Java-面试八股文-并发编程篇
一.线程和进程的区别是什么?
线程和进程是操作系统中并发执行的两个基本单位。
-
进程(Process)
👉 程序在操作系统中的一次运行实例,是资源分配的最小单位。
每个进程有自己独立的内存空间(代码区、数据区、堆、栈),切换时需要上下文切换,进程切换需要保存和恢复大量上下文,开销大。 -
线程(Thread)
👉 进程中的一个执行流,是 CPU 调度的最小单位。
一个进程可以包含多个线程,这些线程共享该进程的资源(如内存、文件句柄),线程切换开销相对小。
二.并行和并发的区别是什么?
1. 概念
-
并发(Concurrency)
👉 多个任务在同一时间段内交替执行,宏观上“同时进行”,微观上可能还是串行的。- 强调:任务的交替和管理
- 比如:单核 CPU 通过时间片轮转来执行多个任务,看起来好像同时在运行。
-
并行(Parallelism)
👉 多个任务在同一时刻真正同时执行。- 强调:任务的同时执行
- 比如:多核 CPU 上,不同核心各自执行一个任务。
2. 区别表格
| 维度 | 并发(Concurrency) | 并行(Parallelism) |
|---|---|---|
| 执行本质 | 任务交替执行 | 任务同时执行 |
| 硬件依赖 | 单核或多核都能实现 | 必须多核或分布式才能实现 |
| 关注点 | 如何管理和调度多个任务 | 如何提高任务的执行速度 |
| 例子 | 一个 CPU 轮流切换执行多个程序 | 多个 CPU 核心同时运行多个程序 |
| 比喻 | 1 个厨师轮流炒几道菜 | 多个厨师同时各炒一道菜 |
三.创建线程的方式有哪些?
1. 继承 Thread 类
重写 run() 方法,然后调用 start() 启动线程。
class MyThread extends Thread {@Overridepublic void run() {System.out.println("线程运行:" + Thread.currentThread().getName());}
}public class Demo {public static void main(String[] args) {MyThread t1 = new MyThread();t1.start(); // 启动线程,调用 run()}
}
✅ 简单直观
❌ 不能再继承其他类(Java 单继承限制)
2. 实现 Runnable 接口
实现 Runnable 的 run() 方法,然后用 Thread 包装并启动。
class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("线程运行:" + Thread.currentThread().getName());}
}public class Demo {public static void main(String[] args) {Thread t1 = new Thread(new MyRunnable());t1.start();}
}
✅ 更灵活,可以避免单继承的限制,适合多个线程共享同一个任务对象。
3. 实现 Callable 接口 + FutureTask
Callable 可以有返回值,还能抛出异常。
import java.util.concurrent.*;class MyCallable implements Callable<String> {@Overridepublic String call() {return "线程执行完成:" + Thread.currentThread().getName();}
}public class Demo {public static void main(String[] args) throws Exception {FutureTask<String> futureTask = new FutureTask<>(new MyCallable());new Thread(futureTask).start();System.out.println(futureTask.get()); // 阻塞等待结果}
}
✅ 能获取返回值,适合有结果的任务。
4. 使用线程池(推荐 ✅)
通过 ExecutorService 或 Executors 提供的线程池来创建和管理线程。
import java.util.concurrent.*;public class Demo {public static void main(String[] args) {ExecutorService pool = Executors.newFixedThreadPool(3);pool.execute(() -> System.out.println("线程池执行任务:" + Thread.currentThread().getName()));pool.shutdown();}
}
✅ 高效,避免频繁创建/销毁线程,适合生产环境。
四.runnable和callable接口的区别是什么?
Runnable 和 Callable 是 Java 中两种常见的任务接口,它们主要用来表示需要被线程执行的任务。二者既有相似点也有明显区别。
1. 相同点
- 都可以被线程执行,通常通过
Thread或线程池来启动。 - 都代表一个需要执行的任务,封装了业务逻辑。
2. 不同点
| 对比点 | Runnable | Callable |
|---|---|---|
| 定义方法 | public void run() | public V call() throws Exception |
| 返回值 | 无返回值(void) | 有返回值(泛型 V) |
| 异常处理 | 不能抛出受检异常(checked exception),仅支持自检查try-catch异常 | 可以抛出异常 |
| 使用方式 | 通常作为 new Thread(runnable).start() 或 Executor.execute(runnable) | 通常与 Future、FutureTask 搭配,用 submit() 提交给线程池 |
| 适用场景 | 执行不需要返回结果的任务 | 执行需要返回结果的任务 |
五.run()和start()有什么区别?
1. run() 方法
- 定义:
run()是Thread类或Runnable接口里定义的方法。 - 调用效果:如果直接调用
run(),它只是一个普通方法调用,不会开启新线程,代码仍在主线程中顺序执行。 - 本质:普通的函数调用。
2. start() 方法
- 定义:
start()是Thread类的方法。 - 调用效果:
start()会通知 JVM 创建一个新的线程,由该线程去执行run()方法里的逻辑。 - 本质:真正地开启一条新的执行路径(子线程)。
三. 关键区别总结
| 对比点 | run() | start() |
|---|---|---|
| 是否启动新线程 | ❌ 不会 | ✅ 会 |
| 执行者 | 仍是当前线程(一般是 main) | 新建一个子线程 |
| 调用次数 | 可以反复调用 | 只能调用一次(否则抛 IllegalThreadStateException) |
| 本质 | 普通方法 | JVM 调度,触发线程生命周期 |
六.在Java中线程包括那些状态,状态是如何变化的?
1. Java 线程的六种状态
Java 使用 Thread.State 枚举类 定义了 6 种状态:
-
NEW(新建)
- 刚创建,还没调用
start()。 - 示例:
Thread t = new Thread(runnable);
- 刚创建,还没调用
-
RUNNABLE(就绪/可运行)
- 调用
start()后进入该状态,等待 CPU 调度。 - 注意:Java 把 就绪 和 运行中 都归为
RUNNABLE,具体由操作系统调度。
- 调用
-
BLOCKED(阻塞)
- 线程在等待 获取某个对象的锁 时进入该状态。
- 示例:两个线程同时进入同步代码块,一个持有锁,另一个就进入 BLOCKED。
-
WAITING(无限等待)
- 调用
