硅基计划5.0 MySQL 壹 初识MySQL 初版

文章目录
- 一、数据集合操作
- 1. 展示所有数据库
- 2. 创建新的数据库
- 3. 操作数据库
- 二、数据类型
- 1. 数字
- 2. 字符串
- 3. 日期
- 三、数据表操作
- 1. 查看数据库中所有的表
- 2. 创建表
- 3. 查看表的结构
- 4. 修改表
- 5. 增删改查
- 1. 新增
- 2. 简易普通查询
- 3. 条件查询
一、数据集合操作
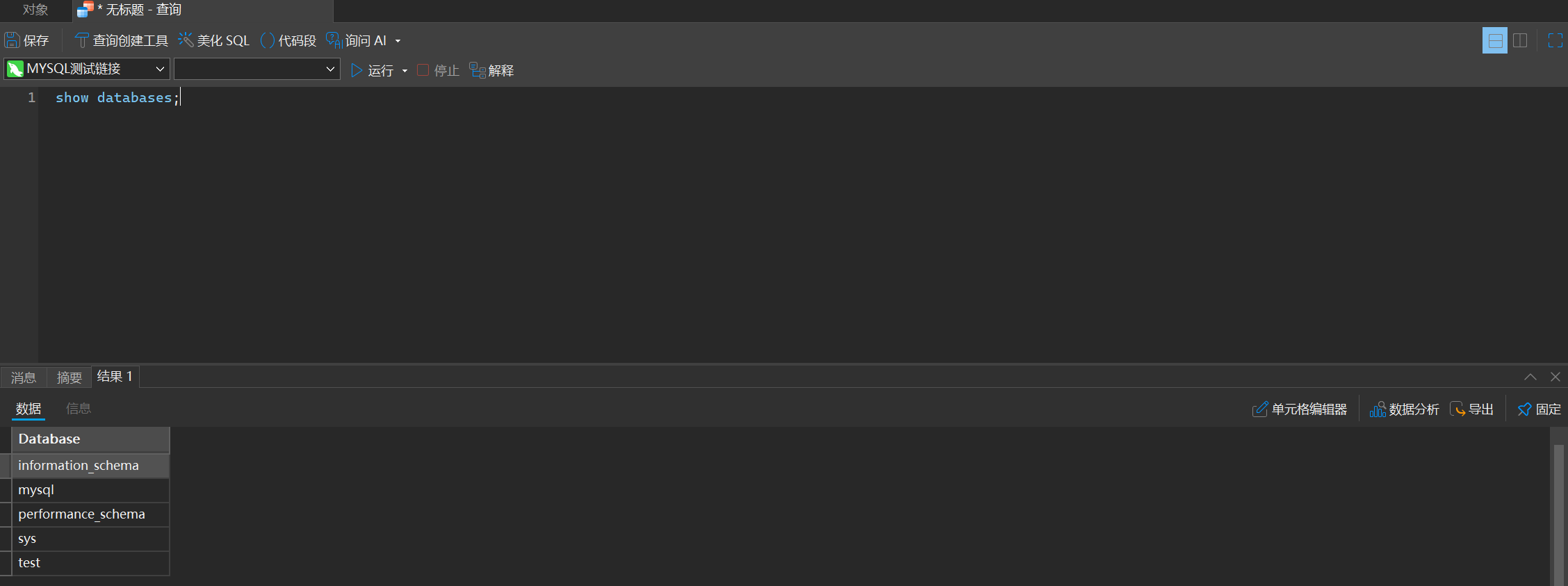
1. 展示所有数据库
show databases;
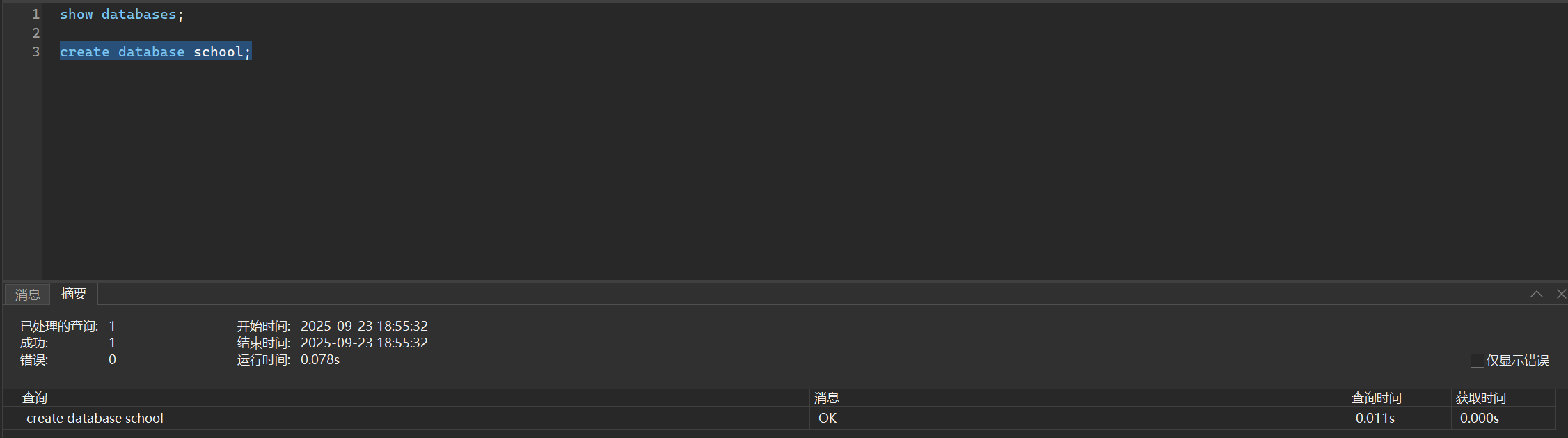
2. 创建新的数据库
请注意,我们的名字不可以和关键字一样,但是如果你非要这样,你可以使用反引号`扩起来
create database school;
当然,如果你为了更加安全,如果出现重名,则不会再次创建
create database if not exists school;
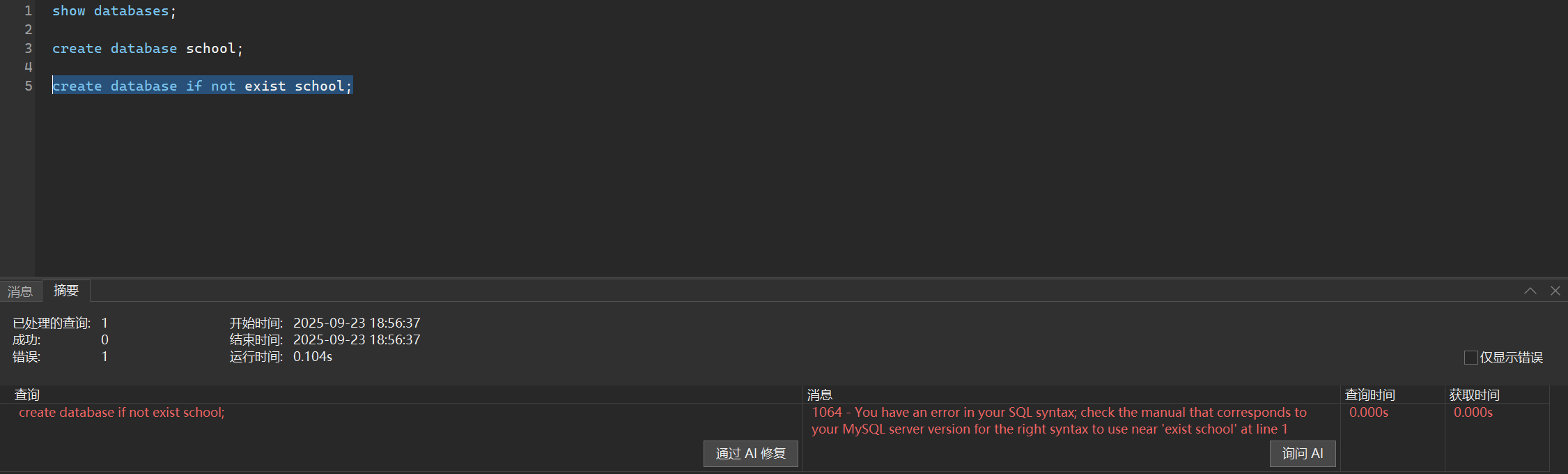
你看,我们名字重复了就不会再创建了
同时,如果我们想在创建数据库的时候指定字符集,即内部内容的编码格式,我们可以
create database if not exists home charset utf8mb4;
