dinov3 foreground_segmentation.ipynb魔改py ,不走torch.hub 训练
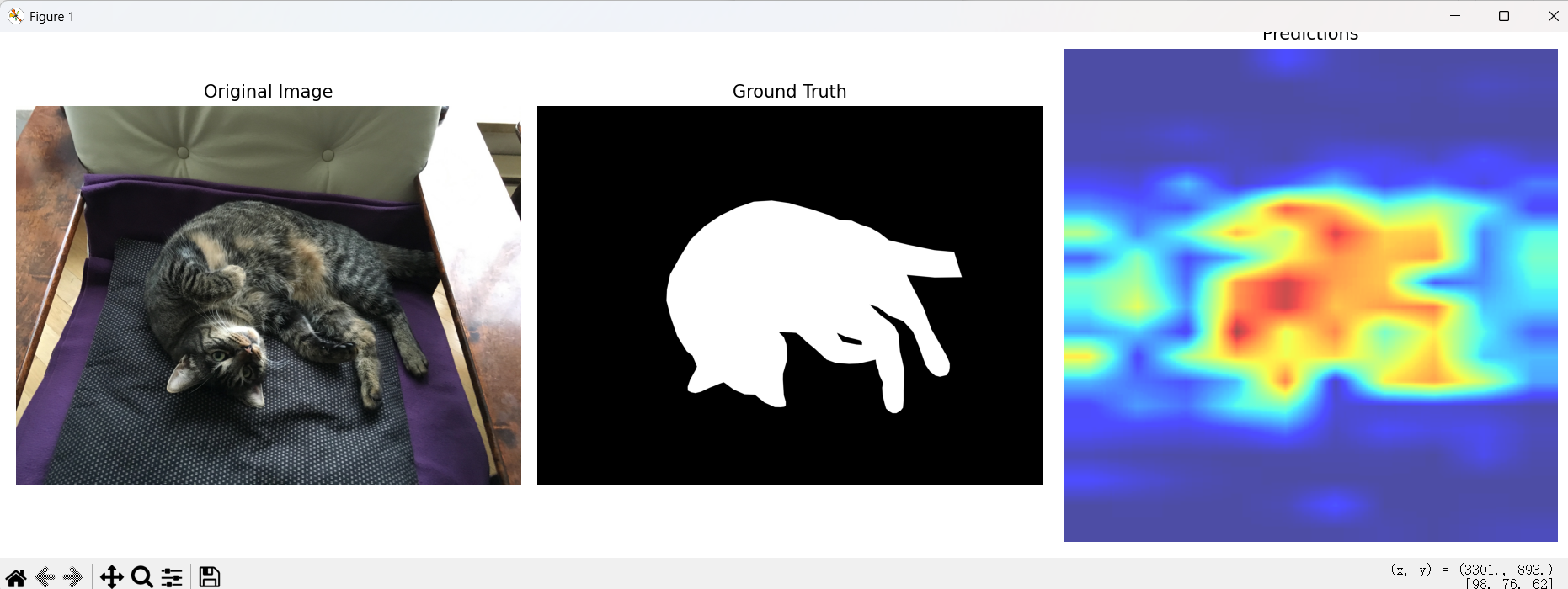
先看结果


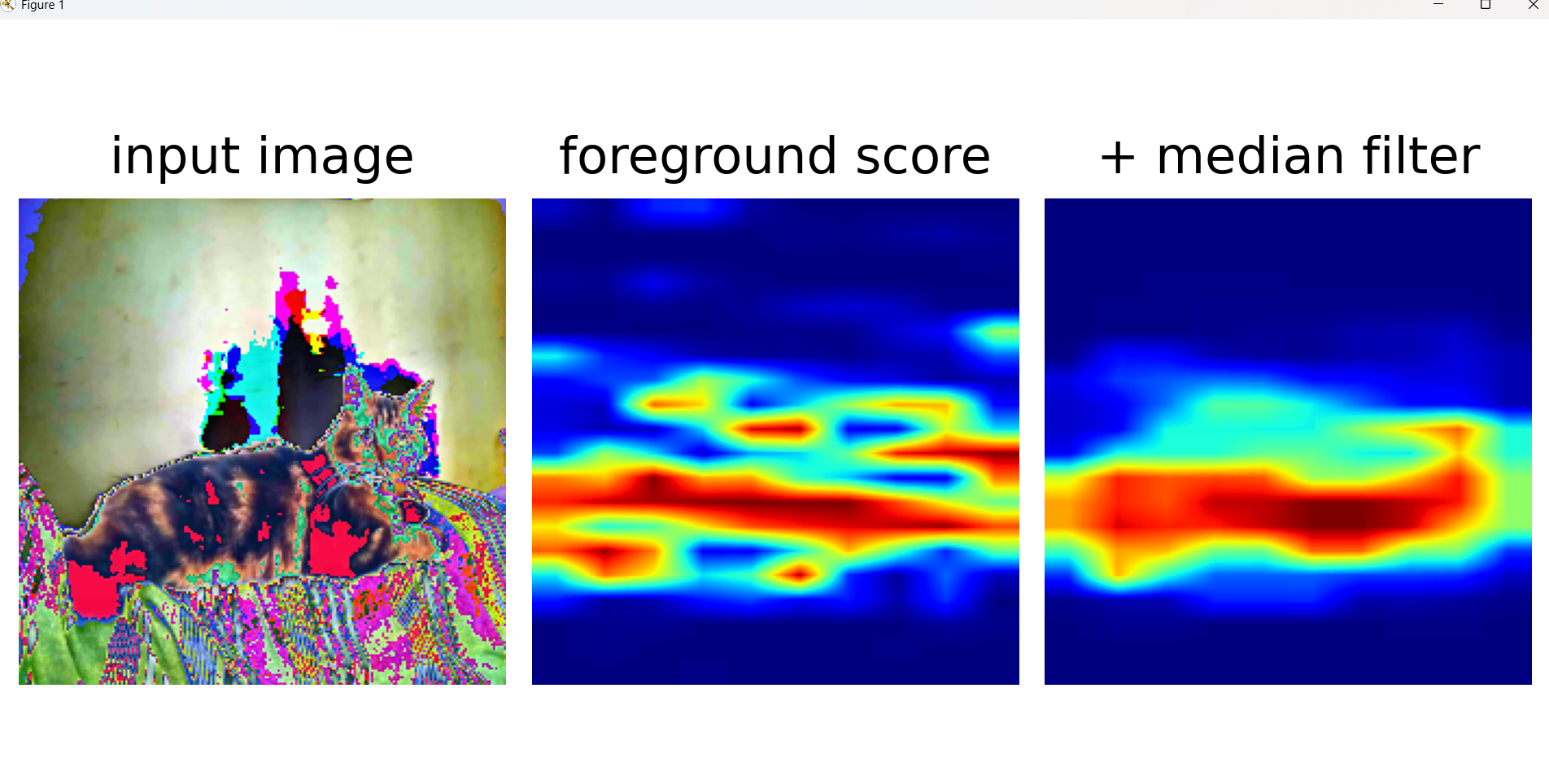
原神图片没训练过
input image 是 预训练模型处理后的结果
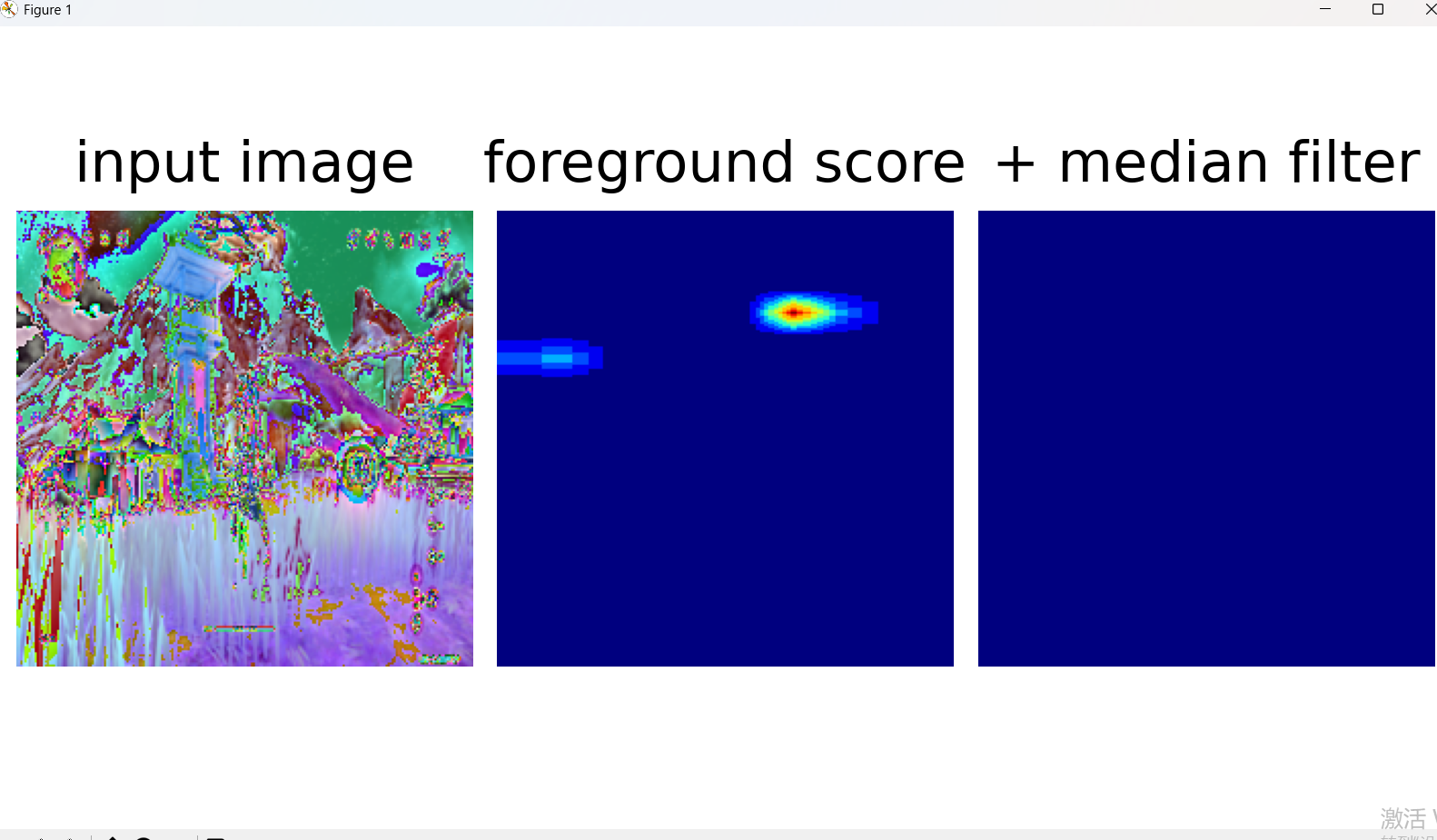
???
可以看到预训练模型识别几何特征竟然如此nb
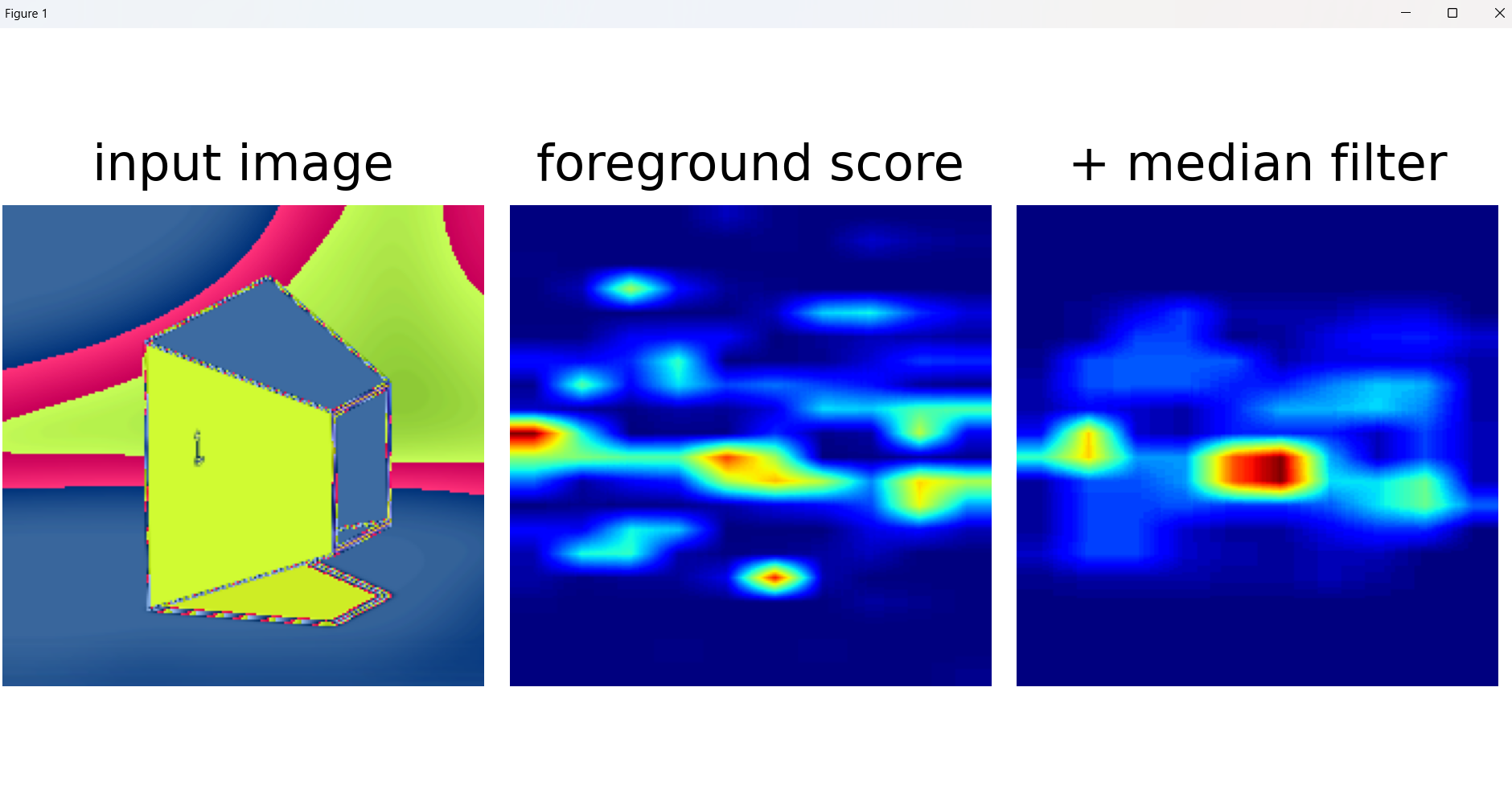
bb
是我不想用torch.hub吗.jpg
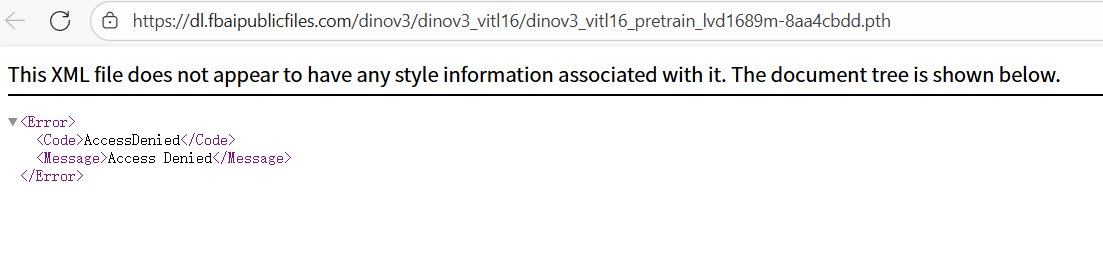
不用torch.hub会遇到这个问题
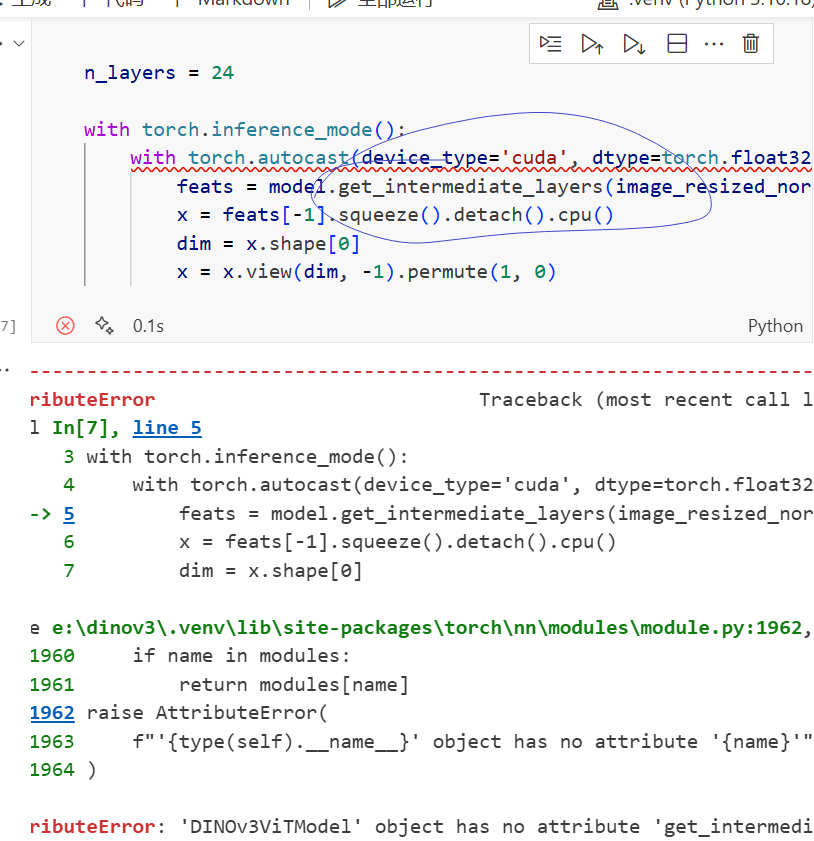
本地运行会遇到这个问题
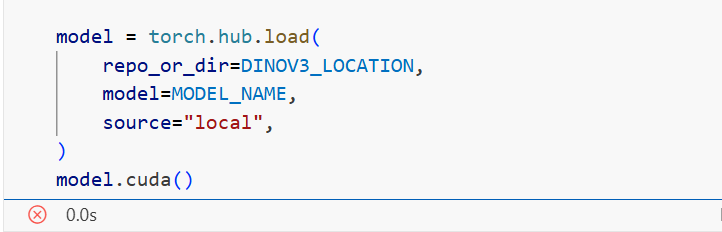

维度不匹配是主要问题

pkl是啥
pkl 是 Python 中使用 pickle 模块序列化对象时常用的文件扩展名。以下是关于 pkl 文件的详细说明:什么是 pkl 文件
pkl 文件是使用 Python 的 pickle 模块序列化后的二进制文件,用于保存 Python 对象的状态,以便后续可以恢复该对象。在你的代码中的用途
在你的代码中,pkl 文件用于保存两个重要组件:模型文件: foreground_segmentation_model.pkl保存训练好的 LogisticRegression 分类器
可以在后续使用中直接加载,无需重新训练
配置文件: feature_extractor_config.pkl保存特征提取器的相关配置信息
包括模型名称和 patch 大小等参数
工作原理python# 保存对象到 .pkl 文件 with open('file.pkl', 'wb') as f: pickle.dump(object, f) # 从 .pkl 文件加载对象 with open('file.pkl', 'rb') as f: object = pickle.load(f)优势
可以完整保存训练好的模型状态
方便模型的持久化存储和部署
能够恢复复杂的对象结构和参数
便于在不同程序或会话之间共享模型代码
.ipynb文件统一林码不好发挥改成py了
import io
import os
import pickle
import tarfile
import urllibfrom PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.linear_model import LogisticRegression
import torch
import torchvision.transforms.functional as TF
from tqdm import tqdm# 加载DINOv3模型
MODEL_DINOV3_VITL = "dinov3_vitl16"
MODEL_NAME = "dinov3_vitl16_pretrain_lvd1689m"# 加载预训练模型
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_imagepretrained_model_name = os.path.abspath("E:\\dinov3\\model\\dinov3-vitl16-pretrain-lvd1689m")
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(pretrained_model_name, device_map="auto")
model.cuda()# 加载数据
IMAGES_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_images.tar.gz"
LABELS_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_labels.tar.gz"def load_images_from_remote_tar(tar_uri: str) -> list[Image.Image]:images = []with urllib.request.urlopen(tar_uri) as f:tar = tarfile.open(fileobj=io.BytesIO(f.read()))for member in tar.getmembers():image_data = tar.extractfile(member)image = Image.open(image_data)images.append(image)return imagesimages = load_images_from_remote_tar(IMAGES_URI)
labels = load_images_from_remote_tar(LABELS_URI)
n_images = len(images)
assert n_images == len(labels), f"{len(images)=}, {len(labels)=}"print(f"Loaded {n_images} images and labels")# 提取DINOv3特征
def extract_features(model, processor, images):"""使用DINOv3模型提取图像特征"""all_features = []processed_shapes = []for img in tqdm(images, desc="Extracting features"):# 预处理图像inputs = processor(images=img, return_tensors="pt")processed_shapes.append(inputs['pixel_values'].shape)inputs = {k: v.cuda() for k, v in inputs.items()}# 提取特征with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)# 使用最后一层的特征features = outputs.last_hidden_state[:, 1:] # 去掉CLS tokenall_features.append(features.cpu().numpy())return all_features, processed_shapes# 提取所有图像的特征
features, processed_shapes = extract_features(model, processor, images)# 准备训练数据
