cosy-3

DEMO : https://funaudiollm.github.io/cosyvoice3。
概述
CosyVoice 2 的局限性:
- 语言覆盖范围有限
- 领域多样性不足
- 训练数据量不足
- 文本格式支持有限
- 后训练技术不足
CosyVoice 3 的主要改进和特点:
- 新型语音标记器: 通过监督多任务训练(包括自动语音识别、语音情感识别、语言识别、音频事件检测和说话人分析),提高韵律自然度。
- 可微分奖励优化 (DiffRO): 一种新的强化学习方法,适用于 CosyVoice 3 及其他基于离散语音标记的语音合成模型的后训练。
- 数据集规模扩展: 训练数据从一万小时扩展到一百万小时,涵盖 9 种语言和 18 种中文方言,以及各种领域和文本格式。
- 模型规模扩展: 模型参数从 0.5B 增加到 1.5B,在多语言基准测试中表现更优。
- 提出了一种新的测试集
speech tokenizer
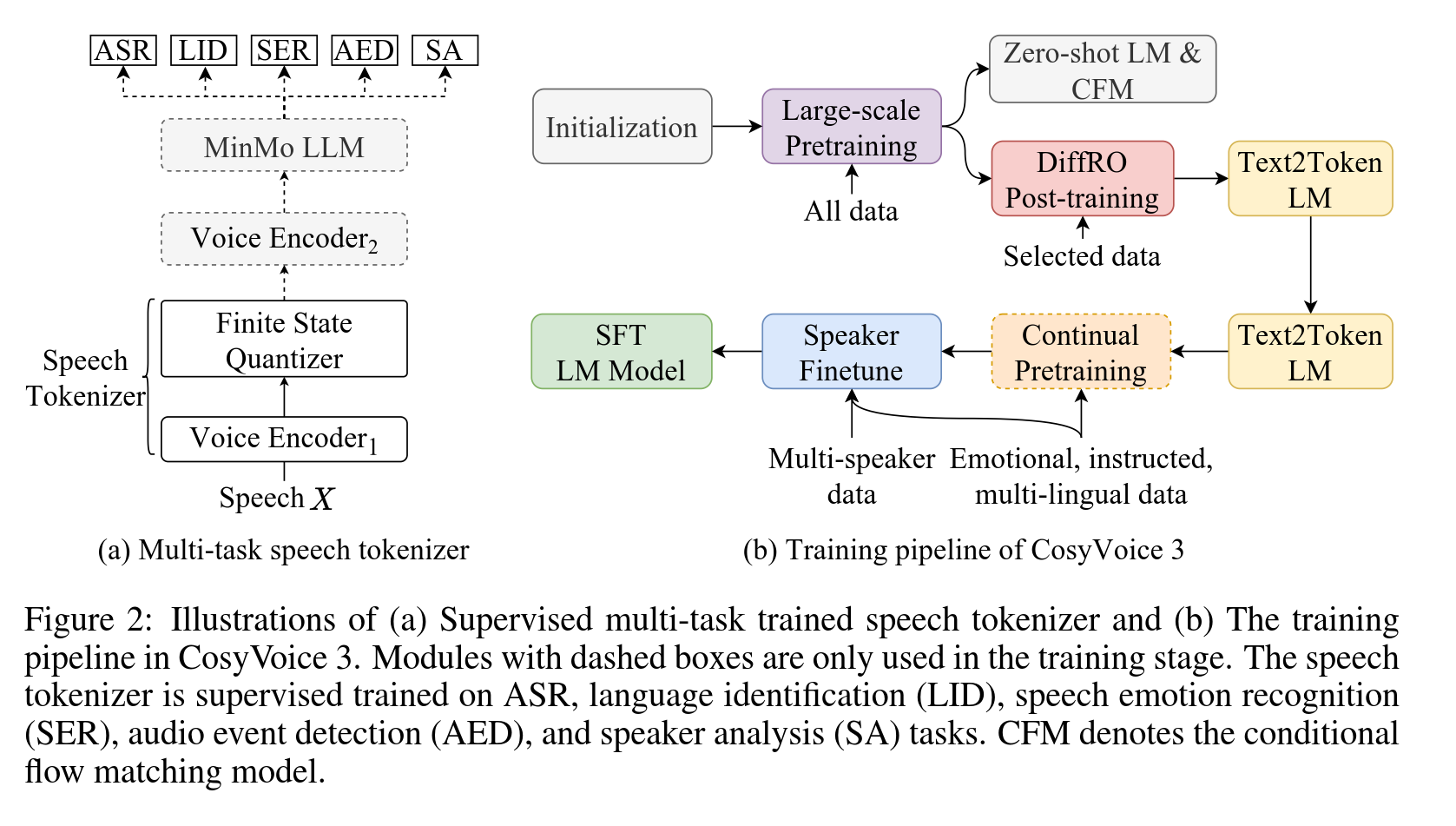
基于 MinMo 模型, 使用带监督的多任务训练, 训练时使用 MinMo 模型的部分训练数据进行监督多任务学习,包括 ASR, LID(语种识别), SER(情感识别), AED(音频事件检测), SA(说话人分析), FSQ.