简要说说字符集utf8和utf8mb4区别
主要区别就是utf8mb4比utf8多了个emjio表示
3. 操作数据库
选中数据库
use home;
删除数据库——⚠️⚠️⚠️
use home;
二、数据类型
1. 数字
bit(4)括号中的数字可不写,括号中数字表示几个比特位,最多不超过64
tinyint——byte类型,smallint——short类型,mediumint(3字节),int,bigint——long类型
他们后边都可以加括号填写数字,而数字表示的是显示的数字大小,并不是指的是其实际大小
而对于小数,基本上也是一致的
float(A,B) double(A,B) decime(A,B)A表示几位数,B表示精确位数
但是为什么使用dicime要三思呢,虽然其存储精度很高,但是其非常耗内存耗时间啊
2. 字符串
char()固定长度字符串
varchar()可变长度字符串,参数一样不是指的实际大小,会自适应长度
tinytext() text() mediumtext() longtext表示的是文本类型
我们一般不适用SQL中的二进制类型存储数据,因为数据类型非常巨大,会消耗非常多的计算机资源,我们一般存储的都是索引
3. 日期
timestamp()是表示的时间戳,利用这个可以计算与1970.1.1 0:00:00的差值表示当前时间
datatime()表示的是大的时间戳,格式为YYYY--MM--DD MM:HH:SS
