链组件,直接将语言模型(LLM)与提示词模板(PromptTemplate)绑定 | 根据输入参数填充提示词模板,调用语言模型生成对应文本结果,适用于简单文本生成场景 |
SequentialChain | 用于串联多个子链的组件,按预设顺序执行流程 | 自动将前一个子链的输出作为后一个子链的输入,实现多步骤、流水线式的复杂任务处理 |
StuffDocumentsChain | 专门处理文档集合的链,适用于文档总量较小的场景 | 将多个文档内容合并为单一输入,传递给下游模型进行总结、分析等处理,减少调用开销 |
MapReduceDocumentsChain | 处理大规模文档的链,分为 “Map” 和 “Reduce” 两个阶段 | 先对每个文档单独处理生成中间结果(Map),再汇总所有结果得到最终结论(Reduce),适合大量长文档处理 |
RouterChain | 具备动态路由能力的基础链 | 按输入内容选对应子链处理 |
GraphChain | 支持图结构工作流的链(0.3.x 版本新增) | 基于图结构定义节点及跳转逻辑,实现具有复杂分支、循环或依赖关系的任务流程 |
3.1. LLMchain简单链
LangChain v0.1 + 推荐用函数式编程语法(|运算符)定义 Chain,把复杂流程写成 “流水线”:
比如:chain = prompt | model 一个基础链生成
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate# 1. 定义单步模块:Prompt模板 + LLM
prompt = ChatPromptTemplate.from_template("请解释:{topic}")
model = ChatOpenAI(model="gpt-3.5-turbo")# 2. 拼接成Chain:prompt → model
# 先执行接收输入变量并生成完整提示词,再将提示词传递给大模型
chain = prompt | model# 3. 运行Chain
response = chain.invoke({"topic": "LangChain Chain是什么?"})
print(response.content)
这就是 Chain 的最简形态 ——把 “输入→处理→输出” 的单步逻辑连成线,代码简洁到 “一看就懂”。
3.2. SequentialChain顺序链
SequentialChain 串联多个子链,按序执行,自动传参的多步骤链。
顺序链有两种类型:
- SimpleSequentialChain(最简单形式的顺序链,单输入,单输出)
- SequentialChain(一种更通用的顺序链,允许多个输入 / 输出)。
如下代码我创建了3个基础chain(LLMChain)任务,使用SequentialChain串联这三个任务,上一个chain输出会作为下一个chain的输入。
返回最终的输出结果。
full_chain = generator_chain | trans_chain | market_chain 顺序链生成
def test_simple_sequential_chain(modelName: str):"""用于串联多个子链的组件,按预设顺序执行流程 链"""llm = getChatModel(modelName)parser = StrOutputParser()# 步骤1:生成产品描述prompt1 = PromptTemplate(input_variables=["product"],template="为{product}生成一段吸引人的中文描述(50字内)")generator_chain = prompt1 | llm | parser | print_step("中文描述生成") # 产品→中文描述# 步骤2:翻译为英文prompt2 = PromptTemplate(input_variables=["chinese_desc"],template="将以下内容翻译成英文:{chinese_desc}")trans_chain = prompt2 | llm | parser | print_step("英文翻译") # 中文描述→英文描述# 步骤3:生成营销标签prompt3 = PromptTemplate(input_variables=["english_desc"],template="根据英文描述生成3个营销标签(用逗号分隔):{english_desc}")market_chain = prompt3 | llm | parser | print_step("生成营销标签") # 英文描述→营销标签# 用|串联所有步骤,形成完整流程(替代SequentialChain)full_chain = generator_chain | trans_chain | market_chainresp = full_chain.invoke({"product": "小辣堡-喜德盛子品牌自行车"})print("顺序链调用结果:", resp)3.3. RouterChain路由链
具备动态路由能力的基础链 按输入内容选对应子链处理.
如下例子:有三个子链(技术问题、产品问题、售后问题),用户输入问题,先交由路由链执行,判断其归属于哪个问题,选择对应的链执行。

获取路由链
核心方法:我们是通过提示词设置,让路由链帮我们输出需要使用的具体任务子链。
# 核心代码:根据路由结果动态选择子链,用管道符串联完整流程full_chain = (RunnablePassthrough() # 透传原始输入| router_chain # 先执行路由判断,得到{"destination":..., "next_inputs":...}| RunnableBranch( # 根据destination选择子链(lambda x: x["destination"] == "技术问题", tech_chain),(lambda x: x["destination"] == "产品问题", product_chain),(lambda x: x["destination"] == "售后问题", after_sale_chain),default_chain))
具体代码如下:
def getRouterChain(llm: BaseChatModel):"""获取路由链:param llm::return:"""prompt_infos = [{"name": "技术问题","description": "适用于处理产品使用中的技术故障、设置方法等问题",},{"name": "产品问题","description": "适用于咨询产品特点、功能、规格、价格等信息",},{"name": "售后问题","description": "适用于处理退换货、维修、投诉等售后服务问题",}]# 将prompt_infos转换为LLM能理解的文字(提取name和description)prompt_infos_str = "\n".join([f"- 类型:{info['name']}\n 适用场景:{info['description']}"for info in prompt_infos])# 核心:为 next_inputs 定义嵌套结构的 schemaresponse_schemas = [# 1. destination:简单字符串类型(子链名称)ResponseSchema(name="destination",description="子链名称,必须是以下之一:'技术问题'、'产品问题'、'售后问题'",type="string" # 显式指定类型,避免LLM输出其他格式),# 2. next_inputs:嵌套字典(内部包含 input 键)ResponseSchema(name="next_inputs",description="传递给子链的输入参数,固定为包含 'input' 键的字典",# 通过 schema 定义嵌套结构:next_inputs 是字典,内部有 input 字符串字段schema={"type": "object", # next_inputs 是对象(字典)"properties": {"input": {"type": "string","description": "用户原始输入,直接传递给子链的内容"}},"required": ["input"], # 强制要求包含 input 键,避免缺失"additionalProperties": False # 禁止额外字段,保证格式纯净})]output_parser = StructuredOutputParser.from_response_schemas(response_schemas)format_instructions = output_parser.get_format_instructions()print("格式化信息:",format_instructions)# 3. 创建路由链的提示词和解析器router_template = """请根据用户输入,从以下可用问题类型中选择最合适的一种(只能选一个):{prompt_infos_str}用户输入:{input}输出格式必须严格遵循:{format_instructions}"""# 客观的说 使用该方式补充提示词要比 使用ResponseSchema效果好# TODO 如果模型输出不符合下面的要求 考虑使用下面方式代替# router_template = """# 请根据用户输入,从以下可用问题类型中选择最合适的一种(只能选一个):# {prompt_infos_str}# 用户输入:{input}# # 输出格式必须是JSON,且包含以下字段:# {{# "destination": "子链名称(如'技术问题')",# "next_inputs": {{# "input": "传递给子链的用户输入"# }}# }}# """router_prompt = PromptTemplate(input_variables=["input"],template=router_template,partial_variables={"prompt_infos_str": prompt_infos_str,"format_instructions": format_instructions},output_parser=output_parser,)# TODO 手动调试生成的提示词# full_prompt = router_prompt.format(input="小辣宝自行车都有哪些配置和价位")# print("=" * 50)# print("【手动调试:RouterPrompt 完整提示词】")# print(full_prompt)# print("=" * 50 + "\n")# 3. 创建路由链router_chain = LLMRouterChain.from_llm(llm=llm,prompt=router_prompt)return router_chain
路由链调用
def test_router_chain(modelName: str):# 获取语言模型llm = getChatModel(modelName)# 输出解析器parser = StrOutputParser()# 1. 定义子链(使用管道符构建)# 技术问题子链tech_prompt = PromptTemplate(input_variables=["input"],template="你是技术支持专家,简洁解答技术问题:{input}")tech_chain = tech_prompt | llm | parser# 产品问题子链product_prompt = PromptTemplate(input_variables=["input"],template="你是产品顾问,详细介绍产品特点:{input}")product_chain = product_prompt | llm | parser# 售后问题子链after_sale_prompt = PromptTemplate(input_variables=["input"],template="你是售后专员,提供解决方案:{input}")after_sale_chain = after_sale_prompt | llm | parser# 默认链:无法识别时调用default_prompt = PromptTemplate(input_variables=["input"],template="无法识别问题类型,请补充说明:{input}")default_chain = default_prompt | llm | parser# 2. 获取路由router_chain = getRouterChain(llm)# 4. 用RunnableBranch实现动态路由(替代MultiPromptChain)# 核心代码:根据路由结果动态选择子链,用管道符串联完整流程full_chain = (RunnablePassthrough() # 透传原始输入| router_chain # 先执行路由判断,得到{"destination":..., "next_inputs":...}| RunnableBranch( # 根据destination选择子链(lambda x: x["destination"] == "技术问题", tech_chain),(lambda x: x["destination"] == "产品问题", product_chain),(lambda x: x["destination"] == "售后问题", after_sale_chain),default_chain))# 5. 测试(统一用invoke调用,输入格式更简洁)print("=== 技术问题测试 ===")print(full_chain.invoke({"input": "自行车刹车失灵怎么处理?"}))print("\n=== 产品问题测试 ===")print(full_chain.invoke({"input": "小辣堡自行车有哪些颜色可选?"}))print("\n=== 售后问题测试 ===")print(full_chain.invoke({"input": "购买的自行车尺寸不合适,能换货吗?"}))
3.4. TransformChain转换链
转换链(Transformation Chain) 是一类专注于 “数据格式 / 内容转换” 的链。核心作用是将输入数据通过一系列步骤输出为目标格式或结构化内容。它不直接依赖 LLM 生成新内容,而是更侧重 “数据清洗、格式转换、信息提取、结构重组” 等功能性处理。

