(Arxiv-2025)重构对齐提升了统一多模态模型的性能
重构对齐提升了统一多模态模型的性能
paper title:RECONSTRUCTION ALIGNMENT IMPROVES UNIFIED
MULTIMODAL MODELS
paper是UC Berkeley 发布在Arxiv 2025的工作
Code:链接
ABSTRACT
统一多模态模型(UMMs)在单一架构中统一了视觉理解与生成。然而,传统的训练依赖于图文对(或序列),这些图像的文字描述通常较为稀疏,缺乏细粒度的视觉细节——即便描述一个简单图像时使用了数百字。我们提出了一种资源高效的后训练方法——重构对齐(Reconstruction Alignment,简称 RecA),它利用视觉理解编码器的嵌入作为密集的“文本提示”,在无需文字描述的情况下提供丰富的监督。具体而言,RecA 将统一多模态模型(UMM)以其自身的视觉理解嵌入为条件,优化模型去重构输入图像,通过自监督的重构损失来实现理解与生成的重新对齐。尽管方法简单,RecA 具有广泛适用性:无论是自回归、掩码自回归,还是基于扩散的 UMMs,RecA 都能稳定提升生成与编辑的保真度。仅需 27 个 GPU 小时的后训练,RecA 就显著提升了图像生成的性能,在 GenEval 上从 0.73→0.900.73 \rightarrow 0.900.73→0.90,在 DPGBench 上从 80.93→88.1580.93 \rightarrow 88.1580.93→88.15,同时也提升了图像编辑基准(ImgEdit 从 3.38→3.753.38 \rightarrow 3.753.38→3.75,GEdit 从 6.94→7.256.94 \rightarrow 7.256.94→7.25)。值得注意的是,RecA 超越了更大规模的开源模型,并能广泛应用于各种不同架构的 UMMs,确立了其作为一种高效通用的 UMM 后训练对齐策略的地位。
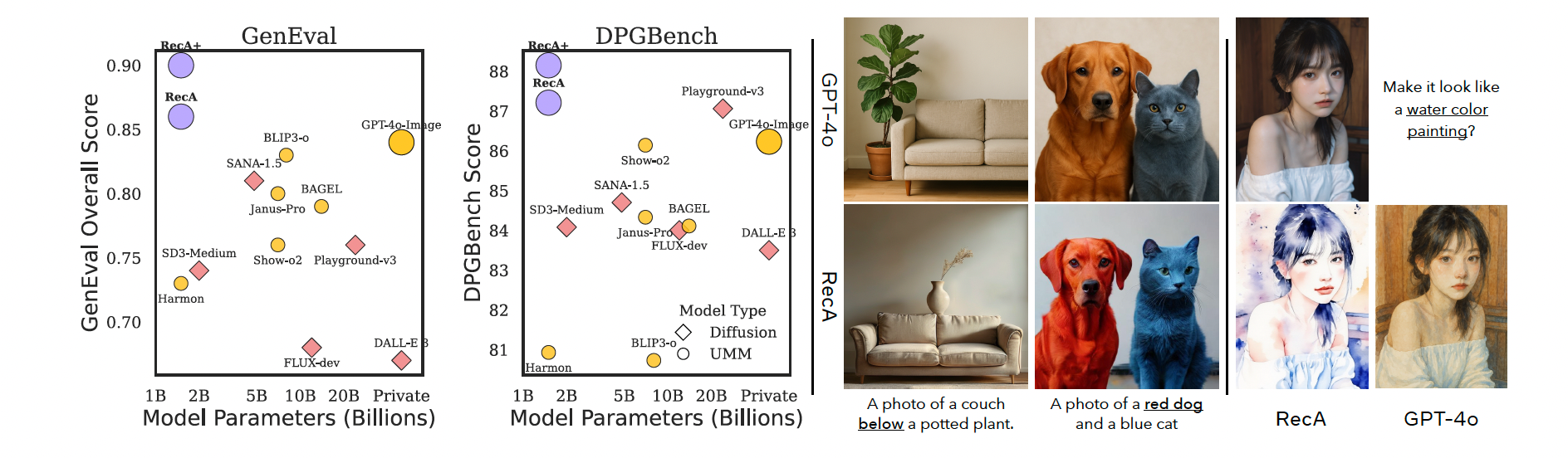
