Hive实战(三)
接上文:Hive实战(二)
数据管理、查询、函数、调优。
1.Hive-数据管理
通常来说,对数据的增删改查都是属于数据管理。但是对于Hive来说,对数据的增、删、改,往往都不是他的重点。而对于Hive来说,管理数据的方式重要的就是导入导出 和 查询两个方面。这一章节就来介绍下hive如何对数据进行导入导出操作。
向表中装载数据(Load)
这种方式之前已经接触过。
hive> load data [local] inpath 'path' [overwrite] into table
tablename [partition (partcol1=val1,…)];
这个指令中 load data表示加载数据。
local表示从本地加载数据,默认是从Hdfs加载数据。
inpath表示加载数据的路径。
override表示覆盖表中已有的数据,否则就表示追加数据。
partition表示上传到指定的分区。
在指定位置创建表
这种方式通常是针对Hdfs上已经有数据的场景。大部分情况下都是建为外部表,hive只做数据索引,不做数据管理。
create external table if not exists student5(
id int ,name string
)
row format delimited fields terminated by ','
location '/student';

数据导出
使用insert直接将查询结果导出到本地。
#导出到服务器本地
INSERT OVERWRITE LOCAL DIRECTORY '/home/hive/data/export/student'
SELECT * FROM student5;#格式化后导出到本地
INSERT OVERWRITE LOCAL DIRECTORY '/home/hive/data/export/student1'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM student5;#导出到HDFS
INSERT OVERWRITE DIRECTORY '/hive/data/export/student'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM student5;#在Hive中直接操作hdfs
dfs -get /student/student.txt /home/hive/data/export/student5.txt;
然后还有一组导入导出的指令 export import ,多用于不同平台集群之间迁移Hive表。
export table student5 to '/user/hive/warehouse/export/student5';
import table student2 from '/user/hive/warehouse/export/student5';
另外,对于Hive的数据导入导出,更多的场景不是在Hive之间转移数据,而是在不同数据平台之间转移数据,例如hive与mysql数据、与redis数据之间进行互相导入导出。这时候一般会用其他一些专门的数据转移工具,比如Sqoop。
2.Hive-查询
查询是Hive的重点功能。官方也专门有网页详细介绍Hive的查询功能。具体可参见官方的wiki。
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
完整的查询语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE where_condition][GROUP BY col_list][ORDER BY col_list][CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]][LIMIT [offset,] rows]
基本的SQL操作,比如增删改查、join连接、sort排序等功能基本跟标准SQL没什么区别,这里就不一一介绍了,下面找一些Hive比较有特色的查询功能介绍一下。
2.1构建数据
我们准备两张测试的表:
--部门表
create table if not exists dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by ',';--员工表
create table if not exists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by ',';
然后准备两个数据文件:
dept:
10,ACCOUNTING,1700
20,RESEARCH,1800
30,SALES,1900
40,OPERATIONS,1700
emp:
7369,SMITH,CLERK,7902,1980-12-17,800.00,,20
7499,ALLEN,SALESMAN,7698,1981-2-20,1600.00,300.00,30
7521,WARD,SALESMAN,7698,1981-2-22,1250.00,500.00,30
7566,JONES,MANAGER,7839,1981-4-2,2975.00,,20
7654,MARTIN,SALESMAN,7698,1981-9-28,1250.00,1400.00,30
7698,BLAKE,MANAGER,7839,1981-5-1,2850.00,,30
7782,CLARK,MANAGER,7839,1981-6-9,2450.00,,10
7788,SCOTT,ANALYST,7566,1987-4-19,3000.00,,20
7839,KING,PRESIDENT,,1981-11-17,5000.00,,10
7844,TURNER,SALESMAN,7698,1981-9-8,1500.00,0.00,30
7876,ADAMS,CLERK,7788,1987-5-23,1100.00,,20
7900,JAMES,CLERK,7698,1981-12-3,950.00,,30
7902,FORD,ANALYST,7566,1981-12-3,3000.00,,20
7934,MILLER,CLERK,7782,1982-1-23,1300.00,,10
然后将数据文件导入到这两个表中,作为示例数据:
load data local inpath '/home/dept' into table dept;
load data local inpath '/home/emp' into table emp;
接下来可以对这两个表进行基础的增删改查操作,基本跟MySQL差不多。稍微有点区别:
(1)hive语句不区分大小写;
(2)select语句中支持指定列,也支持给列取别名。支持常用的聚合函数如 count、max、min、sum、avg。支持limit 条件限制返回的行数。支持Group by +having的分组统计语句。支持join进行数据连接。
(3)尝试执行update、delete操作时,会报错:
FAILED: SemanticException [Error 10294]: Attempt to do update or delete
using transaction manager that does not support these operations.
