公司网站注册要多少钱唐山路南网站建设
【GPT入门】第50课 LlamaFacotory 客观评估模型效果
- 概要
- 1. 训练前准备
- 2.评估
- 2.1 主观评估
- 2.1.1 未收敛检查效果
- 2.1.2 训练到收敛
- 2.2 LLamaFacotory 客观评估
概要
使用LlamaFacotory训练千问,使用验证功能,实现客观评价指标,同时用主观评价检查训练效果。最终客观评价如下:
{
“predict_bleu-4”: 88.85199886363637,
“predict_model_preparation_time”: 0.0056,
“predict_rouge-1”: 92.91442994652407,
“predict_rouge-2”: 90.54005568181817,
“predict_rouge-l”: 92.0889979946524,
“predict_runtime”: 146.0479,
“predict_samples_per_second”: 10.243,
“predict_steps_per_second”: 0.205
}
指标分析,直接找AI分析
1. 训练前准备
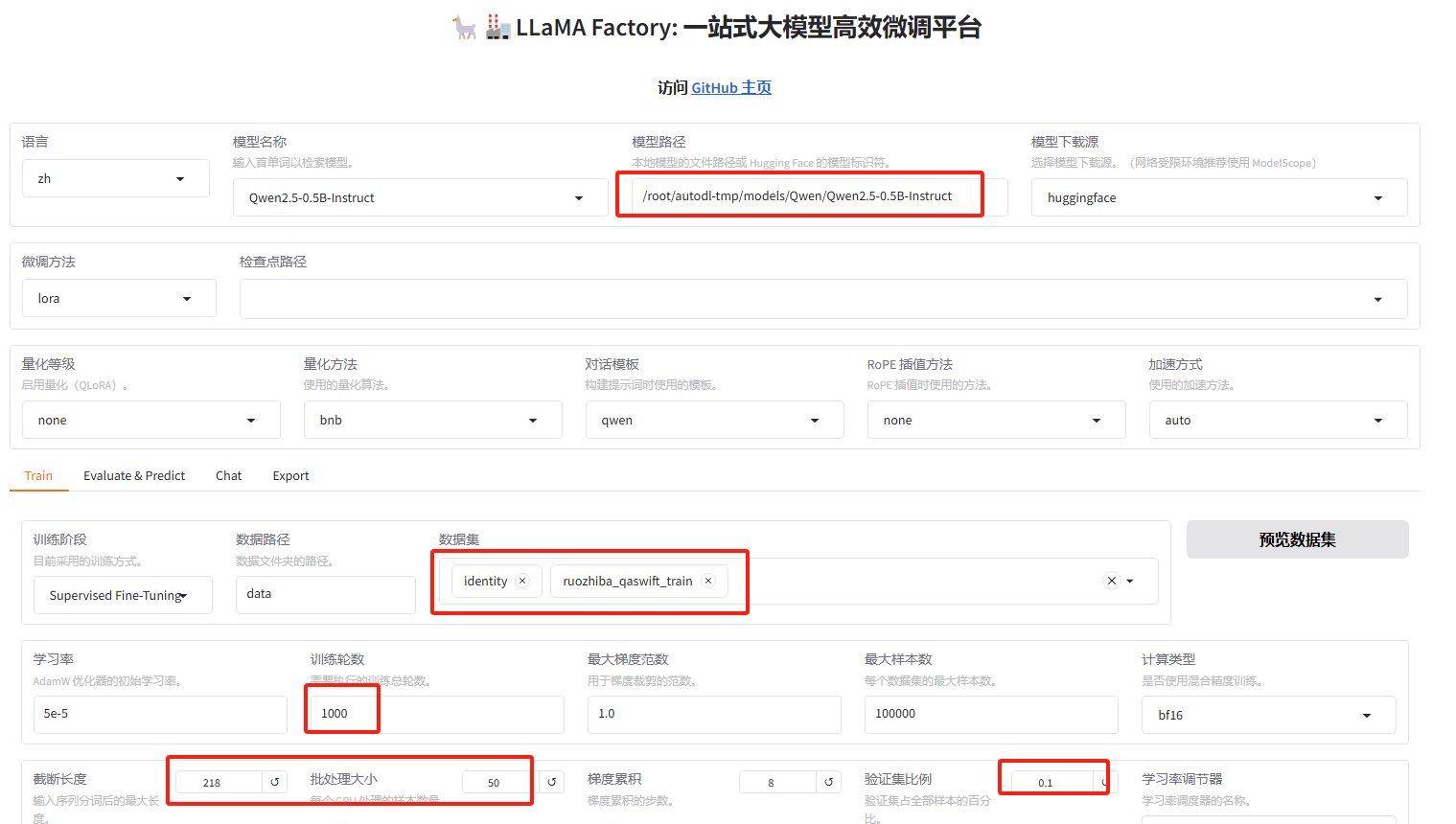
重新配环境,训练数据为indeitiy和ruozhiba_qaswift_train这两种
新数据,使用model_scope上的弱智吧数据,转为训练格式, 训练数据如下:
{"instruction": "只剩一个心脏了还能活吗?","input": "","output": "能,人本来就只有一个心脏。"},{"instruction": "爸爸再婚,我是不是就有了个新娘?","input": "","output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"},{"instruction": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买","input": "","output": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"}
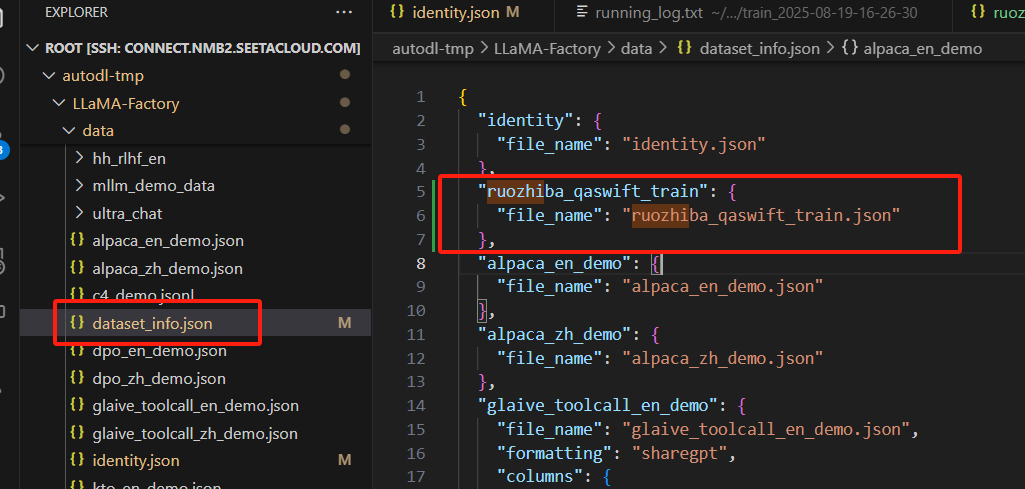
把该文件放到data目录,并配置到dataset_info.json文件,如下图
2.评估
2.1 主观评估
2.1.1 未收敛检查效果
一般用主观评估,
- 客观评估
- 主观评估
用弱者吧数据评估
{
“instruction”: “只剩一个心脏了还能活吗?”,
“input”: “”,
“output”: “能,人本来就只有一个心脏。”
}
3万分之1000,,
模型回答:

分析:明显,回答的不是训练的数据。需要继续训练
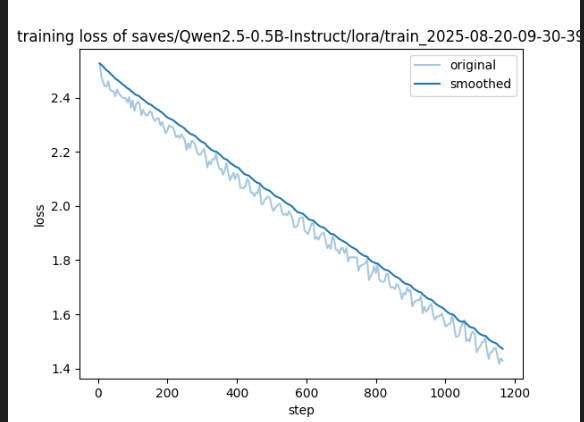
- 训练损失未收敛
2.1.2 训练到收敛
重新训练,重新调整批次大小,改为没批50条数据,加快训练速度。
检查对话效果:


训练语料:
{"instruction": "只剩一个心脏了还能活吗?","input": "","output": "能,人本来就只有一个心脏。"},{"instruction": "爸爸再婚,我是不是就有了个新娘?","input": "","output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"}
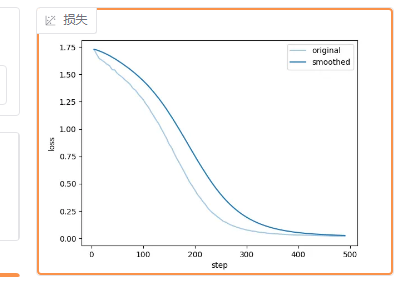
训练结国分析:loss收敛后,训练效果与预期一致
2.2 LLamaFacotory 客观评估
-
参数配置
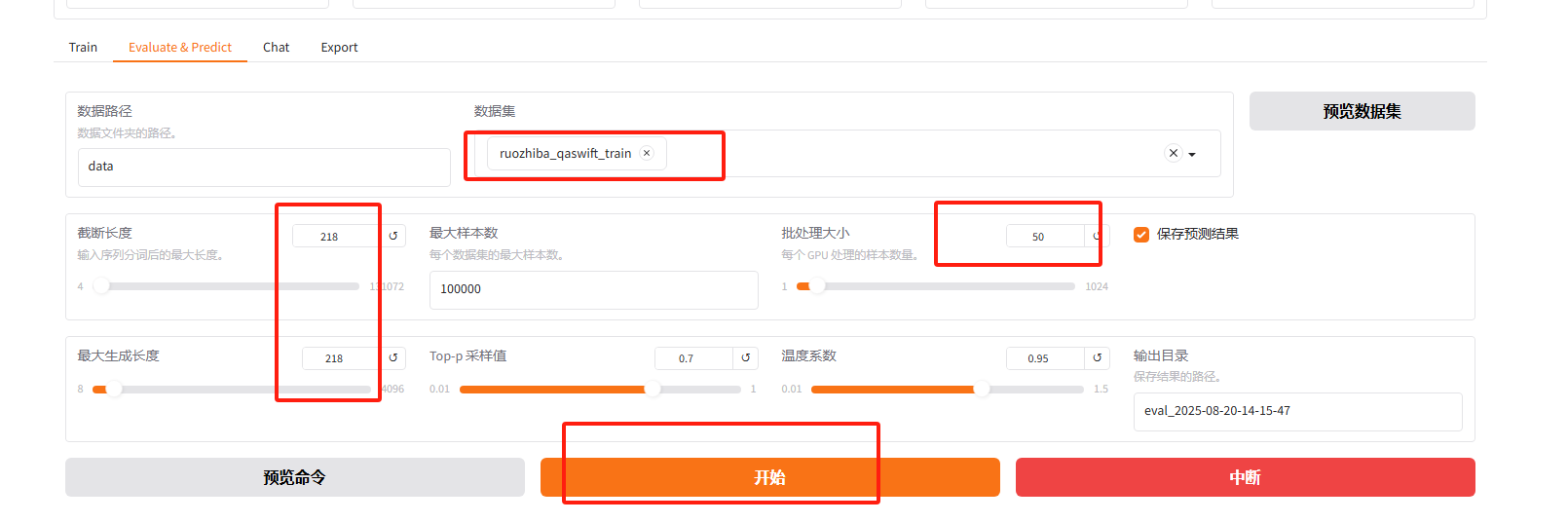
-
执行报错,安装依赖
pip install jieba
pip install nltk
pip install rouge_chinese -
训练结果
{"predict_bleu-4": 88.85199886363637,"predict_model_preparation_time": 0.0056,"predict_rouge-1": 92.91442994652407,"predict_rouge-2": 90.54005568181817,"predict_rouge-l": 92.0889979946524,"predict_runtime": 146.0479,"predict_samples_per_second": 10.243,"predict_steps_per_second": 0.205
}
评估分数分析:分数高的原因是,评估数据和训练数据是同一份。应该用非训练数据测试
- 训练日志
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file vocab.json
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file merges.txt
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file tokenizer.json
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file added_tokens.json
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file special_tokens_map.json
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file tokenizer_config.json
[INFO|2025-08-20 15:29:14] tokenization_utils_base.py:2065 >> loading file chat_template.jinja
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2336 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-08-20 15:29:15] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct/config.json
[INFO|2025-08-20 15:29:15] configuration_utils.py:817 >> Model config Qwen2Config {"architectures": ["Qwen2ForCausalLM"],"attention_dropout": 0.0,"bos_token_id": 151643,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 896,"initializer_range": 0.02,"intermediate_size": 4864,"layer_types": ["full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention"],"max_position_embeddings": 32768,"max_window_layers": 21,"model_type": "qwen2","num_attention_heads": 14,"num_hidden_layers": 24,"num_key_value_heads": 2,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 1000000.0,"sliding_window": null,"tie_word_embeddings": true,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"use_sliding_window": false,"vocab_size": 151936
}[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file vocab.json
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file merges.txt
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file tokenizer.json
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file added_tokens.json
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file special_tokens_map.json
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file tokenizer_config.json
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2065 >> loading file chat_template.jinja
[INFO|2025-08-20 15:29:15] tokenization_utils_base.py:2336 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-08-20 15:29:15] logging.py:143 >> Loading dataset ruozhiba_qaswift_train.json...