图1:使用重构对齐(即 RecA)对统一多模态模型(UMMs)进行后训练,可显著提升图像生成与编辑性能。左图:在 GenEval 与 DPGBench 基准上的性能对比中,一个经过 RecA 后训练的 15 亿参数模型在多个基准上(表1:GenEval、DPGBench 与 Wise;表3:ImgEdit 与 GEdit-Bench-EN)超越了规模更大的模型。中图:与 GPT-4o 相比,RecA 在图像生成中更忠实地遵循指令,尤其是在颜色属性与空间位置方面。右图:在图像编辑任务中,RecA 更好地保留了原始图像中的实例身份、整体布局与物体形状,例如女孩的嘴唇。
1 INTRODUCTION
在大语言模型(LLMs)(Brown et al., 2020;Touvron et al., 2023;Yang et al., 2024a)取得成功的基础上,研究者们开发了多模态大语言模型(MLLMs)(Liu et al., 2024b;Bai et al., 2023;2025;Radford et al., 2021;Zhai et al., 2023;Chen et al., 2024;Zhu et al., 2025),在视觉理解方面表现出色。近年来,统一多模态模型(Unified Multimodal Models,UMMs),又称全能模型(Omni Models),被提出以实现在单一架构中同时进行跨模态的理解与生成——即在同一模型中读取和生成视觉内容与文本(Team, 2024;Zhou et al., 2025;Tong et al., 2024;Ge et al., 2024;Wu et al., 2024b;Chen et al., 2025c;Pan et al., 2025a;OpenAI, 2024;Li et al., 2025)。学术界设想,这种统一框架可以继承 LLMs 的推理与世界知识,并将其扩展到内容生成领域。
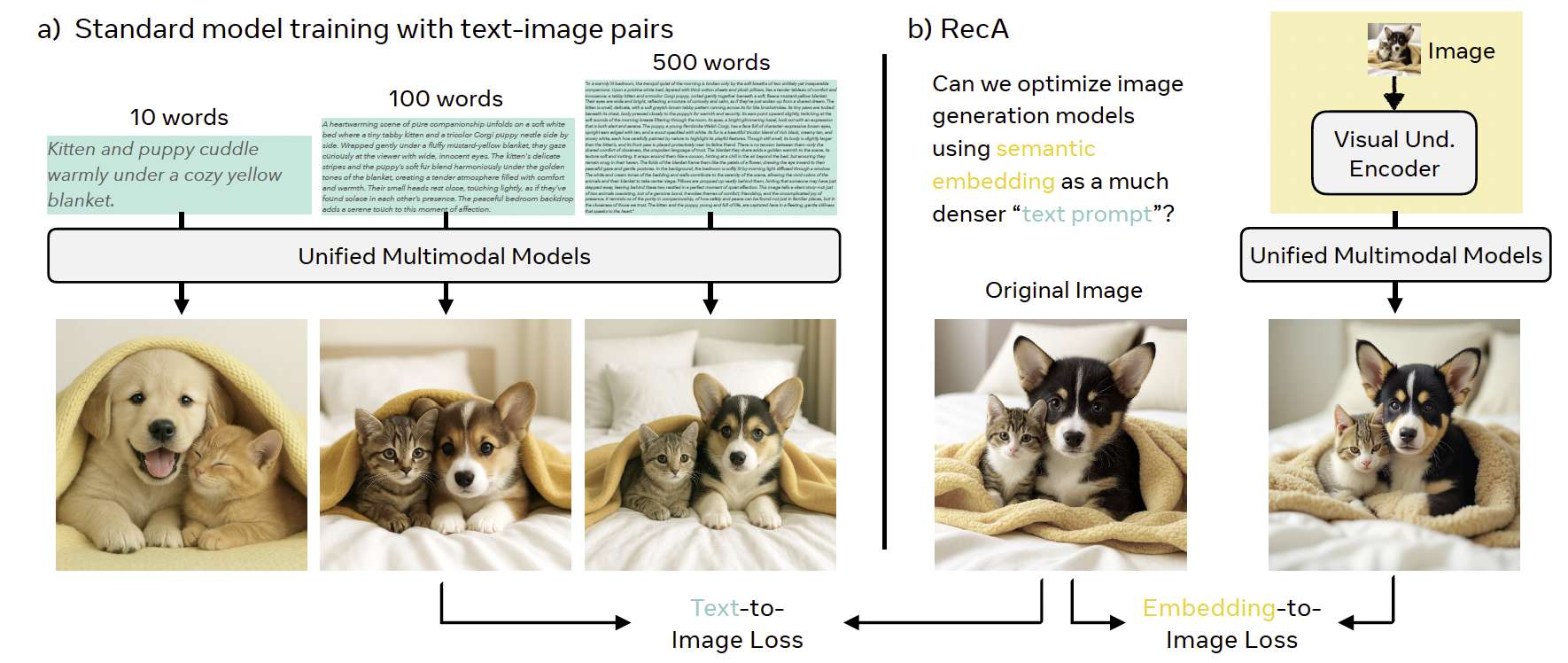
