【完整源码+数据集+部署教程】农作物病害检测系统源码和数据集:改进yolo11-HSFPN
背景意义
研究背景与意义
随着全球人口的不断增长,农业生产面临着巨大的挑战,尤其是在作物病害的管理和控制方面。农作物病害不仅影响作物的产量和质量,还对农民的经济收入造成了严重影响。因此,开发高效、准确的病害检测系统显得尤为重要。近年来,计算机视觉技术的迅猛发展为农业病害检测提供了新的解决方案。基于深度学习的目标检测模型,尤其是YOLO(You Only Look Once)系列模型,因其在实时检测和高精度方面的优势,成为了研究的热点。
本研究旨在基于改进的YOLOv11模型,构建一个针对农作物病害的检测系统。我们使用的数据集包含1700张图像,涵盖了六种主要的病害类别,包括细菌性穗腐病、假黑穗病、健康水稻叶、健康水稻粒、感染性稻瘟病和叶螟。这些类别的选择不仅反映了当前农业生产中常见的病害类型,也为模型的训练提供了丰富的样本数据。通过对这些图像的实例分割和目标检测,我们希望能够实现对农作物病害的快速识别和分类,从而为农民提供及时的病害预警和管理建议。
此外,随着人工智能技术的不断进步,基于YOLOv11的农作物病害检测系统将能够在实际应用中实现更高的准确性和效率。这不仅有助于提高农业生产的智能化水平,也为实现可持续农业发展提供了技术支持。通过本研究,我们期望能够为农业领域的病害管理提供一种新的思路和方法,推动农业科技的进步和农民收入的增加。
图片效果
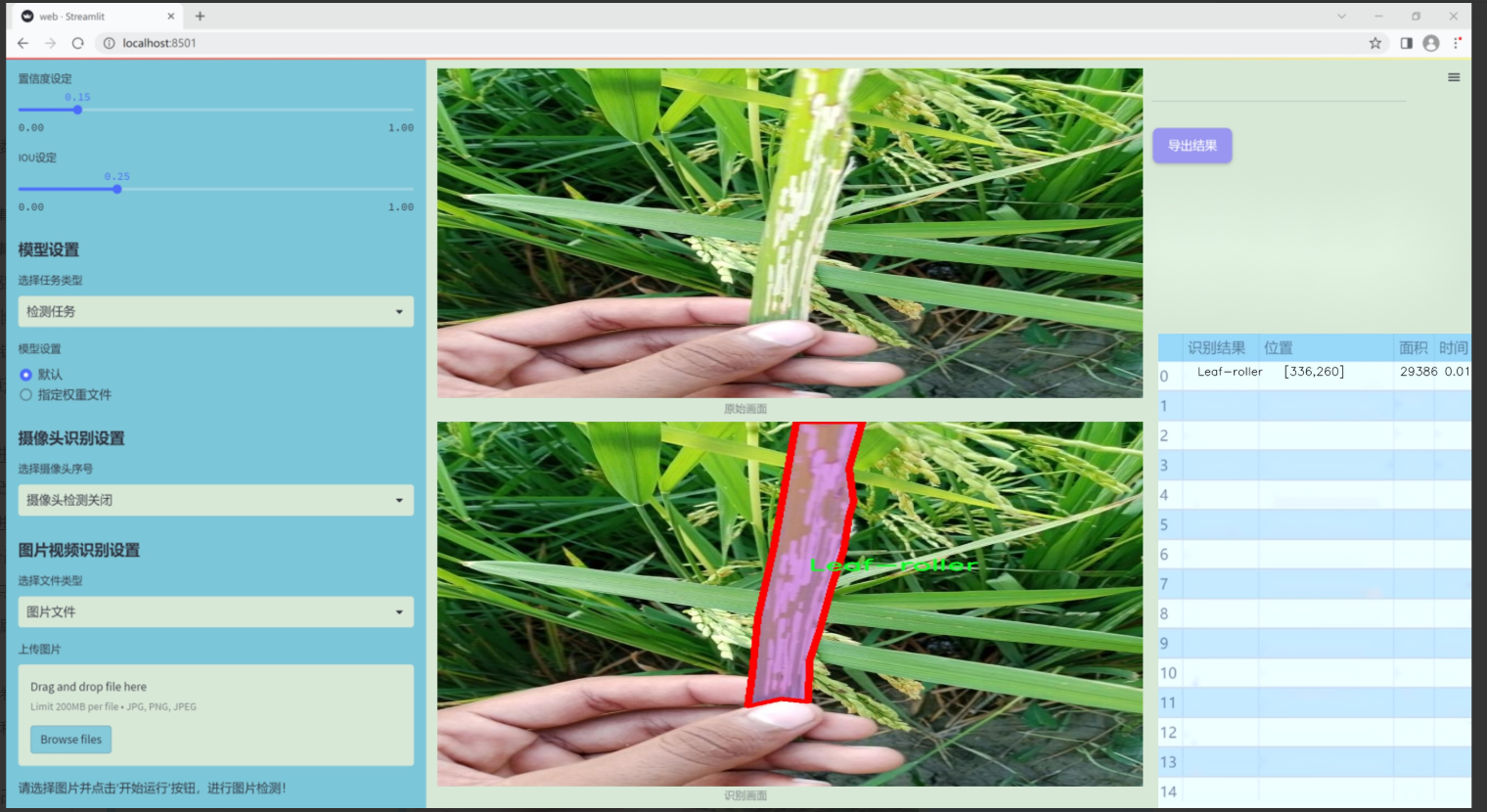
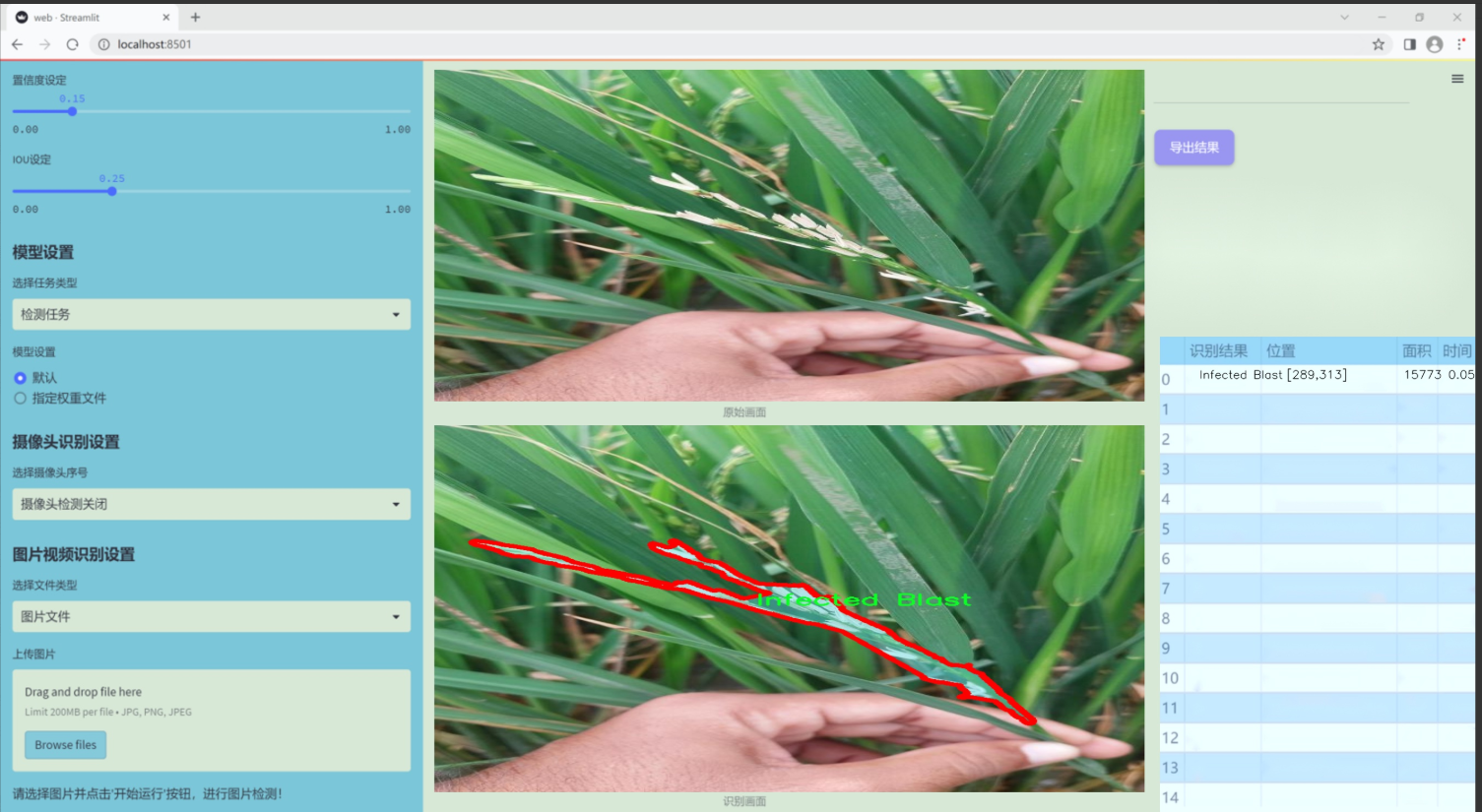
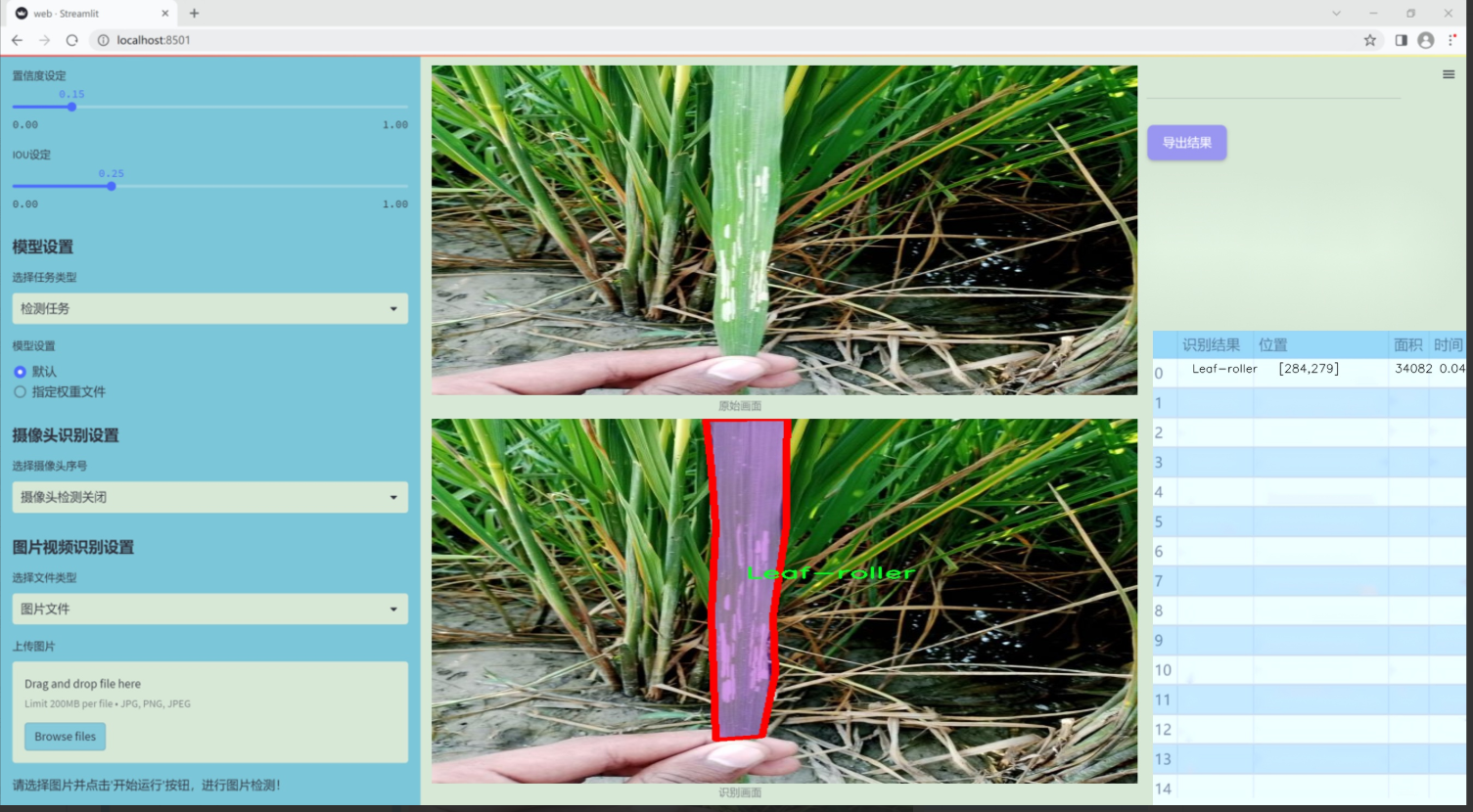
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的农作物病害检测系统,所使用的数据集专注于农业领域,特别是水稻病害的识别与分类。该数据集包含六个主要类别,涵盖了水稻在生长过程中可能遭遇的各种病害及健康状态。这些类别包括“Bacterial panicle Blight”(细菌性穗腐病)、“False-Smut”(假黑穗病)、“Healthy Rice Leaf”(健康水稻叶)、“Healthy Rice beads”(健康水稻珠)、“Infected Blast”(稻瘟病)以及“Leaf-roller”(叶螟)。通过对这些类别的细致划分,数据集不仅为模型提供了丰富的训练样本,也为后续的病害检测提供了明确的目标和参考。
在数据集的构建过程中,特别注重样本的多样性和代表性,以确保模型在实际应用中具备良好的泛化能力。每个类别的样本均经过精心挑选,确保涵盖不同生长阶段、不同环境条件下的表现。这种多样性不仅有助于提升模型的准确性,还能增强其对各种病害的识别能力,从而在实际农业生产中发挥更大的作用。
此外,数据集的标注过程也遵循严格的标准,确保每个样本的标签准确无误。通过这种方式,研究团队能够有效地训练和验证YOLOv11模型,提升其在农作物病害检测中的性能。随着农业技术的不断进步,利用深度学习方法进行病害检测将成为未来农业管理的重要工具,而本项目的数据集正是实现这一目标的重要基础。通过不断优化和扩展数据集,我们期望能够为农业生产提供更为精准和高效的病害检测解决方案。





