多示例演绎基于DeepSeek和Dify工作流实现大模型应用的快速搭建
文章目录
- 模型部署与接入
- 对话主题提取
- 应用目标与效果
- 工作流实现
- 多轮文件问答
- 应用目标与效果
- 工作流实现
- PPT助手
- 应用目标与效果
- 工作流实现
- 图表自动生成
- 应用目标与效果
- 工作流实现
🎉进入大模型应用与实战专栏 | 🚀查看更多专栏内容

在这篇文章中,我将在《基于Dify的工作流全流程测试》的基础上,从实际业务需求出发,详细展示如何利用DeepSeek模型与工作流的强大组合,快速构建四个实用有趣的AI应用工具:对话主题提取、多轮文件问答、PPT助手和图表自动生成。通过这些案例,您将了解从模型部署到应用开发的完整流程。
模型部署与接入
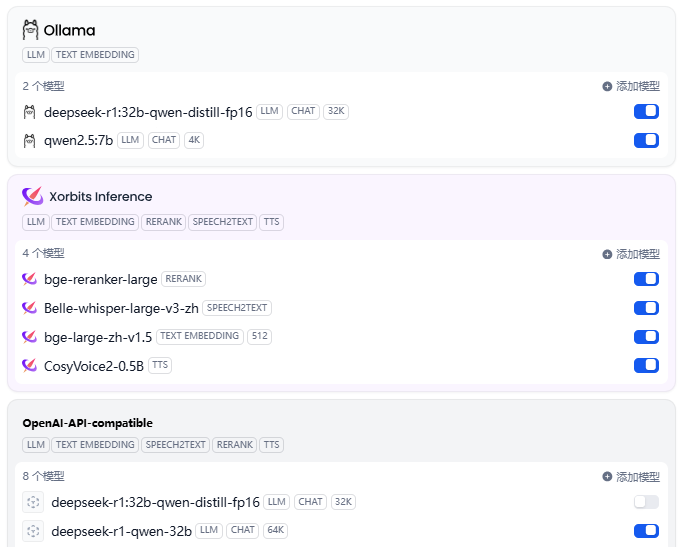
基于ollama或其他框架下载好适合服务器显存大小的DeepSeek开源模型后,基于Dify接入模型。如果Dify没有提供对应的推理框架接入,可以基于通用的OpenAI-API-compatible来接入,详细步骤可参考《Dify部署及初步测试》完成,最终接入效果如下图所示。