这是因为频繁的行级数据更改已经违背了Hive的设计初衷,所以hive默认不支持。如果非要支持,需要调整hive的配置文件hive-site.xml
<name>hive.support.concurrency</name>
<value>true</value><name>hive.enforce.bucketing</name>
<value>true</value><name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value><name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value><name>hive.compactor.initiator.on</name>
<value>true</value><name>hive.compactor.worker.threads</name>
<value>1</value><name>hive.in.test</name>
<value>true</value>
然后重启。
2.2常用的算数运算符
| 运算符 | 描述 |
|---|---|
| A%B | A对B取余 |
| A&B | A和B按位与 |
| A | B |
| A^B | A和B按位异或 |
| ~A | A按位取反 |
| A<=>B | 如果A和B都为NULL返回true,如果一边为NULL返回false |
| A [NOT] LIKE B | B是一个SQL下的简单正则表达式。'x%'表示A必须以’X’开头 |
| A RLIKE B,A REGEXP B | B是基于java的正则表达式。匹配使用的是JKD中的正则表达式。官方给了一个测试页面:https://www.regexplanet.com/advanced/java/index.html |
例如:如何判断一个数字是不是2的指数?
select 4&-4==4; //true
select 5&-5==5; //false
正则查询:
--查找名字以A开头的员工
select * from emp where ename like 'A%';
--查找名字中第二个字母为A的员工
select * from emp where ename like '_A%';
--查找名字中带A的员工
select * from emp where ename rlike '[A]';
2.3 分组排序
SORT/ORDER/CLUSTER/DISTRIBUTE BY
order by:hive中支持以order by关键字对结果进行排序
select * from emp order by deptno desc;
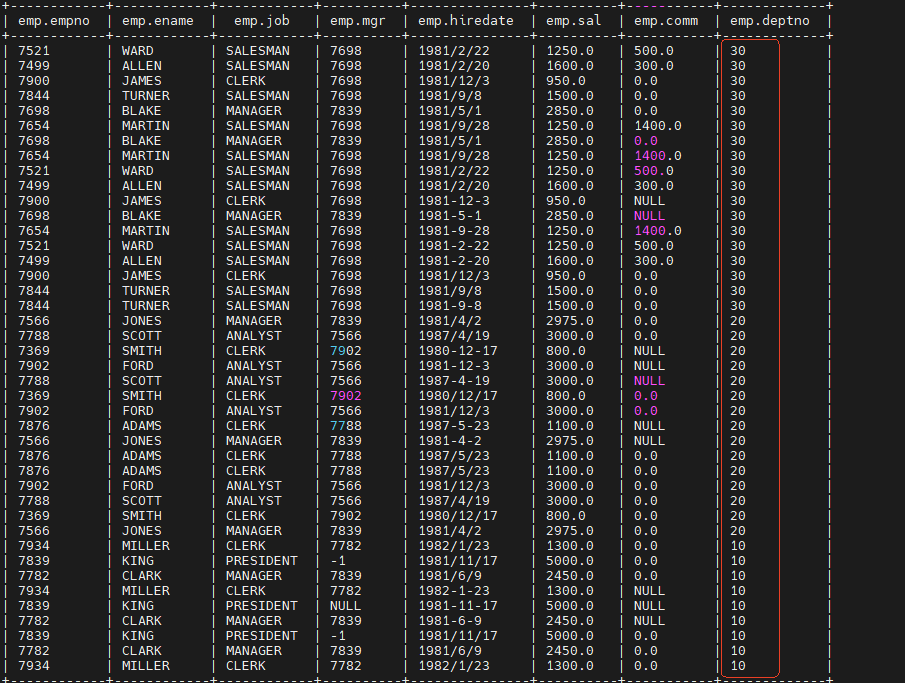
这时可以看到hive会对结果做整体排序。但是如果对于大规模的数据集,order by的效率就会非常低。在很多情况下,并不需要全局排序,只是需要分区有序,就可以用sort by。
sort by:sort by会为每个reducer产生一个排序文件。每个Reducer内部进行排序,而对全局结果集来说并不进行排序。
set mapreduce.job.reduces=4;