核心代码
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
“”"
将卷积核和批归一化层的参数融合,返回融合后的卷积核和偏置。
“”"
gamma = bn.weight # 获取批归一化的缩放因子
std = (bn.running_var + bn.eps).sqrt() # 计算标准差
# 融合卷积核和批归一化参数
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1):
“”"
创建一个卷积层和一个批归一化层的组合。
“”"
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False) # 创建卷积层,不使用偏置
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True) # 创建批归一化层
return nn.Sequential(conv_layer, bn_layer) # 返回组合的层
class DiverseBranchBlock(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=None, dilation=1, groups=1):
“”"
初始化DiverseBranchBlock模块,包含多个分支的卷积操作。
“”"
super(DiverseBranchBlock, self).init()
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
if padding is None:padding = kernel_size // 2 # 默认填充为卷积核大小的一半# 原始卷积和批归一化self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)# 平均池化分支self.dbb_avg = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels),nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))# 1x1卷积分支self.dbb_1x1_kxk = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels))def forward(self, inputs):"""前向传播,计算输出。"""out = self.dbb_origin(inputs) # 通过原始卷积分支out += self.dbb_avg(inputs) # 加上平均池化分支out += self.dbb_1x1_kxk(inputs) # 加上1x1卷积分支return out # 返回最终输出def get_equivalent_kernel_bias(self):"""获取等效的卷积核和偏置,用于部署时的卷积层。"""