对话主题提取
应用目标与效果
当您使用ChatGPT、DeepSeek或Claude等流行大模型应用时,一定注意到对话历史在侧边栏中会以简短标题的形式呈现,方便用户快速定位和回顾之前的对话。
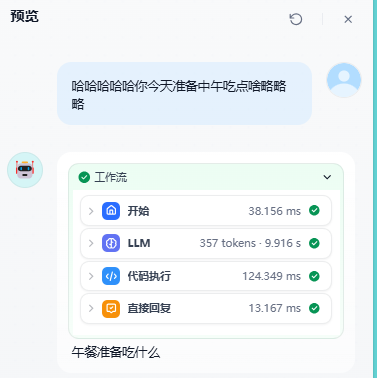
这个看似简单的功能背后,需要一个能够准确提取对话核心主题的智能系统。我们的目标是实现一个接口:输入是一段完整对话,输出是一个简洁的主题或标题,最终实现下面这种效果:
工作流实现
这里的工作流类型要选chatflow。
整体工作流架构设计如下,它采用了简洁而高效的流程:用户输入→DeepSeek主题提取→结果处理→返回对话主题。
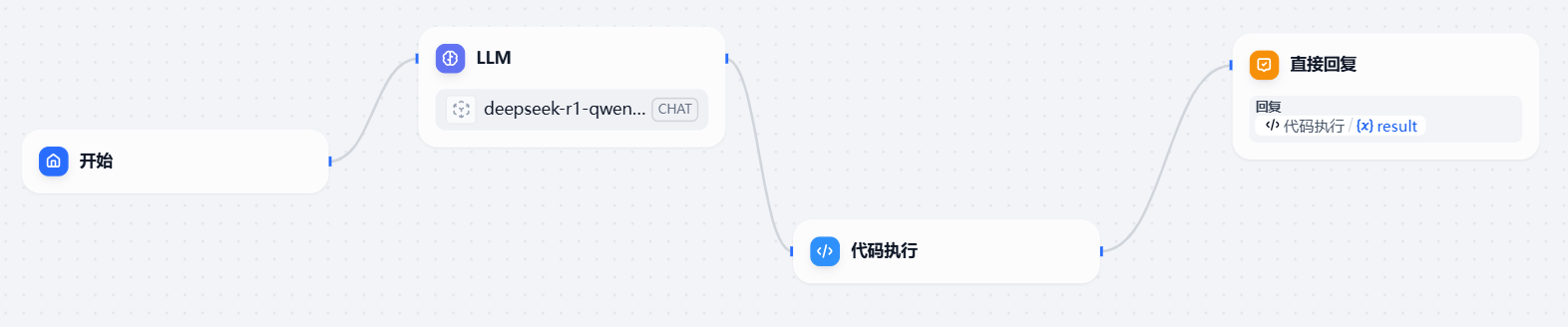
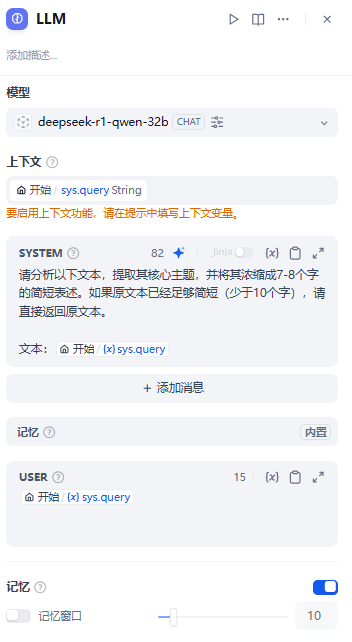
LLM实现部分主要基于精心设计的提示词进行主题提取。
请分析以下文本,提取其核心主题,并将其浓缩成7-8个字的简短表述。如果原文本已经足够简短(少于10个字),请直接返回原文本。
文本:{{#sys.query#}}