图2:来自视觉嵌入的密集监督。a)典型的图像生成模型通常在图像–标题对和/或序列上训练,而这些文本只是视觉信息的稀疏表示。一图胜千言,图像中蕴含的细节远超文字所能描述。如左侧三个示例所示,即使是长达500字的标题,也常常遗漏诸如纹理、风格、布局、形状与属性等关键要素,导致生成图像相较于原始图像存在缺陷。b)相比之下,来自视觉理解编码器(如 CLIP)的嵌入保留了更丰富、更忠实的语义信息。那么,这些图像–嵌入对是否能提供增强图像生成与编辑所需的密集监督?令人惊讶的是,答案是肯定的:我们发现图像–嵌入对可以在零样本条件下提升文本生成图像(T2I)与图像编辑的性能。
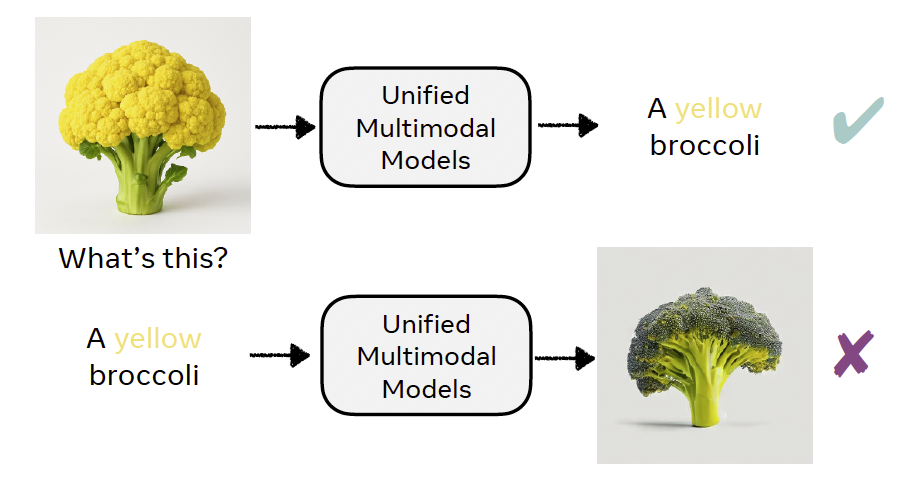
图3:统一多模态模型(UMMs)常常能够正确识别非常见概念(如黄色西兰花),但在生成时却失败,暴露出理解与生成之间的对齐偏差。
然而,UMMs 面临一个根本性限制:传统训练依赖图文对,其中的图像标题作为监督信号。即使是数百字的描述,也常常忽略关键视觉细节,如空间布局、几何结构或细粒度属性(见图2),从而在模型中引入系统性偏差。例如,由于标题很少描述西兰花的颜色,模型往往过拟合于规则“broccoli → green”,在遇到如“a yellow broccoli”这类非典型提示时容易生成绿色结果或失败(见图3)。这种理解与生成之间的不一致促使我们探索替代监督形式。我们不依赖图像标题,而是利用视觉理解编码器的嵌入(Radford et al., 2021;Zhai et al., 2023;Chen et al., 2024;Zhu et al., 2025),这些编码器将像素映射到统一多模态模型可解释的语言对齐语义空间。关键在于,理解型编码器(如 CLIP、SigLIP)的嵌入比生成型编码器(如 VAE、VQ-GAN)更有效地捕捉语义结构。这些语义嵌入无需配对标题即可提供密集、语义对齐的监督,提出了一个核心问题:
我们是否可以通过使用语义嵌入作为最信息丰富的“文本提示”来提升UMM的生成能力?我们是否可以通过使用语义嵌入作为最信息丰富的“文本提示”来提升 UMM 的生成能力? 我们是否可以通过使用语义嵌入作为最信息丰富的“文本提示”来提升UMM的生成能力?