date()指标是年月日,3个字节,不推荐使用,也很少使用
三、数据表操作
我们之前选好了数据库,而在数据库中我们是由一个个表组成的,因此接下来我们进行表的操作
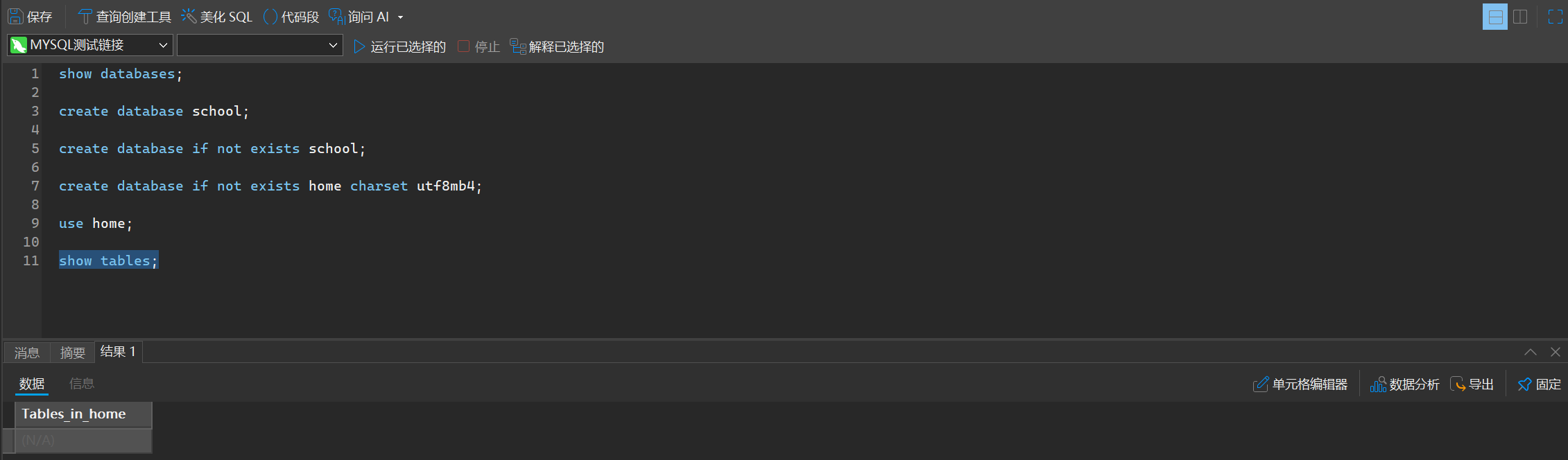
1. 查看数据库中所有的表
show tables;
2. 创建表
我们每个列命名都是不是采用驼峰命名,而是采用蛇形命名法,即不同单词之间使用_隔开
同理我们还是可以去指定字符集或者是检测是否重名等操作
create table if not exists student_information(name varchar(10),school_id int,gender varchar(1)) charset utf8mb4;
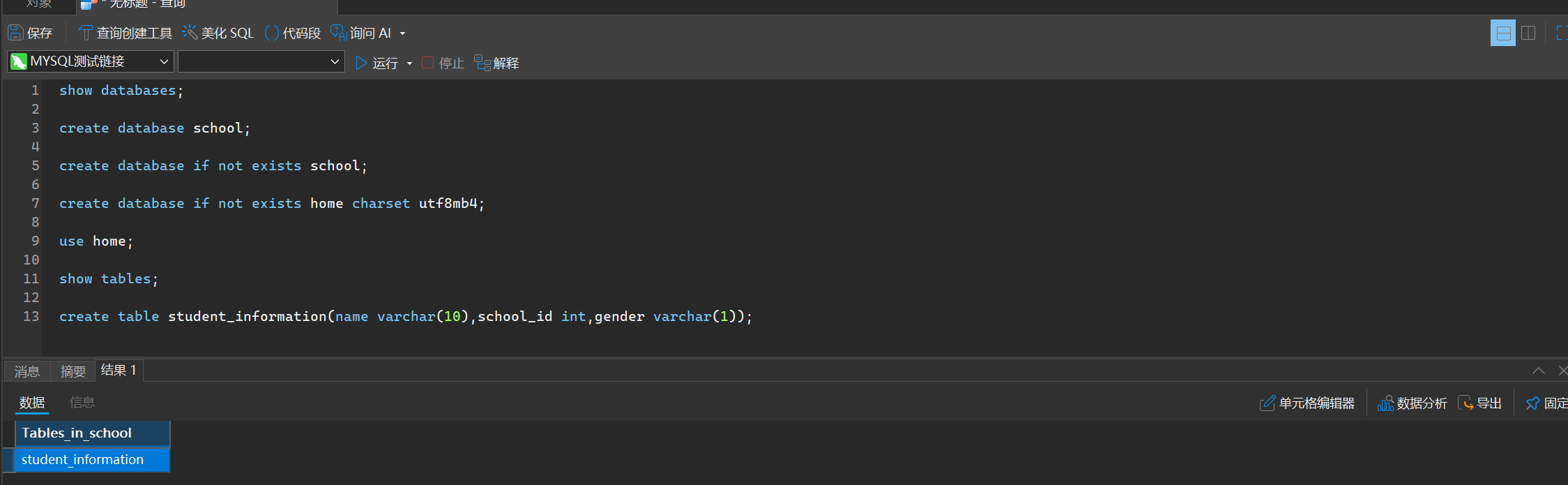
这个文件是真的创建到我们电脑上的,我们可以可以打开看看

3. 查看表的结构
desc student_informations;
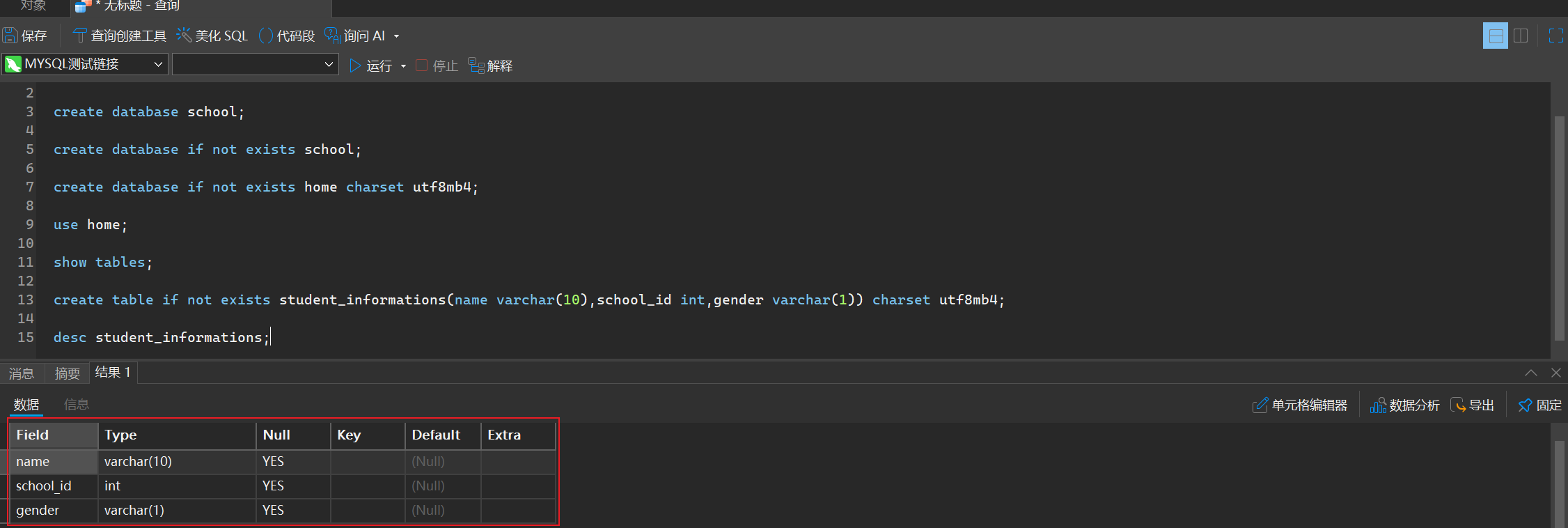
虽然可以简写,但是我们更加推崇全写,这样可以提高代码规范性,提高可读性
describe student_information;
4. 修改表
语法格式
alter table 表名 具体操作
我们具体有哪一些操作呢?