k_origin, b_origin = transI_fusebn(self.dbb_origin[0].weight, self.dbb_origin[1]) # 融合原始卷积的权重和偏置k_avg, b_avg = transI_fusebn(self.dbb_avg[0].weight, self.dbb_avg[1]) # 融合平均池化分支的权重和偏置k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1_kxk[0].weight, self.dbb_1x1_kxk[1]) # 融合1x1卷积分支的权重和偏置# 返回所有分支的卷积核和偏置的总和return (k_origin + k_avg + k_1x1), (b_origin + b_avg + b_1x1)
示例使用
block = DiverseBranchBlock(in_channels=64, out_channels=128, kernel_size=3)
output = block(torch.randn(1, 64, 224, 224)) # 输入一个随机张量
代码注释说明:
transI_fusebn: 该函数用于将卷积层的权重与批归一化层的参数融合,以便在推理时简化计算。
conv_bn: 该函数创建一个包含卷积层和批归一化层的组合模块,便于后续使用。
DiverseBranchBlock: 这是一个自定义的神经网络模块,包含多个分支(原始卷积、平均池化和1x1卷积),用于实现多样化的特征提取。
forward: 定义了模块的前向传播逻辑,计算输入的输出。
get_equivalent_kernel_bias: 该方法用于获取融合后的卷积核和偏置,适用于模型部署阶段。
这个程序文件 rep_block.py 是一个实现多分支卷积块的深度学习模块,主要用于构建复杂的卷积神经网络(CNN)结构。文件中定义了多个类和函数,主要包括 DiverseBranchBlock、WideDiverseBranchBlock 和 DeepDiverseBranchBlock,它们都继承自 torch.nn.Module,并实现了不同的卷积操作。
首先,文件导入了必要的库,包括 torch 和 torch.nn,以及一些自定义的卷积模块和功能函数。接下来,定义了一些用于卷积和批归一化的转换函数,这些函数主要用于处理卷积核和偏置的融合、分支的合并等操作。
conv_bn 函数用于创建一个包含卷积层和批归一化层的序列模块,方便后续的使用。IdentityBasedConv1x1 类实现了一个特殊的 1x1 卷积层,确保在特定条件下保留输入的特征。
BNAndPadLayer 类实现了一个结合批归一化和填充的层,能够在进行批归一化后,对输出进行填充处理,以保持特征图的尺寸。
DiverseBranchBlock 类是一个多分支卷积块的实现,包含多个分支的卷积操作,包括常规卷积、1x1 卷积和平均池化等。该类的构造函数中根据输入参数初始化不同的卷积层和批归一化层,并提供了切换到部署模式的方法,以便在推理时使用融合后的卷积核和偏置。
