Python从入门到高手9.4节-基于字典树的敏感词识别算法
目录
9.4.1 什么是字典树?
9.4.2 字典树实现及使用场景
9.4.3 今天情人节,你为啥还单身?
9.4.1 什么是字典树?
字典树又称单词查找树,Trie树,是一种树形结构。字典树的三个基本性质:
(1) 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
(2) 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
(3) 每个节点的所有子节点包含的字符都不相同
下图所示的结构就是字典树:
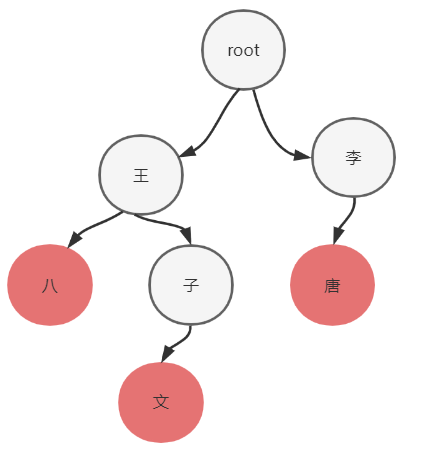
上图中的root表示根节点,红色的节点表示从根节点到该节点路径的所有字符构成一个完整的单词。比如图中的王八就是一个单词,王子文就是一个单词。王八和王子文有一个共同的前缀:王。这也是为什么使用字典树可以查找共同前缀。
9.4.2 字典树实现及使用场景
我们现在利用Python中的字典来构造这棵字典树:
"""
@author: 薯条老师
@desc: 实现字典树结构
"""names = ["王八", "王子文", "李唐"]
trie = {"root": {}}
for name in names:prev = trie_next = trie["root"]for ch in name:if ch not in trie_next:trie_next[ch] = {}prev = trie_nexttrie_next = trie_next[ch]else:# 键为None时即为红色节点prev[ch] = {None: 0}
print(trie)字典树常用于字符串检索,以及查找字符串的公共前缀等。我们现在根据字典树结构,来写一个识别文本中的敏感词算法。Python代码如下:
"""
@author: 薯条老师
@desc: 根据字典树来识别文本中的敏感词
"""
# 定义敏感词列表,后续根据该列表来构造字典树
sensitive_words = ["他妈的", "你妹"]trie = {"root": {}}
for sensitive_word in sensitive_words:prev = trie_next = trie["root"]for ch in sensitive_word:if ch not in trie_next:trie_next[ch] = {}prev = trie_nexttrie_next = trie_next[ch]else:prev[ch] = {None: 0}# text系用户在某论坛发表的一些评论
text = "我跟他妈在街上偶遇,没想到被你妹妹看到了"
length_of_text = len(text)for index in range(length_of_text):pos = indexsensitive_word = ""trie_next = trie["root"]while text[pos] in trie_next and pos < length_of_text:sensitive_word += text[pos]trie_next = trie_next[text[pos]]if None in trie_next:print(f"发现了敏感词汇{sensitive_word}")breakpos += 19.4.3 今天情人节,你为啥还单身?
跟薯条老师学高级爬虫(JS逆向+安卓逆向),数据分析,数据科学,金融量化交易,以及机器学习+深度学习+大模型算法。坚持下去,你一定会成为高手。
薯条老师的学生在南方电网,林氏家居,京东,阿里等大厂。薯条老师的个人技术博客:Python神仙级入门教程-零基础学习数据分析,高级爬虫,机器学习+大模型算法。对本节教程有任何不懂的同学,亦可在评论区中进行评论。