2、CPU深度解析:从微架构到性能优化
核心学习目标:深入理解现代CPU的微架构设计原理,掌握多核处理器的工作机制,理解CPU性能优化的关键技术,建立对串行计算优化策略的系统性认知,为后续理解GPU并行计算的优势奠定扎实基础。
为什么要深入学习CPU? 在进入CUDA并行计算的世界之前,我们必须深刻理解CPU的工作原理和局限性。正如一位建筑师在设计摩天大楼之前必须理解传统建筑的结构原理一样,只有透彻理解CPU的串行计算模式,我们才能真正领悟GPU并行计算的革命性意义。CPU代表了计算机科学在串行优化方向的巅峰智慧,而这些智慧将成为我们理解现代异构计算系统的基石。
有些mermaid图看不清,由于没渲染成功的原因,可以到这个网站:mermaid渲染——www.jyshare.com
2.1 CPU内核架构:精密机械的工程艺术
> CPU微架构的整体设计哲学
现代CPU的设计就像一座精密的工厂,每个组件都经过精心设计,以最大化单线程执行效率(Single-Thread Performance)。这种设计哲学与GPU的大规模并行思路形成鲜明对比。
微架构设计的核心权衡:CPU设计者面临的根本挑战是如何在有限的晶体管预算下,最大化单个指令流的执行效率。这导致了以下设计特点:
- 复杂控制逻辑占主导:约35-40%的晶体管用于分支预测、乱序执行、寄存器重命名等控制逻辑
- 大容量缓存系统:约40-45%的晶体管用于多级缓存,减少内存访问延迟
- 少而强的执行单元:只有15-20%的晶体管用于实际计算,但每个执行单元都极其复杂
> 指令执行的四个阶段深度解析
现代CPU将 指令执行周期(Instruction Execution Cycle) 分解为多个精细的阶段,每个阶段都有专门的硬件支持:
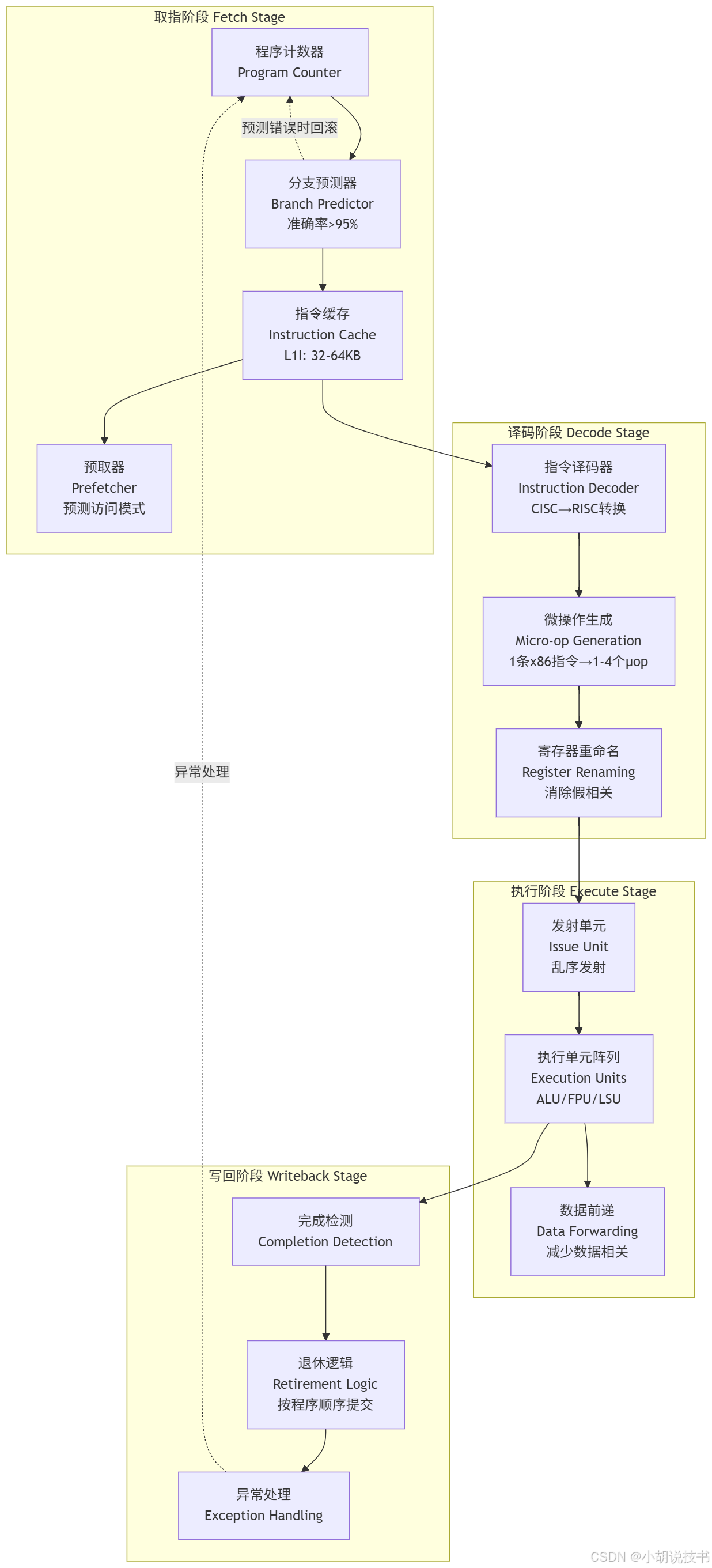
下面是未渲染版。
flowchart TDsubgraph "取指阶段 Fetch Stage"PC[程序计数器<br/>Program Counter]BP[分支预测器<br/>Branch Predictor<br/>准确率>95%]IC[指令缓存<br/>Instruction Cache<br/>L1I: 32-64KB]PF[预取器<br/>Prefetcher<br/>预测访问模式]endsubgraph "译码阶段 Decode Stage" DEC[指令译码器<br/>Instruction Decoder<br/>CISC→RISC转换]UOP_GEN[微操作生成<br/>Micro-op Generation<br/>1条x86指令→1-4个μop]RENAME[寄存器重命名<br/>Register Renaming<br/>消除假相关]endsubgraph "执行阶段 Execute Stage"ISSUE[发射单元<br/>Issue Unit<br/>乱序发射]EXEC_UNITS[执行单元阵列<br/>Execution Units<br/>ALU/FPU/LSU]FWD[数据前递<br/>Data Forwarding<br/>减少数据相关]endsubgraph "写回阶段 Writeback Stage"COMPLETE[完成检测<br/>Completion Detection]RETIRE[退休逻辑<br/>Retirement Logic<br/>按程序顺序提交]EXCEPT[异常处理<br/>Exception Handling]endPC --> BP --> IC --> PFIC --> DEC --> UOP_GEN --> RENAMERENAME --> ISSUE --> EXEC_UNITS --> FWDEXEC_UNITS --> COMPLETE --> RETIRE --> EXCEPTBP -.->|预测错误时回滚| PCEXCEPT -.->|异常处理| PC
让我们通过一个具体的例子理解这个过程:
指令示例:ADD EAX, [EBX + ECX*2 + 8]
这条x86指令需要:从内存地址(EBX + ECX*2 + 8)读取数据,与EAX相加,结果写回EAX1. 取指阶段 (Fetch):- 程序计数器指向指令地址- 分支预测器预测下一条指令位置(如果是分支指令)- 从L1指令缓存读取指令字节- 预取器预测后续可能访问的指令2. 译码阶段 (Decode):- 译码器识别这是一条复杂的x86指令- 分解为3个微操作:μop1: AGU计算有效地址 (EBX + ECX*2 + 8)μop2: LOAD从内存读取数据μop3: ADD执行加法运算- 寄存器重命名:EAX→P15, EBX→P23, ECX→P31(物理寄存器)3. 执行阶段 (Execute):- 发射单元将μop分发到不同执行单元:* μop1→地址生成单元AGU* μop2→加载存储单元LSU * μop3→整数运算单元ALU- 乱序执行:如果数据就绪,μop可以乱序执行- 数据前递:ALU结果直接转发给依赖指令4. 写回阶段 (Writeback):- 重排序缓冲区确保按程序顺序提交结果- 检查异常(如页面错误、除零等)- 更新架构寄存器状态- 释放物理寄存器资源
> 超标量执行:并行处理的CPU实现
超标量执行(Superscalar Execution) 是CPU实现指令级并行的核心技术。现代高端CPU可以同时执行4-8条指令,这需要复杂的硬件支持:
超标量执行的性能指标:
- 发射宽度(Issue Width):每周期最多发射的指令数(通常4-6条)
- 执行宽度(Execute Width):同时执行的最大指令数(通常6-8条)
- 退休宽度(Retirement Width):每周期最多提交的指令数(通常4-6条)
2.2 缓存层次结构:速度与容量的精巧平衡
> 内存墙问题与缓存系统的诞生
内存墙(Memory Wall) 是现代计算机架构面临的根本挑战:处理器速度的提升远超内存访问速度的改善。过去30年中,CPU性能每年提升约50%,而内存延迟每年只改善约7%,这个巨大的性能差距催生了复杂的缓存层次结构。
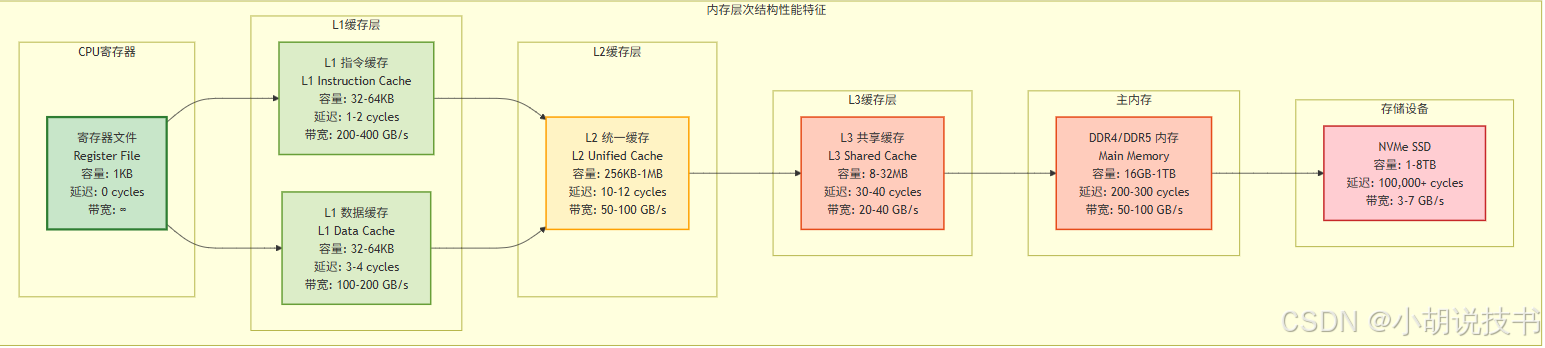
graph TBsubgraph "内存层次结构性能特征"subgraph "CPU寄存器"REG[寄存器文件<br/>Register File<br/>容量: 1KB<br/>延迟: 0 cycles<br/>带宽: ∞]endsubgraph "L1缓存层"L1I_DETAIL[L1 指令缓存<br/>L1 Instruction Cache<br/>容量: 32-64KB<br/>延迟: 1-2 cycles<br/>带宽: 200-400 GB/s]L1D_DETAIL[L1 数据缓存<br/>L1 Data Cache<br/>容量: 32-64KB<br/>延迟: 3-4 cycles<br/>带宽: 100-200 GB/s]endsubgraph "L2缓存层"L2_DETAIL[L2 统一缓存<br/>L2 Unified Cache<br/>容量: 256KB-1MB<br/>延迟: 10-12 cycles<br/>带宽: 50-100 GB/s]endsubgraph "L3缓存层"L3_DETAIL[L3 共享缓存<br/>L3 