DiverseBranchBlockNOAct 类是一个没有激活函数的多分支卷积块实现,适用于某些特定的网络结构。DeepDiverseBranchBlock 类则在 DiverseBranchBlock 的基础上进行了扩展,增加了更多的卷积操作和分支,以提高模型的表达能力。
WideDiverseBranchBlock 类实现了宽卷积块,支持在训练过程中进行垂直和水平卷积的操作,以增强模型对不同方向特征的捕捉能力。
每个类都实现了 forward 方法,用于定义前向传播的计算过程。此外,许多类还实现了初始化权重和偏置的方法,以便在训练开始时设置合适的初始值。
总的来说,这个文件提供了一种灵活的方式来构建复杂的卷积神经网络结构,支持多种卷积操作和分支设计,适用于各种计算机视觉任务。
10.4 efficientViT.py
以下是经过简化和注释的核心代码部分,保留了 EfficientViT 模型的主要结构和功能。
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import SqueezeExcite
定义卷积层和批归一化的组合
class Conv2d_BN(torch.nn.Sequential):
def init(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0):
super().init()
# 添加卷积层
self.add_module(‘conv’, nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False))
# 添加批归一化层
self.add_module(‘bn’, nn.BatchNorm2d(out_channels))
@torch.no_grad()
def switch_to_deploy(self):# 将训练模式下的层转换为推理模式下的层conv, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps)**0.5w = conv.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5return nn.Conv2d(w.size(1), w.size(0), w.shape[2:], stride=conv.stride, padding=conv.padding, bias=True).to(w.device).copy_(w), b
定义高效的 ViT 模块
class EfficientViTBlock(torch.nn.Module):
def init(self, embed_dim, key_dim, num_heads=8):
super().init()
# 残差卷积层
self.dw = nn.Sequential(
Conv2d_BN(embed_dim, embed_dim, kernel_size=3, stride=1, padding=1, groups=embed_dim),
