【分布式】分布式ID生成方案、接口幂等、一致性哈希
【分布式】分布式ID生成方案、接口幂等、一致性哈希
- 1、分布式ID生成方案都有哪些?
- 1.1 UUID
- 1.2 数据库自增
- 1.3 号段模式
- 1.4 Redis 实现
- 1.5 雪花算法
- 2、如何解决接口幂等的问题?
- 3、什么是一致性哈希?
1、分布式ID生成方案都有哪些?
在单体应用中,我们可以通过数据库的主键ID来生成唯一的ID,但是如果数据量变大,就需要进行分库分表,在分库分表之后,如何生成一个全局唯一的ID,就是一个关键的问题。
通常情况下,对于分布式ID来说,我们一般希望他具有以下几个特点:
● 全局唯一:必须保证全局唯一性,这个是最基本的要求。
● 高性能&高可用:需要保证ID的生成是稳定且高效的。
● 递增:根据不同的业务情况,有的会要求生成的ID呈递增趋势,也有的要求必须单调递增(后一个ID必须比前一个大),也有的没有严格要求。
1.1 UUID
UUID(Universally Unique Identifier)全局唯一标识符,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。
标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12),共32个字符,通常由以下几部分的组合而成:当前日期和时间,时钟序列,全局唯一的IEEE机器识别号
UUID的优点就是他的性能比较高,不依赖网络,本地就可以生成,使用起来也比较简单。但是他也有两个比较明显的缺点,那就是长度过长和没有任何含义。长度自然不必说,他有32位16进制数字。对于"550e8400-e29b-41d4-a716-446655440000"这个字符串来说,我想任何一个程序员都看不出其表达的含义。一旦使用它作为全局唯一标识,就意味着在日后的问题排查和开发调试过程中会遇到很大的困难。
用UUID当做分布式ID,存在着不适合范围查询、不方便展示以及查询效率低等问题。
1.2 数据库自增
分布式ID也可以使用数据库的自增ID,但是这种实现中就要求一定是一个单库单表才能保证ID自增且不重复,这就带来了一个单点故障的问题。
一旦这个数据库挂了,那整个分布式ID的生成服务就挂了。而且还存在一个性能问题,如果高并发访问数据库的话,就会带来阻塞问题。
1.3 号段模式
号段模式是在数据库的基础上,为了解决性能问题而产生的一种方案。他的意思就是每次去数据库中取ID的时候取出来一批,并放在缓存中,然后下一次生成新ID的时候就从缓存中取。这一批用完了再去数据库中拿新的。
而为了防止多个实例之间发生冲突,需要采用号段的方式,即给每个客户端发放的时候按号段分开,如客户端A取的号段是1-1000,客户端B取的是1001-2000,客户端C取的是2001-3000。当客户端A用完之后,再来取的时候取到的是3001-4000。
号段模式的好处是在同一个客户端中,生成的ID是顺序递增的。并且不需要频繁的访问数据库,也能提升获取ID的性能。缺点是没办法保证全局顺序递增,也存在数据库的单点故障问题。
其实很多分库分表的中间件的主键ID的生成,主要采用的也是号段模式,如TDDL Sequence。
1.4 Redis 实现
基于数据库可以实现,那么基于Redis也是可以的,我们可以依赖Redis的incr命令实现ID的原子性自增。
Redis的好处就是可以借助集群解决单点故障的问题,并且他基于内存性能也比较高。
但是Redis存在数据丢失的情况,无论是那种持久化机制,都无法完全避免。
1.5 雪花算法
雪花算法(Snowflake)是由Twitter研发的一种分布式ID生成算法,它可以生成全局唯一且递增的ID。它的核心思想是将一个64位的ID划分成多个部分,每个部分都有不同的含义,包括时间戳、数据中心标识、机器标识和序列号等。