Shared Cache<br/>容量: 8-32MB<br/>延迟: 30-40 cycles<br/>带宽: 20-40 GB/s]endsubgraph "主内存"DRAM_DETAIL[DDR4/DDR5 内存<br/>Main Memory<br/>容量: 16GB-1TB<br/>延迟: 200-300 cycles<br/>带宽: 50-100 GB/s]endsubgraph "存储设备"SSD_DETAIL[NVMe SSD<br/>容量: 1-8TB<br/>延迟: 100,000+ cycles<br/>带宽: 3-7 GB/s]endendREG --> L1I_DETAILREG --> L1D_DETAILL1I_DETAIL --> L2_DETAILL1D_DETAIL --> L2_DETAILL2_DETAIL --> L3_DETAILL3_DETAIL --> DRAM_DETAILDRAM_DETAIL --> SSD_DETAILclassDef ultrafast fill:#c8e6c9,stroke:#2e7d32,stroke-width:3pxclassDef fast fill:#dcedc8,stroke:#689f38,stroke-width:2pxclassDef medium fill:#fff3c4,stroke:#ffa000,stroke-width:2pxclassDef slow fill:#ffccbc,stroke:#e64a19,stroke-width:2pxclassDef ultraslow fill:#ffcdd2,stroke:#c62828,stroke-width:2pxclass REG ultrafastclass L1I_DETAIL,L1D_DETAIL fastclass L2_DETAIL mediumclass L3_DETAIL,DRAM_DETAIL slowclass SSD_DETAIL ultraslow
> L1缓存:最接近核心的高速缓存
L1缓存(Level 1 Cache) 是CPU性能的第一道防线,其设计直接影响处理器的单周期执行能力:
L1缓存的关键特征:
- 容量限制:32-64KB(受物理距离和访问延迟约束)
- 访问速度:1-4个时钟周期(必须匹配CPU流水线)
- 分离设计:指令缓存(L1I)和数据缓存(L1D)分离
- 关联度:通常为8路组关联(8-way Set-Associative)
L1缓存访问的微观过程:
内存访问地址: 0x12345678 (32位地址)
缓存配置: 32KB, 8路组关联, 64字节缓存行地址分解:
- 标签位 (Tag): 0x12345 (高20位) - 用于匹配缓存行
- 索引位 (Index): 0x6 (中6位) - 选择缓存组 (64组)
- 偏移位 (Offset): 0x38 (低6位) - 缓存行内字节偏移缓存查找过程:
1. 用索引位选择第6组(Set 6)
2. 并行比较8路的标签位与0x12345
3. 如果命中,用偏移位从64字节中选择需要的数据
4. 如果未命中,从L2缓存加载整个64字节缓存行
5. 根据LRU算法选择要替换的路(Way)
> L2/L3缓存:容量与共享的权衡
L2缓存(Level 2 Cache) 作为L1和L3之间的缓冲层,在容量和速度之间寻找平衡:
| 缓存级别 | L1D | L2 | L3 |
|---|---|---|---|
| 容量 | 32-64KB | 256KB-1MB | 8-32MB |
| 访问延迟 | 3-4 cycles | 10-12 cycles | 30-40 cycles |
| 关联度 | 8-way | 8-16-way | 16-20-way |
| 缓存行大小 | 64 bytes | 64 bytes | 64 bytes |
| 共享范围 | 单核私有 | 单核私有 | 多核共享 |
| 主要用途 | 热点数据 | 工作集缓存 | 跨核数据共享 |
| 替换策略 | LRU/Random | LRU | 复杂的RRIP |
| 预取支持 | 步幅预取 | 多模式预取 | 区域预取 |
L3缓存的设计挑战:
L3缓存面临的核心挑战是如何在多个CPU核心之间高效共享数据,同时保持访问延迟的可预测性:
> 缓存一致性:多核心数据同步的挑战
在多核系统中,缓存一致性(Cache Coherence) 确保所有核心看到内存的一致视图。MESI协议(Modified, Exclusive, Shared, Invalid) 是最常用的解决方案:
缓存一致性的性能开销:
- 通信开销:核间一致性消息传递延迟(通常20-40个周期)
- 同步开销:写操作需要等待其他核心确认
- 带宽消耗:一致性协议消息占用互连带宽
- 错误共享:不同数据项位于同一缓存行导致的伪共享问题
2.3 指令集架构:从CISC到RISC的演进之路
> x86架构:复杂指令集的工程杰作
x86架构(x86 Architecture) 代表了复杂指令集计算机(Complex Instruction Set Computer, CISC) 的典型实现。其设计哲学是通过复杂的硬件实现来简化软件编程:

graph TBsubgraph "x86指令集特征分析"subgraph "指令复杂性"VAR_LENGTH[可变长度指令<br/>Variable Length<br/>1-15字节]COMPLEX_ADDR[复杂寻址模式<br/>Complex Addressing<br/>基址+索引+偏移]MICRO_CODED[微码实现<br/>Microcoded<br/>复杂指令→微操作]endsubgraph "寄存器架构"FEW_REGS[寄存器较少<br/>16个通用寄存器<br/>x64模式]SPECIAL_REGS[专用寄存器<br/>EAX, EBX, ECX...<br/>特殊用途]FLAGS_REG[标志寄存器<br/>EFLAGS<br/>条件码]endsubgraph "指令类型"ARITHMETIC[算术指令<br/>ADD, SUB, MUL...]LOGICAL[逻辑指令<br/>AND, OR, XOR...]MEMORY[内存操作<br/>MOV, LOAD, STORE]CONTROL[控制流指令<br/>JMP, CALL, RET]SIMD[向量指令<br/>SSE, AVX, AVX-512]SYSTEM[系统指令<br/>特权级操作]endsubgraph "编码特点"PREFIX[指令前缀<br/>操作数大小/段选择]OPCODE[操作码<br/>1-3字节]MODRM[ModR/M字节<br/>寻址模式]SIB[SIB字节<br/>比例索引基址]DISP[位移量<br/>0-4字节]IMM[立即数<br/>0-8字节]endendVAR_LENGTH --> PREFIXPREFIX --> OPCODEOPCODE --> MODRMMODRM --> SIBSIB --> DISPDISP --> IMM
x86指令编码示例分析:
指令:MOV EAX, [EBX + ECX*4 + 0x12345678]
含义:将内存地址(EBX + ECX*4 + 0x12345678)的值加载到EAX寄存器十六进制编码:8B 84 8B 78 56 34 12