Object.wait()进入等待状态,需要其他线程显式唤醒(notify()/notifyAll())。 - 没有时间限制。
- 调用
-
TIMED_WAITING(计时等待)
- 在指定时间内等待,时间到后自动恢复。
- 示例:
Thread.sleep(ms)、join(ms)、wait(ms)、LockSupport.parkNanos()。
-
TERMINATED(终止)
- 线程执行完毕或抛出异常结束,进入终止状态。
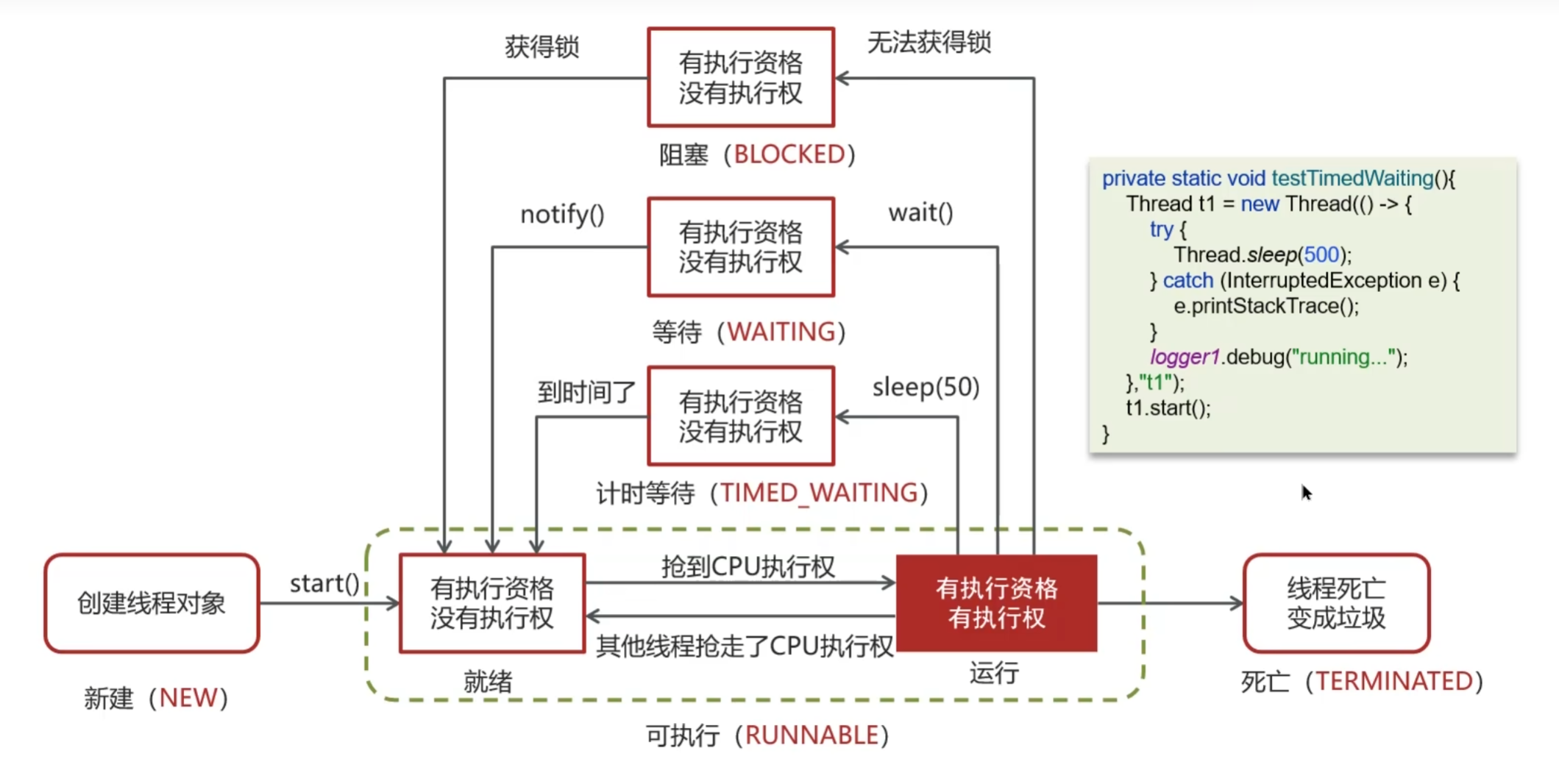
2. 具体状态转化说明
- NEW → RUNNABLE:调用
start()。 - RUNNABLE → RUNNING:获得 CPU 时间片(由操作系统决定)。
- RUNNING → BLOCKED:尝试获取对象锁失败。
- RUNNING → WAITING:调用
wait(),等待唤醒。 - RUNNING → TIMED_WAITING:调用
sleep(ms)、join(ms)等。 - WAITING / TIMED_WAITING / BLOCKED → RUNNABLE:被唤醒 / 时间到 / 获得锁。
- RUNNING → TERMINATED:任务执行完成或异常退出。
七.新建T1,T2,T3三个线程,如何保证他们按顺序执行?
使用 join()
join() 会让当前线程等待目标线程执行完毕。
public class ThreadOrderDemo {public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> System.out.println("T1 执行"));Thread t2 = new Thread(() -> System.out.println("T2 执行"));Thread t3 = new Thread(() -> System.out.println("T3 执行"));t1.start();t1.join(); // 等待 T1 执行完t2.start();t2.join(); // 等待 T2 执行完t3.start();t3.join(); // 等待 T3 执行完}
}
✅ 简单,保证严格顺序。
八.notify()和notifyAll()有什么区别?
| 方法 | 含义 | 特点 |
|---|---|---|
| notify() | 随机唤醒 一个正在 wait() 的线程 | 只唤醒一个,其他仍然等待,效率高,但可能出现“遗漏唤醒”问题 |
| notifyAll() | 唤醒 所有正在 wait() 的线程 | 所有等待的线程都进入就绪队列,竞争锁,保证不会遗漏,但效率低(唤醒一堆线程再让它们竞争) |
九.Java中wait和sleep方法有什么不同?
1. 相同点
- 都能让线程 暂停执行。
- 都可以被 中断(
InterruptedException)。
2. 不同点
| 对比点 | wait() | sleep() |
|---|---|---|
| 所属类 | Object(所有对象都能调用) | Thread |
| 是否释放锁 | ✅ 会释放当前持有的对象锁(monitor) | ❌ 不会释放锁 |
| 使用环境 | 只能在 同步代码块 / 同步方法 中调用(必须持有锁) | 可以在任意地方调用 |
| 唤醒方式 | 需要被其他线程调用 notify() 或 notifyAll()(或超时 wait(ms)) | 时间到自动唤醒,或者被中断 |
| 目的 | 用于线程之间的 通信/协作 | 用于 暂停执行 一段时间 |
| 语法签名 | wait() / wait(long timeout) | sleep(long millis) |
3. 举例对比
sleep() 示例
public class SleepDemo {public static void main(String[] args) throws InterruptedException {synchronized (SleepDemo.class) {System.out.println("开始睡眠");Thread.sleep(2000); // 不会释放锁System.out.println("睡眠结束");}}
}
👉 如果有另一个线程也想进入 synchronized,会被阻塞到 sleep() 结束。
wait() 示例
public class WaitDemo {private static final Object lock = new Object();public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {synchronized (lock) {try {System.out.println("线程进入等待");lock.wait(); // 会释放锁System.out.println("线程被唤醒");} catch (InterruptedException e) {}}});t1.start();Thread.sleep(1000); // 确保 t1 先进入 waitsynchronized (lock) {System.out.println("唤醒线程");lock.notify();}}
}
👉 wait() 会释放锁,让其他线程可以进入同步块,直到被 notify() 唤醒。
十.如何停止一个正在运行的线程?
推荐的方式 ✅
方式一:使用 标志位(volatile 变量)
通过设置一个共享变量来通知线程“要结束了”。
public class StopThreadDemo implements Runnable {private volatile boolean running = true; // 标志位@Overridepublic void run() {while (running) {System.out.println("线程运行中:" + Thread.currentThread().getName());try { Thread.sleep(500); } catch (InterruptedException e) { }}System.out.println("线程结束");}public void stop() {running = false;}public static void main(String[] args) throws InterruptedException {StopThreadDemo task = new StopThreadDemo();Thread t = new Thread(task);t.start();Thread.sleep(2000);task.stop(); // 修改标志位,通知线程退出}
}
✅ 安全、优雅,适合大多数业务场景。
方式二:使用 interrupt()
- 线程调用阻塞方法(如
sleep()、wait()、join())时,可以通过interrupt()来打断。 - 自己需要在代码里检测中断状态。
public class InterruptDemo {public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {while (!Thread.currentThread().isInterrupted()) {try {Thread.sleep(500);System.out.println("线程运行中...");} catch (InterruptedException e) {System.out.println("线程被中断,准备退出");Thread.currentThread().interrupt(); // 再次设置中断标志位}}});t.start();Thread.sleep(2000);t.interrupt(); // 中断线程}
}
✅ 更专业,尤其适合和阻塞方法配合使用。
十一.synchronized关键字的底层原理?
后续完成
十二.谈谈你对JMM(Java内存模型)的理解?
1、为什么需要 JMM?
