精准定位性能瓶颈:深入解析 PaddleOCR v3.2 全新 Benchmark 功能
飞桨技术生态伙伴 算力魔方
| 摘要:在实际落地OCR和文档解析项目时,大家常常会遇到一个棘手问题:模型跑得不够快,但到底是检测太慢、识别耗时,还是模块之间的数据流转不高效?PaddleOCR v3.2 给出了一个非常实用的解决方案——全新的 细粒度 Benchmark 功能。它不仅能测量端到端的整体速度,还能拆解到每个模块、每个关键方法的耗时,帮你一眼锁定性能瓶颈。结果支持控制台直观展示,也能导出为 CSV 方便后续可视化和分析。有了这个工具,性能调优不再是“盲人摸象”,开发者可以更快找到问题、对症优化,打造更高效、更稳定的OCR和文档解析服务。
一,痛点与挑战
对于每一位致力于将OCR和文档解析技术落地的开发者来说,性能是绕不开的核心议题。一个高效的OCR和文档解析系统不仅要“看得准”,更要“跑得快”。然而,现代OCR或文档解析系统,尤其是像 PP-OCRv5 或PP-StructureV3这样的产线级方案,其内部结构日益复杂,性能分析也因此变得极具挑战。
例如,在 PaddleOCR 3.x 中,PP-OCRv5产线通常由多个功能模块组合而成:
文本图像预处理
文本检测模块
文本行方向分类模块
文本识别模块
这些模块之间并非简单的线性串联,而是包含了复杂的逻辑交互。因此,我们常常面临一个棘手的问题:当产线端到端推理速度不达预期时,性能瓶颈究竟出在哪里? 是检测模型太慢,还是识别模型耗时过长,亦或是模块间的数据流转效率不高?
二,细粒度性能 Benchmark概述
为了解决这一痛点,我们在 PaddleOCR v3.2 中正式推出了全新的细粒度性能 Benchmark 功能,赋予开发者前所未有的性能洞察力。
全新的 Benchmark 功能不仅支持对整个产线的端到端推理速度进行测量,其真正的强大之处在于,它能提供逐层级、逐模块的详细性能数据。这意味着您可以深入到产线内部,清晰地看到每一环节、每一个关键方法的具体耗时情况。
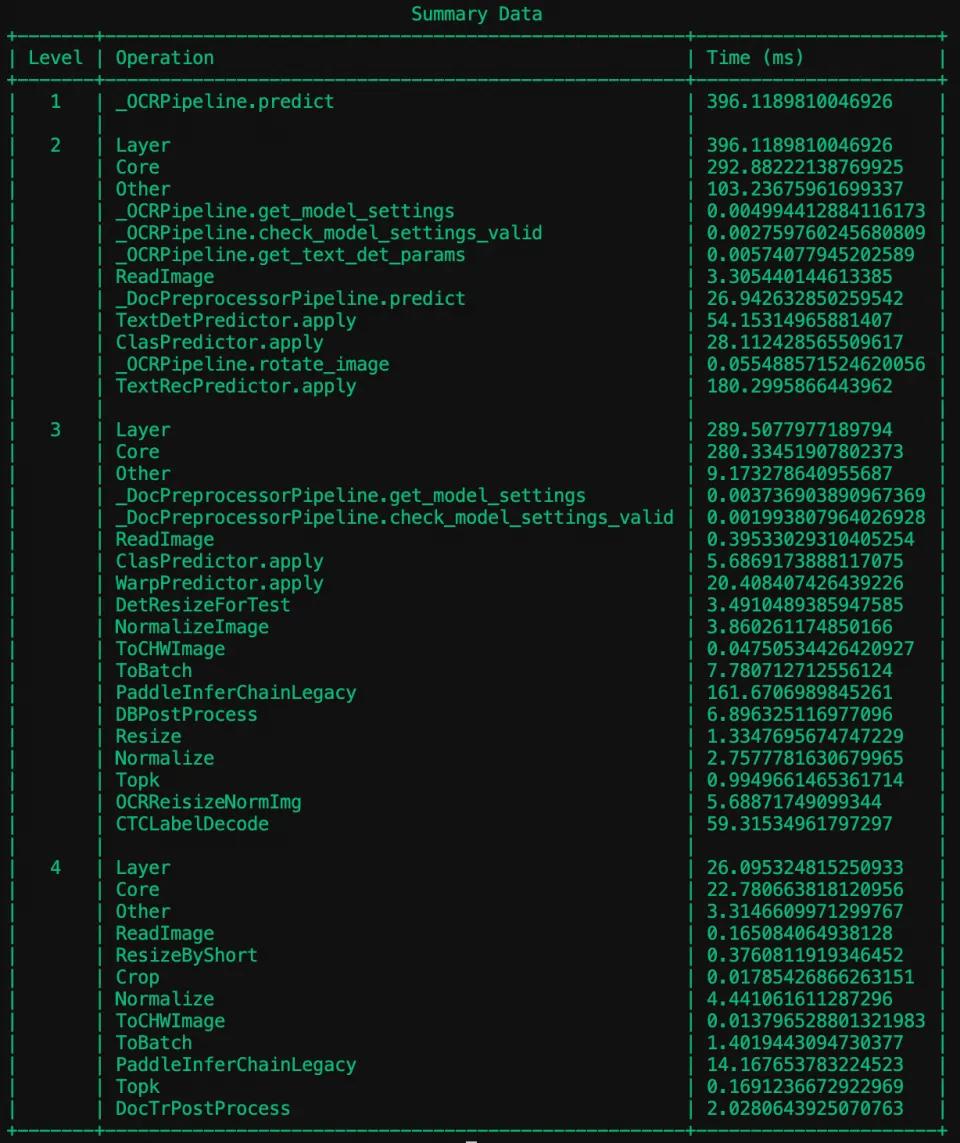