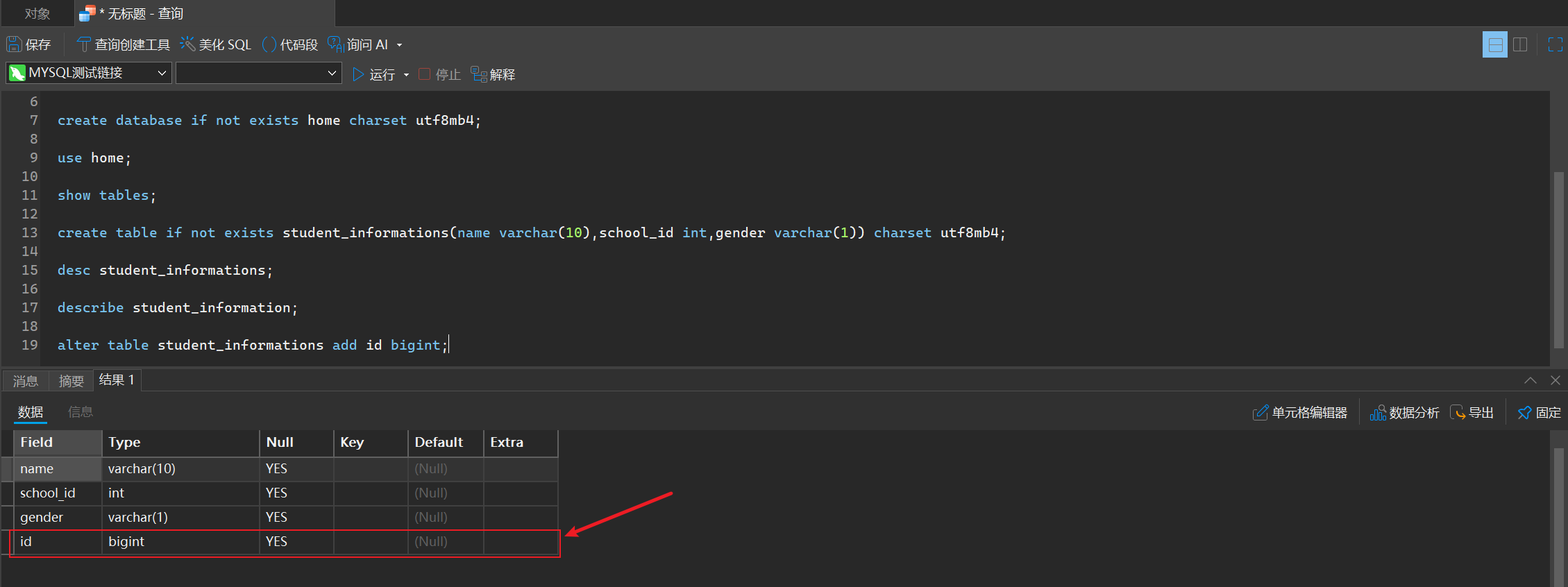
- 添加列/修改列
alter table student_informations add id bigint;
alter table student_informations modify id int;
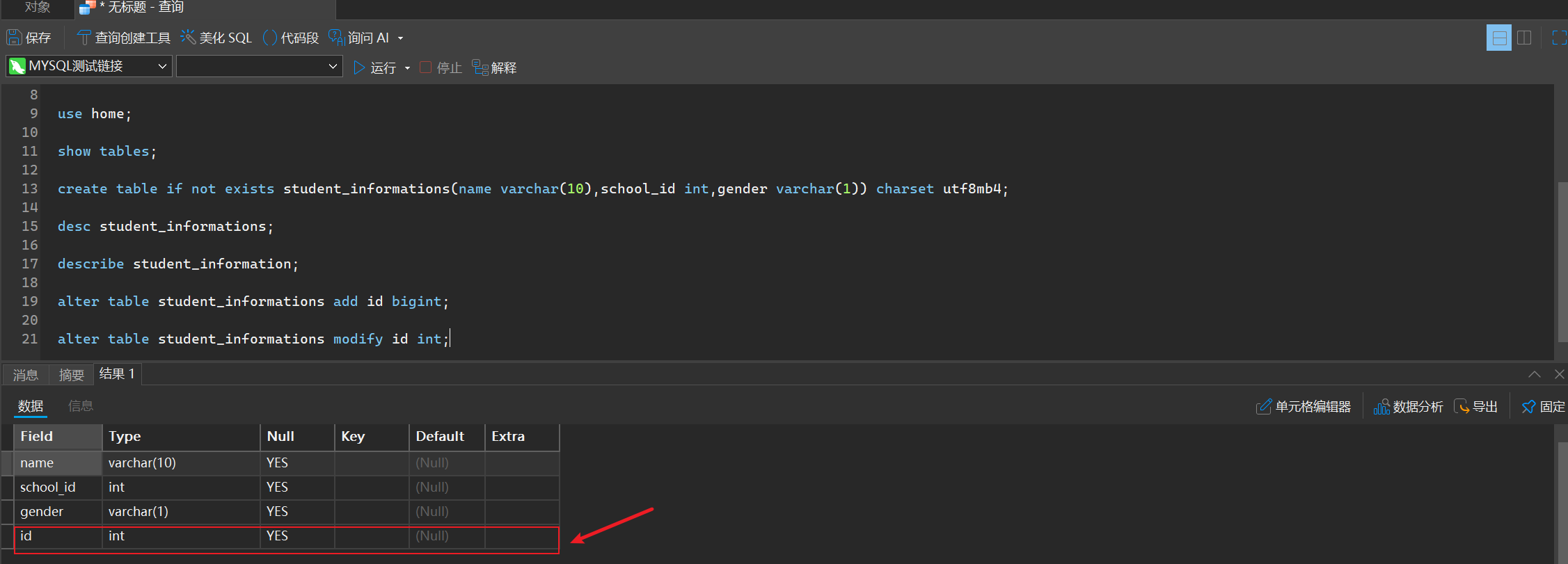
- 删除列
alter table student_informations drop id;
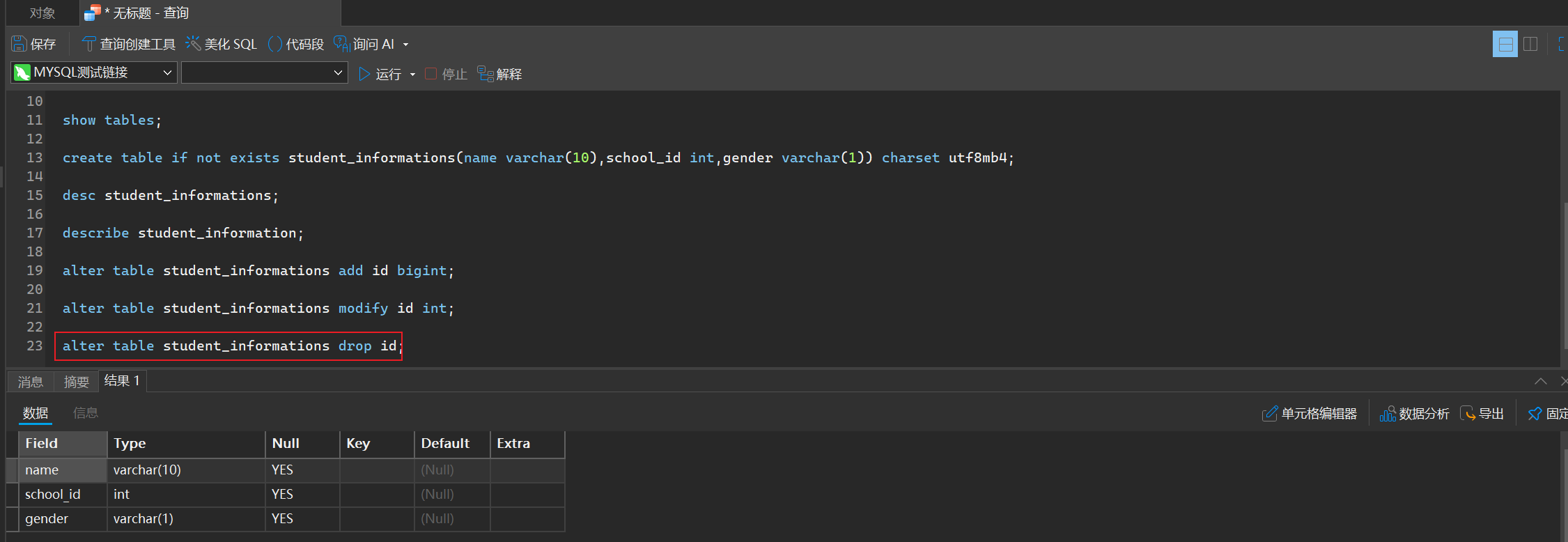
- 重命名
alter table student_informations rename column name to real_name;
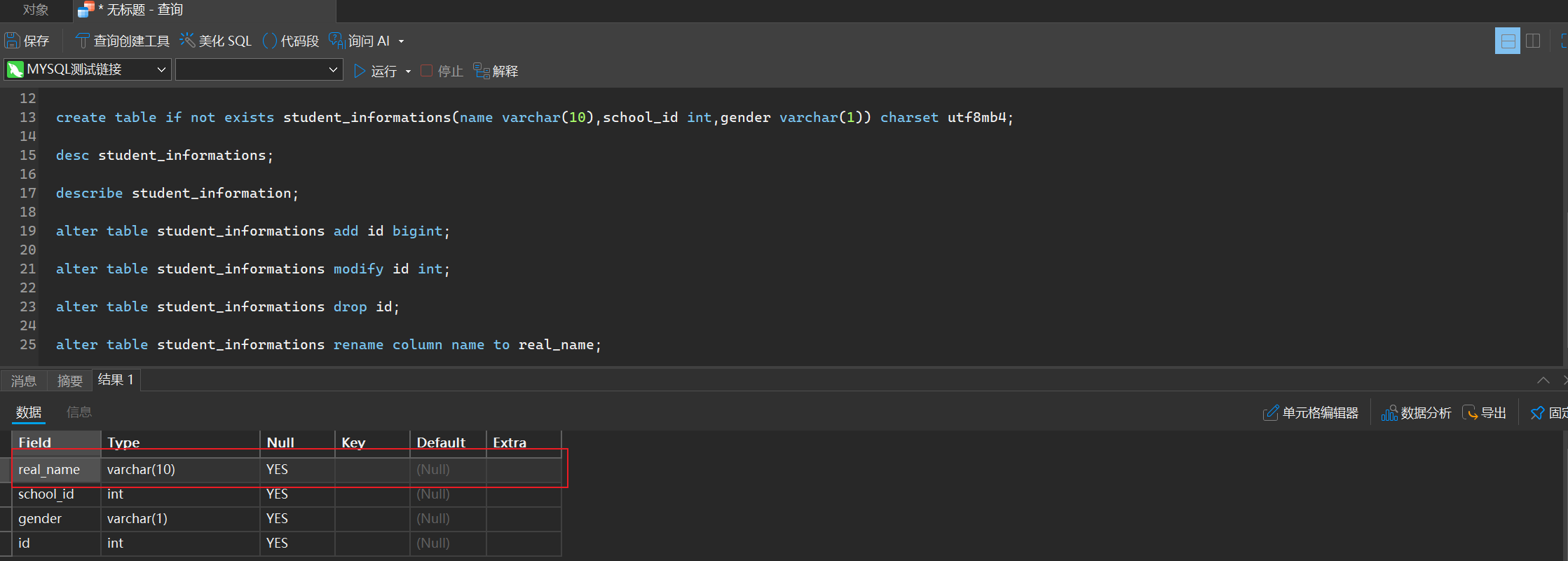
- 删除表
drop table goods;
注意,这也是一个非常危险的操作,请勿轻易尝试
5. 增删改查
1. 新增
insert int 表名 (可以指定哪些列) values (对应你所指定的列,顺序不能颠倒)
比如我创建一个学生成绩的表作为演示
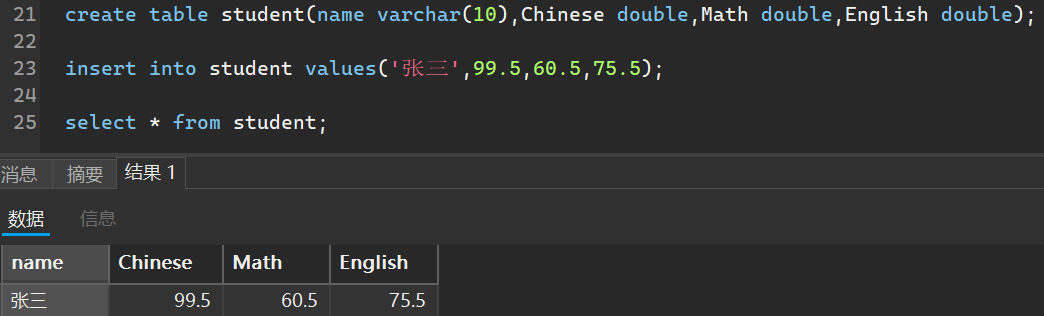
当然,我可以指定添加哪些列的成绩,未添加的默认是空