在多线程编程中,线程之间如何共享和传递数据是核心问题。
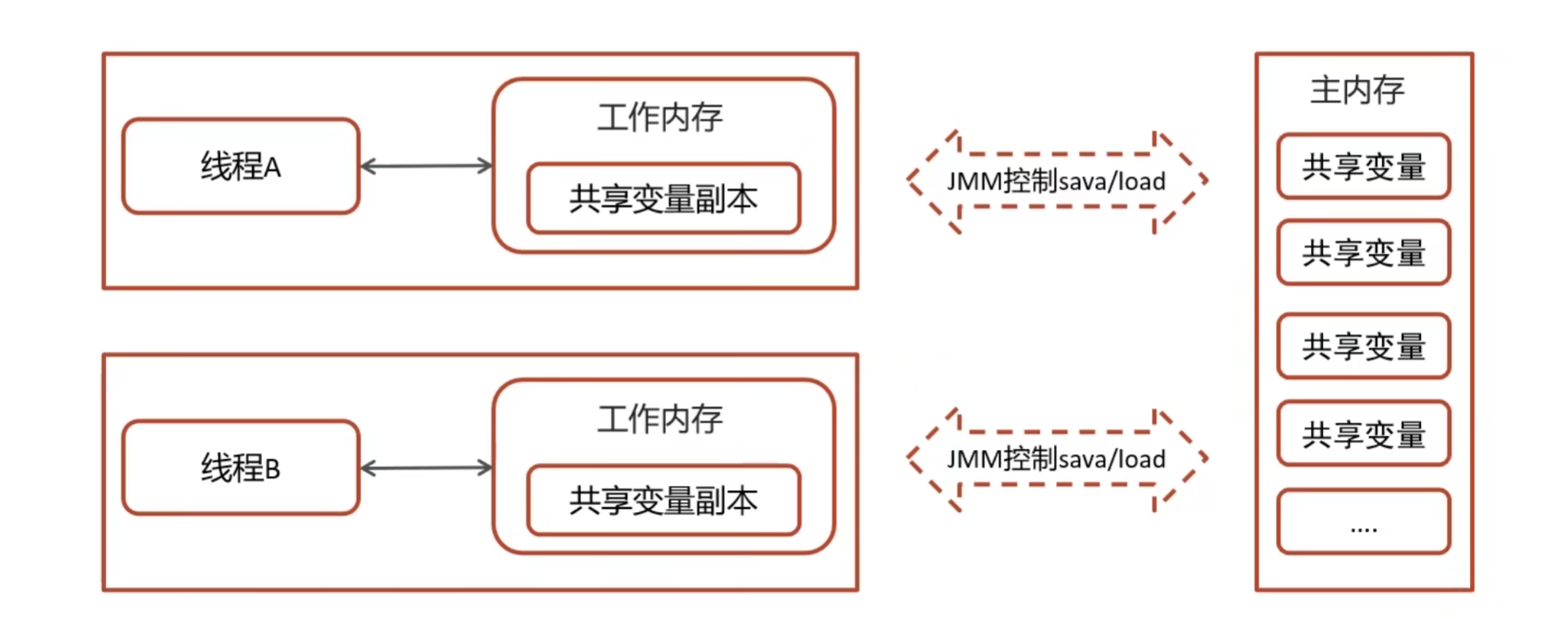
- 每个线程都有自己的 工作内存(线程栈 + CPU缓存);
- 主存(堆 + 方法区)存放所有共享变量;
- 线程对变量的操作不是直接在主存上进行的,而是先拷贝到自己的工作内存,再操作,最后可能会刷新回主存。
⚠️ 这就可能导致 可见性问题:线程 A 修改了变量,线程 B 看不到。
👉 为了解决这种 可见性、有序性、原子性 问题,Java 定义了 JMM(Java Memory Model)。
2、JMM 的三大特性
-
原子性(Atomicity)
- 一组操作要么全部成功,要么全部失败,不会被线程切换中断。
synchronized、Lock可以保证代码块的原子性。
-
可见性(Visibility)
- 当一个线程修改了共享变量,其他线程能立刻看到最新值。
volatile、synchronized、Lock都能保证可见性。
-
有序性(Ordering)
- 程序执行的顺序和代码编写顺序不一定一致(JIT 和 CPU 会指令重排)。
- JMM 通过 happens-before 原则 来保证逻辑上的有序性。
十三.你知道CAS吗,能不能谈谈你对他的理解?
1. 什么是 CAS?
CAS 即compare And Swap (比较并交换),是一种 原子操作。
它的逻辑很简单:
- 比较内存中某个变量的值 是否等于预期值;
- 如果相等,就更新为新值;
- 如果不相等,说明被其他线程改过了,更新失败。
就像乐观锁的思想:我先假设别人不会改,如果发现别人改了,就重试。
2. CAS 的底层实现
在 Java 中,CAS 主要通过 Unsafe 类的 compareAndSwapXXX 方法实现。
底层依赖 CPU 的原子指令(比如 cmpxchg),保证在硬件层面只有一个线程能成功更新值(C++实现)。
简化伪代码:
boolean compareAndSwap(int[] arr, int index, int expectedValue, int newValue) {synchronized (this) {if (arr[index] == expectedValue) {arr[index] = newValue;return true;}return false;}
}
(实际中是用 CPU 原子指令实现的,不需要 synchronized)
3. CAS 的优点
- 无锁化:线程不会因为竞争锁而阻塞,性能比
synchronized好。 - 高效:适合高并发环境下,失败时只需要 重试。
- 被广泛应用:JUC 包中的
AtomicInteger、ConcurrentHashMap、AQS等都基于 CAS。
4. CAS 的缺点
-
ABA 问题
- 假设线程 1 读取到值 A,准备改成 B。
- 在此期间线程 2 把值 A 改成 C,又改回 A。
- 线程 1 看到的还是 A,于是 CAS 成功,但实际上值已经被改过。
- 解决方案:版本号机制(
AtomicStampedReference)。
-
自旋开销大
- CAS 失败时会不停重试,如果冲突严重,会造成 CPU 空转。
-
只能保证一个变量的原子操作
- 对多个变量的操作 CAS 无能为力。
- 解决方案:
AtomicReference或者加锁。
5. 总结
- CAS = 乐观锁思想 + CPU 原子指令支持。
- 优点:高效、无锁。
- 缺点:ABA 问题、自旋开销、只能作用于单变量。
- 应用场景:JUC 的
AtomicXXX、并发容器、锁框架 AQS 等。
十三.乐观锁和悲观锁有什么区别?
1. 悲观锁(Pessimistic Lock)
- 思想:对数据持悲观态度,认为只要我不用锁,别人就会来修改,所以在访问数据时先加锁,保证同一时间只有一个线程能操作。
- 实现方式:数据库的行锁、表锁,Java 里的
synchronized、ReentrantLock。 - 优点:简单、直接,能有效避免并发冲突。
- 缺点:性能开销大(阻塞、上下文切换),不适合读多写少的场景。
2. 乐观锁(Optimistic Lock)
- 思想:对数据持乐观态度,认为冲突不会经常发生,所以不加锁,操作时只在提交时校验是否冲突。
- 实现方式:CAS(Compare-And-Swap)、数据库中的版本号字段(version)。
- 优点:没有锁的开销,适合读多写少的高并发场景。
- 缺点:如果冲突频繁,会不断重试,导致性能下降。
3. 直观对比
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 并发策略 | 先加锁,阻塞其他线程 | 不加锁,提交时检查是否冲突 |
| 实现方式 | synchronized、ReentrantLock | CAS、自旋、版本号机制 |
| 性能 | 并发度低,性能损耗大 | 并发度高,性能更好 |
| 适用场景 | 冲突严重、写多读少 | 冲突少、读多写少 |
| 问题 | 线程阻塞、死锁 | ABA 问题、频繁重试 |
十四.什么是AQS?
AQS 全称是 AbstractQueuedSynchronizer, 就是一个 基于状态(state)+ 队列(CLH 变种)+ 模板方法 的同步器框架,它把“线程等待与唤醒”的通用逻辑抽取出来,具体的资源获取和释放规则交给子类实现,从而极大简化了并发工具的开发。
它是 JUC 锁和同步器的基础框架,例如:
- ReentrantLock(可重入锁)
- Semaphore(信号量)
- CountDownLatch(倒计时器)
- ReentrantReadWriteLock(读写锁)
- FutureTask(任务框架)
这些同步工具的底层实现基本都是基于 AQS 来完成的。
1. AQS 的核心思想
AQS 通过一个 volatile int state(共享资源)来表示同步状态,并通过 FIFO 的等待队列(CLH 队列变种) 来管理获取资源失败的线程。
-
state:表示锁的占用情况
- 对于独占锁(如 ReentrantLock):0 表示未被占用,1 表示已被占用。
- 对于共享锁(如 Semaphore):state 表示剩余许可数。
-
队列:获取锁失败的线程会被包装成一个节点(Node),进入一个双向链表(同步队列),挂起等待。
2. AQS 提供的主要模式
AQS 提供了两种模式:
-
独占模式(Exclusive)
- 一个线程独占资源。
- 如 ReentrantLock。
-
共享模式(Shared)
- 多个线程可以同时访问资源。
- 如 Semaphore、CountDownLatch、读写锁的读锁。
3. 工作流程(以独占锁为例)
-
线程调用
acquire()尝试获取锁。 -
内部调用
tryAcquire()判断能否获取锁。- 如果成功,直接返回。
- 如果失败,线程进入 同步队列,并被阻塞(park)。
-
当锁释放时(
release()),会调用tryRelease()改变 state。 -
然后唤醒队列中的下一个等待线程,让它去竞争锁。
十五.在AQS中,多个线程共同抢夺资源是如何保证原子性呢?
