视觉语言模型应用开发——Qwen 2.5 VL模型视频理解与定位能力深度解析及实践指南
引言
随着多媒体技术的飞速发展,视频数据已成为信息传递的主要载体之一。然而,对视频内容进行高效、精准的理解与分析仍面临诸多挑战,尤其是在处理时空动态信息方面。Qwen 2.5 视觉-语言(VL)模型的问世为解决这一难题提供了突破性方案。
在前序研究中,我们已揭示 Qwen 2.5 模型通过零样本学习在内容审核任务中展现的显著优势,其在维护安全且包容的数字空间方面具有重要应用价值。本文将进一步拓展研究视野,聚焦该模型在视频理解与定位领域的卓越性能,深入探讨其在动态场景分析中的技术创新与实践应用。
无论是从动态场景中提取文本线索、识别动作序列,还是解码跨帧的对象交互关系,Qwen 2.5 均展现出超越传统模型的理解能力。本文将系统介绍利用 Qwen 2.5 进行视频分析的核心技术、实现步骤及应用案例,为相关领域研究者和实践者提供全面的技术参考。
Qwen 2.5 模型中增强的视频理解能力
Qwen 2.5-VL 模型在视频理解领域实现了重大技术飞跃,其核心突破在于对时间动态信息的精确且高效处理。考虑到视频数据同时包含空间维度(单帧内的视觉信息)和时间维度(帧间的动态变化)的双重复杂性,Qwen 2.5 引入了多项尖端技术改进以增强其理解能力(如图 1 所示)。

图 1: Qwen 2.5 系列的视频理解框架
为实现对视频内容的有效分析,Qwen 2.5-VL 创新性地融入了动态帧率训练机制和绝对时间编码技术。通过在训练过程中模拟并适应不同的帧率变化,该模型能够细致捕捉时间动态特征,实现对不同速度视频内容的无缝适配(如图 2 所示)。
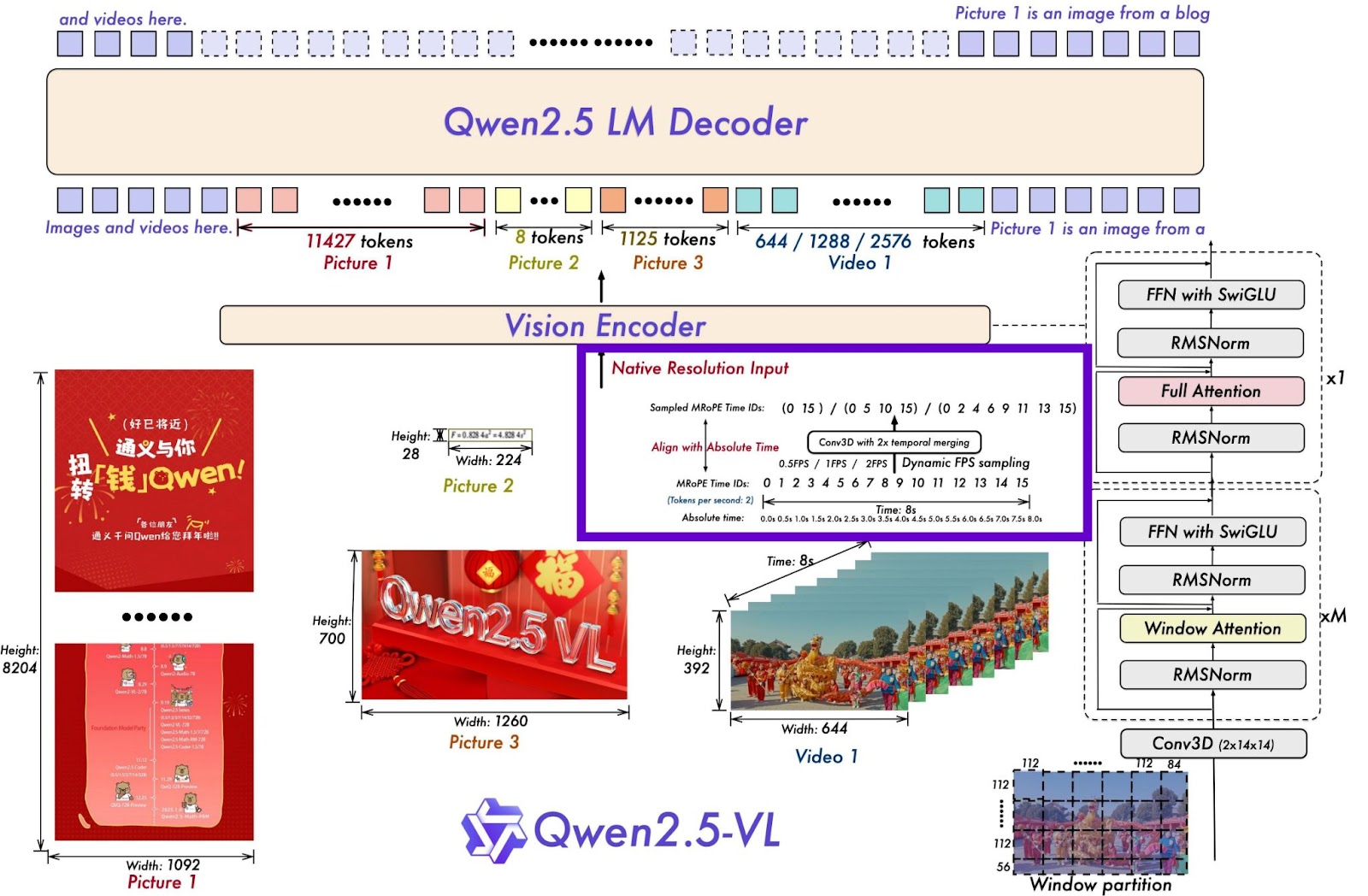
图 2: Qwen 2.5 系列的动态帧率采样策略
与传统方法中依赖文本时间戳或额外计算层实现时间定位的方案不同,Qwen 2.5 采用了一种更为高效的创新方法。该模型将多模态旋转位置嵌入(MRoPE)的标识符与时间戳直接对齐,使模型能够通过时间维度标识符之间的间隔直接感知时间节奏。这种设计策略在不增加额外计算开销的前提下,显著提升了时间定位的准确性。
动态帧率(FPS)与绝对时间编码技术
在 Qwen 2-VL 模型引入的原始 MRoPE 基础上,Qwen 2.5 进一步扩展了其功能以更好地处理视频中的时间信息。MRoPE 框架将位置嵌入分解为三个独立维度:时间、高度和宽度(如图 3 所示),这种多维分解设计为多模态输入的全面建模提供了结构基础。

图 3: 用于时间精度的多模态旋转位置嵌入(来源:Qwen 团队和阿里巴巴集团,2024)
对于文本数据,MRoPE 的功能类似于传统的一维 RoPE(旋转位置编码),确保了在所有组件中的一致性处理。而对于视觉数据,时间标识符随每个视频帧递增,高度和宽度标识符则在空间位置范围内保持恒定。这种差异化处理机制使模型能够同时精确捕捉空间布局和时间演进信息。
Qwen 2.5-VL 的关键增强点在于将时间位置标识符与绝对时间进行校准。通过利用时间标识符之间的间隔信息,模型在视频中实现了独立于帧率变化的一致性时间对齐。这一改进使 Qwen 2.5 不仅能够捕获序列数据的相对时序关系,还能精确感知事件的实际持续时间,从而实现对视频内容更深入的理解。
基于训练创新的模型韧性提升
为进一步增强视频理解能力,Qwen 2.5-VL 采用了多项创新训练技术。训练过程中的动态每秒帧数(FPS)采样策略确保了模型对数据集中各种帧率分布的均衡学习,显著提升了模型对不同拍摄条件下视频的适应能力。
针对时长超过半小时的长视频处理挑战,该模型采用专用管道合成多帧字幕,使模型能够连贯理解扩展时间范围内的内容逻辑。此外,Qwen 2.5 设计了灵活的时间戳处理机制,可兼容多种时间戳格式的视频定位数据,包括基于秒的格式和时-分-秒-帧(HMSF)格式,确保了对时间信息理解的精确性和输出形式的多样性(如表 1 所示)。
