ultralytics导出engine之后,用tensorrt c++ api加载报Serialization failed
一。问题复现
1.生成engine
在安装了ultralytics之后,或者直接用源码也一样。运行如下代码
(或者用命令行也行:yolo task=detect mode=export model=/home/kv183/tensorrt_starter/ultralytics-main/weights/yolov8s.pt format=engine )
from ultralytics import YOLO
if __name__ == '__main__':
# Load a pretrained YOLO11n model
model = YOLO("/home/kv183/tensorrt_starter/ultralytics-main/weights/yolov8s.pt")
print(model.export(format='engine'))
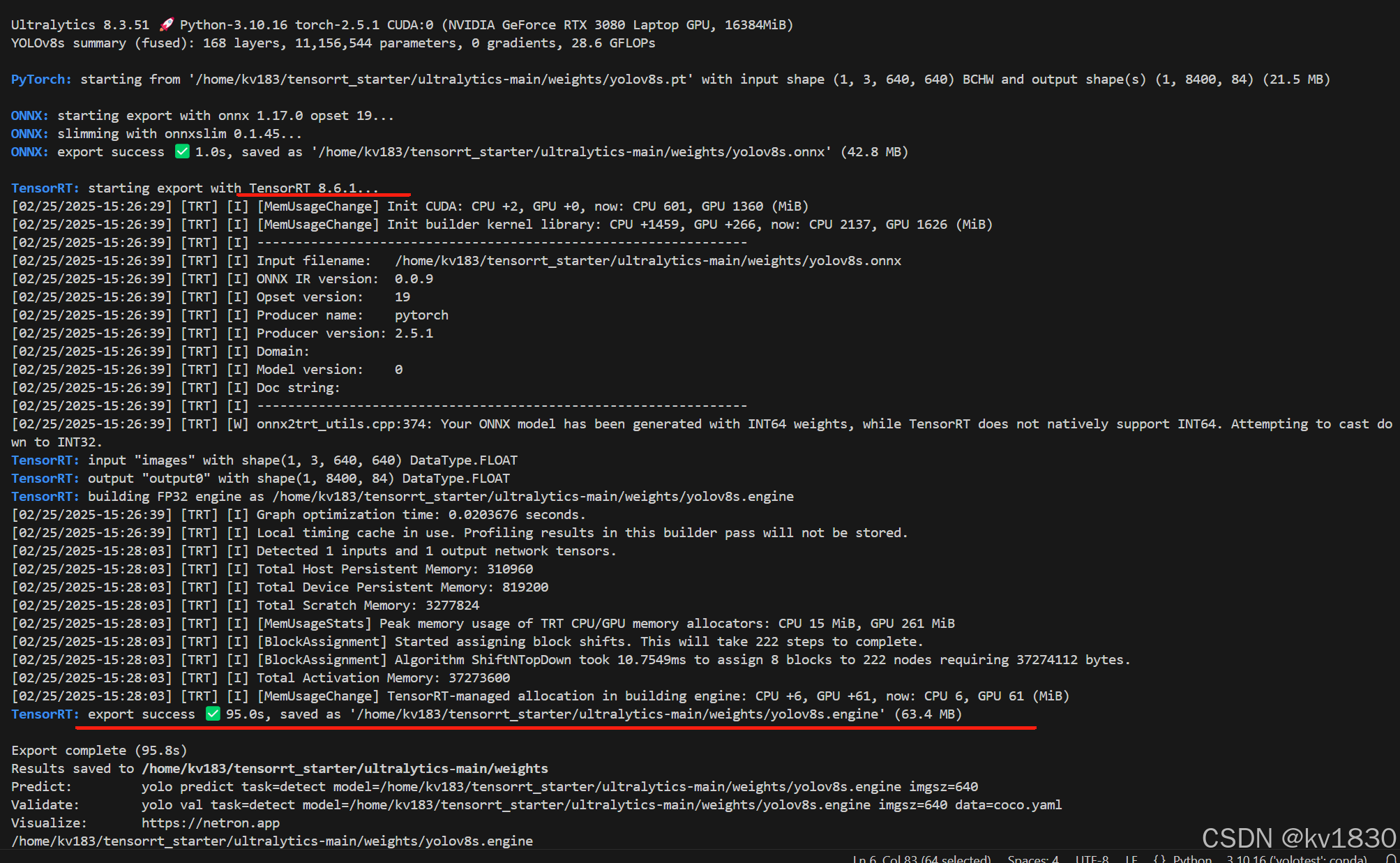
注意,我在python环境中安装的tensorrt是8.6.1,跟我c++工程所用的tensorrt版本保持一致,其实这个python的tensorrt就是在从英伟达下载的tensorrt8.6.1的python目录中找到的wheel包。
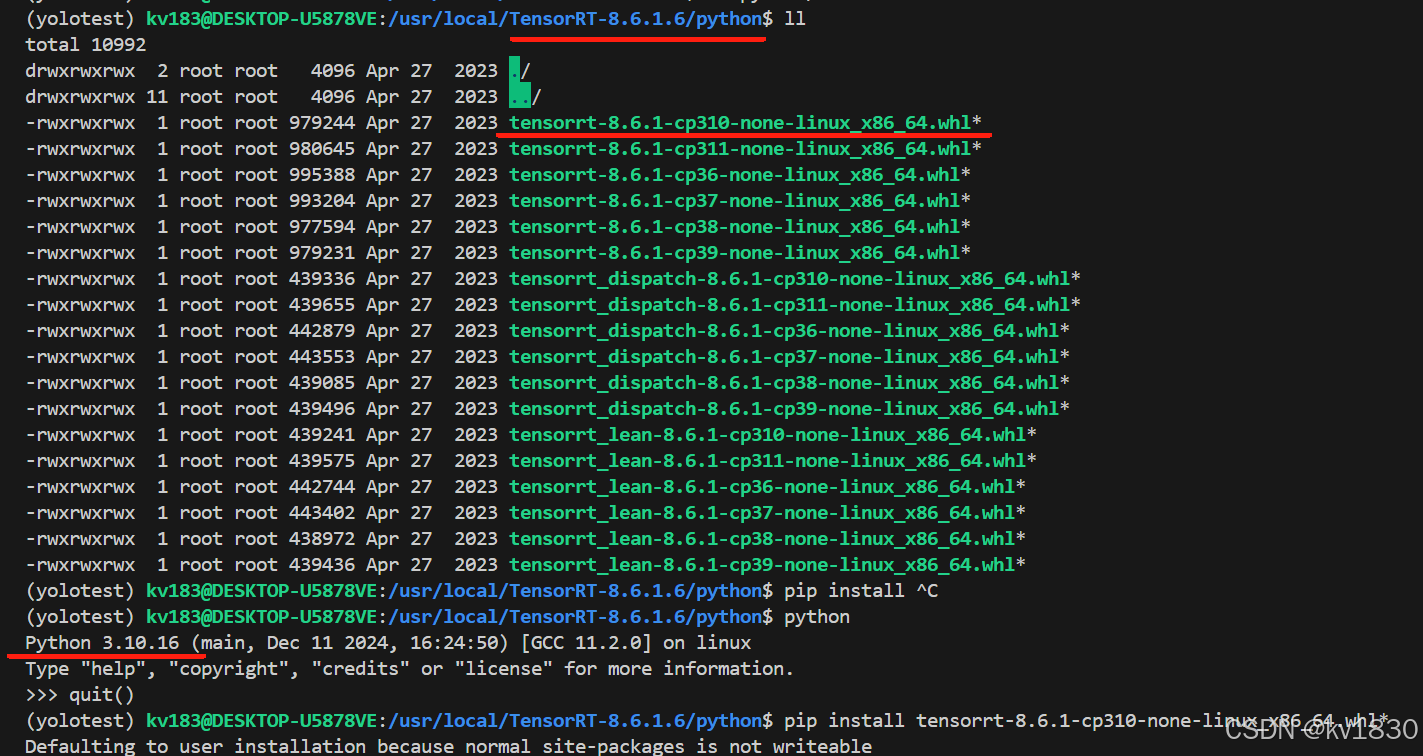
