机器学习-决策树(下)
多个决策树:
前面讨论提到的所有决策树都是只有单个决策树,而实际上如果样本数据存在一些微小的变化,决策树却有可能发生很大的变动,因为每一个节点的选择都与样本息息相关。因此这样的决策树对数据变动非常敏感,为了增强稳健性我们可以一次构造多个决策树。
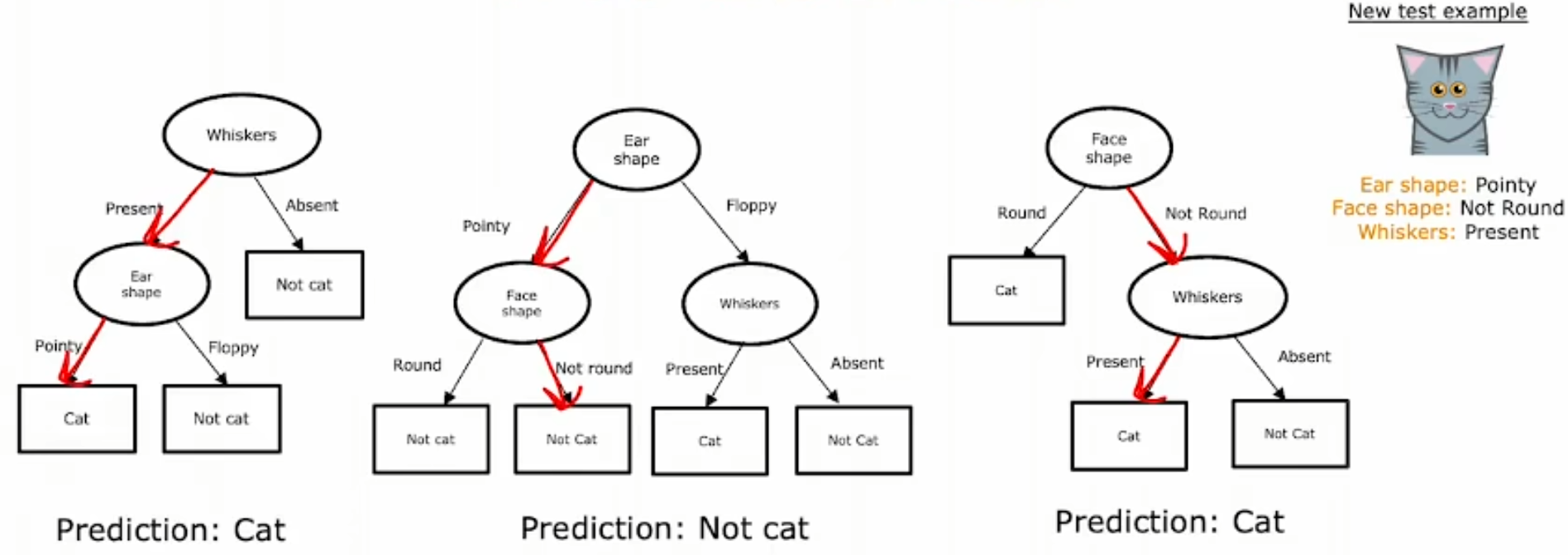
为了构造多个决策树,我们需要对原始的样本进行处理,已得到多批训练样本,因此引入有放回抽样的概念,即在每一次随机抽取后,将抽取到的样本重新放回,再进行下一次抽样。有放回抽样可以创建与原训练集类似但又不同的新训练集。
袋装决策树:
假设原训练集共有m个样本,那么一共进行B轮,每一轮都进行m次有放回抽样,我们就得到了B个不同的训练集(每个训练集样本个数都是m,且每一个训练集中都可能存在样本重复),也就可以训练B个决策树(一般B取64-128)。
随机森林:
假设样本共有n个特征,在每一棵树每一个节点进行实际节点决策时,规定从k<n的k个特征中,根据最大信息增益来选择特征作为节点,当n的取值较大时,一般取。这样做可以增强森林的多样性,降低树与树之间的相关性,从而提升模型的泛化能力。
假设k=n,那么在所有特征中,总有一个或多个特征是比较具有判别力的,因此在节点选择时每一棵树都会倾向于选择这些特征作为顶部节点进行分裂,也就导致了树具有较高的相似性,树与树之间高度相关。因此这样更有可能导致模型过拟合、泛化能力差。
由于每次分裂时可用的特征不同,每棵树被迫去寻找不同的、可能不那么明显但仍有用的分裂方式。这大大增加了森林中树的多样性。不同的树使用不同的特征集,使得它们犯的错误也不同,从而得到更稳定、更准确的总体预测。
XGBoost:
与袋装决策树的独立随机抽样不同,此时我们不再进行完全的随机抽样,而是增加在已构造的树集合中表现得较差的样本的被抽取到的概率,也就是说,我们在后续决策树的构造中,会更多地关注前面的树中表现不好的样本,尽可能地学习好每一个训练样本,也就增强了模型的泛化能力。可以类比此时的决策树是“串行”的,每一个树(模型)都在尽量地修正前面的树(模型)的错误。
决策树与神经网络:
两者作为有效地机器学习方法,各自适用的范围并不一致。
对于决策树,根据其构造过程可知,其更适用于结构化的数据(也就是可以用表格形式展示的数据),而对于非结构化的图像、音频或文本,则表现不好。同时,其训练速度较快。
对于神经网络,其可以适用于所有类型的数据,不过相应的训练速度较慢,但可以于迁移学习结合,也可以多个神经网络串联。