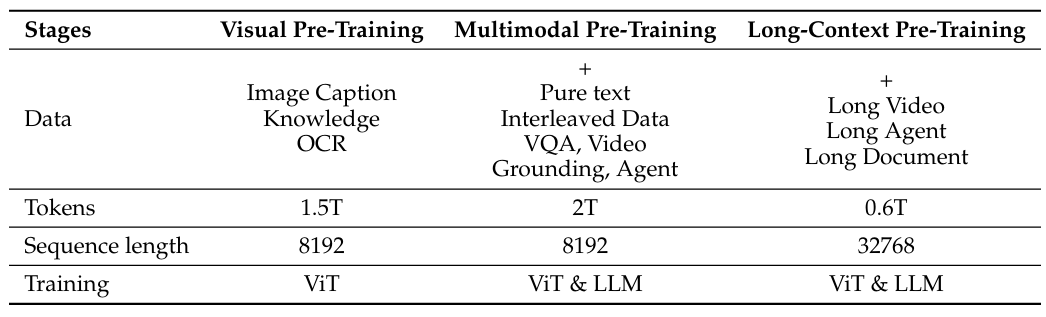
表 1: 不同阶段的训练数据量和组成(来源:Qwen 团队和阿里巴巴集团,2025)
Qwen 2.5 视频理解任务的实践指南
本节将系统介绍如何使用 Qwen 2.5 模型执行各类视频理解任务,包括从视频帧中提取文本、生成视频摘要、实现视频定位以及创建视频字幕等。我们将从环境配置开始,逐步引导完成模型部署与任务实现。
环境配置与依赖安装
首先需要安装必要的库以支持模型运行和视频处理:
pip install git+https://github.com/huggingface/transformers
pip install qwen-vl-utils
pip install kagglehub
pip install decord
这些库分别提供了模型加载、视觉信息处理、数据获取和视频帧提取等功能,共同构成了 Qwen 2.5 视频理解的技术基础。
模型与处理器加载
我们首先将 Qwen 2.5 VL 模型加载到内存中,并初始化用于处理各类视频理解任务的推理组件:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info# 默认配置:将模型加载到可用设备上
model = Qwen2_5_VLForConditionalGeneration.from_pretrained( "Qwen/Qwen2.5-VL-3B-Instruct", torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
本实践案例中采用的 Qwen2.5-VL-3B 模型是 Qwen2.5 视觉-语言模型系列中的一个 30 亿参数版本,在保持较高推理效率的同时,能够满足多数视频理解任务的精度需求。
代码解析:
- 第 1-2 行导入了必要的类和工具函数
- 第 5-8 行通过
from_pretrained方法从 Hugging Face 模型仓库加载预训练模型 torch_dtype="auto"参数确保模型根据硬件条件自动选择合适的数据类型device_map="auto"参数实现模型在可用设备(如 GPU)上的自动分配,以优化计算性能- 第 9-12 行创建处理器对象,负责视觉信息的预处理(如将图像大小调整到指定像素范围)
模型与处理器的协同工作,使系统能够基于输入的视频数据高效生成符合任务要求的条件输出。
视频处理工具函数实现
为便于从视频中提取关键帧并进行可视化,我们实现了以下工具函数:
from IPython.display import Markdown, display
import numpy as np
from PIL import Image
import decord
from decord import VideoReader, cpudef get_video_frames(video_file_path, num_frames=128):"""从视频文件中提取指定数量的均匀间隔帧及其时间戳参数:video_file_path: 视频文件路径num_frames: 需要提取的帧数量返回:video_file_path: 视频文件路径frames: 提取的视频帧数组timestamps: 对应帧的时间戳数组"""vr = VideoReader(video_file_path, ctx=cpu(0))total_frames = len(vr)# 生成均匀分布的帧索引indices = np.linspace(0, total_frames - 1, num=num_frames, dtype=int)frames = vr.get_batch(indices).asnumpy()# 获取每个帧的时间戳timestamps = np.array([vr.get_frame_timestamp(idx) for idx in indices])return video_file_path, frames, timestamps