select * from emp sort by deptno desc;
-- 分四个reducer。每个reducer内部有序,整体无序。
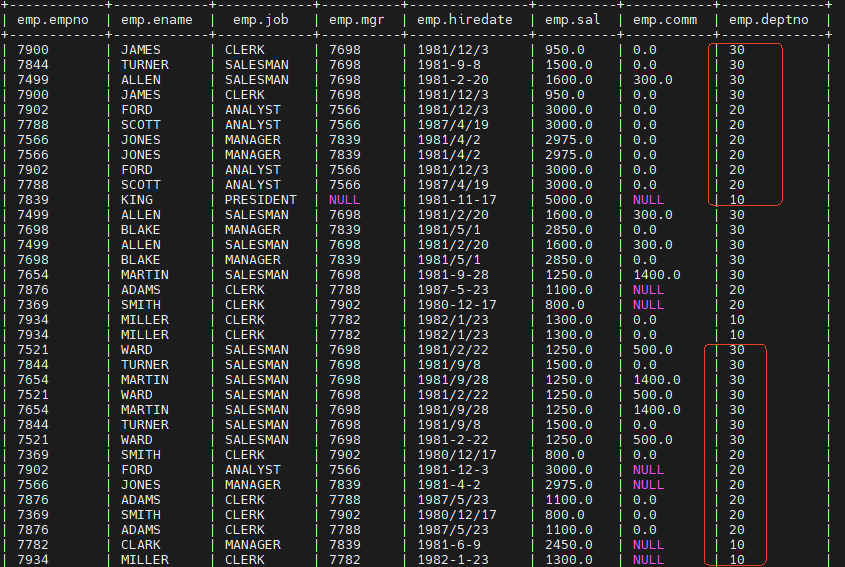
insert overwrite local directory '/home/hive/data/emp' select * from
emp sort by deptno desc;
--在本地生成四个reduce结果文件。每个文件局部有序。

districbute by:在sort by的基础上,可以通过districbute by指定sql语句的分区键,即按哪个字段字段分区。类似于MapReduce中的pattition。
select * from emp distribute by deptno sort by empno desc;
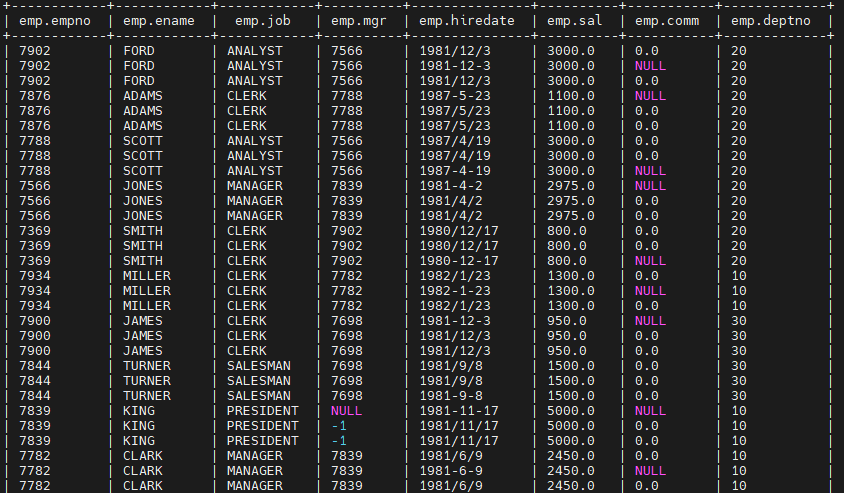
districbute by的分区规则是按分区阻断的hash码与reduce的个数取模进行的,结果相同的就分到同一个区。
clueter by: 如果distribute by 和 sort by 的字段相同,可以使用cluster by。cluster by 兼具了distribute by和sort by 的功能,但是排序时,只能升序排序,不能指定排序规则。
select * from emp cluster by deptno;
-- 等价于
select * from emp distribute by deptno sort by deptno;
2.4 With关键字 Common Table Expression(CTE)
Hive可以在执行SELECT、INSERT、CREATE TABLE AS SELECT 或者CREATE VIEW AS SELECT 指令时,可以使用with关键字创建一个临时的结果。就相当于提前创建了视图,只不过这个视图只在当前语句中有效。
with cte_dept_20 as (select deptno,dname from dept where deptno='20')
select * from cte_dept_20; --查看20部门的部门名字with cte_dept as (select deptno,dname from dept),
cte_emp as (select deptno,empno,ename from emp)
select e.empno,e.ename,e.deptno,d.dname from cte_emp e left join
cte_dept d on e.deptno=d.deptno; --查看每个人所属的部门create table dept_member as
with cte_dept as (select deptno,dname from dept),
cte_emp as (select deptno,empno,ename from emp)
select e.empno,e.ename,e.deptno,d.dname from cte_emp e left join
cte_dept d on e.deptno=d.deptno; --根据结果创建表。