具体来说,雪花算法生成的ID由以下几个部分组成:
- 符号位(1bit):预留的符号位,始终为0,占用1位。
- 时间戳(41bit):精确到毫秒级别,41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000,算下来可以使用69年。
- 数据中心标识(5bit):可以用来区分不同的数据中心。
- 机器标识(5bit):可以用来区分不同的机器。
- 序列号(12bit):可以生成4096个不同的序列号。

基于以上结构,雪花算法在唯一性保证方面就有很多优势:
首先,时间戳位于ID的最高位,保证新生成的ID比旧的ID大,在不同的毫秒内,时间戳肯定不一样。
其次,引入数据中心标识和机器标识,这两个标识位都是可以手动配置的,帮助业务来保证不同的数据中心和机器能生成不同的ID。
还有就是,引入序列号,用来解决同一毫秒内多次生成ID的问题,每次生成ID时序列号都会自增,因此不同的ID在序列号上有区别。
所以,基于时间戳+数据中心标识+机器标识+序列号,就保证了在不同进程中主键的不重复,在相同进程中主键的有序性。
雪花算法之所以被广泛使用,主要是因为他有以下优点:
- 高性能高可用:生成时不依赖于数据库,完全在内存中生成
- 高吞吐:每秒钟能生成数百万的自增 ID
- ID 自增:在单个进程中,生成的ID是自增的,可以用作数据库主键做范围查询。但是需要注意的是,在集群中是没办法保证一定顺序递增的。
SnowFlake 算法的缺点或者限制:
1、在Snowflake算法中,每个节点的机器ID和数据中心ID都是硬编码在代码中的,而且这些ID是全局唯一的。当某个节点出现故障或者需要扩容时,就需要更改其对应的机器ID或数据中心ID,但是这个过程比较麻烦,需要重新编译代码,重新部署系统。还有就是,如果某个节点的机器ID或数据中心ID被设置成了已经被分配的ID,那么就会出现重复的ID,这样会导致系统的错误和异常。
2、Snowflake算法中,需要使用zookeeper来协调各个节点的ID生成,但是ZK的部署其实是有挺大的成本的,并且zookeeper本身也可能成为系统的瓶颈。
3、依赖于系统时间的一致性,如果系统时间被回拨,或者不一致,可能会造成 ID 重复。但是时钟回拨并不常见,而且就算发生了,也不代表着生成的ID一定就会重复。所以重复其实是个低概率事件,所以遇到ID重复可以直接抛异常重试。
2、如何解决接口幂等的问题?
高并发场景下,想要解决这个问题,只需要记住一句口令"一锁、二判、三更新",只要严格遵守这个过程,那么就可以解决高并发问题。
一锁:第一步,先加锁。可以加分布式锁、或者悲观锁都可以。但是一定要是一个互斥锁!
二判:第二步,进行幂等性判断。可以基于状态机、流水表、唯一性索引等等进行重复操作的判断。
三更新:第三步,进行数据的更新,将数据进行持久化。
三步需要严格控制顺序,确保加锁成功后进行数据查询和判断,幂等性判断通过后再更新,更新结束后释放锁。
以上操作需要有一个前提,那就是第一步加锁、和第二步判断的时候,需要有一个依据,这个就是幂等号了,通常需要和上游约定一个唯一ID作为幂等号。然后通过对幂等号加锁,再通过幂等号进行幂等判断即可。
一锁这个过程,建议使用Redis实现分布式锁,因为他是非阻塞(tryLock)的高效率的互斥锁。非常适合在幂等控制场景中。
二判这个过程,如果有操作流水,建议基于操作流水做幂等,并将幂等号作为唯一性约束,确保唯一性。如果没有流水,那么基于状态机也是可以的。
但是不管怎么样,数据库的唯一性约束都要加好,这是系统的最后一道防线。万一前面的锁失效了,这里也能控制得住不会产生脏数据。
3、什么是一致性哈希?
哈希算法大家都不陌生,经常被用在负载均衡、分库分表等场景中,比如说我们在做分库分表的时候,最开始我们根据业务预估,把数据库分成了128张表,这时候要插入或者查询一条记录的时候,我们就会先把分表键,如buyer_id进行hash运算,然后再对128取模,得到0-127之间的数字,这样就可以唯一定位到一个分表。
但是随着业务得突飞猛进,128张表,已经不够用了,这时候就需要重新分表,比如增加一张新的表。这时候如果采用hash或者取模的方式,就会导致128+1张表的数据都需要重新分配,成本巨高。
而一致性hash算法, 就能有效的解决这种分布式系统中增加或者删除节点时的失效问题。
一致性哈希(Consistent Hashing)是一种用于分布式系统中数据分片和负载均衡的算法。它的目标是在节点的动态增加或删除时,尽可能地减少数据迁移和重新分布的成本。
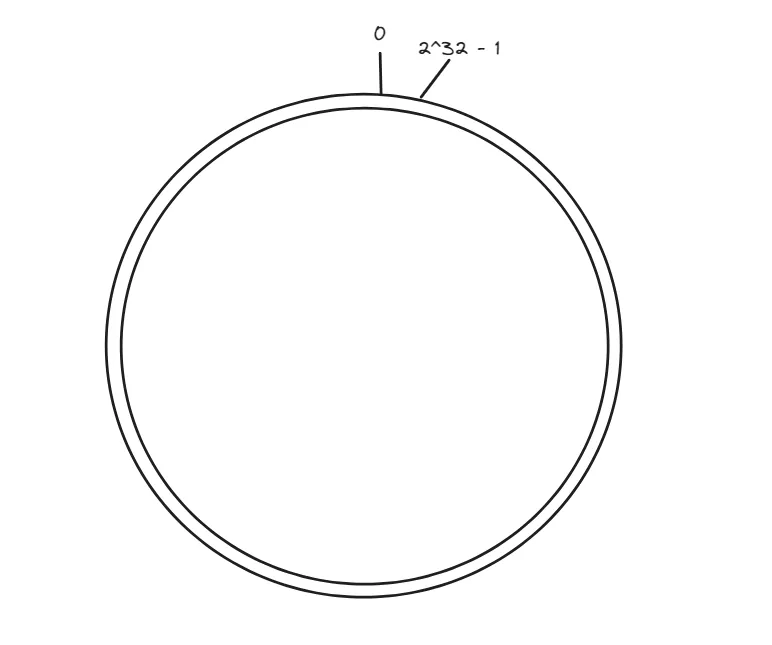
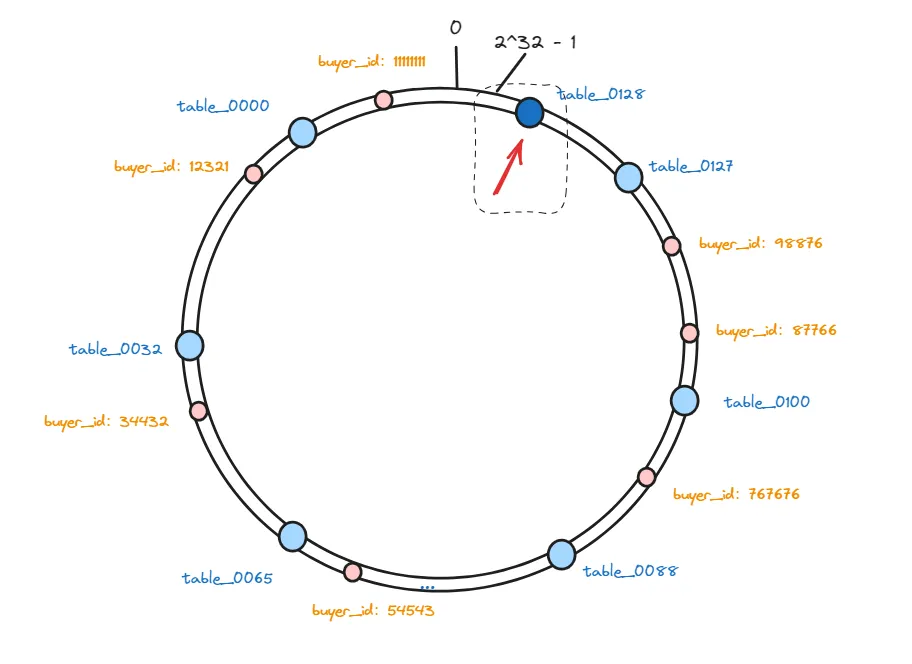
实现一致性哈希算法首先需要构造一个哈希环,然后把他划分为固定数量的虚拟节点,如2^32。那么他的节点编号就是 0-2^32-1:
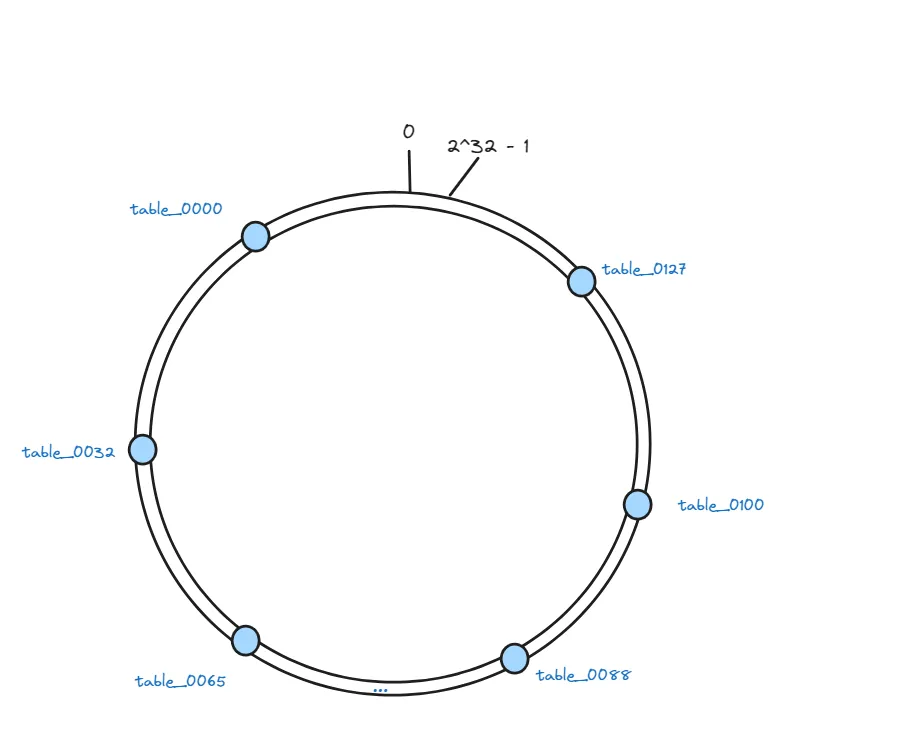
接下来, 我们把128张表作为节点映射到这些虚拟节点上,每个节点在哈希空间上都有一个对应的虚拟节点:
hash(table_0000)%232、hash(table_0001)%232、hash(table_0002)%2^32 … hash(table_0127)%2^32
在把这些表做好hash映射之后,我们就需要存储数据了,现在我们要把一些需要分表的数据也根据同样的算法进行hash,并且也将其映射哈希环上。
hash(buyer_id)%2^32:
hash(12321)%232、hash(34432)%232、hash(54543)%2^32 … hash(767676)%2^32
