记录下chatgpt的openai 开发过程
open ai
最近公司调整战略 想使用ai来操作一些重复性的动作 减少冗余 所以研究了一下国内能接入的chatgap 发现微软在去年就已经接入了 但是公司给到我这边的只有一个key 所以我把开发的过程记录下
一、接通接口
from openai import AsyncAzureOpenAIopenai_client = AsyncAzureOpenAI(azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],api_version=os.environ["AZURE_OPENAI_API_VERSION"],api_key=os.environ["AZURE_OPENAI_API_KEY"],
)if __name__ == "__main__":# Test the OpenAI clientasync def test_openai_client():response = await openai_client.chat.completions.create(model="gpt-4o",messages=[{"role": "user", "content": "Hello, how are you?"}],)print(response.choices[0].message.content)import asyncioasyncio.run(test_openai_client())
这一步打印的就是openai返回给我们的对话结果,但是我们是想从一个文本内容当中获取我们想要的信息 这一步的代码为初步尝试
二、获取网页pdf信息
def fetch_pdf_bytes(url: str, timeout: int, headers: dict, session: requests.Session) -> bytes:# 尝试 Range 取前 4MB,失败回退全量try:r = session.get(url, headers={**headers, "Range": "bytes=0-4194303"}, timeout=(10, timeout), stream=True)if r.status_code == 206:return r.contentr.close()except Exception:passr = session.get(url, headers=headers, timeout=(10, timeout), stream=True)r.raise_for_status()return r.content
这一步是获取到网页的信息
def build_session(verify: bool = True, proxies: Optional[dict] = None) -> requests.Session:retry = Retry(total=3,connect=3,read=3,backoff_factor=1.0,status_forcelist=(429, 500, 502, 503, 504),allowed_methods=("HEAD", "GET"),respect_retry_after_header=True,)adapter = HTTPAdapter(max_retries=retry, pool_connections=10, pool_maxsize=10)s = requests.Session()s.mount("http://", adapter)s.mount("https://", adapter)s.verify = verifyif proxies:s.proxies.update(proxies)return s相关用到的代码块
def extract_text_from_pdf_bytes(data: bytes, max_pages: Optional[int] = None) -> str:reader = PdfReader(BytesIO(data))total = len(reader.pages)limit = min(total, max_pages) if max_pages else totaltexts = []for i in range(limit):page = reader.pages[i]texts.append(page.extract_text() or "")return "\n".join(texts)
经过上面的步骤可以成功的获取到网页pdf的内容
三、整合内容 调整发送到openai的信息
messages = [{"role": "system", "content": "You are a 前置条件" },{"role": "user","content": pdf_text,#pdf的内容},{"role": "system", "content": req.text} 你的问题]
这样chatgap就能返回你想要的信息了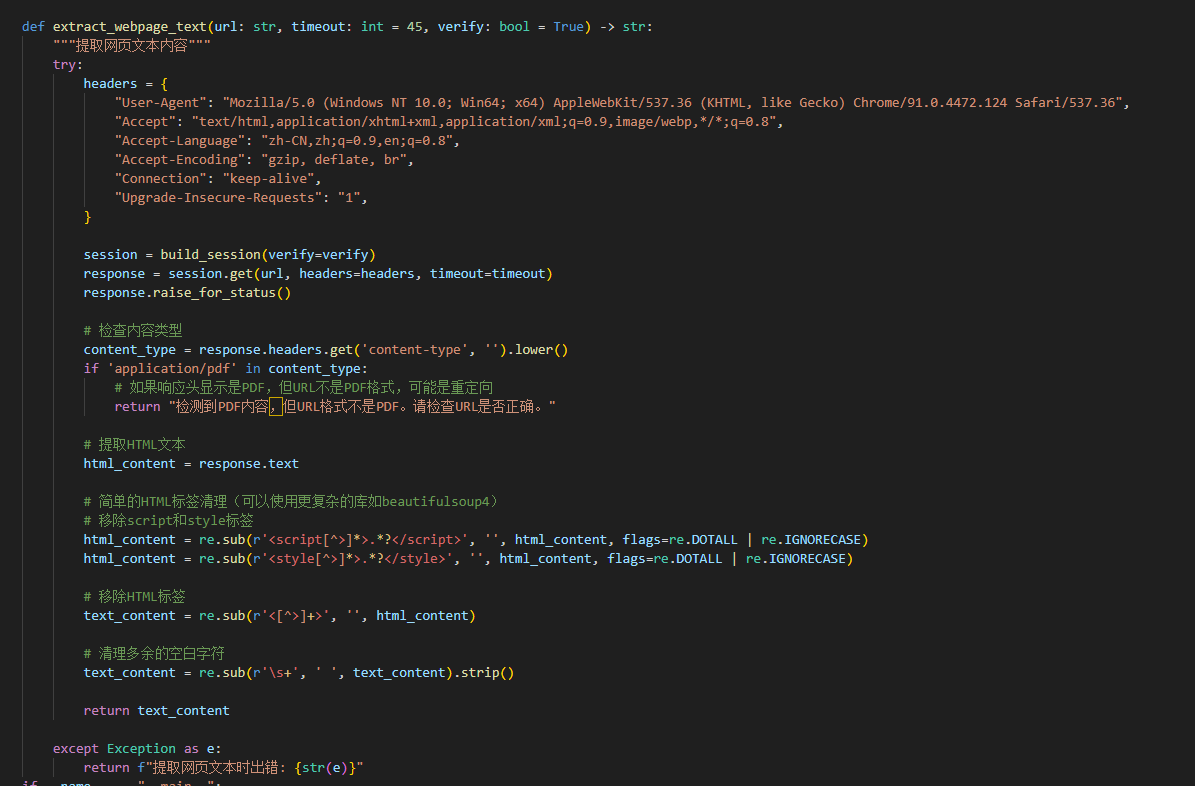 这个是后面发现不仅需要提取pdf的内容 有些网页的内容也是需要提取的
这个是后面发现不仅需要提取pdf的内容 有些网页的内容也是需要提取的