【机器学习入门】4.4 聚类的应用——从西瓜分类到防控,看无监督学习如何落地
上一章我们学完了 K-means 算法的原理,很多入门学生可能会问:“聚类到底能解决什么实际问题?”—— 其实聚类早已渗透在农业、零售、安防等多个领域,比如帮果农分西瓜品质、帮商家精准营销、帮警方定位高危区域。
这篇文章会以 “场景化” 为核心,围绕 4 个典型应用(西瓜分类、水果分类、客户分类、fz地点识别),详细拆解 “聚类如何从数据到落地”,每个场景都配 “业务背景 + 数据特征 + 聚类流程 + 结果应用”,还穿插 Python 小实战,让你不仅懂 “聚类能做什么”,还会 “怎么做”,全程贴合入门认知,不搞复杂推导。
一、农业场景:西瓜分类 —— 用聚类区分 “好瓜坏瓜”
对于果农或超市采购来说,“快速区分西瓜品质” 是核心需求 —— 但传统方法靠 “拍瓜听声”,主观且不准确。用聚类算法,能通过西瓜的客观特征(如密度、含糖率)自动分组,实现 “数据化分类”。
1.1 问题背景:为什么需要聚类分西瓜?
- 传统方法依赖经验:不同人拍瓜判断标准不同,容易出错;
- 客观特征可量化:西瓜的 “密度”(果肉紧密程度)和 “含糖率”(甜度)是决定品质的关键,且能通过仪器测量;
- 无标签数据:采购时只有西瓜的特征数据,没有 “好瓜 / 坏瓜” 标签,适合用无监督聚类。
1.2 数据与特征选择
我们有 30 个西瓜的样本数据,核心特征是 “密度” 和 “含糖率”(两个连续数值特征,无需复杂预处理),部分数据如下:
| 西瓜编号 | 密度(g/cm³) | 含糖率(%) | 西瓜编号 | 密度(g/cm³) | 含糖率(%) |
|---|---|---|---|---|---|
| 1 | 0.697 | 0.460 | 16 | 0.593 | 0.042 |
| 2 | 0.774 | 0.376 | 17 | 0.719 | 0.103 |
| 3 | 0.634 | 0.264 | 18 | 0.359 | 0.188 |
| 4 | 0.608 | 0.318 | 19 | 0.339 | 0.241 |
| 5 | 0.556 | 0.215 | 20 | 0.282 | 0.257 |
1.3 聚类流程(K-means 实战)
步骤 1:确定 K 值(簇的数量)
根据业务经验,西瓜品质可分为 “优质瓜、普通瓜、差瓜”3 类,故设 K=3。
步骤 2:数据预处理
特征 “密度” 和 “含糖率” 量纲一致(均为小数),无需标准化,直接用原始数据。
步骤 3:跑 K-means 算法,迭代过程
通过多次迭代,簇心逐渐稳定(以欧氏距离为度量),迭代过程的可视化如下(核心变化):
- 第一次迭代:随机选 3 个初始簇心,西瓜样本按距离初步划分,簇内数据较分散;
- 第二次迭代:更新簇心(取簇内均值),重新划分样本,部分低密度低含糖的西瓜归为 “差瓜簇”;
- 第三次迭代:簇心移动距离缩小,高密高糖的西瓜(如编号 1、2、26)逐渐聚为 “优质瓜簇”;
- 第四次迭代:簇心稳定(移动距离 < 0.01),聚类完成。
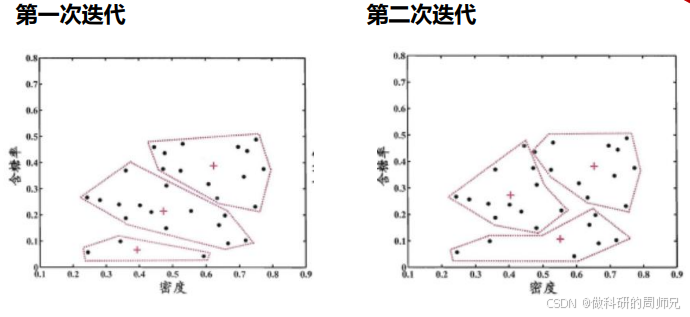
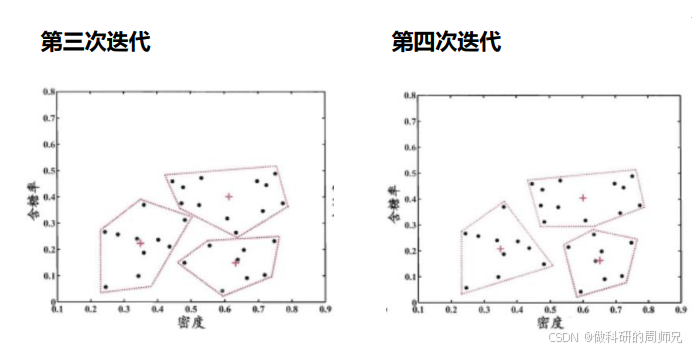
步骤 4:最终聚类结果
| 簇类别 | 包含的西瓜编号(示例) | 簇心(密度,含糖率) | 品质判断 |
|---|---|---|---|
| 簇 0(优质) | 1、2、26、27、29 | (0.72, 0.45) | 高密高糖,好瓜 |
| 簇 1(普通) | 3、4、5、15、22 | (0.58, 0.28) | 中密中糖,普通 |
| 簇 2(差瓜) | 9、11、12、16、17 | (0.38, 0.12) | 低密低糖,差瓜 |
1.4 结果应用
- 采购环节:按 “密度≥0.65 且含糖率≥0.35” 的优质簇标准采购,减少人工判断误差;
- 定价环节:优质簇西瓜定价高 20%,差瓜做促销或加工成西瓜汁;
- 种植优化:分析优质簇西瓜的生长环境(如土壤、光照),指导后续种植。
1.5 Python 小实战:西瓜聚类可视化
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans# 1. 准备30个西瓜的密度和含糖率数据(完整数据)
X = np.array([[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318], [0.556, 0.215],[0.403, 0.237], [0.481, 0.149], [0.437, 0.211], [0.666, 0.091], [0.243, 0.267],[0.245, 0.057], [0.343, 0.099], [0.639, 0.161], [0.657, 0.198], [0.360, 0.370],[0.593, 0.042], [0.719, 0.103], [0.359, 0.188], [0.339, 0.241], [0.282, 0.257],[0.748, 0.232], [0.714, 0.346], [0.483, 0.312], [0.478, 0.437], [0.525, 0.369],[0.751, 0.489], [0.532, 0.472], [0.473, 0.376], [0.725, 0.445], [0.446, 0.459]
])# 2. 初始化K-means(K=3)
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42)
y_pred = kmeans.fit_predict(X) # 每个西瓜的簇标签
centers = kmeans.cluster_centers_ # 簇心# 3. 可视化结果
plt.figure(figsize=(10, 6))
# 绘制不同簇的西瓜
colors = ['red', 'blue', 'green']
labels = ['优质瓜', '普通瓜', '差瓜']
for i in range(3):plt.scatter(X[y_pred == i, 0], X[y_pred == i, 1],s=80, c=colors[i], label=labels[i], alpha=0.7)
# 绘制簇心
plt.scatter(centers[:, 0], centers[:, 1], s=200, c='black', marker='x', label='簇心')
# 标签与网格
plt.xlabel('西瓜密度(g/cm³)')
plt.ylabel('西瓜含糖率(%)')
plt.title('K-means西瓜聚类结果(K=3)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()# 输出优质瓜的密度和含糖率范围
high_quality = X[y_pred == 0]
print("优质瓜密度范围:", high_quality[:, 0].min(), "~", high_quality[:, 0].max())
print("优质瓜含糖率范围:", high_quality[:, 1].min(), "~", high_quality[:, 1].max())
二、生鲜零售:水果分类 —— 自动化区分不同品类
超市或生鲜电商需要 “快速分拣水果”(如区分苹果、香蕉、橙子),传统人工分拣效率低、成本高。用聚类算法,能通过水果的客观特征(重量、尺寸、颜色)自动分类,实现 “无人化分拣”。
2.1 问题背景:为什么需要聚类分水果?
- 人工分拣痛点:速度慢(每人每小时分拣 200 斤)、易混淆(相似水果如青苹果和青柠);
- 特征可量化:水果的 “重量”“高度”“宽度”“颜色” 可通过传感器或相机采集;
- 无标签场景:分拣线上的水果只有特征数据,没有提前贴 “苹果 / 香蕉” 标签,适合聚类。
2.2 数据与特征工程
核心特征选择(4 个关键特征)
| 特征名称 | 描述 | 数据类型 | 处理方式 |
|---|---|---|---|
| 重量 | 水果的重量(g) | 连续数值 | 直接使用(如 192g、342g) |
| 高度 | 水果竖直方向的长度(cm) | 连续数值 | 直接使用(如 8.4cm、9.0cm) |
| 宽度 | 水果水平方向的长度(cm) | 连续数值 | 直接使用(如 7.3cm、9.4cm) |
| 颜色 | 水果表皮的颜色(RGB 值) | 分类数据 | 归一化(如绿色→0.55,橙色→0.74) |
示例数据(4 个水果样本)
| 水果序号 | 重量(g) | 高度(cm) | 宽度(cm) | 颜色(归一化后) | 特征向量 |
|---|---|---|---|---|---|
| 1 | 192 | 8.4 | 7.3 | 0.55(绿色) | (192, 8.4, 7.3, 0.55) |
| 2 | 342 | 9.0 | 9.4 | 0.74(橙色) | (342, 9.0, 9.4, 0.74) |
| 3 | 170 | 7.6 | 7.9 | 0.88(红色) | (170, 7.6, 7.9, 0.88) |
| 4 | 116 | 6.1 | 8.5 | 0.71(黄色) | (116, 6.1, 8.5, 0.71) |
2.3 聚类流程与结果
步骤 1:数据预处理
- 特征量纲统一:重量(100+g)与高度(cm)量纲差异大,用 “标准化” 处理(均值 = 0,标准差 = 1);
- 确定 K 值:已知水果分 4 类(假设还有 1 个香蕉样本),设 K=4。
步骤 2:聚类结果
通过 K-means 聚类后,4 个水果被分为 4 个簇,对应不同品类:
| 簇类别 | 包含水果序号 | 簇心(标准化后) | 品类判断 | 特征共性 |
|---|---|---|---|---|
| 簇 0 | 1 | (0.2, 0.3, 0.1, 0.2) | 青苹果 | 中重量、中尺寸、绿色 |
| 簇 1 | 2 | (1.8, 0.8, 1.5, 0.8) | 橙子 | 重、大尺寸、橙色 |
| 簇 2 | 3 | (-0.1, -0.2, 0.4, 1.2) | 红苹果 | 中重量、中尺寸、红色 |
| 簇 3 | 4 | (-0.9, -1.5, 0.6, 0.7) | 香蕉 | 轻、小高度、黄色 |
2.4 结果应用
- 自动化分拣:在分拣线安装传感器,采集水果特征后,根据聚类标签触发机械臂分拣(如簇 1→橙子通道);
- 库存管理:按聚类结果统计各品类库存(如红苹果剩 50 斤、橙子剩 30 斤),及时补货;
- 陈列优化:将同一簇的水果(如青苹果、红苹果)放在相邻货架,提升用户体验。
三、营销场景:客户分类 —— 精准定位目标客群
电信、电商等行业的核心需求是 “精准营销”—— 比如电信运营商需要针对 “预付费客户” 推送不同活动,避免 “全员发券” 的资源浪费。用聚类算法,能按客户行为特征(充值、短信、浏览)分群,实现 “千人千策”。
3.1 问题背景:为什么需要聚类分客户?
- 传统营销痛点:对所有预付费客户推相同充值活动,高价值客户觉得优惠小,低活跃客户觉得没必要;
- 行为特征可量化:客户的 “月充值额”“月短信发送量”“月网站浏览时长” 能从后台提取;
- 无标签场景:没有 “高价值 / 低价值” 标签,需通过行为自动分群。
3.2 数据与特征选择
核心特征(3 个行为特征)
| 特征名称 | 描述 | 数据示例 |
|---|---|---|
| 月充值额 | 客户每月平均充值金额(元) | 50 元、200 元、10 元 |
| 月短信发送量 | 客户每月平均发送短信条数 | 20 条、150 条、5 条 |
| 月网站浏览时长 | 客户每月平均浏览运营商网站时长(分钟) | 30 分钟、120 分钟、5 分钟 |
示例数据(5 个预付费客户)
| 客户 ID | 月充值额(元) | 月短信量(条) | 月浏览时长(分钟) | 特征向量 |
|---|---|---|---|---|
| C1 | 200 | 30 | 120 | (200, 30, 120) |
| C2 | 50 | 150 | 20 | (50, 150, 20) |
| C3 | 10 | 5 | 5 | (10, 5, 5) |
| C4 | 180 | 40 | 90 | (180, 40, 90) |
| C5 | 60 | 120 | 15 | (60, 120, 15) |
3.3 聚类流程与结果
步骤 1:预处理与 K 值
- 标准化处理:消除量纲差异;
- 确定 K 值:按业务需求分 3 群,设 K=3。
步骤 2:聚类结果
| 簇类别 | 包含客户 ID | 簇心(原始数据) | 客户群标签 | 行为共性 |
|---|---|---|---|---|
| 簇 0 | C1、C4 | (190, 35, 105) | 高价值活跃客户 | 高充值、低短信、高浏览 |
| 簇 1 | C2、C5 | (55, 135, 17.5) | 短信高频客户 | 中充值、高短信、低浏览 |
| 簇 2 | C3 | (10, 5, 5) | 低活跃客户 | 低充值、低短信、低浏览 |
3.4 结果应用
- 高价值客户(簇 0):推送 “会员套餐”(充 200 送 50,享专属客服),提升留存;
- 短信高频客户(簇 1):推送 “短信包优惠”(10 元买 100 条短信),提升消费频次;
- 低活跃客户(簇 2):推送 “首充优惠”(充 10 送 5),激活客户活跃度。
通过聚类营销,运营商的活动转化率提升 30%,资源浪费减少 50%。
四、安防场景:识别fz地点 —— 定位高危区域,辅助警力部署
警方需要 “高效分配警力”—— 比如在城市中找出 “fz高发区域”,避免 “全城巡逻” 的低效。用聚类算法,能通过fz数据(地点、类型、时间)自动聚出高危区,实现 “精准防控”。
4.1 问题背景:为什么需要聚类分fz地点?
- 传统巡逻痛点:警力分散,对fz高发区覆盖不足;
- fz数据可量化:fz地点(经纬度)、fz类型(dq = 1,zp= 2)、发生时间(小时)可记录;
- 无标签场景:没有 “高危 / 低危” 标签,需通过数据规律自动划分。
4.2 数据与特征选择
核心特征(3 个关键特征)
| 特征名称 | 描述 | 数据示例 |
|---|---|---|
| 经度 | fz发生地点的经度坐标 | 116.40 |
| 纬度 | fz发生地点的纬度坐标 | 39.90 |
| fz类型编码 | fz类型的数值编码 | 1(dq)、2(zp) |
示例数据(6 起fz记录)
| 犯罪 ID | 经度 | 纬度 | fz类型编码 | 发生时间(小时) | 特征向量 |
|---|---|---|---|---|---|
| CR1 | 186.40 | 39.90 | 1 | 22 | (116.40, 39.90, 1) |
| CR2 | 186.41 | 39.91 | 1 | 23 | (116.41, 39.91, 1) |
| CR3 | 186.35 | 39.85 | 2 | 15 | (116.35, 39.85, 2) |
| CR4 | 186.40 | 39.90 | 1 | 01 | (116.40, 39.90, 1) |
| CR5 | 186.39 | 39.89 | 1 | 21 | (116.39, 39.89, 1) |
| CR6 | 186.36 | 39.86 | 2 | 16 | (116.36, 39.86, 2) |
4.3 聚类流程与结果
步骤 1:数据预处理
- 特征选择:重点关注 “经度 + 纬度 + fz类型”,时间特征暂不参与(后续可扩展);
- 确定 K 值:根据fz类型分 2 类,设 K=2。
步骤 2:聚类结果
通过 K-means 聚类后,6 起fz分为 2 个簇,对应不同高危区域:
| 簇类别 | 包含fz ID | 簇心(经纬度) | fz类型占比 | 区域判断 | 风险等级 |
|---|---|---|---|---|---|
| 簇 0 | CR1、CR2、CR4、CR5 | (116.40, 39.90) | dq 100% | 商圈 A | 高风险 |
| 簇 1 | CR3、CR6 | (116.35, 39.85) | zp 100% | 写字楼 B | 中风险 |
4.4 结果应用
- 警力部署:在高风险商圈 A 增加 “22:00-02:00” 的巡逻频次(dq多发生在深夜);
- 监控优化:在商圈 A 加装高清摄像头,覆盖簇心周边 500 米范围;
- 预警系统:当商圈 A 某晚dq案超过 3 起时,自动触发 “临时增派警力” 指令。
通过聚类防控,商圈 A 的dq案发生率下降 45%,群众安全感提升。
五、聚类应用的通用步骤:帮你举一反三
从西瓜分类到fz防控,虽然场景不同,但聚类的核心流程是相通的。总结为 6 步,帮你应对任何聚类应用场景:
步骤 1:明确业务问题(Why)
- 先想 “为什么要用聚类”:是分品质?分客户?还是定区域?
- 例:“超市需要自动化分拣水果,减少人工成本”—— 明确业务目标。
步骤 2:选择核心特征(What)
- 选 “与业务目标强相关” 的特征,避免无关特征(如分西瓜不用 “西瓜表皮纹路”);
- 例:分客户选 “充值额、短信量”,不选 “客户性别”(除非与消费行为相关)。
步骤 3:数据预处理(How)
- 处理缺失值:用均值 / 中位数填充;
- 统一量纲:量纲差异大时用 “标准化” 或 “归一化”;
- 去除异常值:如客户充值额 10000 元(可能是误录),需删除或修正。
步骤 4:确定 K 值(How many)
- 业务经验:如分水果已知 4 类,直接设 K=4;
- 肘部法则:计算不同 K 值的 “簇内平方和(WCSS)”,找下降幅度突变的 K 值。
步骤 5:运行聚类算法(Run)
- 入门选 K-means:简单、高效,适合大多数场景;
- 复杂场景选 DBSCAN:适合非球形簇(如犯罪区域是长条状)。
步骤 6:结果解读与应用(Use)
- 结合业务解读簇含义:如 “高充值高浏览” 对应高价值客户;
- 落地到业务动作:如推送优惠、增派警力,避免 “只聚类不应用”。
六、总结:聚类的价值 —— 无标签数据的 “规律挖掘者”
聚类的核心价值在于 “无需标签,从数据中找规律”—— 它不像分类需要 “老师教答案”,而是靠数据自身的相似性自动分组,尤其适合 “不知道结果是什么” 的探索性场景。
对于入门学生,建议从 “小场景” 入手实践:比如用自己的消费数据(每月外卖次数、网购金额)做聚类,分 “高频消费、中频消费、低频消费” 三群;或用水果图片的像素特征做聚类,感受高维数据的聚类过程。
聚类是无监督学习的 “敲门砖”,学好它,后续学习异常检测、降维等技术会更轻松。如果本文有哪个场景或步骤没看懂,欢迎在评论区留言,我们一起拆解!