Fusion to Enhance Fusion Visual Encoder to Enhance Multimodal Language Model
Fusion to Enhance: Fusion Visual Encoder to Enhance Multimodal Language Model
Authors: Yifei She, Huangxuan Wu
Deep-Dive Summary:
FUSION TO ENHANCE: FUSION VISUAL ENCODER TO ENHANCE MULTIMODAL LANGUAGE MODEL
作者: She Yifei, Huangxuan Wu
机构: 北京邮电大学,北京,中国
邮箱: {bupt3.1415926, oddfunction}@bupt.edu.cn
完整代码: 我们的代码库
摘要
多模态大型语言模型(MLLMs)在连接视觉感知与高级文本推理方面取得了显著进展。然而,这些模型面临一个根本性的矛盾:尽管它们在复杂的语义理解方面表现出色,但在需要精确细节感知的基本视觉任务中常常失败。这一缺陷主要源于当前架构对单一视觉编码器的依赖,这种编码器针对高级语义对齐进行了优化,但却牺牲了捕捉细粒度视觉信息的能力。为了解决这一问题,我们提出了“Fusion to Enhance (FtZ)”这一新颖的视觉塔框架。FtZ 超越了单一编码器设计,通过轻量级的多头交叉注意力机制,将一个语义能力强大的锚编码器与一个感知能力丰富的增强编码器创新性地组合在一起。实验结果表明,在多个需要细粒度视觉理解的挑战性基准测试中,例如 TextVQA、POPE、MMMU、MME 和 MM-Vet,我们的 FtZ 模型显著优于仅使用单一编码器或现有特征融合方法的基线。这项工作证明,组合异构专家编码器是克服当前 MLLMs 中视觉感知瓶颈的一种高效且有效的途径,为构建具有更强感知能力的下一代 AI 系统提供了新的设计范式。
1 引言
我们正处于多模态智能的时代。在极短的时间内,多模态大型语言模型(MLLMs)重塑了人工智能的格局,展现了将视觉感知与复杂的文本推理相结合的深远能力[1, 2]。这些模型能够解读复杂的场景,针对图像进行细致的对话,并开启人机交互的新领域[3, 4]。它们的成功预示了一个未来,人工智能可以以与人类相当的流畅度感知、理解和推理我们的世界。然而,在这些先进能力背后,隐藏着一个基本且常被忽视的矛盾。虽然一个MLLM可以为一幅名画创作诗歌,但它可能无法准确地数出画中的人物数量(见图1(a))。MLLM可以分析繁忙街道的上下文,正确推断行人有绿灯,但它在视觉 grounding 的基本任务上失败了,将这种推断呈现为直接观察,实际上是幻觉了一个它无法真正看到的细节(见图1(b))。这种高层次推理与低层次感知之间的巨大差距,导致模型忽视关键细节,无法准确把握空间关系[7, 8]。它们在认知上是巨人,但在许多方面却是感知上的婴儿[9]。这种现象,即模型“识别实例但忽视其状态”,表明它们可以推理所见之物,但并不总是真正“看见”[10]。
这种缺陷的根源并非偶然的瑕疵,而是社区主导架构范式的直接后果:依赖单一的、整体的视觉编码器。绝大多数MLLM的视觉理解(例如Kimi-VL [11]、Qwen-VL [12] 和 Baichuan-Omni [13])基于像CLIP [14]、SigLIP [15]或其他变体这样的视觉编码器,这些编码器明确地预训练以掌握高层次语义对齐。这些视觉编码器要么以原始形式使用,要么作为进一步训练的基础起点。其目标是将图像嵌入映射到同一概念的文本嵌入附近[16]。然而,这种优势伴随着巨大的、不可避免的代价。为了优化语义意义——即“是什么”——这些编码器学会了丢弃定义对象具体状态、纹理和世界中位置的感知细节——即“怎么样”[17]。行业标准的架构在其设计上就造成了一个瓶颈,牺牲了感知保真度以换取语义抽象。这种局限性在需要精确的任务中尤为明显,例如对象计数、属性识别、空间推理和状态区分,即使是最先进的模型也表现出惊人的脆弱性[18]。
之前的努力主要集中在扩展上:更大的数据集、更多的参数或更长的训练计划[19, 20]。然而,这些方法往往收益递减,因为它们未能解决核心的架构限制。其他工作方向探索了任务特定的微调或添加额外模块[21, 22]。但这些解决方案损害了MLLM之所以强大的通用性和效率。因此,该领域面临一个明显的挑战:如何在不牺牲高层次语义理解或定义通用多模态智能的灵活、零样本能力的情况下,增强低层次感知敏锐度?
如果问题是整体的“一刀切”编码器,那么解决方案是否不在于构建一个更好的整体,而在于组合专家?本文介绍了“融合增强”(Fusion to Enhance, FtE),这是一个新颖的框架,优雅地解决了这种固有的架构权衡。我们不是依赖单一视角,而是组合了两个专家视觉编码器:一个语义强大的锚定模型提供高层次理解,一个感知细节的增强模型捕捉细粒度的视觉信息。通过轻量高效的多头交叉注意力机制,锚定模型动态查询增强模型,选择性地提取所需的精确细节以丰富其理解。这种双赢方法协同融合了语义上下文与感知保真度,保留了两个模型宝贵的预训练知识,而无需昂贵的微调。
我们的主要贡献如下:
- 我们系统地分析并证明,依赖单一的、语义偏见的视觉编码器是问题的根源。
- 我们提出了“融合增强”(FtE),一个新颖、灵活且可扩展的框架,利用多头交叉注意力动态融合来自多个预训练视觉专家的特征,产生更丰富、更适应任务的视觉表示,特别是在需要精确感知对象状态、属性和空间关系的复杂场景中,显著优于基线编码器和使用静态特征融合的方法。

2 相关工作
在引言中概述的基础挑战基础上,本节回顾了现有文献,以激励我们的“融合增强”策略。具体而言,我们考察了两个关键领域:当前多模态大语言模型(MLLMs)在视觉感知方面的固有局限性,以及现有视觉特征融合方法的不足。
2.1 MLLMs 在视觉理解方面的局限性
最近的基准测试显示,尽管多模态大语言模型(MLLMs)取得了巨大成功,但在基础视觉理解方面存在关键缺陷。一个核心问题在于物体计数,即使是表现最佳的模型在高物体密度的杂乱现实场景中也表现得很挣扎,如 CountQA 基准测试 [23] 所示。这一局限性不仅仅是数值上的,而是指向更深层次的细粒度空间感知问题。[24] 推测,这种多物体推理任务(包括视觉搜索和数值估计)的失败源于表征干扰,即模型无法正确将特征与其对应的物体绑定。尽管模型通常知道该关注何处,能够正确地关注相关区域,但它们在实际感知小的视觉细节方面失败了,这一局限性与物体大小有因果关联,如 [25] 所示。[26] 使用 TallyQA [27] 和 TDIUC [28] 等专门数据集进一步证实了在复杂计数和位置推理方面的系统性弱点,这一挑战甚至延伸到像素级别,模型在精确理解上挣扎,需要新的评估范式,如 [29] 提出的“类人掩码标注任务”,以评估和改进这些内在的视觉能力,而无需改变模型架构。
除了感知不准确外,MLLMs 还因缺乏事实一致性和鲁棒性而受到影响,表现为视觉幻觉和安全漏洞。[30] 为这一问题建立了一个框架,将错误分为模态冲突幻觉(例如,描述不存在的物体或错误识别属性)和事实冲突幻觉(与已建立的世界知识相矛盾)。Robust-LLaVA [31] 的研究结果进一步揭示了这种脆弱性,表明 MLLMs 极易受到视觉对抗性扰动的影响,这些扰动可以操纵其响应或诱发幻觉。这些攻击凸显了一个关键的安全挑战,影响到在现实世界应用中的部署。
2.2 当前视觉特征融合策略的缺陷
为了解决这些深刻的视觉缺陷,一种有前景的策略是超越单一视觉主干网络,转而融合来自多个专业视觉编码器的特征。然而,最直接的解决方案往往显得粗糙。浅层融合方法,如序列级或通道级的拼接,常常引入比解决的问题更多的麻烦。随着编码器数量的增加,序列拼接在计算上变得难以承受且冗余,而通道级拼接则难以应对分辨率不同的编码器之间的架构不兼容问题,最终无法实现深层次的协同特征融合 [32, 33]。
认识到这些浅层技术的局限性,研究人员探索了更复杂的策略,但这些策略同样充满了妥协。复杂的集成方法,如利用交叉注意力或分辨率混合适配器的机制,常常无法用显著的性能提升来证明其增加的计算和内存开销是合理的 [17, 34, 35]。另一种方法,即解冻并微调编码器,则带来了灾难性遗忘的严重风险,这会侵蚀原本专门的、预训练的知识——例如像 CLIP [14] 这样的视觉-语言模型与像 DINOv2 [36] 这样的自监督模型的独特能力——而这些知识正是最初采用多编码器方法的动机所在 [37]。这一综述揭示了对新范式的明确需求:一种能够以参数高效的方式融合来自异构、专业视觉编码器的特征,而不损害其现有能力的方法。
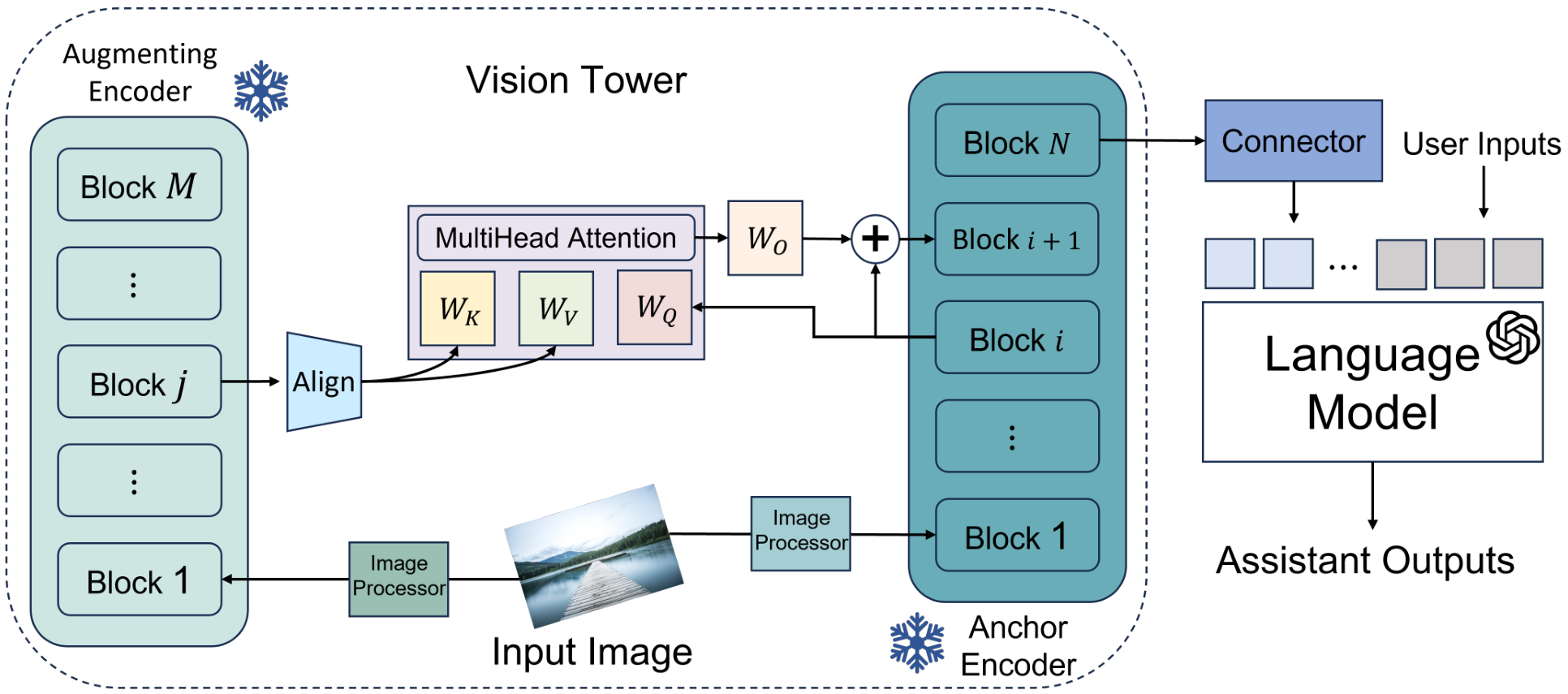
3 方法论
我们提出的方法,Fusion to Enhance (FtE),为多模态大语言模型(MLLMs)引入了一种新颖的基于组合的视觉编码器。该方法植根于对单模态语言领域概念的原则性改编,经过精心重新设计以应对视觉和多模态理解的独特挑战。
3.1 概念框架:从语言到视觉
本文提出的方法受到[38]提出的架构的启发。在其原始情境中,CALM 展示了通过跨注意力机制将通用的“锚点”语言模型与专门的“增强”模型相结合,可以以惊人的参数效率解锁新的能力。这是通过保持核心模型的冻结状态实现的,从而保留了它们大量的预训练知识,同时避免了完全微调带来的灾难性遗忘。
我们的贡献在于将这种强大的组合理念从纯语言情境扩展到复杂的视觉领域。针对融合异构视觉编码器的挑战,我们的工作解决了每个编码器因其独特的预训练范式而带来的不同归纳偏差问题。我们的方法研究并实施了视觉特征融合的策略,需要仔细考虑整合策略,以协调高层次的语义抽象与低层次的感知保真度。
3.2 组合视觉编码器的架构
我们的视觉编码器采用双分支架构,其中两个互补模型协同工作。我们指定预训练的 CLIP 视觉变换器(ViT)[14]作为锚点视觉编码器,将其作为我们系统的语义骨干。选择 CLIP 的理由在于其与自然语言的深刻语义对齐,这是其在海量图像-文本语料库上进行对比训练的直接结果。这使其成为高层次场景解释和物体识别的杰出基础——理解图像中的“是什么”。
然而,这种强大的语义抽象往往以牺牲细粒度的感知细节为代价。为了解决这一固有局限性,我们引入了另一个预训练的 DINOv2 ViT [36]作为专门的增强视觉编码器。DINOv2 通过自监督学习进行训练,擅长捕捉 CLIP 可能忽略的细节:复杂的纹理、物体边界和精确的空间关系。它提供了“看起来如何”的信息,创造了对视觉世界的丰富、高保真的表征。我们以效率为核心原则的一个关键是保留这些宝贵的预训练知识。因此,在我们的训练过程中,锚点和增强视觉编码器的权重始终保持完全冻结。
3.3 融合增强:多头交叉注意力机制
在我们的方法中,我们采用了多头交叉注意力(MHCA)模块,而非在最后阶段进行简单的融合。我们的方法通过在编码器架构的多个层次中战略性地插入这些模块,促进了信息的深度和分层交流。这种设计实现了特征的逐步丰富,将语义上下文(对场景的高层次理解)和感知细节(细粒度的视觉信息)在不断提高的抽象层次上融合在一起。
在组合预训练模型时,一个主要挑战是潜在的结构差异,例如不同的等效相对处理深度。我们首先从锚定编码器中选择一组均匀分布的层,每个层在其自身架构中具有相对位置。例如,锚定层在其较深架构的中点位置(例如第3层,共6层)。这确保了信息在语义上可比较的特征提取阶段之间进行交换,无论架构如何变化,都能保持一致且逻辑合理的融合。
在这些映射的融合点上,记为锚定层 iii 和增强层 jjj 的配对,机制设计为从增强编码器到锚定编码器的单向信息流。这种有意的非对称性确保锚定模型的特征以目标方式得到丰富,而不会被稀释。令 HanchoriH_{\mathrm{anchor}}^iHanchori 表示锚定编码器第 iii 层的表示,HaugmentjH_{\mathrm{augment}}^jHaugmentj 表示增强编码器第 jjj 层的表示。我们机制的核心是使语义感知的锚定特征能够主动“查询”增强编码器的详细特征空间。这使得锚定模型能够选择性地引入最相关的高保真细节,以优化其自身的表示,而不会被无关信息稀释。
正式过程首先是对齐特征维度。增强模型的表示首先通过一个可训练的线性投影 WprojW_{\mathrm{proj}}Wproj,以匹配锚定模型的维度:
KaTeX parse error: Undefined control sequence: \j at position 116: …ze~augrment}}^{\̲j̲}\ W_{\mathrm{\…
从这个对齐后的表示中,使用各自的权重矩阵推导出 MHCA 操作的查询(Q)、键(K)和值(V)向量:
Q=HanchoriWQQ=H_{\mathrm{anchor}}^{i}W_{Q} Q=HanchoriWQ
KaTeX parse error: Undefined control sequence: \j at position 44: …hrm{augment}}^{\̲j̲ ̲j}{\cal W}_{K}
KaTeX parse error: Undefined control sequence: \j at position 48: …e}\underline{{{\̲j̲}}}_{\mathrm{au…
此操作的输出 HcrossH_{\mathrm{cross}}Hcross 捕获了从增强编码器中提取的上下文细节。然后通过残差连接将此输出整合回锚定模型的处理流中,生成更新的层表示 Hanchor′H'_{\mathrm{anchor}}Hanchor′:
iiintDcross⟶UIIICPASPPPPPPPPP\mathcal{iiint}\mathcal{D}\mathsf{c r o s s}\longrightarrow\mathsf{U}\mathsf{I I I}\mathsf{C}\mathsf{P}\mathsf{A}\mathsf{S}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P}\mathsf{P} iiintDcross⟶UIIICPASPPPPPPPPP
KaTeX parse error: Undefined control sequence: \anchor at position 30: …iiint_{\mathrm{\̲a̲n̲c̲h̲o̲r̲}}}}}\longright…
这个更新后的表示 Hanchor′H'_{\mathrm{anchor}}Hanchor′ 被整合到锚定编码器的处理流中。残差连接作为一种自然且高效的门控机制,使模型能够在处理的每个阶段学习最佳的融合程度。
3.4 端到端多模态整合
