SciKit-Learn 全面分析分类任务 wine 葡萄酒数据集
背景
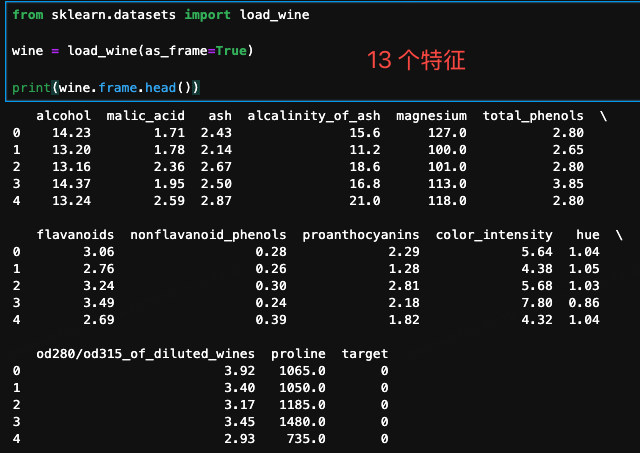
wine 葡萄酒数据集,提供了对三种不同品种的意大利葡萄酒的化学分析结果
主要特点:
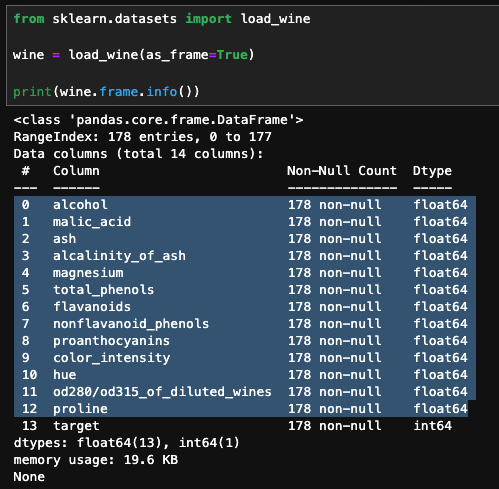
- 数据集规模:总共有 178 个样本
- 特征数量:每个样本有 13 个化学特征,包括酒精、苹果酸、灰分、镁等
- 类别数量:总共有 3 个类别,分别代表三种不同的葡萄酒品种
步骤
- 加载数据集
- 拆分训练集、测试集
- 数据预处理(标准化)
- 选择模型
- 模型训练(拟合)
- 测试模型效果
- 评估模型
分析方法
对数据集使用 7 种分类方法进行分析
- K 近邻(K-NN)
- 决策树
- 支持向量机(SVM)
- 逻辑回归
- 随机森林
- 朴素贝叶斯
- 多层感知机(MLP)
分析结果
不同模型的 ROC 及 AUC

不同模型效果
--- 模型训练与评估 ------ 正在训练 K近邻 (K-NN) 模型 ---
K近邻 (K-NN) 模型的准确率: 0.9630
K近邻 (K-NN) 模型的分类报告:precision recall f1-score supportclass_0 0.95 1.00 0.97 19class_1 1.00 0.90 0.95 21class_2 0.93 1.00 0.97 14accuracy 0.96 54macro avg 0.96 0.97 0.96 54
weighted avg 0.97 0.96 0.96 54--- 正在训练 决策树 模型 ---
决策树 模型的准确率: 0.9630
决策树 模型的分类报告:precision recall f1-score supportclass_0 0.95 0.95 0.95 19class_1 0.95 1.00 0.98 21class_2 1.00 0.93 0.96 14accuracy 0.96 54macro avg 0.97 0.96 0.96 54
weighted avg 0.96 0.96 0.96 54--- 正在训练 支持向量机 (SVM) 模型 ---
支持向量机 (SVM) 模型的准确率: 0.9815
支持向量机 (SVM) 模型的分类报告:precision recall f1-score supportclass_0 1.00 1.00 1.00 19class_1 0.95 1.00 0.98 21class_2 1.00 0.93 0.96 14accuracy 0.98 54macro avg 0.98 0.98 0.98 54
weighted avg 0.98 0.98 0.98 54--- 正在训练 逻辑回归 模型 ---
逻辑回归 模型的准确率: 0.9815
逻辑回归 模型的分类报告:precision recall f1-score supportclass_0 1.00 1.00 1.00 19class_1 1.00 0.95 0.98 21class_2 0.93 1.00 0.97 14accuracy 0.98 54macro avg 0.98 0.98 0.98 54
weighted avg 0.98 0.98 0.98 54--- 正在训练 随机森林 模型 ---
随机森林 模型的准确率: 1.0000
随机森林 模型的分类报告:precision recall f1-score supportclass_0 1.00 1.00 1.00 19class_1 1.00 1.00 1.00 21class_2 1.00 1.00 1.00 14accuracy 1.00 54macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54--- 正在训练 朴素贝叶斯 模型 ---
朴素贝叶斯 模型的准确率: 1.0000
朴素贝叶斯 模型的分类报告:precision recall f1-score supportclass_0 1.00 1.00 1.00 19class_1 1.00 1.00 1.00 21class_2 1.00 1.00 1.00 14accuracy 1.00 54macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54--- 正在训练 多层感知器 (MLP) 模型 ---
多层感知器 (MLP) 模型的准确率: 0.9815
多层感知器 (MLP) 模型的分类报告:precision recall f1-score supportclass_0 1.00 1.00 1.00 19class_1 1.00 0.95 0.98 21class_2 0.93 1.00 0.97 14accuracy 0.98 54macro avg 0.98 0.98 0.98 54
weighted avg 0.98 0.98 0.98 54
代码
from sklearn.datasets import load_winefrom sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifierfrom sklearn.metrics import accuracy_score, classification_report, roc_curve, auc
from sklearn.preprocessing import label_binarizeimport matplotlib.pyplot as plt
import numpy as np# 设置 Matplotlib 字体以正确显示中文
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Zen Hei', 'STHeiti', 'Arial Unicode MS']