AQS 之所以能在多线程竞争中保证 原子性,核心在于它结合了 volatile 内存可见性 和 CAS(Compare-And-Swap) 原子操作。
🔑 1. AQS 的关键字
AQS 里最重要的字段就是:
// 共享资源状态
private volatile int state;
- volatile:保证不同线程读取到的 state 值是最新的。
- CAS 操作(通过 Unsafe 类实现):保证修改 state 的时候是原子性的。
🔑 2. CAS 保证原子性
AQS 并不会直接用 synchronized 来保证并发安全,而是用 CAS 来做状态更新:
protected final boolean compareAndSetState(int expect, int update) {return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
原理:
- CAS(比较并交换) 会判断
state是否等于期望值expect。 - 如果相等,则将其更新为
update,并返回 true(更新成功)。 - 如果不相等,说明有其他线程已经修改过了,本次更新失败,返回 false。
这样就能保证 多个线程同时修改 state 时不会出现并发冲突。
🔑 3. 线程排队(CLH 队列)保证公平
如果 CAS 失败,说明有其他线程成功获取了锁,这时当前线程会进入 AQS 的队列(基于 CLH 队列的变种),等待前驱节点释放锁:
- 入队过程本身也使用 CAS 保证原子性(避免两个线程同时插入出错)。
- 队列保证了获取锁的顺序性和可控性。
🔑 4. 举例
假设多个线程调用 acquire(1):
- 线程 A 调用
tryAcquire()→ 内部用CAS将state从 0 改为 1 → 成功获取锁。 - 线程 B 也调用
tryAcquire()→ CAS 失败(因为 state 已是 1) → 入队等待。 - 当 A 调用
release(1)时 → 内部 CAS 把state改为 0 → 唤醒队列中的线程 B → B 再次尝试 CAS 获取锁。
十六. ReentrantLock 的实现原理?
它的底层就是基于 AQS(AbstractQueuedSynchronizer) 实现的。
1. ReentrantLock 的核心特点
-
可重入性:同一个线程可以多次获得同一把锁,内部维护一个计数器(state)。
-
互斥性:同一时间只能有一个线程持有锁。
-
支持公平/非公平模式:
- 非公平锁(默认):线程来就直接尝试抢锁,成功了就进入,不管队列里有没有等待的。
- 公平锁:必须按队列的顺序来,一个个排队获取。
2. 结构概览
ReentrantLock 内部有一个 静态内部类 Sync 继承了 AQS:
abstract static class Sync extends AbstractQueuedSynchronizer {abstract void lock();// AQS 提供的核心方法,如 tryAcquire、tryRelease
}
它有两个实现:
- NonfairSync:非公平锁
- FairSync:公平锁
final Sync sync;public ReentrantLock() {sync = new NonfairSync();
}public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();
}
3. 加锁(lock)
调用过程(非公平模式为例):
public void lock() {sync.lock();
}
NonfairSync.lock()
final void lock() {// 直接用 CAS 抢锁if (compareAndSetState(0, 1))setExclusiveOwnerThread(Thread.currentThread());elseacquire(1); // 调用 AQS 的 acquire
}
情况 1:锁空闲
state == 0,CAS 成功,锁被占用,当前线程成为 owner。
情况 2:锁已被占用
- CAS 失败 → 调用
acquire(1)→ 进入 AQS 队列挂起。
4. 可重入性实现
在 AQS 的 tryAcquire(int acquires) 里:
protected final boolean tryAcquire(int acquires) {Thread current = Thread.currentThread();int c = getState();if (c == 0) { // 没人占用锁if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) { // 当前线程已经占有锁 → 可重入int nextc = c + acquires;setState(nextc); // 计数 +1return true;}return false;
}
👉 如果同一个线程再次 lock(),就直接把 state + 1,表示重入。
5. 解锁(unlock)
调用过程:
public void unlock() {sync.release(1);
}
在 AQS 的 release 内部会调用 tryRelease(int releases):
protected final boolean tryRelease(int releases) {int c = getState() - releases;if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) { // 说明完全释放free = true;setExclusiveOwnerThread(null);}setState(c);return free;
}
- 如果
state > 0,说明锁还被重入了几次,只是减少计数。 - 如果
state == 0,说明锁彻底释放 → 唤醒队列中的下一个线程。
6. 公平锁 vs 非公平锁
公平锁(FairSync)在 tryAcquire 时会先检查队列:
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}...
}
👉 hasQueuedPredecessors() 用于判断是否有线程在等待,如果有就乖乖排队。
而 非公平锁 则直接上来 CAS 抢,不管队列。
十七.synchronized和Lock有什么区别?
synchronized 和 Lock 都是用于实现线程同步的机制,用来确保多线程环境下对共享资源的访问安全,避免数据不一致或竞争条件。
1. 基本概念
- synchronized:是 Java 的关键字,基于 JVM 的内置锁机制(monitor 锁)实现同步。它可以用来修饰方法或代码块,自动获取和释放锁。
- Lock:是 Java 5 引入的
java.util.concurrent.locks包中的接口(常用实现类是ReentrantLock),提供了更灵活的锁机制,需手动获取和释放锁。
2. 使用方式
- synchronized:
- 使用简单,直接在方法或代码块上加
synchronized关键字。 - 自动获取锁,方法或代码块执行完后自动释放锁。
- 示例:
synchronized (obj) {// 同步代码块 } public synchronized void method() {// 同步方法 }
- 使用简单,直接在方法或代码块上加
- Lock:
- 需要显式调用
lock()获取锁,unlock()释放锁,通常放在try-finally块中确保释放。 - 示例:
Lock lock = new ReentrantLock(); lock.lock(); try {// 同步代码 } finally {lock.unlock(); }
- 需要显式调用
3. 功能对比
| 特性 | synchronized | Lock (ReentrantLock) |
|---|---|---|
| 锁的获取与释放 | 自动获取和释放锁 | 需手动调用 lock() 和 unlock() |
| 灵活性 | 较为简单,功能有限 | 更灵活,支持更多高级功能 |
| 可中断性 | 不支持中断 | 支持中断(lockInterruptibly()) |
| 公平性 | 非公平锁 | 可配置公平锁(new ReentrantLock(true)) |
| 条件变量 | 依赖 wait()/notify() | 支持多个 Condition 对象(更灵活) |
| 超时机制 | 不支持尝试获取锁超时 | 支持超时(tryLock(long, TimeUnit)) |
| 性能 | 早期版本性能较低,现代 JVM 优化后差距不大 | 性能较优,尤其在高并发场景下 |
| 锁的类型 | 仅支持可重入锁 | 支持可重入锁、读写锁(如 ReentrantReadWriteLock) |
4. 适用场景
- synchronized:
- 适合简单同步场景,代码简洁。
- 适合不需要高级锁功能的场景,如简单的互斥访问。
- 依赖 JVM 实现,移植性好。
- Lock:
- 适合需要高级功能的场景,如可中断锁、超时机制、公平锁或多条件变量。
- 适合复杂并发逻辑,如读写分离(使用
ReentrantReadWriteLock)。 - 代码更复杂,需确保正确释放锁以避免死锁。
# 十八.死锁的产生条件
死锁(Deadlock)是多线程编程中一种常见的并发问题,指多个线程因互相等待对方释放资源而导致无法继续执行的状态。死锁的产生需要同时满足以下 四个必要条件:
-
互斥条件(Mutual Exclusion):
- 资源只能被一个线程独占使用,其他线程必须等待该资源释放。
- 例如,某个对象锁一次只能被一个线程持有。
-
占有且等待条件(Hold and Wait):
- 线程在持有至少一个资源(锁)的同时,请求获取其他资源,且在获取到新资源前不会释放已有资源。
- 例如,线程 A 持有锁 L1 并请求锁 L2,而不释放 L1。
-
不可抢占条件(No Preemption):
- 资源不能被强制剥夺,只能由持有资源的线程主动释放。
- 例如,线程 A 持有的锁 L1 不能被其他线程抢占,必须等待 A 主动释放。
-
循环等待条件(Circular Wait):
- 多个线程形成一个循环链,每个线程都在等待下一个线程持有的资源。
- 例如,线程 A 持有锁 L1 并等待锁 L2,线程 B 持有锁 L2 并等待锁 L1,形成循环。
总结:只要上述四个条件同时满足,死锁就可能发生。打破其中任一条件即可避免死锁。
十九.如何进行死锁的诊断
死锁会导致程序无响应或线程卡死,诊断死锁通常需要借助工具和方法来分析线程状态及锁的持有情况。以下是常见的死锁诊断方法:
1. 使用 Java 工具诊断死锁
Java 提供了多种工具来检测和分析死锁:
- jstack:
- 功能:
jstack是 JDK 自带的命令行工具,用于生成 JVM 中所有线程的堆栈跟踪(Thread Dump),可以直接显示死锁信息。 - 步骤:
- 获取 Java 进程的 PID(通过
jps或ps命令)。 - 运行
jstack -l <PID>,生成线程堆栈信息。 - 检查输出,查找类似
Found one Java-level deadlock的信息,jstack 会明确指出死锁的线程、锁和等待关系。
- 示例输出:
Found one Java-level deadlock: ============================= "Thread-1":waiting to lock monitor 0x00007f8b4c003800 (object 0x000000076b8c3a10, a java.lang.Object),which is held by "Thread-2" "Thread-2":waiting to lock monitor 0x00007f8b4c004000 (object 0x000000076b8c3a20, a java.lang.Object),which is held by "Thread-1"
- 获取 Java 进程的 PID(通过
- 优点:简单直接,适合快速诊断。
- 功能:
2. 日志分析
- 在开发阶段,可以通过日志记录线程的锁获取和释放情况,帮助定位潜在死锁。
- 使用日志框架(如 SLF4J、Log4j)记录线程进入和退出同步块的时间、锁对象和线程状态。
3. 使用第三方工具
- VisualVM 插件:如 VisualVM-MBeans 或 VisualVM-Threads,增强死锁检测能力。
- 商业工具:如 JProfiler、YourKit,支持更深入的线程和锁分析。
- IDE 集成:IntelliJ IDEA、Eclipse 等 IDE 提供线程调试工具,可实时监控线程状态。
二十.如何避免死锁
在诊断死锁后,可采取以下方法预防死锁:
- 固定锁顺序:确保所有线程以相同的顺序获取锁,避免循环等待。
- 示例:总是先获取 L1 再获取 L2。
- 使用超时机制:
Lock接口的tryLock(long, TimeUnit)支持超时,避免无限等待。 - 减少锁范围:尽量缩小同步代码块的范围,减少锁持有时间。
二十一.聊一下ConcurrentHashMap?