示例代码如下:
# 定义转换链
def struct_data(inputs: dict) -> dict:"""定义转换链:param inputs: llm:模型IO ,raw_text用户输入信息:return: 格式化数据"""llm = inputs["llm"]# 定义结构化输出的字段(目标格式:产品名称、价格、特点、适用人群)response_schemas = [ResponseSchema(name="product_name", description="产品的正式名称,如'小辣堡自行车'"),ResponseSchema(name="price", description="产品价格,格式为'XX元',如'899元'"),ResponseSchema(name="features", description="产品核心特点,用列表形式呈现,如['轻便', '变速']"),ResponseSchema(name="target_audience", description="适用人群,如'城市通勤族'")]# 结构化输出解析器(确保LLM输出符合字典格式)output_parser = StructuredOutputParser.from_response_schemas(response_schemas)format_instructions = output_parser.get_format_instructions() # 自动生成格式约束# 2. 定义转换链1:LLM提取结构化信息(核心转换逻辑)# 提示词:告诉LLM从非结构化文本中提取指定字段extract_prompt = PromptTemplate(input_variables=["raw_text"],template="""任务:从以下非结构化产品描述中,提取并转换为结构化字典。产品描述:{raw_text}输出要求:{format_instructions}注意:1. 严格按照字段要求提取,不要添加额外字段;2. 若描述中没有某字段(如价格),填充为"未提及";3. 仅返回结构化字典,不要添加其他文字。""",partial_variables={"format_instructions": format_instructions,"raw_text": inputs["raw_text"]})struct_chain = extract_prompt | llm | output_parserstruct_data = struct_chain.invoke(inputs)print("转换结果:",struct_data)return {"structured_data": struct_data}#对输出数据再次校验并修正结构化数据(程序健壮性考虑)
def validate_structured_data(data: dict) -> dict:"""自定义转换逻辑:校验并修正结构化数据- 确保features是列表类型(避免LLM输出字符串)- 统一价格格式(如去除"约"等模糊词)"""# 修正features格式(若为字符串,转为列表)if isinstance(data.get("features"), str):data["features"] = [feat.strip() for feat in data["features"].strip("[]").split(",")]# 统一价格格式(去除"约""大概"等词)price = data.get("price", "未提及")if price != "未提及":data["price"] = price.replace("约", "").replace("大概", "").strip()# 补充字段说明(增强下游可用性)data["extracted_time"] = "2024年" # 示例:添加额外转换字段return datadef test_transform_chain(modelName: str):# LLM转换链:输入非结构化文本 → 输出结构化字典transform_chain = TransformChain(input_variables=["llm","raw_text"], # 输入变量名(与转换函数的inputs键对应)output_variables=["structured_data"], # 输出变量名(与转换函数的返回键对应)transform=struct_data # 转换函数(实现实际转换逻辑))# 用RunnableLambda包装自定义转换逻辑(转为LangChain可调用的链),# 因为langchain的所有组件底层都继承了RunnableSerializable 都是可运行的组件# 对输出结果进行格式化修订validate_chain = RunnableLambda(validate_structured_data)# 4. 组合完整转换链:非结构化文本 → LLM提取 → 格式校验 → 最终结构化数据full_transformation_chain = transform_chain | validate_chain# 其实transform_chain调用输出已经是结构化数据了, 使用transform_chain只是为了程序健壮性# 顺便学习一个如何将一个函数包装成可运行组件,以及顺便复习一下顺序链 # 5. 测试转换链raw_product_text = """【小辣堡通勤自行车】专为城市上班族设计!车身轻便仅12kg,支持3档变速,配色有薄荷绿、深空灰两种,适合160-180cm身高人群使用。官网售价约999元,续航辅助可达20公里,日常通勤超方便~"""# 执行转换链llm = getChatModel(modelName)result = full_transformation_chain.invoke({"llm": llm, "raw_text": raw_product_text})# 输出结果(结构化字典)print("原始输入(非结构化文本):")print(raw_product_text)print("\n转换后输出(结构化字典):")print(result["structured_data"])
四、合并文档链
合并文档链(Combine Documents Chain)是 LangChain 中专门用于 “多文档问答场景” 的核心组件,核心作用是:将多个分散的文档片段(如检索到的多篇文档、单篇文档的多段落)的信息整合、处理,最终生成基于所有文档的统一、连贯回答,解决 “仅用单篇文档回答导致信息片面、遗漏” 的问题。
常用的4大合并链
| 文档链名称 | 说明 | 使用场景 |
|---|---|---|
| StuffChain(直接拼接链) | 将所有文档片段直接拼接成单段文本,一次性传入 LLM,基于完整文本生成回答,无信息丢失。 | 文档数量少、单篇长度短(未超 LLM 上下文窗口),需保留全部细节的场景(如短文档精准问答)。 |
| MapReduceChain(映射 - 归约链) | 分两步处理:1.Map 阶段(单文档生成局部回答);2.Reduce 阶段(整合所有局部回答成最终结果)。 | 文档数量多、总长度超 LLM 上下文窗口,需独立提炼每篇文档信息再整合的场景(如多文档对比问答)。 |