基于这一洞察,我们提出了 RecA——一种资源高效的后训练策略。其核心思想很简单:以 UMM 自身的视觉理解编码器嵌入作为条件,即作为编码了布局、颜色和属性的密集“视觉提示”,并训练模型去重构图像。该语义重构过程无需额外标签即可提供更丰富的监督。尽管方法简单,RecA 带来了显著提升。仅使用 27 个 A100 GPU 小时,一个拥有 15 亿参数的 UMM 经 RecA 后训练便超过了 GPT-4o 以及明显更大的开源模型,在 GenEval 和 DPGBench 上分别达到了 0.860.860.86 和 87.2187.2187.21 的表现。重要的是,这些提升并未使用任何 GPT-4o 图像蒸馏数据或强化学习(OpenAI, 2024;Chen et al., 2025a;b),与以往方法形成鲜明对比。此外,当引入 GPT-4o 数据进行后训练时,RecA 表现进一步提升至 GenEval 0.900.900.90 和 DPGBench 88.1588.1588.15,大幅超越使用更大模型规模的现有方法。RecA 同样提升了图像编辑质量,将 ImgEdit 从 3.38→3.753.38 \rightarrow 3.753.38→3.75,GEdit 从 6.94→7.256.94 \rightarrow 7.256.94→7.25。更重要的是,RecA 能广泛适用于各类 UMM 家族,包括:
- Show-o(Xie et al., 2025b)(AR)
- Harmon(Wu et al., 2025c)(AR+MAR)
- OpenUni(Wu et al., 2025b)(AR+Diffusion)
- BAGEL(Deng et al., 2025)(AR+Diffusion)
凸显了其通用性。
关键贡献总结如下:
-
方法:我们提出 RecA,一种基于语义重构的后训练方法,使用语义视觉嵌入作为“密集提示”,在无标题情况下提供丰富监督。
-
通用性:我们展示 RecA 能一致提升多种不同架构的 UMM,从自回归模型到混合框架。
-
性能:我们验证了强大的实际效果,仅用 27 个 A100 GPU 小时的 15 亿参数模型便超越 GPT-4o 及更大模型,在未使用蒸馏或强化学习的前提下,显著超越现有方法。
2 RECONSTRUCTION ALIGNMENT
在本节中,我们提出了重构对齐(Reconstruction Alignment,RecA)作为一种自监督图像重构目标。通过训练模型根据其视觉理解编码器嵌入重构图像,RecA 提供了密集的监督,捕捉了文本标题中常被忽略的细粒度视觉细节。我们在图4中展示了整体流程。
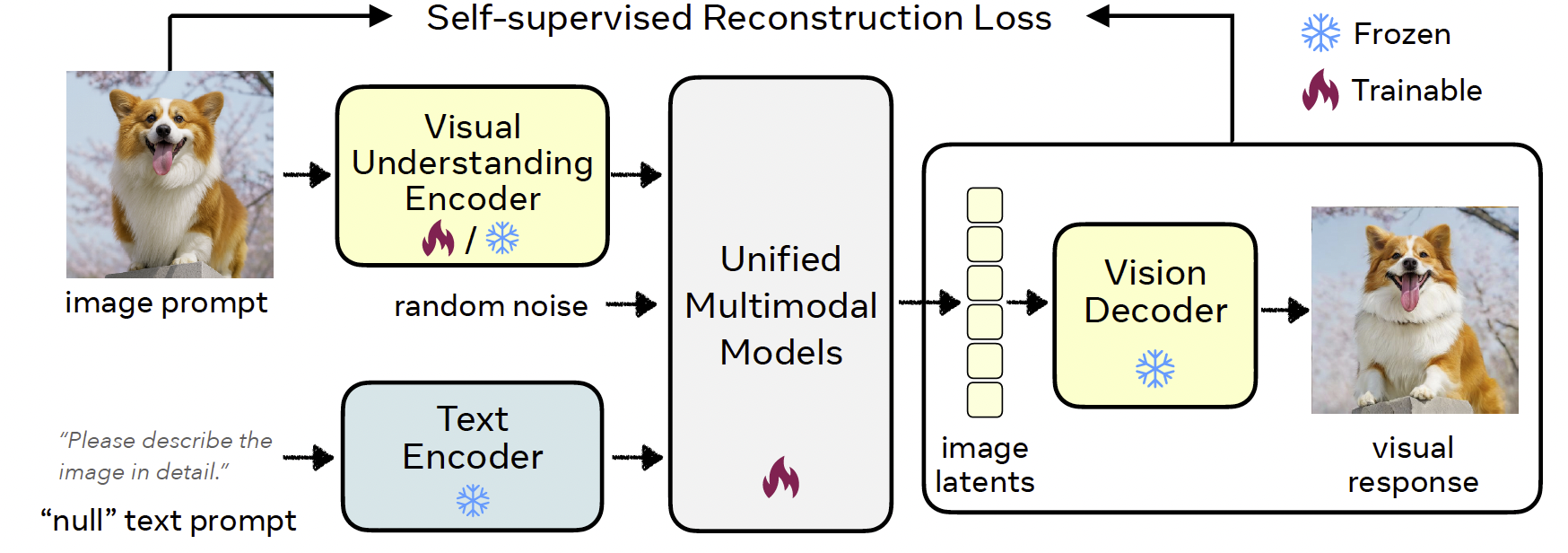
图4:语义重构对齐(RecA)流程概览。一个视觉理解编码器(如 CLIP 或 DINO)从输入图像中提取语义特征,这些特征与模板文本嵌入融合后传入统一多模态模型(UMM),用于重新生成图像。UMM 通过自监督损失(扩散损失或交叉熵损失)在原始图像与重构图像或其隐变量之间进行优化。在推理阶段,RecA 无需额外输入,作为一个标准的 UMM 运作。
2.1 MOTIVATION AND SETUP
由于视觉理解编码器将图像特征投射到一个与语言对齐的语义空间中,一个真正“统一”的视觉理解与生成模型应能够利用这种密集且丰富的语义信息来生成原始图像。为验证这一点,我们从视觉理解编码器中提取语义嵌入,将其插入到提示模板中(例如:“Describe the image in detail.”),并要求 UMM 重新生成输入图像。