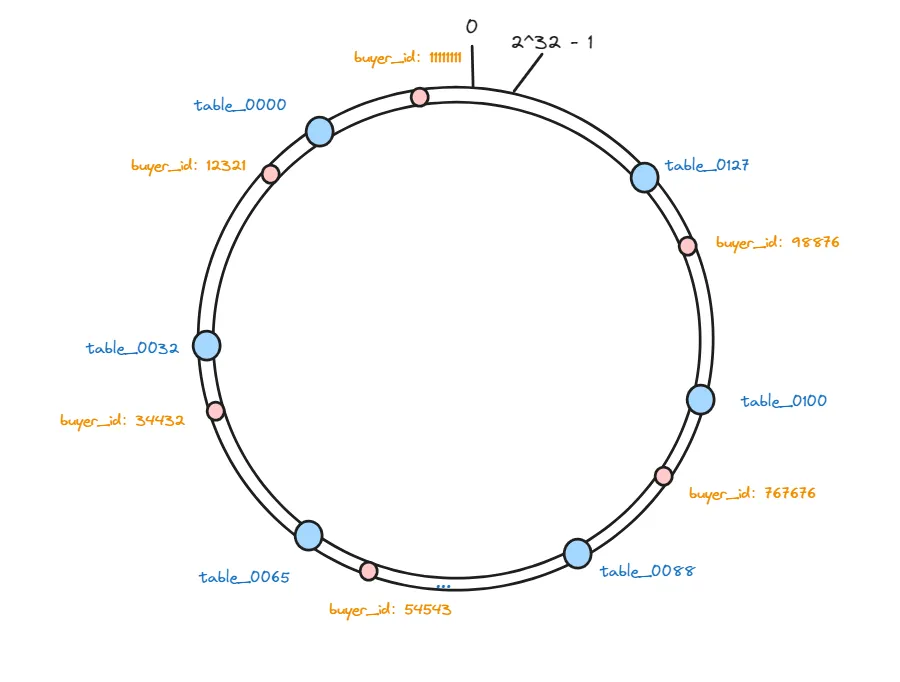
这样,这个hash环上的虚拟节点就包含两部分数据的映射了,一部分是存储数据的分表的映射,一部分是真实要存储的数据的映射。
那么, 我们最终还是要把这些数据存储到数据库分表中,那么做好哈希之后,这些数据又要保存在哪个数据库表节点中呢?
其实很简单,只需要按照数据的位置,沿着顺时针方向查找,找到的第一个分表节点就是数据应该存放的节点:
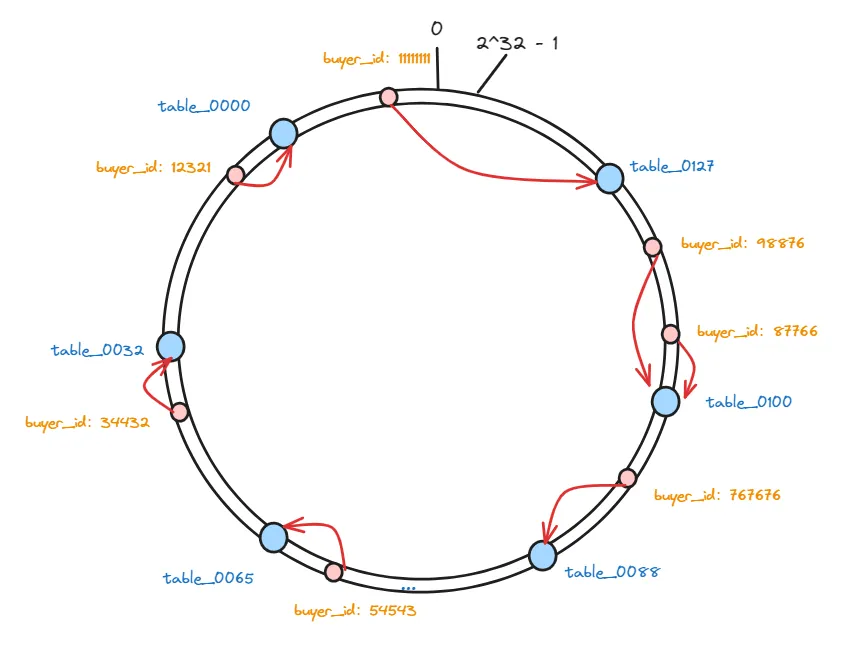
因为要存储的数据,以及存储这些数据的数据库分表,hash后的值都是固定的,所以在数据库数量不变的情况下,下次想要查询数据的时候,只需要按照同样的算法计算一次就能找到对应的分表了。
以上,就是一致性hash算法的原理,那么,再回到我们开头的问题,如果我要增加一个分表怎么办呢?
我们首先要将新增加的表通过一致性hash算法映射到哈希环的虚拟节点中:
这样,会有一部分数据,因为节点数量发生变化,那么他顺时针遇到的第一个分表可能就变了。
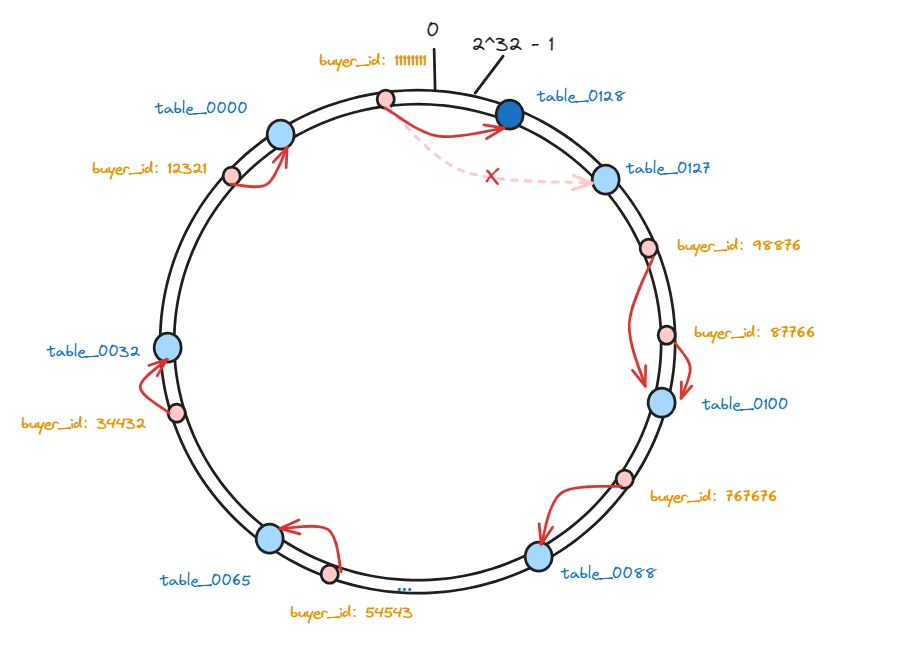
相比于普通hash算法,在增加服务器之后,影响的范围非常小,只影响到一部分数据,其他的数据是不需要调整的。
所以,一致性哈希算法将整个哈希空间视为一个环状结构,将节点和数据都映射到这个环上。每个节点通过计算一个哈希值,将节点映射到环上的一个位置。而数据也通过计算一个哈希值,将数据映射到环上的一个位置。
当有新的数据需要存储时,首先计算数据的哈希值,然后顺时针或逆时针在环上找到最近的节点,将数据存储在这个节点上。当需要查找数据时,同样计算数据的哈希值,然后顺时针或逆时针在环上找到最近的节点,从该节点获取数据。
优点:
- 数据均衡:在增加或删除节点时,一致性哈希算法只会影响到少量的数据迁移,保持了数据的均衡性。
- 高扩展性:当节点数发生变化时,对于已经存在的数据,只有部分数据需要重新分布,不会影响到整体的数据结构。
缺点:
- hash倾斜:在节点数较少的情况下,由于哈希空间是有限的,节点的分布可能不够均匀,导致数据倾斜。
- 节点的频繁变更:如果频繁添加或删除节点,可能导致大量的数据迁移,造成系统压力。
参考链接:
1、https://www.yuque.com/hollis666/wk6won/hgx0twgg4t7nqg6v