| RefineChain(迭代优化链) | 按顺序迭代处理文档:用第一篇生成初始回答,后续文档依次补充 / 修正已有回答,逐步完善结果。 | 文档间存在递进关系(如基础概念→细节补充→例外说明),需生成精准、完整回答的场景(如技术文档问答)。 |
| MapRerankChain(映射 - 排序链) | 分两步处理:1.Map 阶段(单文档生成局部回答 + 相关性评分);2.Rerank 阶段(筛选高评分回答并整合)。 | 文档中含大量低相关内容(如检索结果混杂无关文档),需优先基于高相关信息回答的场景(如搜索引擎问答)。 |
4大合并链不同维度对比
| 特性 | StuffChain (直接拼接链) | MapReduceChain (映射 - 归约链) | RefineChain (迭代优化链) | MapRerankChain (映射 - 排序链) |
|---|---|---|---|---|
| 核心逻辑 | 全量文档直接拼接成单文本,一次性传给 LLM 生成回答 | 1.Map:单文档生成局部回答;2.Reduce:整合所有局部回答 | 按顺序迭代,用当前文档补充 / 修正已有回答 | 1.Map:单文档生成局部回答 + 相关性评分; 2.Rerank:筛选高评分回答并整合 |
| LLM 调用次数 | 1 次 | N+1 次(N = 文档数) | N 次(N = 文档数) | N+1 次(N = 文档数) |
| 上下文压力 | 大(全量文本需适配 LLM 窗口) | 小(单文档 + 局部回答单独处理) | 小(单文档 + 现有回答迭代) | 小(单文档 + 评分单独处理) |
| 适用场景 | 文档少、短,需完整保留细节 | 文档多、长,突破上下文限制 | 文档有递进关系(补充 / 修正) | 文档含低相关内容,需优先高相关信息 |
| 信息完整性 | 无丢失(全量传递) | 可能丢失文档间关联信息 | 递进补充,完整性高 | 筛选高相关,低相关信息被过滤 |
| 效率 / 成本 | 高效、低成本(1 次调用) | 低效、高成本(多次调用) | 低效、高成本(多次调用) | 低效、高成本(多次调用) |
4.1 stuff链
Stuff 链是 LangChain 中最基础的合并文档链,核心逻辑是将所有文档片段直接拼接成一个长文本,作为完整输入传给 LLM,让 LLM 基于全量文档信息生成回答。
- 优点:无信息丢失(所有文档内容都传递给 LLM)、实现简单;
- 缺点:受 LLM 上下文窗口限制,仅适合文档数量少、总长度短的场景(如单篇短文档、3-5 篇小片段)。
以下是 create_stuff_documents_chain 方法的参数说明表格:
| 参数名 | 类型 | 必填 | 描述 |
|---|---|---|---|
llm | LanguageModelLike | 是 | 大语言模型实例.用于生成回答 |
prompt | BasePromptTemplate | 是 | 提示词模板,定义回答的规则和格式, 需包含文档变量(如 {context}) |
output_parser | Optional[BaseOutputParser] | 否 | 输出解析器,用于将 LLM 生成的原始文本转换 为特定格式(如 JSON、列表等),默认不解析 |
document_prompt | Optional[BasePromptTemplate] | 否 | 文档格式化模板,用于单独文档片段 (如给每篇文档添加前缀 “文档 X:”), 默认直接拼接文档 |
document_separator | str | 否 | 文档之间的分隔符,默认值为 "\n\n"(两个换行符) |
document_variable_name | str | 否 | 提示词中接收文档集合的变量名,默认值为 "documents",需与 prompt 中的变量名一致 |
代码示例如下:
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.documents import Document
from lang_chain_base.chat_models.model_language import getChatModel
def test_stuff_chain(modelName:str):# 1、准备文档片段(可替换为实际业务中的文档,如从文件/数据库读取)docs = [Document(page_content="自行车刹车分为碟刹和V刹,碟刹雨天刹车效果更稳定,适合山地路况"),Document(page_content="V刹结构简单、重量轻,维护成本低,更适合城市通勤骑行"),Document(page_content="自行车刹车日常维护需注意:每月检查刹车线松紧度,每3个月更换一次刹车片")]# 2. 初始化模型llm = getChatModel(modelName)# 3. 定义问答Prompt(明确让LLM基于拼接的文档回答)chat_template = ChatPromptTemplate.from_messages([# 系统消息:包含文档变量和指令("system", """请严格基于以下所有文档内容回答问题,不要编造信息:{input_documents}回答要求:简洁明了,直接对应文档信息。"""),# 用户消息:包含问题变量("human", "用户问题:{question}")])# 4. 初始化Stuff链(指定文档在Prompt中的变量名)#已经过期 StuffDocumentsChain(llm_chain=LLMChain(llm=llm, prompt=chat_template))stuff_chain = create_stuff_documents_chain(llm=llm,prompt=chat_template,document_variable_name="input_documents")# 5. 调用Stuff链生成回答result = stuff_chain.invoke({"input_documents": docs, # 传入文档集合"question": "自行车碟刹和V刹分别适合什么场景?" # 传入用户问题})# 6. 输出结果print("Stuff链回答:")print(result)

根据回答结果,可以知道查询跨了两个文档,所以可以得出三个文档全部合并传递给了大模型。
4.2 refine链
Refine 链是 LangChain 中用于处理多文档的合并文档链之一,核心逻辑是按顺序迭代处理文档,逐步优化回答:
- 先用第一篇文档生成初始回答;
- 处理后续文档时,对比 “现有回答” 和 “当前文档信息”,补充或修正回答;
- 重复步骤 2 直到所有文档处理完毕,最终得到整合所有信息的优化结果。
它特别适合文档间存在递进关系的场景(如 “基础概念→细节补充→例外说明”),能捕捉文档间的关联信息,生成更完整、精准的回答。

RefineDocumentsChain参数说明
| 字段名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
initial_llm_chain | LLMChain | 是 | 处理第一篇文档的链,用于生成初始回答,需包含文档变量和问题变量 |
