ICCV-2025 | 对话协作驱动具身导航!DialNav:远程向导指导下的多轮对话导航
- 作者:Leekyeung Han1^{1}1, Hyunji Min1^{1}1, Gyeom Hwangbo2^{2}2, Jonghyun Choi3^{3}3, Paul Hongsuck Seo1^{1}1
- 单位:1^{1}1韩国大学,2^{2}2首尔大学,3^{3}3首尔国立大学
- 论文标题:DialNav: Multi-turn Dialog Navigation with a Remote Guide
- 论文链接:https://arxiv.org/pdf/2509.12894
- 项目主页:https://happilee12.github.io/DialNav/
主要贡献
- 提出协作式具身对话导航任务 DialNav,该任务涉及导航智能体(Navigator)和远程向导(Guide)之间的多轮对话,以到达目标位置,强调了对话对于任务成功的重要性。
- 收集并发布了 Remote Assistance in Navigation(RAIN)数据集,包含在逼真环境中的人类人类对话与导航轨迹,为训练和评估 Navigator 和 Guide 提供了标准化条件。
- 设计了综合的基准来评估导航和对话能力,并在各种设置和模块配置下对 Navigator 和 Guide 模型进行了广泛的实验,提供了关于这一新任务的宝贵见解。
- 公开发布数据集、代码、数据收集工具以及训练和评估框架,确保研究的可重复性,并为未来在具身对话领域的研究提供基础资源。
研究背景

- 具身 AI 智能体的挑战:具身 AI 智能体能够感知并与环境互动,但错误理解人类指令或执行未预期的动作可能会带来不便甚至造成物理伤害。因此,智能体在面对模糊任务时需要通过对话澄清,以提高任务的安全性和有效性。