def prepare_training_data(features, labels, processed_shapes):"""准备用于训练的数据"""X_train = []y_train = []for i in range(len(features)):# 获取特征feat = features[i].squeeze() # (num_patches, feature_dim)# 获取标签(掩码)label_img = labels[i]# 直接使用特征的实际维度来计算patch的高和宽num_patches = feat.shape[0]# 对于正方形图像,patch_h和patch_w应该相等# 但我们需要考虑实际的图像宽高比_, _, h, w = processed_shapes[i] # (batch, channels, height, width)# 计算实际的patch_h和patch_w# 由于我们不知道确切的padding方式,我们根据特征数量反推patch_size = 16 # DINOv3 ViT-L/16的patch大小为16# 计算不考虑padding时的patch数量orig_patch_h = h // patch_sizeorig_patch_w = w // patch_size# 如果特征数量与原始计算的patch数量不一致,说明有paddingif num_patches != orig_patch_h * orig_patch_w:# 根据实际特征数量计算patch的维度# 假设接近正方形的分布patch_h = int(np.sqrt(num_patches))patch_w = num_patches // patch_h# 确保乘积等于特征数量while patch_h * patch_w != num_patches:patch_h += 1patch_w = num_patches // patch_helse:# 没有padding的情况patch_h, patch_w = orig_patch_h, orig_patch_wprint(f"Image {i}: shape {h}x{w}, patches {patch_h}x{patch_w}={num_patches}")# 调整标签尺寸以匹配特征图label_resized = label_img.resize((patch_w, patch_h)) # resize参数是(width, height)label_array = np.array(label_resized)# 如果是RGBA图像,使用alpha通道作为掩码if len(label_array.shape) == 3 and label_array.shape[2] == 4:mask = label_array[:, :, 3] > 128 # alpha > 128为前景elif len(label_array.shape) == 2:mask = label_array > 128 # 灰度图,> 128为前景else:mask = label_array[:, :, 0] > 128 # RGB图,使用红色通道# 展平掩码mask_flat = mask.flatten()# 确保特征和标签尺寸匹配if feat.shape[0] == mask_flat.shape[0]:X_train.append(feat)y_train.append(mask_flat)else:print(f"Skipping image {i} due to size mismatch: {feat.shape[0]} vs {mask_flat.shape[0]}")# 合并所有数据if X_train:X_train = np.vstack(X_train)y_train = np.hstack(y_train)return X_train, y_trainelse:return None, None# 准备训练数据
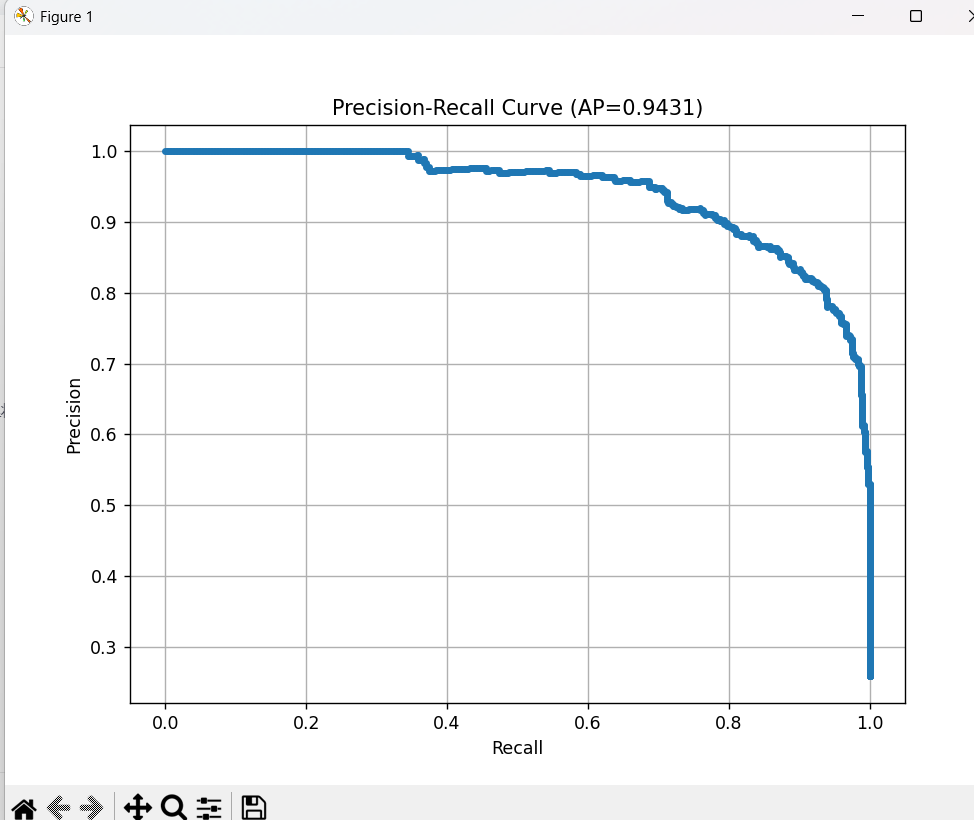
X_train, y_train = prepare_training_data(features, labels, processed_shapes)if X_train is not None:print(f"Training data shape: {X_train.shape}")print(f"Training labels shape: {y_train.shape}")print(f"Foreground pixels: {np.sum(y_train)} ({100*np.sum(y_train)/len(y_train):.2f}%)")# 训练线性分类器print("Training linear classifier...")classifier = LogisticRegression(max_iter=1000, verbose=1)classifier.fit(X_train, y_train)print("Training completed!")# 评估模型train_score = classifier.score(X_train, y_train)print(f"Training accuracy: {train_score:.4f}")# 可视化结果def visualize_prediction(image, label, features, classifier, idx):"""可视化预测结果"""fig, axes = plt.subplots(1, 3, figsize=(15, 5))# 原图axes[0].imshow(image)axes[0].set_title("Original Image")axes[0].axis('off')# 真实标签label_img = labelif hasattr(label_img, 'mode') and label_img.mode == 'RGBA':label_array = np.array(label_img)if len(label_array.shape) == 3:mask = label_array[:, :, 3] # alpha通道axes[1].imshow(mask, cmap='gray')else:axes[1].imshow(label_img, cmap='gray')axes[1].set_title("Ground Truth")axes[1].axis('off')# 预测结果feat = features[idx].squeeze()with torch.no_grad():predictions = classifier.predict_proba(feat)[:, 1] # 前景概率# 获取特征数量并计算patch维度num_patches = feat.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = processed_shapes[idx]pred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)pred_array = np.array(pred_img)axes[2].imshow(pred_array, cmap='jet', alpha=0.7)axes[2].set_title("Predictions")axes[2].axis('off')plt.tight_layout()plt.show()# 显示几个预测示例for i in range(min(3, len(images))):visualize_prediction(images[i], labels[i], features, classifier, i)# 计算精度-召回率曲线def compute_pr_curve(X_train, y_train, classifier):"""计算精度-召回率曲线"""y_scores = classifier.predict_proba(X_train)[:, 1]precision, recall, thresholds = precision_recall_curve(y_train, y_scores)ap_score = average_precision_score(y_train, y_scores)return precision, recall, ap_scoreprecision, recall, ap_score = compute_pr_curve(X_train, y_train, classifier)print(f"Average