为了构建一个完整的多模态大语言模型(MLLM),我们将组合的视觉编码器无缝集成到一个标准的端到端架构中。视觉编码器通过并行的、冻结的编码器进行增强,然后通过“融合增强”(Fusion to Enhance)机制在多个深度上丰富锚点视觉编码器的特征,最终生成一组语义丰富、感知细节完整的视觉令牌。通常,这一过程涉及一个多层感知器(MLP)。遵循LLaVA风格架构[39]的成功策略,将这一序列的视觉嵌入添加到文本令牌嵌入之前。最终的组合序列通过自回归方式生成最终答案。
4 实验
本节介绍了我们提出的“融合增强”(FtE)方法的实证评估。我们首先详细说明了实验设置,包括训练框架、数据集和流程。然后介绍了用于评估的基准测试套件以及与我们方法进行比较的基线模型。最后,我们展示了主要结果的全面定量分析,并提供了定性分析以说明实际应用效果。
4.1 实验设置
所有实验均在TinyLLaVA [40]训练框架内进行,利用DeepSpeed [41]库实现高效的分布式训练。我们的训练方法遵循LLaVA [39]推广的标准两阶段策略,包括视觉-语言预训练阶段和监督微调阶段。
第一阶段,视觉-语言预训练,旨在实现视觉编码器与语言模型之间的稳健对齐。此阶段的一个关键目标是训练我们FtE模块的随机初始化参数。为此,我们使用了LAION-CC-SBU图像数据集的558K子集以及blip-laion-cc-sbu标注数据集,与LLaVA预训练[39]相同。此阶段使用全局批次大小为256,学习率为1e-3。
第二阶段,监督微调旨在提升模型遵循复杂指令和进行多模态对话的能力。这是通过使用LLaVA-v1.5-mix665k数据集[39]实现的,该数据集是一个多样化的指令跟随语料库,聚合了包括COCO [42]、GQA [43]、OCR-VQA [44]、TextVQA [45]和Visual Genome [46]在内的多个图像来源。在SFT阶段,我们对FtE模块、投影器和LLM骨干进行微调,使整个模型专注于指令跟随任务。在此阶段,我们使用了全局批次大小。
4.2 评估基准
为了全面评估我们模型的能力,我们采用了一套针对多模态理解不同方面的综合基准测试。对于文本推理,我们使用TextVQA [45],这要求模型不仅执行OCR,还要对识别的文本和视觉上下文进行联合推理,为处理细粒度文本细节提供关键测试。为了评估对象级别的幻觉,我们使用POPE [47],它采用平衡的二元(是/否)问题格式来探测不存在的对象;通过F1分数等指标进行评估,为视觉 grounding 提供了一个稳健的测试,衡量模型对未描绘内容的信心。对于高级的学科特定推理,我们转向MMMU [48],这是一个具有挑战性的基准,包含大学水平的问题,需要解释标准VQA数据集中不存在的复杂、信息丰富的图表和图形。为了进行核心视觉技能的细粒度诊断,我们使用MME [49],它系统地评估了广泛的基本感知和认知任务,包括OCR、对象存在、计数、颜色和位置识别。最后,为了评估在复杂现实世界任务上的表现,我们使用MM-Vet [50],它通过基于GPT-4的流程对开放式答案进行评分,验证我们模型的实用性。
4.3 模型与基线