图5:通过 RecA 后训练可恢复超越基线模型的视觉细节。对于每张查询图像(左),我们将其视觉理解嵌入与指令 “Describe the image in detail.” 一同输入回 UMM。基线模型(中)生成的视觉响应(即图像)虽然保留了主要物体,但在布局、纹理和颜色上出现扭曲;而 RecA 显著恢复了几何结构、颜色以及整体保真度等视觉细节。
如图5所示,结果具有启示性:当前的 UMMs 虽能保留主要物体,但在空间布局与构图上表现混乱。这表明,在传统范式下训练的 UMMs 未能充分利用模型的细粒度语义信息,即理解与生成所处的潜在空间仍然只有部分对齐。
2.2 RECA TRAINING PARADIGM
训练损失。传统的 UMMs 通过结合文本生成图像(T2I)和图像生成文本(I2T)目标进行训练。形式化地:
Lt2i=L(fθ(tprompt),Igt),Li2t=L(fθ(concat(tquestion,hv)),tanswer)(1)\mathcal{L}_{t2i} = \mathcal{L}(f_{\theta}(t_{prompt}), I_{gt}), \quad \mathcal{L}_{i2t} = \mathcal{L}(f_{\theta}(\text{concat}(t_{question}, h_v)), t_{answer}) \tag{1} Lt2i=L(fθ(tprompt),Igt),Li2t=L(fθ(concat(tquestion,hv)),tanswer)(1)
其中,L(⋅,⋅)\mathcal{L}(\cdot,\cdot)L(⋅,⋅) 表示训练损失(例如,自回归模型的交叉熵损失(Xie et al., 2025b; Chen et al., 2025d),基于扩散模型的扩散损失(Zhou et al., 2025; Deng et al., 2025)),tprompt,tquestion,tanswert_{prompt}, t_{question}, t_{answer}tprompt,tquestion,tanswer 是文本输入/输出,hvh_vhv 是由视觉理解编码器提取的嵌入,IgtI_{gt}Igt 是真实图像(为简化起见,我们省略了显式的 VAE 解码器符号)。fθ(⋅)f_{\theta}(\cdot)fθ(⋅) 表示 UMM 的参数 θ\thetaθ。
我们的关键思想是用图像重构损失替代传统的 T2I 监督。不同于使用在视觉信息上稀疏的文本标题,我们让 UMM 依赖于其自身的视觉理解嵌入,这些嵌入提供了更丰富的语义信息。重构损失定义为:
LRecA=L(fθ(concat(ttemplate,hv)),Igt)(2)\mathcal{L}_{RecA} = \mathcal{L}(f_{\theta}(\text{concat}(t_{template}, h_v)), I_{gt}) \tag{2} LRecA=L(fθ(concat(ttemplate,hv)),Igt)(2)
其中 ttemplatet_{template}ttemplate 是一个简单的提示模板,用于触发图像重构。总体训练目标可表述为:
Ltotal=λRecALRecA+λi2tLi2t+λt2iLt2i.(3)\mathcal{L}_{total} = \lambda_{RecA}\mathcal{L}_{RecA} + \lambda_{i2t}\mathcal{L}_{i2t} + \lambda_{t2i}\mathcal{L}_{t2i}. \tag{3} Ltotal=λRecALRecA+λi2tLi2t+λt2iLt2i.(3)