- 现有研究的局限性:尽管对话在具身 AI 中至关重要,但其发展面临诸多挑战,如数据收集成本高、需要构建能够对话的智能体和提供响应的对应模型、缺乏支持问答交互的框架以及任务的动态性和相互依赖性使得性能评估困难。以往的研究大多关注任务执行,而非利用对话完成任务。
- 非全知向导的必要性:一些研究已经认识到对话的重要性,但往往假设向导对当前情况有全面了解,这在实际场景中并不现实。这种全知向导模型降低了向导仔细考虑问题的动机,也不利于智能体提出高质量的问题。而 DialNav 任务通过设置向导对智能体位置不知情,仅熟悉环境,更贴近现实场景,促使双方进行更有效的沟通。
任务与数据集
DialNav任务
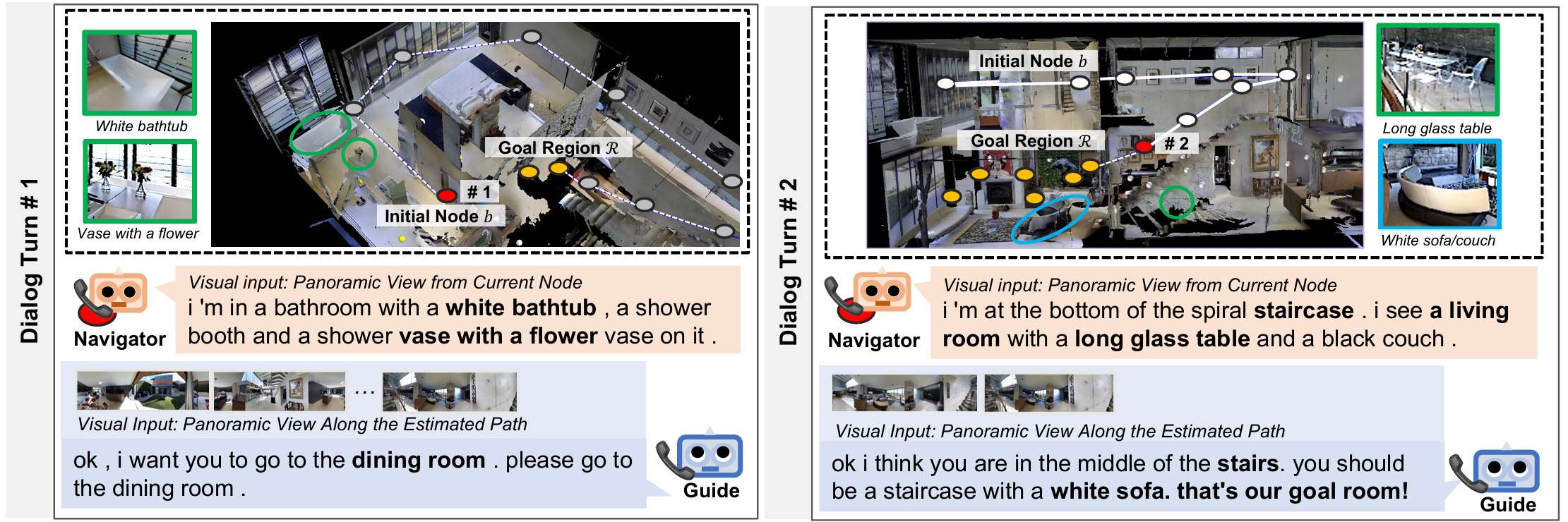
- 任务目标:DialNav是一个新型的导航任务,旨在通过多轮对话的方式,让导航智能体(Navigator)在远程向导(Guide)的协助下,从初始位置(initial node)导航到指定的目标区域(goal region)。
- 任务特点:
- 初始指令模糊性:Navigator开始时仅获得一个关于目标区域的模糊初始指令(initial instruction),例如“目标房间内有地毯”,该指令仅提供关于目标区域的线索,不足以直接导航到目标位置。
- 对话的重要性:导航过程中,Navigator需要通过与Guide的自然语言对话来获取额外的导航指导。Guide对环境熟悉,但不知道Navigator的当前位置,因此需要通过对话来推断Navigator的位置,并提供从当前位置到目标区域的导航指令。
- 任务的动态性:DialNav任务是一个动态的、交互式的任务,导航路径和对话内容会根据Navigator的行动和提问而实时变化,这使得任务的执行过程具有不确定性和多样性。
- 任务的综合性:DialNav任务不仅涉及导航和对话两个主要方面,还整合了多个子任务,包括导航决策、提问时机判断、问题生成、导航定位和回答生成等,这些子任务相互关联、相互影响,共同构成了一个复杂的任务体系。