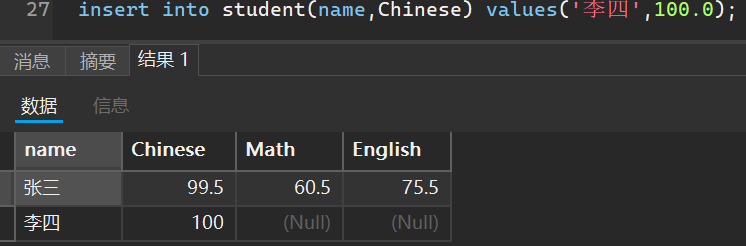
2. 简易普通查询
注意,我们查询的结果是一个临时表,不能数值进行修改
- 全列查询
select * from student;
这个会查看指定表的全部内容,会导致服务器通信卡顿,因为一个表可能有非常非常多的数据,查询导致的贷款占用非常高
- 指定列查询
select 列名1,列名2,...... from 表名;
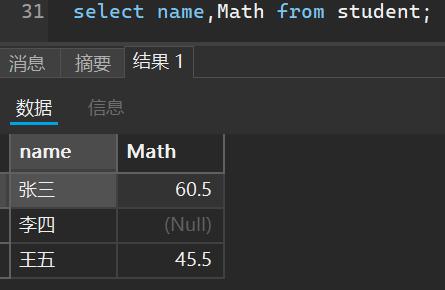
- 带有表达式的查询
select 列名1和表达式1,列名2和表达式2,... from 表名;
就拿刚刚的表来说,我们可以计算总成绩和平均分
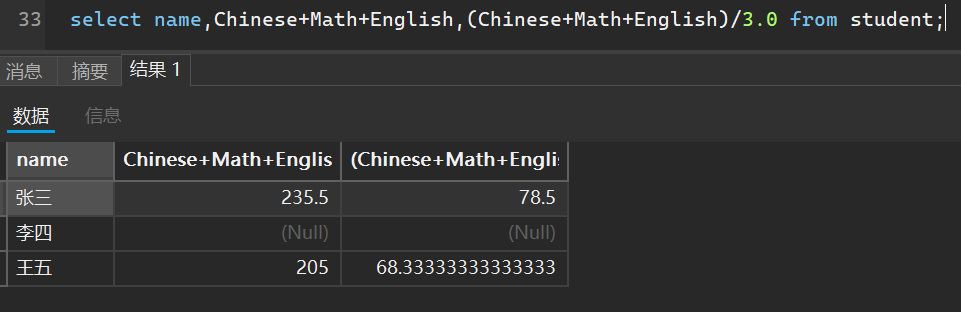
- 查询的结果起别名
select 表达式 as 别名 from 表名;
就拿刚刚我们的总成绩和平均成绩举个例子
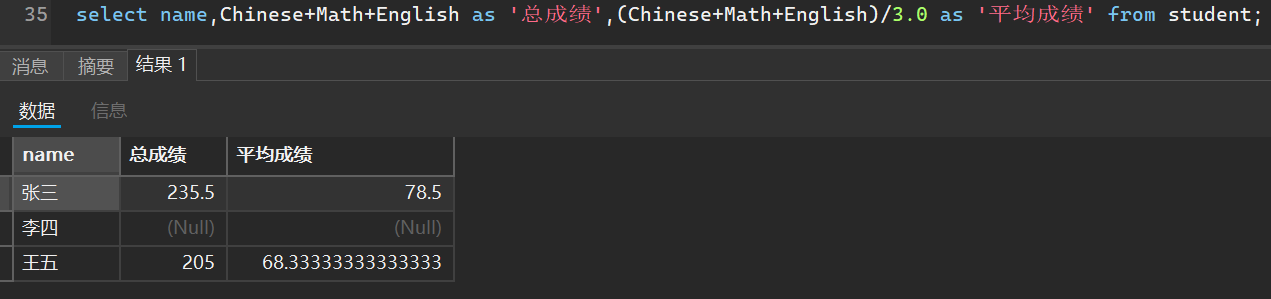
- 结果去重
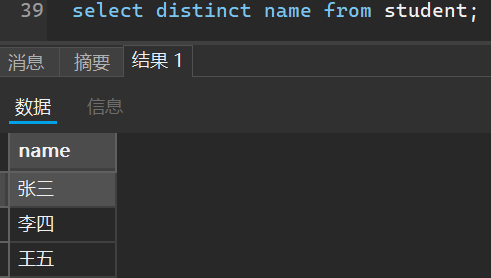
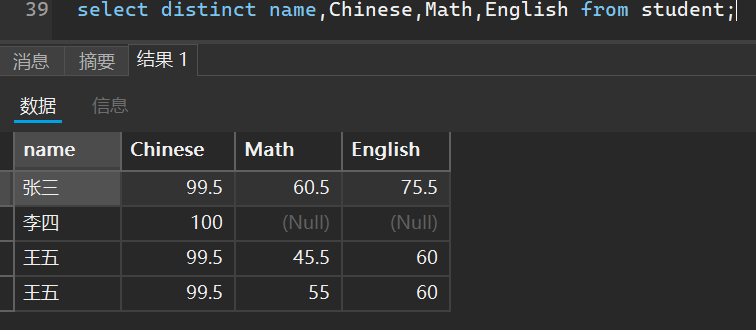
select distinct 列名1,列名2,... from 表名 ;
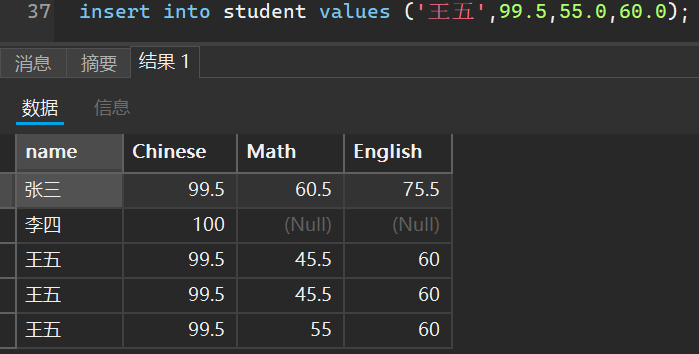
当我们去重条件只有一列的时候,只会根据这一列进行判断然后去重
当我们去重条件有多个的时候,只有这多个列的条件全部满足才会进行去重操作
select distinct name from student;
select distinct name,Chinese,Math,English from student;
3. 条件查询
注意,我们查询的结果是一个临时表,不能数值进行修改
select 表达式或列名 from 表名 where 条件
基本运算符都差不多,只不过在SQL中,=不可以和null进行比较,比较的结果还是null
并且在SQL中,null表示假
因此在SQL中我们和null比较使用的是<=>,比较结果就是true,而且也可以进行多列比较
其他的比较
- 范围比较:
value between A and B,范围从[A,B] - 集合比较:
value in (数字1,数字2...),表示看比较多内容是否在集合()中有对应数字包含 - 和
null比较:is null或is not null,可判断一列是否是空值 - 模糊比较:
like - 逻辑与:
and,逻辑或:or,逻辑否定:not
请注意,我们不可以在条件中使用别名,否则会报错,因为我们每次进行条件比较的时候先是看的条件再去看的表达式,因此你定义在表达式中的别名在条件中还没有初始化好