refine_llm_chain | LLMChain | 是 | 处理后续文档的优化链,需包含 existing_answer(现有回答)变量、文档变量和问题变量 |
document_variable_name | str | 是 | 提示词中接收文档内容的变量名,需与 initial_llm_chain 和 refine_llm_chain 的提示词变量一致 |
initial_response_name | str | 是 | 初始回答在优化阶段的变量名,需与 refine_llm_chain 提示词中的 existing_answer 对应 |
return_intermediate_steps | bool | 否 | 是否返回中间优化步骤,默认 False;设为 True 时,结果中会包含 intermediate_steps 列表 |
input_key | str | 否 | 输入中包含文档的键名,默认 input_documents |
output_key | str | 否 | 输出结果的键名,默认 output_text |
代码如下:
def test_refine_chain(modelName: str):# 1. 初始化LLM(聊天模型,如GPT-3.5/4)llm = getChatModel(modelName)# 2. 定义「初始回答」的提示词与链(处理第一篇文档)initial_prompt = ChatPromptTemplate.from_messages([("system", f"基于以下文档,回答有关的问题,仅用文档信息,不编造内容。"),("human", "文档:{input_documents}\n问题:{question}\n生成初始回答。")])# 旧版需用 LLMChain 包装提示词+LLMinitial_llm_chain = LLMChain(llm=llm, prompt=initial_prompt)# 3. 定义「优化回答」的提示词与链(处理后续文档)refine_prompt = ChatPromptTemplate.from_messages([("system", "基于新文档优化你的回答:保留正确信息,补充新内容,不重复。"),("human", """现有回答:{existing_answer}新文档:{input_documents}问题:{question}判断逻辑:- 若新文档有补充信息:整合优化回答;- 若无新信息:直接返回现有回答。""")])refine_llm_chain = LLMChain(llm=llm, prompt=refine_prompt)# 4. 核心:初始化旧版 RefineDocumentsChain (版本0.3.6 没有提供新的方式,但是提示使用方式已经废弃)refine_chain = RefineDocumentsChain(initial_llm_chain=initial_llm_chain, # 第一篇文档的处理链refine_llm_chain=refine_llm_chain, # 后续文档的优化链document_variable_name="input_documents", # 提示词中接收文档的变量名initial_response_name="existing_answer", # 指定初始回答变量名return_intermediate_steps=True # 是否返回每步优化的中间结果(可选,默认False))# 5. 准备测试文档(递进关系:基础→扩展→场景)docs = [Document(page_content="豆包是智能助手,支持文字对话交互。"), # 基础功能Document(page_content="豆包可生成代码、翻译文本,还能总结文档。"), # 扩展功能Document(page_content="豆包适合程序员写代码、学生做笔记使用。"), # 适用场景Document(page_content="豆包适合程序员写代码、学生做笔记使用。"), # 适用场景]question = "豆包有哪些功能和适用人群?"# 6. 调用 Refine 链生成最终回答result = refine_chain.invoke({"input_documents": docs, # 传入所有文档"question": question # 传入用户问题})# 6. 打印中间结果(每步优化过程)print("中间优化步骤:")for i, step in enumerate(result["intermediate_steps"]):# 第1个元素是初始回答(基于文档1),之后是每轮优化结果(基于文档2、3...)print(f"步骤 {i + 1}:{step}")# 输出结果(旧版结果在 "output_text" 键中)print("最终优化回答:")print(result["output_text"])

根据回答结果,可以知道在基于获取到的文档越来越多的情况下,回来的越来越好。
4.3 MapReduce链
MapReduceChain 是 LangChain 中处理多文档的核心合并链之一,核心逻辑分为两步:
- Map 阶段:对每篇文档单独调用 LLM,生成针对问题的 “局部回答”;
- Reduce 阶段:将所有 “局部回答” 汇总,再调用 LLM 整合成最终统一的回答。
适用于 文档数量多、总长度超过 LLM 上下文窗口 的场景(如 10+ 篇长文档),能突破单轮输入长度限制,但需多次调用 LLM(成本较高)。
流程如下:
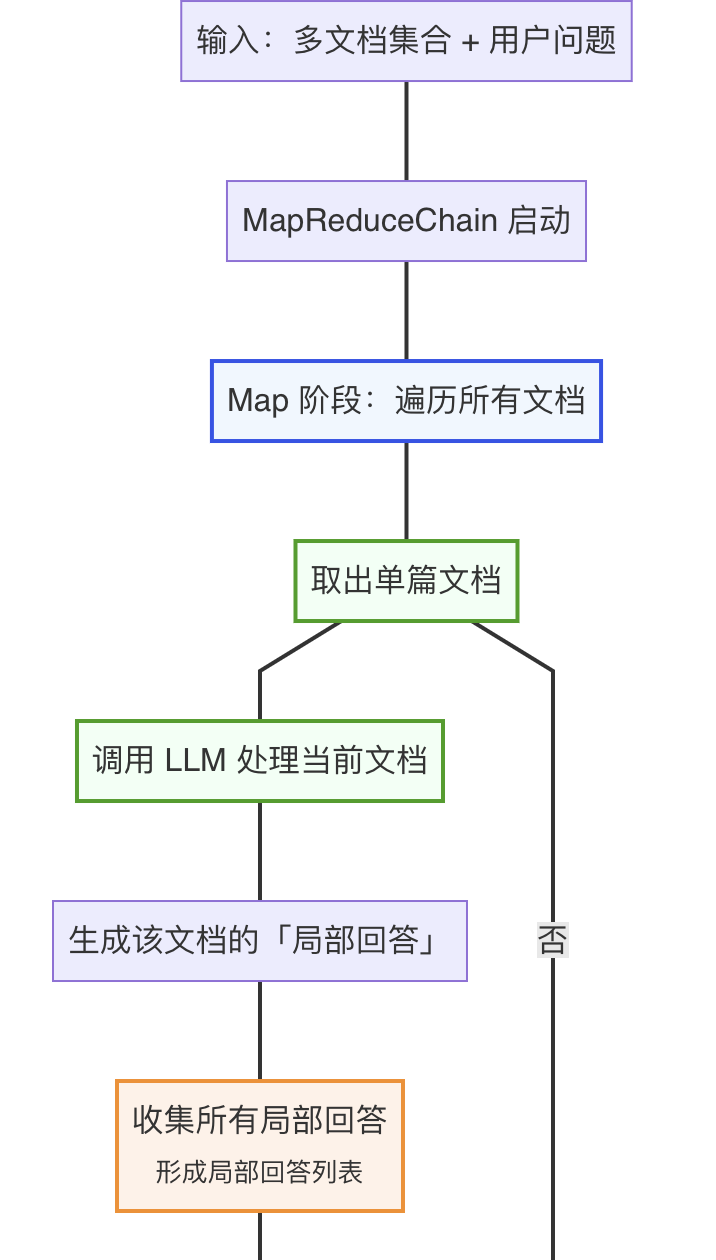
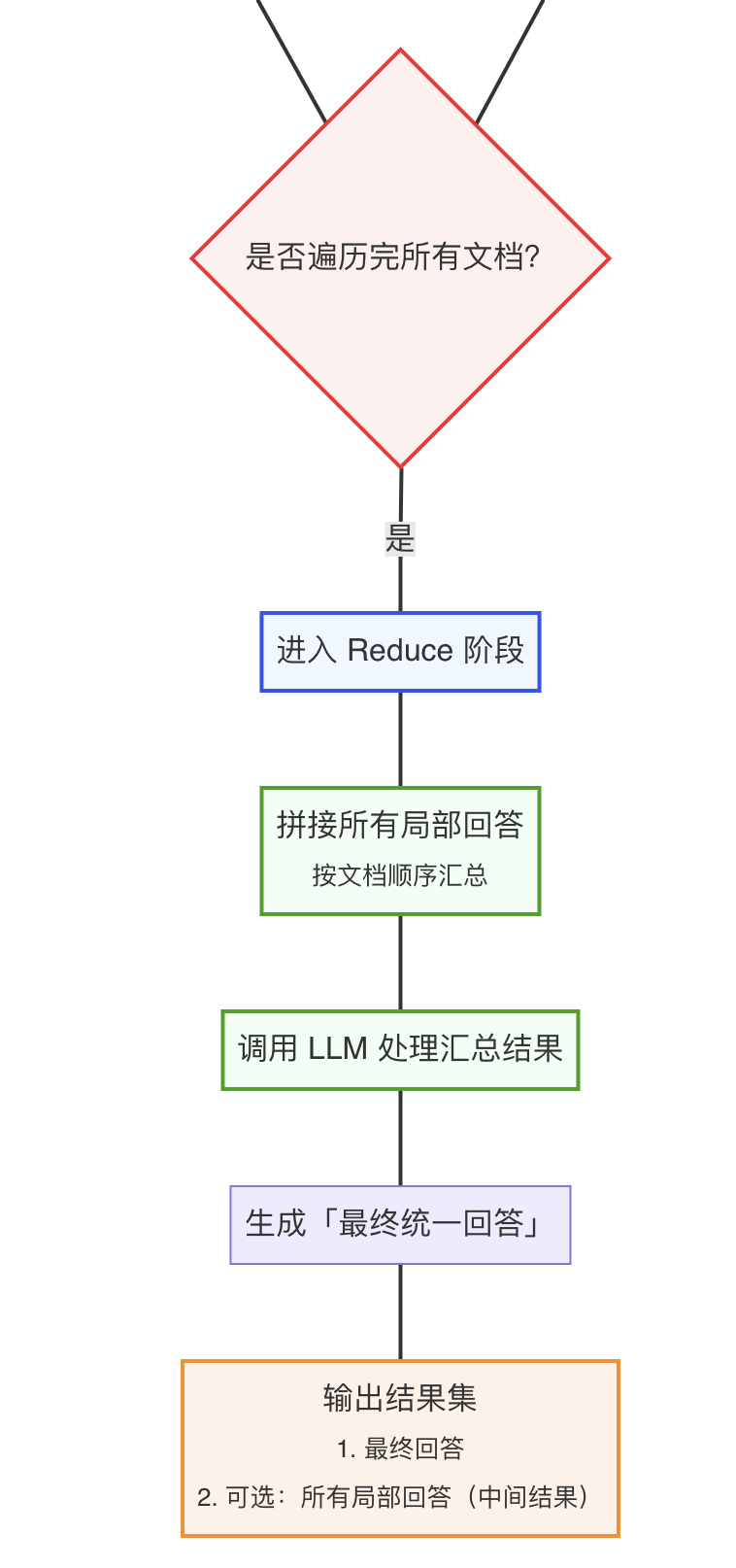
ReduceDocumentsChain 会自动将 Map 阶段生成的 “局部回答列表”(文档对象集合)转换为字符串(如用分隔符拼接),再传入 reduce_chain 的提示词变量(如 {input_documents}),确保 reduce_chain 能正确接收输入。
MapReduceChain参数说明
| 字段名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
map_chain | LLMChain 或 Runnable | 是 | Map 阶段的处理链,用于对单篇文档生成局部回答,需包含文档变量和问题变量 |
combine_document_chain | BaseCombineDocumentsChain | 是 | Reduce 阶段的处理链(要求为 StuffDocumentsChain 实例 版本0.3.6),负责整合所有局部回答。 |
document_variable_name | str | 否 | 提示词中接收文档内容的变量名,默认 input_documents,需与 map 链提示词变量一致 |
return_intermediate_steps | bool | 否 | 是否返回中间结果(Map 阶段的所有局部回答),默认 False |
input_key | str | 否 | 输入中包含文档列表的键名,默认 input_documents |
output_key | str | 否 | 输出结果的键名,默认 output_text |
代码如下