Precision: {ap_score:.4f}")# 绘制PR曲线plt.figure(figsize=(8, 6))plt.plot(recall, precision, marker='.')plt.xlabel('Recall')plt.ylabel('Precision')plt.title(f'Precision-Recall Curve (AP={ap_score:.4f})')plt.grid(True)plt.show()# 保存模型model_path = "foreground_segmentation_model.pkl"with open(model_path, 'wb') as f:pickle.dump(classifier, f)print(f"Model saved to {model_path}")# 保存特征提取器配置config_path = "feature_extractor_config.pkl"config = {'model_name': MODEL_NAME,'patch_size': 16, # DINOv3 ViT-L/16}with open(config_path, 'wb') as f:pickle.dump(config, f)print(f"Feature extractor config saved to {config_path}")else:print("Failed to prepare training data due to size mismatch")# 测试新图像的推理函数
def predict_foreground(model, processor, classifier, image_path):"""对新图像进行前景分割预测"""# 加载图像image = Image.open(image_path).convert('RGB')# 提取特征inputs = processor(images=image, return_tensors="pt")inputs = {k: v.cuda() for k, v in inputs.items()}with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)features = outputs.last_hidden_state[:, 1:].cpu().numpy().squeeze()# 预测predictions = classifier.predict_proba(features)[:, 1]# 根据特征数量计算patch维度num_patches = features.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = inputs['pixel_values'].shapepred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)return np.array(pred_img)print("\nTo predict foreground for a new image, use:")
print("prediction = predict_foreground(model, processor, classifier, 'path/to/image.jpg')")加入test的代码
import io
import os
import pickle
import tarfile
import urllibfrom PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.linear_model import LogisticRegression
import torch
import torchvision.transforms.functional as TF
from tqdm import tqdm# 加载DINOv3模型
MODEL_DINOV3_VITL = "dinov3_vitl16"
MODEL_NAME = "dinov3_vitl16_pretrain_lvd1689m"# 加载预训练模型
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_imagepretrained_model_name = os.path.abspath("E:\\dinov3\\model\\dinov3-vitl16-pretrain-lvd1689m")
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(pretrained_model_name, device_map="auto")
model.cuda()# 加载数据
IMAGES_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_images.tar.gz"
LABELS_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_labels.tar.gz"def load_images_from_remote_tar(tar_uri: str) -> list[Image.Image]:images = []with urllib.request.urlopen(tar_uri) as f:tar = tarfile.open(fileobj=io.BytesIO(f.read()))for member in tar.getmembers():image_data = tar.extractfile(member)image = Image.open(image_data)images.append(image)return imagesimages = load_images_from_remote_tar(IMAGES_URI)
labels = load_images_from_remote_tar(LABELS_URI)
n_images = len(images)
assert n_images == len(labels), f"{len(images)=}, {len(labels)=}"print(f"Loaded {n_images} images and labels")# 提取DINOv3特征
def extract_features(model, processor, images):"""使用DINOv3模型提取图像特征"""all_features = []processed_shapes = []for img in tqdm(images, desc="Extracting features"):# 预处理图像inputs = processor(images=img, return_tensors="pt")processed_shapes.append(inputs['pixel_values'].shape)inputs = {k: v.cuda() for k, v in inputs.items()}# 提取特征with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)# 使用最后一层的特征features = outputs.last_hidden_state[:, 1:] # 去掉CLS tokenall_features.append(features.cpu().numpy())return all_features, processed_shapes# 提取所有图像的特征
