【FireCrawl】:本地部署AI爬虫+DIFY集成+V2新特性
目录
1 安装
1.1 拉取firecrawl项目
1.2 配置 .env 文件
1.3 容器的构建和启动
1.4 启动成功测试
2 firecrawl 与 dify
2.1 接入dify
2.2 dify 工作流
2.3 使用firecarwl构建知识库问答
3 python SDK 调用
3.1 python 基本调用
3.2 firecrawl v2新特性
3.3 firecrawl + beautifulsoup的快速爬取
3.4 尝试firecrawl整站爬取
1 安装
1.1 拉取firecrawl项目
git clone https://github.com/firecrawl/firecrawl.git
1.2 配置 .env 文件
复制一份示例.env文件
cd firecrawl
cp apps/api/.env.example .env
设置.env 参数
关闭数据库相关
设置访问的API KEY

文件源码如下
# ===== Required ENVS ======
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://redis:6379 #for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379 #for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/scrape## To turn on DB authentication, you need to set up supabase.
USE_DB_AUTHENTICATION=false# ===== Optional ENVS ======# SearchApi key. Head to https://searchapi.com/ to get your API key
SEARCHAPI_API_KEY=
# SearchApi engine, defaults to google. Available options: google, bing, baidu, google_news, etc. Head to https://searchapi.com/ to explore more engines
SEARCHAPI_ENGINE=# Supabase Setup (used to support DB authentication, advanced logging, etc.)
SUPABASE_ANON_TOKEN=
SUPABASE_URL=
SUPABASE_SERVICE_TOKEN=# Other Optionals
# use if you've set up authentication and want to test with a real API key
TEST_API_KEY=qwer1234!@#$
# set if you'd like to test the scraping rate limit
RATE_LIMIT_TEST_API_KEY_SCRAPE=
# set if you'd like to test the crawling rate limit
RATE_LIMIT_TEST_API_KEY_CRAWL=
# set if you'd like to use scraping Be to handle JS blocking
SCRAPING_BEE_API_KEY=
# add for LLM dependednt features (image alt generation, etc.)
BULL_AUTH_KEY=@
# set if you have a llamaparse key you'd like to use to parse pdfs
LLAMAPARSE_API_KEY=
# set if you'd like to send slack server health status messages
SLACK_WEBHOOK_URL=
# set if you'd like to send posthog events like job logs
POSTHOG_API_KEY=
# set if you'd like to send posthog events like job logs
POSTHOG_HOST=STRIPE_PRICE_ID_STANDARD=
STRIPE_PRICE_ID_SCALE=
STRIPE_PRICE_ID_STARTER=
STRIPE_PRICE_ID_HOBBY=
STRIPE_PRICE_ID_HOBBY_YEARLY=
STRIPE_PRICE_ID_STANDARD_NEW=
STRIPE_PRICE_ID_STANDARD_NEW_YEARLY=
STRIPE_PRICE_ID_GROWTH=
STRIPE_PRICE_ID_GROWTH_YEARLY=# set if you'd like to use the fire engine closed beta