select name,Math as result from student where result < 60;//错误写法
我们现在开始进行实操
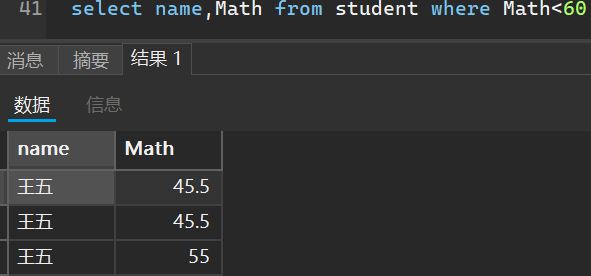
- 查询数学不及格的名单
select name,Math from student where Math<60;
2. 查询总分在220分以下的人
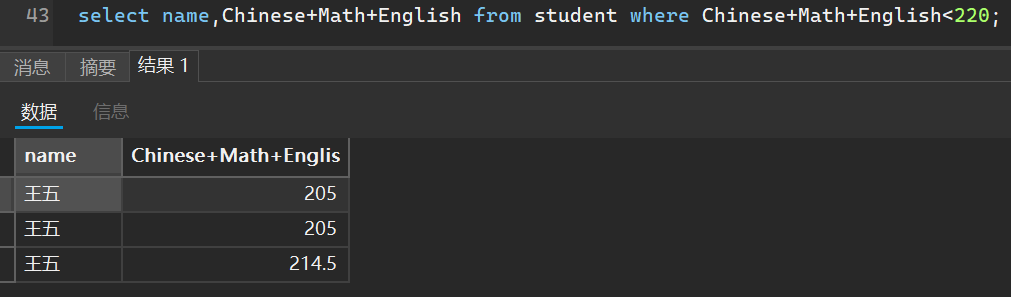
select name,Chinese+Math+English from student where Chinese+Math+English<220;
3. 查询数学和英语都及格的人
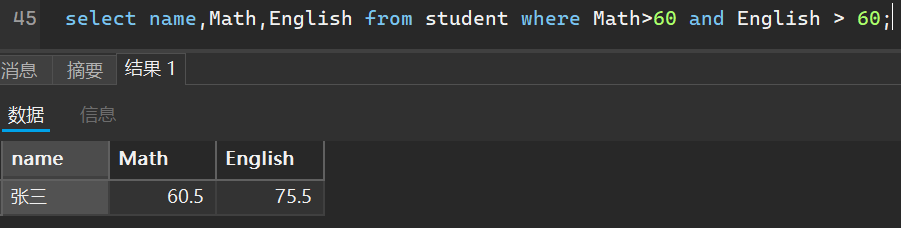
select name,Math,English from student where Math>60 and English > 60;
4. 查询数学或英语都及格的人
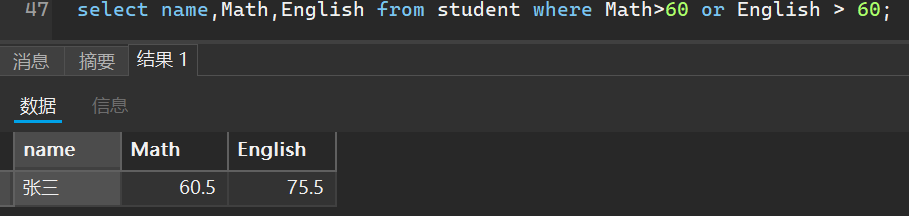
select name,Math,English from student where Math>60 or English > 60;
5. 模糊匹配
我们可以使用通配符,像我们之前的查询整个表的结构使用的是*,因此我们在查询信息时候
%代表多个字符,_代表一个字符
比如我想看看刚刚那个表中有多少个姓王的人
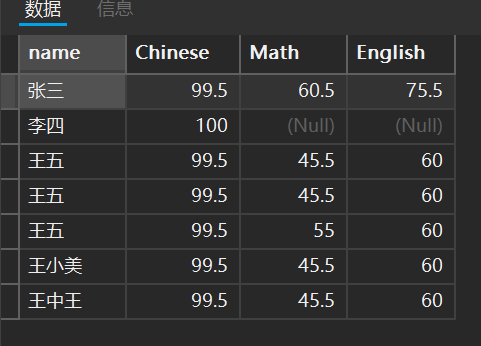
select * from student where name like '王%';
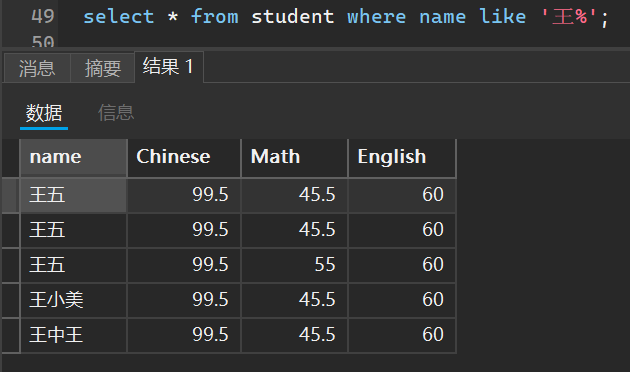
有多少个以王字结尾的人
select * from student where name like '%王';
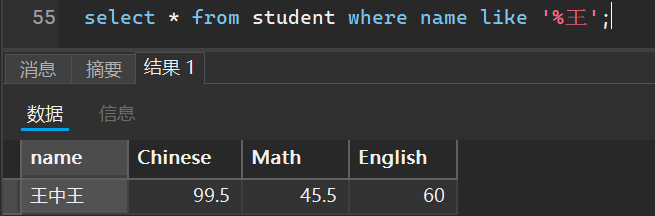
有多少个包含王字的人
select * from student where name like '%王%';
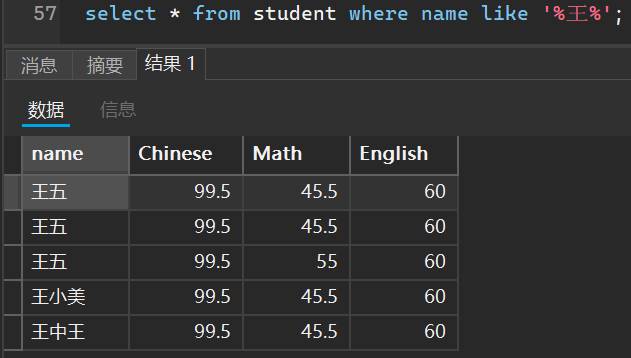
有多少个姓王但是是两个字名字的人
select * from student where name like '王_';
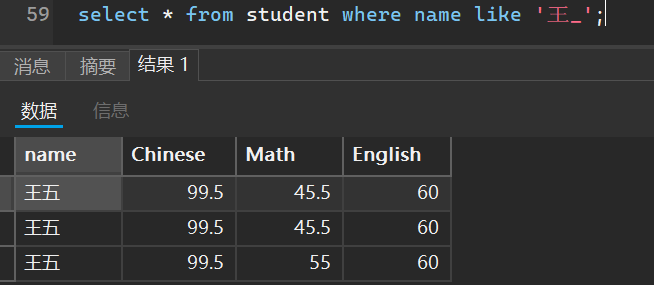
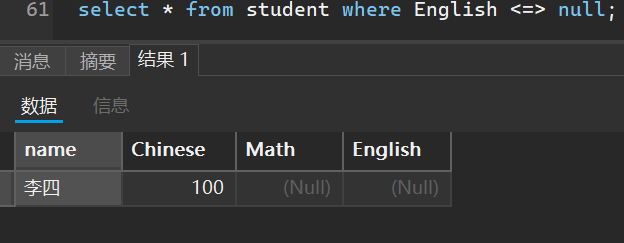
6. 空查询
select * from student where English <=> null;