ConcurrentHashMap 简介
ConcurrentHashMap 是 Java java.util.concurrent 包中的一个类,它是一个线程安全的 HashMap 实现,旨在支持高并发场景下的读写操作,而不会像传统的 Hashtable 那样在所有操作上加全局锁,从而提高性能。它允许多个线程同时读取,而写操作则通过精细的锁机制来确保数据一致性。相比普通的 HashMap,它在多线程环境下更可靠,但开销稍大。
JDK 1.7 中的 ConcurrentHashMap
在 JDK 1.7 中,ConcurrentHashMap 的核心设计是分段锁机制。这是一种锁分离技术,将整个 Map 分成多个独立的“段”(默认 16 个),每个段相当于一个小型的 HashMap。 这种设计允许不同线程并发访问不同段,从而提高并发度。
数据结构
- 底层是一个 Segment 数组,每个 Segment 包含一个 HashEntry 数组(类似于 HashMap 的桶)。
- Segment 的数量由构造函数中的
concurrencyLevel参数决定(默认 16),它决定了最大并发线程数(理想情况下,每个线程访问不同段时无锁竞争)。 - 每个 Segment 继承自 ReentrantLock,支持可重入锁。
锁机制
- 使用 ReentrantLock 在 Segment 级别加锁:写操作(如 put、remove)会锁住整个 Segment,读操作(如 get)也可能短暂锁住以确保可见性,但优化后读操作可以无锁(通过 volatile)。
- 锁粒度较粗:同一个 Segment 内的操作会互斥,但不同 Segment 可以并发。
Put/Get 操作
- Put:先通过 hash 计算 Segment 索引,锁住该 Segment,然后在 Segment 的 HashEntry 数组中插入或更新节点。如果链表过长,会触发 Segment 内部扩容。
- Get:计算 Segment 索引,读取 HashEntry 数组(volatile 保证可见性),无需加锁(除非在扩容中)。
- 操作相对简单,但 Segment 锁可能导致同一段内线程阻塞。
扩容机制
- 每个 Segment 独立扩容:当 Segment 负载因子超过阈值(默认 0.75)时,该 Segment 会单独扩容(翻倍),不影响其他 Segment。
- 扩容期间,该 Segment 被锁住,其他线程无法访问。
性能影响
- 优点:并发度高(默认 16),适合中等并发场景;内存占用可控。
- 缺点:Segment 过多会浪费空间(每个 Segment 有最小开销);高并发下,如果 hash 分布不均,某些 Segment 可能成为热点,导致性能瓶颈。整体性能在极高并发时不如 1.8 版本。
JDK 1.8 中的 ConcurrentHashMap
JDK 1.8 重写了 ConcurrentHashMap,放弃了 Segment 设计,转而采用更细粒度的锁和无锁优化。 这主要是为了利用 Java 8 的新特性(如 lambda 和默认方法),并进一步提升性能。实现更接近 HashMap,但添加了并发控制。
数据结构
- 底层是一个 Node 数组(table),每个桶可以是链表或红黑树(TreeBin,当链表长度 > 8 时树化,类似于 HashMap 的优化)。
- 支持懒初始化:Map 创建时不分配 table,直到第一次 put 时才初始化。
- 引入特殊节点:ForwardingNode(用于扩容标记)、ReservationNode(用于 computeIfAbsent 等)。
锁机制
- 结合 CAS(Compare-And-Swap)和 synchronized:CAS 用于乐观操作(如初始化桶),synchronized 用于锁住桶的头节点(锁粒度细到单个桶)。
- 读操作完全无锁,利用 volatile 保证可见性。
- 从 ReentrantLock 切换到 synchronized,主要是因为 synchronized 在 JVM 优化后性能更好,且代码更简洁。
Put/Get 操作
- Put:先通过 hash 计算桶索引。如果桶为空,用 CAS 插入头节点;否则,用 synchronized 锁住头节点,在链表/树中插入或更新。树化/去树化动态调整。
- Get:直接读取 Node 数组(volatile),遍历链表/树查找,无锁操作。
- 支持更多函数式方法,如 computeIfAbsent、merge 等,这些利用 CAS 和锁实现原子性。
扩容机制
- 当负载因子超过阈值时,全局扩容(table 翻倍),支持多线程协助:线程在 put 时如果发现扩容中,会帮助迁移桶(分片迁移)。
- 使用 ForwardingNode 标记已迁移桶,确保读写一致。
- 元素计数使用 LongAdder(分段计数器),避免了 1.7 中的集中计数瓶颈。
性能影响
- 优点:读操作无锁,写锁粒度更细(桶级),并发度更高;多线程扩容减少阻塞;树化优化了最坏情况下的 O(n) 查询。
- 缺点:实现更复杂,内存可能稍高(树节点开销);在低并发下,CAS 失败重试可能有轻微开销。但整体在高并发场景下性能显著优于 1.7。
1.7 vs 1.8 差异总结
| 方面 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment 数组 + HashEntry 链表 | Node 数组 + 链表/红黑树 (TreeBin) |
| 锁机制 | Segment 级 ReentrantLock | 桶级 synchronized + CAS |
| 读操作 | 可能短暂锁(优化后无锁) | 完全无锁 (volatile) |
| 写操作 | 锁整个 Segment | 锁单个桶头节点 |
| 扩容 | Segment 独立扩容 | 全局并发扩容,多线程协助 |
| 并发度 | 受 Segment 数限制 (默认16) | 理论上无上限 (桶数决定) |
| 性能 | 适合中等并发;热点 Segment 瓶颈 | 高并发更好;读写分离,扩容高效 |
| 其他 | 简单但空间浪费 | 支持更多 API;懒初始化,计数用 LongAdder |
二十二.线程池核心参数有哪些?