其中 Voice Encoder1 是12层Transformer(with RoPE)。
语音标记器的工作原理:
- 语音编码:输入语音经过 Voice Encoder1 进行编码,生成中间表示 H。
- 量化:中间表示 H 被投影到一个低秩空间,并使用 FSQ 模块进行量化,生成量化后的表示 ¯H。
- 重建:量化后的表示 ¯H 被投影回原始维度,生成重建后的表示 ˜H。
- 文本标记预测:重建后的表示 ˜H 经过 MinMo 模型的其他模块,预测对应文本标记的后验概率。
- 语音标记生成:根据量化后的表示 ¯hi 计算索引,生成语音标记 µi。
DiffRO
TTS 系统需要额外的下游条件流匹配 (CFM) 和声码器模型来将离散的语音标记转换为音频波形。这些下游模型的计算需求很大。更重要的是,在下游处理后,生成的语音始终表现出高度相似性,因此很难区分积极和消极的反馈以训练奖励模型。
为了解决这些问题,我们引入了可微分奖励优化 (DiffRO) 方法,直接优化语音标记而不是合成音频: 直接优化语音标记,使其与 ASR 偏好对齐,并通过最大化奖励分数来提高语音生成的质量和准确性。DiffRO 首先在 ASR 训练数据上训练一个类似 ASR 的 Token2Text 模型,然后使用后验概率作为奖励。为了进一步简化训练策略,DiffRO 使用 Gumbel-Softmax 操作。
DiffRO 与其他 RL 方法的主要区别在于,它直接优化输出标记级别的 logits,而不是序列级别的后验概率。这种方法简化了训练过程,并提高了训练效率。
除了 Token2Text 模型外,DiffRO 还使用其他下游任务(如 SER、MOS 分数预测、AED 等)进行多任务奖励 (MTR) 建模。

发音前端
为了修正发音,是的发音在多音字等场景下更准确,在训练数据集中额外添加了一种混合表示的数据集,吧中文字符替换成对应的拼音,英文单词替换成对应的CMU音标,同时扩展了文本tokenizer的词表。
注意,中文只替换单音节字符,英文只替换单音节词语。扩充的数据追加到训练数据集。
为了模型在数字等场景下更准确的发音,在训练数据集中,做了文本正则化&反正则化的数据对。扩充的数据追加到训练数据集。
通过三种方式构建辅助训练集:
- 使用内部基于规则的 TN 模块,获得文本归一化的文本,并使用 CosyVoice 2 合成音频。
- Qwen-Max [38] 进行文本归一化,然后使用 CosyVoice 2 在归一化文本上合成音频。
- Qwen-Max 对现有文本-音频对中的文本进行反向文本归一化,获得原始文本(即未归一化的文本)。
数据处理流程
这段文字描述了一种在稀缺语言中收集和处理大规模、高质量文本到语音(TTS)数据的方法。该过程包括从各种在线来源收集多语言音频,然后通过一个六步流程对其进行提炼:
- 语音检测与分割:使用说话人分离和语音活动检测等技术处理音频,以识别和分离按说话人划分的语音片段。目标是获得短片段(30秒以下)。
- 降噪:使用名为MossFormer2的模型来减少音频中的噪音。此外,还会移除开头或结尾不完整的单词片段。
- ASR 转录:为了获得准确的文本转录,首先使用Faster-Whisper Large-V3对音频进行语言识别。然后,多个开源ASR模型对音频进行转录。选择那些一致性好的转录(不同系统ASR结果的平均成对词错率低于15%)。
- 标点调整:由于ASR生成的文本可能无法准确反映音频中的停顿,因此使用蒙特利尔强制对齐器(Montreal Forced Aligner)来分析音频,并根据单词和短语之间的持续时间调整标点。停顿300毫秒或更多时添加逗号,而停顿50毫秒或更少时则删除表示停顿的某些标点符号(即逗号、分号、冒号、句号、问号和感叹号)。
- 音量标准化:将所有音频片段的音量调整到一致的水平,以确保训练数据的音量一致性。
- 过滤异常数据:移除那些音频和文本转录明显不匹配的数据,例如转录文本中包含非目标语言的片段。
- 在完成上述所有处理步骤后,为每一对生成的语音-文本对提取语音标记和文本标记。然后,计算并排序每个语音-文本对中语音标记和文本标记长度的语句级比率。我们丢弃按长度比率计算处于最小1%和最大5%的语音,以过滤掉可能的异常情况,例如包含非人类语音的短暂音频却对应着冗长的文本转录,或者只包含目标语言中短暂人类语音片段的长音频片段,从而对应着简短的文本转录。