从MR迁移到Spark3:数据倾斜与膨胀问题的实战优化
背景介绍
最近在进行大规模数据任务从MapReduce向Spark3迁移的工作,遇到了一个典型的数据倾斜案例。本文将分享这个案例的具体情况、问题分析思路以及最终的解决方案,为类似场景的优化提供参考。
问题初现:迁移即遇阻
原始MR任务状态


在MapReduce环境下,该任务表现出明显的数据倾斜特征:
-
任务执行时间异常漫长
-
个别Reducer节点负载远高于其他节点
-
整体性能受到严重拖累
Spark3首次运行碰壁
这个任务的迁移,sql逻辑不用更改,直接替换到spark3上执行,第一个任务跑起来就碰壁,看下截图。

根据报错(java.lang.OutOfMemoryError: Java heap space),结合MR的任务状态,看来还是因为倾斜导致的内存问题的,
初步应对:将spark.executor.memory从24G调整到40G,任务得以继续执行,但倾斜问题并未真正解决。
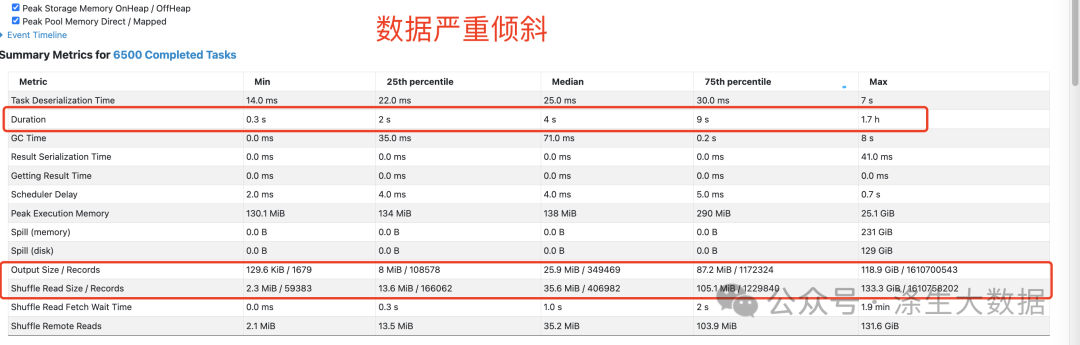
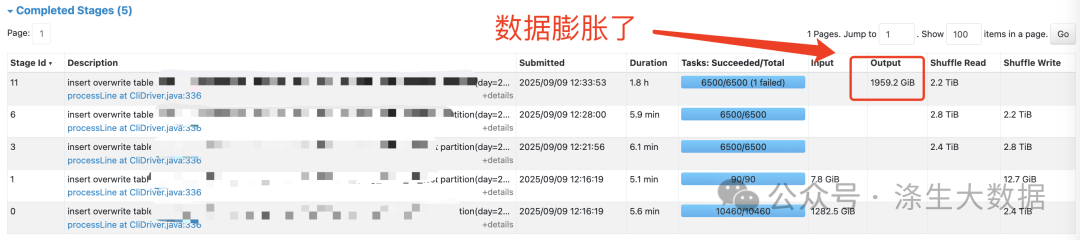
数据膨胀:新问题的出现
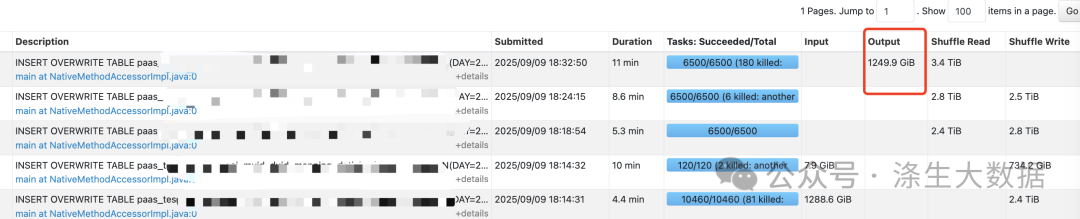
任务虽然能够运行完成,但产生了意外的数据膨胀:
-
MR输出结果:1249.9 GiB
-
Spark3输出结果:1959.2 GiB
-
膨胀量:700+ GiB
这种程度的数据膨胀在生产环境中是不可接受的,需要深入分析根本原因。
深入分析:定位问题根源
原始sql逻辑
INSERT OVERWRITE TABLE test.tableD PARTITION(DAY=20250906)
SELECT m.device, m.duid, m.systime, m.apppkg, n.app_name AS apppkg_name
FROM (-- 复杂的多层子查询,涉及数据去重和排序
) m
LEFT JOIN (SELECT * FROM test.tableC WHERE DAY=20250908
) n ON m.apppkg = n.apppkg
WHERE size(split(nvl(n.app_name,''),'\u0001')) = 1AND size(split(nvl(m.apppkg,''),'\u0001')) = 1
问题定位
通过分析执行计划,确定核心问题:
-
数据倾斜:大表m与维表n进行JOIN时,apppkg字段存在严重的数据倾斜
-
热点Key:少数热门应用包Key对应海量数据,导致单个计算节点成为性能瓶颈
首先考虑,如果tableC表不大,可以走广播join,直接将其广播到每个计算节点,彻底避免 Shuffle,但是tableC表10几个GB的大小,显然这个大小的表不能强制广播,否则会拖垮Driver节点。
解决方案:分层优化策略
第一层:解决数据倾斜问题
优化思路:加盐散列(Salting)技术
通过"打散大表,膨胀维表"的策略,将热点Key的计算压力分摊到多个节点。
下面是优化后的sql:
INSERT OVERWRITE TABLE test.tableD PARTITION(DAY=20250906)
SELECT m.device, m.duid, m.systime, m.apppkg, n.app_name AS apppkg_name
FROM (SELECT device, duid, systime, apppkg,cast(rand() * 50 as int) as salt -- 为左表添加随机盐值FROM (-- 原有复杂子查询逻辑保持不变) aWHERE a.rb < 6
) m
LEFT JOIN (SELECT apppkg, app_name,posexplode(split(space(49), ' ')) as (salt, _) -- 维表膨胀50倍FROM test.tableCWHERE DAY = 20250908AND size(split(nvl(app_name, ''), '\u0001')) = 1
) n ON m.apppkg = n.apppkg AND m.salt = n.salt -- 双向盐值JOIN
WHERE size(split(nvl(m.apppkg, ''), '\u0001')) = 1
优化原理
-
左表加盐:为每条数据添加0-49的随机盐值,分散热点Key
-
右表膨胀:将维表每条数据复制50份,每份对应特定盐值
-
盐值JOIN:修改关联条件,同时匹配业务Key和盐值
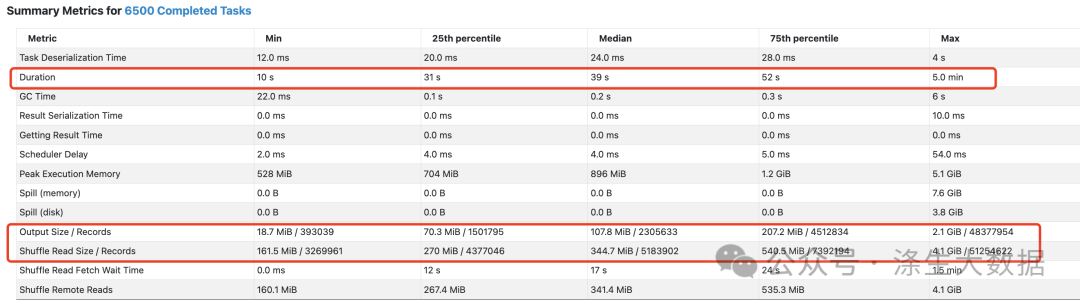
优化效果
-
倾斜的Stage执行时间:从1.8小时缩短到11分钟
-
资源利用率:计算压力均匀分布到多个节点
-
性能提升:彻底消除单点瓶颈
第二层:解决数据膨胀问题