我们的评估旨在严格测试我们提出的方法与相关且具有竞争力的替代方案的对比。我们比较了三种不同的视觉塔配置。首先是 FtZ(我们的方法),即通过 FtE 机制将 CLIP 和 DINOv2 视觉编码器组合而成的提议融合增强模型。我们将我们的模型与两个强大的基线进行比较。第一个是 CLIP-Only 模型,这是一种标准架构,采用单一预训练的 CLIP 模型作为其视觉塔,代表了典型的无特征融合的多模态大语言模型(MLLM)。第二个是 Interleaved-MoF,这是一个最先进的基线,实现了来自 [17] 的交错特征混合方法。该方法同样结合了 CLIP 和 DINOv2 的特征,但通过在空间上交错它们的最终 token 表示来实现,从而可以与另一种先进的融合技术直接比较。
为了展示我们发现的普适性,我们在两个不同的小规模大语言模型上评估了所有三种视觉塔配置:Qwen2.5-0.5B [51] 和 TinyLlama-1.1B [52]。为了隔离视觉塔的影响,所有实验中的连接器架构保持不变,采用具有 GELU 激活函数的 2 层 MLP。
4.4 主要结果
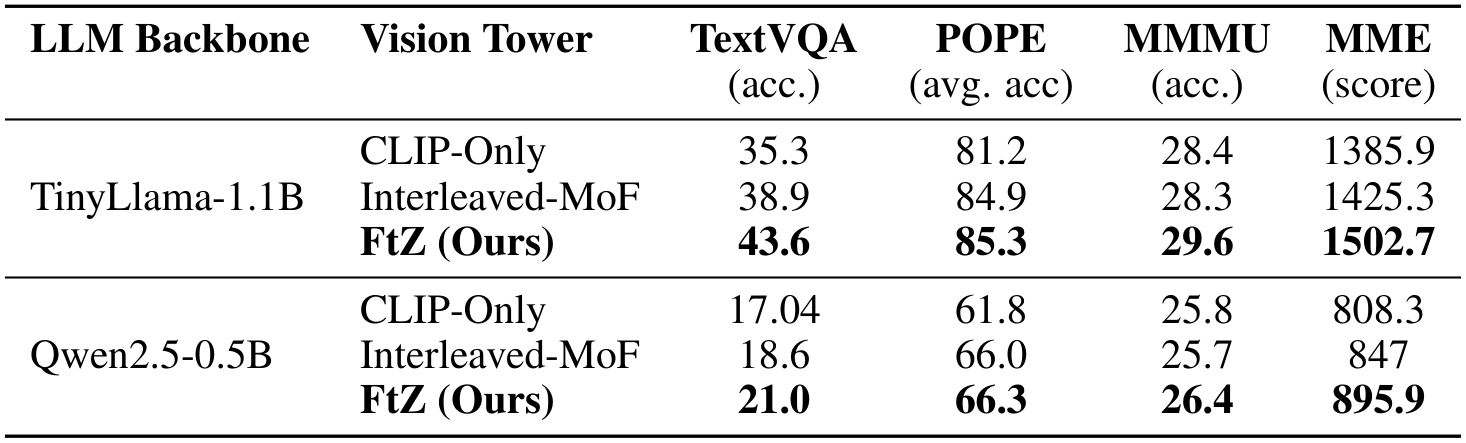
我们比较评估的主要结果展示在表 1 和表 2 中。这些表格展示了我们的 FtZ 方法与基线方法在针对 TinyLlama-1.1B 和 Qwen2.5-0.5B 语言模型主干的一系列全面评估基准上的表现。表 1 详细说明了在评估文本识别、幻觉和一般多模态推理的核心基准上的表现。如表所示,我们的 FtZ 模型预计将优于基线,特别是在需要细粒度视觉细节的基准测试中。
Table 1: 核心多模态基准上的性能比较。对于 TextVQA 和 MMMU,我们报告准确率(acc.)。对于 POPE,我们报告其三个分区的平均准确率(avg. acc)。对于 MME,我们报告总分。我们的 FtZ 方法始终表现出优越的性能。
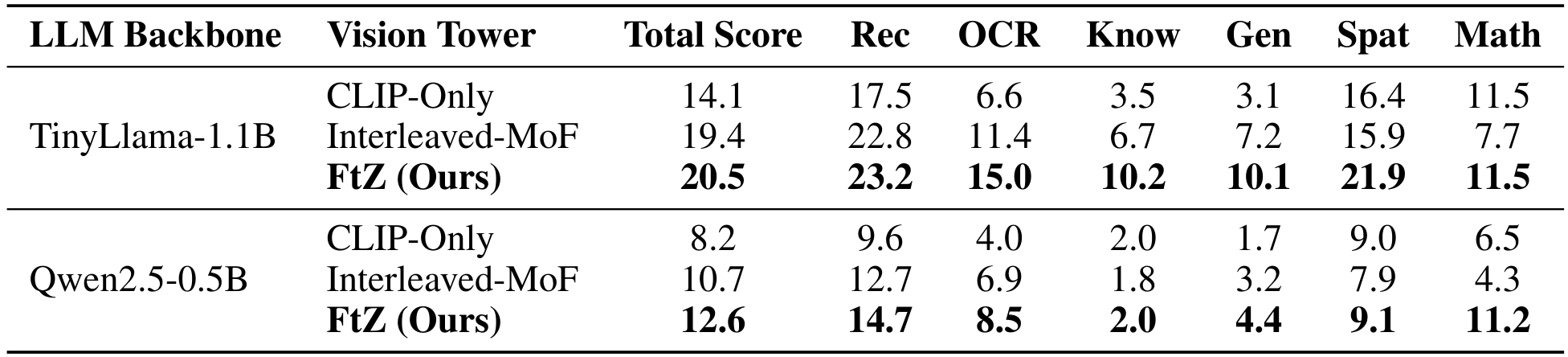
在表 2 中,我们提供了在 MM-Vet 基准上的详细性能分解,该基准评估了广泛的集成视觉-语言能力。这种细粒度分析进一步突出了我们的融合方法在特定领域提供的最大优势。
如表 1 和表 2 所示,我们提出的 FtZ 方法预计将在大多数基准测试中相比 CLIP-Only 和 Interleaved-MoF 基线取得优越的表现。我们预计在需要细粒度细节感知和强大视觉基础的任务(如 TextVQA 和 POPE)上会有最显著的改进。这一结果表明,我们的 FtE 融合策略提供了比 MoF 的 token 级交错策略更为复杂和有效的整合互补特征的机制。与 CLIP-Only 基线相比的显著性能提升验证了我们的核心假设:组合异构视觉编码器是克服单模态视觉塔已知感知限制的关键步骤。这些性能趋势预计在 TinyLlama-1.1B 和 Qwen2.5-0.5B 两种主干上均成立,表明我们 FtZ 架构的益处具有普适性,并不依赖于特定的语言模型。
4.5 结果分析
本文在表1和表2中呈现的定量结果为FtZ框架的有效性提供了令人信服的证据。在两个不同的LLM主干模型上,FtZ始终显著优于标准的CLIP-Only架构和先进的Interleaved-MoF融合基线,验证了我们的核心假设,即动态的、基于组合的融合策略在增强MLLMs的感知能力方面具有优越性。