nn.ReLU()
)
# 前馈网络
self.ffn = nn.Sequential(
Conv2d_BN(embed_dim, embed_dim * 2, kernel_size=1),
nn.ReLU(),
Conv2d_BN(embed_dim * 2, embed_dim, kernel_size=1)
)
# 局部窗口注意力
self.attn = LocalWindowAttention(embed_dim, key_dim, num_heads)
def forward(self, x):# 前向传播x = self.dw(x) + x # 残差连接x = self.attn(x) + x # 注意力连接x = self.ffn(x) + x # 前馈网络连接return x
定义局部窗口注意力机制
class LocalWindowAttention(torch.nn.Module):
def init(self, dim, key_dim, num_heads=8):
super().init()
self.attn = CascadedGroupAttention(dim, key_dim, num_heads)
def forward(self, x):return self.attn(x)
定义高效的 ViT 模型
class EfficientViT(torch.nn.Module):
def init(self, img_size=224, embed_dim=[64, 128, 192], depth=[1, 2, 3], num_heads=[4, 4, 4]):
super().init()
self.patch_embed = nn.Sequential(
Conv2d_BN(3, embed_dim[0] // 8, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
Conv2d_BN(embed_dim[0] // 8, embed_dim[0] // 4, kernel_size=3, stride=2, padding=1),
nn.ReLU()
)
# 定义多个块
self.blocks = nn.ModuleList()
for i in range(len(depth)):
for _ in range(depth[i]):
self.blocks.append(EfficientViTBlock(embed_dim[i], key_dim=16, num_heads=num_heads[i]))
def forward(self, x):x = self.patch_embed(x)for block in self.blocks:x = block(x)return x
示例模型实例化
if name == ‘main’:
model = EfficientViT()
inputs = torch.randn((1, 3, 224, 224)) # 输入一个224x224的图像
output = model(inputs)
