ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
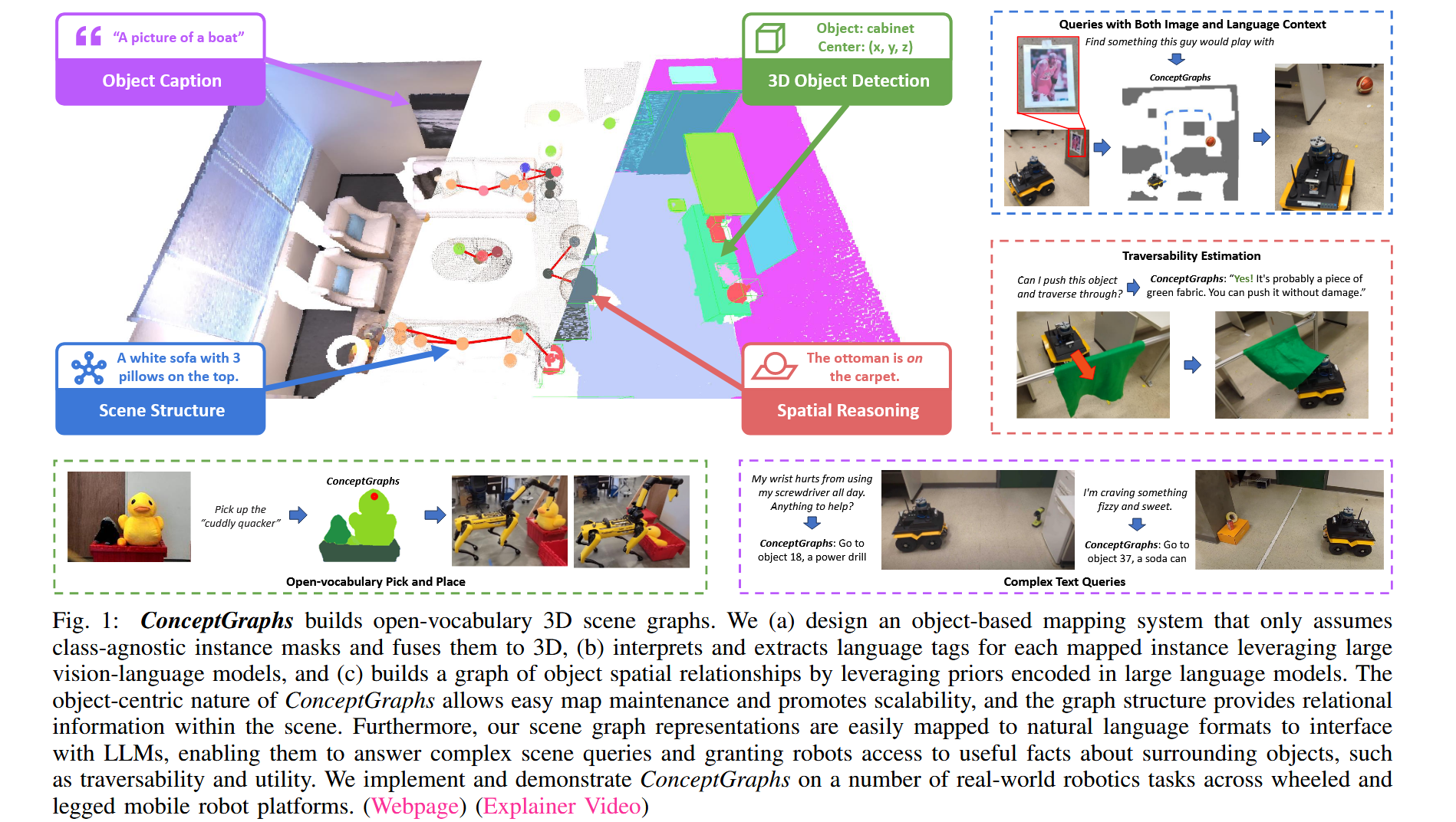
图1:ConceptGraphs 构建开放词汇的3D场景图。(a) 我们设计了一个基于对象的映射系统,它仅依赖类别无关的实例掩码并将其融合到3D中;(b) 利用大型视觉语言模型对每个映射的实例进行语言标签的解析和提取;(c) 通过利用编码在大型语言模型中的先验知识,构建对象空间关系的图结构。ConceptGraphs 的对象中心特性使得地图维护更加便捷并促进了可扩展性,而图结构提供了场景中的关系信息。此外,我们的场景图表示可以轻松映射为自然语言格式,以便与大型语言模型(LLMs)交互,从而能够回答复杂的场景查询,并为机器人提供周围对象的有用信息,例如可通行性和实用性。我们在多个真实世界的机器人任务中实现并展示了 ConceptGraphs,涵盖了轮式和足式移动机器人平台。(网页)(解说视频)
摘要: 为了使机器人能够执行广泛的任务,它们需要对世界进行3D表示,这种表示需要同时具备丰富的语义信息以及紧凑而高效的特性,以支持任务驱动的感知和规划。近期的一些方法尝试利用大型视觉-语言模型的特征来为3D表示编码语义。然而,这些方法通常生成具有每点特征向量的地图,这种方式在较大的环境中缺乏可扩展性,同时也未能包含环境中实体之间的语义空间关系,而后者对下游规划任务非常有用。在本研究中,我们提出了ConceptGraphs,一种用于3D场景的开放词汇表图结构表示。ConceptGraphs通过利用2D基础模型并将其输出通过多视点关联融合到3D中构建而成。这种表示能够泛化到新的语义类别,而无需收集大型3D数据集或对模型进行微调。我们通过一系列需要通过语言抽象提示指定并对空间和语义概念进行复杂推理的下游规划任务,展示了这一表示的实用性。为了进一步探索我们实验和结果的完整范围,我们鼓励读者访问我们的项目网页。
I. 引言
场景表示是促进各种任务(包括移动性和操作性)下游规划的关键设计选择之一。机器人需要在导航环境时通过车载传感器在线构建这些表示。为了高效执行复杂任务,这些表示应该具备以下特性:可扩展并高效维护,随着场景体积和机器人操作时间的增加,表示应保持可扩展性和效率;开放词汇表,不局限于在训练时预定义的一组概念进行推断,而是能够在推断时处理新对象和新概念;且具备细节级别的灵活性,以便在范围广泛的任务中进行规划,从需要密集几何信息以支持移动和操作的任务,到需要抽象语义信息和对象级可供性信息以支持任务规划的任务。我们提出了ConceptGraphs,这是一种满足上述所有要求的机器人感知和规划的三维场景表示方法。