3.Hive-函数
3.1 系统自带的函数
参见官方文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-CreatingCustomUD
-- 查看系统自带的函数
show functions;
-- 显示自带的函数用法
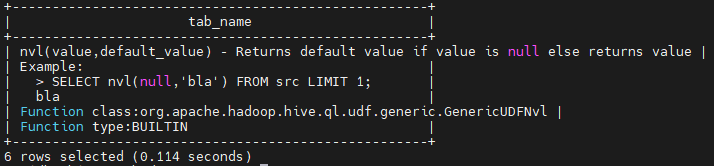
desc function nvl;
-- 详细显示自带函数的用法
desc function extended nvl;
3.2 开窗函数
over 开窗函数: 指定每个分析函数工作的数据窗口大小。每个窗口的大小可能会随着每一行数据的不同而不同。
-- 查看所有薪水
select sum(sal) over() from emp;
-- 查看每个部门的总薪水
select deptno ,sum(sal) over(partition by deptno) as depSal from emp;
-- rows统计自己以及与自己的薪水最接近的两个人,avg统计这三个人的平均奖金
select empno,sal,avg(comm) over(partition by deptno order by sal rows between 1 preceding and 1 following) from emp;
rows between 必须跟在order by子句之后,对排序的结果进行限制。在rows between后可以接以下条件:1 PRECEDING: 前一行, 1 FOLLOWING:后一行,CURRENT ROW 当前行。 另外还有UNBOUNDED 表示不限制前面或后面多少行。
另外,针对over()开窗函数,还可以进行LAG()统计和LEAD()统计。其中,LAG(col,n,default_val)表示往前第n行的数据。LEAD(col,n,defalut_val)表示往后第n行数据。
-- 查询每个人,按工作分组,按薪水排序之后的排名名次。 以及按工作分组,按薪水排序后每个人所在的行数。
select empno ,rank() over (partition by job order by sal desc) salrk ,row_number() over (partition by job order by sal desc) salrow from emp;
3.3 自定义函数
参见官方文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
Hive中的用户自定义函数分为三类:
(1)UDF User-Defined-Function 一行入参出一结果,例如nvl函数,pi函数;
(2)UDAF User-Defined-Aggreget Function 多行入参出一个结果,类似于 max、min、avg这些;
(3)UDTF User-Defined-Table-Generating Function 一行入参出多个结果。例如lateral view explode()。
开发自定义函数
开发hive的自定义函数,需要创建一个maven工程,引入依赖:
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
然后创建一个函数类:
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
使用maven打成jar包,my_jar.jar,然后将这个jar包上传到服务器上。
引入自定义函数
接下来启动hive后,需要引入这个jar包。
-- 引入jar包。
hive> add jar /root/my_jar.jar;
-- 查看引入的jar包。
hive> list jars;
接下来就可以使用这个自定义函数了:
create function my_lower as 'com.example.hive.udf.Lower';
select my_low(ename) from emp;
4.Hive-调优
4.1 了解Hive的执行计划
之前实验阶段已经发现,有些简单的SQL可以不走MapperReduce直接执行,这样效率很高。而很多复杂的SQL都需要走MapperReduce。到执行阶段再去判断SQL如何运行,效率太低了。就需要提前了解SQL的执行计划,作为对SQL优化的依据。其实在MySQL中也可以查看执行计划,Hive中的执行计划也差不多。
基础语法:
explain [extended]|[dependency]|[authorizetion] query;
其中query就是查询语句。
例如:
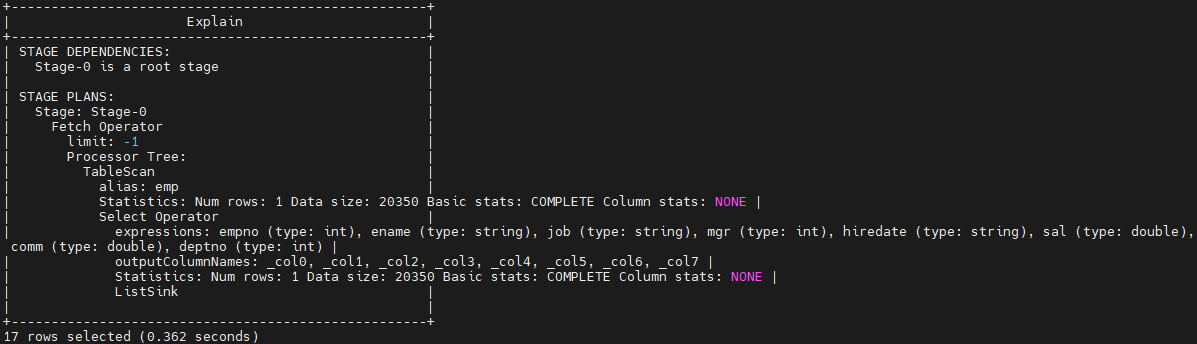
-- 不走MapperReduce
explain select * from emp;
-- 走MapperReduce
explain select deptno,avg(sal) from emp group by deptno;
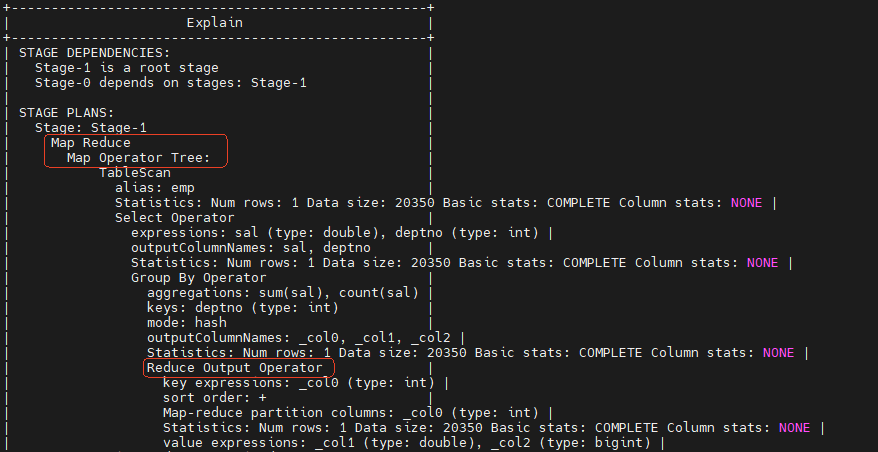
可以看到, 在 STAGE DEPNEDENCIES部分会列出整体的执行步骤。 STAGE PLANS 部分会列出每个步骤的详细执行计划。比如对于第一个不走MapperReduce的SQL语句,就只有一个Fetch Operator阶段。这个Fetch操作,Hive就可以直接读取对应的HDFS目录下的文件,而不需要经过复杂的MapperReduce。而对第二个需要走MapperReduce的SQL语句,就分为了两个阶段,第一个阶段是一个MapperReduce计算。第二个阶段依然是Fetch操作。在MapperReduce的执行计划中,列出了每个阶段的大致计算过程。例如对这个分组后求平均值的SQL语句,就会统计sum(sal)和count(sal),然后在reduce阶段求平均值。
另外,关于Hive在哪些情况下走Fetch,哪些情况下走MapperReduce,在hive-default.xml.template中有一个属性:
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing
latency.
Currently the query should be single sourced not having any subquery
and should not have