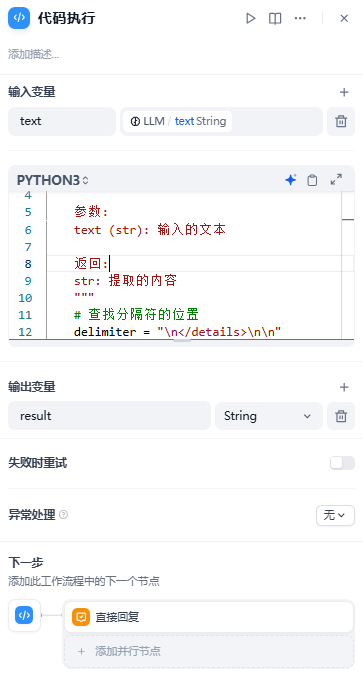
由于DeepSeek模型生成的回答中通常包含思考过程(用标签包裹),我们需要一个额外的处理步骤来精准提取出最终主题。添加代码执行模块,使用正则提取:
def extract_hello(text):
"""
提取文本中\n</details>\n\n后面的部分
参数:
text (str): 输入的文本
返回:
str: 提取的内容
"""
# 查找分隔符的位置
delimiter = "\n</details>\n\n"
position = text.find(delimiter)
if position != -1:
# 提取分隔符后面的内容
result = text[position + len(delimiter):]
return result
else:
# 如果没有找到分隔符,返回原文本
return text[:-7]
def main(text: str) -> dict:
return {
"result": extract_hello(text),
}
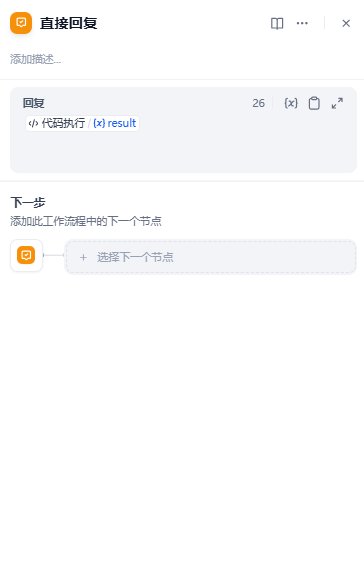