get_video_frames 函数通过以下步骤实现功能:
- 使用
decord.VideoReader加载视频文件(第 10 行) - 计算视频总帧数(第 11 行)
- 利用
np.linspace生成均匀分布的帧索引(第 13 行) - 批量获取指定索引的视频帧(第 14 行)
- 提取每个帧的时间戳信息(第 16 行)
- 返回视频路径、帧数组和时间戳数组(第 17 行)
def create_image_grid(images, num_columns=8):"""将图像列表排列成网格形式并返回组合图像参数:images: 图像数组列表num_columns: 网格的列数返回:grid_image: 组合后的网格图像"""# 将numpy数组转换为PIL图像pil_images = [Image.fromarray(image) for image in images]# 计算所需的行数num_rows = (len(images) + num_columns - 1) // num_columns# 获取单张图像的尺寸img_width, img_height = pil_images[0].size# 计算网格图像的尺寸grid_width = num_columns * img_widthgrid_height = num_rows * img_height# 创建空白网格画布grid_image = Image.new('RGB', (grid_width, grid_height))# 将图像粘贴到网格中的对应位置for idx, image in enumerate(pil_images):row_idx = idx // num_columnscol_idx = idx % num_columnsposition = (col_idx * img_width, row_idx * img_height)grid_image.paste(image, position)return grid_image
create_image_grid 函数的核心功能是将多个视频帧有序排列为网格图像,便于整体观察视频内容:
- 将输入的图像数组转换为 PIL 图像格式(第 5 行)
- 根据列数计算网格所需的行数(第 7 行)
- 确定单张图像的尺寸并计算网格的整体尺寸(第 9-12 行)
- 创建空白画布以容纳整个网格(第 14 行)
- 遍历图像并计算每个图像在网格中的位置(第 17-19 行)
- 将图像粘贴到画布的对应位置(第 20 行)
- 返回组装好的网格图像(第 22 行)
推理函数实现
在完成模型加载和工具函数准备后,我们实现 inference 函数,该函数接收提示信息和视频路径,调用模型进行处理并返回结果。此函数设计具有通用性,可支持多种视频理解任务。
def inference(model, processor, video_path, prompt, max_new_tokens=1024, total_pixels=20480 * 28 * 28, min_pixels=16 * 28 * 28