[INFO|2025-08-20 15:29:19] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct/config.json
[INFO|2025-08-20 15:29:19] configuration_utils.py:817 >> Model config Qwen2Config {"architectures": ["Qwen2ForCausalLM"],"attention_dropout": 0.0,"bos_token_id": 151643,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 896,"initializer_range": 0.02,"intermediate_size": 4864,"layer_types": ["full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention"],"max_position_embeddings": 32768,"max_window_layers": 21,"model_type": "qwen2","num_attention_heads": 14,"num_hidden_layers": 24,"num_key_value_heads": 2,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 1000000.0,"sliding_window": null,"tie_word_embeddings": true,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"use_sliding_window": false,"vocab_size": 151936
}[INFO|2025-08-20 15:29:19] logging.py:143 >> KV cache is enabled for faster generation.
[INFO|2025-08-20 15:29:20] modeling_utils.py:1305 >> loading weights file /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct/model.safetensors
[INFO|2025-08-20 15:29:20] modeling_utils.py:2411 >> Instantiating Qwen2ForCausalLM model under default dtype torch.bfloat16.
[INFO|2025-08-20 15:29:20] configuration_utils.py:1098 >> Generate config GenerationConfig {"bos_token_id": 151643,"eos_token_id": 151645
}[INFO|2025-08-20 15:29:20] modeling_utils.py:5606 >> All model checkpoint weights were used when initializing Qwen2ForCausalLM.[INFO|2025-08-20 15:29:20] modeling_utils.py:5614 >> All the weights of Qwen2ForCausalLM were initialized from the model checkpoint at /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct.
If your task is similar to the task the model of the checkpoint was trained on, you can already use Qwen2ForCausalLM for predictions without further training.
[INFO|2025-08-20 15:29:20] configuration_utils.py:1051 >> loading configuration file /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct/generation_config.json
[INFO|2025-08-20 15:29:20] configuration_utils.py:1098 >> Generate config GenerationConfig {"bos_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"pad_token_id": 151643,"repetition_penalty": 1.1,"temperature": 0.7,"top_k": 20,"top_p": 0.8
}[INFO|2025-08-20 15:29:20] logging.py:143 >> Using torch SDPA for faster training and inference.
[INFO|2025-08-20 15:29:22] logging.py:143 >> Merged 1 adapter(s).
[INFO|2025-08-20 15:29:22] logging.py:143 >> Loaded adapter(s): saves/Qwen2.5-0.5B-Instruct/lora/train_2025-08-20-14-15-47
[INFO|2025-08-20 15:29:22] logging.py:143 >> all params: 494,032,768
[WARNING|2025-08-20 15:29:22] logging.py:154 >> Batch generation can be very slow. Consider using `scripts/vllm_infer.py` instead.
[INFO|2025-08-20 15:29:22] trainer.py:4408 >>
***** Running Prediction *****
[INFO|2025-08-20 15:29:22] trainer.py:4410 >> Num examples = 1496
[INFO|2025-08-20 15:29:22] trainer.py:4413 >> Batch size = 50
[INFO|2025-08-20 15:31:48] logging.py:143 >> Saving prediction results to saves/Qwen2.5-0.5B-Instruct/lora/eval_2025-08-20-14-15-47/generated_predictions.jsonl