def test_map_reduce_chain(modelName: str):# 1. 初始化 LLMllm = getChatModel(modelName)# 2. Map 阶段:单文档生成局部回答map_prompt = ChatPromptTemplate.from_messages([("system", "基于以下单篇文档回答问题,仅用该文档信息,简洁明了。"),("human", "文档:{input_documents}\n问题:{question}\n局部回答:")])map_chain = LLMChain(llm=llm, prompt=map_prompt)# 3. Reduce 阶段:整合所有局部回答reduce_prompt = ChatPromptTemplate.from_messages([("system", "基于以下多个局部回答,生成最终统一回答,避免重复,逻辑连贯。"),("human", "所有局部回答:{input_documents}\n问题:{question}\n最终回答:")])reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)# 4. 包装 Reduce 链(指定文档拼接方式)# 关键:用 StuffDocumentsChain 包装归约链(新版要求)# 细想也能理解,Reduce需要合并多个局部回答,使用合并文档链合适combine_chain = StuffDocumentsChain(llm_chain=reduce_chain,document_variable_name="input_documents" # 与 reduce_prompt 中的变量一致)# 5. 初始化 MapReduce 链map_reduce_chain = MapReduceDocumentsChain(llm_chain=map_chain,combine_document_chain=combine_chain,document_variable_name="input_documents", # 与 map_prompt 中的文档变量一致return_intermediate_steps=True # 可选:返回各阶段中间结果)# 6. 准备测试文档(多文档分散信息)docs = [Document(page_content="Python 是一种解释型语言,语法简洁,适合初学者。"),Document(page_content="Python 支持多种编程范式,包括面向对象和函数式编程。"),Document(page_content="Python 拥有丰富的第三方库,如 NumPy 用于数值计算,Pandas 用于数据分析。")]question = "Python 有哪些特点和常用库?"# 7. 调用链(若文档过长,可先用 text_splitter 拆分)# text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=0)# split_docs = text_splitter.split_documents(docs)result = map_reduce_chain.invoke({"input_documents": docs, # 或 split_docs(拆分后的文档)"question": question})# 8. 输出结果# 打印中间结果(Map 阶段的局部回答)print("Map 阶段局部回答:")for i, step in enumerate(result["intermediate_steps"]):print(f"文档 {i+1} 局部回答:{step}")print("最终回答:\n", result["output_text"], "\n")
回答

从回答的文档可以知道,map阶段:会基于多个文档生成多个局部回答,最后在reduce阶段:汇总局部回答生成完整回答
4.4 MapRerank链
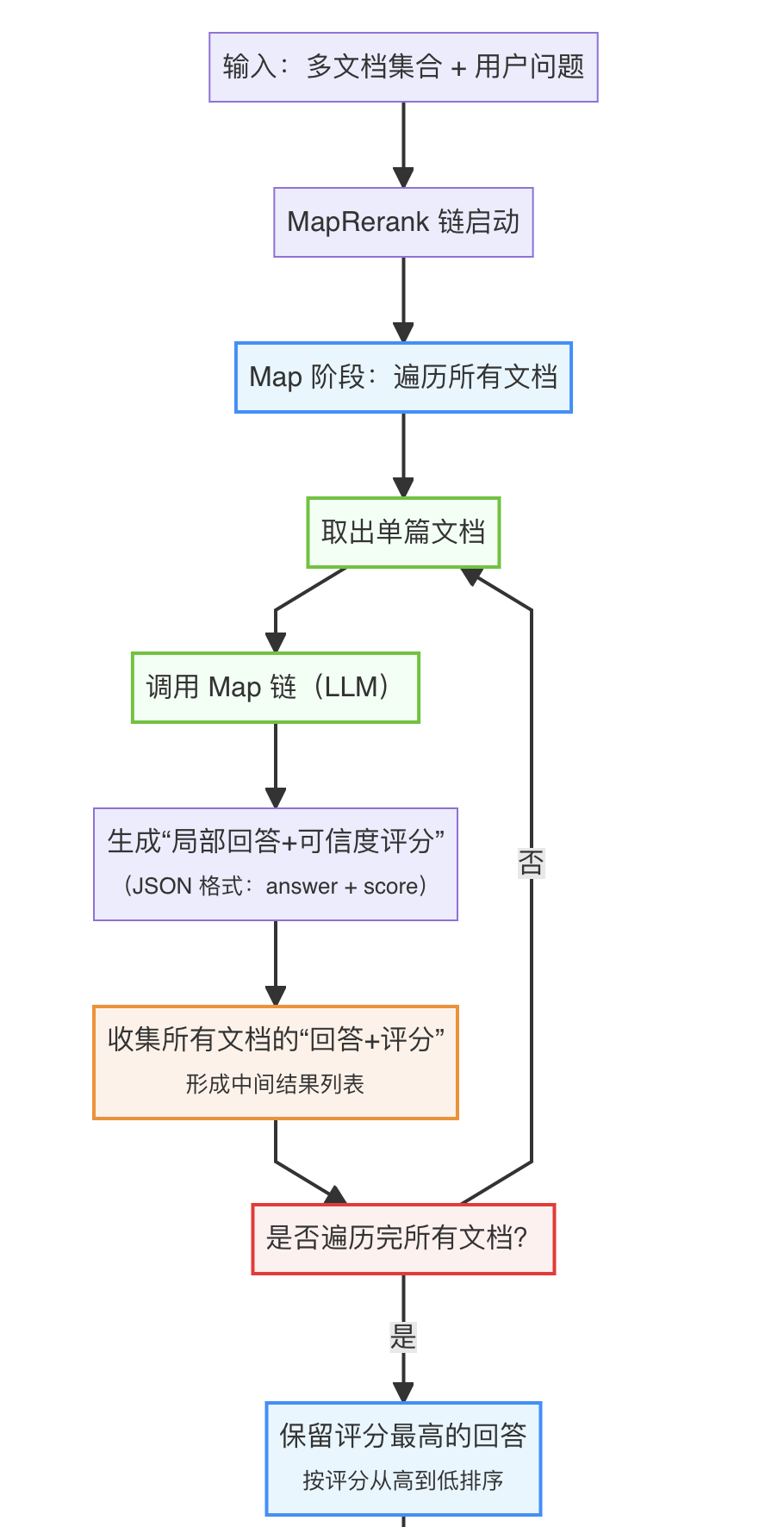
MapRerankChain是 LangChain 中针对多文档问答的核心合并链之一,采用 “映射 - 重排序” 双阶段逻辑:先为每篇文档生成带评分的局部回答(Map 阶段),再根据评分筛选优质回答并整合(Rerank 阶段),最终输出信息准确、优先级高的结果。
- Map 阶段:遍历所有输入文档,对单篇文档调用大语言模型(LLM),生成两个关键输出 —— 针对问题的 “局部回答”+ 该回答的 “可信度评分”(如 1-10 分,评分越高表示回答与文档匹配度、准确性越强)。
- Rerank 阶段:收集所有文档的 “局部回答 + 评分”,按评分从高到低排序,使用评分最高的进行回答
MapRerankDocumentsChain方法参数说明
| 参数信息 | 是否必需 | 核心作用 | 使用说明 |
|---|---|---|---|
llm_chain: LLMChain | 是 | 对每个文档单独进行分析处理的核心链,作为 “单文档处理单元” | 1. 需接收文档内容(通过 document_variable_name 传入)和问题等输入变量2. 输出必须包含 rank_key(评分)和 answer_key(答案)对应的字段3. 需通过 StructuredOutputParser 确保输出结构化格式 |
document_variable_name: str | 否 | 指定 llm_chain 中用于接收 “文档内容” 的变量名 | 1. 若 llm_chain 的 Prompt 只有 1 个输入变量,可省略(自动匹配)2. 若有多个变量(如 question 和 doc_content),必须指定(如 document_variable_name="doc_content") |
rank_key: str | 是 | 从 llm_chain 输出中提取 “评分” 的字段名,用于对文档排序 | 1. 对应 llm_chain 输出中的评分字段(如 "score" 或 "relevance")2. 字段值需为可比较的数字(如 1-10 分)框架将按此字段降序排序文档 |
answer_key: str | 是 | 从 llm_chain 输出中提取 “答案内容” 的字段名,作为文档的核心处理结果 | 对应 llm_chain 输出中的答案字段(如 "answer" 或 "result"),最终结果会提取该字段的值作为文档的回答内容 |
metadata_keys: Optional[list[str]] | 否 | 从文档元数据中额外提取并返回的字段列表(可选) | 1. 需与输入文档的 metadata 字段对应(如文档元数据含 "source",可指定 ["source"] 提取来源信息)2. 不指定则仅返回默认结果,不包含额外元数据 |
return_intermediate_steps: bool | 否 | 控制是否返回所有文档的中间处理结果(而非仅排序后的结果) | 1. 设为 True 时,结果包含 intermediate_steps 字段,存储所有文档的原始处理结果2. 设为 False(默认)时,仅返回按 rank_key 排序后的文档结果 |