在实验中,我们设置 λRecA=1\lambda_{RecA} = 1λRecA=1 且 λt2i=0\lambda_{t2i} = 0λt2i=0。对于共享理解和生成参数的 UMMs,我们设置 λi2t=1\lambda_{i2t} = 1λi2t=1,以此保持图像到文本的理解。对于视觉编码器输入,图像会被调整到编码器可接受的最低分辨率。
模型推理。在推理阶段,我们经过后训练的 UMM 与标准 UMM 的运行方式完全一致,不需要额外的视觉嵌入。对于图像生成,只需输入文本提示;对于图像编辑,输入依然是文本提示与原始图像。这样既保留了模型的原始可用性,又提供了增强的生成能力。
2.3 DIFFERENCE BETWEEN RE CA AND PREVIOUS WORKS
RecA 将语义级别的图像重构引入为 UMMs 的原生后训练目标,直接利用视觉理解先验来提升生成与编辑能力,而无需辅助模块或图文监督。相比之下,以往的工作以不同方式引入重构:
(I) 基于扩散监督的增强(如 DIVA, ViLex)(Wang et al., 2024b; 2025c; Ma et al., 2025a),利用预训练的扩散模型对视觉编码器进行正则化,从而提升理解能力;
(II) 基于隐藏状态的重构(如 ROSS (Wang et al., 2024a; 2025b)),通过添加轻量级解码器,将中间嵌入重新生成输入图像,从而对模型进行正则化以保留细粒度细节,用于 VLMs;
(III) 表示对齐(如 REPA (Yu et al., 2024)),引入额外的对齐模块,将去噪网络中来自 VAE 的噪声隐藏状态映射到由外部预训练视觉编码器获得的干净图像表示;
(IV) 作为先验的重构(如 Lumos (Ma et al., 2025b)),在扩散模型的注意力块中引入额外的 DINO 特征(Caron et al., 2021),并在大规模文本生成图像数据上进一步训练。
我们的方法在方法论、架构、动机和任务方面都有根本性的不同。
2.4 DIFFERENCE BETWEEN RECA AND CLASSIFIER-FREE GUIDANCE (CFG)
无分类器引导(Classifier-free guidance, CFG)(Ho & Salimans, 2022)通常用于提升保真度。在每一步生成过程中,我们会计算一个有条件预测 ocondo_{cond}ocond 和一个无条件预测 ouncondo_{uncond}ouncond,其中 ooo 表示自回归头的 logits(Chen et al., 2025d; Xie et al., 2025b)或扩散头的预测噪声(Zhou et al., 2025; Deng et al., 2025)。输出由下式给出:
o=(1+ω)ocond−ωouncond,(4)o = (1 + \omega) o_{cond} - \omega o_{uncond}, \tag{4} o=(1+ω)ocond−ωouncond,(4)
其中 ω\omegaω 为引导系数。
RecA 在概念上与 CFG 正交。CFG 依赖于条件提示与空文本(或模板提示)之间的对比,而 RecA 则利用来自视觉理解编码器的嵌入作为密集提示,用于基于重构的对齐。这两种技术完全兼容,并且可以结合使用。