从上图可以看出,产线中每个单功能模块,以及模块与产线中的关键方法执行时间均被详细记录。同时,在benchmark目录中存储有CSV格式的测量结果,便于后续编写脚本解析。用户可以基于这些数据精准地分析当前硬件上的模型方案性能瓶颈,进而有针对性地优化部署方案。
三,环境准备与快速体验
PaddleOCR v3.2 引入了全新的细粒度性能 Benchmark 功能,旨在帮助开发者更高效地分析模型性能瓶颈。以下是快速体验该功能的步骤:
3.1 环境准备
本项目依赖 PaddlePaddle、PaddleOCR及常用 Python 工具包。使用前请确保已安装相关依赖。详细安装指南见环境准备文档:
https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/version3.x/installation.en.md
# 创建并激活虚拟环境 (推荐)conda create -n ocr-env python=3.11conda activate ocr-env# 安装PaddlePaddle GPU版本 (根据您的CUDA版本选择合适的版本)pip install paddlepaddle-gpu==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/python -c "import paddle; paddle.utils.run_check()" # 验证PaddlePaddle安装是否成功pip install paddleocr[doc-parser] # 安装PaddleOCRpip install matplotlib tqdm opencv-contrib-python3.2 Benchmark PP-OCRv5 范例:
首先,请下载测试图片到本地,若使用自己的图片,则忽略此步:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O general_ocr_002.png然后,创建BenchMark脚本并运行:
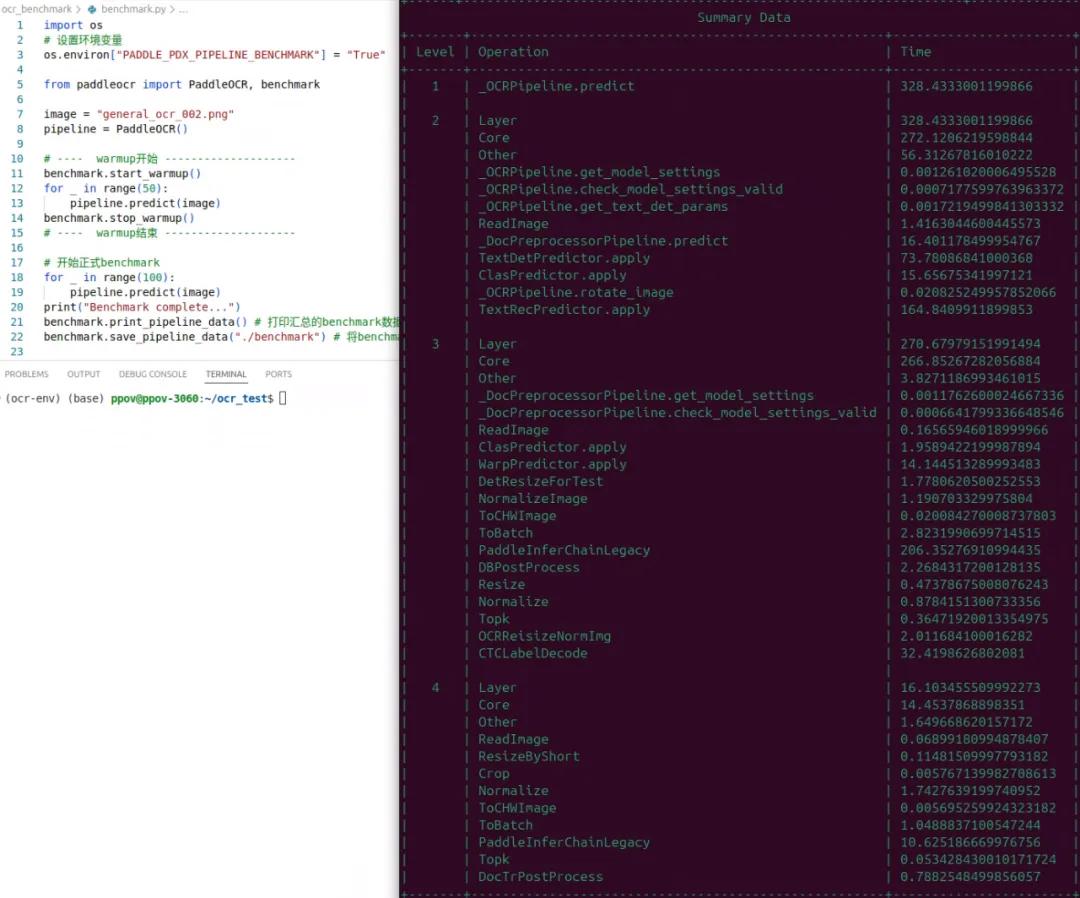