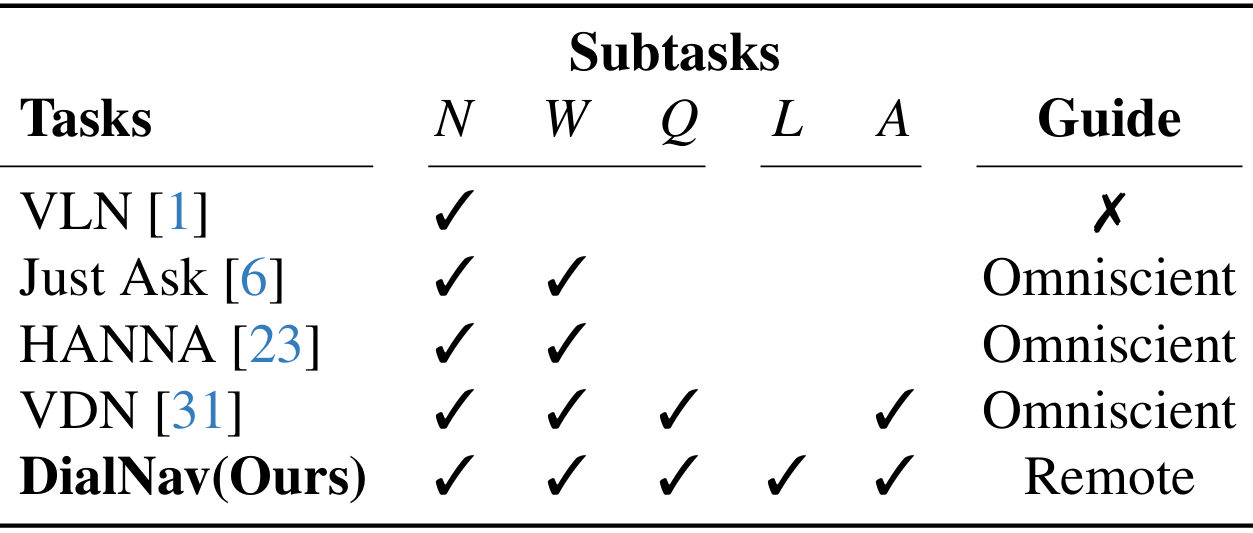
- 任务与现有任务的比较:与现有的视觉语言导航(VLN)任务相比,DialNav的主要区别在于引入了远程向导和对话机制。在传统的VLN任务中,导航智能体通常会收到详细的、预先定义好的导航指令,而DialNav中的导航智能体需要通过与向导的实时对话来获取导航信息,这增加了任务的复杂性和挑战性。
数据集收集
-
数据集概述:为了支持DialNav任务,论文收集并发布了Remote Assistance in Navigation(RAIN)数据集,该数据集包含了2231个导航任务,每个任务都包含了导航轨迹和人类之间的多轮对话。
-
导航模拟器:数据集基于Matterport3D模拟器构建,该模拟器利用真实房屋的三维重建模型,将每个房屋表示为一个图结构,其中节点代表房屋内的可导航位置,边代表节点之间的连接关系。导航智能体可以在图中移动,并在每个节点获得全景视图。
-
数据集划分:数据集被划分为训练集、验证集和测试集,其中训练集包含1559个任务,验证集包含285个任务,测试集包含387个任务。验证集进一步划分为已见环境(seen environments)和未见环境(unseen environments),以评估模型在不同环境下的泛化能力。
-
数据收集工具:为了收集高质量的对话数据,论文开发了一个专门的数据收集工具,该工具为导航智能体和向导提供了交互界面。导航智能体界面包括导航界面、提示(关于目标房间的线索)、聊天界面和猜测按钮(用于指示是否到达目标区域);向导界面则提供了对整个房屋布局的了解,包括房屋信息、房间列表、最短路径轨迹等功能,以帮助向导更好地回答问题。
-
数据收集过程:数据收集过程中,两名人类标注者分别扮演导航智能体和向导的角色,完成导航任务。在开始数据收集之前,标注者需要观看教程视频并完成练习任务,以确保他们熟悉任务流程。每个任务完成后,标注者会相互评价对方的表现,以确保数据质量。此外,为了保证数据的效率,每个任务的时间限制为22分钟,平均完成时间为8分钟。
-
数据集特点:
- 对话的多样性:RAIN数据集中的对话内容丰富多样,涵盖了各种导航场景和问题类型。对话中包含了导航智能体对周围环境的详细描述,以及向导根据这些描述提供的导航建议和澄清问题。
- 导航轨迹的复杂性:由于导航智能体需要根据模糊的初始指令和对话中的信息进行导航,因此导航轨迹可能会比较复杂,存在一定的探索性和不确定性。数据集中的人类导航轨迹长度分布较广,平均长度为46.73米,包含25.97个节点,明显长于最短路径。
- 任务的挑战性:DialNav任务的复杂性在于需要导航智能体和向导之间进行有效的沟通和协作,同时还需要处理环境的不确定性和导航过程中的各种问题。这使得RAIN数据集成为一个具有挑战性的研究资源,能够推动具身对话导航领域的发展。
统计数据
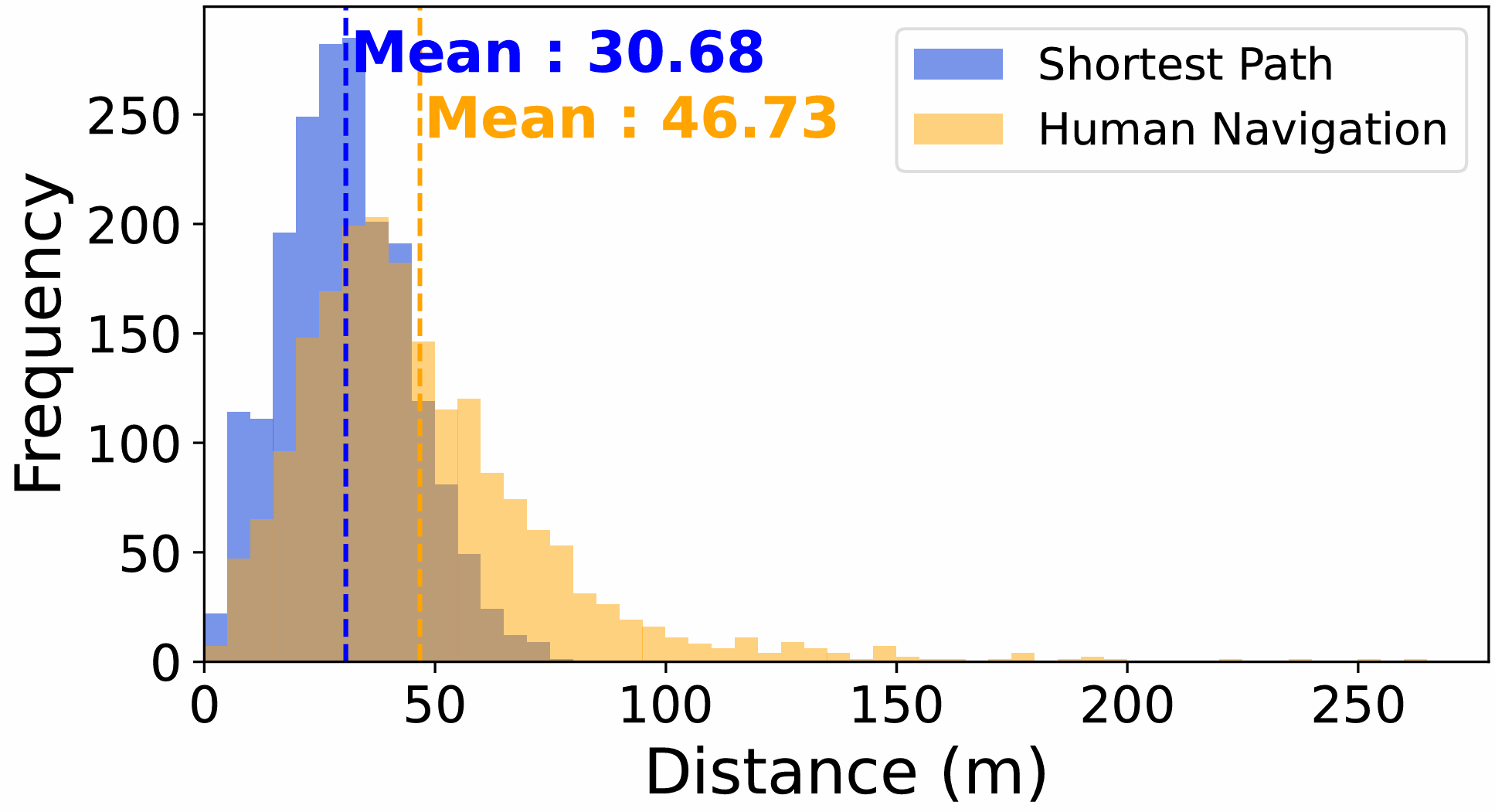
- 导航轨迹统计:上图展示了RAIN数据集中人类导航轨迹长度与最短路径长度的分布情况。最短路径长度范围为2.87米到17.39米,平均长度为10.34米,包含10.34个节点;而人类导航轨迹长度范围为3.02米到262.64米,平均长度为46.73米,包含25.97个节点,人类轨迹平均长度约为最短路径的1.62倍。这表明人类在导航过程中往往会进行更多的探索和迂回,导致轨迹长度增加。
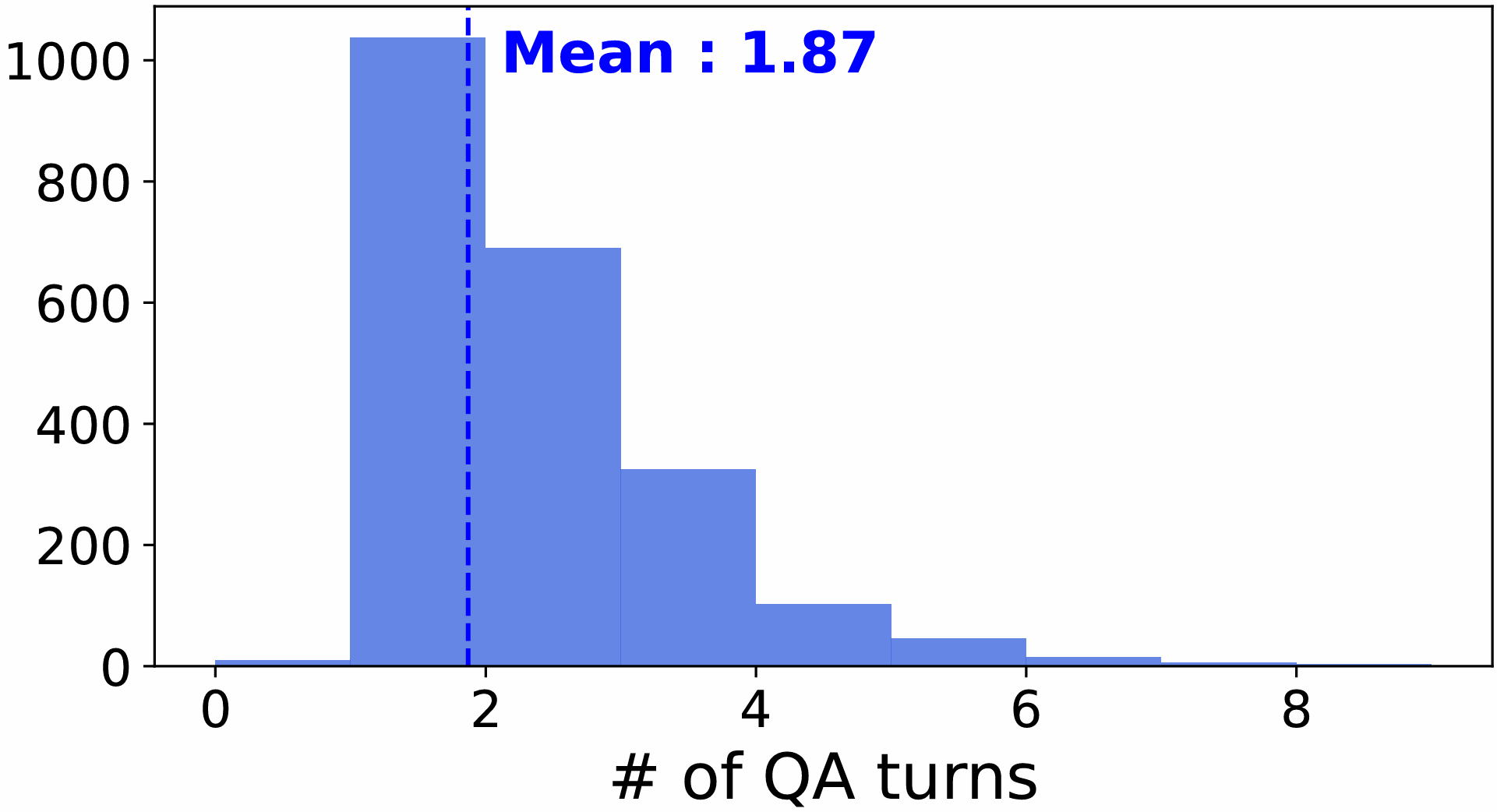
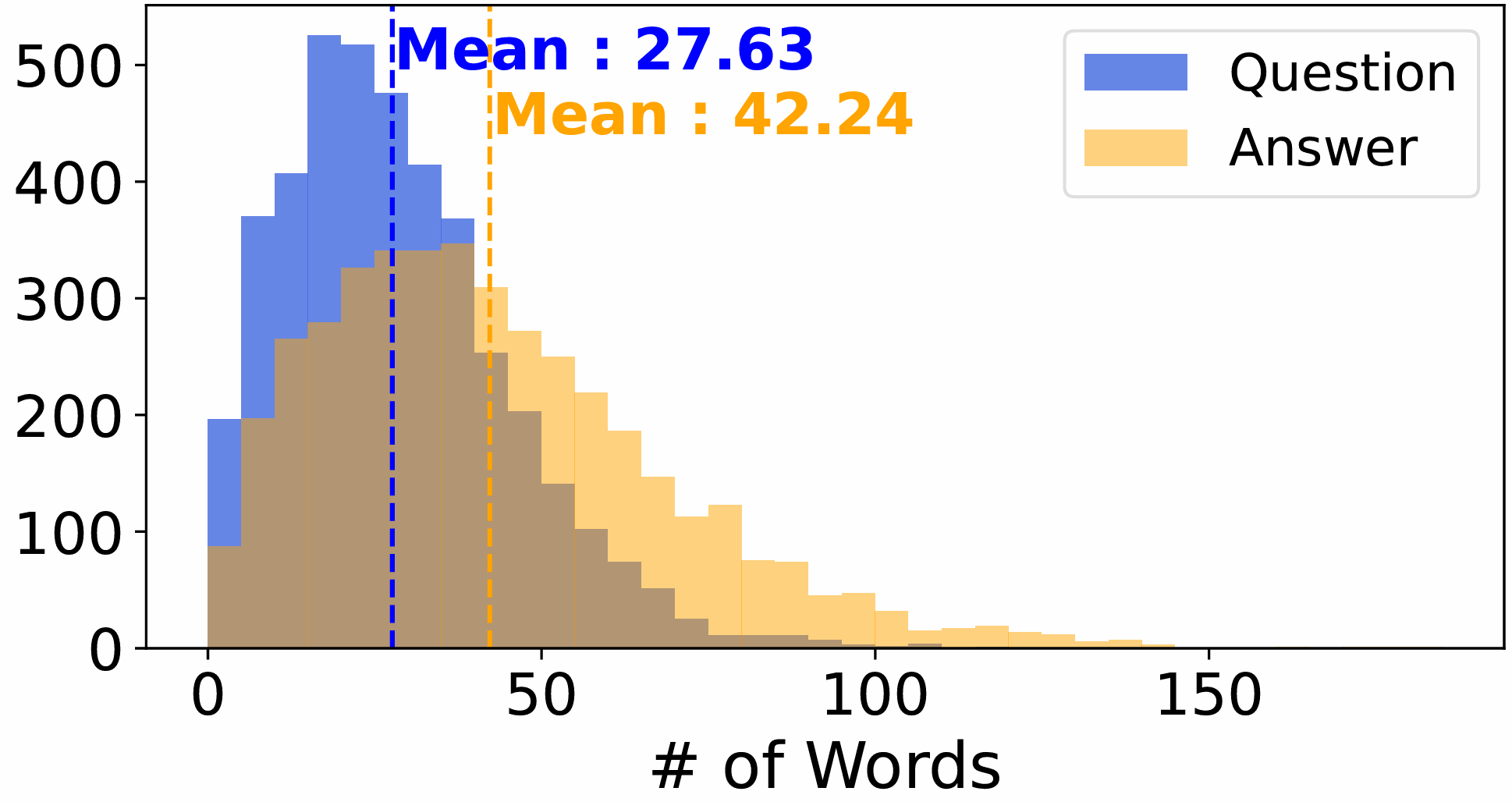
- 对话统计:上图显示了RAIN数据集中每个任务的问答对(QA pairs)数量分布。平均每个任务包含1.87个问答对,超过92%的任务在3个问答对内完成。最长的交互包含8个问答对。问题平均包含27.63个词,答案平均包含42.24个词。由于向导对环境较为熟悉,且每次问答都需要定位导航智能体的位置,因此向导倾向于在可能的情况下提供较为全面的回答,从而导致问答对数量较少,但答案较长。