最后,直接将解析结果作为响应返回:
工作流测试无误后,可以参照基于Dify的Agent全流程测试这篇博文实现API的封装及调用,将此功能集成到您的应用中。
多轮文件问答
应用目标与效果
这个应用结合了文件解析与大模型能力,实现一次文件上传后的持续多轮对话。核心技术挑战在于如何区分首次对话(需要处理文件)和后续对话(直接基于历史进行回答),并为两种情况设置不同的处理逻辑。
实际交互效果展示:

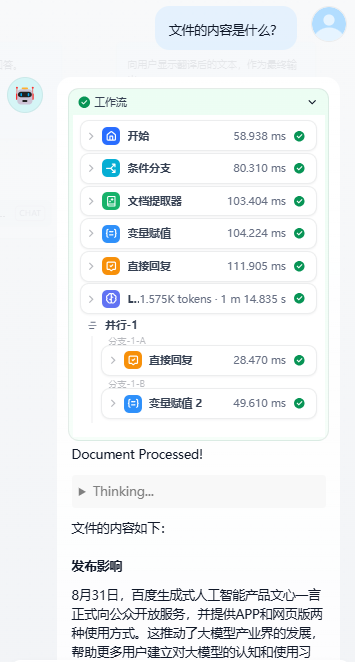
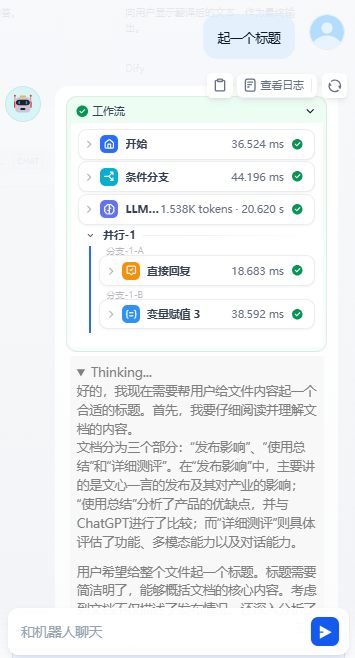
工作流实现
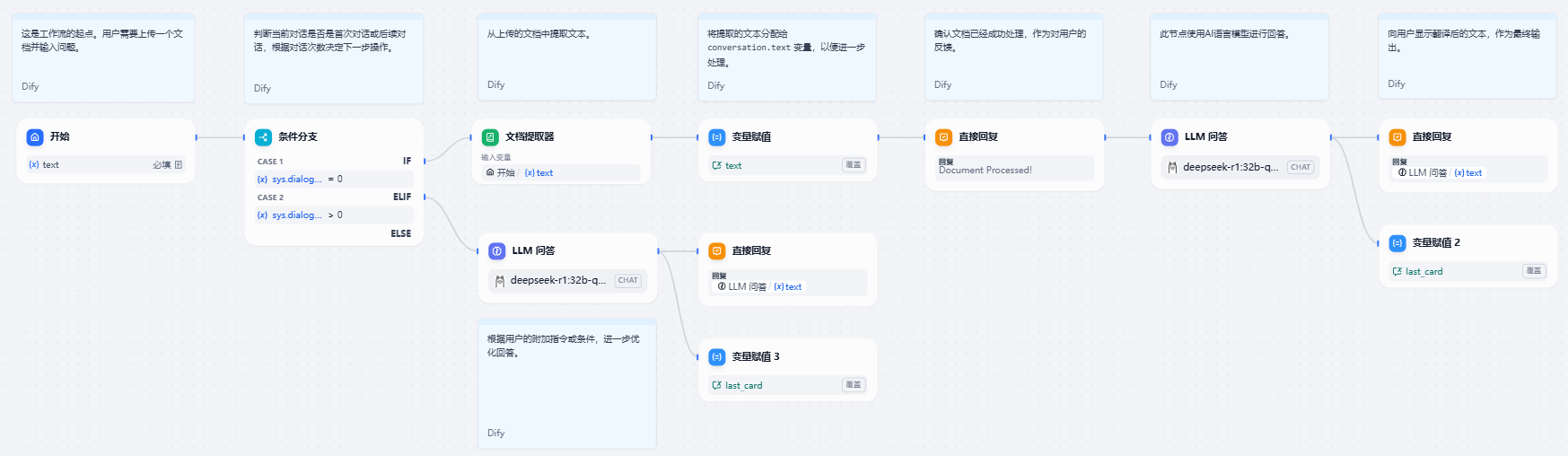
这里的工作流类型依然选chatflow,整体工作流架构如下图所示,通过条件分支判断是否为首次对话,并分别执行文件处理后回答与直接回答逻辑。
首先配置工作流起点,添加要处理的文件:
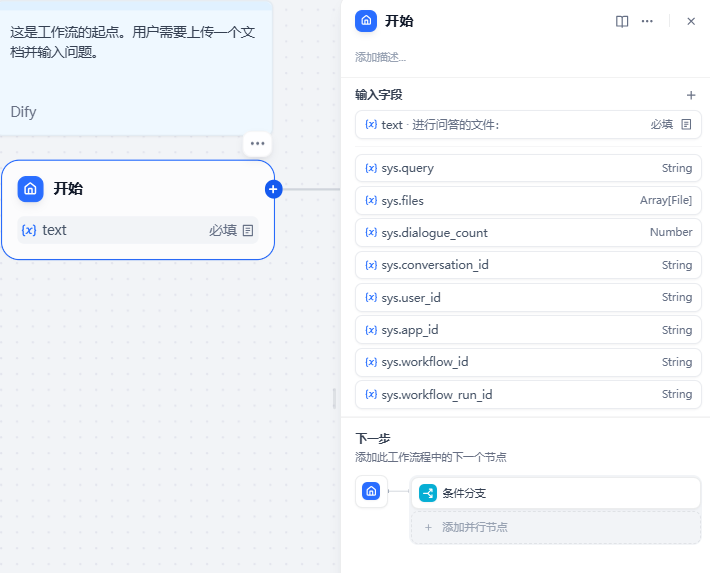
接下来设置条件分支,通过sys.dialogue_count系统变量判断是否为第一轮对话:
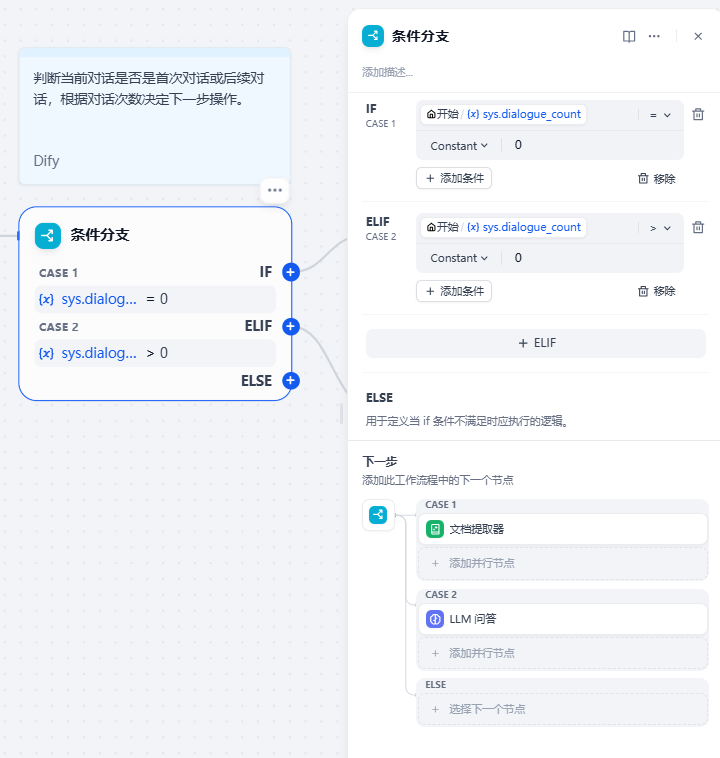
对于首次对话,需要先提取文件内容:
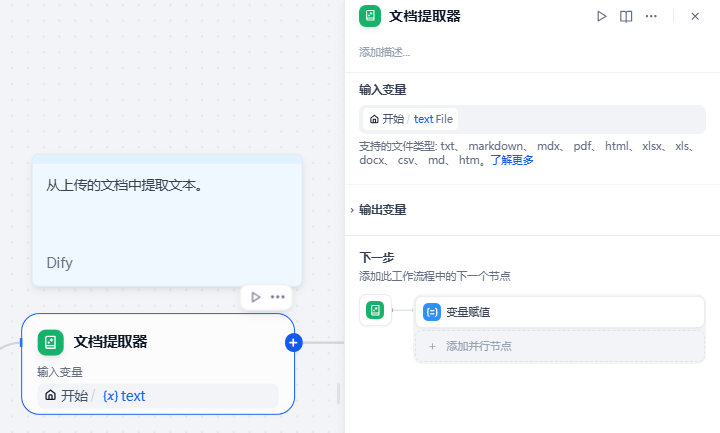
提取后进行变量赋值,保存文件内容以供后续使用:

文档处理完成后,显示提示信息:
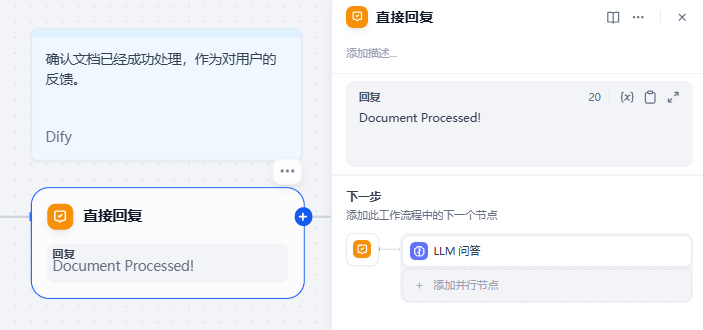
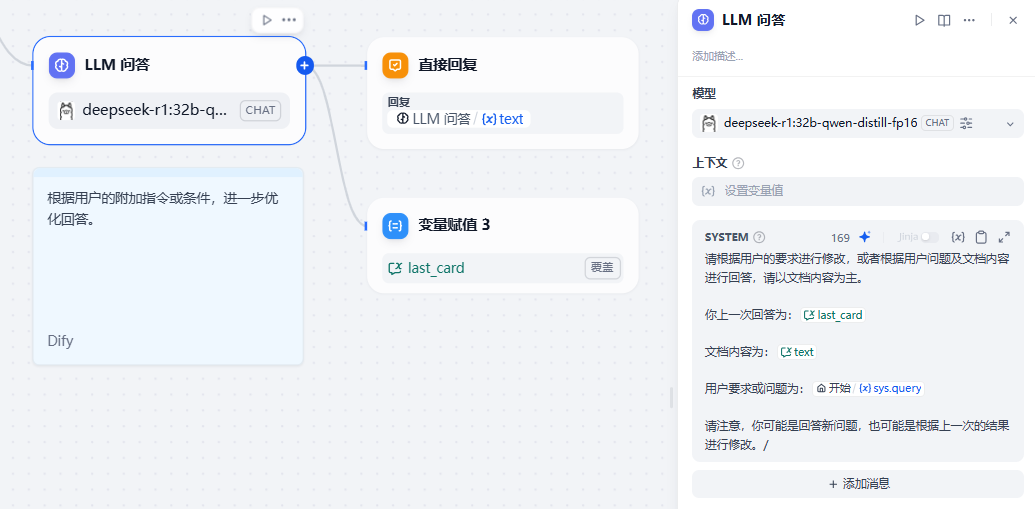
接着设置提示词,指导模型结合文件内容和用户问题进行回答:
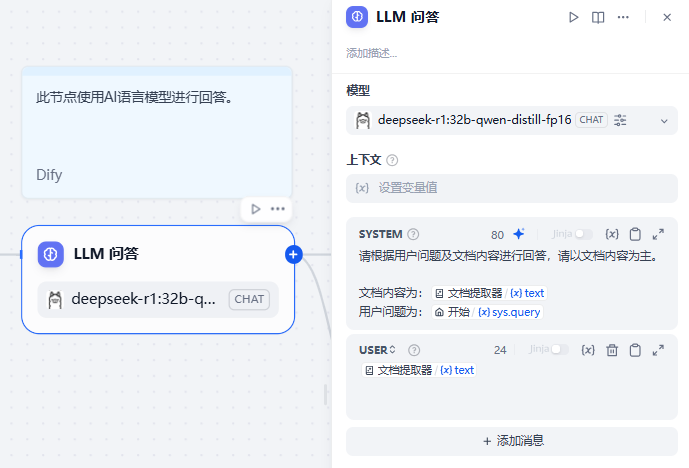
最后回答时,将回答内容存储到一个变量中去,作为我们自己控制的history,它的好处在于,你可以自己对它进行控制和维护,而不完全依赖于Dify的history,例如DeepSeek输出的Thinking块是不是没必要作为上下文一直留着,那我们就可以用主题提取中的正则来把它去掉。
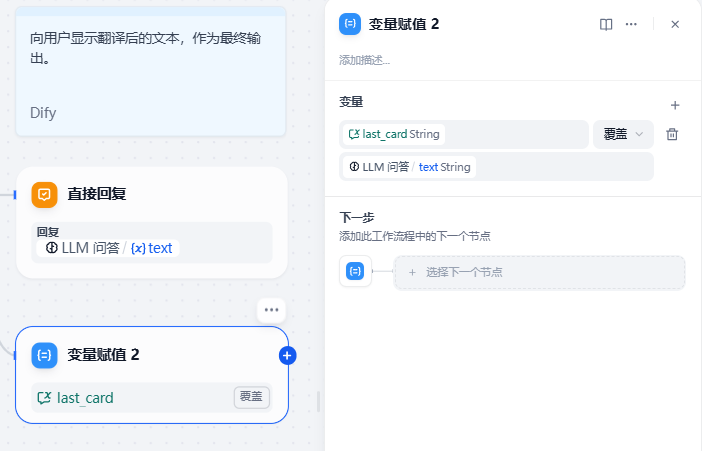