另外说一下,这个python目录里的tensorrt_lean, tensorrt_dispatch是在考虑版本兼容、轻量化的时候才需要用到的, 如果不涉及就没必要用它们。
2.用tensorrt c++ api进行推理
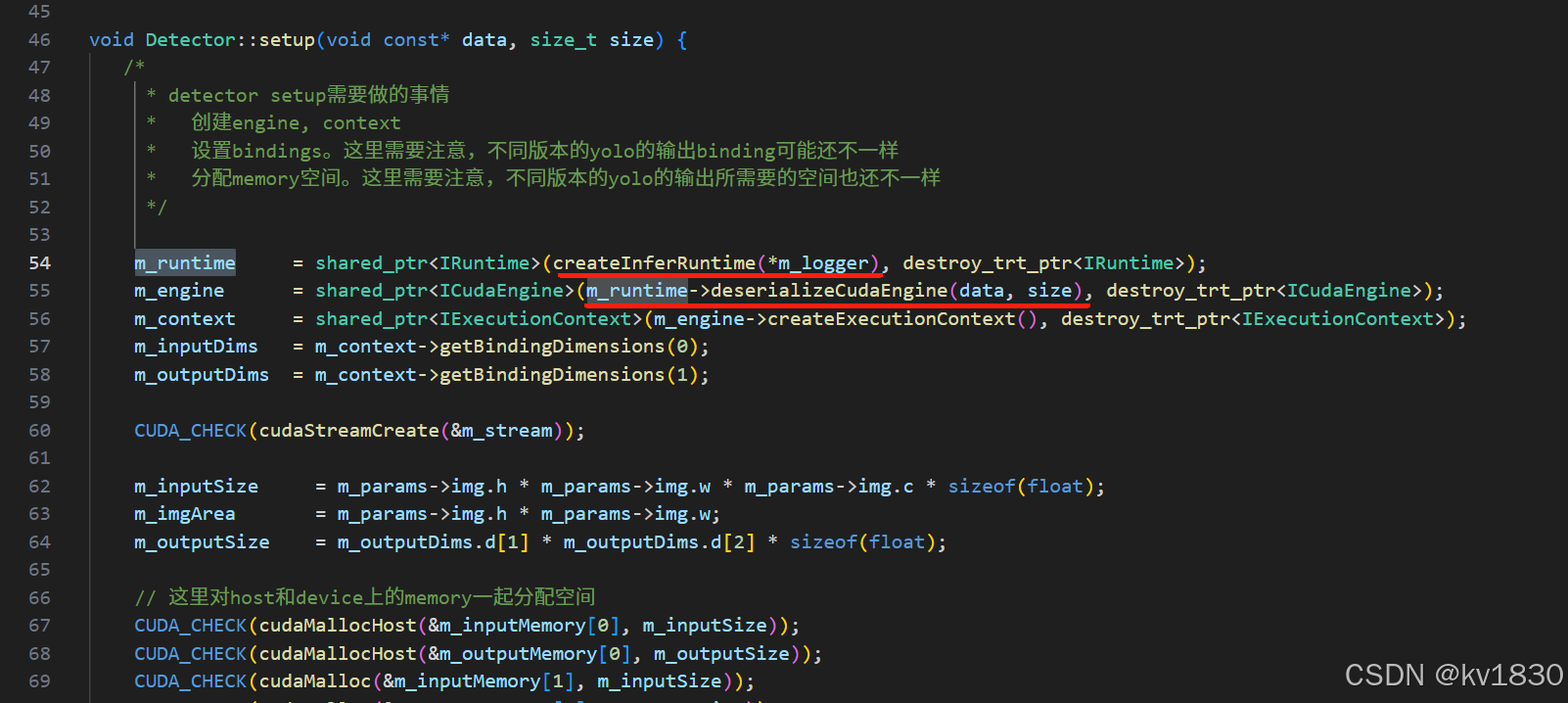
本文并不详细讲解怎么用tensorrt c++ api进行推理,主要就是解决ultralytics导出engine的问题,所以就不详细讲相关代码了。其实问题就出在反序列化engine这一步,运行到第55行就会失败了,那个data就是engine文件的内容(用二进制模式读取文件内容)
报错如下:
[error]1: [runtime.cpp::parsePlan::314] Error Code 