其是在MapReduceChain的基础上添加了局部+评分分和筛选的功能,但是相比于MapReduceChain其缺少了局部汇总能力。应用于如下场景:
- 文档质量参差不齐(如包含冗余、低关联甚至错误信息的文档集合),需优先保留高可信度内容
- 对回答准确性要求高,需通过 “评分筛选” 剔除低质量局部回答
- 文档数量适中(10-50 篇),既需覆盖多文档信息,又需控制计算成本(相比 MapReduce 链,无需汇总所有局部回答,成本更低)
相关代码
def test_map_rerank_chain(modelName: str):# 1. 准备测试文档(包含高关联、低关联文档,模拟真实场景)docs = [Document(page_content="豆包app是智能助手,支持文字对话、代码生成和多语言翻译,响应速度快"), # 高关联文档Document(page_content="豆包app的开发团队专注于 AI 技术研发,拥有 5 年以上行业经验"), # 低关联文档(与“功能”问题关联弱)Document(page_content="豆包app还支持文档总结和表格生成,可满足办公场景需求") # 高关联文档]question = "豆包有哪些核心功能?"# 2. 初始化基础 LLM(支持 GPT-3.5/4 等)llm = getChatModel(modelName)# 3. 定义 Map 阶段提示词(需包含“局部回答”和“可信度评分”输出要求)map_prompt_str = """基于以下文档回答问题,必须严格按照此格式输出:<Answer>[你的回答内容]Score: [1-10的评分]</Answer>- 回答内容需简洁,仅使用文档信息- 评分1-10分,10分表示最准确- 不要添加任何额外内容或解释文档:{input_documents}问题:{question} """output_parser = RegexParser(regex=r"<Answer>(.*?)Score: (\d+)</Answer>",output_keys=["answer", "score"] # 提取回答和评分)map_prompt = PromptTemplate(template=map_prompt_str,input_variables=["input_documents", "question"],output_parser=output_parser)# 添加输出解析器# 4. 初始化 Map 阶段链(结合 JSON 解析器,确保评分可被正确提取)map_chain = LLMChain(llm=llm,prompt=map_prompt,)result = map_chain.invoke({"input_documents": docs, "question": question})print(result)# # 5. 定义 Rerank 阶段提示词(整合 Top N 优质回答)# rerank_prompt = ChatPromptTemplate.from_messages([# ("system", """你需要基于以下高可信度局部回答,整合生成最终回答:# 1. 优先保留评分高的回答内容,去除重复信息;# 2. 若回答存在冲突,以评分更高的内容为准;# 3. 最终回答需逻辑连贯、简洁全面。# 高可信度局部回答:{input_documents}"""),# ("human", "问题:{question}")# ])### # 6. 初始化 Rerank 阶段链# rerank_chain = LLMChain(llm=llm, prompt=rerank_prompt)# # 7. 初始化 MapRerank 总链(核心配置)map_rerank_chain = MapRerankDocumentsChain(llm_chain=map_chain, # Map 阶段链(生成局部回答+评分)rank_key="score", # 评分字段名answer_key="answer",document_variable_name="input_documents", # 提示词中接收文档的变量名return_intermediate_steps=True, # 可选:返回中间结果(局部回答+评分))# 8. 调用链并输出结果result = map_rerank_chain.invoke({"input_documents": docs,"question": question})# 9 打印最终结果print("=" * 50)print("最终回答:\n", result["output_text"])# 打印中间结果(查看每篇文档的局部回答和评分)print("\n中间结果(局部回答+评分):")for i, step in enumerate(result["intermediate_steps"]):print(f"文档 {i + 1} - 评分:{step['score']},回答:{step['answer']}")
获取得分最高的是文档1和文档3 最后选择了其中一个进行回答(注意不是没有局部汇总)。
五、控制流
Chain 不仅能做 “线性流程”,还能处理复杂控制逻辑(比如 “根据条件选分支”“并行执行多任务”),核心工具是以下 3 个 Runnable:
5.1 条件分支
RunnableBranch 根据输入的不同,选择不同的处理逻辑。比如:
- 如果用户问 “事实性问题”(比如 “LangChain 发布于哪一年?”),用检索增强回答;
- 如果用户问 “创造性问题”(比如 “写一首关于 LangChain 的诗”),直接用 LLM 生成。
这篇文档第三章节的3.3 RouterChain路由链就是使用该方式
代码示例:
from langchain.schema.runnable import RunnableBranch
from langchain.retrievers import VectorStoreRetriever# 1. 定义分支条件与对应的Chain
fact_chain = (retriever # 检索知识库| ChatPromptTemplate.from_template("用上下文回答:{context}\n问题:{query}")| model
)
creative_chain = (ChatPromptTemplate.from_template("发挥创意回答:{query}")| model
)# 2. 用RunnableBranch做条件判断
branch_chain = RunnableBranch(# 条件1:问题是否是事实性的?(lambda x: "事实" in x["query"], fact_chain),# 条件2:问题是否是创造性的?(lambda x: "创意" in x["query"], creative_chain),# 默认分支:直接回答model
)# 运行Chain
response = branch_chain.invoke({"query": "LangChain发布于哪一年?(事实)"})
5.2 自定义逻辑
**RunnableLambda**插入自定义 Python 函数,处理 Chain 中的中间结果。比如:
- 检查 LLM 生成的回答是否包含敏感内容;
- 格式化检索到的文档内容。