FIRE_ENGINE_BETA_URL=# Proxy Settings for Playwright (Alternative you can can use a proxy service like oxylabs, which rotates IPs for you on every request)
PROXY_SERVER=
PROXY_USERNAME=
PROXY_PASSWORD=
# set if you'd like to block media requests to save proxy bandwidth
BLOCK_MEDIA=# Set this to the URL of your webhook when using the self-hosted version of FireCrawl
SELF_HOSTED_WEBHOOK_URL=# Resend API Key for transactional emails
RESEND_API_KEY=# LOGGING_LEVEL determines the verbosity of logs that the system will output.
# Available levels are:
# NONE - No logs will be output.
# ERROR - For logging error messages that indicate a failure in a specific operation.
# WARN - For logging potentially harmful situations that are not necessarily errors.
# INFO - For logging informational messages that highlight the progress of the application.
# DEBUG - For logging detailed information on the flow through the system, primarily used for debugging.
# TRACE - For logging more detailed information than the DEBUG level.
# Set LOGGING_LEVEL to one of the above options to control logging output.
LOGGING_LEVEL=INFO# x402 Payment Configuration
X402_PAY_TO_ADDRESS=# ^ Address taken from -> https://portfolio.metamask.io/
X402_NETWORK=base-sepolia
X402_FACILITATOR_URL=https://x402.org/facilitator
X402_ENABLED=true
X402_VERIFICATION_TIMEOUT=30000CDP_API_KEY_ID=""
CDP_API_KEY_SECRET=""# ^ KEYS taken from -> https://portal.cdp.coinbase.com/projects/api-keys## ENDPOINT PRICING TEST $0.01
X402_ENDPOINT_PRICE_USD=0.011.3 容器的构建和启动
docker compose build
docker compose up -d
1.4 启动成功测试
输入对应网址测试显示 hello,world!

2 firecrawl 与 dify
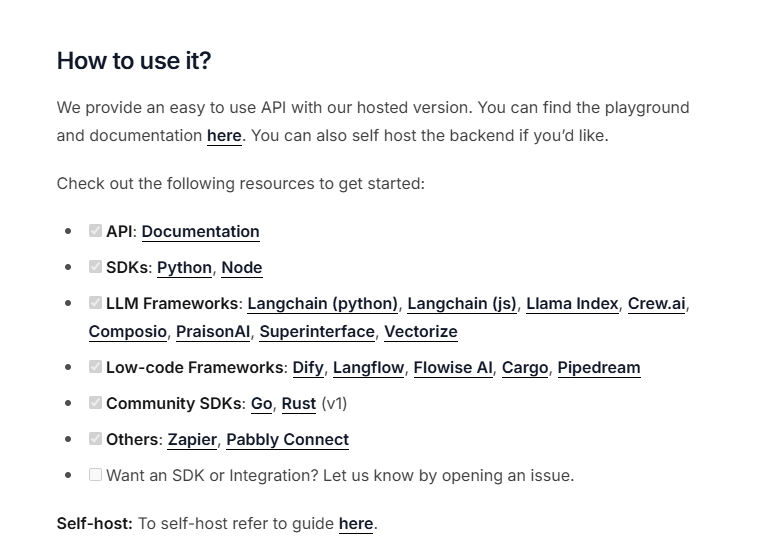
2.1 接入dify
进入设置的数据来源,点击firecrawl配置
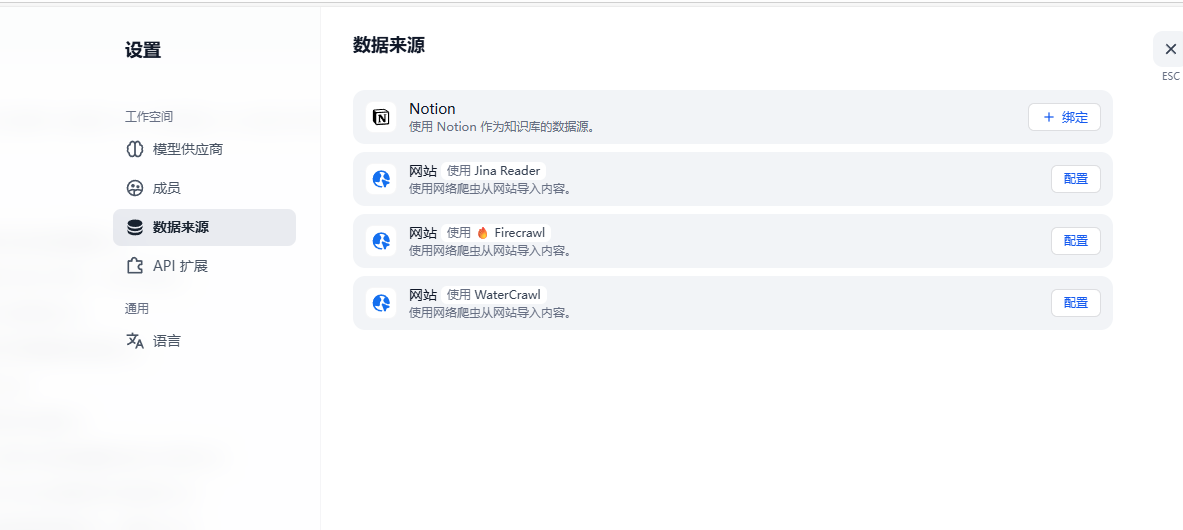
输入服务地址和之前设置的API KEY
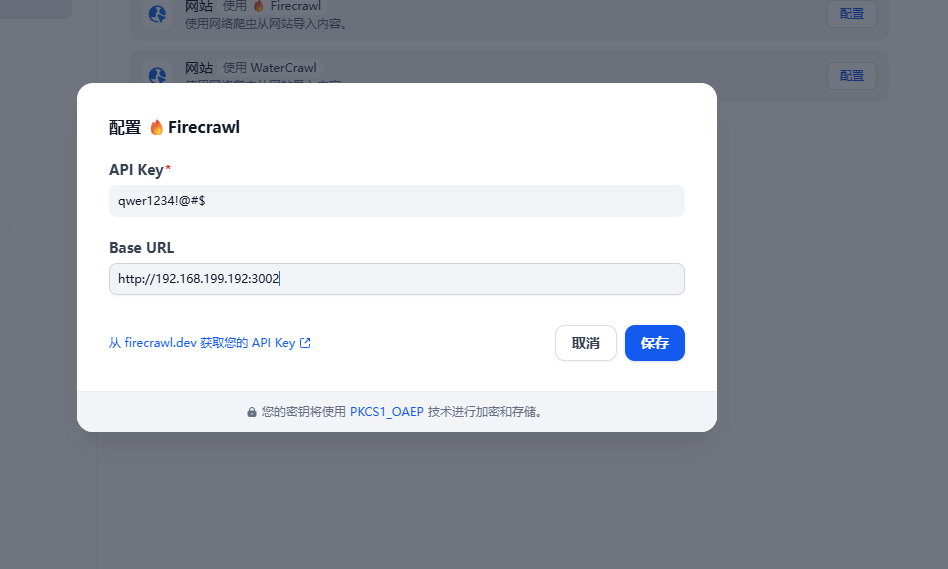
2.2 dify 工作流
在配置了firecrawl之后,在创建节点的工具里面就有firecrawl,里面有地图,整个网站爬取,单页面爬取等;
下图是一个单页面爬取:返回格式是爬取之后firecrawl会处理一下,方便用户后续使用,因为dify已经页面化,就不做过多解释,有中文参数解释
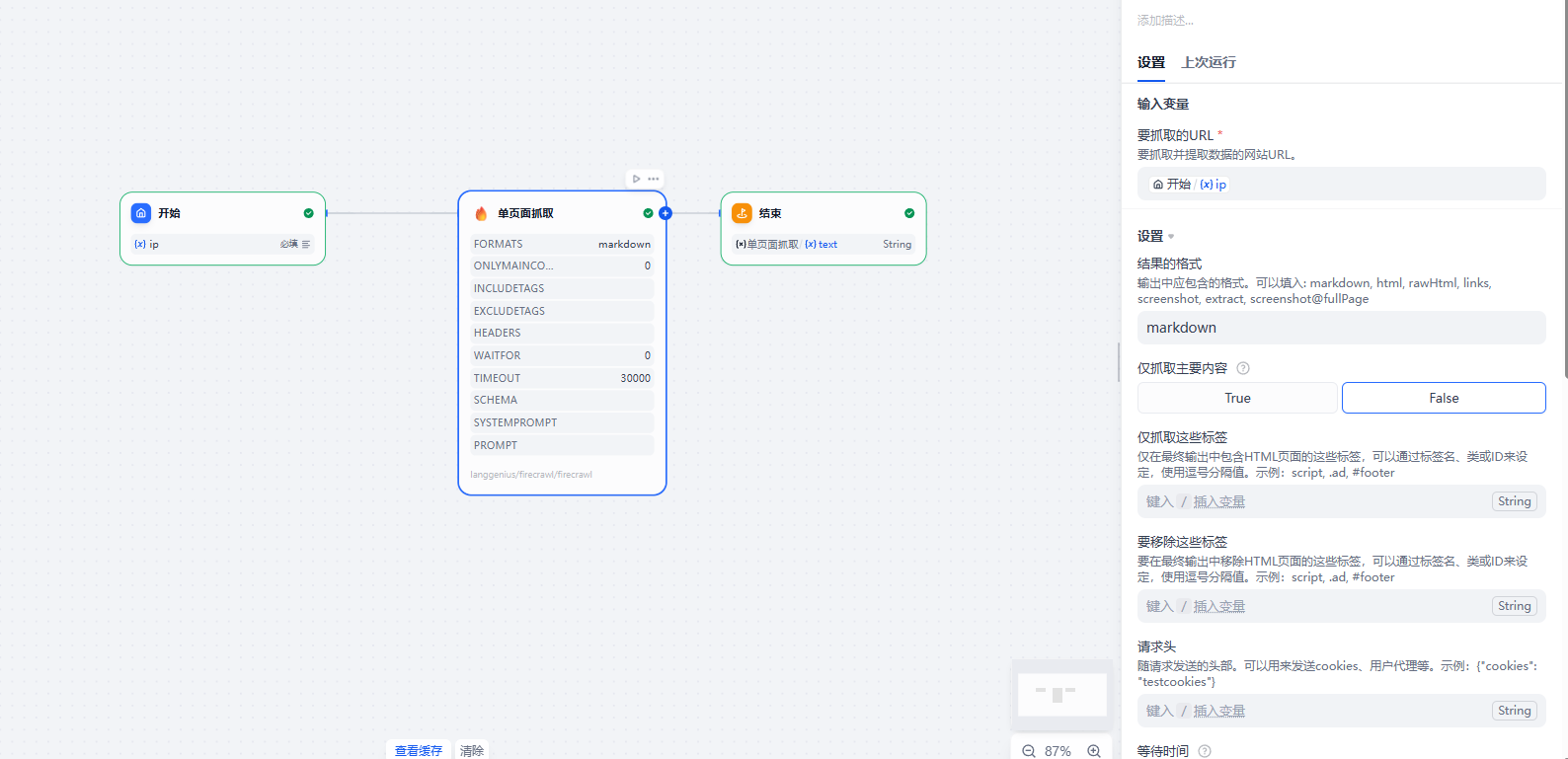
运行结果如下
输入百度
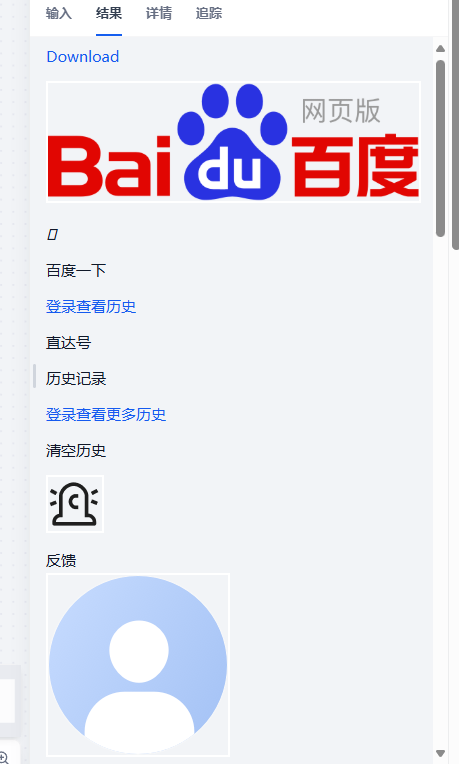
得到百度页面的md格式数据
2.3 使用firecarwl构建知识库问答
爬取csdn网站的10个页面来构建知识库
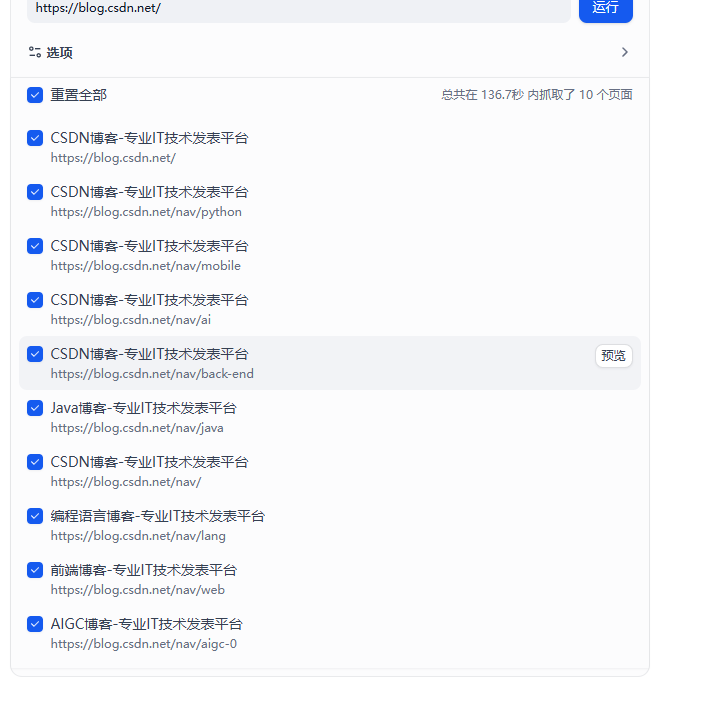
成功爬取10页面
采用最基本的分词模式处理
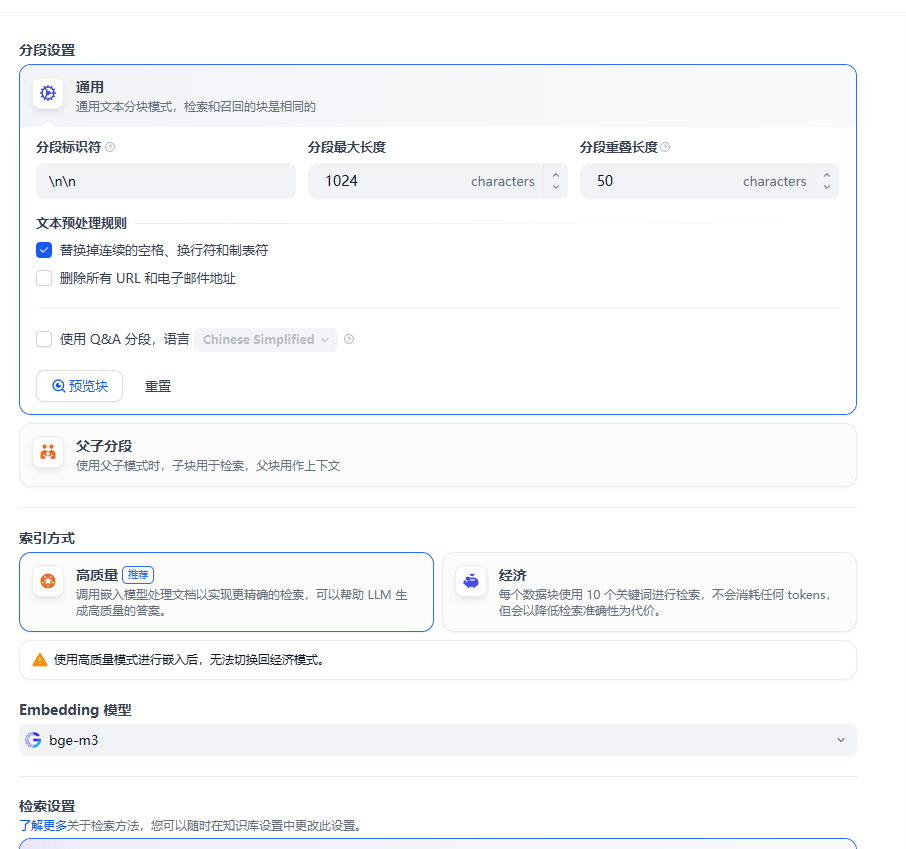
构建对话流
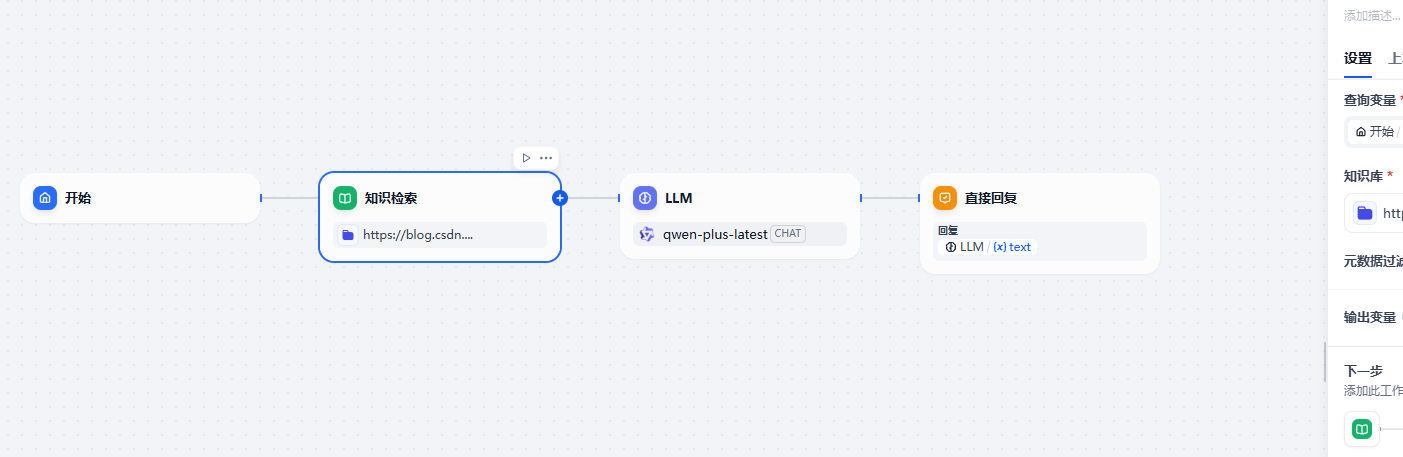
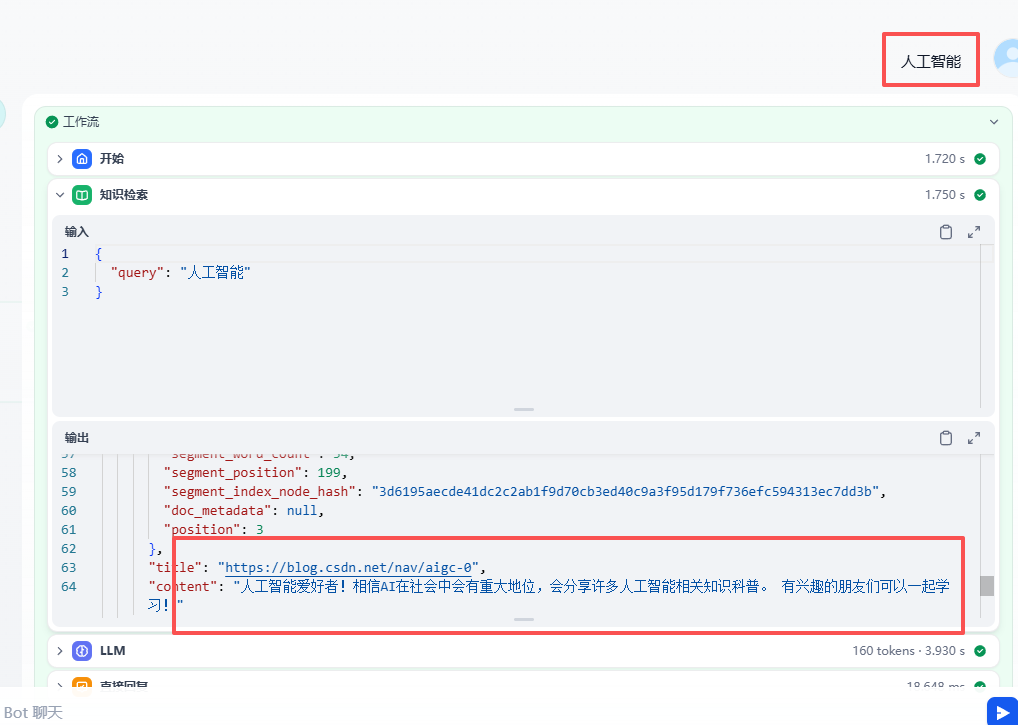
测试:成功检测到知识库中的内容,完成问答
3 python SDK 调用