import os# 设置环境变量os.environ["PADDLE_PDX_PIPELINE_BENCHMARK"] = "True"from paddleocr import PaddleOCR, benchmarkimage = "general_ocr_002.png"pipeline = PaddleOCR()# ---- warmup开始 --------------------benchmark.start_warmup()for _ in range(50):pipeline.predict(image)benchmark.stop_warmup()# ---- warmup结束 --------------------# 开始正式benchmarkfor _ in range(100):pipeline.predict(image)print("Benchmark complete...")benchmark.print_pipeline_data() # 打印汇总的benchmark数据benchmark.save_pipeline_data("./benchmark") # 将benchmark数据保存至benchmark文件夹运行结果如下:
图片
如上图所示,print_pipeline_data() 会在控制台输出清晰的层级化耗时报告,产线中每个模块及关键方法的执行时间一目了然。
同时,在 benchmark_results 目录下会生成一个 CSV 格式的测量结果文件。您可以轻松编写脚本对其进行解析,或导入到电子表格软件中进行可视化分析,从而精准定位当前硬件环境下的模型性能瓶颈。
3.3 Benchmark PP-StructureV3 范例:
PP-StructureV3 是 PaddleOCR 推出的文档解析方案,同样支持细粒度 Benchmark 功能,以下是代码示例:
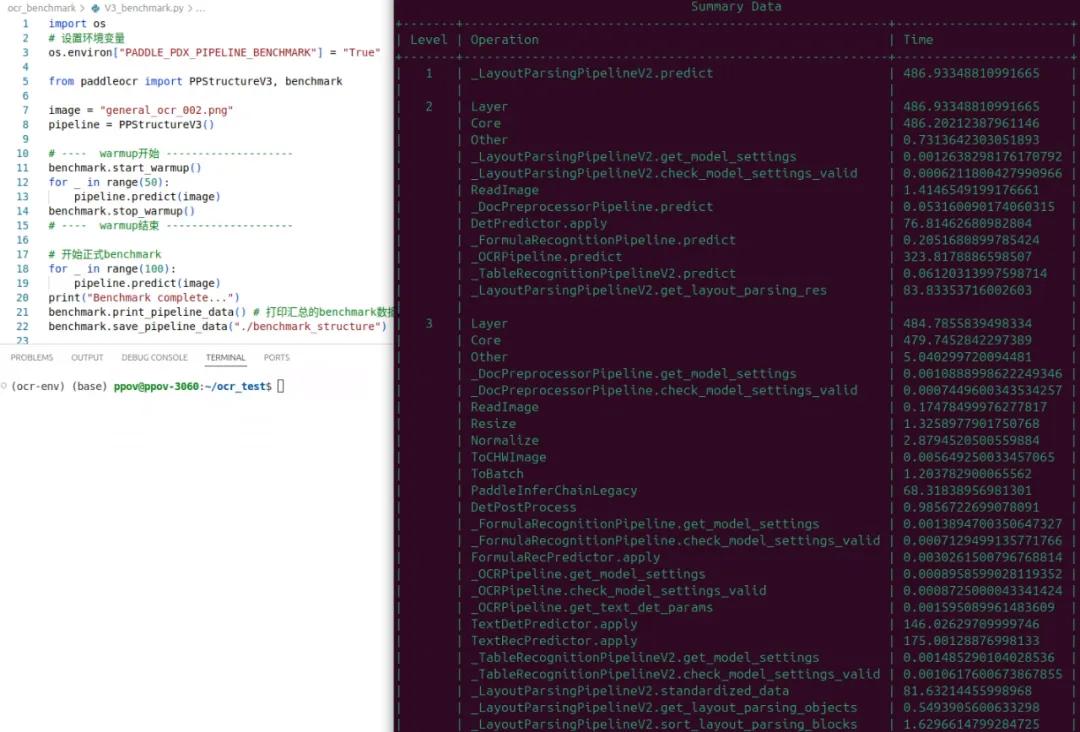