print(output.size()) # 输出特征图的尺寸
代码注释说明:
Conv2d_BN: 这个类定义了一个卷积层和批归一化层的组合,便于构建高效的卷积神经网络。
EfficientViTBlock: 这是高效 ViT 模型的基本构建块,包含残差卷积、前馈网络和局部窗口注意力机制。
LocalWindowAttention: 该类实现了局部窗口注意力机制,利用注意力机制增强特征表示。
EfficientViT: 这是整个高效 ViT 模型的定义,包含多个块的堆叠和图像的嵌入处理。
主程序: 在主程序中实例化模型并传入一个随机生成的输入张量,输出特征图的尺寸。
以上代码为 EfficientViT 模型的核心部分,去除了冗余部分,保留了主要功能并进行了详细注释。
这个程序文件实现了一个高效的视觉变换器(EfficientViT)模型架构,旨在用于下游任务。代码中定义了多个类和函数,构成了整个模型的结构。
首先,程序导入了必要的库,包括PyTorch及其相关模块。接着,定义了一个名为Conv2d_BN的类,该类继承自torch.nn.Sequential,用于创建一个包含卷积层和批归一化层的组合。它的构造函数中设置了卷积层的参数,并初始化了批归一化层的权重和偏置。该类还提供了一个switch_to_deploy方法,用于在推理时将卷积层和批归一化层融合,以提高推理效率。
接下来,定义了一个replace_batchnorm函数,用于替换模型中的批归一化层为恒等映射,以便在推理时减少计算开销。
PatchMerging类实现了一个用于合并图像块的模块,包含多个卷积层和激活函数。它通过逐层处理输入,最终输出合并后的特征图。
Residual类实现了残差连接的功能,允许在训练时随机丢弃部分输入,以增强模型的鲁棒性。
FFN类实现了前馈神经网络模块,包含两个卷积层和一个ReLU激活函数。
CascadedGroupAttention类实现了级联组注意力机制,支持多头注意力和自适应的注意力偏置。该模块通过对输入特征进行分块处理,计算注意力权重,并将其应用于输入特征。
LocalWindowAttention类实现了局部窗口注意力机制,允许在较小的窗口内计算注意力,从而提高计算效率。
EfficientViTBlock类是一个基本的EfficientViT构建块,包含多个卷积层、前馈网络和注意力机制的组合。
EfficientViT类是整个模型的核心,负责构建整个网络结构。它首先通过patch_embed模块将输入图像嵌入到特征空间中,然后依次通过多个EfficientViT块进行处理。模型的参数包括图像大小、补丁大小、嵌入维度、深度、头数等。
在文件的最后部分,定义了多个不同配置的EfficientViT模型(如EfficientViT_m0到EfficientViT_m5),并提供了加载预训练权重和替换批归一化层的功能。
最后,程序的主入口部分创建了一个EfficientViT模型实例,并对随机生成的输入进行前向传播,输出每个阶段的特征图尺寸。这一部分展示了如何使用该模型进行推理。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式