# 解决保存图像时负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False def perform_wine_analysis():"""使用 scikit-learn 对葡萄酒数据集进行全面的分析。该函数包含数据加载、预处理、模型训练、评估和 ROC/AUC 可视化。"""print("--- 正在加载葡萄酒数据集 ---")# 加载葡萄酒数据集wine = load_wine()# 获取数据特征和目标标签X = wine.datay = wine.targettarget_names = wine.target_namesprint("\n--- 数据集概览 ---")print(f"数据形状: {X.shape}")print(f"目标名称: {target_names}")# 将数据集划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)print("\n--- 数据划分结果 ---")print(f"训练集形状: {X_train.shape}")print(f"测试集形状: {X_test.shape}")# 数据标准化print("\n--- 正在对数据进行标准化处理 ---")scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# 定义并训练多个分类器模型models = {"K近邻 (K-NN)": KNeighborsClassifier(n_neighbors=5),"决策树": DecisionTreeClassifier(random_state=42),"支持向量机 (SVM)": SVC(kernel='rbf', C=1.0, random_state=42, probability=True),"逻辑回归": LogisticRegression(random_state=42, max_iter=10000),"随机森林": RandomForestClassifier(random_state=42),"朴素贝叶斯": GaussianNB(),"多层感知器 (MLP)": MLPClassifier(random_state=42, max_iter=10000)}print("\n--- 模型训练与评估 ---")for name, model in models.items():print(f"\n--- 正在训练 {name} 模型 ---")model.fit(X_train_scaled, y_train)y_pred = model.predict(X_test_scaled)accuracy = accuracy_score(y_test, y_pred)report = classification_report(y_test, y_pred, target_names=target_names)print(f"{name} 模型的准确率: {accuracy:.4f}")print(f"{name} 模型的分类报告:\n{report}")print("\n--- ROC 曲线和 AUC 对比 ---")num_models = len(models)cols = 3rows = (num_models + cols - 1) // colsfig, axes = plt.subplots(rows, cols, figsize=(18, 6 * rows))axes = axes.flatten()# 将多分类标签二值化,用于 ROC 曲线计算y_test_bin = label_binarize(y_test, classes=np.arange(len(target_names)))for i, (name, model) in enumerate(models.items()):ax = axes[i]# 获取预测概率if hasattr(model, "predict_proba"):y_score = model.predict_proba(X_test_scaled)else:y_score = model.decision_function(X_test_scaled)# 计算每个类别的 ROC 曲线和 AUCfpr = dict()tpr = dict()roc_auc = dict()for j in range(len(target_names)):fpr[j], tpr[j], _ = roc_curve(y_test_bin[:, j], y_score[:, j])roc_auc[j] = auc(fpr[j], tpr[j])# 计算微平均 ROC 曲线和 AUCfpr["micro"], tpr["micro"], _ = roc_curve(y_test_bin.ravel(), y_score.ravel())roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])# 绘制所有类别的 ROC 曲线并填充for j in range(len(target_names)):ax.plot(fpr[j], tpr[j], label=f'类别 {target_names[j]} (AUC = {roc_auc[j]:.2f})', alpha=0.7)ax.fill_between(fpr[j], tpr[j], alpha=0.1)# 绘制微平均 ROC 曲线ax.plot(fpr["micro"], tpr["micro"], label=f'微平均 (AUC = {roc_auc["micro"]:.2f})',color='deeppink', linestyle=':', linewidth=4)# 绘制对角线 (随机猜测)ax.plot([0, 1], [0, 1], 'k--', lw=2)# 设置图表属性ax.set_xlim([0.0, 1.0])ax.set_ylim([0.0, 1.05])ax.set_xlabel('假正率 (FPR)')ax.set_ylabel('真正率 (TPR)')ax.set_title(f'{name} - ROC 曲线')ax.legend(loc="lower right", fontsize='small')ax.grid(True)# 隐藏未使用的子图边框for j in range(num_models, len(axes)):axes[j].axis('off')plt.tight_layout()plt.show()if __name__ == "__main__":perform_wine_analysis()