如果不是第一轮对话,那处理逻辑就简单得多,直接走大模型根据历史回答即可,后面的处理都是一样的。
PPT助手
应用目标与效果
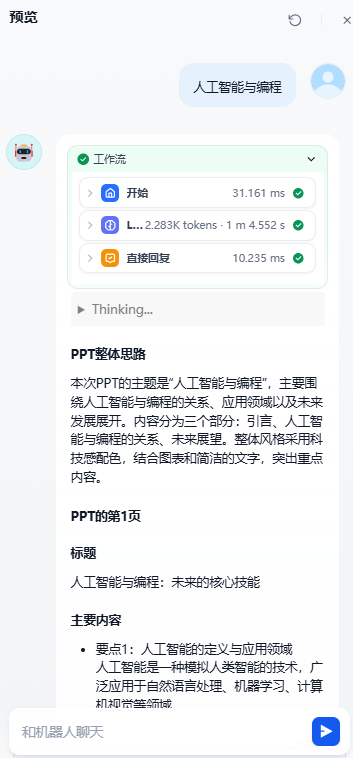
这是一个基于精细提示工程的实用应用,能够根据用户输入的主题自动生成完整的PPT内容,包括结构、要点和设计建议。效果预览:
工作流实现
此应用的工作流设计极为简洁,架构如下:
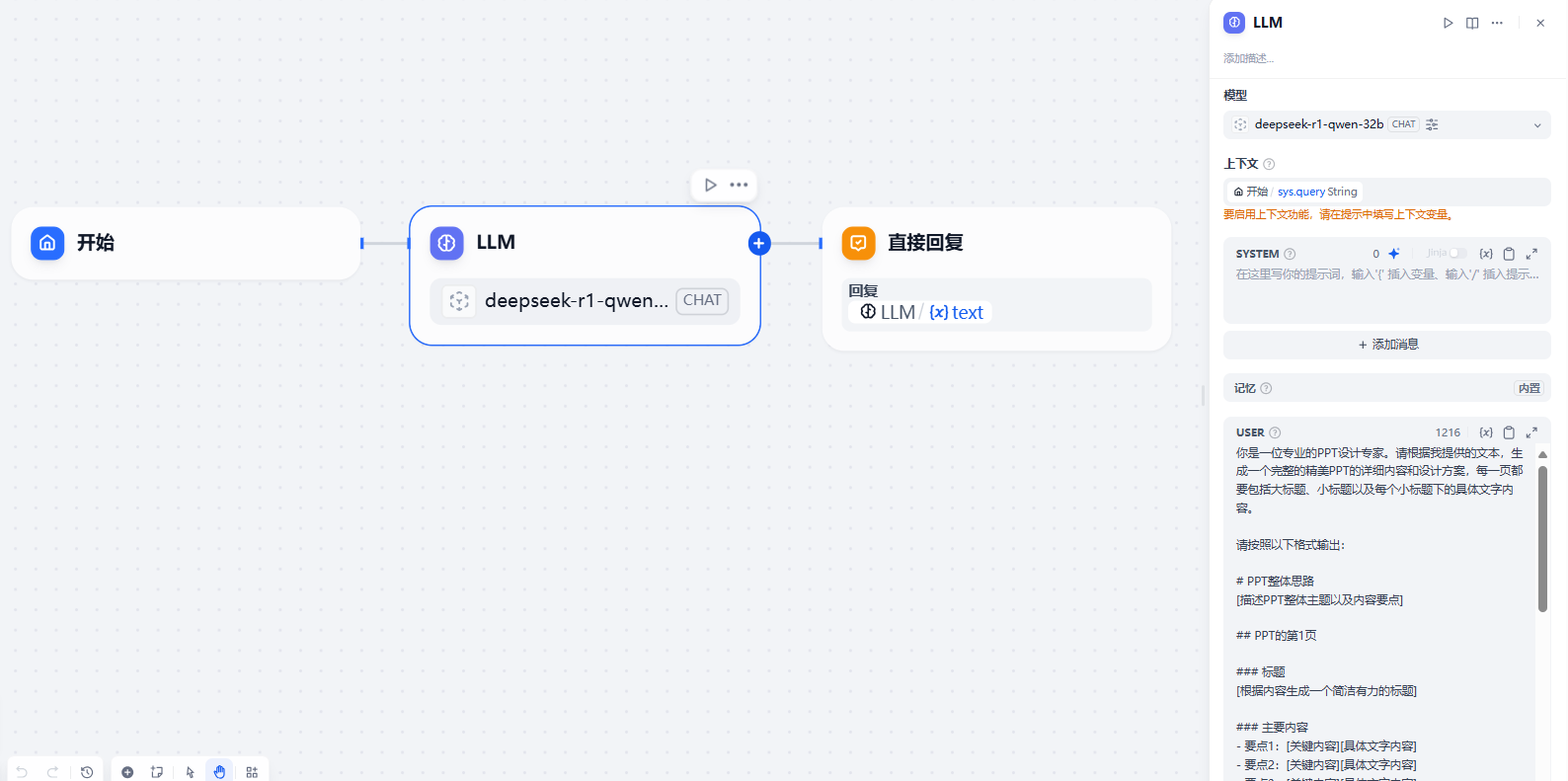
核心在于精心设计的提示词,引导DeepSeek模型生成结构化的PPT内容:
你是一位专业的PPT设计专家。请根据我提供的文本,生成一个完整的精美PPT的详细内容和设计方案,每一页都要包括大标题、小标题以及每个小标题下的具体文字内容。
请按照以下格式输出:
# PPT整体思路
[描述PPT整体主题以及内容要点]
## PPT的第1页
### 标题
[根据内容生成一个简洁有力的标题]
### 主要内容
- 要点1:[关键内容][具体文字内容]
- 要点2:[关键内容][具体文字内容]
- 要点3:[关键内容][具体文字内容]
- ...(根据内容复杂度,列出3-5个要点及相关文字内容即可)
### 版式布局
[建议包含的图表、图片、图标或其他视觉元素,以及它们应该如何排布;建议使用的PPT版式,如标题+内容、双栏、比较等]
### 配色方案
[建议的2-3种主要颜色及其用途]
### 其他设计要点
[任何其他能使这页PPT更加出色的设计建议]
## PPT的第2页
...
### 标题
...
### 主要内容
...
### 预览效果
...
### 版式布局
...
### 配色方案
...
### 其他设计要点
...
## PPT的第3页
...
文本内容:{{#sys.query#}}
这个结构化的提示词确保了模型能够生成包含完整设计元素和内容建议的PPT方案,而不仅仅是内容大纲。
图表自动生成
应用目标与效果
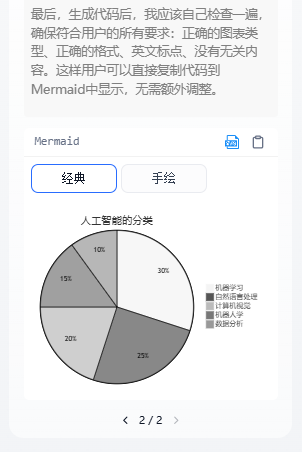
这个应用能够从自然语言对话中智能识别用户的图表需求,然后自动生成对应的可视化图表代码。系统返回的不是图片,而是mermaid语言代码,Dify平台会自动渲染为可视化图表。
工作流实现
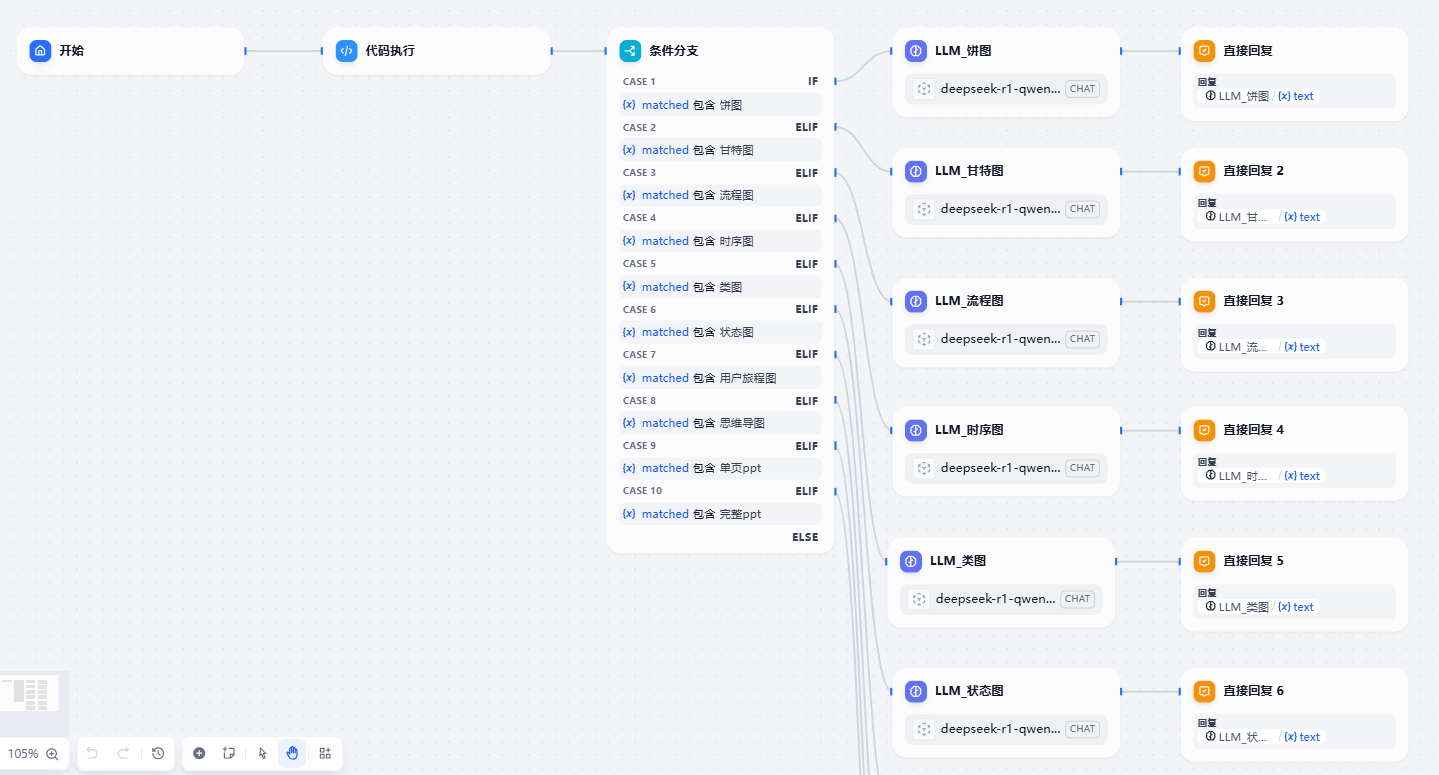
