一文读懂 RNN 循环神经网络
在深度学习领域,处理文本、语音、时间序列等序列数据时,传统神经网络往往 “力不从心”。而RNN(循环神经网络) 凭借独特的 “记忆能力”,成为解决这类问题的基础模型。本文将用通俗的语言拆解 RNN 的核心逻辑,从传统网络的痛点切入,带你理解它的结构、计算过程与局限性,为后续学习 LSTM、GRU 打下基础。
一、先搞懂:为什么需要 RNN?传统神经网络的 “致命缺陷”
传统前馈神经网络(如 CNN、全连接网络)在处理序列数据时,存在一个无法回避的问题:无法捕捉数据的 “顺序关系”。
举个直观的例子:
- 对于句子 “我要去打篮球”,传统网络会把分词后的 “我”“要”“去”“打”“篮球” 当作独立的输入,完全忽略词语之间的先后逻辑。
- 若把句子改成 “我要打篮球去”,虽然语义不通,但传统网络会认为这和原句是 “相似输入”,输出相同的结果 —— 因为它看不到 “顺序” 带来的语义差异。
核心原因在于:传统神经网络的输入层之间没有关联,每个输入的处理都是 “孤立的”,就像我们看书时只看单个字,却不懂句子的连贯意思。而现实中的序列数据(文本、语音、股票价格),当前信息往往依赖于前面的内容,比如 “他今天出门带了伞,因为昨天____”,空格处的词需要依赖 “带伞” 这个前提,传统网络无法做到这种 “上下文关联”。
为了解决这个问题,RNN 应运而生 —— 它给神经网络加了 “记忆”,能把前面输入的信息保留下来,用于处理后面的数据。
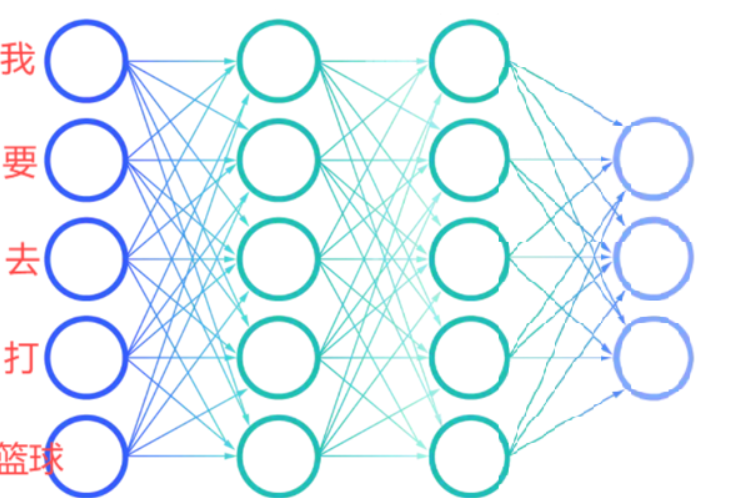
二、RNN 的核心:带 “记忆” 的循环结构
RNN 的本质是在神经元之间增加了循环连接,让网络能 “记住” 之前的输入信息。我们可以从 “基本单元” 和 “整体结构” 两个层面理解它。
1. RNN 基本单元:能存信息的 “小盒子”
RNN 的最小计算单元(可理解为一个神经元)有两个关键输入,和一个核心输出:
- 输入 1:当前时间步的输入 x比如处理文本时,x 就是当前词语的词向量(如 “我” 对应的向量)。
- 输入 2:上一个时间步的隐藏状态 h_prev这是 RNN “记忆” 的核心!h_prev 保存了前面所有时间步输入的信息(比如前面所有词语的语义)。
- 输出:当前时间步的隐藏状态 h_curr单元会结合 x 和 h_prev,计算出最新的 h_curr—— 它既包含当前输入的信息,也继承了之前的 “记忆”,然后传递给下一个时间步。
简单来说:每个 RNN 单元就像一个 “接力棒选手”,接过上一棒的信息(h_prev),加上自己的新信息(x),再把整合后的信息(h_curr)传给下一棒。
2. RNN 整体结构:展开后像 “多层前馈网络”
为了更直观理解,我们可以把 RNN 按 “时间步” 展开 —— 假设处理一个长度为 3 的序列(x1→x2→x3),展开后结构如下:
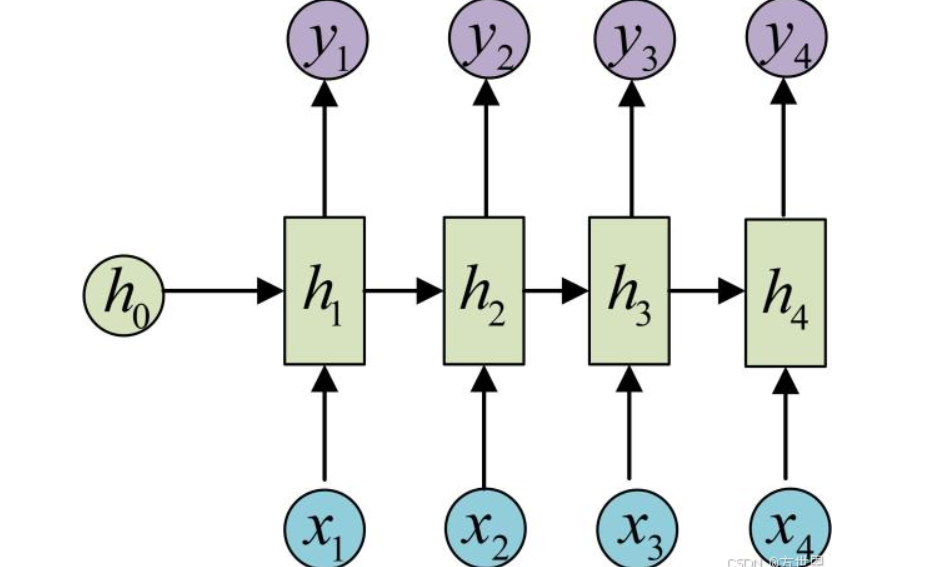
这个展开结构有两个关键特点:
- 输入输出等长:若输入是长度为 n 的序列(x1~xn),输出也会是长度为 n 的隐藏状态(h1~hn)。但实际任务中,我们通常只需要最后一个隐藏状态 h_n—— 因为它包含了整个序列的所有信息(比如处理句子时,h_n 就是整个句子的语义向量)。
- 权重共享:展开后的所有 RNN 单元,使用的是同一套参数(U、W、b)。这意味着无论序列多长,网络参数数量不变,既能处理任意长度的序列,又能避免参数过多导致的过拟合。
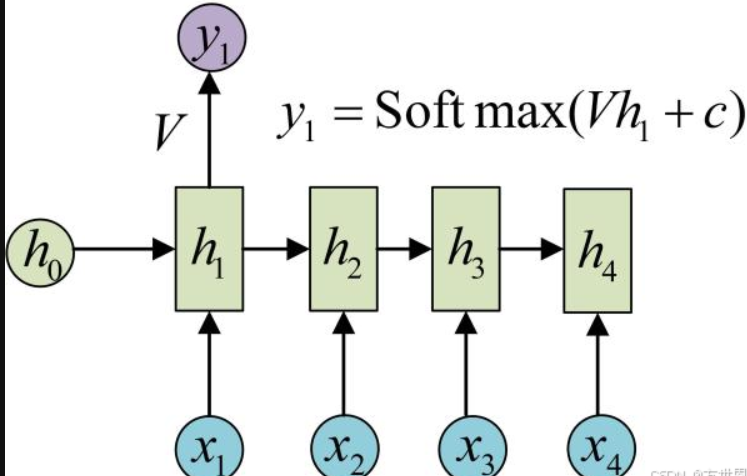
三、计算过程
RNN的展开形式(Unfolding)有助于理解其工作原理。
注意:展开后,RNN看起来像是一个多层的前馈神经网络,但每一层的权重是共享的,每层的U、W、b是一样的,这是RNN的重要特点。这种权重共享机制使得RNN能够处理任意长度的序列,而不需要为每个时间步训练不同的权重。
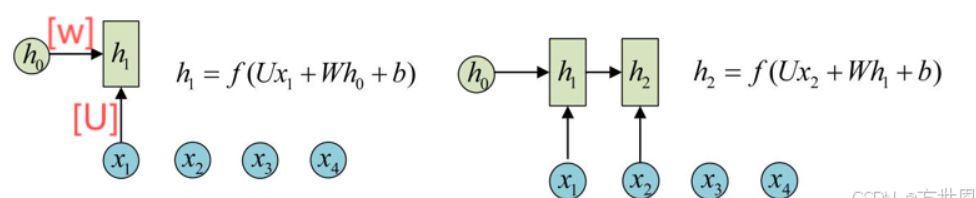
如此计算就可以保留序列数据的关系,比如,”今天我要去打球“,分词后”今天“,”我要“,”去“,”打球“,传入循环神经网络:
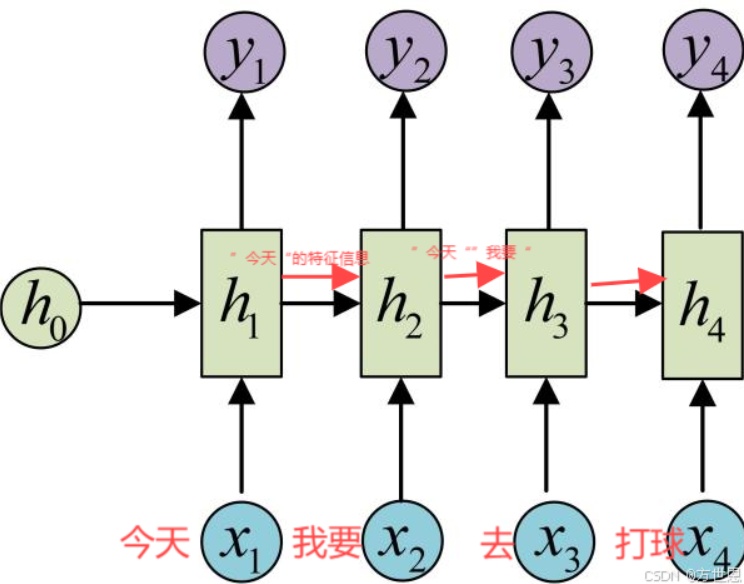
每一层训练都保留了上一层训练的特征信息,从而使得最后的输出结果保留了所有单词的特征信息,这样模型预测时,输入”我要打球去今天“,只要特征信息对应上就可以理解为相同意思。
四、RNN 的 “硬伤”:为什么记不住 “长远信息”?
虽然 RNN 能处理序列数据,但它有一个致命局限 ——长期依赖问题(Long-Term Dependencies):当序列过长时,RNN 无法有效传递 “早期关键信息”。
1. 问题场景:早期信息 “被遗忘”
举个例子:对于句子 “我的职业是程序员,我每天用 Python 写代码,周末喜欢看电影,最近在学新框架,我最擅长的是____”,空格处需要填 “编程” 或 “代码”,而这个答案的关键信息在最开头的 “职业是程序员”。
但 RNN 处理这个长句子时,会出现一个问题:随着时间步增加,“职业是程序员” 的信息在传递过程中会不断 “稀释”,到最后一个时间步时,几乎记不住这个早期信息,导致无法正确预测空格处的词。
2. 根本原因:梯度消失 / 爆炸
这个问题的本质是反向传播时的梯度问题:
- 反向传播更新参数时,梯度需要从最后一个时间步往回传递。
- 当序列过长,梯度会经过多次乘法运算(对应权重矩阵 W 的多次相乘):
- 若梯度值小于 1,多次相乘后会变得越来越小,最终趋近于 0(梯度消失)—— 此时早期时间步的参数无法更新,网络 “记不住” 早期信息。
- 若梯度值大于 1,多次相乘后会变得越来越大(梯度爆炸)—— 导致参数更新异常,网络无法稳定训练。
形象点说:这就像我们背一篇长课文,背到后面时,前面的内容已经忘了;或者记笔记时,前面的字迹越来越淡,最后完全看不清。
3. 解决方案:LSTM/GRU
为了解决长期依赖问题,研究者在 RNN 的基础上改进出了LSTM(长短期记忆网络) 和GRU(门控循环单元)。它们通过 “门控机制”(输入门、遗忘门、输出门),可以主动 “记住” 重要的长期信息,“遗忘” 无关的短期信息,从而有效解决梯度消失问题。这部分内容我们会在后续文章中详细讲解。
五、总结:RNN 的核心要点与适用场景
1. 核心要点
- 优势:能捕捉序列数据的时间依赖关系,权重共享支持任意长度序列,模型结构简单易实现。
- 局限:无法处理长期依赖问题(梯度消失 / 爆炸),仅适用于短序列任务。
- 关键概念:隐藏状态(记忆载体)、权重共享(适应变长序列)、时间步(序列处理单位)。
2. 适用场景
RNN 虽然有局限,但仍是很多基础序列任务的首选,比如:
- 短文本分类(如情感分析:判断 “这部电影很好看” 是正面还是负面)。
- 简单时间序列预测(如预测未来 1~2 天的气温)。
- 语音识别的基础模块(提取短片段语音特征)。
通过本文,你应该已经理解了 RNN 的核心逻辑 —— 它本质是给神经网络加了 “短期记忆”,解决了传统网络处理序列数据的痛点,但也因梯度问题无法应对长序列。如果想进一步学习如何解决长期依赖问题,后续的 LSTM/GRU 就是关键。