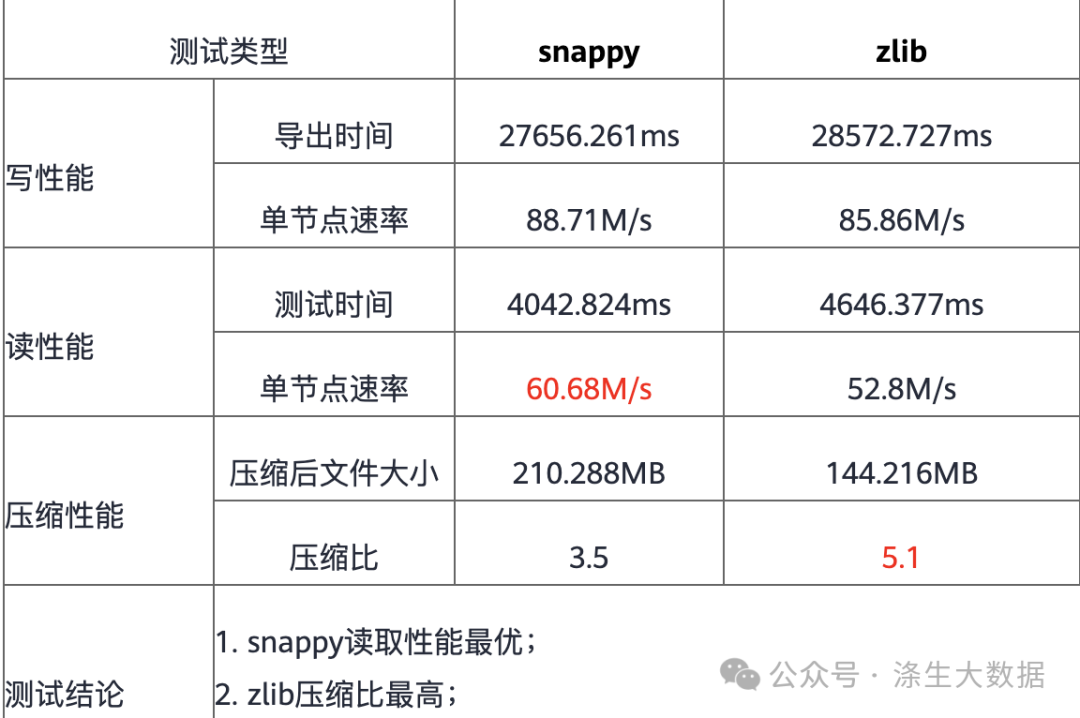
数据条数相同但体积差异巨大,表明问题出在压缩算法上:
-
Hive默认:ORC + ZLIB压缩
-
Spark3默认:ORC + SNAPPY压缩

“两种压缩算法的测试对比:参考https://bbs.huaweicloud.com/blogs/278702#H21
解决方案
修改spark的压缩算法和hive的一致:--conf spark.sql.orc.compression.codec=zlib
最后效果图:
最终效果:全面提升
经过双重优化后,任务表现出色:
-
性能表现:执行时间大幅缩短,整个任务的执行时间从MR的6.7小时缩短到35分钟。
-
稳定性:无内存溢出或长尾任务问题,任务可以稳定的运行。
--------
为什么选择涤生大数据?
-
1.跟随行业专家学习:我们的导师不是传统的讲师,而是实际的行业专家。他们都是来自国内一线大厂的资深开发,大数据技术专家等。
-
2.跟企业在职开发一起学习:涤生的社招学员目前60%+是企业在职进阶学员,基本各大厂的进阶学员都有,他们的薪资从10k,15k,20k,25k,30k,35k,40k。所以你会跟很多企业在职人员一起交流学习
-
3.定制化课程设计:结合每位学员的进行定制化教学,学习规划,让你的学习更有重点;结合每个学员的时间规划学习进度,督促考核,让学习变得更加灵活。
-
4.专业教学和平台:术业有专攻,企业怎么用,面试怎么面,我们就怎么学,涤生让大数据学习不迷惘。目前涤生采购10台服务器,自研提供一站式大数据平台供学习使用,拒绝虚拟机。
-
5.专业的简历面试辅导:涤生内部所有同学简历面试辅导都包含在内,从学习到入职试用期全流程提供保障服务。2024年截止当前涤生到简历面试7级群的学员就业率98%+,2024年上岸200+同学,60+入职一线中大厂。当然也有不少培训找不到工作的同学,以及裁员的同学,空窗期太久,最终跟着我们搞顺利上岸
-
6.不错的口碑:在涤生这,只要你不摆烂,我们不抛弃不放弃。目前涤生的学员大概有25%是老学员推荐和转化。
-
7.专门的校招大数据:校招跟社招不一样。全网独家的校招大数据课程,专门的校招团队辅导,今年是第五届校招大数据,内部校招面试资料覆盖一线中大厂90%的面试。从校招规划+系统的大数据课程+实习面试辅导+简历面试辅导+实习期辅导+试用期辅导,一次收费一条龙全流程贯穿。2024春招+2025年春招累计50+同学拿到一线中大厂offer