K8S部署的rook-ceph下线osd流程
背景
因为某个osd是ssd类型存储,现在其他盘都是hdd,所以把这个ssd的存储下线,于是开始整个流程。
要下线的盘是osd.0。
操作流程
进入到ceph的tool工具pod进行操作
kubectl exec -it -n rook-ceph rook-ceph-tools-xxx -- sh
把要下线的osd设置 noup 标志(防止 OSD 自动上线)
ceph osd add-noup 0
把要下线的osd权重设置为0
ceph osd crush reweight osd.0 0
执行 ceph -w 实时监控,直到该 OSD 的 PGs 变为 0 且集群状态稳定(HEALTH_OK 或 HEALTH_WARN 但无数据不一致告警)
ceph -w
查看osd.0的具体pg
ceph pg ls-by-osd osd.0 | grep -v ^PG | sed -e '/^$/d' -e '/^\*$/d' | awk '{print $1}' | grep '^[0-9]\+\.[0-9a-fA-F]\+$' | sort -u
查看osd的pg数量
ceph pg ls-by-osd osd.0 | grep -v ^PG | sed -e '/^$/d' -e '/^\*$/d' | awk '{print $1}' | grep '^[0-9]\+\.[0-9a-fA-F]\+$' | sort -u | wc -l

数据迁移完成后在ui界面上查看数量也是0,并且没有正在迁移的pg
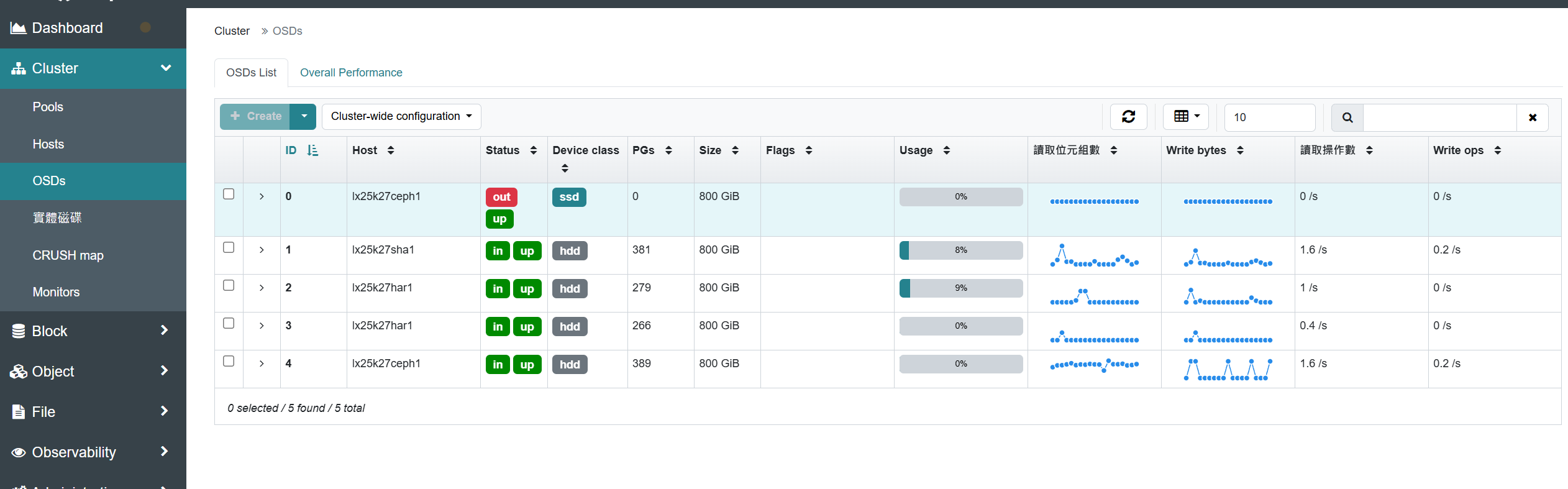
把要下线的osd标记 为 down
ceph osd down 0
把要下线的OSD标记为 out,其实设置权重为0就会自动触发迁移,等数据迁移执行完成后再标记为out的流程最符合规范,当然直接执行也可。
ceph osd out 0
在ceph的k8s cluster配置文件中更改配置取消osd对应盘配置
kubectl get cephcluster rook-ceph -n rook-ceph -o yaml > cephcluster.yaml
将其中osd对应的node盘删除,圈内的格式全部删除,哪个下线就删除哪个配置
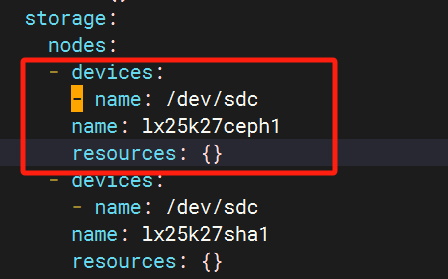
重新加载配置
kubectl apply -f cephcluster.yaml
加载完最好等个五分钟再操作让配置生效。
接下来,在ceph集群中永久删除 OSD(操作不可逆)
ceph osd purge 0 --yes-i-really-mean-it
删除 OSD 认证密钥
ceph auth del osd.0
ceph上的操作基本完成,接下来操作k8s中现有的资源
kubectl get deploy -n rook-ceph
删除osd.0的deployment资源
kubectl delete deploy rook-ceph-osd-0 -n rook-ceph
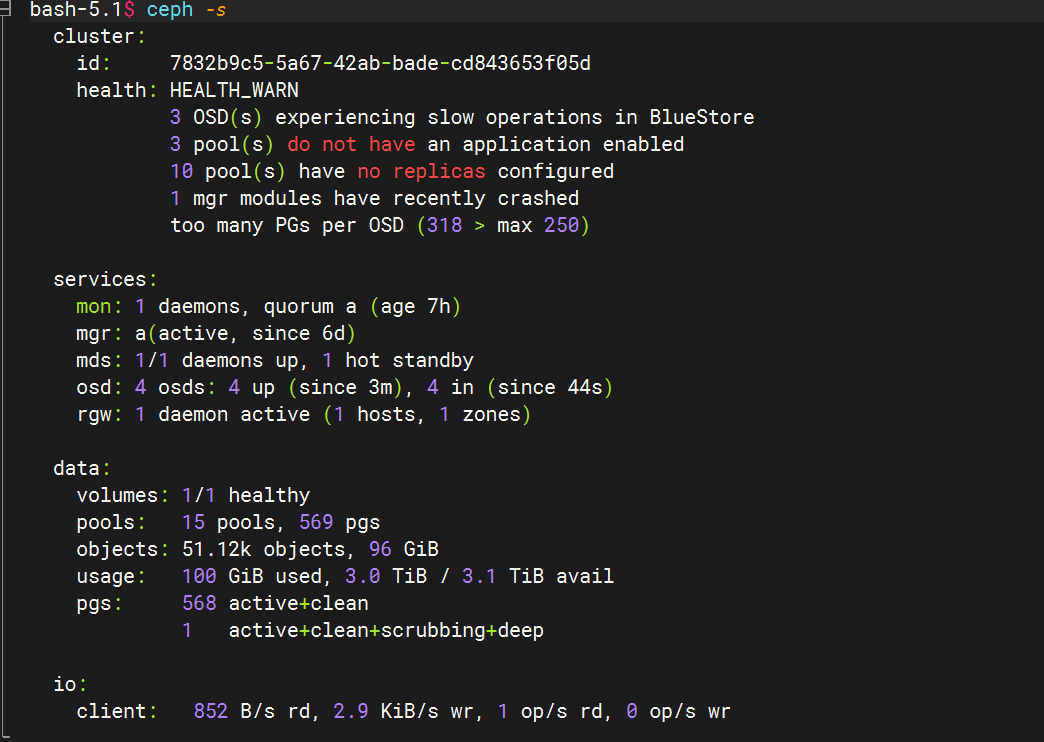
在tool中查看osd数量
ceph -s
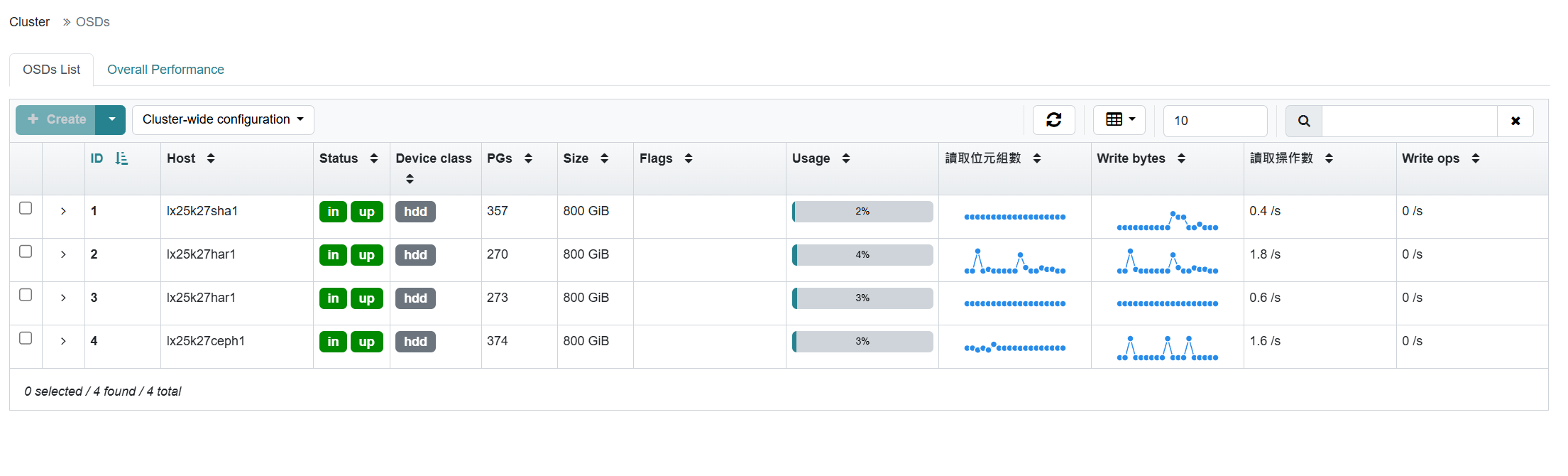
在web界面上查看结果
过程中遇见的问题
按这个流程操作下来,最后在ceph -s查看的时候查看还是原来的osd数量并没有减少
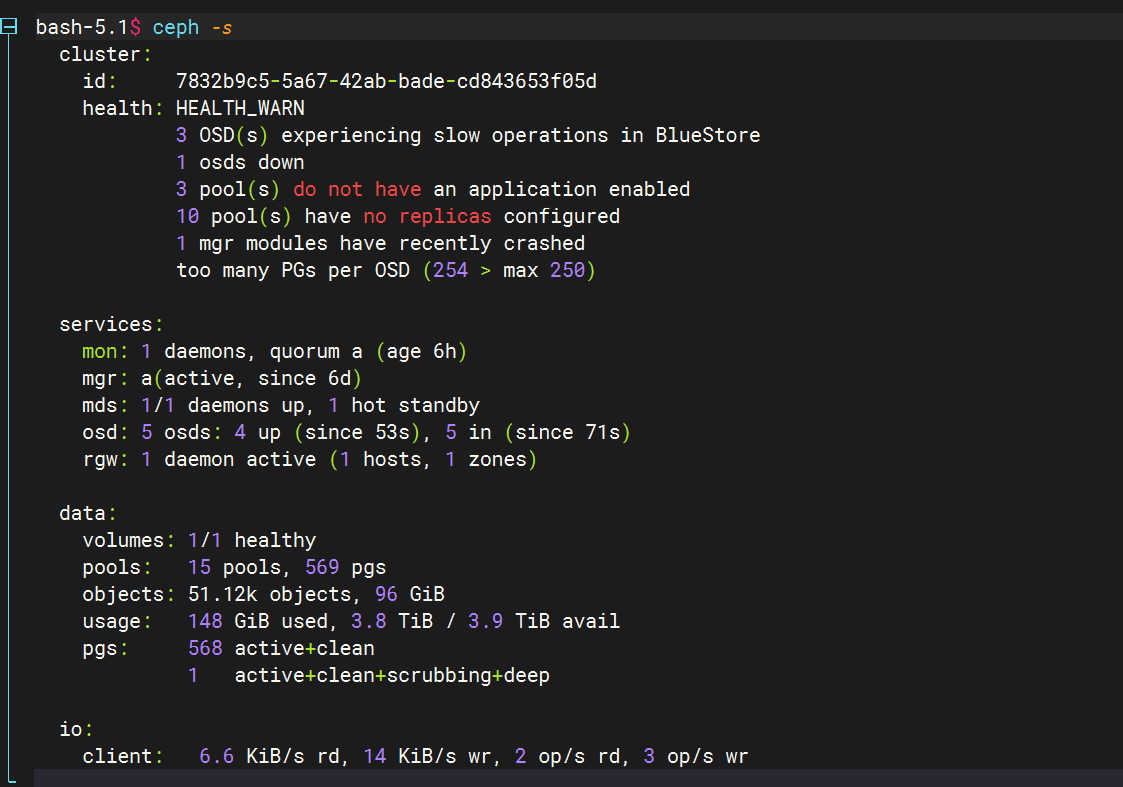
这个时候会觉得操作文档有问题,实际过程中我也遇见了这问题
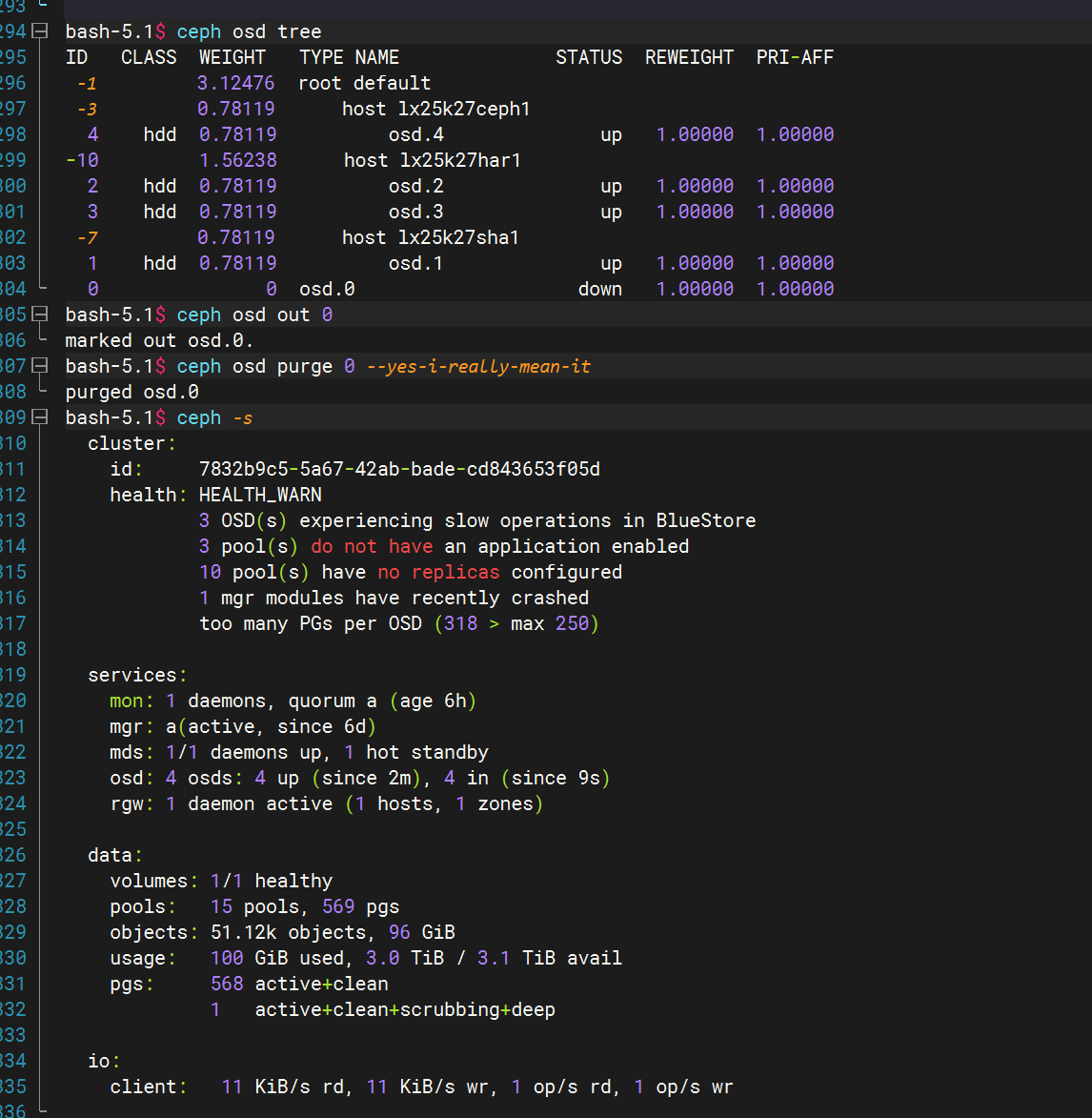
ceph osd purge 0 --yes-i-really-mean-it的命令重新执行后就查询不到osd了,但在之前的流程中这个命令已经执行过了。
因为ceph的配置文件更改加载需要时间,如果配置没生效前执行这个流程,还会重新拉起那个下线的osd,然后osd的可用数量又变成原本数量。
这就是在过程中再重载配置等几分钟的原因,在出现这个问题后我也并没有执行什么其他操作只是再次删除了osd0。
ceph osd purge 0 --yes-i-really-mean-it
如果等待后还是会自动上线可以检查集群配置文件,以及osd对应ID号的配置是否删除。