Video-XL-2论文阅读

1.摘要
background
现有的mllm理解视频的方法从根本上与计算FLOP相对于输入令牌总数的二次增长作斗争。因此,对于越来越长的视频输入,这些模型仍然面临巨大的资源负担,并且经常导致关键信息丢失。
innovation
1. 基于块的预填充:我们通过将其分成相等的长度块。然后,我们在每个块内计算全部注意力,同时在块之间应用稀疏注意力。这种方法大大减少了整体计算量,在预填充大量令牌序列期间的存储器开销。
2. 我们的双层KV解码策略继续以块的形式管理KV缓存。在预填充期间生成的原始KV被指定为密集KV。然后我们对每个块的密集KV应用下采样操作以获得稀疏KV。这个过程确保原始视频输入的每个块对应于一个双层KV。层次KV表示(密集和稀疏)。在解码过程中,我们根据每个视频块与特定文本查询的相关性,选择性地重新加载每个视频块的密集或稀疏KV。这种方法进一步优化了内存使用,并增强了细粒度信息的捕获。
2. 方法 Method

视觉输入处理:
最大帧数采样
预先添加了显式和隐式的时间戳标记
每个图像重复四次,以创建静态的类似视频的序列
训练策略:
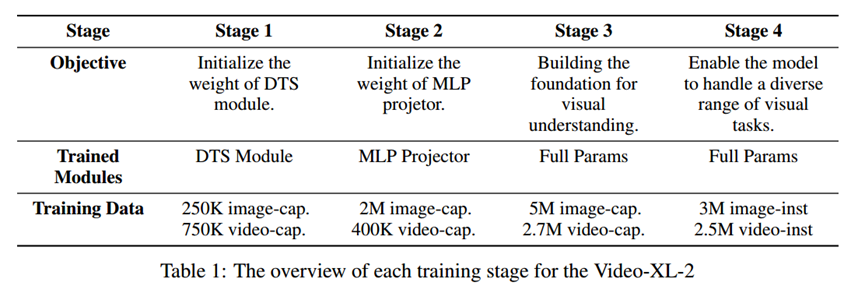
基于块的预填充:
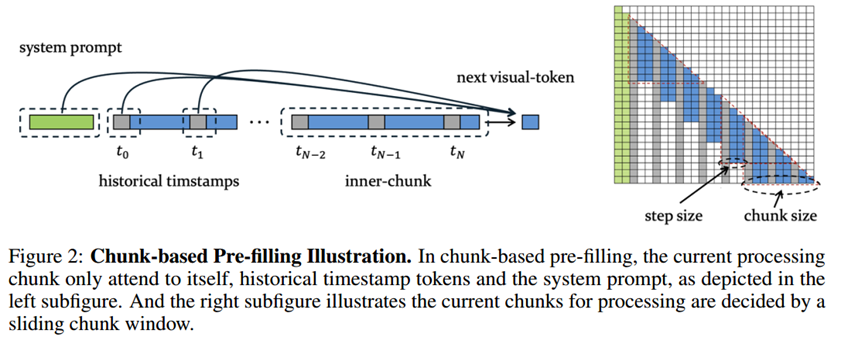
只关注当前块的内注意力和一个历史token。
双层KV解码:
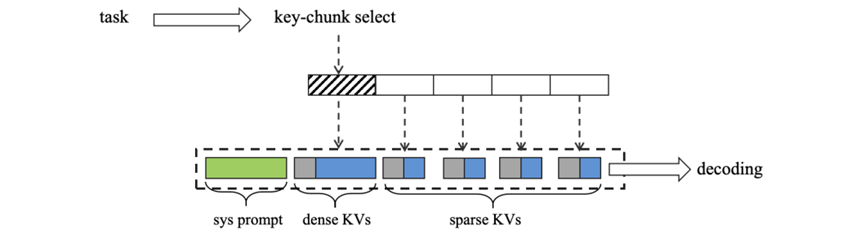
原本的dense KV被划分成块以及pooling过后得到稀疏KV,query进来相似度搞得用dense KV,相似度低的用sparse KV。
3. 实验 Experimental Results
实验数据集 (Experimental Datasets)模型在多个流行的长视频理解基准上进行评估,包括:
MLVU [49] (多选和生成任务)
Video-MME [50] (涵盖不同类型和长度的视频)
LongVideoBench [51] (需精确检索和推理的复杂多模态信息)
LVBench [52] (超长视频理解)
VideoEval-Pro [53] (逼真、开放式短答案问题)
Charades-STA [54] 和 V-STaR [55] (时序定位,评估时间感知能力)
主要结果 (Main Results):
Video-XL-2在MLVU开发集和测试集上表现优于主流开源方法,甚至超过了GPT-40等闭源模型。
在VideoMME、LongVideoBench和LVBench等长视频理解基准上达到SOTA性能。
在Charades-STA和V-STaR等时序定位基准上展现了强大的时序定位能力。
在所有评估模型中,Video-XL-2的FLOPs最低,实现了效率与性能的最佳平衡。
目的: 证明Video-XL-2在长视频理解和时序定位任务上的领先性能和综合能力。
效率分析 (Efficiency Analysis):
分块预填充: 将平均FLOPs降低到原始的48.8%,同时性能下降极小(<0.5%)。
双层KV解码: 将推理阶段的KV缓存使用率降低了38.8%,性能下降同样极小。
预填充时间: 随着输入帧数的增加几乎呈线性增长(图4a),表明了其在超长视频处理上的高度可扩展性。
内存使用: 在单张80G A100 GPU上可处理高达10,000帧,24GB GPU也可处理数千帧(图4b),展示了卓越的内存效率。
目的: 量化并直观展示分块预填充和双层KV解码策略带来的显著效率提升,证明Video-XL-2是长视频理解的实用解决方案。
超长视频场景 ("大海捞针"评估) (Extra-long Video Scenario & Needle in Haystack Evaluation):
Video-XL-2能够处理高达10,000帧的视频并保持强劲性能,而之前的Video-XL模型只能处理2048帧(图5)。
目的: 证明Video-XL-2在处理极其冗长的视频输入时,能同时保持内存效率和捕获关键细节的能力,有效解决了“大海捞针”这一严峻挑战。
4. 总结 Conclusion
Video-XL-2是一个轻量级的视觉语言模型,通过其创新的分块预填充和双层KV解码技术,在长视频理解和时序定位方面达到了SOTA性能,并展现了卓越的推理效率。它为解决长视频内容处理和理解的挑战提供了一个高度实用且强大的解决方案。