线程池核心参数(ThreadPoolExecutor)
ThreadPoolExecutor 的构造函数中定义了以下核心参数:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
1. corePoolSize(核心线程数)
- 定义:线程池中始终保留的线程数量,即使这些线程空闲也不会被销毁(除非设置了
allowCoreThreadTimeOut)。 - 作用:
- 任务提交时,若当前线程数 <
corePoolSize,创建新线程执行任务。 - 核心线程通常处理持续的任务,适合长期运行的场景。
- 任务提交时,若当前线程数 <
- 配置注意:
- 设置过小可能导致任务排队,降低并发能力。
- 设置过大可能浪费资源,尤其在任务量低时。
- 示例:
corePoolSize=5表示最多保留5个核心线程。
2. maximumPoolSize(最大线程数)
- 定义:线程池允许创建的最大线程数(包括核心线程和临时线程)。
- 作用:
- 当任务队列满且线程数 <
maximumPoolSize时,创建临时线程处理任务。 - 临时线程在空闲超过一定时间后会被回收。
- 当任务队列满且线程数 <
- 配置注意:
- 应根据系统资源(如 CPU 核心数、内存)合理设置,避免过多的线程导致上下文切换或内存溢出。
- 示例:
maximumPoolSize=10表示线程池最多有10个线程。
3. keepAliveTime(空闲线程存活时间)
- 定义:非核心线程(即超出
corePoolSize的线程)在空闲状态下的存活时间。 - 作用:
- 如果空闲时间超过
keepAliveTime,非核心线程会被终止,释放资源。 - 若设置了
allowCoreThreadTimeOut(true),核心线程空闲超时也会被回收。
- 如果空闲时间超过
- 配置注意:
- 设置较短适合动态任务场景,节省资源。
- 设置较长适合任务间隔较长的场景,避免频繁创建线程。
- 示例:
keepAliveTime=60, unit=TimeUnit.SECONDS表示空闲线程存活60秒。
4. unit(时间单位)
- 定义:
keepAliveTime的时间单位(如秒、毫秒)。 - 作用:指定
keepAliveTime的时间单位,常用TimeUnit.SECONDS或TimeUnit.MILLISECONDS。 - 配置注意:确保与
keepAliveTime匹配,避免配置错误导致线程回收过快或过慢。
5. workQueue(任务队列)
- 定义:用于存储待执行任务的阻塞队列。
- 作用:
- 当线程数达到
corePoolSize且都在忙碌时,新任务会进入队列等待。 - 队列满后,若线程数 <
maximumPoolSize,会创建新线程。
- 当线程数达到
- 常用队列类型:
LinkedBlockingQueue:无界队列(默认大小为Integer.MAX_VALUE),可能导致任务堆积。ArrayBlockingQueue:有界队列,固定大小,适合控制任务量。SynchronousQueue:不存储任务,直接将任务交给线程或拒绝,适合高吞吐场景。PriorityBlockingQueue:基于优先级的队列,适合有优先级任务。
- 配置注意:
- 无界队列可能导致内存溢出(OOM),慎用。
- 有界队列需合理设置容量,避免频繁拒绝任务。
- 示例:
new LinkedBlockingQueue<>(100)表示最多排队100个任务。
6. threadFactory(线程工厂)
- 定义:用于创建线程的工厂,控制线程属性(如名称、优先级、是否守护线程)。
- 作用:
- 自定义线程命名,便于调试和监控(如通过日志或工具识别线程)。
- 可设置线程组、优先级等。
- 配置注意:
- 默认使用
Executors.defaultThreadFactory(),生成普通线程。 - 自定义工厂可为线程设置有意义的名称,如:
new ThreadFactory() {private final AtomicInteger threadNumber = new AtomicInteger(1);@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "MyThread-" + threadNumber.getAndIncrement());} }
- 默认使用
7. handler(拒绝策略)
- 定义:当任务队列满且线程数达到
maximumPoolSize时,处理新提交任务的策略。 - 作用:决定如何处理无法接受的任务。
- 内置策略:
AbortPolicy(默认):抛出RejectedExecutionException异常。CallerRunsPolicy:由提交任务的线程直接执行任务,减缓提交速度。DiscardPolicy:默默丢弃任务,不抛异常。DiscardOldestPolicy:丢弃队列中最老的任务,尝试加入新任务。
- 配置注意:
- 选择合适的拒绝策略,避免任务丢失或异常影响业务。
- 自定义策略可记录拒绝任务日志,用于监控。
- 示例:
new ThreadPoolExecutor.AbortPolicy()表示拒绝时抛异常。
参数之间的关系
线程池的任务处理流程如下:
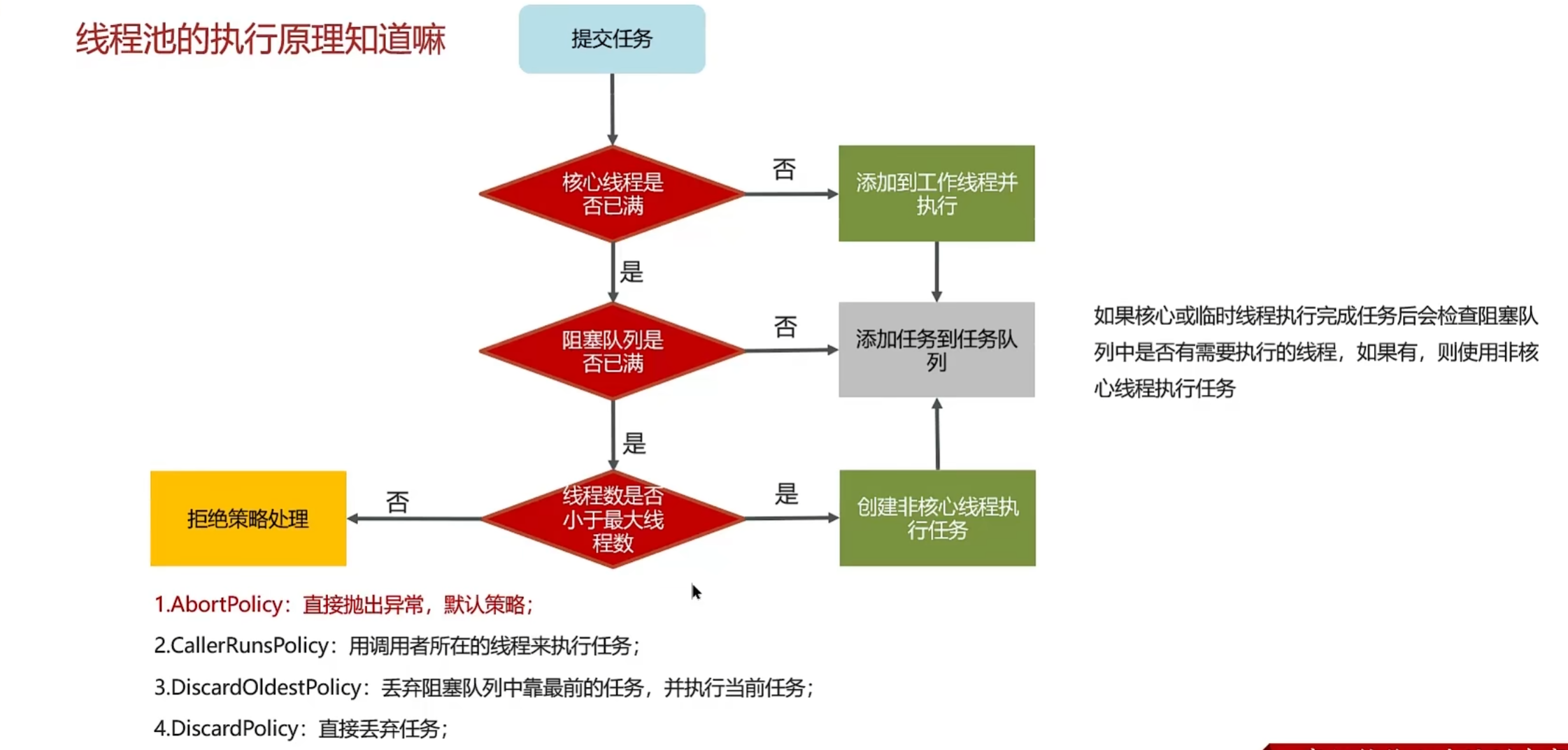
- 如果当前线程数 <
corePoolSize,创建新线程执行任务。 - 如果线程数 ≥
corePoolSize且队列未满,任务进入队列。 - 如果队列满且线程数 <
maximumPoolSize,创建临时线程。 - 如果线程数 ≥
maximumPoolSize且队列满,执行拒绝策略。
示例代码
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, // corePoolSize10, // maximumPoolSize60, TimeUnit.SECONDS, // keepAliveTimenew ArrayBlockingQueue<>(100), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.CallerRunsPolicy() // handler
);
executor.submit(() -> System.out.println("Task executed by " + Thread.currentThread().getName()));
二十三.线程池中有哪些常见的阻塞队列?