1: Serialization (Serialization assertion plan->header.magicTag == rt::kPLAN_MAGIC_TAG failed.)

二。问题分析
1.兼容性问题
就这个报错本身来说,多半是兼容性问题,比如你生成engine用的tensorrt版本是A,它会在engine文件中写一个magicTag,但你推理的时候用的tensorrt版本是B,它在反序列化engine的时候发现文件中的magicTag与当前版本的不一致,就会报上面的错误并退出程序。
兼容性问题包括:tensorrt版本、系统(windows、linux)、gpu,具体可以看tensorrt文档
但我这里明显不会有兼容性问题,首先是在同一台电脑上,在wsl ubuntu中,c++用tensorrt8.6.1,python用的tensorrt也是相同版本。
2.文件格式问题
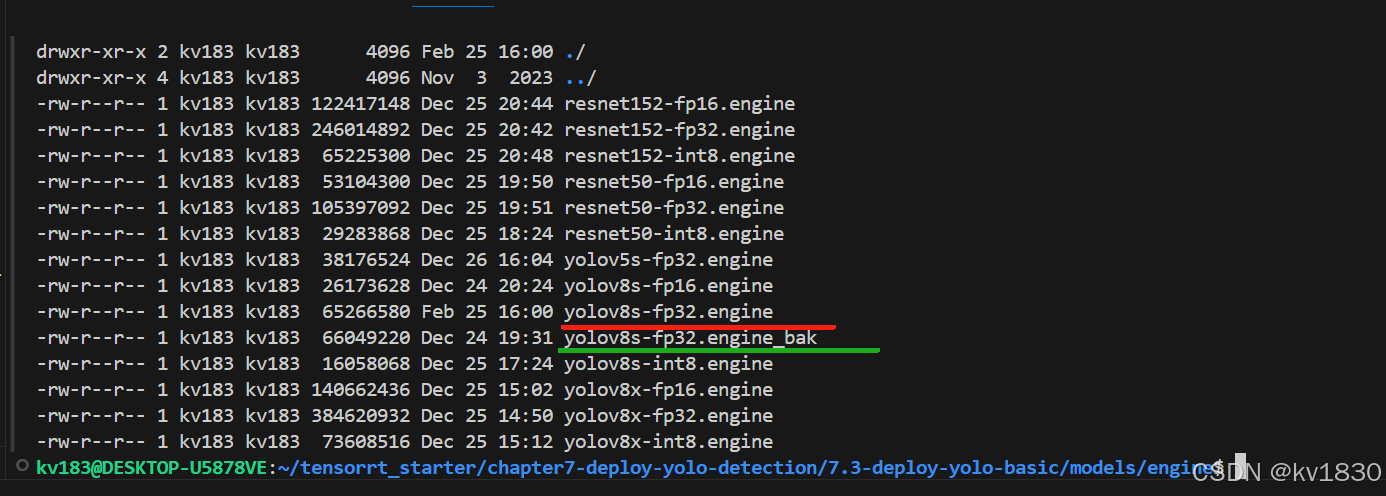
在c++项目中,yolov8s我有两个engine文件,绿色的是直接调tensorrt api,解析onnx然后生成的engine(其实跟用tensorrt提供的trtexec差不多,trtexec本身也是调tensorrt api的),而红色的就是用ultralytics生成的engine。
用vi看一下绿色的文件内容,开头可以看到ftrt几个字母,其实这叫魔数(Magic Number),它就是代表这个文件的格式,表明它是engine文件。很多文件都有魔数,比如zip文件是PK,pdf文件是%PDF。