):"""基于Qwen 2.5 VL模型执行视频理解推理参数:model: 加载的Qwen 2.5 VL模型processor: 对应的处理器video_path: 视频文件路径prompt: 任务提示文本max_new_tokens: 生成文本的最大长度total_pixels: 处理的总像素数min_pixels: 最小像素数返回:模型生成的文本结果"""# 构建对话消息messages = [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": [{"type": "text", "text": prompt},{"video": video_path, "total_pixels": total_pixels, "min_pixels": min_pixels}]}]# 准备推理输入text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 处理视觉信息image_inputs, video_inputs, video_kwargs = process_vision_info([messages], return_video_kwargs=True)fps_inputs = video_kwargs['fps']# 打印调试信息print("video input shape:", video_inputs[0].shape)num_frames, _, resized_height, resized_width = video_inputs[0].shapeprint("number of video tokens:", int(num_frames / 2 * resized_height / 28 * resized_width / 28))# 处理输入数据inputs = processor(text=[text], images=image_inputs, videos=video_inputs, fps=fps_inputs, padding=True, return_tensors="pt")# 将输入转移到GPUinputs = inputs.to('cuda')# 模型推理生成输出output_ids = model.generate(**inputs, max_new_tokens=max_new_tokens)# 提取生成的部分generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]# 解码生成的文本output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)return output_text[0]
推理函数的工作流程可分为以下几个关键步骤:
1.** 消息构建 **(第 23-38 行):
- 构建包含系统提示和用户请求的消息结构
- 消息中包含提示文本和视频元数据(如像素范围参数)
- 像素范围参数用于平衡处理性能和计算成本
2.** 输入准备 **(第 41-50 行):
- 使用
apply_chat_template处理文本输入,生成符合模型要求的格式 - 通过
process_vision_info提取图像和视频输入及其帧率信息
3.** 调试信息输出 **(第 53-55 行):
- 打印视频输入形状和视频令牌数量等信息,便于监控处理过程
4.** 输入处理与设备分配 **(第 58-67 行):
- 将文本、图像和视频数据组合成模型可接受的张量格式
- 将处理后的输入传输到 GPU 以加速推理过程
5.** 模型推理与结果解码 **(第 70-82 行):
- 调用模型的
generate方法生成任务结果 - 提取并解码模型生成的部分,得到人类可读的文本输出
该函数设计支持多模态输入的协同处理,为各类视频理解任务提供了统一的接口。
Qwen 2.5 VL 模型的提示工程实践
接下来,我们将使用上述 inference 函数在样本视频上执行各类视频理解任务,展示 Qwen 2.5 VL 模型的实际性能。
首先,我们需要准备一个样本视频。本案例选用 YouTube 上的早餐食谱视频《一个土豆和一个鸡蛋!完美的快速早餐食谱》(One Potato & One Egg! Quick Recipe Perfect For Breakfast)。
视频下载步骤:
- 将视频 URL 粘贴到 YouTube 视频下载网站(如 Yt1z:免费 YouTube 视频下载器)
- 下载视频并命名为
breakfast_recipe.mp4 - 上传到运行环境(如 Colab 笔记本)
视频帧可视化代码如下:
video_file_path, frames, timestamps = get_video_frames("./recipe.mp4", num_frames=64)
print(f"Frames shape: {frames.shape}, Timestamps shape: {timestamps.shape}")
image_grid = create_image_grid(frames, num_columns=8)
display(image_grid)

图 4: 视频样本帧网格(来源:作者提供的图像)
从视频帧中提取文本
视频文本提取是许多实际应用中的重要任务,如自动识别视频中的字幕、标牌或文档内容。以下代码展示如何使用 Qwen 2.5 模型从视频帧中提取文本:
prompt = "Watch the video and list the OCR text in the video frames."
response = inference(model, processor, video_file_path, prompt)
display(Markdown(response))
上述代码的输出结果如下:
![[外链图片转存中...(img-Bgg379bl-1757309185544)]](https://i-blog.csdnimg.cn/direct/c364fa2fcd764298bfd0c5e346d078da.png)
结果表明,Qwen 2.5 模型能够高精度地从视频帧中提取文本信息,这使其在智能 OCR 应用领域(如交通监控中的车牌识别、工业场景中的设备标识读取等)具有重要应用价值。
视频内容理解与综合
视频内容理解需要模型不仅能感知视觉元素,还能理解其内在逻辑和语义关联。以下案例展示模型如何生成视频的全面摘要,并提取食谱的食材和步骤:
prompt = "Watch the video till end and provide the detailed recipe instructions with exact measurement of ingredients."
response = inference(model, processor, video_file_path, prompt)
display(Markdown(response))
上述代码的输出结果如下:

该结果展示了 Qwen 2.5 模型处理和分析长视频内容的能力,能够从连续的视觉流中提取有意义的结构化信息,准确理解视频的核心内容和细节。
视频定位(Video Grounding)
视频定位任务要求模型能够根据自然语言查询,在视频中精确找到对应的时间位置。这一能力在视频检索、内容编辑等场景中具有重要应用。
以下代码展示如何提示模型定位视频中特定动作的发生时间:
prompt = "Give the query: 'Adding 2 tbsp of all purpose flour', when does the described content occur exactly (in seconds) in the video?"
response = inference(model, processor, video_file_path, prompt)
display(Markdown(response))
上述代码的输出结果如下:
The query "Adding 2 tbsp of all purpose flour" occurs at approximately 70.4 seconds into the video.