Advanced Scraping Guide | Firecrawl
3.1 python 基本调用
"""
爬取百度
"""import os
from firecrawl import FirecrawlApp# 配置本地 API 地址,端口需与你的部署一致
LOCAL_FIRECRAWL_API_URL = "http://192.168.199.192:3002" # 通常是 http://localhost:3002/v0 或 /v1# 初始化 App 并指向本地服务
# 如果本地部署设置了认证,请提供 api_key;若未设置,可省略或设为 None
firecrawl = FirecrawlApp(api_url=LOCAL_FIRECRAWL_API_URL, api_key='qwer1234!@#$') # 或你的本地 API Keyprint(f"[*] 客户端已配置,将连接到本地服务: {LOCAL_FIRECRAWL_API_URL}")scrape_status = firecrawl.scrape('www.baidu.com', formats=['markdown']
)
print(scrape_status)结果如下:

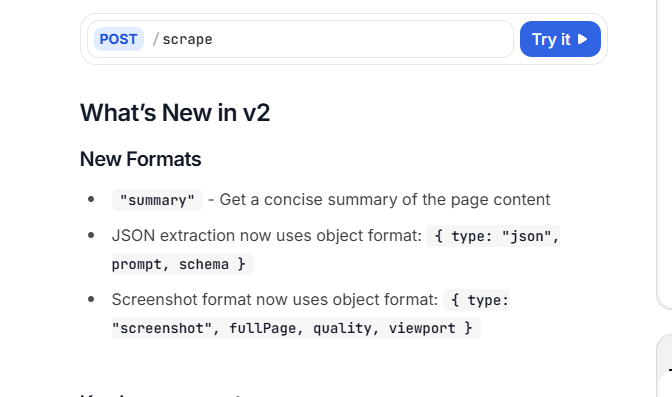
3.2 firecrawl v2新特性
新特性分别是页面摘要,提取数据和截图
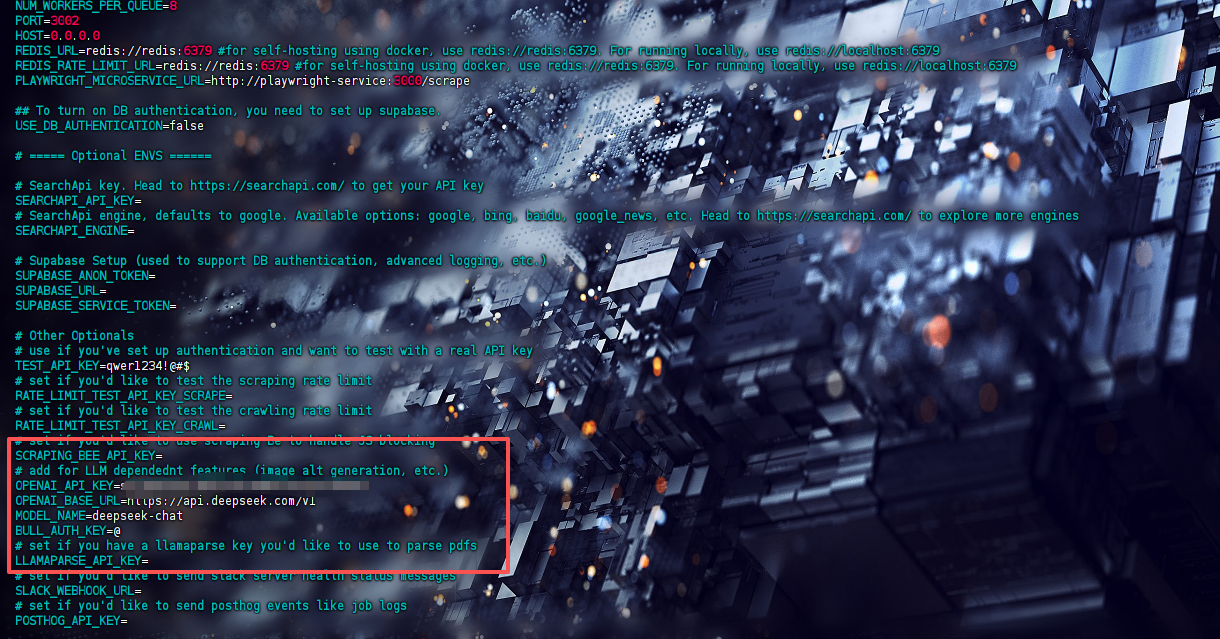
首先在.env 文件中增加 大模型的地址和api key等环境变量(默认的只有openai_api_key,要想使用自己本地部署或者其他家的大模型就需要增加地址和模型名称这两个环境变量)
其次就是调用参数的输入,主要是formats这个参数,summary(页面摘要的返回),markdown,rawhtml等都是都是数组中的字符串格式,规定了返回的类型,要想使用数据提取和截图功能就要在这些字符串后面添加一个json变量,如下图所示:

数据提取json的要求如下:

示例:
{"type": "json","prompt": "提取指令描述","schema": {"type": "object","properties": {"字段名": {"type": "数据类型","description": "字段描述",// 其他约束条件}}}
}截图json的要求如下:

示例:
{"type": "screenshot","fullPage": True, # 全屏截图"quality": 85, # 图片质量 (1-100)"viewport": {"width": 1920, "height": 1080} # 视口尺寸
}完整代码如下(爬取csdn并且生成总结,使用数据提取将核心数据提取,并且截图):
# --------------------------
# Firecrawl v2 CSDN博客数据提取工具
# 使用Firecrawl v2新特性进行智能数据提取
# --------------------------from firecrawl import FirecrawlApp
import json
import requests
from datetime import datetime
import traceback# --------------------------
# 基础配置
# --------------------------
LOCAL_FIRECRAWL_API_URL = "http://192.168.199.192:3002" # 本地Firecrawl服务地址
FIRECRAWL_API_KEY = "qwer1234!@#$" # Firecrawl API密钥
TARGET_CSDN_URL = "https://blog.csdn.net" # 目标URL:CSDN博客首页# --------------------------
# 辅助函数
# --------------------------
def check_service_health(service_url: str) -> bool:"""检查Firecrawl服务是否正常"""try:response = requests.get(f"{service_url}/test", timeout=10)return response.status_code == 200 and "hello" in response.text.lower()except:return False# --------------------------
# Firecrawl v2 JSON提取配置详解
# --------------------------
"""
Firecrawl v2 JSON提取使用对象格式:
{"type": "json","prompt": "提取指令描述","schema": {"type": "object","properties": {"字段名": {"type": "数据类型","description": "字段描述",// 其他约束条件}}}
}参数说明:
- type: "json" - 固定值,表示JSON提取
- prompt: 自然语言指令,告诉AI要提取什么数据
- schema: JSON Schema结构定义,指定提取数据的格式支持的数据类型:
- string: 字符串
- number: 数字
- array: 数组
- object: 对象
- boolean: 布尔值示例用法:
1. 提取结构化数据
2. 内容分类和标签
3. 实体识别(人物、地点、产品等)
4. 情感分析
5. 关键信息提取
"""# JSON提取配置 - CSDN博客数据提取
CSDN_JSON_EXTRACTION_CONFIG = {"type": "json","prompt": """从CSDN博客首页提取以下结构化数据(使用中文):1. 热门技术文章列表(标题、作者、阅读量、点赞数、分类标签)2. 推荐技术博主信息(名称、粉丝数、擅长领域)3. 热门技术话题/标签4. 平台功能特性请确保数据准确且使用中文输出。""","schema": {"type": "object","properties": {"hot_articles": {"type": "array","items": {"type": "object","properties": {"title": {"type": "string", "description": "文章标题"},"author": {"type": "string", "description": "作者名称"},"read_count": {"type": "string", "description": "阅读量"},"like_count": {"type": "string", "description": "点赞数"},"tags": {"type": "array", "items": {"type": "string"}, "description": "文章标签"}}}},"recommended_authors": {"type": "array", "items": {"type": "object","properties": {"name": {"type": "string", "description": "博主名称"},"fans_count": {"type": "string", "description": "粉丝数量"},"expertise": {"type": "array", "items": {"type": "string"}, "description": "擅长领域"}}}},"hot_topics": {"type": "array","items": {"type": "string", "description": "热门技术话题"}},"platform_features": {"type": "array","items": {"type": "string", "description": "平台功能特性"}}}}
}# --------------------------
# 截图配置
# --------------------------
SCREENSHOT_CONFIG = {"type": "screenshot","fullPage": True, # 全屏截图"quality": 85, # 图片质量 (1-100)"viewport": {"width": 1920, "height": 1080} # 视口尺寸
}# --------------------------
# 核心抓取函数
# --------------------------
def crawl_csdn_with_ai():"""使用Firecrawl v2 AI功能抓取CSDN数据"""# 1. 服务检查if not check_service_health(LOCAL_FIRECRAWL_API_URL):print("[❌] Firecrawl服务不可用")return# 2. 初始化客户端try:firecrawl = FirecrawlApp(api_url=LOCAL_FIRECRAWL_API_URL, api_key=FIRECRAWL_API_KEY)print("[✅] Firecrawl客户端初始化成功")except Exception as e:print(f"[❌] 初始化失败: {e}")return# 3. 执行抓取(使用v2所有新特性)try:print("[*] 开始AI数据提取...")# Firecrawl v2 formats参数配置result_doc = firecrawl.scrape(TARGET_CSDN_URL,formats=["summary", # AI生成页面摘要CSDN_JSON_EXTRACTION_CONFIG, # JSON AI提取"markdown", # 原始markdown内容SCREENSHOT_CONFIG # 全屏截图])print("[✅] AI提取成功!")# 4. 处理提取结果result_data = {'summary': getattr(result_doc, 'summary', None),'json': getattr(result_doc, 'json', None),'markdown': getattr(result_doc, 'markdown', None),'screenshot': getattr(result_doc, 'screenshot', None),'metadata': {'title': getattr(result_doc.metadata, 'title', None) if hasattr(result_doc, 'metadata') else None,'url': getattr(result_doc.metadata, 'url', None) if hasattr(result_doc, 'metadata') else None,}}# 5. 保存结果filename = f"csdn_ai_result_{datetime.now().strftime('%Y%m%d%H%M%S')}.json"with open(filename, "w", encoding="utf-8") as f:json.dump(result_data, f, ensure_ascii=False, indent=2)print(f"[💾] 结果已保存: {filename}")print("[🎉] 任务完成!Firecrawl v2所有特性测试成功")# 6. 显示关键提取结果if result_data.get('json'):json_data = result_data['json']print("\n" + "="*60)print("AI提取的核心数据:")print("="*60)if json_data.get('hot_articles'):print(f"📚 热门文章: {len(json_data['hot_articles'])}篇")for article in json_data['hot_articles'][:3]:print(f" • {article.get('title')} (阅读: {article.get('read_count')})")if json_data.get('hot_topics'):print(f"🏷️ 热门话题: {', '.join(json_data['hot_topics'][:5])}")except Exception as e:print(f"[❌] 提取失败: {e}")traceback.print_exc()# --------------------------
# 主程序
# --------------------------
if __name__ == "__main__":print("🚀 Firecrawl v2 CSDN数据提取工具")print("📖 使用JSON extraction object format进行AI数据提取")crawl_csdn_with_ai()1
运行结果如下成功提取页面摘要,使用一句话描述该页面,提取了热门技术文章的结构化数据,并且保存到了文件中去
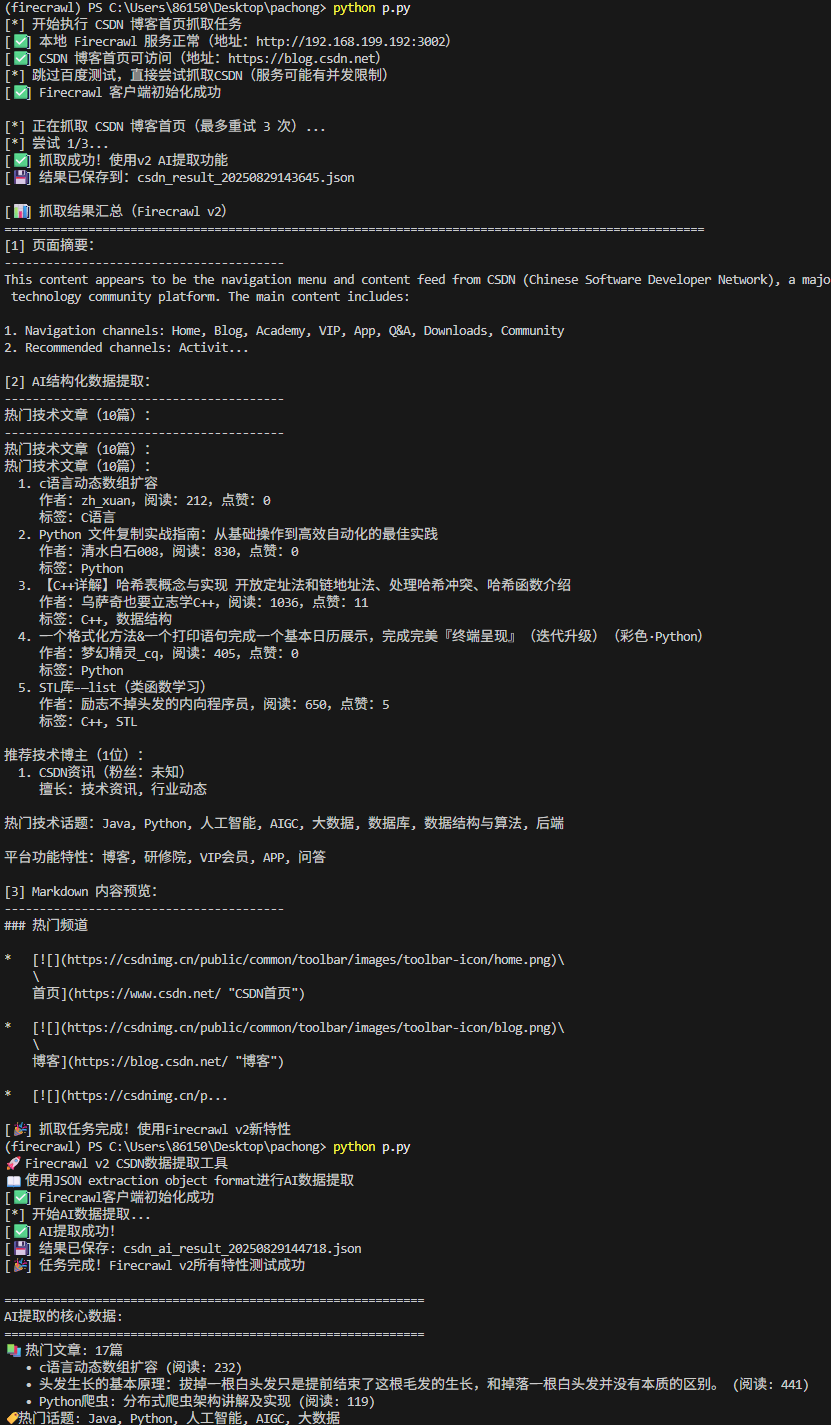
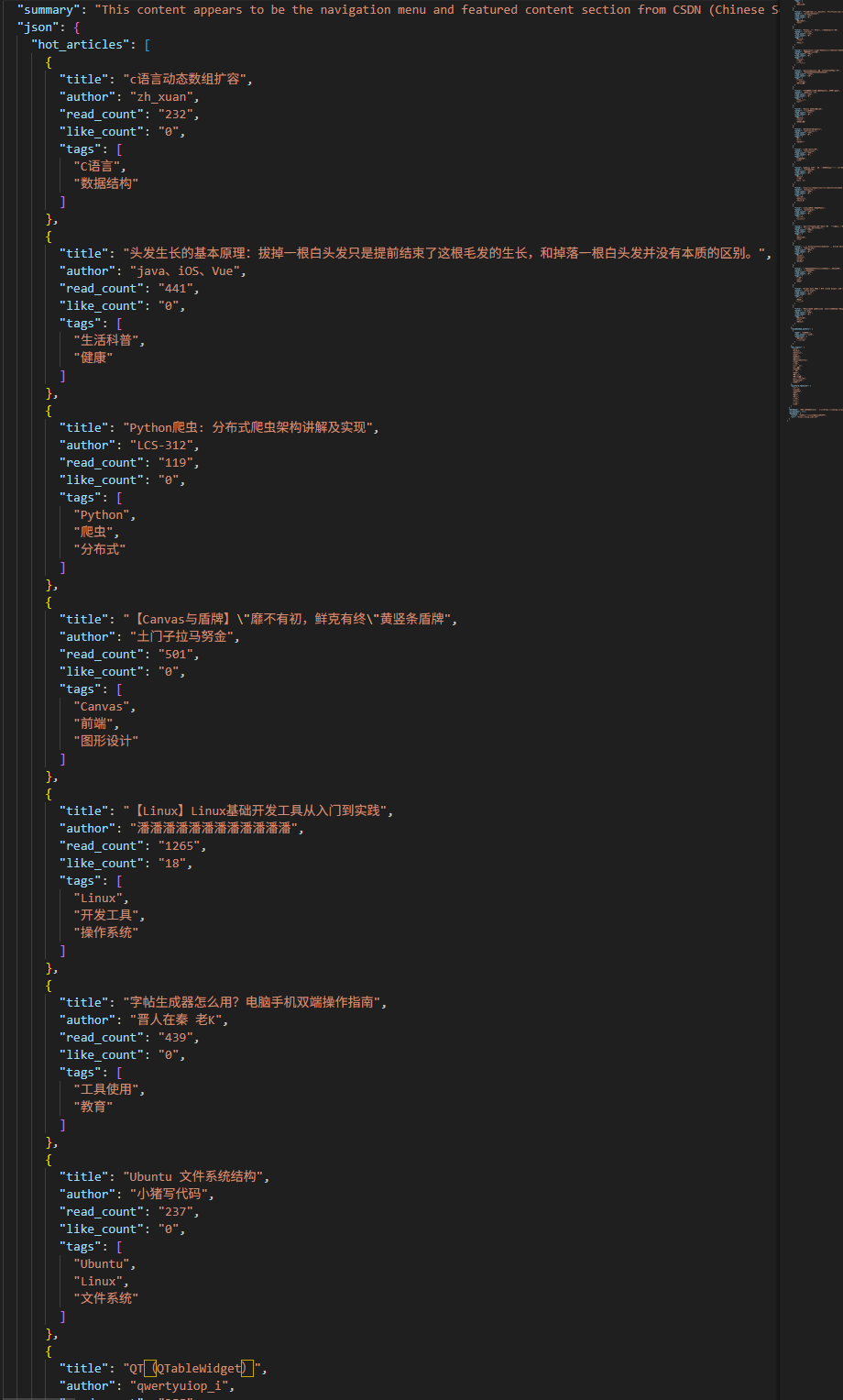
缺点:因为要调用大模型处理数据,所以比较慢
3.3 firecrawl + beautifulsoup的快速爬取
(登入状态使用cookie解决)
使用firecrawl爬取页面得到html页面,在使用beautifulsoup定位关键内容提取数据
from firecrawl import FirecrawlApp
from bs4 import BeautifulSoup
import json
import requestsLOCAL_FIRECRAWL_API_URL = "http://192.168.199.192:3002"
FIRECRAWL_API_KEY = "qwer1234!@#$"
url = "http://dspace.imech.ac.cn/handle/311007/1"# 初始化Firecrawl客户端
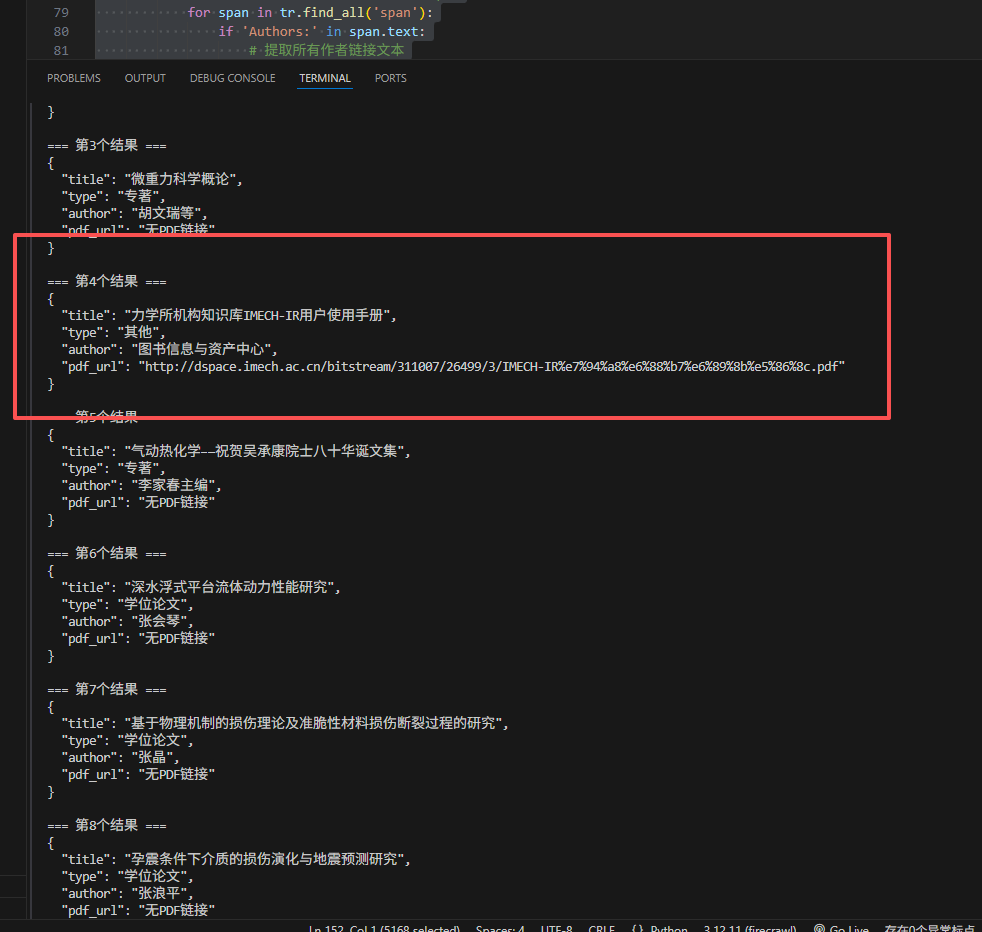
firecrawl = FirecrawlApp(api_url=LOCAL_FIRECRAWL_API_URL, api_key=FIRECRAWL_API_KEY)try:print("开始爬取单页...")# 简化配置,先确保基础功能正常scrape_options = {"formats": ["html"], # 只获取HTML格式"only_main_content": False, # 获取完整页面"headers" :{"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Cache-Control": "max-age=0","Connection": "keep-alive","Cookie": "td_cookie=1215501483;JSESSIONID=73C3D6E91658482FAADA7A07E97A3A9B","Host": "dspace.imech.ac.cn","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"},"wait_for": 3000, # 等待时间"timeout": 15000, # 超时时间}# 尝试爬取result = firecrawl.scrape(url, **scrape_options)print(f"爬取成功!响应类型: {type(result)}")# 检查结果并获取HTML内容html_content = Noneif hasattr(result, 'html'):html_content = result.htmlprint("从result.html获取内容")elif isinstance(result, dict) and 'html' in result:html_content = result['html']print("从result字典的html键获取内容")else:print("无法获取HTML内容,原始响应:", result)exit()print(f"HTML内容长度: {len(html_content)}")# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(html_content, 'html.parser')# 查找所有符合条件的tr元素tr_elements = soup.find_all('tr', class_='itemLine')results = []for tr in tr_elements:try:# 提取数据item_id = tr.find('input', {'name': 'item'})['value']# 提取标题 - 从strong标签获取title_element = tr.find('strong')title = title_element.text.strip() if title_element else "未知"# 提取类型 - 从class为patent的a标签获取type_element = tr.find('a', class_='patent')item_type = type_element.text if type_element else "未知"# 改进的作者提取方法author = "未知"# 方法1: 查找包含"Authors:"文本的spanfor span in tr.find_all('span'):if 'Authors:' in span.text:# 提取所有作者链接文本author_links = span.find_all('a')if author_links:# 提取所有作者文本并用逗号分隔authors = [link.text for link in author_links]author = ", ".join(authors)break# 如果没有找到链接,尝试直接提取文本内容span_text = span.text.replace('Authors:', '').replace(' ', '').strip()if span_text:author = span_textbreak# 方法2: 如果上述方法失败,尝试更通用的方法if author == "未知":# 查找所有span,寻找可能包含作者信息的文本for span in tr.find_all('span'):text = span.text.strip()if ('作者:' in text or 'Authors:' in text) and len(text) < 100: # 限制长度以避免误匹配# 提取作者部分author_text = text.split(':')[-1].replace(' ', '').strip()if author_text:author = author_textbreak# 提取PDF链接 - 从包含"bitstream"的a标签获取pdf_element = tr.find('a', href=lambda x: x and 'bitstream' in x)pdf_url = pdf_element['href'] if pdf_element else "无PDF链接"# 构建完整URL(如果需要)if pdf_url.startswith('/'):pdf_url = "http://dspace.imech.ac.cn" + pdf_url# 构建JSON对象item_data = {"title": title,"type": item_type,"author": author,"pdf_url": pdf_url}results.append(item_data)except Exception as e:print(f"处理元素时出错: {str(e)}")import tracebacktraceback.print_exc()continue# 输出所有提取的数据for i, result in enumerate(results):print(f"=== 第{i+1}个结果 ===")print(json.dumps(result, ensure_ascii=False, indent=2))print()
except Exception as e:print(f"爬取失败: {str(e)}")import tracebacktraceback.print_exc()print("\n爬取和解析任务完成!")提取的结果如下(因为cookie已过期,所以部分数据不可见——pdf_url)
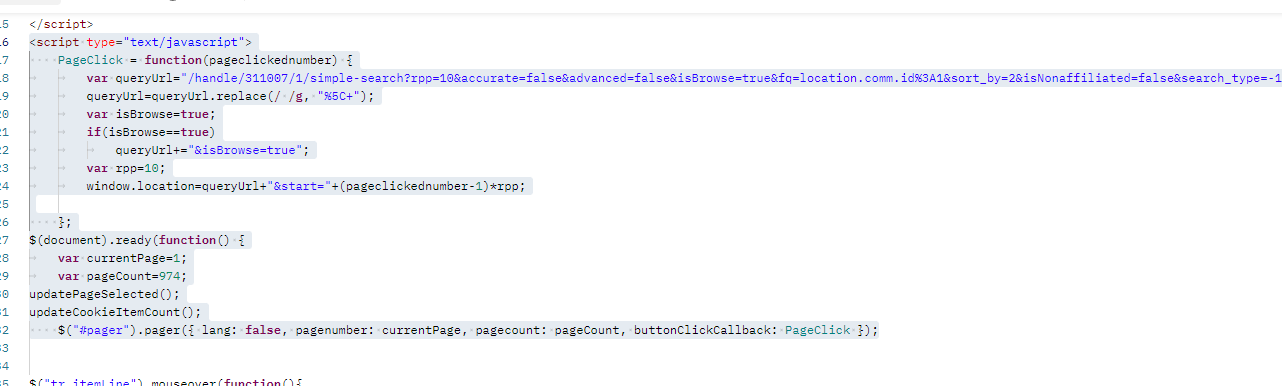