features, processed_shapes = extract_features(model, processor, images)# 准备训练数据
def prepare_training_data(features, labels, processed_shapes):"""准备用于训练的数据"""X_train = []y_train = []for i in range(len(features)):# 获取特征feat = features[i].squeeze() # (num_patches, feature_dim)# 获取标签(掩码)label_img = labels[i]# 直接使用特征的实际维度来计算patch的高和宽num_patches = feat.shape[0]# 对于正方形图像,patch_h和patch_w应该相等# 但我们需要考虑实际的图像宽高比_, _, h, w = processed_shapes[i] # (batch, channels, height, width)# 计算实际的patch_h和patch_w# 由于我们不知道确切的padding方式,我们根据特征数量反推patch_size = 16 # DINOv3 ViT-L/16的patch大小为16# 计算不考虑padding时的patch数量orig_patch_h = h // patch_sizeorig_patch_w = w // patch_size# 如果特征数量与原始计算的patch数量不一致,说明有paddingif num_patches != orig_patch_h * orig_patch_w:# 根据实际特征数量计算patch的维度# 假设接近正方形的分布patch_h = int(np.sqrt(num_patches))patch_w = num_patches // patch_h# 确保乘积等于特征数量while patch_h * patch_w != num_patches:patch_h += 1patch_w = num_patches // patch_helse:# 没有padding的情况patch_h, patch_w = orig_patch_h, orig_patch_wprint(f"Image {i}: shape {h}x{w}, patches {patch_h}x{patch_w}={num_patches}")# 调整标签尺寸以匹配特征图label_resized = label_img.resize((patch_w, patch_h)) # resize参数是(width, height)label_array = np.array(label_resized)# 如果是RGBA图像,使用alpha通道作为掩码if len(label_array.shape) == 3 and label_array.shape[2] == 4:mask = label_array[:, :, 3] > 128 # alpha > 128为前景elif len(label_array.shape) == 2:mask = label_array > 128 # 灰度图,> 128为前景else:mask = label_array[:, :, 0] > 128 # RGB图,使用红色通道# 展平掩码mask_flat = mask.flatten()# 确保特征和标签尺寸匹配if feat.shape[0] == mask_flat.shape[0]:X_train.append(feat)y_train.append(mask_flat)else:print(f"Skipping image {i} due to size mismatch: {feat.shape[0]} vs {mask_flat.shape[0]}")# 合并所有数据if X_train:X_train = np.vstack(X_train)y_train = np.hstack(y_train)return X_train, y_trainelse:return None, None# 准备训练数据
X_train, y_train = prepare_training_data(features, labels, processed_shapes)if X_train is not None:print(f"Training data shape: {X_train.shape}")print(f"Training labels shape: {y_train.shape}")print(f"Foreground pixels: {np.sum(y_train)} ({100*np.sum(y_train)/len(y_train):.2f}%)")# 训练线性分类器print("Training linear classifier...")classifier = LogisticRegression(max_iter=1000, verbose=1)classifier.fit(X_train, y_train)print("Training completed!")# 评估模型train_score = classifier.score(X_train, y_train)print(f"Training accuracy: {train_score:.4f}")# 可视化结果def visualize_prediction(image, label, features, classifier, idx):"""可视化预测结果"""fig, axes = plt.subplots(1, 3, figsize=(15, 5))# 原图axes[0].imshow(image)axes[0].set_title("Original Image")axes[0].axis('off')# 真实标签label_img = labelif hasattr(label_img, 'mode') and label_img.mode == 'RGBA':label_array = np.array(label_img)if len(label_array.shape) == 3:mask = label_array[:, :, 3] # alpha通道axes[1].imshow(mask, cmap='gray')else:axes[1].imshow(label_img, cmap='gray')axes[1].set_title("Ground Truth")axes[1].axis('off')# 预测结果feat = features[idx].squeeze()with torch.no_grad():predictions = classifier.predict_proba(feat)[:, 1] # 前景概率# 获取特征数量并计算patch维度num_patches = feat.