any aggregations or distincts (which incurs RS), lateral views and
joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and
virtual columns)
</description>
</property>
none就表示所有SQL都走MapperReduce,而默认的more,列出了大部分可以走Fetch的操作。
当然,对于Hive来说,能够仅仅通过一个Fetch操作就解决的,毕竟只是一小部分简单的SQL。大部分的SQL还是需要MapperReduce进行计算的,所以,对Hive来说,大部分的调优工作就是针对MapperReduce计算过程定制更适合的参数。
4.1 定制Mapper和Reducer数量
接下来对Hive的调优,就都是针对MapperReduce计算过程的调优了。
针对MapperReduce计算,默认情况下, Map阶段会将同一个key的所有数据分发给一个Reduce,这时,当其中一个key的数据量非常大时,就会造成一个Reduce非常繁忙,而其他的Reduce并不会帮忙分担计算任务的情况。这时候整个集群的计算能力实际上被最繁忙的Reduce给拖累了,而集群的整体计算能力又没有充分发挥出来,这就是经常提到的数据倾斜的问题。而对于我们之前第二个groupby的SQL语句,在Hive当中,可以通过启用map端聚合的方式,来减轻数据倾斜问题的影响。涉及到几个重要的配置参数:
<!--对于Group By操作,是否启用map端聚合。 默认是启用 -->
<property>
<name>hive.map.aggr</name>
<value>true</value>
<description>Whether to use map-side aggregation in Hive Group By
queries</description>
</property>
<!-- 对于Group by操作,当有数据倾斜时,进行负载均衡优化。默认是关闭的 -->
</property>
<property>
<name>hive.groupby.skewindata</name>
<value>false</value>
<description>Whether there is skew in data to optimize group by queries</description>
</property>
<!-- 在Map端进行聚合操作的条目数 -->
<property>
<name>hive.groupby.mapaggr.checkinterval</name>
<value>100000</value>
<description>Number of rows after which size of the grouping keys/aggregation classes is performed</description>
</property>
而针对MapperReduce计算过程,另一个很重要的调优手段就是手动调整Map和Reduce的个数。