解析过程:
- 8B:操作码 (MOV r32, r/m32)
- 84:ModR/M字节 = 10 000 100* Mod=10: 使用32位位移* Reg=000: 目标寄存器EAX* R/M=100: 使用SIB字节
- 8B:SIB字节 = 10 001 011 * Scale=10: 比例因子4 (2^2)* Index=001: 索引寄存器ECX* Base=011: 基址寄存器EBX
- 78 56 34 12:32位位移量0x12345678 (小端序)微架构执行过程:
1. 指令取指:从L1I读取7字节指令
2. 指令译码:译码器分析复杂编码格式
3. 地址计算:AGU计算有效地址
4. 内存访问:LSU执行内存读取操作
5. 写回结果:将数据写入EAX寄存器
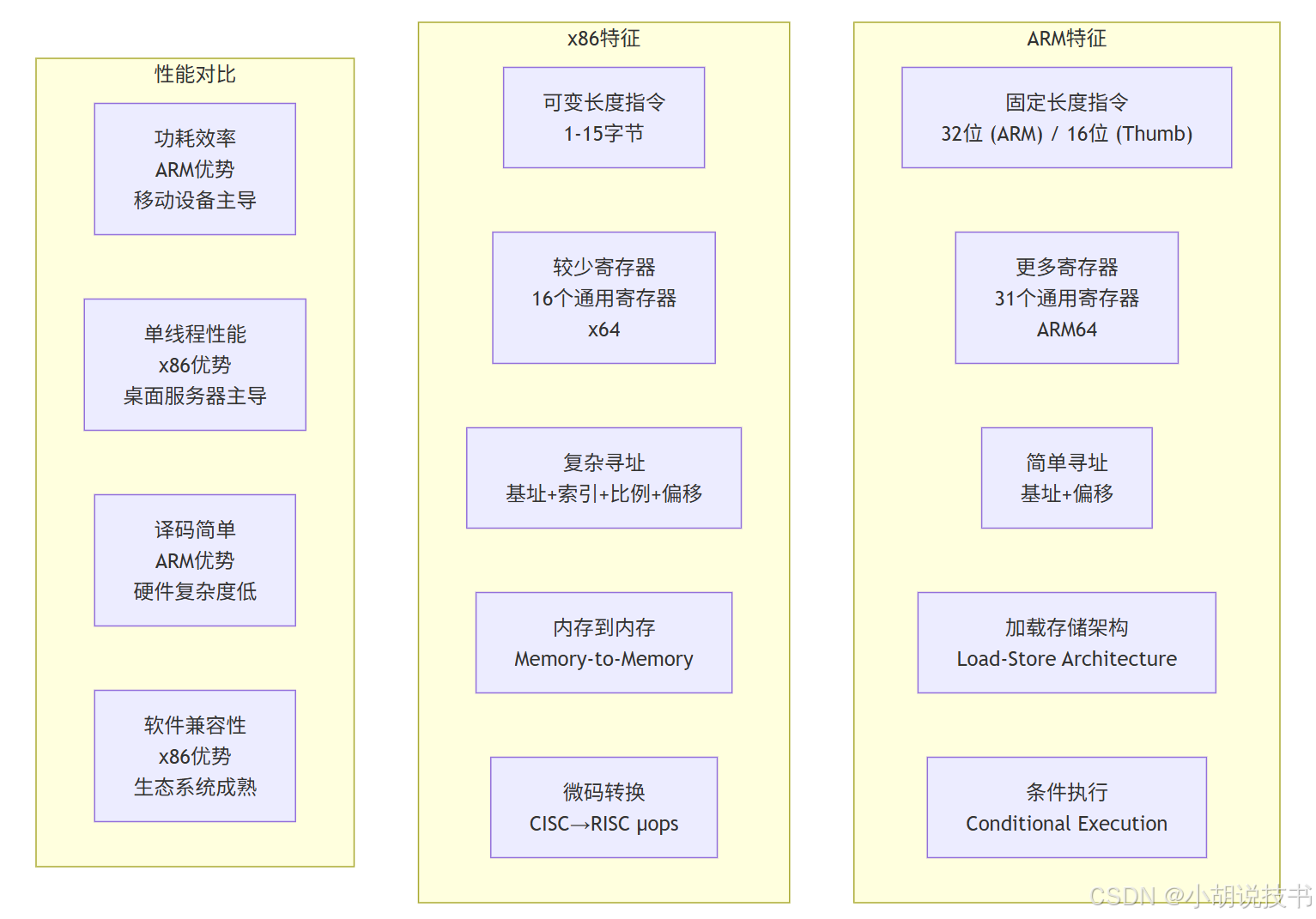
> ARM架构:精简指令集的现代实践
ARM架构(Advanced RISC Machine) 代表了精简指令集计算机(Reduced Instruction Set Computer, RISC) 的现代实现,强调简单性和能效:
下面是默认渲染的。
> 指令集架构选择的工程权衡
不同指令集架构的选择反映了不同的设计哲学和应用场景:
| 对比维度 | x86 (CISC) | ARM (RISC) | RISC-V |
|---|---|---|---|
| 设计哲学 | 硬件复杂,软件简单 | 软件复杂,硬件简单 | 开放标准,模块化 |
| 指令编码 | 可变长度(1-15字节) | 固定长度(32位) | 固定长度(32位) |
| 寄存器数量 | 16个(x64) | 31个(ARM64) | 32个 |
| 寻址模式 | 复杂(9种) | 简单(3种) | 简单(基址+偏移) |
| 译码复杂度 | 高(微码转换) | 低(直接执行) | 低(模块化译码) |
| 代码密度 | 高(复杂指令) | 中等(Thumb改善) | 中等(压缩扩展) |
| 功耗效率 | 中等 | 高 | 高 |
| 单线程性能 | 最高 | 中等 | 中等 |
| 生态系统 | 成熟(桌面/服务器) | 成熟(移动/嵌入式) | 新兴(开源硬件) |
| 主要应用 | 桌面、服务器、HPC | 移动、嵌入式、数据中心 | 研究、教育、新兴应用 |
2.4 分支预测:预见未来的艺术
> 分支预测的重要性
在现代CPU的流水线执行中,分支指令(Branch Instructions) 是性能的主要杀手。每当程序遇到条件跳转(如if语句、循环),CPU必须决定下一步执行哪条指令路径。错误的预测会导致整个流水线清空,损失10-20个时钟周期。
分支预测准确率的性能影响:
现代CPU流水线深度:12-20级
分支预测错误损失:10-20个周期
典型程序分支指令比例:15-25%性能影响计算:
- 预测准确率90%:错误率10% × 20周期损失 × 20%分支比例 = 0.4%性能损失
- 预测准确率95%:错误率5% × 20周期损失 × 20%分支比例 = 0.2%性能损失
- 预测准确率99%:错误率1% × 20周期损失 × 20%分支比例 = 0.04%性能损失结论:预测准确率从90%提升到99%,可以带来约0.36%的性能提升
> 现代分支预测器架构
现代CPU使用多级分支预测器来实现高达95-99%的预测准确率:
分支预测器的工作原理详解:
- 两位饱和计数器(Two-bit Saturating Counter):
状态转换:
强不跳转(00) → 弱不跳转(01) → 弱跳转(10) → 强跳转(11)工作机制:
- 预测:根据计数器高位决定(0=不跳转,1=跳转)
- 更新:分支结果为跳转时+1,不跳转时-1
- 饱和:计数器不会超出[00,11]范围优点:对噪声有一定容忍度,避免单次错误影响预测
缺点:需要2次错误预测才能改变方向,适应性较慢
- 全局历史预测器(Global History Predictor):
基本思想:使用最近N个分支的全局历史来预测当前分支实现方法:
- 全局历史寄存器(GHR):记录最近N个分支结果
- 模式历史表(PHT):2^N个2位计数器
- 预测:GHR作为索引,查找PHT中对应的计数器示例(N=4):
GHR = 1011 (最近4个分支:跳转-不跳转-跳转-跳转)
索引 = 1011₂ = 11₁₀
预测 = PHT[11] 的计数器值优势:能够识别复杂的分支模式
劣势:不同分支的历史可能相互干扰
> 分支预测的编程优化策略
了解分支预测的工作原理,可以指导我们编写更高效的代码:
优化原则1:减少不可预测的分支
// 不好的写法:不可预测的分支
int sum = 0;
for (int i = 0; i < n; i++) {if (array[i] > threshold) { // 随机分支,难以预测sum += array[i];}
}// 优化后:使用条件移动指令
int sum = 0;
for (int i = 0; i < n; i++) {int condition = array[i] > threshold;sum += array[i] * condition; // 避免分支,使用乘法
}
优化原则2:数据排序提升预测准确率
// 预处理:对数据进行排序
std::sort(array, array + n);// 排序后的分支更容易预测
int sum = 0;
for (int i = 0; i < n; i++) {if (array[i] > threshold) { // 排序后的数据有更强的空间局部性sum += array[i];}
}
2.5 多核心设计:并行计算的CPU实现
> 多核心架构的演进历程
多核心处理器(Multi-core Processor) 的发展是CPU性能提升的重要转折点。当单核心频率提升遇到物理极限(功耗墙、内存墙、指令级并行墙),CPU设计转向多核心并行:
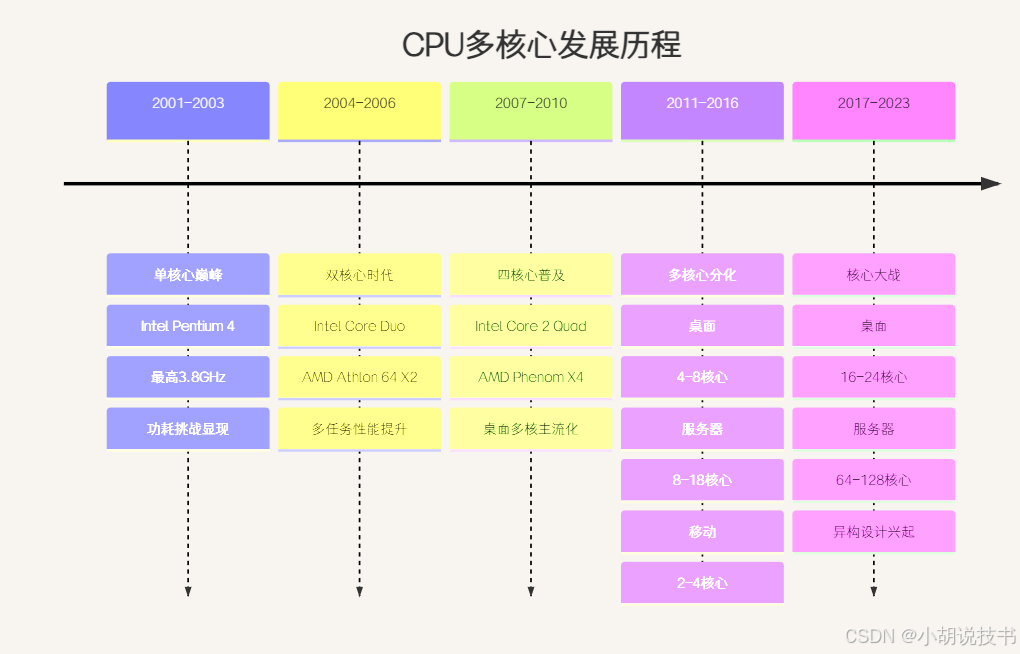
timelinetitle CPU多核心发展历程2001-2003 : 单核心巅峰: Intel Pentium 4: 最高3.8GHz: 功耗挑战显现2004-2006 : 双核心时代: Intel Core Duo: AMD Athlon 64 X2: 多任务性能提升2007-2010 : 四核心普及: Intel Core 2 Quad: AMD Phenom X4: 桌面多核主流化2011-2016 : 多核心分化: 桌面: 4-8核心: 服务器: 8-18核心: 移动: 2-4核心2017-2023 : 核心大战: 桌面: 16-24核心: 服务器: 64-128核心: 异构设计兴起
> 多核心系统的硬件架构
现代多核心CPU需要解决核间通信、缓存一致性、内存访问竞争等复杂问题:
> 多核心编程模型与挑战
多核心系统的性能发挥需要适当的软件支持,这带来了新的编程挑战:
并行编程的基本模型:
- 数据并行(Data Parallelism):
// OpenMP并行循环示例
#pragma omp parallel for