A. 相关工作
3D 的封闭词汇语义映射。早期的工作通过在线算法(如同步定位与建图(SLAM)[1]-[5])或离线方法(如从运动中重建结构(SfM)[6], [7])来重建 3D 地图。除了重建 3D 几何形状,近期的工作还利用基于深度学习的物体检测和分割模型,通过密集语义映射 [8]-[11] 或物体级分解 [12]-[15] 来重建 3D 场景表示。这些方法在将语义信息映射到 3D 中取得了令人印象深刻的成果,但它们是封闭词汇的,其适用性仅限于训练数据集中标注的物体类别。
利用基础模型的 3D 场景表示。近年来有大量研究 [16]-[30] 致力于利用基础模型(即大型、功能强大的模型,可捕捉多样化概念并完成广泛任务 [31]-[35])来构建 3D 表示。这些模型在处理 2D 视觉中的开放词汇问题时表现出色。然而,这类模型需要“大规模互联网”级的数据集进行训练,而目前尚不存在同等规模的 3D 数据集。因此,近期的研究试图将通过图像和语言基础模型生成的 2D 表示与 3D 世界建立联系,并在开放词汇任务中展示了令人印象深刻的成果,包括语言引导的物体定位 [17], [18], [24], [26], [36],3D 推理 [37], [38],机器人操控 [39]-[41] 和导航 [42], [43] 等。这些方法通过将图像中每像素的密集特征投影到 3D 来构建显式表示(如点云 [17]-[21] 或隐式神经表示 [16], [22]-[30])。然而,这些方法有两个主要局限性。首先,为每个点分配语义特征向量非常冗余,且消耗了不必要的内存,从而极大地限制了其在大场景中的可扩展性。其次,这些密集表示难以进行简单分解——这种缺乏结构的特性使它们不易于对地图进行动态更新(这一点对机器人技术至关重要)。
3D 场景图表。3D 场景图表(3DSGs)通过图结构紧凑且高效地描述场景,节点表示物体,边表示物体间的关系 [44]-[48],从而解决了上述第二个局限性。这些方法支持动态构建分层 3D 场景表示的实时系统 [49]-[51],并在近期展示了各类机器人规划任务如何受益于 3DSGs 的效率与紧凑性 [52], [53]。然而,现有关于构建 3D 场景图的研究仍局限于封闭词汇环境