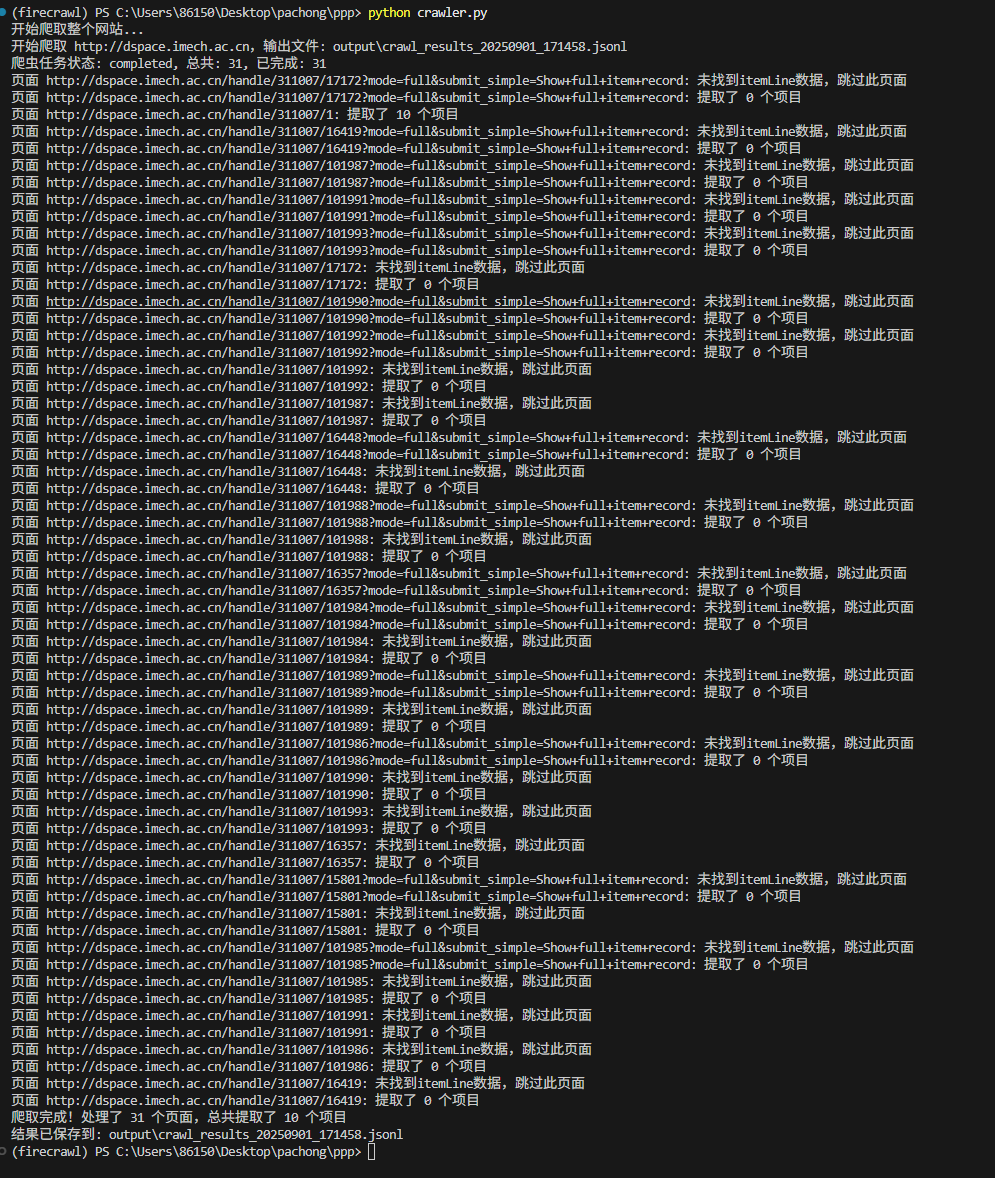
3.4 尝试firecrawl整站爬取
代码如下:
from firecrawl import FirecrawlApp
from bs4 import BeautifulSoup
import json
import jsonlines
import os
from datetime import datetimeLOCAL_FIRECRAWL_API_URL = "http://192.168.199.192:3002"
FIRECRAWL_API_KEY = "qwer1234!@#$"
base_url = "http://dspace.imech.ac.cn"# 初始化Firecrawl客户端
firecrawl = FirecrawlApp(api_url=LOCAL_FIRECRAWL_API_URL, api_key=FIRECRAWL_API_KEY)def extract_data_from_html(html_content, url):"""从HTML内容中提取数据"""try:soup = BeautifulSoup(html_content, 'html.parser')# 查找所有符合条件的tr元素tr_elements = soup.find_all('tr', class_='itemLine')# 如果没有找到itemLine数据,返回空列表if not tr_elements:print(f"页面 {url}: 未找到itemLine数据,跳过此页面")return []results = []for tr in tr_elements:try:# 提取数据item_id = tr.find('input', {'name': 'item'})item_id = item_id['value'] if item_id else "未知"# 提取标题 - 从strong标签获取title_element = tr.find('strong')title = title_element.text.strip() if title_element else "未知"# 提取类型 - 从class为patent的a标签获取type_element = tr.find('a', class_='patent')item_type = type_element.text if type_element else "未知"# 改进的作者提取方法author = "未知"# 方法1: 查找包含"Authors:"文本的spanfor span in tr.find_all('span'):if 'Authors:' in span.text:# 提取所有作者链接文本author_links = span.find_all('a')if author_links:# 提取所有作者文本并用逗号分隔authors = [link.text for link in author_links]author = ", ".join(authors)break# 如果没有找到链接,尝试直接提取文本内容span_text = span.text.replace('Authors:', '').replace(' ', '').strip()if span_text:author = span_textbreak# 方法2: 如果上述方法失败,尝试更通用的方法if author == "未知":# 查找所有span,寻找可能包含作者信息的文本for span in tr.find_all('span'):text = span.text.strip()if ('作者:' in text or 'Authors:' in text) and len(text) < 100: # 限制长度以避免误匹配# 提取作者部分author_text = text.split(':')[-1].replace(' ', '').strip()if author_text:author = author_textbreak# 提取PDF链接 - 从包含"bitstream"的a标签获取pdf_element = tr.find('a', href=lambda x: x and 'bitstream' in x)pdf_url = pdf_element['href'] if pdf_element else "无PDF链接"# 构建完整URL(如果需要)if pdf_url.startswith('/'):pdf_url = base_url + pdf_url# 构建JSON对象item_data = {"url": url,"title": title,"type": item_type,"author": author,"pdf_url": pdf_url,"item_id": item_id,"extracted_at": datetime.now().isoformat()}results.append(item_data)except Exception as e:print(f"处理元素时出错: {str(e)}")continuereturn resultsexcept Exception as e:print(f"解析HTML时出错: {str(e)}")return []def main():try:# First map the site to see what URLs are discoverableprint("开始爬取整个网站...")