接着用vi看一下红色的文件内容(即用ultralytics生成的engine)
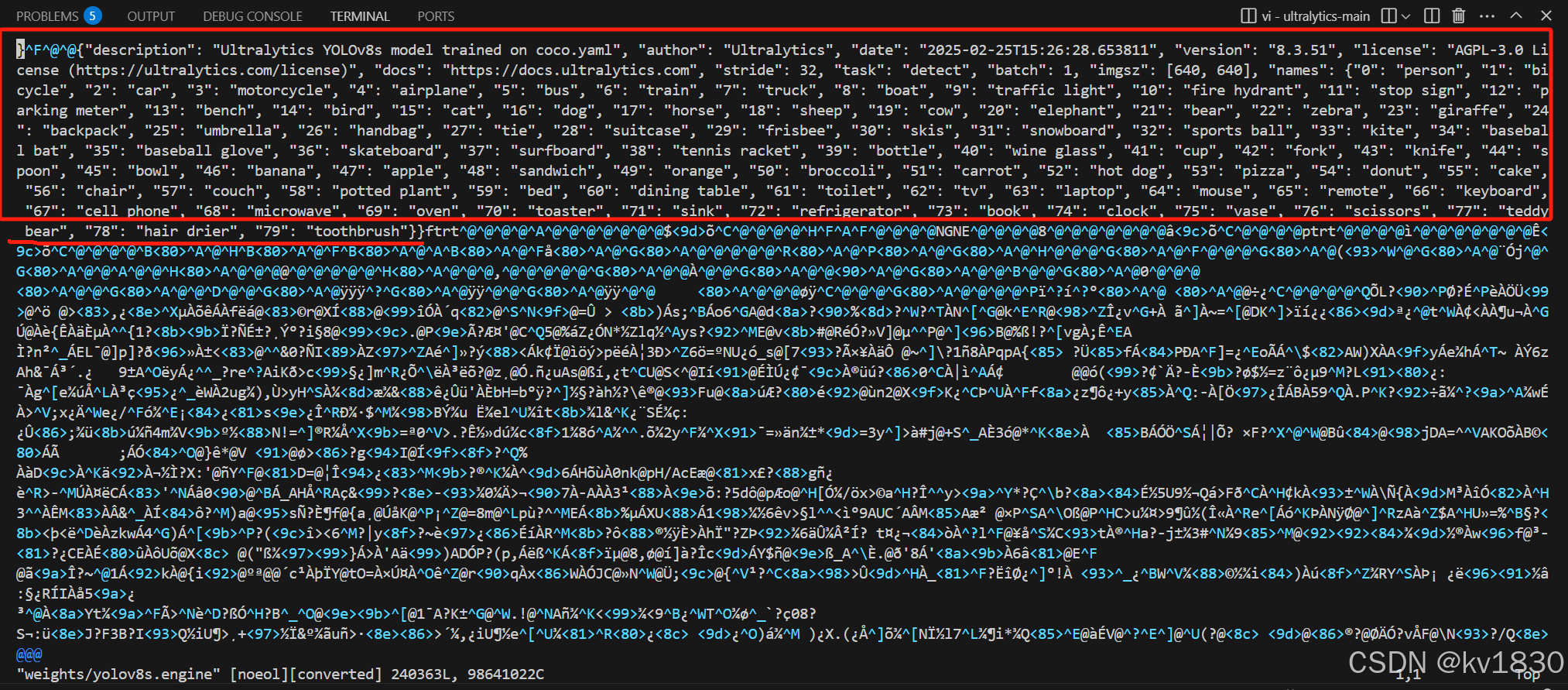 会发现在ftrt前面多了一些东西,这像是ultralytics自己写的一些元数据。
会发现在ftrt前面多了一些东西,这像是ultralytics自己写的一些元数据。
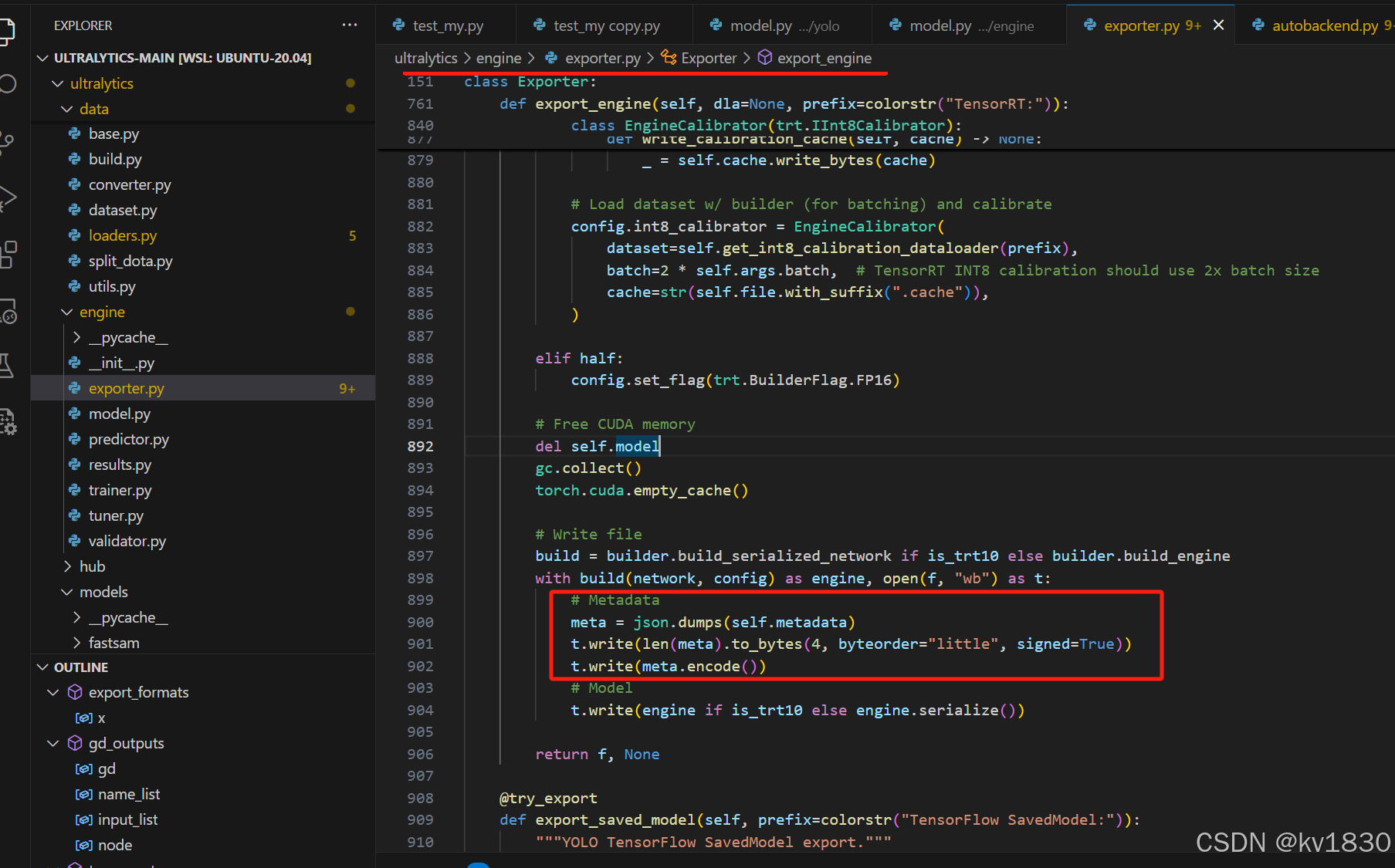
直接去看一下它导出engine文件的代码,如上图,确实在engine文件的开头加入了一些元数据。tensorrt当然是不支持这种操作的,其实这些元数据是ultralytics在加载engine文件进行推理的时候用的,比如输入shape、分类信息。