- 对话特征统计:下表列出了RAIN数据集中对话的一些关键特征及其频率。例如,导航智能体在提问时会详细描述周围环境(频率为0.97),向导有时会请求澄清(频率为0.15),导航智能体也会请求澄清(频率为0.13),并且在到达目标区域后,导航智能体和向导会进行额外的对话以确认目标(频率为0.46)。这些特征表明,在DialNav任务中,对话的详细程度和准确性对于导航的成功至关重要。

导航和向导智能体
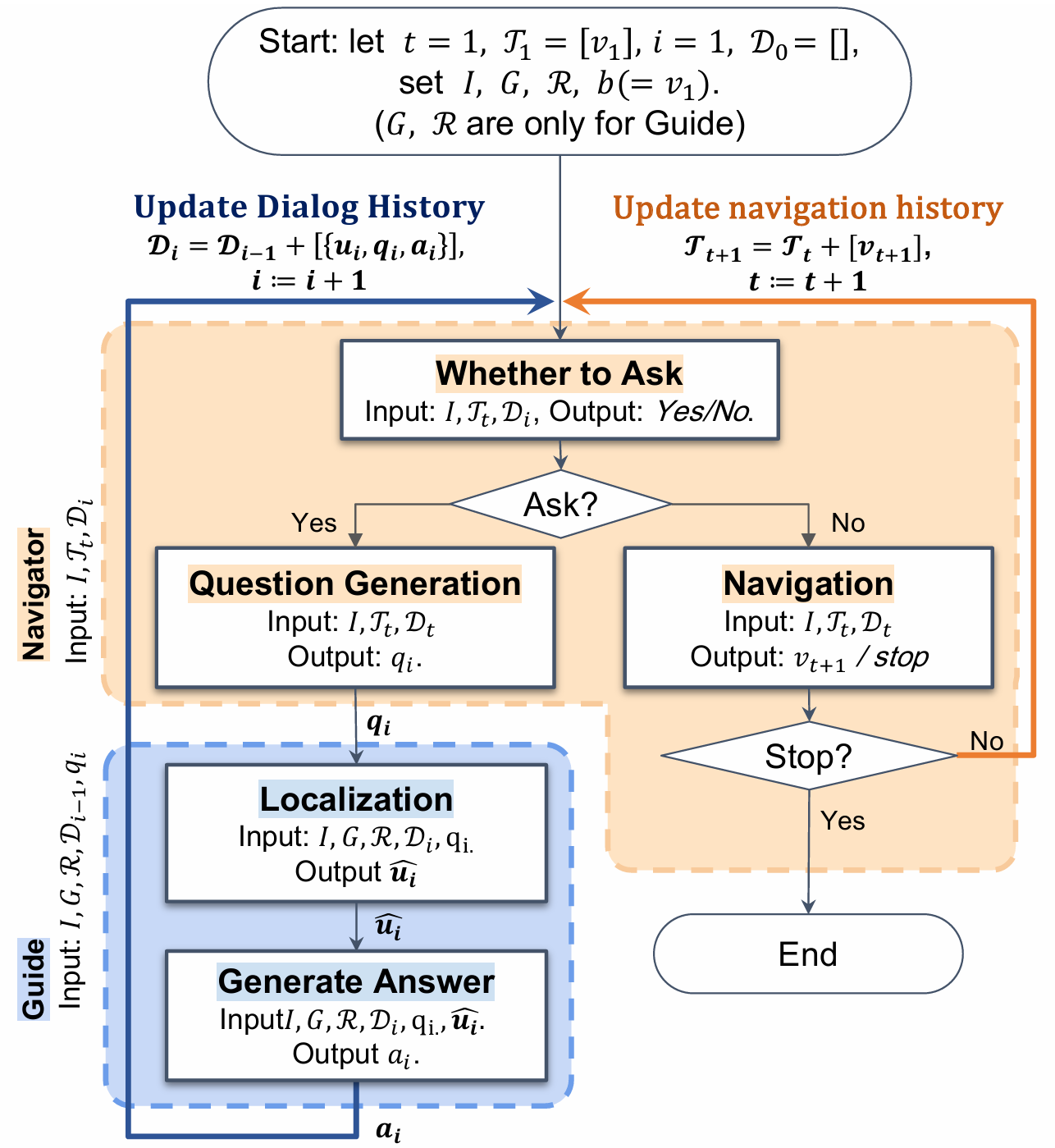
导航智能体
-
Navigator 是导航智能体,它在远程向导(Guide)的协助下,通过对话来完成导航任务。Navigator 的核心能力包括:
-
导航决策:在每个时间步,Navigator 根据过去的对话和导航历史选择下一个节点。这类似于视觉语言导航(VLN)任务,但与 VLN 不同的是,DialNav 中的指令是动态收集的。论文使用了 VLN 模型架构来处理这种动态对话,并将过去的对话视为剩余导航路径的单一指令。具体来说,论文测试了 HAMT 和 DUET 两种模型,最终选择了预训练权重的 DUET 作为基线模型。
-
是否提问:Navigator 需要决定何时向 Guide 提问。过于频繁的提问会增加 Guide 的负担,而提问过少可能导致导航错误。论文测试了三种策略:固定间隔(Fixed-Interval)、置信度阈值(Confidence Thresholding)和决策头(Decision Head)。最终,决策头策略被选为基线模型,因为它能够从 RAIN 数据集中学习提问时机。
-
问题生成:当 Navigator 不确定下一步行动时,它需要向 Guide 提问,并提供周围环境的描述以提供上下文。论文使用了 LANA 模型来生成问题,该模型基于视觉地标生成描述。此外,论文还测试了 LLaVA-1.5 多模态模型,并将其与 LANA 进行了比较。最终,LANA 被选为问题生成的基线模块。