该结果证明 Qwen 2.5 模型具备理解精确时间戳并在视频中搜索特定事件的能力。需要注意的是,模型的时间定位准确性随参数规模增大而提升——较大的模型(如 7B、13B、72B 版本)通常能提供更高的定位精度,而本案例中使用的 3B 版本在某些复杂场景下可能存在一定误差。
结构化视频字幕生成
结构化视频字幕生成任务要求模型能够识别视频中的关键事件序列,为每个事件分配时间区间并提供描述。这一功能可将视频分割为语义连贯的片段,便于内容索引和快速浏览。
prompt = "Localize a series of activity events in the video, output the start and end timestamp for each event, and describe each event with sentences. Provide the result in json format with 'seconds' format for time depiction."
response = inference(model, processor, video_file_path, prompt)
display(Markdown(response))
上述代码的输出结果如下:
[{"start_time": "0.0", "end_time": "14.2", "description": "Peel 1 potato."},{"start_time": "15.3", "end_time": "46.8", "description": "Slice thin and shred the potatoes."},{"start_time": "47.9", "end_time": "123.0", "description": "Put the shredded potatoes in a bowl, add an egg, flour, salt, and water, then mix well."},{"start_time": "124.1", "end_time": "189.0", "description": "Cook the mixture in a pan with oil, cover it, and cook for 3 minutes under medium heat. Open and turn it over, then cover and cook for 2 minutes more under medium heat."},{"start_time": "190.1", "end_time": "235.0", "description": "Serve the dish and cut into pieces. Enjoy the delicious potato dish."}
]
输出结果显示,模型成功识别了视频中的关键事件,为每个事件分配了精确的时间区间并提供了描述性文本。为进一步可视化这些视频片段,我们可以使用以下解析脚本:
import json
import markdown
from bs4 import BeautifulSoup
from datetime import datetimedef parse_json(response):"""解析markdown格式中的JSON数据"""html = markdown.markdown(response, extensions=['fenced_code'])soup = BeautifulSoup(html, 'html.parser')json_text = soup.find('code').textdata = json.loads(json_text)return data# 解析视频片段数据
data = parse_json(response)# 显示每个片段并可视化对应帧
for item in data:start_time = item["start_time"]end_time = item["end_time"]description = item["description"]# 显示时间戳和描述display(Markdown(f"**{start_time} - {end_time}:**\t\t{description}"))# 转换时间戳为浮点数start_time = float(start_time)end_time = float(end_time)# 筛选当前时间区间内的帧current_frames = []for frame, timestamp in zip(frames, timestamps):if timestamp[0] > start_time and timestamp[1] < end_time:current_frames.append(frame)# 生成并显示帧网格current_frames = np.array(current_frames)current_image_grid = create_image_grid(current_frames, num_columns=8)display(current_image_grid.resize((480, (int(len(current_frames) / 8) + 1) * 60)))
该脚本的功能解析:
1.** JSON 解析 (第 5-11 行):将 markdown 格式的输出转换为结构化 JSON 数据
2. 时间戳处理 (第 19-20 行):将文本格式的时间戳转换为浮点数以便比较
3. 帧筛选 (第 24-27 行):根据时间区间筛选对应的视频帧
4. 可视化 **(第 30-32 行):生成并显示每个事件片段的帧网格
上述代码的输出结果如图 5 所示:

图 5: 结构化视频字幕生成结果(来源:作者提供的图像)
结论
本文系统介绍了 Qwen 2.5 VL 模型在视频理解与定位任务中的先进能力。该模型通过创新的动态帧率调整、绝对时间编码和多模态旋转位置嵌入(MRoPE)等技术,显著提升了对视频时空信息的理解能力,并实现了多模态数据的高效对齐。这些技术创新与精心设计的训练方法相结合,使 Qwen 2.5 在处理复杂视频场景时展现出卓越的性能。
本文提供了从环境配置到模型部署的完整实践指南,包括工具函数实现和推理流程设计,使读者能够快速掌握 Qwen 2.5 视频理解的核心技术。通过视频文本提取、内容理解、精确定位和结构化字幕生成等案例,展示了该模型在不同应用场景下的实用价值。
Qwen 2.5 VL 模型在视频理解领域的突破,不仅体现在技术创新层面,更在于其将复杂的视频分析任务变得更加易用和高效。未来,随着模型性能的进一步提升和应用场景的不断拓展,Qwen 2.5 有望在智能监控、内容创作、教育培训等多个领域发挥重要作用,推动视频理解技术的实际应用和产业发展。