for (int i = 0; i < n; i++) {result[i] = expensive_function(input[i]); // 每个核心处理不同的数据
}// 理想情况:8核心系统可获得接近8倍加速
// 实际情况:受限于内存带宽、缓存冲突、负载不均衡
- 任务并行(Task Parallelism):
// 不同核心执行不同任务
std::thread t1([]{ compute_physics(); });
std::thread t2([]{ render_graphics(); });
std::thread t3([]{ process_audio(); });
std::thread t4([]{ handle_network(); });t1.join(); t2.join(); t3.join(); t4.join();
多核心性能的限制因素:
| 限制因素 | 问题描述 | 典型影响 | 缓解策略 |
|---|---|---|---|
| 阿姆达尔定律 | 串行部分限制并行加速比 | 20%串行→最大5倍加速 | 减少串行代码段 |
| 内存墙 | 多核心竞争内存带宽 | 8核心共享100GB/s带宽 | 增加缓存、优化访问模式 |
| 缓存一致性 | 核间数据同步开销 | 20-50周期同步延迟 | 减少共享数据写入 |
| NUMA效应 | 跨插槽内存访问延迟 | 2-3倍访问延迟差异 | CPU亲和性绑定 |
| 负载不均衡 | 不同核心工作量差异 | 等待最慢核心完成 | 动态负载均衡 |
| 同步开销 | 锁竞争和同步原语 | 锁争用导致串行化 | 无锁数据结构 |
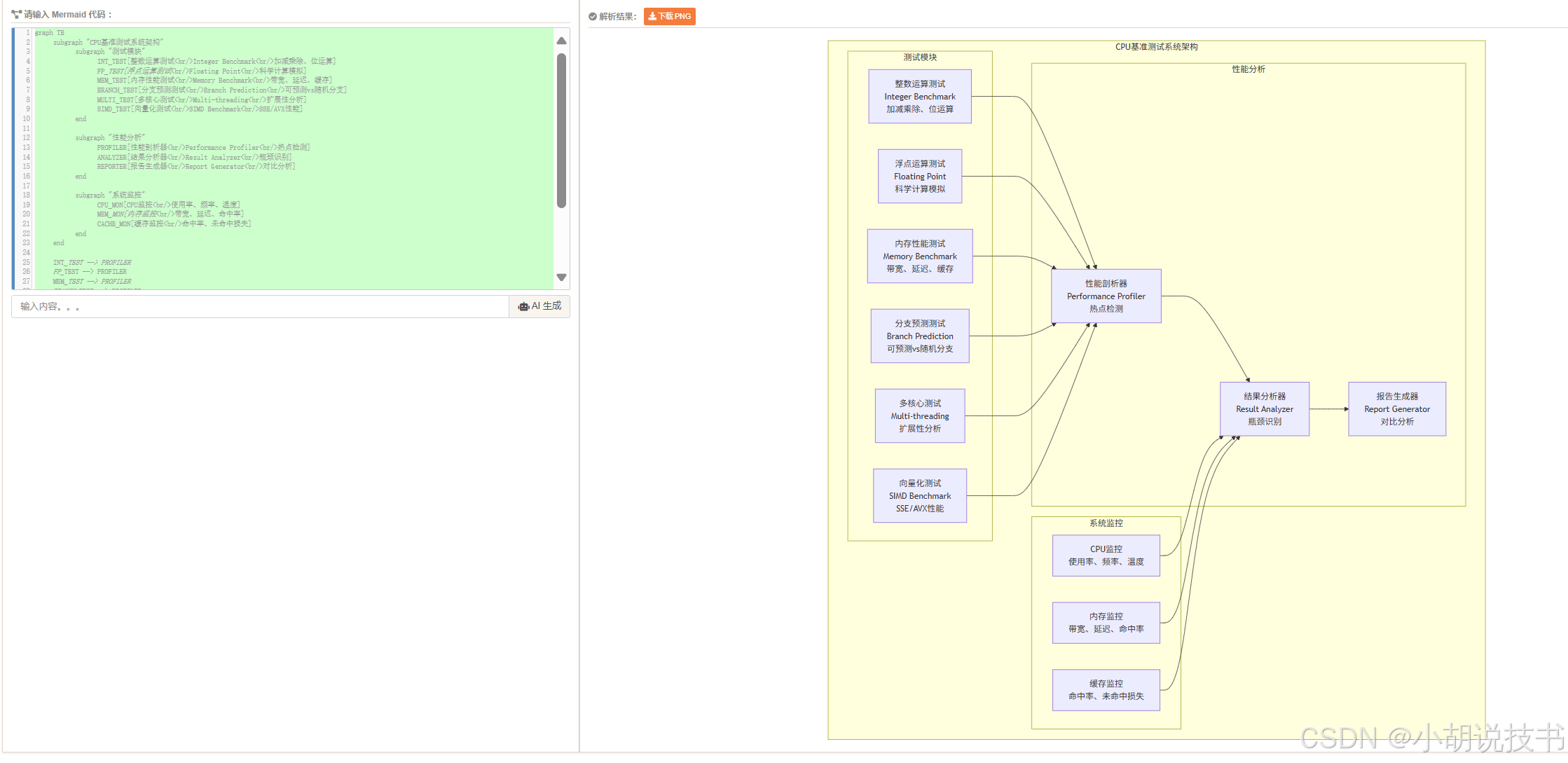
2.6 实战项目:CPU性能基准测试系统
> 项目架构设计
我们将构建一个综合性的CPU性能基准测试系统,全面评估CPU的各项性能指标,为后续GPU性能对比提供基准:
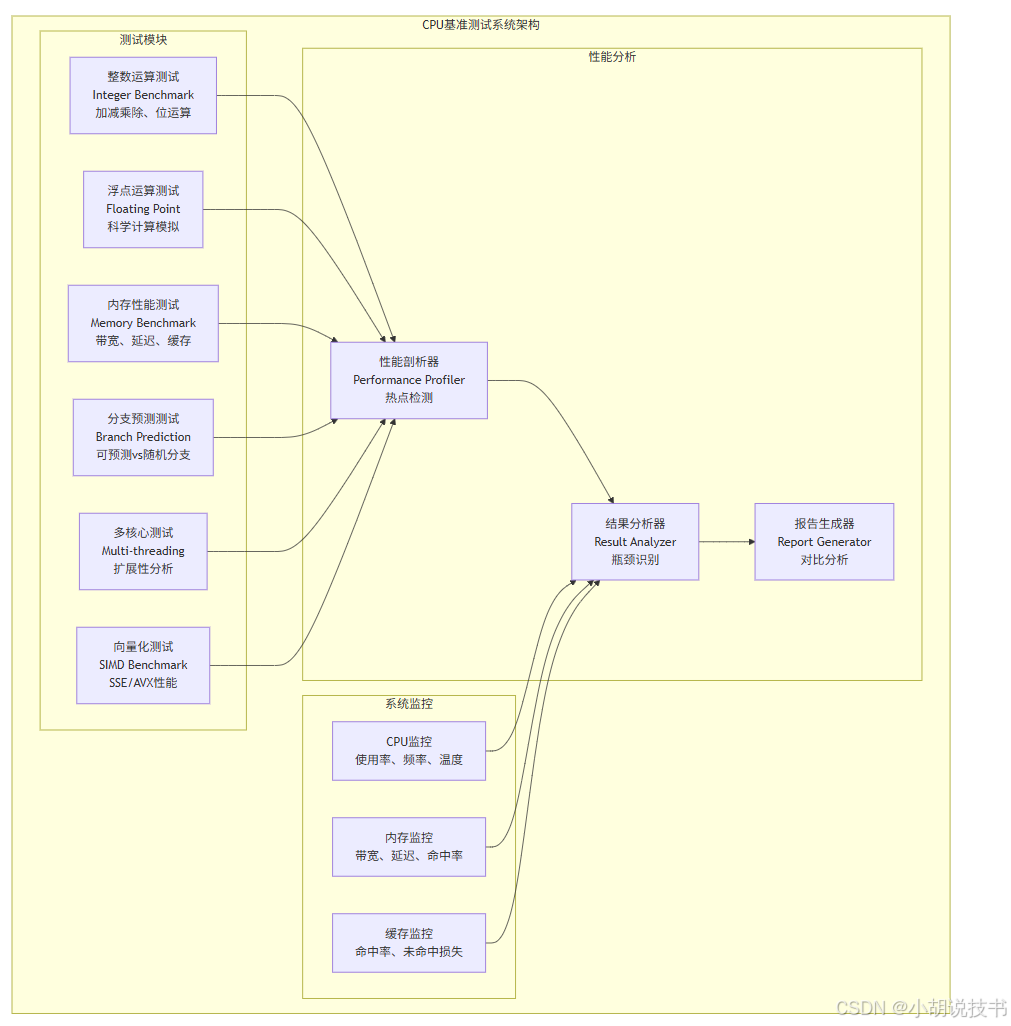
graph TBsubgraph "CPU基准测试系统架构"subgraph "测试模块"INT_TEST[整数运算测试<br/>Integer Benchmark<br/>加减乘除、位运算]FP_TEST[浮点运算测试<br/>Floating Point<br/>科学计算模拟]MEM_TEST[内存性能测试<br/>Memory Benchmark<br/>带宽、延迟、缓存]BRANCH_TEST[分支预测测试<br/>Branch Prediction<br/>可预测vs随机分支]MULTI_TEST[多核心测试<br/>Multi-threading<br/>扩展性分析]SIMD_TEST[向量化测试<br/>SIMD Benchmark<br/>SSE/AVX性能]endsubgraph "性能分析"PROFILER[性能剖析器<br/>Performance Profiler<br/>热点检测]ANALYZER[结果分析器<br/>Result Analyzer<br/>瓶颈识别]REPORTER[报告生成器<br/>Report Generator<br/>对比分析]endsubgraph "系统监控"CPU_MON[CPU监控<br/>使用率、频率、温度]MEM_MON[内存监控<br/>带宽、延迟、命中率]CACHE_MON[缓存监控<br/>命中率、未命中损失]endendINT_TEST --> PROFILERFP_TEST --> PROFILERMEM_TEST --> PROFILERBRANCH_TEST --> PROFILERMULTI_TEST --> PROFILERSIMD_TEST --> PROFILERPROFILER --> ANALYZERANALYZER --> REPORTERCPU_MON --> ANALYZERMEM_MON --> ANALYZERCACHE_MON --> ANALYZER
> 核心测试模块实现

import time
import threading
import multiprocessing
import numpy as np
import psutil
import platform
import math
import random
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from typing import Dict, List, Tuple, Any
import jsonclass CPUBenchmarkSuite:def __init__(self):self.results = {}self.system_info = self._get_system_info()def _get_system_info(self) -> Dict[str, Any]:"""获取系统信息"""return {'cpu_model': platform.processor(),'cpu_count_logical': psutil.cpu_count(logical=True),'cpu_count_physical': psutil.cpu_count(logical=False),'memory_total_gb': round(psutil.virtual_memory().total / (1024**3), 2),'platform': f"{platform.system()} {platform.release()}",'python_version': platform.python_version()}def integer_benchmark(self, iterations: int = 10_000_000) -> Dict[str, float]:"""整数运算性能测试"""print(f"执行整数运算测试 ({iterations:,} 次迭代)...")# 测试不同类型的整数运算tests = {'addition': lambda a, b: a + b,'multiplication': lambda a, b: a * b,'division': lambda a, b: a // max(b, 1), # 避免除零'modulo': lambda a, b: a % max(b, 1),'bitwise_and': lambda a, b: a & b,'bitwise_or': lambda a, b: a | b,'bitwise_xor': lambda a, b: a ^ b,'shift_left': lambda a, b: a << (b % 32),'shift_right': lambda a, b: a >> (b % 32),}results = {}for test_name, operation in tests.items():# 预生成测试数据data_a = [random.randint(1, 1000000) for _ in range(1000)]data_b = [random.randint(1, 1000000) for _ in range(1000)]start_time = time.time()for _ in range(iterations // 