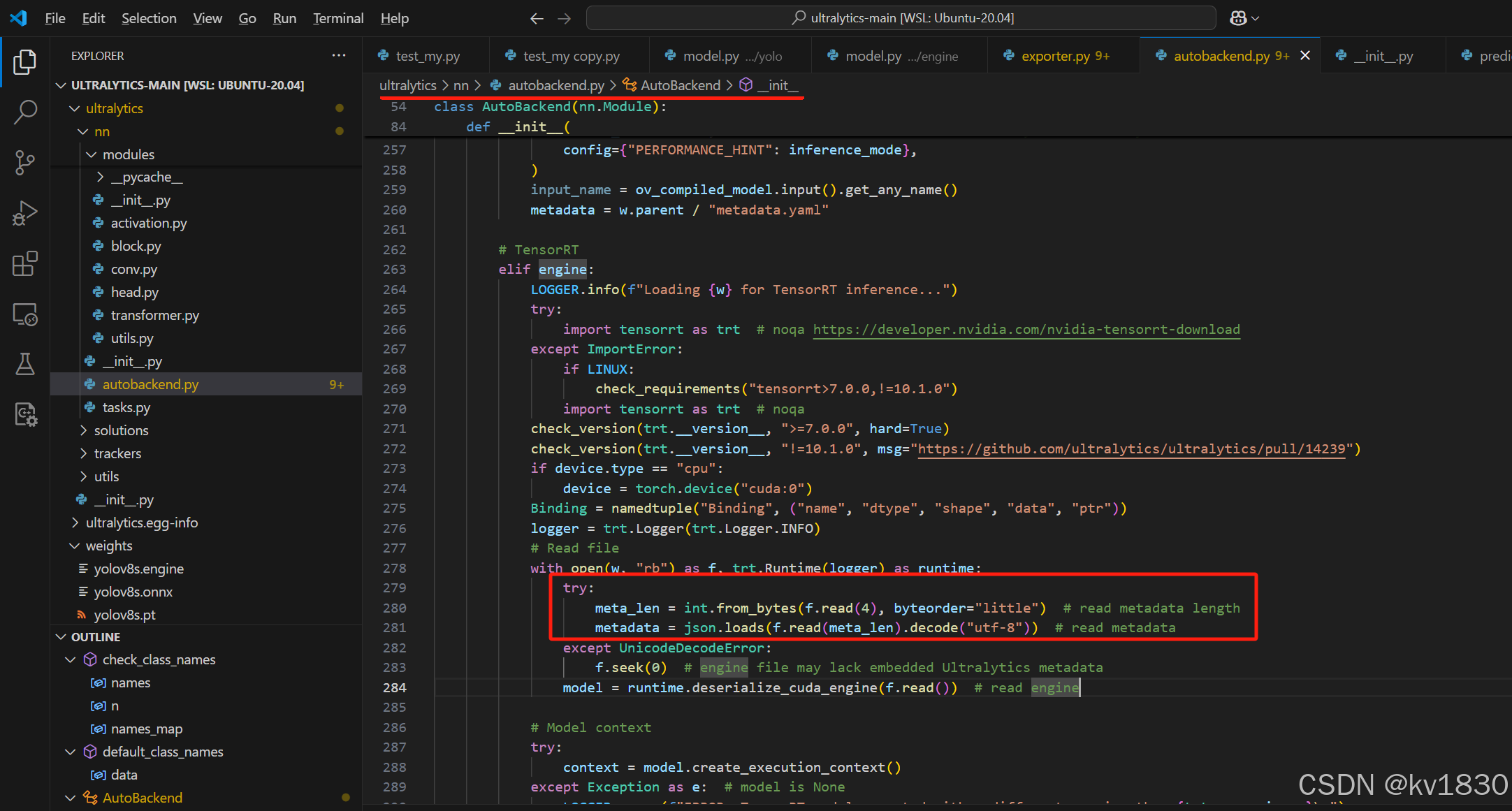
上图就是ultralytics在加载engine时,会尝试加载元数据。
现在已经很明确了,解决这个问题的办法无非下面几个:
(1)不用ultralytics生成engine,只用它导出onnx文件,然后用trtexec解析onnx生成engine,或者自己直接调tensorrt api解析onnx生成engine。
(2)如果想在c++项目中使用ultralytics生成的engine,则
a)把ultralytics写元数据那几行代码注释掉,如下
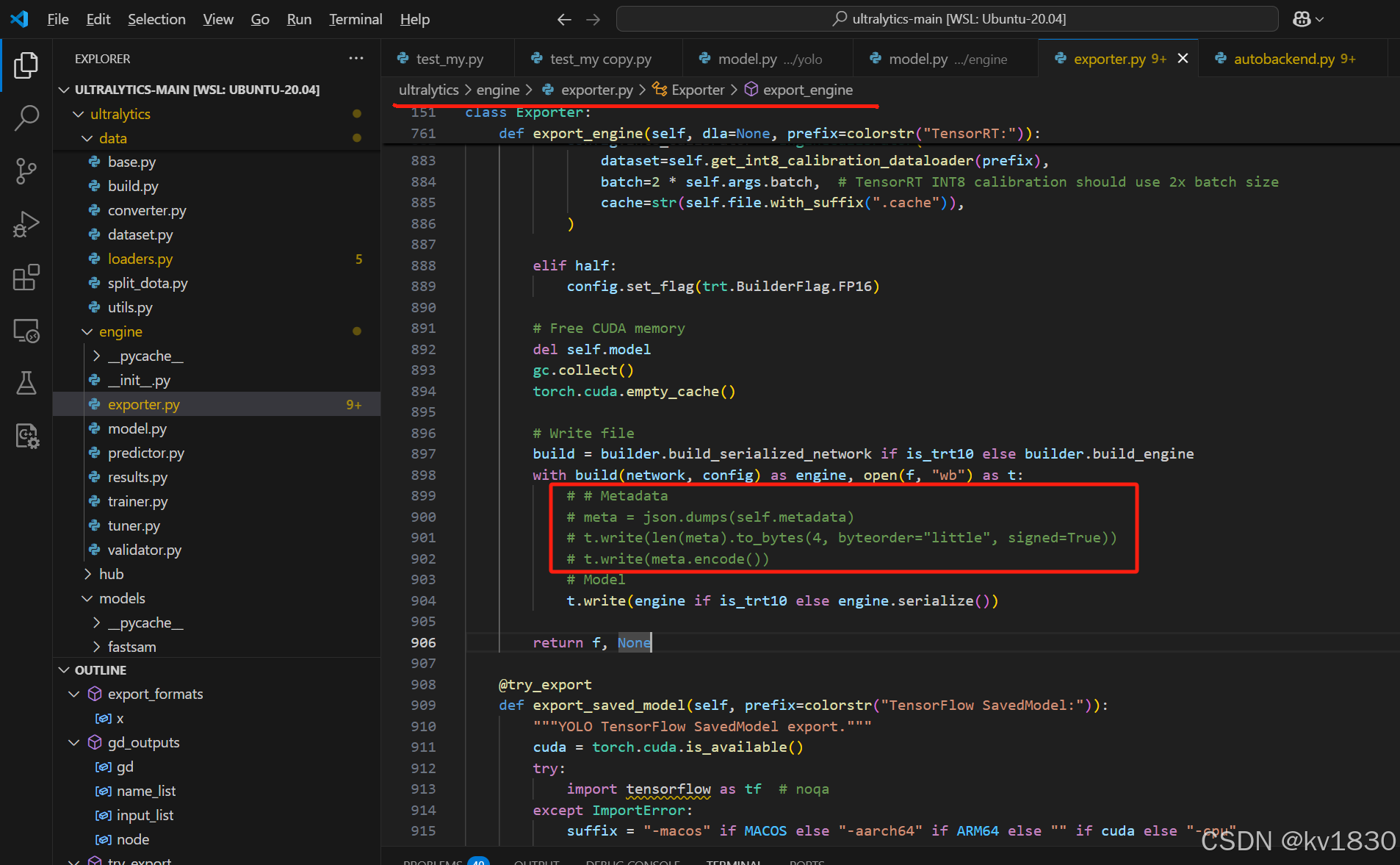