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = processed_shapes[idx]pred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)pred_array = np.array(pred_img)axes[2].imshow(pred_array, cmap='jet', alpha=0.7)axes[2].set_title("Predictions")axes[2].axis('off')plt.tight_layout()plt.show()# 显示几个预测示例for i in range(min(3, len(images))):visualize_prediction(images[i], labels[i], features, classifier, i)# 计算精度-召回率曲线def compute_pr_curve(X_train, y_train, classifier):"""计算精度-召回率曲线"""y_scores = classifier.predict_proba(X_train)[:, 1]precision, recall, thresholds = precision_recall_curve(y_train, y_scores)ap_score = average_precision_score(y_train, y_scores)return precision, recall, ap_scoreprecision, recall, ap_score = compute_pr_curve(X_train, y_train, classifier)print(f"Average Precision: {ap_score:.4f}")# 绘制PR曲线plt.figure(figsize=(8, 6))plt.plot(recall, precision, marker='.')plt.xlabel('Recall')plt.ylabel('Precision')plt.title(f'Precision-Recall Curve (AP={ap_score:.4f})')plt.grid(True)plt.show()# 保存模型model_path = "foreground_segmentation_model.pkl"with open(model_path, 'wb') as f:pickle.dump(classifier, f)print(f"Model saved to {model_path}")# 保存特征提取器配置config_path = "feature_extractor_config.pkl"config = {'model_name': MODEL_NAME,'patch_size': 16, # DINOv3 ViT-L/16}with open(config_path, 'wb') as f:pickle.dump(config, f)print(f"Feature extractor config saved to {config_path}")else:print("Failed to prepare training data due to size mismatch")# 测试新图像的推理函数
def predict_foreground(model, processor, classifier, image_path):"""对新图像进行前景分割预测"""# 加载图像image = Image.open(image_path).convert('RGB')# 提取特征inputs = processor(images=image, return_tensors="pt")inputs = {k: v.cuda() for k, v in inputs.items()}with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)features = outputs.last_hidden_state[:, 1:].cpu().numpy().squeeze()# 预测predictions = classifier.predict_proba(features)[:, 1]# 根据特征数量计算patch维度num_patches = features.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = inputs['pixel_values'].shapepred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)return np.array(pred_img)print("\nTo predict foreground for a new image, use:")
print("prediction = predict_foreground(model, processor, classifier, 'path/to/image.jpg')")test_image_fpath = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/test_image.jpg"def load_image_from_url(url: str) -> Image:with urllib.request.urlopen(url) as f:return Image.open(f).convert("RGB")# 修正后的预测代码
test_image = load_image_from_url(test_image_fpath)# 使用processor处理图像
inputs = processor(images=test_image, return_tensors="pt")
test_image_processed = inputs['pixel_values'][0] # 获取处理后的图像with torch.inference_mode():with torch.autocast(device_type='cuda', dtype=torch.float32):# 使用训练好的模型提取特征inputs_cuda = {k: v.cuda() for k, v in inputs.items()}outputs = model(**inputs_cuda, output_hidden_states=True)feats = outputs.last_hidden_state[:, 1:] # 去掉CLS tokenx = feats.squeeze().detach().cpu()if len(x.shape) == 1:x = x.unsqueeze(0) # 确保至少有2个维度# 根据实际特征数量计算patch维度
num_patches = x.shape[0]
feat_h = int(np.sqrt(num_patches))
feat_w = num_patches // feat_h
# 确保计算出的维度乘积等于特征数量
while feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_h# 使用训练好的classifier进行预测
fg_scores = classifier.predict_proba(x)[:, 1]# 重塑为特征图形状
fg_score = fg_scores.reshape(feat_h, feat_w)# 应用中值滤波
fg_score_mf = torch.from_numpy(signal.medfilt2d(fg_score, kernel_size=3))# 上采样到输入图像尺寸
_, _, h, w = inputs['pixel_values'].shape
fg_score_upsampled = Image.fromarray((fg_score * 255).astype(np.uint8))
fg_score_upsampled = fg_score_upsampled.resize((w, h), resample=Image.BILINEAR)
fg_score_upsampled = np.array(fg_score_upsampled)fg_score_mf_upsampled = Image.fromarray((fg_score_mf.numpy() * 255).astype(np.uint8))
fg_score_mf_upsampled = fg_score_mf_upsampled.resize((w, h), resample=Image.BILINEAR)
fg_score_mf_upsampled = np.array(fg_score_mf_upsampled)# 可视化结果
plt.figure(figsize=(9, 3), dpi=300)
plt.subplot(1, 3, 1)
plt.axis('off')
plt.imshow(TF.to_pil_image(test_image_processed))
plt.title('input image')plt.subplot(1, 3, 2)
plt.axis('off')
plt.imshow(fg_score_upsampled, cmap='jet')
plt.title('foreground score')plt.subplot(1, 3, 3)
plt.axis('off')
plt.imshow(fg_score_mf_upsampled, cmap='jet')
plt.title('+ median filter')plt.tight_layout()
plt.show()加入本地test的代码
import io
import os
import pickle
import tarfile
import urllibfrom PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.linear_model import LogisticRegression
import torch
import torchvision.transforms.functional as TF
from tqdm import tqdm# 加载DINOv3模型
MODEL_DINOV3_VITL = "dinov3_vitl16"
MODEL_NAME = "dinov3_vitl16_pretrain_lvd1689m"# 加载预训练模型
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_imagepretrained_model_name = os.path.abspath("E:\\dinov3\\model\\dinov3-vitl16-pretrain-lvd1689m")
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(pretrained_model_name, device_map="auto")
model.cuda()# 加载数据
IMAGES_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_images.tar.gz"
LABELS_URI = "https://dl.fbaipublicfiles.com/dinov3/notebooks/foreground_segmentation/foreground_segmentation_labels.tar.gz"def load_images_from_remote_tar(tar_uri: str) -> list[Image.Image]:images = []with urllib.request.urlopen(tar_uri) as f:tar = tarfile.open(fileobj=io.BytesIO(f.read()))for member in tar.getmembers():image_data = tar.extractfile(member)image = Image.open(image_data)images.append(image)return imagesimages = load_images_from_remote_tar(IMAGES_URI)
labels = load_images_from_remote_tar(LABELS_URI)
n_images = len(images)
assert n_images == len(labels), f"{len(images)=}, {len(labels)=}"print(f"Loaded {n_images} images and labels")# 提取DINOv3特征
def extract_features(model, processor, images):"""使用DINOv3模型提取图像特征"""all_features = []processed_shapes = []for img in tqdm(images, desc="Extracting features"):# 预处理图像inputs = processor(images=img, return_tensors="pt")processed_shapes.append(inputs['pixel_values'].shape)inputs = {k: v.cuda() for k, v in inputs.items()}# 提取特征with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)# 使用最后一层的特征features = outputs.last_hidden_state[:, 1:] # 去掉CLS tokenall_features.append(features.cpu().numpy())return all_features, processed_shapes# 提取所有图像的特征
features, processed_shapes = extract_features(model, processor, images)# 准备训练数据
def prepare_training_data(features, labels, processed_shapes):"""准备用于训练的数据"""X_train = []y_train = []for i in range(len(features)):# 获取特征feat = features[i].squeeze() # (num_patches, feature_dim)# 获取标签(掩码)label_img = labels[i]# 直接使用特征的实际维度来计算patch的高和宽num_patches = feat.shape[0]# 对于正方形图像,patch_h和patch_w应该相等# 但我们需要考虑实际的图像宽高比_, _, h, w = processed_shapes[i] # (batch, channels, height, width)# 计算实际的patch_h和patch_w# 由于我们不知道确切的padding方式,我们根据特征数量反推patch_size = 16 # DINOv3 ViT-L/16的patch大小为16# 计算不考虑padding时的patch数量orig_patch_h = h // patch_sizeorig_patch_w = w // patch_size# 如果特征数量与原始计算的patch数量不一致,说明有paddingif num_patches != orig_patch_h * orig_patch_w:# 根据实际特征数量计算patch的维度# 假设接近正方形的分布patch_h = int(np.sqrt(num_patches))patch_w = num_patches // patch_h# 确保乘积等于特征数量while patch_h * patch_w != num_patches:patch_h += 1patch_w = num_patches // patch_helse:# 没有padding的情况patch_h, patch_w = orig_patch_h, orig_patch_wprint(f"Image {i}: shape {h}x{w}, patches {patch_h}x{patch_w}={num_patches}")# 调整标签尺寸以匹配特征图label_resized = label_img.resize((patch_w, patch_h)) # resize参数是(width, height)label_array = np.array(label_resized)# 如果是RGBA图像,使用alpha通道作为掩码if len(label_array.shape) == 3 and label_array.shape[2] == 4:mask = label_array[:, :, 3] > 128 # alpha > 128为前景elif len(label_array.shape) == 2:mask = label_array > 128 # 灰度图,> 128为前景else:mask = label_array[:, :, 0] > 128 # RGB图,使用红色通道# 展平掩码mask_flat = mask.flatten()# 确保特征和标签尺寸匹配if feat.shape[0] == mask_flat.shape[0]:X_train.append(feat)y_train.append(mask_flat)else:print(f"Skipping image {i} due to size mismatch: {feat.shape[0]} vs {mask_flat.shape[0]}")# 合并所有数据if X_train:X_train = np.vstack(X_train)y_train = np.hstack(y_train)return X_train, y_trainelse:return None, None# 准备训练数据
X_train, y_train = prepare_training_data(features, labels, processed_shapes)if X_train is not None:print(f"Training data shape: {X_train.shape}")print(f"Training labels shape: {y_train.shape}")print(f"Foreground pixels: {np.sum(y_train)} ({100*np.sum(y_train)/len(y_train):.2f}%)")# 训练线性分类器print("Training linear classifier...")classifier = LogisticRegression(max_iter=1000, verbose=1)classifier.fit(X_train, y_train)print("Training completed!")# 评估模型train_score = classifier.score(X_train, y_train)print(f"Training accuracy: {train_score:.4f}")# 可视化结果def visualize_prediction(image, label, features, classifier, idx):"""可视化预测结果"""fig, axes = plt.subplots(1, 3, figsize=(15, 5))# 原图axes[0].imshow(image)axes[0].set_title("Original Image")axes[0].axis('off')# 真实标签label_img = labelif hasattr(label_img, 'mode') and label_img.mode == 'RGBA':label_array = np.array(label_img)if len(label_array.shape) == 3:mask = label_array[:, :, 3] # alpha通道axes[1].imshow(mask, cmap='gray')else:axes[1].imshow(label_img, cmap='gray')axes[1].set_title("Ground Truth")axes[1].axis('off')# 预测结果feat = features[idx].squeeze()with torch.no_grad():predictions = classifier.predict_proba(feat)[:, 1] # 前景概率# 获取特征数量并计算patch维度num_patches = feat.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = processed_shapes[idx]pred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)pred_array = np.array(pred_img)axes[2].imshow(pred_array, cmap='jet', alpha=0.7)axes[2].set_title("Predictions")axes[2].axis('off')plt.tight_layout()plt.show()# 显示几个预测示例for i in range(min(3, len(images))):visualize_prediction(images[i], labels[i], features, classifier, i)# 计算精度-召回率曲线def compute_pr_curve(X_train, y_train, classifier):"""计算精度-召回率曲线"""y_scores = classifier.predict_proba(X_train)[:, 1]precision, recall, thresholds = precision_recall_curve(y_train, y_scores)ap_score = average_precision_score(y_train, y_scores)return precision, recall, ap_scoreprecision, recall, ap_score = compute_pr_curve(X_train, y_train, classifier)print(f"Average Precision: {ap_score:.4f}")# 绘制PR曲线plt.figure(figsize=(8, 6))plt.plot(recall, precision, marker='.')plt.xlabel('Recall')plt.ylabel('Precision')plt.title(f'Precision-Recall Curve (AP={ap_score:.4f})')plt.grid(True)plt.show()# 保存模型model_path = "foreground_segmentation_model.pkl"with open(model_path, 'wb') as f:pickle.dump(classifier, f)print(f"Model saved to {model_path}")# 保存特征提取器配置config_path = "feature_extractor_config.pkl"config = {'model_name': MODEL_NAME,'patch_size': 16, # DINOv3 ViT-L/16}with open(config_path, 'wb') as f:pickle.dump(config, f)print(f"Feature extractor config saved to {config_path}")else:print("Failed to prepare training data due to size mismatch")# 测试新图像的推理函数
def predict_foreground(model, processor, classifier, image_path):"""对新图像进行前景分割预测"""# 加载图像image = Image.open(image_path).convert('RGB')# 提取特征inputs = processor(images=image, return_tensors="pt")inputs = {k: v.cuda() for k, v in inputs.items()}with torch.no_grad():outputs = model(**inputs, output_hidden_states=True)features = outputs.last_hidden_state[:, 1:].cpu().numpy().squeeze()# 预测predictions = classifier.predict_proba(features)[:, 1]# 根据特征数量计算patch维度num_patches = features.shape[0]feat_h = int(np.sqrt(num_patches))feat_w = num_patches // feat_hwhile feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_hpred_map = predictions.reshape(feat_h, feat_w)# 上采样到原图尺寸_, _, h, w = inputs['pixel_values'].shapepred_img = Image.fromarray((pred_map * 255).astype(np.uint8))pred_img = pred_img.resize((w, h), resample=Image.BILINEAR)return np.array(pred_img)print("\nTo predict foreground for a new image, use:")
print("prediction = predict_foreground(model, processor, classifier, 'path/to/image.jpg')")# 修改后的代码,支持本地图片
test_image_fpath = r"E:\dinov3\图片\原神.png"def load_image_from_path(path: str) -> Image:"""支持本地和网络图片路径"""if path.startswith('http'):# 网络图片with urllib.request.urlopen(path) as f:return Image.open(f).convert("RGB")else:# 本地图片return Image.open(path).convert("RGB")# 使用修改后的函数加载图片
test_image = load_image_from_path(test_image_fpath)# 使用processor处理图像
inputs = processor(images=test_image, return_tensors="pt")
test_image_processed = inputs['pixel_values'][0] # 获取处理后的图像with torch.inference_mode():with torch.autocast(device_type='cuda', dtype=torch.float32):# 使用训练好的模型提取特征inputs_cuda = {k: v.cuda() for k, v in inputs.items()}outputs = model(**inputs_cuda, output_hidden_states=True)feats = outputs.last_hidden_state[:, 1:] # 去掉CLS tokenx = feats.squeeze().detach().cpu()if len(x.shape) == 1:x = x.unsqueeze(0) # 确保至少有2个维度# 根据实际特征数量计算patch维度
num_patches = x.shape[0]
feat_h = int(np.sqrt(num_patches))
feat_w = num_patches // feat_h
# 确保计算出的维度乘积等于特征数量
while feat_h * feat_w != num_patches:feat_h += 1feat_w = num_patches // feat_h# 使用训练好的classifier进行预测
fg_scores = classifier.predict_proba(x)[:, 1]# 重塑为特征图形状
fg_score = fg_scores.reshape(feat_h, feat_w)# 应用中值滤波
fg_score_mf = torch.from_numpy(signal.medfilt2d(fg_score, kernel_size=3))# 上采样到输入图像尺寸
_, _, h, w = inputs['pixel_values'].shape
fg_score_upsampled = Image.fromarray((fg_score * 255).astype(np.uint8))
fg_score_upsampled = fg_score_upsampled.resize((w, h), resample=Image.BILINEAR)
fg_score_upsampled = np.array(fg_score_upsampled)fg_score_mf_upsampled = Image.fromarray((fg_score_mf.numpy() * 255).astype(np.uint8))
fg_score_mf_upsampled = fg_score_mf_upsampled.resize((w, h), resample=Image.BILINEAR)
fg_score_mf_upsampled = np.array(fg_score_mf_upsampled)# 可视化结果
plt.figure(figsize=(9, 3), dpi=300)
plt.subplot(1, 3, 1)
plt.axis('off')
plt.imshow(TF.to_pil_image(test_image_processed))
plt.title('input image')plt.subplot(1, 3, 2)
plt.axis('off')
plt.imshow(fg_score_upsampled, cmap='jet')
plt.title('foreground score')plt.subplot(1, 3, 3)
plt.axis('off')
plt.imshow(fg_score_mf_upsampled, cmap='jet')
plt.title('+ median filter')plt.tight_layout()
plt.show()