通过对表1中核心基准的详细检查,可以发现我们方法的具体优势。在TextVQA任务中,FtZ的得分比CLIP-Only模型(35.3%)高出6.3个百分点,比Interleaved-MoF(38.9%)高出4.7个百分点。这表明FtZ在需要详细文本识别和推理的TextVQA任务中至关重要。同样,在评估广泛基本感知技能的MME基准中,FtZ获得1502.7的分数,分别比CLIP-Only和Interleaved-MoF模型高出116.8和77.4分。这种全方位的改进凸显了FtZ在创建更全面的视觉系统方面的能力。此外,在旨在测量对象级幻觉的POPE基准上,FtZ达到了最高的平均准确率(85.3%),表明其视觉 grounding 能力得到改善,并且更能辨别对象的缺失。在Qwen2.5-0.5B主干模型上也观察到同样的优越模式,证实了FtZ架构的益处具有普遍性,并非特定于单一语言模型。
表2中MM-Vet基准提供的细化分析进一步揭示了FtZ成功背后的原因。使用TinyLlama-1.1B模型时,FtZ在高度依赖感知敏锐度的类别中表现出最显著的提升。在OCR类别中,FtZ得分15.0,是CLIP-Only基线(6.6)的两倍以上,并且远超Interleaved-MoF(11.4)。在空间意识(Spat)方面,FtZ得分21.9,相比CLIP-Only(16.4)和Interleaved-MoF(15.9)有显著提升。这些结果直接支持了我们的主张,即通过允许语义锚点(CLIP)动态查询感知专家(DINOv2),我们的模型能够更好地理解和推理图像中的精确文本细节和空间关系。这种增强的感知能力为更高层次的能力奠定了更坚实的基础,从而在识别(Rec)、基于知识的推理(Know)和生成(Gen)等方面取得了显著改进。
总之,全面的实证证据一致表明,FtZ框架提供了比现有方法更强大的特征融合机制。通过智能组合异构编码器,FtZ有效缓解了单编码器MLLMs固有的感知缺陷,从而构建了一个更稳健、准确和可靠的多模态系统。
5 结论
本研究针对多模态大型语言模型(MLLMs)在高级推理与较弱感知能力之间的关键脱节问题进行了探讨,我们将这一缺陷归因于其依赖单一、语义聚焦的视觉编码器。我们提出了“融合增强”(FtZ)这一新颖框架,该框架基于“组合优于单一”的原则。通过轻量级、参数高效的多头交叉注意力机制,将语义锚点与感知增强器协同融合,FtZ 在无需昂贵微调的情况下,将高层次特征与必要的细粒度细节相结合。我们在多个具有挑战性的基准测试中取得了持续且显著的性能提升,特别是在 TextVQA 等任务上,实证验证了我们的核心假设:精确的感知与语义理解并非零和游戏,而是可以有力结合,创造出更具能力且全面的视觉系统。
FtZ 的成功倡导了多模态架构设计范式的更广泛转变——从追求单一通用编码器转向智能组合专业化专家。尽管我们认识到未来需要在更大规模模型上验证这一方法,并分析推理开销的权衡,但我们的框架开辟了有前景的研究方向。这些方向包括探索两个以上专家编码器的动态融合,以及将这一组合范式扩展到其他模态,如音频和视频。最终,本研究为开发更健壮、全面且真正多模态的 AI 系统奠定了基础,这些系统既能对世界进行推理,又能以更高的保真度感知世界。
致谢
本研究得到了北京邮电大学未来学院“未来学者计划”(编号:2024WLPY03)的支持。
A 案例研究
本节通过两个案例研究直观展示了 CLIP-Only 模型与 FtZ 在感知及其对严重视觉幻觉的鲁棒性方面的性能差异。
A.1 案例研究 1:准确的文本识别

问题:图片中的英文单词是什么?
表 3:OCR 任务的模型响应。FtZ 和 Interleaved-MoF 正确识别了文本,而 CLIP-Only 模型失败了。


问题:详细描述场景。
表 4:场景描述任务的模型响应。CLIP-Only 模型出现了严重的幻觉,描述了一个完全不同的场景。FtZ 提供了最详细和准确的描述。