在 Java 的线程池(ThreadPoolExecutor)中,阻塞队列(BlockingQueue)用于存储待执行的任务,是线程池核心参数之一。不同的阻塞队列类型会显著影响线程池的行为和性能。以下是线程池中常见的阻塞队列类型及其特点:
1. LinkedBlockingQueue(链式阻塞队列)
- 特点:
- 基于单向链表实现的有界或无界阻塞队列(默认无界,容量为
Integer.MAX_VALUE)。 - 任务以 FIFO(先进先出)顺序存储。
- 支持高效的并发访问,内部使用两个锁(putLock 和 takeLock)分别控制入队和出队。
- 基于单向链表实现的有界或无界阻塞队列(默认无界,容量为
- 适用场景:
- 适合任务量较大但不需要严格限制队列长度的场景。
- 常用于默认的
Executors.newFixedThreadPool和Executors.newSingleThreadExecutor。
- 注意事项:
- 默认无界队列可能导致任务无限堆积,耗尽内存(OOM),建议显式设置容量。
- 示例:
new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
- 性能:入队和出队效率较高,但无界队列可能隐藏性能问题。
2. ArrayBlockingQueue(数组阻塞队列)
- 特点:
- 基于数组实现的有界阻塞队列,初始化时必须指定固定容量。
- FIFO 顺序,内部使用单个
ReentrantLock和两个Condition控制并发访问。 - 队列满时,入队操作阻塞;队列空时,出队操作阻塞。
- 适用场景:
- 适合需要严格控制任务队列长度的场景,避免内存溢出。
- 常用于资源受限或需要背压(backpressure)的系统。
- 注意事项:
- 容量不可动态调整,需根据任务量和硬件资源合理设置。
- 示例:
new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(50));
- 性能:性能略低于
LinkedBlockingQueue,因为使用单一锁,适合中小规模任务队列。
对比总结
| 队列类型 | 是否有界 | 排序方式 | 适用场景 | 性能特点 |
|---|---|---|---|---|
| LinkedBlockingQueue | 可选 | FIFO | 通用,任务量大 | 高吞吐,低开销 |
| ArrayBlockingQueue | 有界 | FIFO | 资源受限,需背压 | 中等吞吐,固定容量 |
二十四.在Java中,线程池的种类有哪些?
1. FixedThreadPool(定长线程池)
-
创建方式:
ExecutorService pool = Executors.newFixedThreadPool(int nThreads); -
特点:
- 固定数量的线程,线程数不会变。
- 任务超出线程数量时,任务会放入 无界队列(LinkedBlockingQueue)。
- 适合 稳定并发场景,比如服务器需要处理固定数量的长期任务。
2. CachedThreadPool(缓存线程池)
-
创建方式:
ExecutorService pool = Executors.newCachedThreadPool(); -
特点:
- 线程数不固定,按需创建。
- 空闲线程存活时间 60s,超过时间会被回收。
- 使用 SynchronousQueue(直接提交,不存储任务)。
- 适合 大量短期异步任务,并且任务执行时间较短的场景。
3. SingleThreadExecutor(单线程线程池)
-
创建方式:
ExecutorService pool = Executors.newSingleThreadExecutor(); -
特点:
- 永远只有一个线程。
- 所有任务按 FIFO 顺序(队列)依次执行。
- 保证任务的顺序性和线程安全。
- 适合 需要顺序执行任务 的场景。
4. ScheduledThreadPool(定时/周期性线程池)
-
创建方式:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(int corePoolSize); -
特点:
- 可以执行 定时任务 和 周期性任务。
- 底层使用 DelayQueue 实现。
- 适合 定时调度、周期执行 的场景(替代
Timer类)。
5. SingleThreadScheduledExecutor(单线程定时任务池)
-
创建方式:
ScheduledExecutorService pool = Executors.newSingleThreadScheduledExecutor(); -
特点:
- 只有一个线程,顺序执行任务。
- 支持 延迟执行 和 周期执行。
- 适合需要 单线程定时任务调度 的场景。
二十五.为什么不推荐直接使用 Executors 创建线程池?
1. FixedThreadPool 和 SingleThreadExecutor 使用了无界队列
-
源码里是:
new LinkedBlockingQueue<Runnable>()默认容量是
Integer.MAX_VALUE,接近 21 亿。 -
一旦任务堆积过多,队列会无限增长,导致内存溢出(OOM)。
2. CachedThreadPool 线程数几乎无限制
-
源码里:
new SynchronousQueue<Runnable>()- 没有存储任务的能力,只要有新任务就必须创建新线程。
- 最大线程数是
Integer.MAX_VALUE,相当于 理论上可创建 21 亿个线程。
-
如果短时间内大量请求进来,就可能 疯狂创建线程,CPU 上下文切换开销巨大,最终导致 OOM 或系统崩溃。
3. ScheduledThreadPool 也有风险
- 底层用 DelayedWorkQueue(无界队列),任务过多时同样可能堆积,造成 内存泄漏 或 OOM。
二十六.线程池的应用-es批量导入大量数据
模拟从数据库分页读取数据(用 MyBatis/JDBC),然后用 线程池 + Bulk API 批量导入到 ES。
1. 数据库实体类(假设数据库表是 article)
public class Article {private Long id;private String title;private String content;// getter & setter
}
2. MyBatis Mapper 接口
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;import java.util.List;public interface ArticleMapper {// 分页查询数据@Select("SELECT id, title, content FROM article LIMIT #{offset}, #{pageSize}")List<Article> findPage(@Param("offset") int offset, @Param("pageSize") int pageSize);// 查询总数@Select("SELECT COUNT(*) FROM article")int countAll();
}
3. 批量导入 ES Demo
package com.example.esdemo;import com.example.mapper.ArticleMapper;
import com.example.model.Article;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;import java.io.IOException;
import java.util.List;
import java.util.concurrent.*;public class EsImportFromDbDemo {public static void main(String[] args) throws InterruptedException {// 1. 初始化 Spring/MyBatis 上下文ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");ArticleMapper articleMapper = context.getBean(ArticleMapper.class);// 2. ES 客户端RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 3. 线程池的创建ThreadPoolExecutor executor = new ThreadPoolExecutor(4, 8,60L, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1000),Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());// 4. 分页读取数据int pageSize = 1000;//每页的数量int total = articleMapper.countAll();//count(*)查询总数据量int pageCount = (total + pageSize - 1) / pageSize;//总页数CountDownLatch latch = new CountDownLatch(pageCount);//创建了一个计数器,初始值是 pageCount(分页总数)。//循环对每一页执行插入操作for (int page = 0; page < pageCount; page++) {int offset = page * pageSize;List<Article> articles = articleMapper.findPage(offset, pageSize);executor.submit(() -> {try {BulkRequest bulkRequest = new BulkRequest();for (Article article : articles) {bulkRequest.add(new IndexRequest("article_index").id(article.getId().toString()).source("title", article.getTitle(),"content", article.getContent()));}BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);if (bulkResponse.hasFailures()) {System.err.println("批量写入失败: " + bulkResponse.buildFailureMessage());} else {System.out.println("成功写入 " + articles.size() + " 条");}} catch (Exception e) {e.printStackTrace();} finally {latch.countDown();// 每完成一页任务,就减 1}});}// 5. 等待任务完成latch.await();executor.shutdown();System.out.println("所有数据导入完成!");// 6. 关闭 ES 客户端try {client.close();//关闭客户端} catch (IOException e) {e.printStackTrace();}}
}
📌 实现思路
-
分页查询数据库:一次只取
pageSize条数据,避免一次性加载上百万条导致 OOM。 -
线程池并发处理:每一页数据交给线程池处理,提高吞吐量。
-
Bulk API 批量写入:每批 1000 条一起写入 ES,减少网络交互。
-
CountDownLatch 等待完成:保证所有分页任务都执行完再退出。
-
可调参数:
pageSize(批大小,取决于 ES 集群写入能力)- 线程池核心线程数、队列大小(根据 CPU 和机器内存调优)
二十七.线程池的应用-实现一个电商下单后查询订单、商品、物流信息的Demo,用多线程优化耗时?
✅ 实现目标
- 手动创建线程池:使用
ThreadPoolExecutor构造函数。 - 并行执行多个任务:模拟订单、商品和物流信息查询。
- 使用
CompletableFuture提交任务:将任务提交给线程池异步执行。 - 线程安全地收集结果:使用共享数组保存每个任务的结果。
- 关闭线程池:执行结束后调用
shutdown()方法。
🧩 核心实现逻辑
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicReferenceArray;class ServiceImpl {// 模拟订单服务(500ms)public String getOrderInfo() {sleep(500);return "订单信息: 订单号 ORD20240911, ";}// 模拟商品服务(800ms)public String getItemInfo() {sleep(800);return "商品信息: iPhone 15 Pro, 颜色=星光, ";}// 模拟物流服务(500ms)public String getLogisticsInfo() {sleep(500);return "物流信息: 物流单号 LW2024001, 已发货";}private void sleep(int millis) {try {Thread.sleep(millis);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}
}public class EcommerceManualThreadPool {public static void main(String[] args) {ServiceImpl service = new ServiceImpl();// 1. 串行调用serialExecute(service);// 2. 并行调用(手动创建线程池)parallelExecute(service);}private static void serialExecute(ServiceImpl service) {long start = System.currentTimeMillis();String order = service.getOrderInfo();String item = service.getItemInfo();String logistics = service.getLogisticsInfo();long cost = System.currentTimeMillis() - start;System.out.println("\n=== 串行执行结果 ===");System.out.println(order + item + logistics);System.out.println("总耗时: " + cost + "ms");}private static void parallelExecute(ServiceImpl service) {long start = System.currentTimeMillis();// 手动创建线程池(不使用 Executors)ThreadPoolExecutor executor = new ThreadPoolExecutor(3, // 核心线程数3, // 最大线程数0L, // 空闲线程存活时间TimeUnit.MILLISECONDS,new LinkedBlockingQueue<>(100), // 任务队列new ThreadPoolExecutor.AbortPolicy() // 拒绝策略);// 使用 AtomicReferenceArray 线程安全地保存结果AtomicReferenceArray<String> results = new AtomicReferenceArray<>(3);CompletableFuture<Void> futureOrder = CompletableFuture.runAsync(() -> {results.set(0, service.getOrderInfo());}, executor);CompletableFuture<Void> futureItem = CompletableFuture.runAsync(() -> {results.set(1, service.getItemInfo());}, executor);CompletableFuture<Void> futureLogistics = CompletableFuture.runAsync(() -> {results.set(2, service.getLogisticsInfo());}, executor);// 等待所有任务完成CompletableFuture.allOf(futureOrder, futureItem, futureLogistics).join();// 关闭线程池executor.shutdown();long cost = System.currentTimeMillis() - start;System.out.println("\n=== 并行执行结果(手动线程池) ===");System.out.println(results.get(0) + results.get(1) + results.get(2));System.out.println("总耗时: " + cost + "ms");}
}
🔍 示例输出(近似值)
=== 串行执行结果 ===
订单信息: 订单号 ORD20240911, 商品信息: iPhone 15 Pro, 颜色=星光, 物流信息: 物流单号 LW2024001, 已发货
总耗时: 1800ms=== 并行执行结果(手动线程池) ===
订单信息: 订单号 ORD20240911, 商品信息: iPhone 15 Pro, 颜色=星光, 物流信息: 物流单号 LW2024001, 已发货
总耗时: 805ms
🚀 优势与注意事项
- 优势:
- 更加灵活地控制线程池行为(如队列策略、拒绝策略等)。
- 明确线程池的生命周期管理。
- 适合需要精细化控制线程资源的场景。
- 注意事项:
- 需要手动配置线程池参数,不能像
Executors那样快速创建。 - 如果任务量较大,建议设置合理的队列容量和拒绝策略。
- 使用完线程池后务必调用
shutdown(),避免资源泄露。
- 需要手动配置线程池参数,不能像
二十八.线程池的应用-在用户搜索时,主线程用于搜索记录查询,重新开启一个线程异步完成搜索记录异步添加功能?
示例代码
import java.util.concurrent.*;public class SearchService {// 自定义线程池private static final ThreadPoolExecutor executorService =new ThreadPoolExecutor(2, // 核心线程数5, // 最大线程数60L, // 非核心线程最大空闲时间TimeUnit.SECONDS,new LinkedBlockingQueue<>(10), // 队列容量Executors.defaultThreadFactory(), // 线程工厂new ThreadPoolExecutor.AbortPolicy() // 拒绝策略);/*** 用户搜索业务*/public String search(String keyword) {// 1. 主流程:返回搜索结果String result = "搜索结果:" + keyword;// 2. 异步保存搜索记录(线程池执行)executorService.submit(() -> saveSearchLog(keyword));return result;}/*** 模拟保存搜索记录*/private void saveSearchLog(String keyword) {try {// 模拟耗时操作,比如写数据库Thread.sleep(1000);System.out.println("搜索记录已保存:" + keyword + ",线程:" + Thread.currentThread().getName());} catch (InterruptedException e) {Thread.currentThread().interrupt();System.err.println("保存搜索记录失败:" + e.getMessage());}}/*** 主函数测试*/public static void main(String[] args) {SearchService searchService = new SearchService();// 模拟用户多次搜索System.out.println(searchService.search("Java 多线程"));System.out.println(searchService.search("线程池原理"));System.out.println(searchService.search("MyBatis 分页查询"));// 给异步任务一些执行时间try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}// 关闭线程池executorService.shutdown();}
}
输出示例
搜索结果:Java 多线程
搜索结果:线程池原理
搜索结果:MyBatis 分页查询
搜索记录已保存:Java 多线程,线程:pool-1-thread-1
搜索记录已保存:线程池原理,线程:pool-1-thread-2
搜索记录已保存:MyBatis 分页查询,线程:pool-1-thread-3
二十八.线程池的应用-如何控制某个线程允许线程并发访问的数量?
1. 使用 Semaphore(信号量)
Semaphore 可以限制同一时刻允许多少个线程同时执行某段代码。
例如:最多允许 3 个线程同时访问保存搜索记录的方法:
import java.util.concurrent.Semaphore;public class SearchService {// 定义一个信号量,最多允许3个线程同时访问private final Semaphore semaphore = new Semaphore(3);public void saveSearchLog(String keyword) {try {// 获取一个许可(没有许可时会阻塞等待)semaphore.acquire();System.out.println(Thread.currentThread().getName() + " 正在保存日志:" + keyword);Thread.sleep(2000); // 模拟耗时操作System.out.println(Thread.currentThread().getName() + " 保存日志完成:" + keyword);} catch (InterruptedException e) {Thread.currentThread().interrupt();} finally {// 释放许可semaphore.release();}}public static void main(String[] args) {SearchService service = new SearchService();for (int i = 0; i < 10; i++) {String keyword = "搜索-" + i;new Thread(() -> service.saveSearchLog(keyword)).start();}}
}
效果:
同一时间最多只有 3 个线程在执行 saveSearchLog,其余线程会等待。
二十九.谈谈你对ThreadLocal的理解?
1. ThreadLocal 是什么
-
ThreadLocal是 JDK 提供的一个 线程本地变量工具类。 -
它的作用是:给每个线程都提供一份 独立的变量副本,不同线程之间互不干扰。
-
典型的应用场景:
- 保存用户会话信息(如
userId) - 保存数据库连接(Connection)
- 保存事务上下文
- 保存全局日志跟踪 ID
- 保存用户会话信息(如
它不是用来解决多线程共享变量的问题,而是为每个线程提供独立的变量副本,避免线程安全问题。
2. 底层原理
- 每个线程对象(
Thread)内部有一个ThreadLocalMap。 - 当你调用
threadLocal.set(value)时,其实是把 当前线程作为 key,把value存到ThreadLocalMap里。 - 当你
get()时,线程就能拿到自己对应的value。
示意图:
Thread-1 --> ThreadLocalMap --> { ThreadLocalA: value1, ThreadLocalB: value2 }
Thread-2 --> ThreadLocalMap --> { ThreadLocalA: value3 }
所以 每个线程的数据是隔离的。
3. 使用示例
public class ThreadLocalDemo {private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();public static void main(String[] args) {Runnable task = () -> {String name = Thread.currentThread().getName();threadLocal.set("数据-" + name); // 存储线程独有的数据try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(name + " 取出的值:" + threadLocal.get());// 用完记得清理,避免内存泄漏threadLocal.remove();};new Thread(task, "线程A").start();new Thread(task, "线程B").start();}
}
输出类似:
线程A 取出的值:数据-线程A
线程B 取出的值:数据-线程B
4. 内存泄漏风险
- 原因:
ThreadLocalMap的 key 是ThreadLocal的弱引用,value是强引用,如果ThreadLocal对象被 GC 回收了,但对应的 value 还在,可能导致 value 无法被回收(泄漏)。 - 解决办法:用完之后要手动
remove()。