b)如果不想改ultralytics的代码,则在c++项目中读取engine文件内容的时候, 跳过开头的元数据
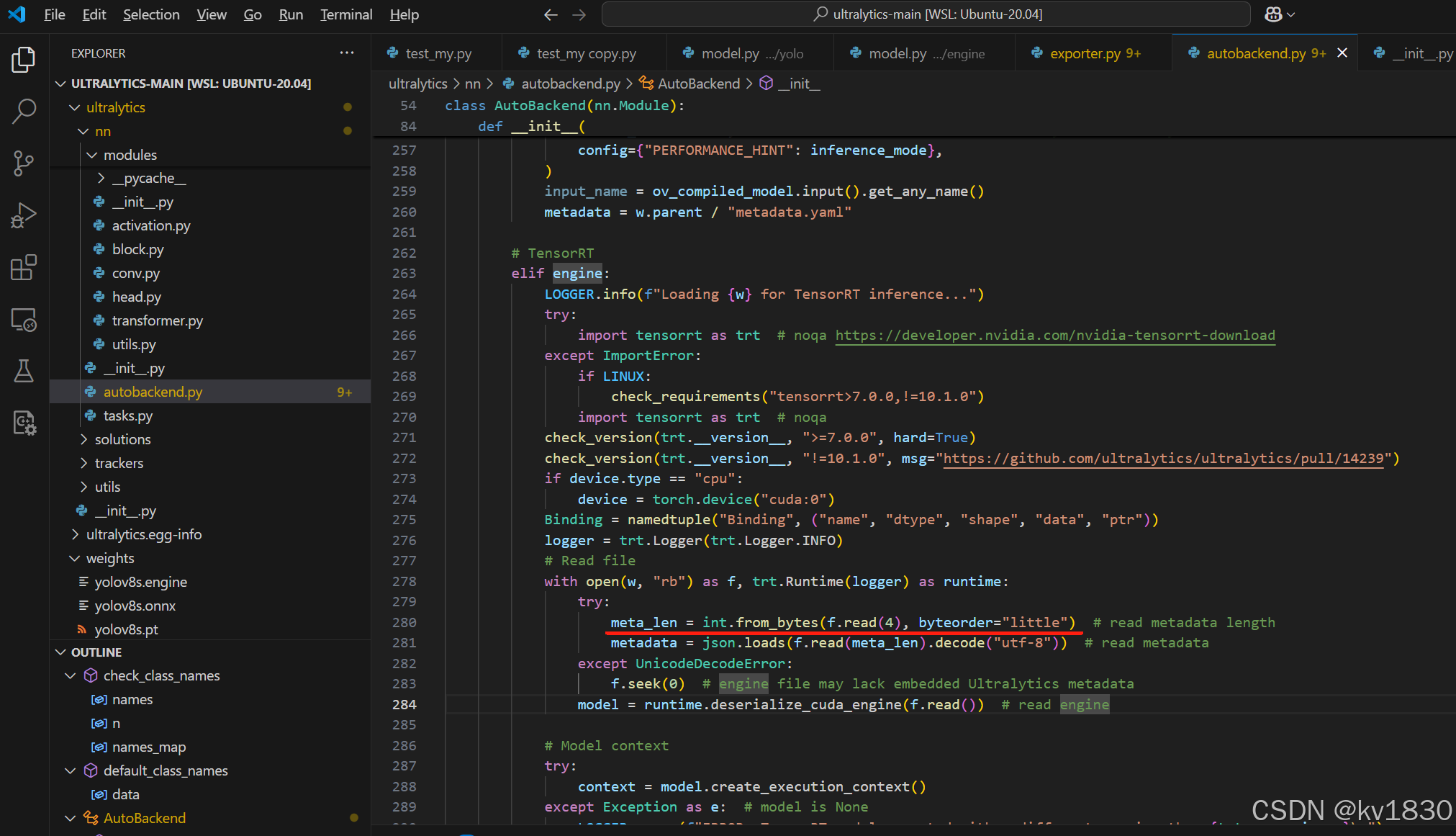
再参考一下ultralytics加载engine的代码如上图,元数据的长度不是固定的,但是它开头的4个字节就是代表了元数据的长度。即ultralytics生成的engine文件的内容是:4字节的整型数+元数据+真正的engine内容。
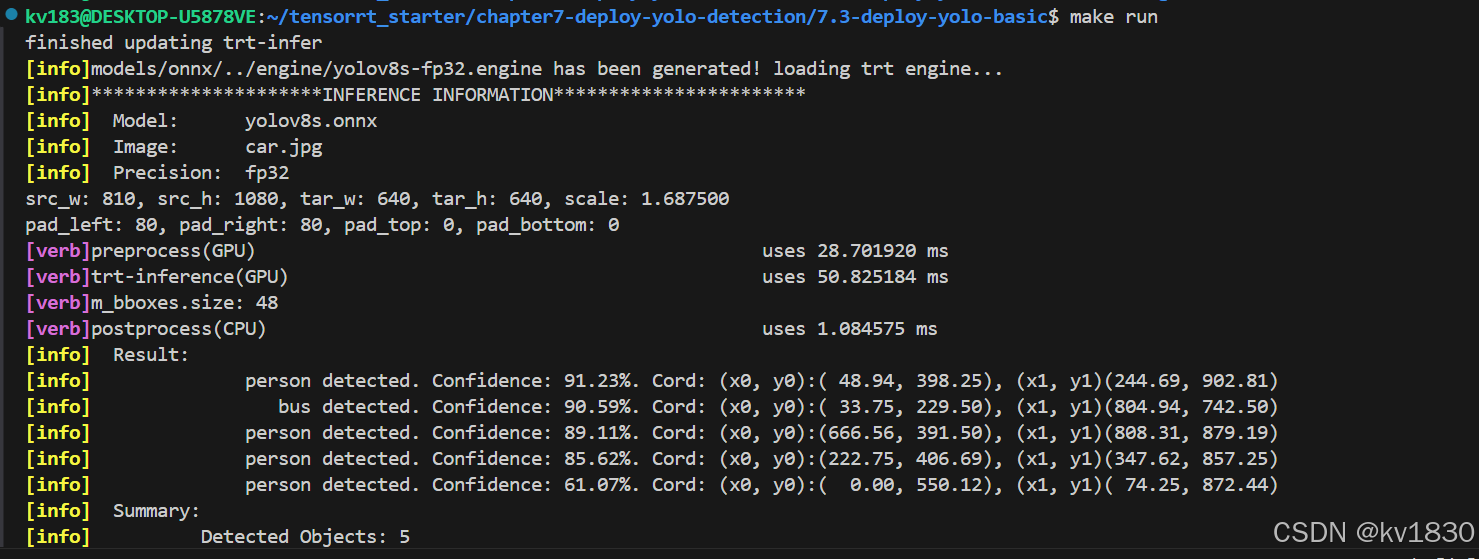
接下来验证一下,采用方案(2)-a),即注释ultralytics中生成元数据的代码,重新生成engine,通过c++项目加载engine,成功推理如下: