自动化C到Rust翻译工具探索:工具实操、不足与挑战解析
文章目录
- 一、工具分类与技术路线概述
- 二、典型工具实操指南与不足剖析
- 1. c2rust:基础语法转换工具
- 工具使用步骤
- 实际案例演示
- 工具不足
- 2. LAERTES:反馈驱动修复工具
- 工具使用流程
- 工具不足
- 3. FLOURINE:LLM驱动的智能翻译工具
- 工具使用步骤
- 实际案例演示
- 工具不足
- 4. VERT:双路径验证翻译工具
- 核心工作原理
- 工具不足
- 三、自动化C到Rust翻译的核心挑战
- 1. 语义鸿沟:C与Rust的核心模型冲突
- 2. 库函数阻抗:API适配复杂度高
- 3. 全局变量困境:安全与兼容性的平衡难题
- 4. 联合体转化:类型双关的处理瓶颈
- 四、未来突破方向与实践建议
- 1. 混合策略:静态分析+LLM协同
- 2. 策略库建设:构建类型提升规则
- 3. 渐进迁移:混合编排除非必要不转换
- 五、总结
在软件开发领域,将C代码迁移到Rust以提升安全性和性能的需求日益增长,自动化C到Rust翻译工具成为关键助力。本教程详细介绍主流自动化C到Rust翻译工具的使用方法、实际案例及存在的不足,并梳理核心挑战与未来方向,帮助开发者高效利用工具完成代码迁移。
一、工具分类与技术路线概述
当前自动化C到Rust翻译工具主要分为两类,二者技术原理和目标存在显著差异,具体如下表所示:
| 工具类别 | 代表工具 | 核心原理 | 翻译目标 |
|---|---|---|---|
| 编译器静态分析工具 | c2rust(基础转换器)、LAERTES(反馈驱动修复)、CROWN(所有权分析) | 通过语法树分析,先将C源码转换为不安全Rust代码,再经LAERTES或CROWN优化为安全Rust代码 | 直接映射C代码结构到Rust,保证代码逻辑正确性的同时,尽可能提升安全性 |
| LLM代码生成工具 | FLOURINE(GPT-4驱动)、VERT(双路径验证) | 利用大语言模型(LLM)理解C代码语义,生成符合Rust编码习惯的代码,部分工具结合多路径验证修正偏差 | 生成更贴近Rust原生风格的代码,减少人工后续修改成本 |
二、典型工具实操指南与不足剖析
1. c2rust:基础语法转换工具
c2rust是最基础的C到Rust翻译工具,能快速完成语法层面的转换,但生成的代码安全性较低,需人工进一步优化。
工具使用步骤
- 安装工具:确保本地已安装Rust环境(
rustup),通过Cargo安装c2rust:cargo install c2rust - 执行转换:在命令行中输入以下命令,将C文件(如
input.c)转换为Rust文件(如output.rs):c2rust translate input.c -o output.rs
实际案例演示
- C源码(文件处理功能):
#include <stdio.h> #include <stdlib.h> void process_file(char* filename) { FILE* fp = fopen(filename, "r"); char buffer[256]; while (fgets(buffer, sizeof(buffer), fp)) { printf("%s", buffer); } fclose(fp); } - c2rust翻译结果:
extern "C" { fn fopen(_: *const libc::c_char, _: *const libc::c_char) -> *mut libc::FILE; fn fgets(_: *mut libc::c_char, _: libc::c_int, _: *mut libc::FILE) -> *mut libc::c_char; fn fclose(_: *mut libc::FILE) -> libc::c_int; } unsafe fn process_file(filename: *mut libc::c_char) { let fp = fopen(filename, b"r\0".as_ptr()); let mut buffer = [0; 256]; while !fgets(buffer.as_mut_ptr(), 256, fp).is_null() { libc::printf(b"%s\0".as_ptr(), buffer.as_ptr()); } fclose(fp); }
工具不足
- 安全性极低:生成的代码完全包裹在
unsafe块中,依赖libc库,安全Rust代码占比不足2%,无法利用Rust的内存安全特性。 - 所有权未处理:直接暴露原始指针(如
*mut libc::c_char),未遵循Rust的所有权规则,存在内存泄漏、野指针风险。 - 忽略Rust数据抽象:仍使用C风格的数组(
[0; 256])和指针,未替换为Rust原生的Vec<String>、&str等更安全、易用的数据结构。
2. LAERTES:反馈驱动修复工具
LAERTES需基于c2rust的输出结果工作,通过“编译器诊断-问题修复-编译验证”的循环,将部分不安全代码优化为安全代码,但优化能力有限。
工具使用流程
- 前置步骤:先用c2rust将C源码转换为初始Rust代码(如
unsafe_code.rs)。 - 启动反馈循环:
- LAERTES自动调用Rust编译器(
rustc)对unsafe_code.rs进行诊断,识别可优化的指针(如无别名的原始指针)。 - 将可优化指针替换为Rust的安全引用(
&或&mut),生成临时代码(如temp_safe.rs)。 - 再次用
rustc编译temp_safe.rs,若编译通过则保存结果;若失败则返回“识别可优化指针”步骤,重新调整优化策略。 - 流程示意图:
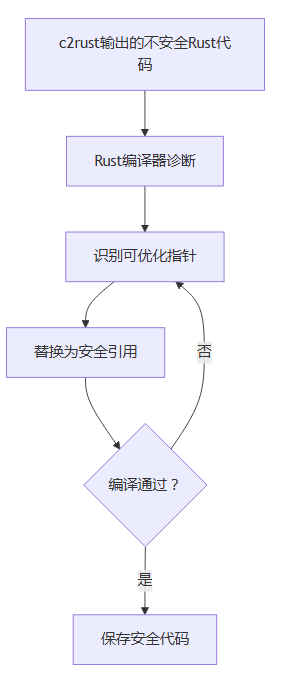
- LAERTES自动调用Rust编译器(
工具不足
- 优化比例低:仅能将11%的原始指针转换为安全引用(数据来源:研究论文表IV),大部分不安全代码仍需人工处理。
- 无法处理复杂指针关系:对跨函数的指针别名(如
static mut全局变量)完全无法优化,会保留原始不安全结构。 - 数据结构优化缺失:仅关注指针安全性,忽略Rust高阶数据类型(如
String、Vec)的替换,生成的代码仍带有浓厚C风格。
3. FLOURINE:LLM驱动的智能翻译工具
FLOURINE基于GPT-4大语言模型,能理解C代码语义并生成更贴近Rust原生风格的代码,但稳定性和兼容性较差。
工具使用步骤
- 输入配置:将C代码片段(或完整文件)输入FLOURINE的交互界面,同时指定翻译需求(如“需使用Rust安全数据结构”“避免不必要的unsafe”)。
- 生成与验证循环:
- LLM生成初始Rust代码,开发者需编写单元测试(如验证函数输入输出一致性)。
- 若测试失败,将错误信息反馈给FLOURINE,LLM根据错误提示修正代码,重复“生成-测试-修正”流程直至代码通过测试。
实际案例演示
- C源码(字符串反转功能):
#include <string.h> void reverse(char* str) { int len = strlen(str); for (int i=0; i<len/2; i++) { char tmp = str[i]; str[i] = str[len-i-1]; str[len-i-1] = tmp; } } - FLOURINE生成结果:
fn reverse(s: &mut String) { let bytes = unsafe { s.as_bytes_mut() }; let len = bytes.len(); for i in 0..len/2 { bytes.swap(i, len-i-1); } }
工具不足
- unsafe滥用:生成的代码存在不必要的
unsafe块,如上述案例中,无需使用unsafe { s.as_bytes_mut() },可通过安全方法s.as_mut_vec()实现相同功能。 - 长代码处理能力差:对超过150行的C程序,翻译成功率低于20%,主要原因是LLM无法处理复杂的函数依赖和代码逻辑,导致分解与合并失败。
- 类型一致性问题:易出现跨函数的类型混用(如
&str与String、Vec<u8>与[u8]),需人工逐一修正。
4. VERT:双路径验证翻译工具
VERT通过“双路径并行翻译+差异测试”的方式提升代码正确性,但当前版本存在严重的兼容性问题,实用性较低。
核心工作原理
- 双路径翻译:
- 路径1:先将C代码转换为WASM(WebAssembly),再从WASM反向生成不安全Rust代码(保证逻辑与C一致)。
- 路径2:利用LLM直接生成安全Rust代码(保证Rust风格)。
- 差异测试:对比两条路径生成的代码在相同输入下的输出结果,若存在差异,分析偏差原因并修正LLM生成的代码。
工具不足
- 依赖独立性假设:假设C代码中的函数和组件可独立翻译,但实际C程序存在复杂的函数调用依赖,导致双路径生成的代码无法整合。
- 编译成功率为0:根据研究论文表IV,所有基准测试程序经VERT翻译后均无法通过Rust编译,核心原因是系统调用(如
libc::isatty)处理失败。 - 适用场景狭窄:仅能处理无外部依赖的简单C代码片段,无法应对工业级C项目(如包含多文件、复杂库依赖的程序)。
三、自动化C到Rust翻译的核心挑战
1. 语义鸿沟:C与Rust的核心模型冲突
C语言基于“指针+手动内存管理”,而Rust基于“所有权+借用检查”,二者语义模型存在根本差异:
- C的原始指针可自由别名(同一内存被多个指针指向)且可修改,而Rust的
AXM(别名异或可变性)规则要求:内存要么可被多个只读引用访问,要么被一个可变引用访问,二者不可同时存在。 - 自动化工具若保留C的指针结构,必然违反Rust规则;若强行转换为Rust引用,又可能破坏C代码的原始逻辑,形成“转换即出错”的困境。
2. 库函数阻抗:API适配复杂度高
C标准库与Rust标准库的函数设计差异极大,39%的C库API无法直接映射到Rust库,需重写为多行Rust表达式:
- 例如C的字符串分割函数
strtok,在Rust中需通过split_whitespace()、split()等方法结合迭代器实现,且需处理空字符串、边界条件等细节,自动化工具难以完整覆盖所有场景。
3. 全局变量困境:安全与兼容性的平衡难题
C程序中大量使用static全局变量,而Rust的static mut全局变量需包裹在unsafe块中,且存在线程安全风险:
- 理想的解决方案是将全局变量重构为局部结构体(策略A),通过函数参数传递状态,但自动化工具无法理解全局变量的跨函数依赖关系,只能保留
static mut,导致代码安全性无法提升。
4. 联合体转化:类型双关的处理瓶颈
C的union(联合体)支持“类型双关”(同一内存区域存储不同类型数据),而Rust不直接支持该特性,需通过特殊API实现:
- 例如C的联合体若存储
int和float,在Rust中需用to_le_bytes()、from_le_bytes()等零成本API转换,但自动化工具无法识别联合体的实际用途,只能保留C风格的union结构,违反Rust的类型安全规则。
四、未来突破方向与实践建议
1. 混合策略:静态分析+LLM协同
- 核心思路:先用LLM识别C代码的业务逻辑和数据结构模式(如“文件读取”“字符串处理”),再用静态分析工具(如CROWN)验证所有权关系,生成安全的Rust代码。
- 优势:LLM负责“语义理解”,静态分析负责“安全验证”,二者互补可提升转换成功率。
2. 策略库建设:构建类型提升规则
- 建立详细的“C类型→Rust类型”提升规则库,例如:
- 当C的
char*指向以\0结尾的字符串时,转换为Rust的&str或String; - 当
char*指向二进制数据时,转换为&[u8]或Vec<u8>; - 通过决策树覆盖不同场景,减少工具的“模糊判断”。
- 当C的
3. 渐进迁移:混合编排除非必要不转换
- 对大型C项目,不追求一次性全量转换,而是通过
bindgen工具生成C与Rust的交互接口,实现二者混编:- 先将核心安全敏感模块(如网络通信、数据解析)手动或半自动化转换为Rust;
- 其余模块仍保留C代码,通过接口调用与Rust模块交互,逐步完成迁移,降低风险。
五、总结
当前自动化C到Rust翻译工具仍处于“辅助工具”阶段,无法实现“一键完美转换”,但可显著降低人工迁移成本:
- 简单C代码片段(<50行):优先使用c2rust+LAERTES,快速生成基础代码后人工优化不安全部分;
- 复杂业务逻辑代码:优先使用FLOURINE,结合单元测试修正LLM生成的错误,提升代码风格一致性;
- 工业级项目:采用“渐进迁移”策略,结合
bindgen混编,逐步用Rust替代核心模块。
未来工具的核心突破点在于“语义理解能力”——只有真正理解C代码的业务逻辑,才能在保留功能正确性的前提下,生成符合Rust安全模型的代码,实现从“语法转换”到“语义迁移”的跨越。