这篇文档第三章节的3.4 TransFormChain转换链就是使用该方式 RunnableLambda可以将一个自定义函数包装成langchain的Runable可运行组件 而chain就是一个可运行的组件。
示例代码
from langchain.schema.runnable import RunnableLambda# 自定义函数:过滤敏感内容
def filter_sensitive(content):sensitive_words = ["敏感词1", "敏感词2"]for word in sensitive_words:content = content.replace(word, "*"*len(word))return content# 拼接Chain:生成 → 过滤
chain = (prompt | model | RunnableLambda(lambda x: x.content) # 提取LLM输出的文本| RunnableLambda(filter_sensitive) # 过滤敏感内容
)
5.3 并行执行
**RunnableParallel**同时执行多个任务,合并结果。比如:
- 同时检索 “LangChain Chain” 的文档和 “LangChain Agent” 的文档;
- 同时生成 “中文回答” 和 “英文回答”。
def test_paraller_chain(modelName: str):"""并行链:param modelName::return:"""llm = getChatModel(modelName)# 2. 定义多个独立的可运行组件(Runnable)# 组件1:生成产品名称product_prompt = ChatPromptTemplate.from_messages([("system", "你是产品命名专家,为{product_type}生成3个创意名称,用逗号分隔"),("user", "请为我的产品命名")])product_chain = product_prompt | llm | StrOutputParser()# 组件2:生成产品卖点selling_point_prompt = ChatPromptTemplate.from_messages([("system", "你是营销专家,为{product_type}提炼2个核心卖点,每点不超过20字"),("user", "请分析我的产品卖点")])selling_point_chain = selling_point_prompt | llm | StrOutputParser()# 组件3:直接传递原始输入(不经过 LLM 处理)passthrough_component = RunnablePassthrough()# 3. 使用 RunnableParallel 并行组合多个组件# 每个键对应一个并行任务,值为要执行的 Runnableparallel_chain = RunnableParallel(product_names=product_chain, # 任务1:生成产品名称selling_points=selling_point_chain, # 任务2:生成产品卖点original_input=passthrough_component # 任务3:传递原始输入)# 4. 执行并行任务(输入会同时传递给所有组件)input_data = {"product_type": "智能保温杯"}result = parallel_chain.invoke(input_data)# 5. 输出结果(字典形式,键与 RunnableParallel 中定义的一致)print("并行任务结果:")print(f"产品名称建议:{result['product_names']}")print(f"核心卖点:{result['selling_points']}")print(f"原始输入:{result['original_input']}")
六、 实战场景
| 核心能力场景 | 典型应用场景 | 常用链类型 / 组合 |
|---|---|---|
| 检索增强生成(RAG) | 1. 企业知识库问答(如内部政策、产品手册问答) 2. 学术论文辅助阅读(如论文库问答) 3. 实时信息问答(如结合搜索引擎获取引擎获取最新数据) | 1. RetrievalChain + StuffDocumentsChain2. VectorDBQAChain+ RefineDocumentsChain3. ToolChain(搜索工具)+ LLMChain |
| 多步推理与决策 | 1. 数学 / 逻辑题求解(如应用题、复杂计算) 2. 代码生成与调试(如多文件代码、Bug 修复) 3. 复杂需求拆解(如项目规划、任务分解) | 1. LLMChain + CalculatorChain2. CodeChain +ToolChain(代码检查)+ RefineChain +MapRerankDocumentsChain + LLMChain |
| 流程化内容生成 | 1. 批量营销内容(如产品文案、社交媒体帖子) 2. 文档自动化(如周报、合同初稿) 3. 多语言翻译与本地化(如产品说明书多语言版本) | 1. LLMChain(Prompt 模板)+ StructuredOutputParser + SequentialChain2. DataLoadChain + StuffDocumentsChain+ FormatChain3. LLMChain+ ToolChain(本地化工具)+ ParallelChain |
| 工具与外部系统交互 | 1. 数据库查询与分析(如自然语言查 SQL 数据) 2. API 调用与服务集成(如高铁预订、数据同步) 3. 智能家居控制(如灯光、空调控制) | 1. SQLChain + DatabaseToolChain + LLMChain2. LLMChain(解析需求)+ APIToolChain+ NotificationChain3. IntentChain + DeviceToolChain+ LLMChain |
| 个性化服务 | 1. 个性化学习辅导(如定制练习题、学习计划) 2. 个性化推荐(如商品、内容推荐) 3. 个性化客服(如结合历史记录的精准服务) | 1. UserProfileChain + LLMChain + FeedbackChain2. DataRetrievalChain + LLMChain+ ToolChain(实时信息)3. RetrievalChain(历史记录) + LLMChain + ActionChain(转接人工) |
七、Chain 总结
Chain 的价值:构建复杂 LLM 应用的基石
LangChain 的 Chain 不是 “花架子”,而是解决 “从想法到落地” 的关键工具:
- 模块化:把复杂流程拆成可复用的单步模块(比如 “检索模块”“生成模块”)
- 可调试:用
astream_log查看每一步的输出,快速定位问题; - 可扩展:从 “最简链” 到 “多分支链” 再到 “Agent”,逐步升级无需重构代码。
Chain 的核心思想是:把复杂的智能流程拆解成可控制的单步操作,再用灵活的方式拼接起来。掌握了 Chain,你就能从 “调用 LLM API” 进化到 “构建真正的 LLM 应用”。