首先在Map阶段,需要尽量调整输入文件的个数,让输入的文件尽量接近Hadoop的文件块大小(默认128M),而不要是很多小的文件。大量小而碎的文件不仅加大了NameNode的负担,也会造成更多的Map,从而浪费Map在任务启动和初始化过程中的资源。例如通过hadoop fs -getmerge指令,将HDFS上一个目录里的文件整理合并成服务器本地的一个大文件,再上传到HDFS上。另外,在Hive中,也有两个参数配置了MapperReduce计算过程中是否需要进行小文件合并。
<property>
<name>hive.merge.mapfiles</name>
<value>true</value>
<description>Merge small files at the end of a map-only
job</description>
</property>
<property>
<name>hive.merge.mapredfiles</name>
<value>false</value>
<description>Merge small files at the end of a map-reduce
job</description>
</property>
然后在Reduce阶段,同样需要调整Reduce计算的个数,过多的Reduce也同样会消耗更多的启动和初始化的时间,并没每个Reduce会产生一个输出文件,同样也会带来文件碎片过多的问题。而过少的Reduce又会降低整体的计算速度。所以,需要综合定制Reduce的个数。而定制Reduce个数的参数,其实在之前每次执行SQL时,已经有所体现。
<!-- 每个Reduce处理的数据量 -->
<property>
<name>hive.exec.reducers.bytes.per.reducer</name>
<value>256000000</value>
<description>size per reducer.The default is 256Mb, i.e if the input size is 1G, it will use 4 reducers.</description>
</property>
<!-- 定制最大reduce数 -->
<property>
<name>hive.exec.reducers.max</name>
<value>1009</value>
<description>
max number of reducers will be used. If the one specified in the configuration parameter mapred.reduce.tasks is
negative, Hive will use this one as the max number of reducers when automatically determine number of reducers.
</description>
</property>
通过这两个参数可以定制如何计算reduce的个数。另外,还有一个参数可以强行指定reduce的个数,针对某些特定的SQL还是挺有用的。
set mapreduce.job.reduces;
mapreduce.job.reduces=-1
4.3 Hive与其他大数据组件融合