1000):for a, b in zip(data_a, data_b):result = operation(a, b)elapsed = time.time() - start_timeops_per_second = iterations / elapsedresults[test_name] = {'ops_per_second': round(ops_per_second, 2),'elapsed_time': round(elapsed, 4)}return resultsdef floating_point_benchmark(self, iterations: int = 5_000_000) -> Dict[str, float]:"""浮点运算性能测试"""print(f"执行浮点运算测试 ({iterations:,} 次迭代)...")tests = {'fp_addition': lambda a, b: a + b,'fp_multiplication': lambda a, b: a * b,'fp_division': lambda a, b: a / max(abs(b), 1e-10),'fp_sqrt': lambda a, b: math.sqrt(abs(a)),'fp_sin': lambda a, b: math.sin(a),'fp_cos': lambda a, b: math.cos(a),'fp_exp': lambda a, b: math.exp(min(a, 100)), # 限制指数避免溢出'fp_log': lambda a, b: math.log(max(abs(a), 1e-10)),}results = {}for test_name, operation in tests.items():# 预生成浮点测试数据data_a = [random.uniform(-100, 100) for _ in range(1000)]data_b = [random.uniform(-100, 100) for _ in range(1000)]start_time = time.time()for _ in range(iterations // 1000):for a, b in zip(data_a, data_b):try:result = operation(a, b)except:pass # 忽略数学错误elapsed = time.time() - start_timeops_per_second = iterations / elapsedresults[test_name] = {'ops_per_second': round(ops_per_second, 2),'elapsed_time': round(elapsed, 4)}return resultsdef memory_benchmark(self) -> Dict[str, Any]:"""内存性能测试"""print("执行内存性能测试...")results = {}# 测试不同大小的内存访问模式test_sizes = [(1024, "1KB - L1缓存"),(32 * 1024, "32KB - L1缓存边界"),(256 * 1024, "256KB - L2缓存"),(8 * 1024 * 1024, "8MB - L3缓存"),(64 * 1024 * 1024, "64MB - 主内存"),]for size_bytes, description in test_sizes:size_elements = size_bytes // 8 # 8字节双精度浮点数# 顺序访问测试data = list(range(size_elements))start_time = time.time()total = sum(data)sequential_time = time.time() - start_time# 随机访问测试random.shuffle(data)start_time = time.time()total = sum(data)random_time = time.time() - start_timebandwidth_sequential = (size_bytes * 2) / sequential_time / (1024**3) # GB/s (读+写)bandwidth_random = (size_bytes * 2) / random_time / (1024**3)results[f"size_{size_bytes}"] = {'description': description,'sequential_bandwidth_gbps': round(bandwidth_sequential, 2),'random_bandwidth_gbps': round(bandwidth_random, 2),'sequential_time': round(sequential_time, 4),'random_time': round(random_time, 4),'random_penalty_ratio': round(random_time / sequential_time, 2)}return resultsdef branch_prediction_benchmark(self, iterations: int = 10_000_000) -> Dict[str, Any]:"""分支预测性能测试"""print(f"执行分支预测测试 ({iterations:,} 次迭代)...")results = {}# 测试1:完全可预测的分支start_time = time.time()count = 0for i in range(iterations):if i % 2 == 0: # 完全可预测的模式count += 1predictable_time = time.time() - start_time# 测试2:完全随机的分支random_data = [random.choice([True, False]) for _ in range(iterations)]start_time = time.time()count = 0for condition in random_data:if condition: # 随机分支,难以预测count += 1random_time = time.time() - start_time# 测试3:部分可预测的分支(80%预测准确率)pattern_data = []for i in range(iterations):if i % 10 < 8: # 80%的情况为Truepattern_data.append(True)else:pattern_data.append(False)random.shuffle(pattern_data) # 打乱顺序但保持比例start_time = time.time()count = 0for condition in pattern_data:if condition:count += 1pattern_time = time.time() - start_timeresults = {'predictable_branch': {'time_seconds': round(predictable_time, 4),'branches_per_second': round(iterations / predictable_time, 2)},'random_branch': {'time_seconds': round(random_time, 4),'branches_per_second': round(iterations / random_time, 2)},'pattern_branch': {'time_seconds': round(pattern_time, 4),'branches_per_second': round(iterations / pattern_time, 2)},'prediction_penalty': {'random_vs_predictable': round(random_time / predictable_time, 2),'pattern_vs_predictable': round(pattern_time / predictable_time, 2)}}return resultsdef multithreading_benchmark(self) -> Dict[str, Any]:"""多线程性能测试"""print("执行多线程扩展性测试...")def cpu_intensive_task(iterations: int = 1_000_000) -> float:"""CPU密集型任务"""result = 0for i in range(iterations):result += math.sin(i) * math.cos(i)return result# 测试不同线程数的性能max_threads = self.system_info['cpu_count_logical']thread_counts = [1, 2, 4, max_threads] if max_threads >= 4 else [1, 2, max_threads]results = {}baseline_time = Nonefor thread_count in thread_counts:if thread_count > max_threads:continueprint(f" 测试 {thread_count} 个线程...")start_time = time.time()with ThreadPoolExecutor(max_workers=thread_count) as executor:futures = [executor.submit(cpu_intensive_task) for _ in range(thread_count)]for future in futures:future.result()elapsed = time.time() - start_timeif baseline_time is None:baseline_time = elapsedspeedup = baseline_time / elapsed if baseline_time else 1.0efficiency = speedup / thread_count * 100results[f"threads_{thread_count}"] = {'elapsed_time': round(elapsed, 4),'speedup': round(speedup, 2),'efficiency_percent': round(efficiency, 1)}return resultsdef simd_benchmark(self) -> Dict[str, Any]:"""SIMD向量化性能测试"""print("执行SIMD向量化测试...")# 使用numpy测试向量化性能size = 1_000_000a = np.random.rand(size).astype(np.float32)b = np.random.rand(size).astype(np.float32)results = {}# 标量运算(纯Python)start_time = time.time()c_scalar = []for i in range(len(a)):c_scalar.append(a[i] * b[i] + a[i])scalar_time = time.time() - start_time# 向量化运算(numpy,利用SIMD)start_time = time.time()c_vectorized = a * b + avectorized_time = time.time() - start_time# 数学函数向量化start_time = time.time()sin_scalar = [math.sin(x) for x in a[:10000]] # 只计算部分,避免太慢sin_scalar_time = time.time() - start_timestart_time = time.time()sin_vectorized = np.sin(a)sin_vectorized_time = time.time() - start_timeresults = {'arithmetic_operations': {'scalar_time': round(scalar_time, 4),'vectorized_time': round(vectorized_time, 4),'speedup': round(scalar_time / vectorized_time, 2)},'math_functions': {'scalar_time_10k': round(sin_scalar_time, 4),'vectorized_time_1m': round(sin_vectorized_time, 4),'estimated_speedup': round((sin_scalar_time * 100) / sin_vectorized_time, 2)}}return resultsdef run_all_benchmarks(self) -> Dict[str, Any]:"""运行所有基准测试"""print("="*60)print("CPU综合性能基准测试")print("="*60)print(f"系统: {self.system_info['platform']}")print(f"CPU: {self.system_info['cpu_model']}")print(f"核心: {self.system_info['cpu_count_physical']}物理 / {self.system_info['cpu_count_logical']}逻辑")print(f"内存: {self.system_info['memory_total_gb']} GB")print("="*60)all_results = {'system_info': self.system_info,'timestamp': time.strftime('%Y-%m-%d %H:%M:%S'),'benchmarks': {}}# 执行各项测试test_functions = [('integer_arithmetic', self.integer_benchmark),('floating_point', self.floating_point_benchmark),('memory_performance', self.memory_benchmark),('branch_prediction', self.branch_prediction_benchmark),('multithreading', self.multithreading_benchmark),('simd_vectorization', self.simd_benchmark),]for test_name, test_function in test_functions:try:print(f"\n[{test_name.upper()}]")result = test_function()all_results['benchmarks'][test_name] = resultprint(f"✓ {test_name} 测试完成")except Exception as e:print(f"✗ {test_name} 测试失败: {str(e)}")all_results['benchmarks'][test_name] = {'error': str(e)}return all_resultsdef generate_performance_analysis(self, results: Dict[str, Any]) -> str:"""生成性能分析报告"""analysis = []analysis.append("="*60)analysis.append("CPU性能分析报告")analysis.append("="*60)# 系统信息总结sys_info = results['system_info']analysis.append(f"测试系统: {sys_info['platform']}")analysis.append(f"处理器: {sys_info['cpu_model']}")analysis.append(f"核心配置: {sys_info['cpu_count_physical']}物理核心 / {sys_info['cpu_count_logical']}逻辑核心")analysis.append("")benchmarks = results['benchmarks']# 整数运算分析if 'integer_arithmetic' in benchmarks:int_data = benchmarks['integer_arithmetic']analysis.append("整数运算性能:")best_op = max(int_data.items(), key=lambda x: x[1]['ops_per_second'] if isinstance(x[1], dict) else 0)analysis.append(f" 最快运算: {best_op[0]} ({best_op[1]['ops_per_second']:,.0f} ops/sec)")analysis.append("")# 内存性能分析if 'memory_performance' in benchmarks:mem_data = benchmarks['memory_performance']analysis.append("内存层次结构性能:")for size, data in mem_data.items():if isinstance(data, dict) and 'description' in data:analysis.append(f" {data['description']}: 顺序{data['sequential_bandwidth_gbps']} GB/s, "f"随机{data['random_bandwidth_gbps']} GB/s "f"(惩罚倍数: {data['random_penalty_ratio']}x)")analysis.append("")# 多线程扩展性分析if 'multithreading' in benchmarks:mt_data = benchmarks['multithreading']analysis.append("多线程扩展性:")for thread_key, data in mt_data.items():if isinstance(data, dict):thread_num = thread_key.split('_')[1]analysis.append(f" {thread_num}线程: 加速比{data['speedup']}x, "f"效率{data['efficiency_percent']}%")analysis.append("")# 分支预测分析if 'branch_prediction' in benchmarks:bp_data = benchmarks['branch_prediction']if 'prediction_penalty' in bp_data:penalty = bp_data['prediction_penalty']analysis.append("分支预测影响:")analysis.append(f" 随机分支惩罚: {penalty['random_vs_predictable']}x")analysis.append(f" 模式分支惩罚: {penalty['pattern_vs_predictable']}x")analysis.append("")# SIMD向量化分析if 'simd_vectorization' in benchmarks:simd_data = benchmarks['simd_vectorization']if 'arithmetic_operations' in simd_data:arith = simd_data['arithmetic_operations']analysis.append("SIMD向量化效果:")analysis.append(f" 算术运算加速: {arith['speedup']}x")if 'math_functions' in simd_data:math_func = simd_data['math_functions']analysis.append(f" 数学函数加速: {math_func['estimated_speedup']}x")analysis.append("")# 性能建议analysis.append("性能优化建议:")# 基于多线程效率给出建议if 'multithreading' in benchmarks:mt_data = benchmarks['multithreading']max_threads = max([int(k.split('_')[1]) for k in mt_data.keys() if k.startswith('threads_')])max_thread_data = mt_data[f'threads_{max_threads}']if max_thread_data['efficiency_percent'] > 80:analysis.append(" ✓ 多核心扩展性良好,适合并行计算任务")elif max_thread_data['efficiency_percent'] > 50:analysis.append(" ⚠ 多核心扩展性一般,注意负载均衡和缓存局部性")else:analysis.append(" ✗ 多核心扩展性差,可能存在内存带宽瓶颈或频繁的同步操作")# 基于内存性能给出建议if 'memory_performance' in benchmarks:mem_data = benchmarks['memory_performance']# 检查最大的内存测试项largest_mem_key = max(mem_data.keys(), key=lambda x: int(x.split('_')[1]) if x.startswith('size_') else 0)largest_mem_data = mem_data[largest_mem_key]if largest_mem_data['random_penalty_ratio'] > 5:analysis.append(" ⚠ 随机内存访问惩罚较大,优化数据结构以提高缓存友好性")else:analysis.append(" ✓ 内存访问模式优化良好")analysis.append("="*60)return "\n".join(analysis)def run_cpu_benchmark():"""运行CPU基准测试"""benchmark = CPUBenchmarkSuite()results = benchmark.run_all_benchmarks()# 生成分析报告analysis = benchmark.generate_performance_analysis(results)print("\n" + analysis)# 保存结果到文件try:with open('cpu_benchmark_results.json', 'w', encoding='utf-8') as f:json.dump(results, f, ensure_ascii=False, indent=2)print(f"\n详细测试结果已保存到: cpu_benchmark_results.json")except Exception as e:print(f"保存结果文件失败: {e}")return resultsif __name__ == "__main__":run_cpu_benchmark()
> 性能分析与GPU对比预告
通过CPU基准测试,我们可以清楚地看到CPU设计的优势和局限性:
CPU的优势领域:
- 单线程性能:复杂的控制逻辑和缓存系统使CPU在串行任务上表现卓越
- 分支处理能力:先进的分支预测技术能够有效处理复杂的条件逻辑
- 内存层次优化:多级缓存系统大大降低了内存访问延迟
- 指令集丰富性:复杂指令集支持各种特殊操作和系统级功能
CPU的局限性:
- 并行度限制:即使是高端CPU也只有几十个核心
- 内存带宽限制:多核心共享有限的内存带宽
- 缓存一致性开销:核间数据同步带来性能损失
- 功耗与复杂性:复杂的控制逻辑消耗大量晶体管和功耗
为GPU计算铺垫:
理解了CPU的这些特点,我们就能更好地理解GPU的设计初衷:
- 大规模并行:成千上万个简单核心同时工作
- 高内存带宽:专门优化的内存系统支持大数据量处理
- 简化控制逻辑:牺牲单核复杂性换取整体并行性能
- 数据并行优化:专门针对SIMD类型的计算任务设计
2.7 学习总结与进阶路径
> 核心知识点回顾
通过本章深入学习,我们建立了对现代CPU工作原理的全面认知:
微架构设计理念:
- 理解了CPU如何通过复杂的硬件设计实现单线程性能的极致优化
- 掌握了指令执行周期的四个阶段及其硬件实现原理
- 学会了超标量执行如何在CPU内部实现指令级并行
缓存系统工程:
- 深入理解了内存层次结构的设计原理和性能特征
- 掌握了缓存一致性协议对多核心性能的影响
- 学会了编写缓存友好代码的基本原则
架构演进历程:
- 了解了CISC与RISC设计哲学的差异和适用场景
- 理解了不同指令集架构在不同应用领域的竞争格局
- 为理解专用处理器(如GPU)的设计动机做好了准备
性能优化技术:
- 掌握了分支预测的工作原理和编程优化策略
- 理解了多核心系统的挑战和解决方案
- 学会了使用基准测试评估CPU性能的方法
附录:专业术语表
ALU (Arithmetic Logic Unit, 算术逻辑单元): CPU内部执行算术和逻辑运算的硬件单元,是处理器进行数值计算的核心组件
Branch Predictor (分支预测器): 预测条件分支指令执行方向的硬件单元,通过预测减少流水线停顿,现代CPU预测准确率可达95-99%
Cache Coherence (缓存一致性): 多核系统中保证所有核心看到内存一致视图的协议,常用MESI协议实现
CISC (Complex Instruction Set Computer, 复杂指令集计算机): 指令集复杂、功能强大的处理器架构,如x86,强调硬件复杂性来简化软件编程
Core (处理器核心): 包含完整指令执行单元的独立处理单元,现代CPU可包含多个核心实现并行处理
ILP (Instruction Level Parallelism, 指令级并行): 在单个线程内并行执行多条指令的技术,通过超标量执行和乱序执行实现
L1/L2/L3 Cache (一/二/三级缓存): 处理器内部的高速存储器层次结构,L1最快但容量最小,L3最大但速度较慢
Memory Wall (内存墙): 处理器性能提升速度远超内存访问速度改善的现象,是现代计算机架构的主要挑战
MESI Protocol: Modified-Exclusive-Shared-Invalid缓存一致性协议,定义了多核系统中缓存行的四种状态
Microarchitecture (微架构): 处理器的具体硬件实现,包括流水线设计、执行单元配置、缓存层次结构等
Out-of-Order Execution (乱序执行): 处理器不按程序顺序执行指令,而是根据数据依赖关系和资源可用性动态调度指令执行
Pipeline (流水线): 将指令执行过程分解为多个阶段并行处理的技术,类似工厂流水线,可提高指令吞吐量
Prefetcher (预取器): 预测程序未来内存访问模式并提前加载数据到缓存的硬件单元,减少内存访问延迟
RISC (Reduced Instruction Set Computer, 精简指令集计算机): 指令集简单、规整的处理器架构,如ARM,强调软件复杂性来简化硬件设计
Superscalar (超标量): 在单个时钟周期内发射并执行多条指令的处理器设计技术,是提高单线程性能的重要手段
TLB (Translation Lookaside Buffer, 地址转换缓冲): 缓存虚拟地址到物理地址映射的硬件单元,加速内存地址转换
μop (Micro-operation, 微操作): CISC指令被分解后的简单操作,现代x86处理器内部将复杂指令转换为多个微操作执行