整体工作流架构如下,核心是识别图表类型并分流处理:
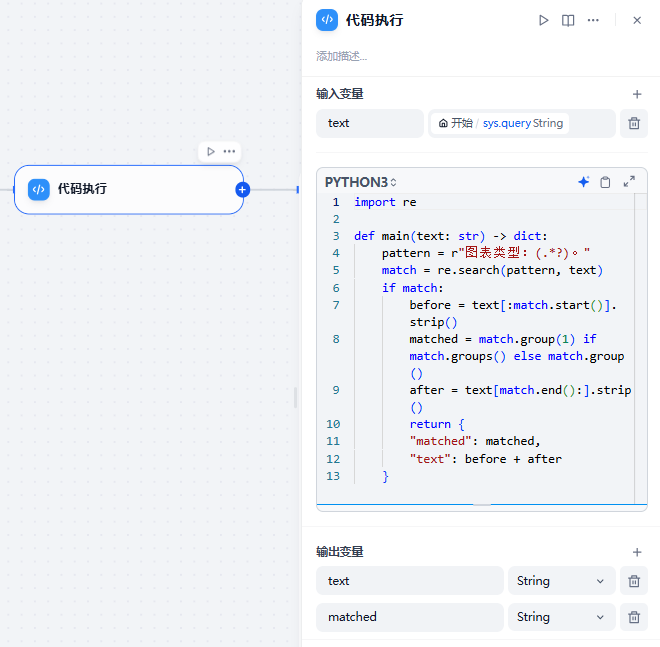
首先通过代码执行模块,使用正则表达式提取用户需要的图表类型:
import re
def main(text: str) -> dict:
pattern = r"图表类型:(.*?)。"
match = re.search(pattern, text)
if match:
before = text[:match.start()].strip()
matched = match.group(1) if match.groups() else match.group()
after = text[match.end():].strip()
return {
"matched": matched,
"text": before + after
}
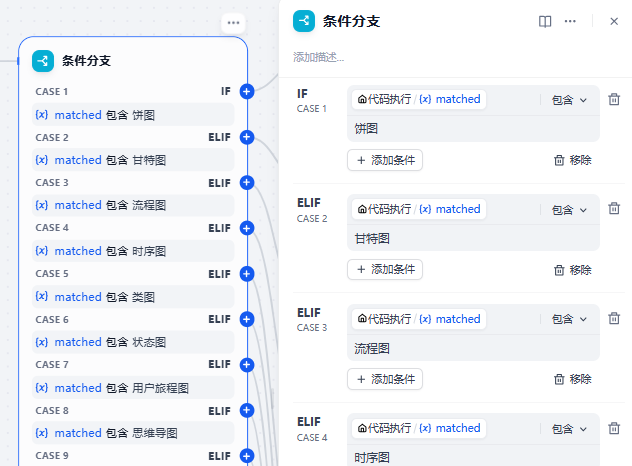
然后通过条件分支,根据识别出的图表类型引导到不同的图表生成组件:
最后,每个图表生成组件使用专门的提示词引导模型生成相应的mermaid代码。以饼图为例:
