RK3588部署yolov8目标检测
Ultralytics YOLOv8 建立在以前YOLO版本的成功基础上, 引入了新的功能和改进,进一步提高了性能和灵活性。YOLOv8设计快速、准确且易于使用,是目标检测和跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
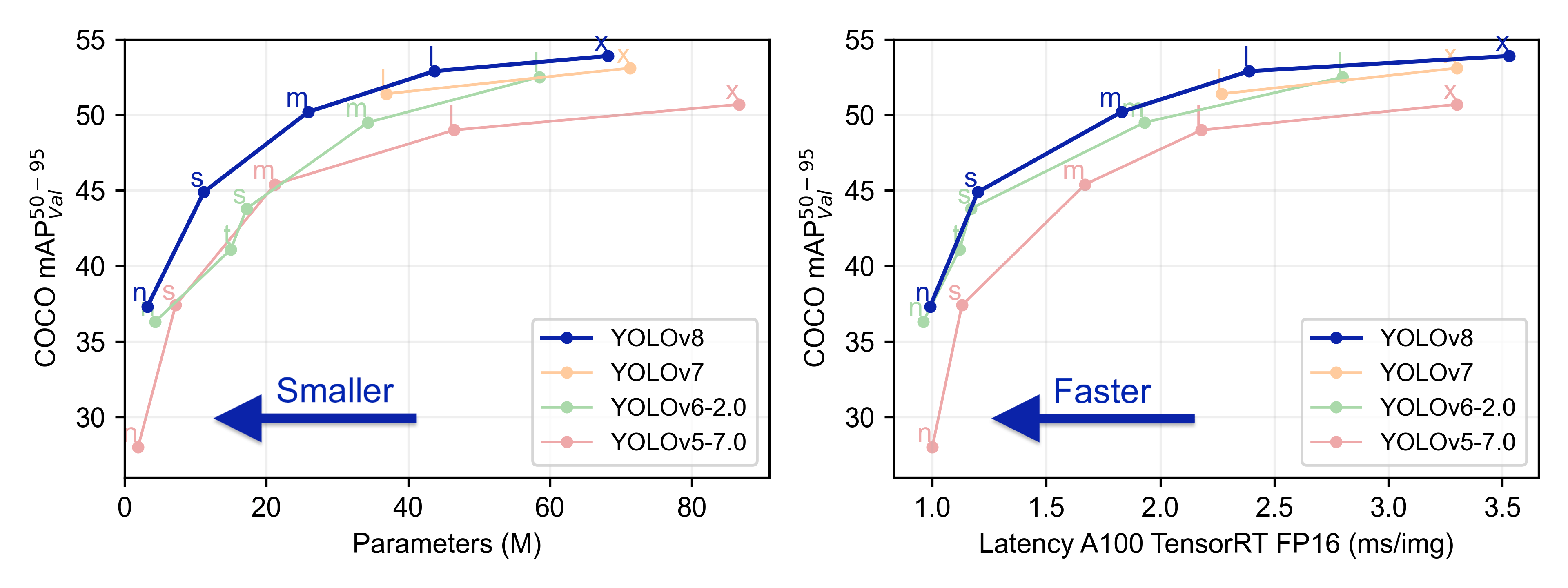
YOLOv8 有5个不同模型大小的预训练模型:n、s、m、l和x。不同大小模型目标检测的准确度:
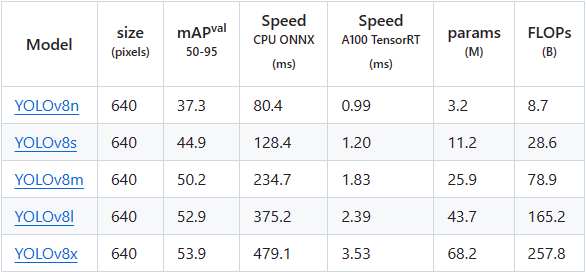
本章将简单测试 YOLOv8 目标检测、 图像分割 以及 姿态估计 模型,并在鲁班猫板卡上部署测试。
提示
测试环境:板卡系统是Debian11,PC是WSL2(ubuntu20.04),rknn-Toolkit2是1.6.0以上版本
1. YOLOv8相关环境安装
在个人PC上使用conda创建虚拟环境,然后安装ultralytics相关环境,主要是为后面使用airockchip/ultralytics_yolov8导出模型创建环境。 也可以直接跳到后面模型导出小结,拉取airockchip/ultralytics_yolov8,然后根据工程文件pyproject.toml中的依赖安装环境。
# 使用conda创建虚拟环境 conda create -n yolov8 python=3.9 conda activate yolov8# 安装YOLOv8,直接使用命令安装 pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple# 或者通过拉取仓库然后安装 git clone https://github.com/ultralytics/ultralytics cd ultralytics pip install -e .# 安装成功后,使用命令yolo简单看下版本 (yolov8) llh@anhao:/$ yolo version 8.2.96
安装之后,就可以直接使用 yolo命令 或者编写 python程序 进行模型训练等等操作。
2. YOLOv8目标检测
2.1. 目标检测简单测试
简单测试下环境,先从官网获取需要的权重文件(也可以不下载,使用yolo命令指定官方预训练权重时会自动下载),然后使用模型进行预测。
# 创建一个目录,然后获取官方仓库的权重(https://github.com/ultralytics/ultralytics/tree/main), # 或者不手动下载,后面使用yolo命令会自动下载。 wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt# 获取测试图片,可以下面位置获取,可能会失败,也可以从配套例程获取 wget https://ultralytics.com/images/bus.jpg
然后使用yolo命令进行测试:
# 第一个参数是指任务[detect, segment, classify], 这里测试目标检测是detect,该参数是可选的; # 第二个参数是模式[train, val, predict, export, track)],是选择进行训练、评估或者推理等等; # 其他参数,model设置模型,source指定要预测的图片路径,imgsz指定图像尺寸等等,更多参数具体参考下:https://docs.ultralytics.com/usage/cfg/# 简单目标检测 (yolov8) llh@anhao: yolo detect predict model=./yolov8n.pt source=./bus.jpg Ultralytics YOLOv8.0.206 🚀 Python-3.8.18 torch-2.1.0+cu121 CUDA:0 (NVIDIA GeForce RTX 3060 Laptop GPU, 6144MiB) YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPsimage 1/1 /yolov8/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 81.8ms Speed: 2.9ms preprocess, 81.8ms inference, 3.3ms postprocess per image at shape (1, 3, 640, 480) Results saved to runs/detect/predict 💡 Learn more at https://docs.ultralytics.com/modes/predict# 预测图片结果保存在当前runs目录下,具体路径是./runs/detect/predict/bus.jpg
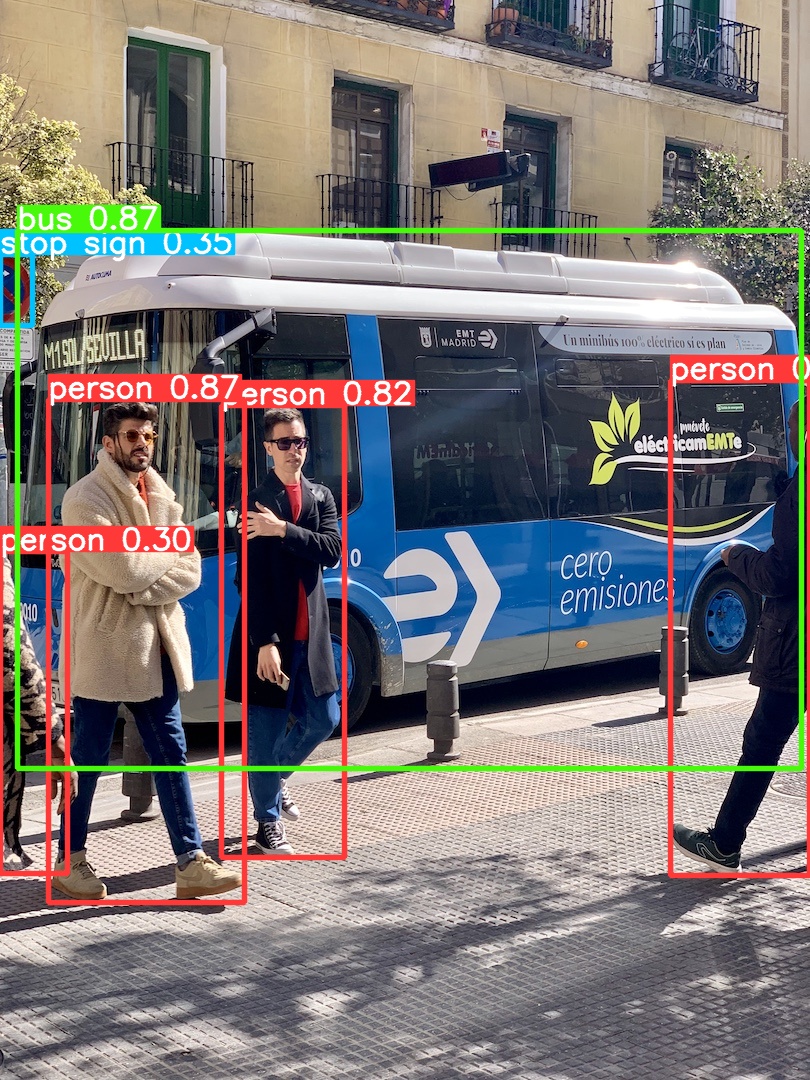
测试结果:
2.2. 模型训练
这里测试coco128,然后训练模型:
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
也可以训练自己的模型。
2.3. 模型导出(airockchip/ultralytics_yolov8)
使用 airockchip/ultralytics_yolov8 可以直接导出适配rknpu的模型,在npu上获得更高的推理效率。 该仓库对模型进行了优化:
-
dfl 结构在NPU处理上性能不佳,移至模型外部。
-
假设有6000个候选框,原模型将 dfl 结构放置于’’框置信度过滤”前,则6000个候选框都需要计算经过dfl计算;而将 dfl 结构放置于’’框置信度过滤”后, 假设过滤后剩100个候选框,则dfl部分计算量减少至100个,大幅减少了计算资源、带宽资源的占用。
假设有6000个候选框,检测类别是 80 类,则阈值检索操作需要重复 6000* 80 ~= 4.8*10^5 次,占据了较多耗时。故导出模型时, 在模型中额外新增了对 80 类检测目标进行求和操作,用于快速过滤置信度。(该结构在部分情况下有效,与模型的训练结果有关) 可以在 ./ultralytics/nn/modules/head.py 52行~54行的位置,注释掉这部分优化,对应的代码是:
cls_sum = torch.clamp(y[-1].sum(1, keepdim=True), 0, 1) y.append(cls_sum)
具体参考下 RKOPT_README.md 。
测试 airockchip/ultralytics_yolov8 模型导出,注意教程测试的是rk_opt_v1分支, 该分支将导出torchscript模型,如果使用main分支默认导出onnx模型,模型转换成rknn时注意修改下加载模型函数。
# 拉取airockchip/ultralytics_yolov8,rk_opt_v1分支 git clone -b rk_opt_v1 https://github.com/airockchip/ultralytics_yolov8.git cd ultralytics_yolov8# 复制训练的模型yolov8n.pt到ultralytics_yolov8目录下 # 然后修改./ultralytics/cfg/default.yaml文件,主要是设置下model,为自己训练的模型路径:model: ./yolov8n.pt # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yamldata: # (str, optional) path to data file, i.e. coco128.yamlepochs: 100 # (int) number of epochs to train for# 导出模型 (yolov8) llh@anhao:~/ultralytics_yolov8$ export PYTHONPATH=./ (yolov8) llh@anhao:~/ultralytics_yolov8$ python ./ultralytics/engine/exporter.py Ultralytics YOLOv8.0.151 🚀 Python-3.8.18 torch-2.1.0+cu121 CPU (12th Gen Intel Core(TM) i5-12500H) YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPsPyTorch: starting from 'yolov8n.pt' with input shape (16, 3, 640, 640) BCHW and output shape(s) ((16, 64, 80, 80), (16, 80, 80, 80), (16, 1, 80, 80), (16, 64, 40, 40), (16, 80, 40, 40), (16, 1, 40, 40), (16, 64, 20, 20), (16, 80, 20, 20), (16, 1, 20, 20)) (6.2 MB)RKNN: starting export with torch 2.1.0+cu121...RKNN: feed yolov8n_rknnopt.torchscript to RKNN-Toolkit or RKNN-Toolkit2 to generate RKNN model. Refer https://github.com/airockchip/rknn_model_zoo/tree/main/models/CV/object_detection/yolo RKNN: export success ✅ 5.0s, saved as 'yolov8n_rknnopt.torchscript' (12.3 MB)Export complete (10.9s) Results saved to /home/llh/ultralytics_yolov8 Predict: yolo predict task=detect model=yolov8n_rknnopt.torchscript imgsz=640 Validate: yolo val task=detect model=yolov8n_rknnopt.torchscript imgsz=640 data=coco.yaml Visualize: https://netron.app
导出的模型,保存在当前目录下的yolov8n_rknnopt.torchscript。
2.4. 模型转换
前面导出的模型,还需要通过toolkit2转换成rknn模型,toolkit2的安装参考下前面环境安装章节。 我们参考 rknn_model_zoo仓库 的例程, 编译下模型转换程序,将torchscript模型(需要注意load_pytorch导入的模型后缀是.pt,模型需要重新命名)转换成rknn模型。
pt2rknn.py(参考配套例程)
123456789 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | if __name__ == '__main__':model_path, platform, do_quant, output_path = parse_arg()# Create RKNN objectrknn = RKNN(verbose=False)# Pre-process configprint('--> Config model')rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform=platform)print('done')# 加载Pytorch模型,如果是使用airockchip/ultralytics_yolov8的main分支,将导入onnx模型print('--> Loading model')#ret = rknn.load_onnx(model=model_path)ret = rknn.load_pytorch(model=model_path, input_size_list=[[1, 3, 640, 640]])if ret != 0:print('Load model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)if ret != 0:print('Build model failed!')exit(ret)print('done')# Export rknn modelprint('--> Export rknn model')ret = rknn.export_rknn(output_path)if ret != 0:print('Export rknn model failed!')exit(ret)print('done')# 精度分析,,输出目录./snapshot#print('--> Accuracy analysis')#ret = rknn.accuracy_analysis(inputs=['./subset/000000052891.jpg'])#if ret != 0:# print('Accuracy analysis failed!')# exit(ret)#print('done')# Releaserknn.release()
|
执行命令,导出rknn模型:
# 执行python3 pt2rknn.py可查看参数解释 (toolkit2_1.6) llh@YH-LONG:/xxx/yolov8$ python3 pt2rknn.py Usage: python3 pt2rknn.py torchscript_model_path [platform] [dtype(optional)] [output_rknn_path(optional)]platform choose from [rk3562,rk3566,rk3568,rk3588]dtype choose from [i8, fp] Example: python pt2rknn.py ./yolov8n.onnx rk3588# 指定模型和目标,转换出rknn模型,默认int8量化 (toolkit2_1.6) llh@YH-LONG:/xxx/yolov8$ python3 pt2rknn.py yolov8n_rknnopt.pt rk3588 W __init__: rknn-toolkit2 version: 1.6.0+81f21f4d --> Config model done --> Loading model W load_onnx: It is recommended onnx opset 19, but your onnx model opset is 12! W load_onnx: Model converted from pytorch, 'opset_version' should be set 19 in torch.onnx.export for successful convert! Loading : 100%|████████████████████████████████████████████████| 136/136 [00:00<00:00, 33780.96it/s] done --> Building model W build: found outlier value, this may affect quantization accuracy const name abs_mean abs_std outlier value model.0.conv.weight 2.44 2.47 -17.494 model.22.cv3.2.1.conv.weight 0.09 0.14 -10.215 model.22.cv3.1.1.conv.weight 0.12 0.19 13.361, 13.317 model.22.cv3.0.1.conv.weight 0.18 0.20 -11.216 GraphPreparing : 100%|██████████████████████████████████████████| 161/161 [00:00<00:00, 5311.08it/s] Quantizating : 100%|██████████████████████████████████████████████| 161/161 [00:05<00:00, 29.91it/s] W build: The default input dtype of 'images' is changed from 'float32' to 'int8' in rknn model for performance!Please take care of this change when deploy rknn model with Runtime API! #....省略.... done --> Export rknn model done
导出rknn模型后,我们使用toolkit2连接板卡,简单测试下模型,或者进行内存、性能评估等等。 可以直接使用 rknn_model_zoo仓库 提供的例程,我们这里参考例程编写下:
test.py(参考配套例程)
123456789 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | if __name__ == '__main__':rknn = RKNN()rknn.list_devices()# 加载rknn模型rknn.load_rknn(path=rknn_model_path)# 设置运行环境,目标默认是rk3588ret = rknn.init_runtime(target=target, device_id=device_id)# 输入图像img_src = cv2.imread(img_path)src_shape = img_src.shape[:2]img, ratio, (dw, dh) = letter_box(img_src, IMG_SIZE)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)#img = cv2.resize(img_src, IMG_SIZE)# 推理运行print('--> Running model')outputs = rknn.inference(inputs=[img])print('done')# 后处理boxes, classes, scores = post_process(outputs)img_p = img_src.copy()if boxes is not None:draw(img_p, get_real_box(src_shape, boxes, dw, dh, ratio), scores, classes)cv2.imwrite("result.jpg", img_p)
|
执行命令前,确认PC通过usb或者网线连接,确认adb设备连接,在板卡上执行rknn_server或者restart_rknn.sh命令,开启rknn_server。 然后在PC ubutnu中执行命令(教程测试的板卡是lubancat-4):
(toolkit2_1.6) llh@YH-LONG:/xxx/yolov8$ python test.py W __init__: rknn-toolkit2 version: 1.6.0+81f21f4d ************************* all device(s) with adb mode: 192.168.103.157:5555 ************************* I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:36) D RKNNAPI: ============================================== D RKNNAPI: RKNN VERSION: D RKNNAPI: API: 1.6.0 (535b468 build@2023-12-11T09:05:46) D RKNNAPI: DRV: rknn_server: 1.5.0 (17e11b1 build: 2023-05-18 21:43:39) D RKNNAPI: DRV: rknnrt: 1.6.0 (9a7b5d24c@2023-12-13T17:31:11) D RKNNAPI: ============================================== D RKNNAPI: Input tensors: D RKNNAPI: index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, w_stride = 0, size_with_stride = 0, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922 D RKNNAPI: Output tensors: D RKNNAPI: index=0, name=318, n_dims=4, dims=[1, 64, 80, 80], n_elems=409600, size=409600, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-58, scale=0.117659 D RKNNAPI: index=1, name=onnx::ReduceSum_326, n_dims=4, dims=[1, 80, 80, 80], n_elems=512000, size=512000, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003104 D RKNNAPI: index=2, name=331, n_dims=4, dims=[1, 1, 80, 80], n_elems=6400, size=6400, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003173 D RKNNAPI: index=3, name=338, n_dims=4, dims=[1, 64, 40, 40], n_elems=102400, size=102400, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-45, scale=0.093747 D RKNNAPI: index=4, name=onnx::ReduceSum_346, n_dims=4, dims=[1, 80, 40, 40], n_elems=128000, size=128000, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003594 D RKNNAPI: index=5, name=350, n_dims=4, dims=[1, 1, 40, 40], n_elems=1600, size=1600, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003627 D RKNNAPI: index=6, name=357, n_dims=4, dims=[1, 64, 20, 20], n_elems=25600, size=25600, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-34, scale=0.083036 D RKNNAPI: index=7, name=onnx::ReduceSum_365, n_dims=4, dims=[1, 80, 20, 20], n_elems=32000, size=32000, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003874 D RKNNAPI: index=8, name=369, n_dims=4, dims=[1, 1, 20, 20], n_elems=400, size=400, w_stride = 0, size_with_stride = 0, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922 --> Running model W inference: The 'data_format' is not set, and its default value is 'nhwc'! done person @ (211 241 282 506) 0.864 person @ (109 235 225 535) 0.860 person @ (477 226 560 522) 0.848 person @ (79 327 116 513) 0.306 bus @ (96 136 549 449) 0.864
最后结果保存在当前目录下result.jpg。
更多的测试参考下 rknn_model_zoo仓库 。
2.5. 板卡上部署推理
重要
如果部署自己训练的模型,按前面的方式转换成rknn模型,在部署时请注意类别的数量,请修改例程中的coco_80_labels_list.txt 文件和宏OBJ_CLASS_NUM等等
部署例程参考 rknn_model_zoo仓库 进行了相应修改, 板卡上获取例程和安装环境:
# 鲁班猫板卡系统默认是debian或者ubuntu发行版,直接使用apt安装opencv,或者自行编译安装opencv sudo apt update sudo apt install libopencv-dev# 获取配套例程(该例程目前只支持linux平台,rk356x,rk3576,rk3588) cat@lubancat:~/$ git clone https://gitee.com/LubanCat/lubancat_ai_manual_code.git# 或者拉取rknn_model_zoo仓库源码,编译使用请参考工程的README文件 # cat@lubancat:~/$ git clone https://github.com/airockchip/rknn_model_zoo.git
切换到编译yolov8_det例程,设置参数-t指定rk3588(教程测试lubancat-4)。
cat@lubancat:~/$ cd lubancat_ai_manual_code/example/yolov8/yolov8_det/cppcat@lubancat:~/lubancat_ai_manual_code/example/yolov8/yolov8_det/cpp$ ./build-linux.sh -t rk3588 =================================== TARGET_SOC=rk3588 INSTALL_DIR=/home/cat/lubancat_ai_manual_code/example/yolov8/yolov8_det/cpp/install/rk3588_linux BUILD_DIR=/home/cat/lubancat_ai_manual_code/example/yolov8/yolov8_det/cpp/build/build_rk3588_linux CC=aarch64-linux-gnu-gcc CXX=aarch64-linux-gnu-g++ =================================== -- The C compiler identification is GNU 10.2.1 -- The CXX compiler identification is GNU 10.2.1 #...省略... [100%] Linking CXX executable rknn_yolov8_demo [100%] Built target rknn_yolov8_demo [100%] Built target rknn_yolov8_demo Install the project... -- Install configuration: "" #...省略...
切换到install/rk3588_linux下,然后执行程序:
# ./rknn_yolov8_demo <model_path> <image_path> cat@lubancat:~/xxx/install/rk3588_linux$ ./rknn_yolov8_demo ./model/yolov8_rk3588.rknn ./model/bus.jpg load lable ./model/coco_80_labels_list.txt model input num: 1, output num: 9 input tensors: index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922 output tensors: index=0, name=318, n_dims=4, dims=[1, 64, 80, 80], n_elems=409600, size=409600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-58, scale=0.117659 index=1, name=onnx::ReduceSum_326, n_dims=4, dims=[1, 80, 80, 80], n_elems=512000, size=512000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003104 index=2, name=331, n_dims=4, dims=[1, 1, 80, 80], n_elems=6400, size=6400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003173 index=3, name=338, n_dims=4, dims=[1, 64, 40, 40], n_elems=102400, size=102400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-45, scale=0.093747 index=4, name=onnx::ReduceSum_346, n_dims=4, dims=[1, 80, 40, 40], n_elems=128000, size=128000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003594 index=5, name=350, n_dims=4, dims=[1, 1, 40, 40], n_elems=1600, size=1600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003627 index=6, name=357, n_dims=4, dims=[1, 64, 20, 20], n_elems=25600, size=25600, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-34, scale=0.083036 index=7, name=onnx::ReduceSum_365, n_dims=4, dims=[1, 80, 20, 20], n_elems=32000, size=32000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003874 index=8, name=369, n_dims=4, dims=[1, 1, 20, 20], n_elems=400, size=400, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922 model is NHWC input fmt model input height=640, width=640, channel=3 scale=1.000000 dst_box=(0 0 639 639) allow_slight_change=1 _left_offset=0 _top_offset=0 padding_w=0 padding_h=0 src width=640 height=640 fmt=0x1 virAddr=0x0x55762912c0 fd=0 dst width=640 height=640 fmt=0x1 virAddr=0x0x55763bd2f0 fd=0 src_box=(0 0 639 639) dst_box=(0 0 639 639) color=0x72 rga_api version 1.10.0_[2] rknn_run person @ (211 241 282 506) 0.864 bus @ (96 136 549 449) 0.864 person @ (109 235 225 535) 0.860 person @ (477 226 560 522) 0.848 person @ (79 327 116 513) 0.306 once rknn run and process use 20.539000 ms
结果保存在当前目录下的/out.jpg,结果显示:

如果上面程序运行提示RGA相关问题,请参考下 Rockchip_FAQ_RGA_CN.md 。