在整个大数据技术生态中,Hive的定位通常是一个数据仓库,即他的强项在于元数据管理以及对Hdfs文件的映射索引。而管理、查询数据的功能其实是比较弱的。通常都会与其他组件融合,才能发挥Hive的强项。这里介绍下Hive与其他大数据组件集成的几种大致思路:
(1)Hive on Tez: 这个之前提到过,就是将Hive的计算引擎由Hadoop的mapreduce转为Tez。而Tez是一个构建DAG有序无环图的计算引擎。构建于Hadoop的YARN之上。
(2)Hive on Spark: 与Hive on Tez的思想类似,就是将Hive的计算引擎转为Spark。利用Spark内存计算高效的特点,加快MapperReduce计算的速度。但是这种方式配置起来比较麻烦,并且如果作为计算入口,其实Spark比Hive使用得更多。所以在实际项目中,这种方式用得比较少,而用得更多的是Spark on Hive。
(3)Spark on Hive: 这种集成方式是让Spark主动来利用Hive的元数据来加快对Hdfs文件的索引。然后利用Spark的Spark SQL 来提供对Hdfs的文件操作。这种方式配置起来相对比较简单,使用场景也更多。
(4)Hive & HBase: Hbase同样是一个构建于Hadoop的Hdfs之上的一个大数据引擎。但是,Hbase是基于列式存储的,他管理数据、过滤数据的效率是非常高的,但是其列式存储的特性,造成他的数据检索是非常自由,也不太规范的。而Hive与Hbase集成后,可以用Hive来映射Hbase中的数据,从而给HBase数据增加SQL管理的功能。这样能够更好的集合两个大数据组件各自的长处。这也是实际项目中使用的比较多的一种方式。
下面简单演示一下第3种,Spark on Hive的效果。这种配置方式比较简单,Spark采用的是基于hadoop3编译的spark-3.5.6-bin-hadoop3.tgz。在这个版本的部署包中已经完成了与Hive的集成。只需要将Hive下的hive-site.xml拷贝到spark的conf目录下,然后就可以使用SparkSQL来访问Hive中的数据了,并且,使用spark后,可以明显的感觉到sql的性能提升。并且,执行计划项目Hive on MR也简化了不少。
唯一需要注意下的是hive中的hive.execution.engine这个组件不要配置成Tez。
import org.apache.spark.sql.hive.HiveContext;
val hc = new HiveContext(sc);
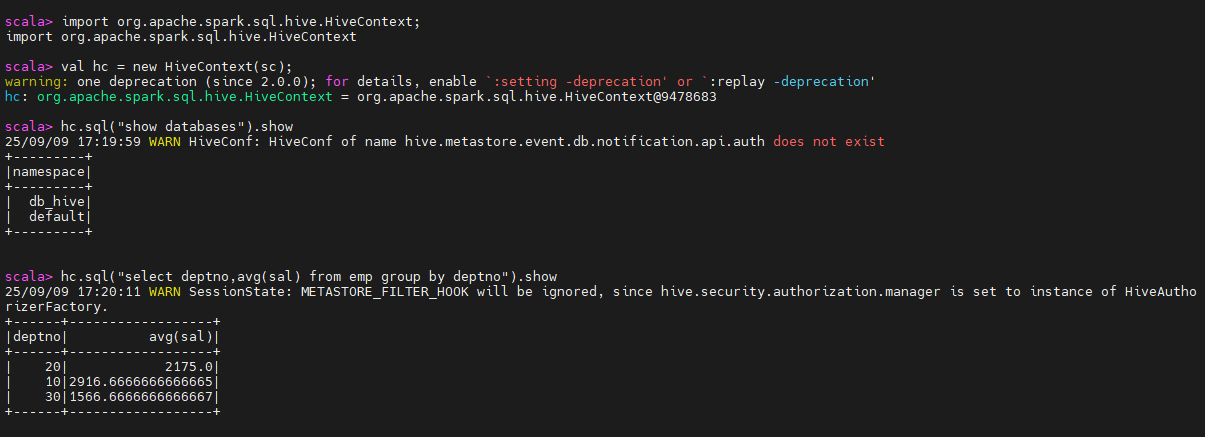
hc.sql("show databases").show
hc.sql("select deptno,avg(sal) from emp group by deptno").show
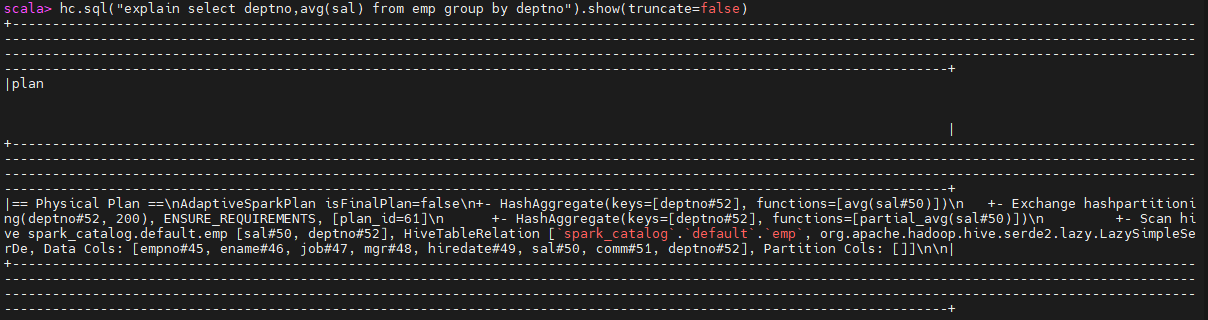
hc.sql("explain select deptno,avg(sal) from emp group by deptno").show(truncate=false)
5.相关资源
百度网盘:https://pan.baidu.com/s/1eaN_8YWIquJKESAmMxhtDg?pwd=vg5n