Original Abstract: Multimodal Large Language Models (MLLMs) have made significant progress in
bridging visual perception with high-level textual reasoning. However, they
face a fundamental contradiction: while excelling at complex semantic
understanding, these models often fail at basic visual tasks that require
precise detail perception. This deficiency primarily stems from the prevalent
architectural reliance on a single vision encoder optimized for high-level
semantic alignment, which inherently sacrifices the ability to capture
fine-grained visual information. To address this issue, we introduce Fusion to
Enhance (FtZ), a novel vision tower framework. FtZ moves beyond the
single-encoder design by innovatively composing a semantically powerful anchor
encoder with a perception-rich augmenting encoder via a lightweight Multi-Head
Cross-Attention mechanism. Experimental results demonstrate that on several
challenging benchmarks demanding fine-grained visual understanding, such as
TextVQA, POPE, MMMU, MME and MM-Vet, our FtZ model significantly outperforms
baselines that use only a single encoder or existing feature fusion methods.
This work proves that composing heterogeneous expert encoders is an efficient
and effective path to overcoming the visual perception bottleneck in current
MLLMs, offering a new design paradigm for building next-generation AI systems
with stronger perceptual capabilities.
PDF Link: 2509.00664v1
部分平台可能图片显示异常,请以我的博客内容为准