向导智能体
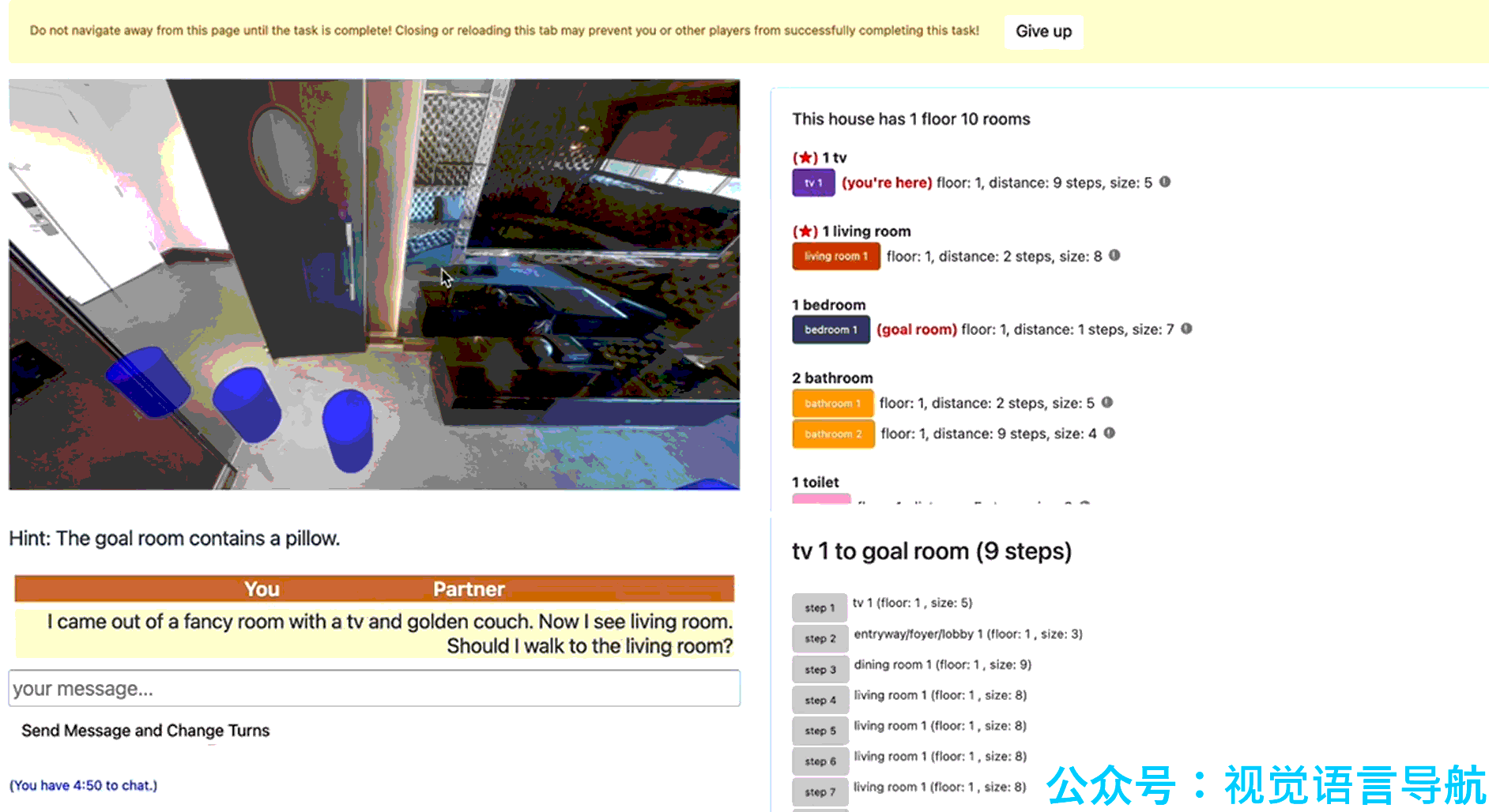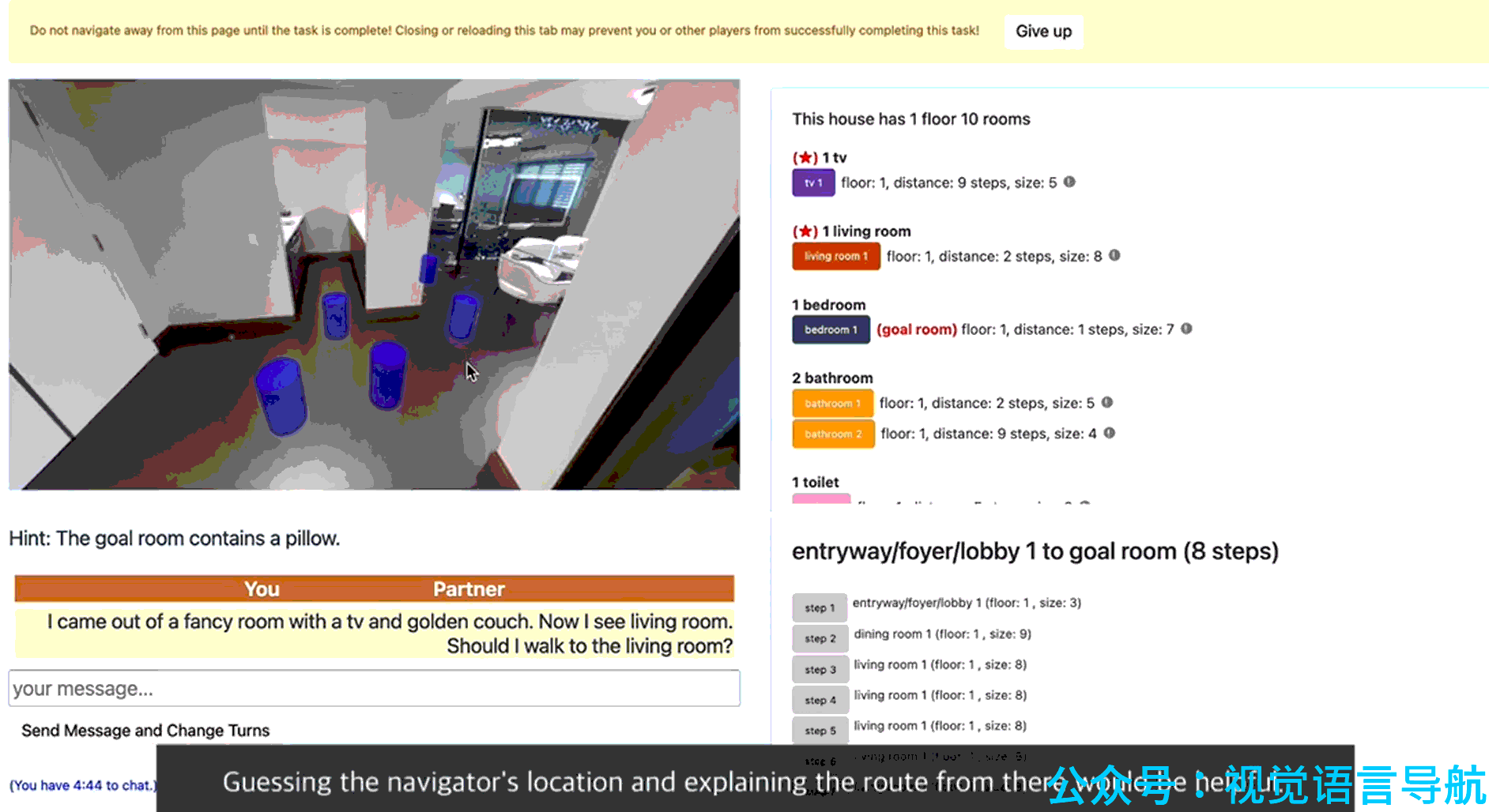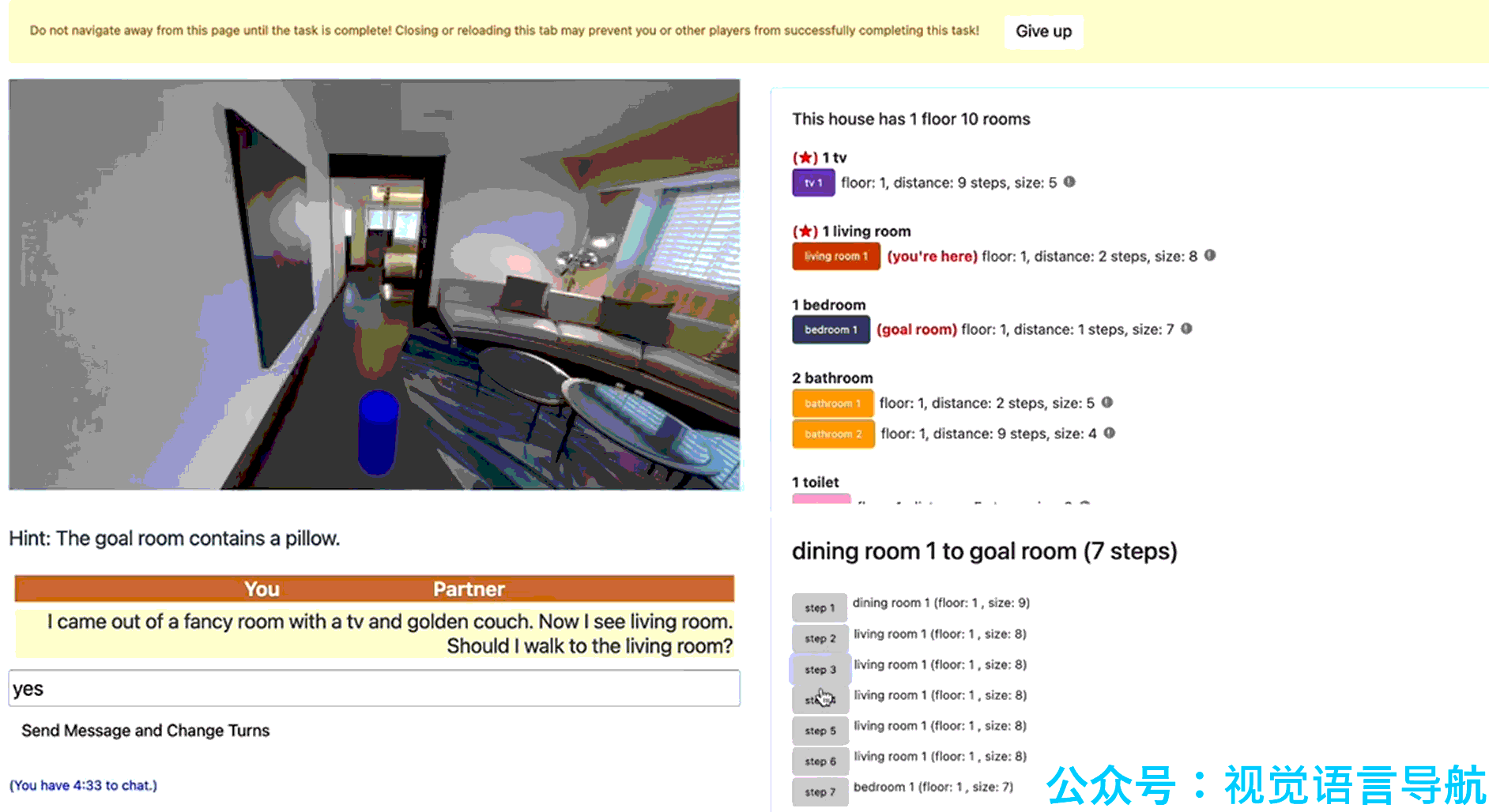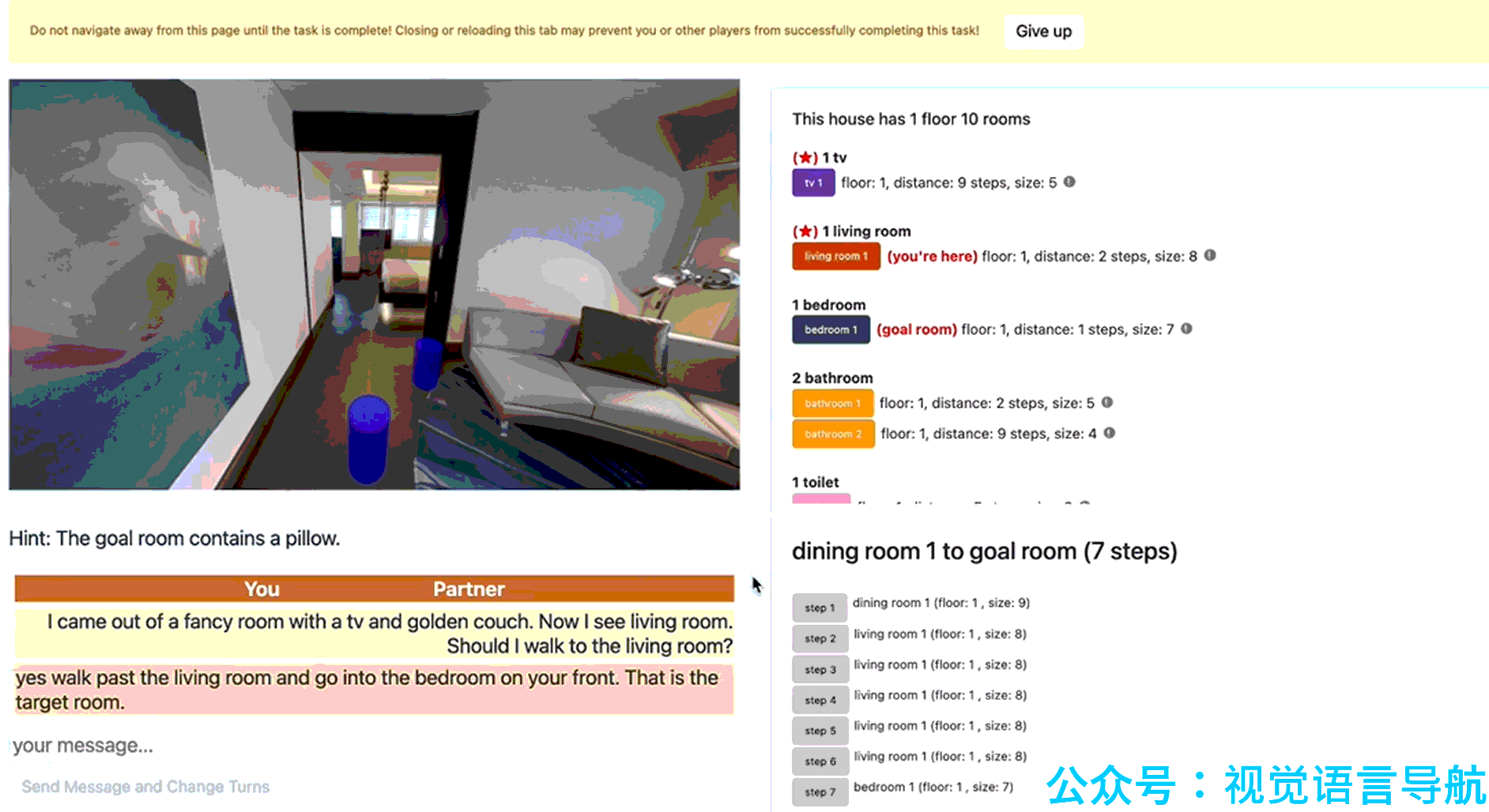
Guide 是远程向导,它根据环境图、初始指令、目标区域和对话历史来为 Navigator 提供导航指导。Guide 的核心能力包括:
- 定位:当 Navigator 提问时,Guide 首先需要估计 Navigator 的位置。这类似于从对话中确定观察者位置的任务(Localization from Embodied Dialog, LED)。论文测试了两种模型:简单跨模态网络(SCN)和图卷积网络(GCN)。最终,GCN 被选为基线模型,因为它在预训练和微调后表现更好。
- 回答生成:Guide 需要生成回答来指导 Navigator 到达目标区域。这类似于 VLN 中的指令生成任务。论文测试了 LANA 和 Llama-3.1-8B-instruct 两种模型,并最终选择了 LANA 作为回答生成的基线模块。
实验
实验设置
- 模块训练:每个模块都在 RAIN 数据集上进行训练,并使用相关 VLN 任务的预训练权重进行初始化。
- 合作评估:将各个模块集成到完整的对话式导航流程中,以评估导航和对话的综合性能。
- 评估指标:使用多种导航和对话效率指标进行评估,包括成功率(SR)、路径长度惩罚的成功率(SPL)、导航误差(NE)、导航步数(NSC)、对话轮次(DTC)和定位误差(LE)。
实验结果
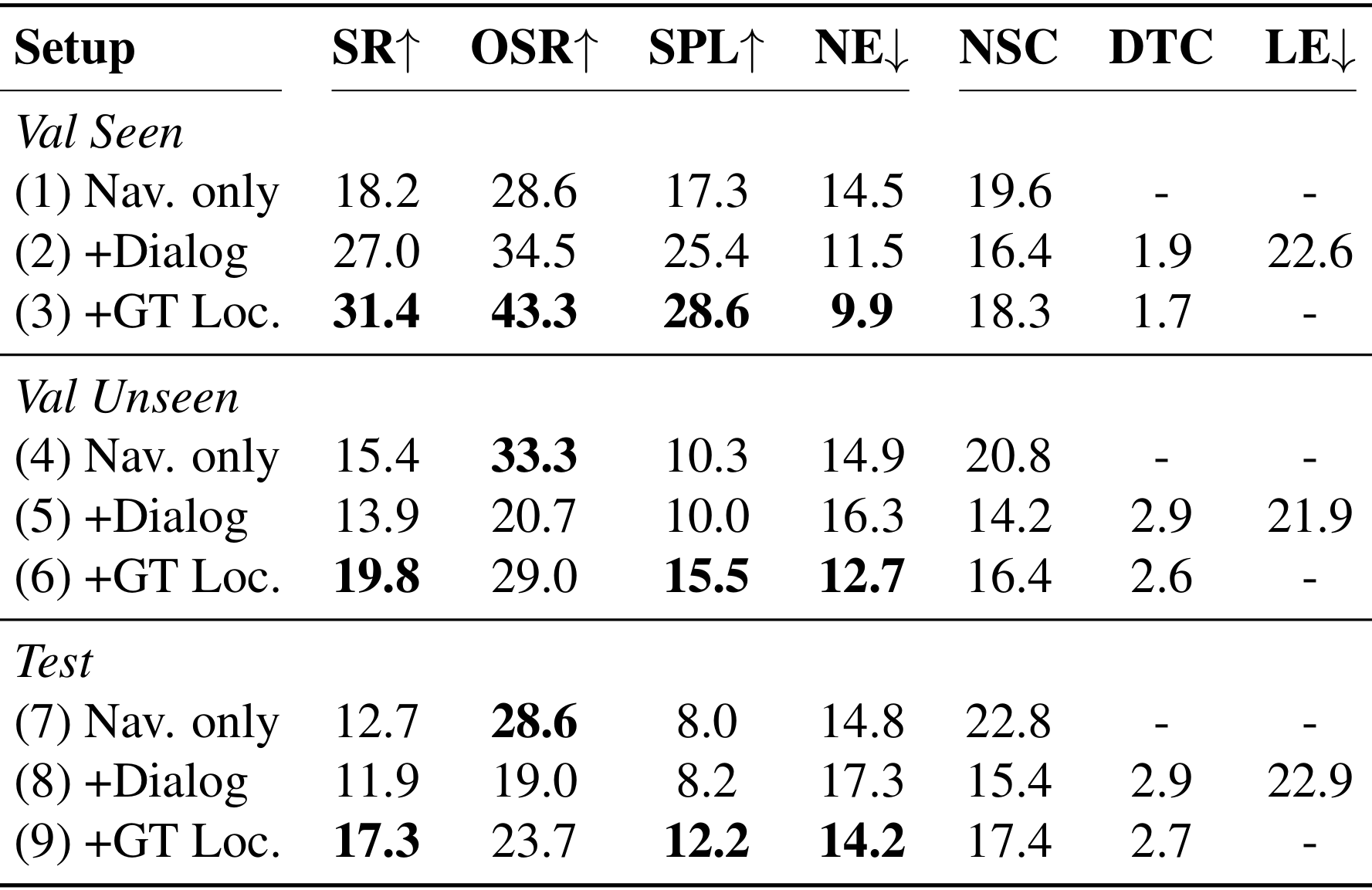
- 对话对导航的影响:
- 已知环境(Val Seen):启用对话的模型(+Dialog)相比仅依赖初始指令的模型(Nav. only)在成功率、路径效率和导航误差方面都有显著提升。具体来说,成功率(SR)从 18.2% 提升到 27.0%,路径长度惩罚的成功率(SPL)从 17.3% 提升到 25.4%,导航误差(NE)从 14.5 降低到 11.5。
- 未知环境(Val Unseen 和 Test):在未知环境中,启用对话的模型虽然整体性能较差,但相比仅依赖初始指令的模型,其导航步数(NSC)更少,表明对话减少了不必要的探索。
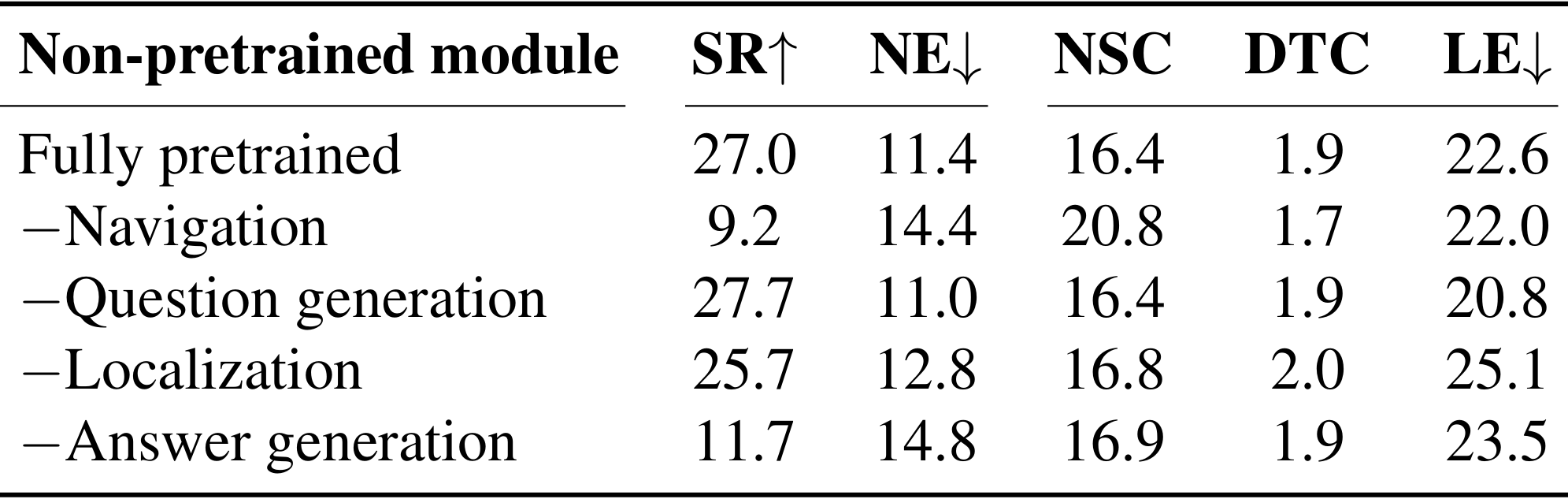
- 预训练的影响:预训练对导航模块和回答生成模块的性能提升至关重要。例如,未预训练的导航模块(-Navigation)的成功率(SR)仅为 9.2%,而预训练的导航模块(Fully pretrained)的成功率(SR)为 27.0%。这表明预训练能够显著提高导航性能。
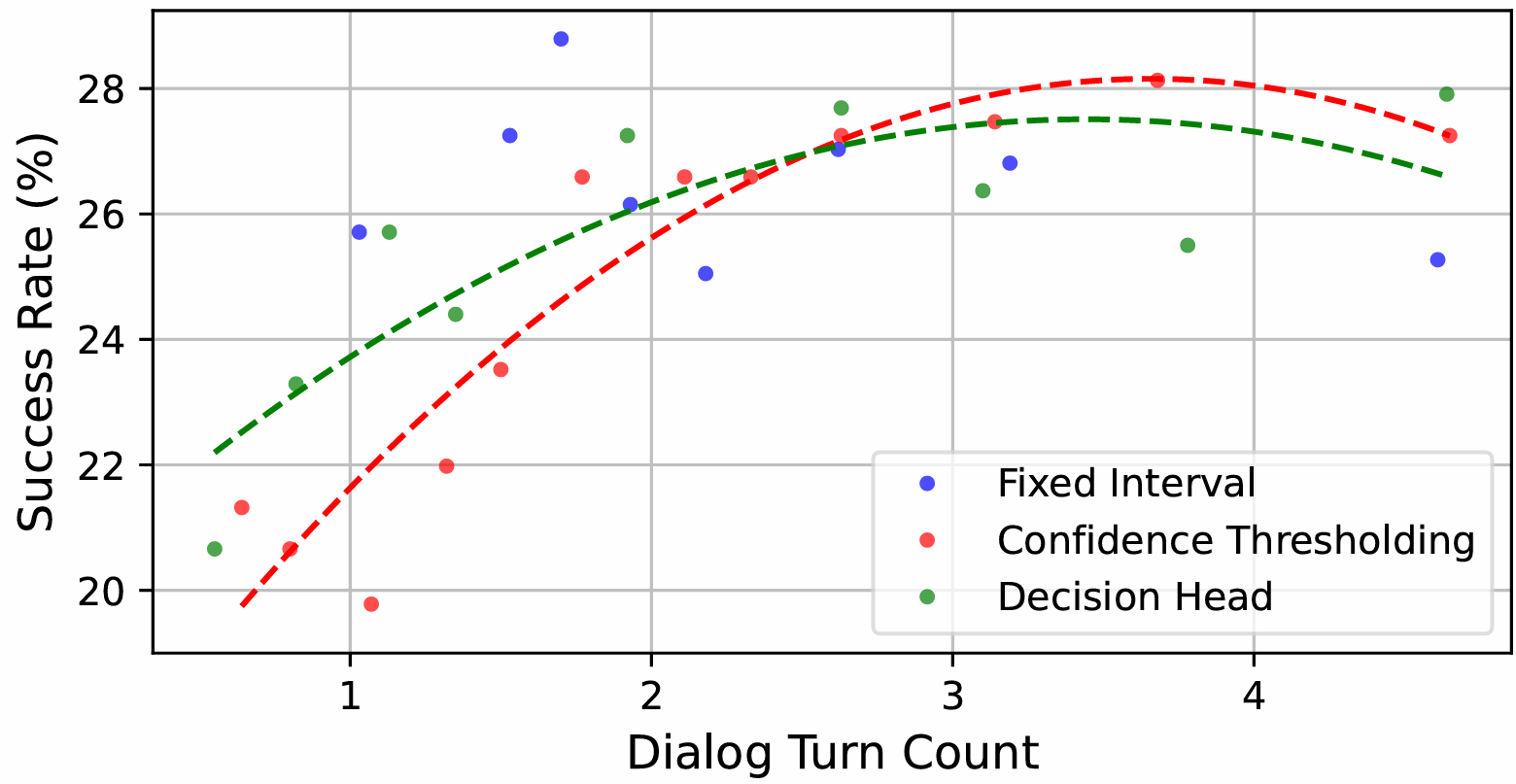
- 是否提问策略的影响:置信度阈值(Confidence Thresholding)和决策头(Decision Head)策略能够在任务成功率和对话效率之间实现平衡。然而,超过一定轮次后,收益会趋于平稳。
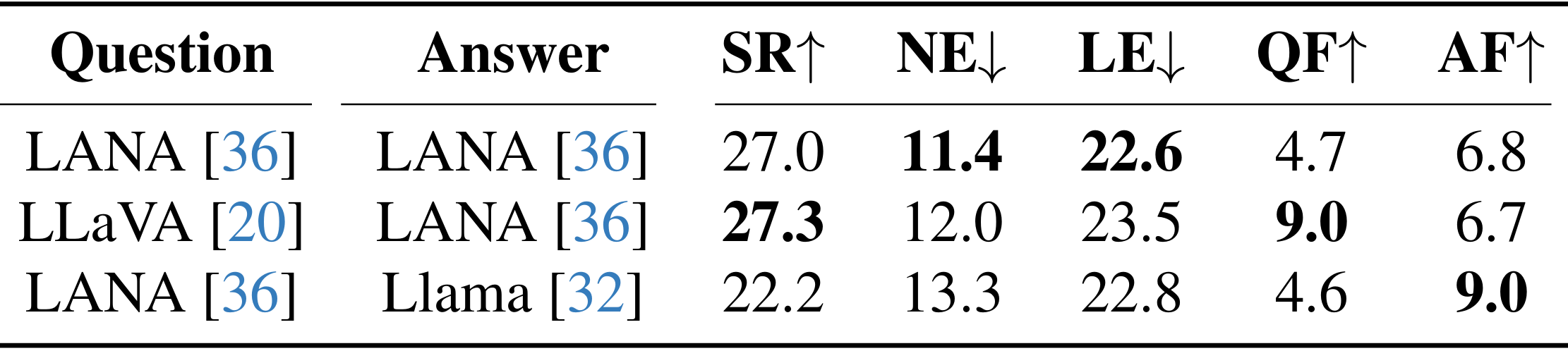
- 对话流畅性的影响:LLaVA 和 Llama 生成的对话更流畅,但由于缺乏针对任务的微调,其导航性能不如 LANA。这表明需要将大型语言模型的强大语言能力与任务特定的导航能力相结合。
挑战
数据收集成本高
- 实时交互需求:DialNav任务需要两名专家标注者实时互动,这使得数据收集成本高昂且难以扩展。
- 效率问题:由于任务的轮流性质,一名标注者需要等待另一名标注者的响应,导致数据收集过程效率低下、耗时较长。
- 环境多样性限制:当前的房屋模拟环境多样性不足,限制了数据集的规模和多样性,进而影响了模型在未见环境中的泛化能力。