import os# 设置环境变量os.environ["PADDLE_PDX_PIPELINE_BENCHMARK"] = "True"from paddleocr import PPStructureV3, benchmarkimage = "general_ocr_002.png"pipeline = PPStructureV3()# ---- warmup开始 --------------------benchmark.start_warmup()for _ in range(50):pipeline.predict(image)benchmark.stop_warmup()# ---- warmup结束 --------------------# 开始正式benchmarkfor _ in range(100):pipeline.predict(image)print("Benchmark complete...")benchmark.print_pipeline_data() # 打印汇总的benchmark数据benchmark.save_pipeline_data("./benchmark_structure") # 将benchmark数据保存至文件夹运行结果如下:
四,总结
PaddleOCR v3.2 推出的细粒度 Benchmark 功能,为开发者提供了一个强大、易用的性能分析工具。它将复杂的产线性能调试过程变得透明化、数据化,帮助您快速定位瓶颈,有针对性地进行优化,从而打造出更高效、更可靠的 OCR或文档解析 服务。
我们相信,这一新特性将成为您部署和优化 OCR或文档解析 应用的得力助手。立即升级到PaddleOCR v3.2,体验前所未有的性能洞察吧!
https://github.com/paddlepaddle/paddleocr
更多细节与使用方法,请参见: Pipeline Benchmark
https://paddlepaddle.github.io/PaddleX/latest/en/pipeline_usage/instructions/benchmark.html
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!