# 爬虫配置crawl_options = {"include_paths": ["^/handle/311007/1.*"], # 爬取所有以/handle/311007/1开头的页面 "^/handle/311007/1.*""exclude_paths": ["^/admin/.*$", "^/private/.*$"], # 排除管理页面"limit": 99999999999, # 限制爬取页面数量"max_discovery_depth": 10, # 最大发现深度"allow_external_links": False, # 不允许外部链接"allow_subdomains": False, # 不允许子域名"delay": 1, # 延迟1秒"scrape_options": {"formats": ["html"], # 只获取HTML格式"only_main_content": False, # 获取完整页面"headers": {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","Accept-Encoding": "gzip, deflate","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Cache-Control": "max-age=0","Connection": "keep-alive","Cookie": "td_cookie=7929238;JSESSIONID=05A1DC2D4D5A49D84E67521FA94AC507","Host": "dspace.imech.ac.cn","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"},"wait_for": 3000, # 等待时间"timeout": 15000, # 超时时间}}# 创建输出目录output_dir = "output"os.makedirs(output_dir, exist_ok=True)# 生成输出文件名(带时间戳)timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")output_file = os.path.join(output_dir, f"crawl_results_{timestamp}.jsonl")# 开始爬取print(f"开始爬取 {base_url},输出文件: {output_file}")# 启动爬虫任务crawl_job = firecrawl.crawl(base_url, **crawl_options)print(f"爬虫任务状态: {crawl_job.status}, 总共: {crawl_job.total}, 已完成: {crawl_job.completed}")# 处理爬取结果并写入JSONL文件total_items = 0total_pages = 0with jsonlines.open(output_file, mode='w') as writer:for page_data in crawl_job.data:total_pages += 1try:if hasattr(page_data, 'html') and page_data.html:html_content = page_data.htmlpage_url = page_data.metadata.url if hasattr(page_data, 'metadata') and page_data.metadata else "未知URL"extracted_data = extract_data_from_html(html_content, page_url)# 为每个提取的项目写入一行JSONLfor item in extracted_data:writer.write(item)total_items += 1print(f"页面 {page_url}: 提取了 {len(extracted_data)} 个项目")else:print(f"页面 {total_pages}: 没有HTML内容")except Exception as e:print(f"处理页面 {total_pages} 时出错: {str(e)}")continueprint(f"爬取完成!处理了 {total_pages} 个页面,总共提取了 {total_items} 个项目")print(f"结果已保存到: {output_file}")except Exception as e:print(f"爬取失败: {str(e)}")import tracebacktraceback.print_exc()if __name__ == "__main__":main()运行之后发现,没有找到我对应的界面,通过查看源码得出该网站的跳页是使用原始的js后期生成的,所以发现不了对应连接(如果是其他的应该是可以的)