子任务相互依赖
- 模块训练复杂性:DialNav任务中的子任务相互依赖,一个模块的错误可能会传播到后续模块,导致整体性能下降。即使在独立测试中表现良好的模块,在完整系统中也可能因错误传播而失败。
- 错误传播问题:微小的错误在子任务之间传递可能会被放大,从而导致不准确的导航决策。因此,减少错误传播并确保所有模块的稳健性能对于任务的成功至关重要。
动态上下文中的评估困难
- 动态和非确定性:DialNav任务的动态性和非确定性使得评估变得复杂。对话生成和导航都涉及序列化的、非确定性的预测,微小的上下文差异可能会显著改变未来的输出。
- 上下文适应性需求:由于任务的动态性,收集到的标注数据可能在预测的上下文中变得无效或不可用。这要求开发更灵活的、能够适应上下文变化的评估方法。
多模态上下文建模的复杂性
- 复杂依赖关系:DialNav任务需要处理全景图像、动作轨迹和多轮对话,这种复杂的依赖关系显著增加了任务的难度,使得有效地整合和利用信息变得更加困难。
导航和对话之间的平衡
- 沟通效率与任务成功率:有效的导航需要在任务成功率和通信效率之间取得平衡。过于频繁的对话可能会提高成功率,但会降低沟通效率;而减少对话可能会导致导航错误增加。此外,智能体需要根据对话的可靠性动态调整提问策略。
结论与未来工作
- 结论:
- 本文介绍了一个新型的具身对话导航任务 DialNav,该任务通过模拟现实世界中导航智能体与远程向导之间的多轮对话来完成导航目标。
- 并为此收集发布了 RAIN 数据集,同时设计了综合评估基准并进行了实验分析,揭示了任务的关键挑战,旨在推动具身对话导航领域的发展。
- 未来工作:
- 未来的研究可以探索自动数据创建和增强技术,以提高模型在未见环境中的泛化能力;
- 开发更统一的端到端模型,以减少子任务之间的错误传播;设计更灵活的上下文感知评估方法,以适应任务的动态性;
- 以及将大型语言模型的强大语言能力更好地融入具身导航任务中,实现更自然、有效的对话式导航。
