RabbitMQ-高级特性
目录
1.消息确认
消息确认机制:
手动确认方法:
1.肯定确认:
2.否定确认:
3.批量否定确认:
Spring-AMQP对消息确认机制提供了三种确认策略:
2.持久化
1.交换机的持久化:
2.队列持久化:
3.消息的持久化:
3.发送方确认
1.confirm确认模式
2.return退回模式
4.如何保证RabbitMQ消息的可靠传输?
5.重试机制
6.TTL过期时间
7.死信队列
死信队列常见面试题:
8.延迟队列
9.事务
10.消息分发
1.限流:
2.负载均衡:
MQ常见面试题:
1.MQ 的作⽤及应⽤场景
2.了解过哪些 MQ,以及他们的区别
3.RabbitMQ 的核⼼概念及⼯作流程
4.RabbitMQ如何保证消息的可靠性
5.如何保证消息消费时的幂等性
6.消息积压的原因, 如何处理
7.RabbitMQ 支持两种消息传递模式
8.RabbitMQ 的⼯作模式
1.简单模式:
2.workQueue(工作模式)
3.Publish/Subscribe(发布订阅模式)
4.routing路由模式:
5.Topic通配符模式:编辑
6.RPC通信模式:
7.publisher/Confirm(发布确认模式):
1.消息确认
生产者将消息发送出去之后,到达消费端时,可能会有两种情况:消息处理成功 / 消息处理失败.
RabbitMQ向消费者发送消息后,就会从队列中将消息删除. 但是若消费者消费消息失败时,要如何处理呢,如何保证消费端成功接收到消息,并成功消费呢?
RabbitMQ的消息确认机制可以保证消息成功到达消费端,并被正确消费.
消息确认机制:
消费者在订阅队列时,可以设置autoAck参数,根据这个参数,消息确认机制有两种:
自动确认: autoAck为true的时候, RabbitMQ会自动把发送出去的消息置为确认,并删除,不管消费者是否成功处理消息.(自动确认模式用于对消息的可靠性要求不高的场景下)
手动确认: autoAck为false的时候,RabbitMQ会等待消费者显式地调⽤Basic.Ack命令, 回复确认信号后才从内存(或者磁盘) 中移去消息. 这种模式适合对消息可靠性要求⽐较⾼的场景.
当autoAck置为false的时候,即设置为手动确认模式, 消息队列中就会有两种消息状态:
1>.未发送出去的消息
2>.已发送出去,未收到消费者确认的消息.
当一直没有收到消费者的确认信号,并且和消费者已经断开连接了,RabbitMQ就会让这条消息重新入队,投递给下一个消费者.
手动确认方法:
消费者收到消息后.可以手动确认,也可以拒绝或者跳过.
RabbitMQ提供了不同的确认应答方式,消费者客户端通过调用与其对应的channel的相关方法来实现:
1.肯定确认:
Channel.basicAck(long deliveryTag, boolean multiple)
消费者调用这个方法表示确认收到消息.
参数注解:
deliveryTag: 消息的唯一标识.
它是⼀个单调递增的64 位的⻓整型值. deliveryTag 是每个通道(Channel)独⽴维护的, 所以在每个通道上都是唯⼀的. 当消费者确认(ack)⼀条消息时, 必须使⽤对应的通道上进⾏确认.
deliveryTag 是RabbitMQ中消息确认机制的⼀个重要组成部分, 它确保了消息传递的可靠性和顺序性.
multiple: 是否批量确认.
为减少网络流量,可以对一系列连续的消息进行确认.当置为true时,就会一次性确认所有小于等于指定deliveryTag的 消息. 为false时,仅确认当前指定的deliveryTag 的消息.
2.否定确认:
Channel.basicReject(long deliveryTag, boolean requeue)
消费者调用这个方法表示拒绝接收消息.
参数注解:
deliveryTag : 消息的唯一标识.(和肯定确认的参数含义一样)
requeue: 是否重新入队.
表示消费者拒绝后,如何处理这条消息,如果requeue为true时,RabbitMQ会将这条消息重新入队.然后发给下一个消费者;为false时,RabbitMQ会直接将这条消息移除,不会再发给新的消费者.
3.批量否定确认:
Channel.basicNack(long deliveryTag, boolean multiple,boolean requeue)
参数注解:
deliveryTag :消息的唯一标识.(和前2中方法的参数含义一样)
multiple:是否批量确认.
Basic.Reject命令⼀次只能拒绝⼀条消息,如果想要批量拒绝消息,则可以使⽤Basic.Nack这个命令.
当置为true时,就会批量拒绝小于等于指定 deliveryTag 的违未被确认的消息.
requeue: 是否重新入队(和上面方法的含义一样)
Spring-AMQP对消息确认机制提供了三种确认策略:
public enum AcknowledgeMode {NONE, MANUAL,AUTO;
}1.NONE:
这种模式下, 消息一旦发送给消费者,不管是否消费者是否正确处理消息,RabbitMQ 就会⾃动确认消息, 从RabbitMQ队列中移除消息. 如果消费者处理消息失败, 消息可能会丢失.
2.AUTO:
这种模式下, 若消息处理成功,会自动确认,若在处理过程中抛出了异常, 则不会确认.
3.MANUAL:
手动模式下,消息处理成功后,消费者必须显示的手动调用basicAck方法来确认消息,若消息未被确认,RabbitMQ会再次将消息放到消息队列中,重新发送消息. 这种模式提⾼了消息处理的可靠性, 因为即使消费者处理消息后失败, 消息也不会丢失, ⽽是可以被重新处理.
代码演示:
创建SpringBoot项目来模拟:
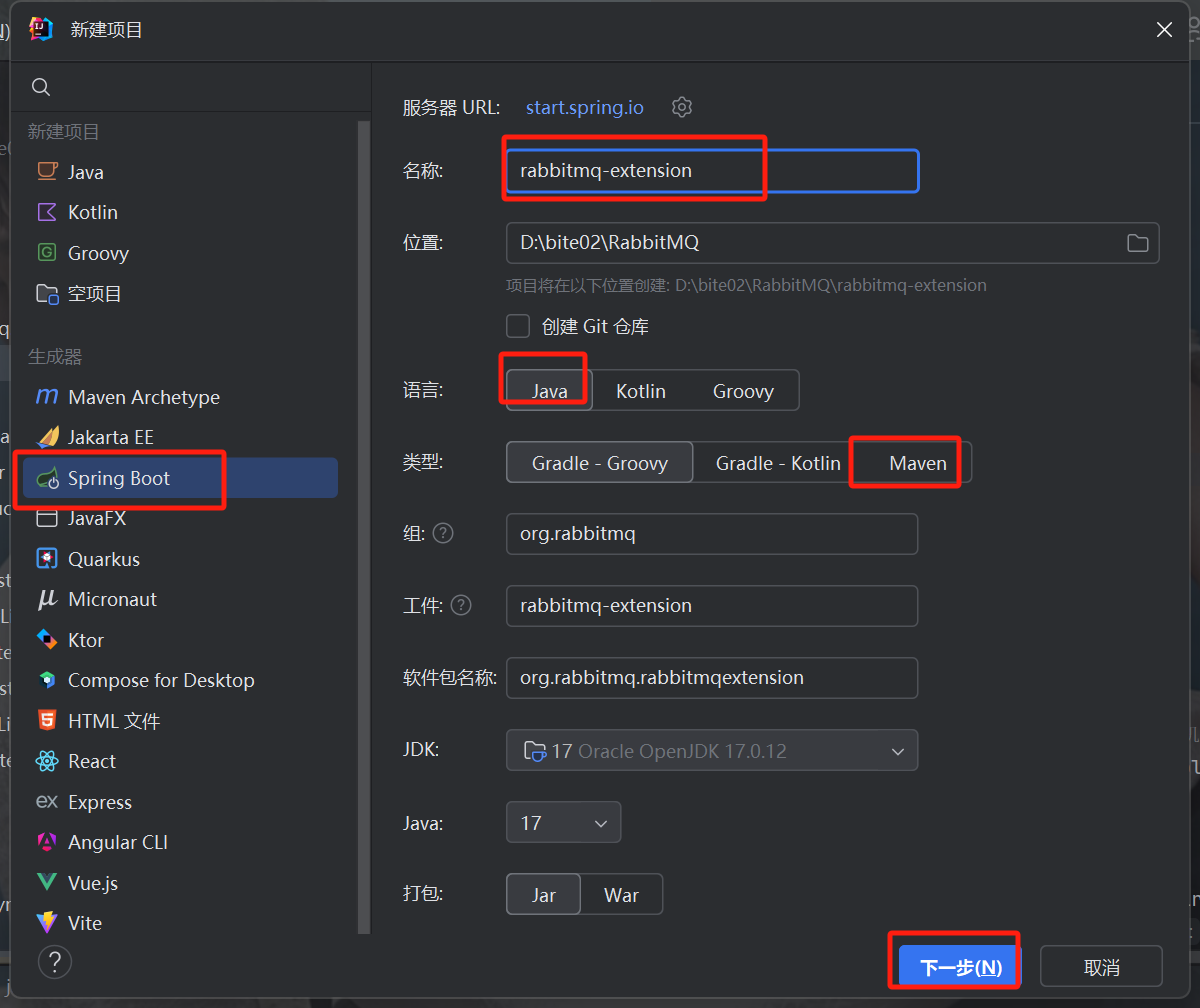
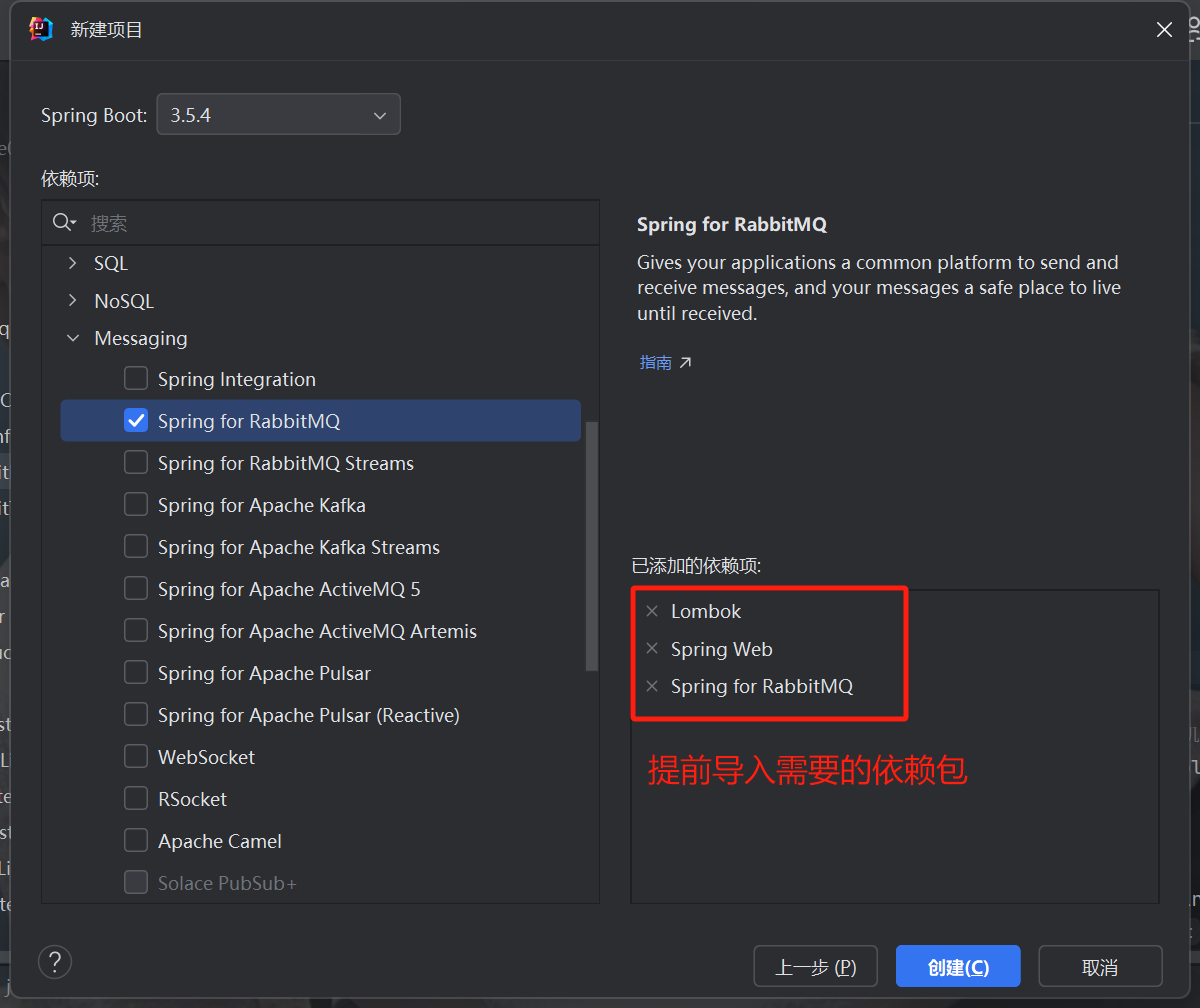
填写配置信息:
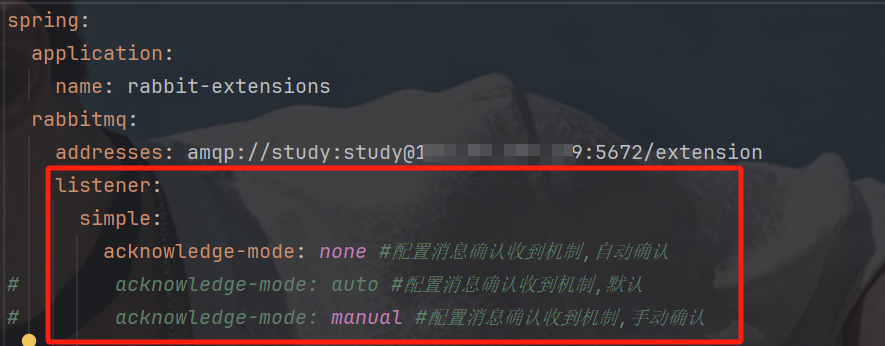
设置为自动确认:
spring:rabbitmq:addresses: amqp://study:study@110.41.51.65:15673/bitelistener:simple:acknowledge-mode: none //消息自动确认
1.声明队列和交换机:
声明常量名:

public static final String ACK_EXCHANGE = "ack_exchange";public static final String ACK_QUEUE = "ack_queue";2.持久化
消息确认机制保证了消费者处理消息的可靠性; 又如何保证当RabbitMQ出现宕机等,服务停掉后,生产者发送的消息不丢失,再次重启RabbitMQ服务器后,原来的消息数据还存在.
将RabbitMQ的一些配置设为持久化可以解决这个问题.
RabbitMQ的持久化分为3中: 交换机的持久化, 队列的持久化, 消息的持久化.
1.交换机的持久化:
交换机的持久化是通过声明交换机的时候,将durable参数设置成true实现的.
ExchangeBuilder.topicExchange(Constant.ACK_EXCHANGE_NAME).durable(true).build()
设置过后的交换机会一直存在, 当重启RabbitMQ的时候,不会再重建交换机; 若交换机未设置持久化, 在RabbitMQ重启后, 相关的交换机的数据就会丢失.建议设为持久化.
2.队列持久化:
队列的持久化是通过在声明队列时将 durable 参数置为 true实现的
QueueBuilder.durable(Constant.ACK_QUEUE).build();
队列的持久性默认为true,弱项设置非持久化队列,可以使用nonDurable设置.
QueueBuilder.nonDurable(Constant.ACK_QUEUE).build();
当队列未设置持久化,在重启RabbitMQ后,队列就会被删除,队列中的消息也就都丢失了.
队列的持久化,能够保证队列本身不会因为异常情况而丢失,但无法保证队列中的消息不会丢失.要想保证消息的持久性,还需要设置消息的持久性.
3.消息的持久化:
消息的持久化需要把消息的投递模式MessageProperties 中的 deliveryMode )设置为2, 也就是 MessageDeliveryMode.PERSISTENT..
public enum MessageDeliveryMode {NON_PERSISTENT,//⾮持久化PERSISTENT;//持久化
}设置了队列和消息的持久化, 当 RabbitMQ 服务重启之后, 消息依旧存在. 如果只设置队列持久化, 重启之后消息会丢失. 如果只设置消息的持久化, 重启之后队列消失, 继⽽消息也丢失. 所以单单设置消息持久化⽽不设置队列的持久化显得毫⽆意义.
//⾮持久化信息
channel.basicPublish("",QUEUE_NAME,null,msg.getBytes());
//持久化信息
channel.basicPublish("",QUEUE_NAME,
MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes());将消息设置为持久化会非常影响RabbitMQ的性能,在实际应用过程中,要对可靠性和性能之间作一个权衡.
将交换机,队列,消息都设置持久化了.也无法保证数据的不丢失.
在持久化的消息正确存⼊RabbitMQ之后,还需要有⼀段时间(虽然很短,但是不可忽视)才能存⼊磁盘中.RabbitMQ并不会为每条消息都进⾏同步存盘(调⽤内核的fsync⽅法)的处理, 可能仅仅保存到操作系统缓存之中⽽不是物理磁盘之中. 如果在这段时间内RabbitMQ服务节点发⽣了宕机、重启等异常情况, 消息保存还没来得及落盘, 那么这些消息将会丢失.
可以通过引入RabbitMQ的仲裁队列.当主节点出现宕机后,自动切换到从节点.可以保证可靠性.
还可以在发送端引入事务机制,或发送发确认机制保证已经正确发送了消息到RabbitMQ中.
3.发送方确认
当发送方发送完消息后,并不知道消息是否成功到达了RabbitMQ服务器,若消息还没有到达服务器就已经丢失了,那么服务器的持久化设置就根本没派上用场.因为消息根本就没有到达服务器.
那么如何解决这个问题呢?
RabbitMQ提供了两种解决方案:
1. 通过事务解决: 当一条消息成功到达接收方时,才发送成功,发送失败时,就进行回滚.
2.通过发送方的发送确认机制解决.
这里介绍一下第二种方法:发送确认机制.
RabbitMQ提供了两种方式来保证消息投递的可靠性.
1.confirm确认模式
2.return退回模式
1.confirm确认模式
produce在发送消息的时候,为发送端设置一个ConfirmCallBack的监听,无论消息是否到达Exchange,这个监听都会被执行,如果Exchange成功收到,ACK为true,若没有收到消息,ACK就位false.
2.return退回模式
消息到达Exchange交换机后,会将消息根据路由匹配规则,将消息放到Queue中,若没有路由匹配的队列,那么这条消息就无法被消费者消费.此时,可以选择将消息退回给发送者,消息退回给发送者时,可以设置一个返回回调方法,对消息进行处理.
4.如何保证RabbitMQ消息的可靠传输?
1.生产者发送消息到RabbitMQ出现问题:
使用confirm确认模式解决.
2.消息到达交换机,通过路由规则匹配队列时,未匹配到队列,导致消息无法被消费:
使用return退回机制解决.
3.RabbitMQ服务器宕机,服务重启后,导致队列中的消息丢失:
通过服务器的持久化来保证消息的可靠性.(交换机,队列,消息的持久化)
4. 消息发送给消费者时,消费者未能成果处理:
可以通过消息确认机制来保证消费者成功接受并处理消息.(手动确认模式)
5.重试机制
在消息发送的过程中,可能会遇到各种问题,导致消息没有没消费者成功消费,为解决这些问题,当消息没有被成功消费的时候,RabbitMQ提供了重试机制,允许消息在处理失败后,重新发送消息.
重试配置:
spring:rabbitmq:listener:simple:acknowledge-mode: auto #消息接收确认 retry:enabled: true # 开启消费者失败重试 initial-interval: 5000ms # 初始失败等待时⻓为5秒 max-attempts: 5 # 最⼤重试次数(包括⾃⾝消费的⼀次) 重试机制只有在设置消息确认方式为AUTO自动确认模式下才生效.若设置为MANUAL手动确认,则重试机制就不会生效. 因为是否重试以及 何时重试更多地取决于应⽤程序的逻辑和消费者的实现.
⾃动确认模式下,RabbitMQ会在消息被投递给消费者后⾃动确认消息.如果消费者处理消息时抛出异 常,RabbitMQ根据配置的重试参数⾃动将消息重新⼊队,从⽽实现重试.重试次数和重试间隔等参数可 以直接在RabbitMQ的配置中设定,并且RabbitMQ会负责执⾏这些重试策略.
⼿动确认模式下,消费者需要显式地对消息进⾏确认.如果消费者在处理消息时遇到异常,可以选择不确 认消息使消息可以重新⼊队.重试的控制权在于应⽤程序本⾝,⽽不是RabbitMQ的内部机制.应⽤程序 可以通过⾃⼰的逻辑和利⽤RabbitMQ的⾼级特性来实现有效的重试策略

6.TTL过期时间
通过对消息和队列设置过期时间,当发送的消息达到过期时间,还未被消费者消费,就会被自动清除.
设置消息的过期时间TTL有两种方式:
1.设置队列的TTL: 队列中的所有消息都有相同的过期时间.
2.设置消息的TTL: 为每条消息设置一个过期时间.
若两种方法一起设置,则按两者的较小值为准.
两者的区别:
设置队列的TTL,一旦消息到达队列的过期,还未被消费,就会直接从队列中删除; 设置消息的TTL,当消息到达过期时间时,不会立即将其从队列中删除,而是当消息到达队列的首部时,才将其删除. 因为队列是按照先进先出的顺序执行的,若让消息到达过期时间就删除,还需要遍历队列,判断是否到达过期时间,进行删除.这样不如等到消息到达对头再判断是否过期,再将其删除.
7.死信队列
死信: 因为各种原因,无法被消费的消息,就是死信.
死信队列: 存储的就是死信.当消息在一个队列中变成死信后,他将会被发送到另一个交换机中,这个交换机就是DLX(dead letter exchange),绑定DLX的队列就是死信队列.(DLQ)
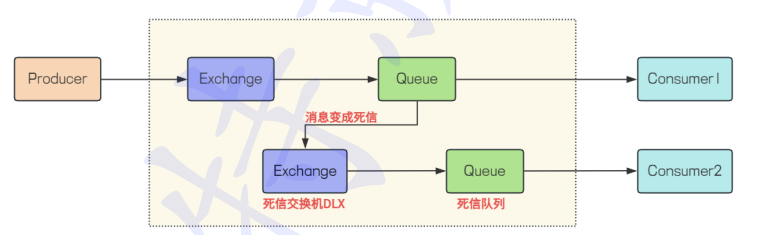
消息变成死信有一下几种情况:
1.消息被拒绝,消费者在处理消息的时候,拒绝处理该消息,且指定未重新入队的消息.
2.消息过期: 消息在队列中的存活时间超过了设定的TTL
3.队列达到最大长度: 队列中的消息达到队列的最大长度,无法再容纳新的消息,新来的消息就会被处理为死信.
死信队列常见面试题:
1.死信队列的概念:
死信是一种特殊的消息,指的是哪些无法被消费者消费也无法确认的消息.存储到一个队列,这个队列就是死信队列.
2.死信的来源:
1.达到过期时间,还未被确认
2.消费者拒绝接受该消息,并且不让其重新入队
3.消息个数达到队列的最大长度,新来的消息就会进入死信队列,成为死信.
3.死信队列的应用场景:
消息重试:将死信消息重新发送到原队列或另⼀个队列进⾏重试处理.
消息丢弃:直接丢弃这些⽆法处理的消息,以避免它们占⽤系统资源.
日志收集:将死信消息作为⽇志收集起来,⽤于后续分析和问题定位
8.延迟队列
延迟队列: 当消息发送出去后,不想让消息立即被消费,而是等待特定的时间后,消费者才能拿到这个消息.
类似于现在的智能家居,通过远程遥控设置规定时间时,启动家电.
RabbitMQ本身并没有支持延迟队列的功能,可以通过过期时间TTL+死信队列组合的方式来实现延迟队列的功能.
但这种方式存在一个问题,对一个消息设置过期时间时,当该消息在队列中到达过期时间,但未在对头,就不会被立即从队列中删除.导致无法将该消息发送到死信队列.因此,当遇到不同的任务类型需要不同的延迟时间,可以为每一种不同的延迟时间建立单独的消息队列.
还可以使用官方提供的延迟插件实现延迟的功能.他可以保证消息按照延迟时间到达消费者.但受版本的限制.
⼆者对⽐:
1. 基于死信实现的延迟队列
a. 优点:1)灵活不需要额外的插件⽀持
b. 缺点:1)存在消息顺序问题 2)需要额外的逻辑来处理死信队列的消息,增加了系统的复杂性
2. 基于插件实现的延迟队列
a. 优点:1)通过插件可以直接创建延迟队列,简化延迟消息的实现.2)避免了DLX的时序问题
b. 缺点:1)需要依赖特定的插件,有运维⼯作2)只适⽤特定版本
9.事务
RabbitMQ是基于AMQP协议实现的, 该协议实现了事务机制, 因此RabbitMQ也⽀持事务机制. Spring AMQP也提供了对事务相关的操作.
RabbitMQ事务允许开发者确保消息的发送和接收是原⼦性的, 要么全部成功, 要么全部失败.
10.消息分发
RabbitMQ队列有多个消费者时,队列会把消息分发给不同的消费者,每条消息只会发给一个消费者.
默认情况下,RabbitMQ以轮训的方式分发消息,但这种方式不太理想.不论消费者是否处理完当前的消息,都轮训发送消息给消费者.若某些消费者消费消息比较慢,而有些消费者消费消息比较快,就可能导致有些消费者消息挤压,有些处于空闲状态,进而影响整体处理消息的速度.
可以通过限制当前信道上的消费者所能保持的最大消息为确认数量,来合理派发消息给不同的消费者.
应用场景:
1.限流:
当在某些特定时间点,(618,双11),某一刻消息瞬间达到一个峰值,若这些消息全部发送到一个消费者上,极有可能会把消费者客户端给压垮. 可以通过限流的方式,控制一个消费者一次只能拉去N个请求,设置应答方式为手动应答,实现流量控制和负载均衡.
2.负载均衡:
当一个消费者处理消息速度快,而另一个消费者处理消息比较慢,就可以为其设置不同的一次接受消息的上限,达到负载均衡的效果.
MQ常见面试题:
1.MQ 的作⽤及应⽤场景
异步解耦: 在业务流程中, 一些操作可能⾮常耗时, 但并不需要即时返回结果. 可以借 助 MQ 把这些操作异步化, ⽐如 用⼾注册后发送注册短信或邮件通知, 可以作为异步 任务处理, 而不必等待这些操作完成后才告知用⼾注册成功.
流量削峰: 在访问量剧增的情况下, 应用仍然需要继续发挥作用, 但是是这样的突发 流量并不常⻅. 如果以能处理这类峰值为标准而投⼊资源,⽆疑是巨⼤的浪费. 使用MQ 能够使关键组件支撑突发访问压⼒, 不会因为突发流量而崩溃. ⽐如秒杀或者促销活动, 可以使用MQ 来控制流量, 将请求排队, 然后系统根据自己的处理能⼒逐步处理这些请 求.
异步通信: 在很多时候应用不需要⽴即处理消息, MQ 提供了异步处理机制, 允许应用 把一些消息放⼊MQ 中, 但并不⽴即处理它,在需要的时候再慢慢处理.
消息分发: 当多个系统需要对同一数据做出响应时, 可以使用MQ 进⾏消息分发. ⽐ 如支付成功后, 支付系统可以向 MQ 发送消息, 其他系统订阅该消息, 而⽆需轮询数据 库.
延迟通知: 在需要在特定时间后发送通知的场景中, 可以使用MQ 的延迟消息功能, ⽐如在电⼦商务平台中,如果用⼾下单后一定时间内未支付,可以使用延迟队列在超 时后自动取消订单.
2.了解过哪些 MQ,以及他们的区别
1.kafak:
Kafka一开始的目的就是用于⽇志收集和传输,追求高吞吐量, 性能卓越, 单机吞吐达 到⼗万级, 在⽇志领域⽐较成熟, 功能较为简单, 主要支持简单的 MQ 功能. 适合⼤数 据处理, ⽇志聚合, 实时分析等场景
2. RabbitMQ
采用Erlang 语⾔开发, MQ 功能⽐较完备, 且⼏乎支持所有主流语⾔, 开源提供的界面 也⾮常友好, 性能较好, 吞吐量能达到万级, 社区活跃度较高,⽂档更新频繁, ⽐较适 合中⼩型公司, 数据量没那么⼤, 且并发没那么高的场景.
3. RocketMQ
采用Java 语⾔开发, 由阿里巴巴开源, 后捐赠给了 Apache. 在可用性, 可靠性以及稳定 性等⽅面都⾮常出色, 吞吐量能达到⼗万级, 在 Alibaba 集团内部⼴泛使用, 但支持的 客⼾端语⾔不多, 产品较新⽂档较少, 且社区活跃度一般. 适合于⼤规模分布式系统, 可靠性要求高, 且并发⼤的场景, ⽐如互联⽹⾦融.
这些消息队列, 各有侧重, 没有好坏, 只有适合不适合, 在实际选型时, 需要结合自⾝需求以及 MQ 产品特征, 综合考虑.
3.RabbitMQ 的核⼼概念及⼯作流程
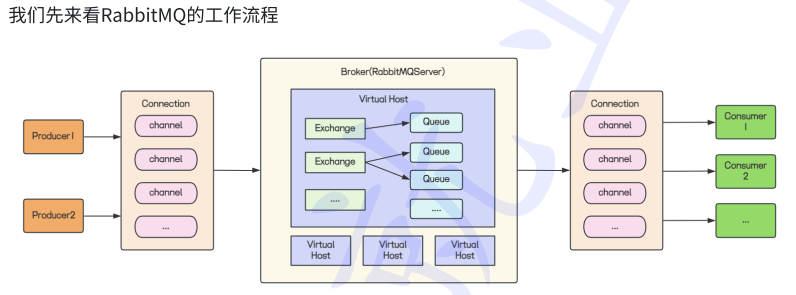
RabbitMQ 是一个消息中间件, 也是一个生产者消费者模型. 它负责接收, 存储并转发消息.
• Producer: 生产者, 向 RabbitMQ 发送消息
• Consumer: 消费者, 从 RabbitMQ 接收消息
• Broker: 消息队列服务器或服务实例, 也就是 RabbitMQ Server
• Connection: ⽹络连接, 它允许客⼾端与 RabbitMQ 通信
• Channel: 连接里的一个虚拟通道, 发送或者接收消息都是通过通道进⾏的.
• Exchange: 交换机. 负责接收生产者发送的消息, 并根据路由算法和规则将消息路由 到一个或多个队列
• Queue: 消息队列, 存储消息直到它们被消费者消费
工作路程:
1.创建连接: 生产者连接到RabbitMQBroker,创建一个connection连接,建立一个channel信道.
2.声明交换机和队列,和绑定规则:生产者声明一个交换机和队列,建立队列和交换机的绑定规则.
3.消息存储: 生产者将消息通过信道,发送给交换机,交换机通过绑定规则,将消息路由到指定队列中存储.
4.消费消息: 队列将消息分发给订阅队列的消费者,消费者接受消息并消费消息.
5.删除消息: 消费者成功接受并消费消息后,手动确认模式下,返回给broker确认消息,RabbitMQ会将发送出去的消息从队列中删除.
4.RabbitMQ如何保证消息的可靠性
5.RabbitMQ如何保证消息的顺序性:
消息的顺序性: 指消费者消费的消息和生产者发送消息的顺序是一致的
哪些情况可能会打破 RabbitMQ 的顺序性呢?
重试机制,
消息进入死信队列,
存在多个消费者,消费者会并行处理消息
网络波动,导致消息无法按时到达
路由问题,无法将消息路由到指定的队列
消息顺序性保障分为: 局部顺序性保证和全局顺序性保证.
局部顺序性通常指的是在单个队列内部保证消息的顺序.
全局顺序性是指在多个队列 或多个消费者之间保证消息的顺序.
RabbitMQ 作为一个分布式消息队列, 主要优化的是吞吐量和可用性, 而不是严格的顺 序性保证. 如果业务场景确实需要严格的消息顺序, 可能需要在应用层面进⾏额外的设 计和实现
解决⽅法:
1. 单队列单消费者, 最简单的⽅法是使用单个队列, 并由单个消费者进⾏处理. 同一个队列中的消息是 先进先出的, 这是 RabbitMQ 来帮助我们保证的
2. 分区消费, 单个消费者的吞吐太低了, 当需要多个消费者以提高处理速度时, 可以使用分区消 费. 把一个队列分割成多个分区, 每个分区由一个消费者处理, 以此来保持每个分区内消息的顺序性. RabbitMQ 本⾝并不支持分区消费, 需要业务逻辑去实现, 或者借助 spring-cloudstream 来实现
3. 消息确认机制, 使用⼿动消息确认机制, 消费者在处理完一条消息后, 显式地发送确认, 这样 RabbitMQ 才会移除并继续发送下一条消息
4. 业务逻辑控制, ⽐如消费端内部实现消息排序逻辑. 在某些情况下, 即使消息乱序到达, 也可以在业务逻辑层面实现顺序控制. ⽐如通过在 消息中嵌⼊序列号, 并在消费时根据这些信息来处理
5.如何保证消息消费时的幂等性
在应⽤程序中, 幂等性就是指对⼀个系统进⾏重复调⽤(相同参数), 不论请求多少次, 这些请求对系统的影响都是相同的效果.
对于 MQ而⾔, 幂等性是指同一条消息, 多次消费, 对系统的影响是相同的.
一般消息中 间件的消息传输保障分为三个层级.
1. At most once:最多一次. 消息可能会丢失,但绝不会重复传输.
2. At least once:最少一次. 消息绝不会丢失,但可能会重复传输.
3. Exactly once:恰好一次. 每条消息肯定会被传输一次且仅传输一次.
RabbitMQ支持"最多一次"和"最少一次". 对于"恰好一次", 目前 RabbitMQ 还做不到, 不仅是 RabbitMQ, 目前市面上主流的消息 中间件, 都做不到这一点. 在业务使用中, 对于可靠性要求⽐较高的场景, 建议使用"最 少一次", 以防⽌消息丢失. "最多一次" 会因为消息发送过程中, ⽹络问题, 消费出现异 常等种种原因, 导致消息丢失.
以下场景可能会导致消息发送重复:
发送时消息重复: 当一条消息已被成功发送到服务端并完成持久化, 此时出现了⽹络闪 断或者客⼾端宕机, 导致服务端对客⼾端应答失败. 如果此时 Producer 意识到消息发 送失败并尝试再次发送消息, Consumer 后续会收到两条内容相同并且 Message ID 也相 同的消息.
投递时消息重复: 消息消费的场景下, 消息已投递到 Consumer 并完成业务处理, 当 客⼾端给服务端反馈应答的时候⽹络闪断. 为了保证消息⾄少被消费一次, 云消息队列 RabbitMQ 版的服务端将在⽹络恢复后再次尝试投递之前已被处理过的消息, Consumer 后续会收到两条内容相同并且 Message ID 也相同的消息.
最终都会导致消费者收到同⼀条消息多次. 对于重要的业务, 如果不对重复的消息进⾏ 处理, 会造成严重事故.
⽐如: 当用⼾对一个订单付款之后, 因为⽹络问题, 付款成功的结果未返回给订单系统, 当用⼾再次点击付款时, 如果系统未做幂等性处理, 那就会造成两次扣款.
解决⽅案:
全局唯⼀ID:
1. 为每条消息分配一个唯一标识符, ⽐如 UUID 或者 MQ 消息中的唯一ID,但是一定要保证唯一性.
2. 消费者收到消息后, 先用该 id 判断该消息是否已经消费过, 如果已经消费过, 则放弃 处理. 3. 如果未消费过, 消费者开始消费消息, 业务处理成功后, 把唯一ID 保存起来(数据库 或 Redis 等) 可以使用Redis 的原⼦性操作 setnx 来保证幂等性, 将唯一ID 作为 key 放到 redis 中 (SETNX messageID ) . 返回 1, 说明之前没有消费过, 正常消费. 返回 0, 说明这条消息 之前已消费过, 抛弃.
2.业务逻辑判断 在业务逻辑层⾯实现消息处理的幂等性.
例如: 通过检查数据库中是否已存在相关数据记录, 或者使用乐观锁机制来避免更新已 被其他事务更改的数据, 再或者在处理消息之前, 先检查相关业务的状态, 确保消息对 应的操作尚未执⾏, 然后才进⾏处理, 具体根据业务场景来处理
6.消息积压的原因, 如何处理
消息积压是指在消息队列(如 RabbitMQ)中, 待处理的消息数量超过了消费者处理能⼒, 导致消息在队列中不断堆积的现象
通常消息积压有以下⼏种原因:
1. 消息⽣产过快: 在高流量或者高负载的情况下, 生产者以极高的速率发送消息, 超过 了消费者的处理能⼒.
2. 消费者处理能⼒不⾜: 消费者处理处理消息的速度跟不上消息生产的速度 可能原因有: 1) 消费端业务逻辑复杂, 耗时⻓ 2) 消费端代码性能低 3) 系统资源限制, 如 CPU、内存、磁盘 I/O 等也会限制消费者处理消息的效率. 4) 异常处理处理不当. 消 费者在处理消息时出现异常, 导致消息⽆法被正确处理和确认.
3. ⽹络问题: 因为⽹络延迟或不稳定, 消费者⽆法及时接收或确认消息,
4. RabbitMQ 服务器配置偏低
消息积压可能会导致系统性能下降, 影响用⼾体验, 甚⾄导致系统崩溃.
解决⽅案:
1. 提⾼消费者效率
a. 增加消费者实例数量, ⽐如新增机器 b. 优化业务逻辑, ⽐如使用多线程来处理业务 c. 设置 prefetchCount, 当一个消费者阻塞时, 消息转发到其他未阻塞的消费者. d. 消息发生异常时, 设置合适的重试策略, 或者转⼊到死信队列
2. 限制⽣产者速率.
⽐如流量控制, 限流算法等. a. 流量控制: 在消息生产者中实现流量控制逻辑, 根据消费者处理能⼒动态调整发送速 率 b. 限流: 使用限流工具, 为消息发送速率设置一个上限 c. 设置过期时间. 如果消息过期未消费, 可以配置死信队列, 以避免消息丢失, 并减少 对主队列的压 ⼒
3. 资源与配置优化. ⽐如升级 RabbitMQ 服务器的硬件, 调整 RabbitMQ 的配置参数 等
7.RabbitMQ 支持两种消息传递模式
RabbitMQ支持两种消息传递模式: 推模式(push)和拉模式(pull)
推模式:消息中间件主动将消息推送给消费者. 对消息的获取更加实时, 适合对数据实 时性要求⽐较高时, ⽐如实时数据处理, 如监控系统, 报表系统等.
拉模式:消费者主动从消息中间件拉取消息. 消费端可以按照自己的处理速度来消费, 避免消息积压, 适合需要流量控制, 或者需要⼤量计算资源的任务, 拉取模式允许消费 者在准备好后再请求消息, 避免资源浪费.
RabbitMQ 主要是基于推模式⼯作的, 它的核⼼设计是让消息队列中的消费者接收到由 生产者发送的消息. 使用channel.basicConsume⽅法订阅队列, RabbitMQ 就会把消息推 送到订阅该队列的消费者, 如果只想从队列中获取单条消息而不是持续订阅,则可以使 用channel.basicGet⽅法来进⾏消费消息.
8.RabbitMQ 的⼯作模式
1.简单模式:
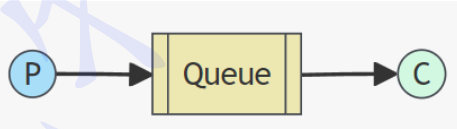
P: 生产者, 也就是要发送消息的程序 C: 消费者,消息的接收者
Queue: 消息队列, 图中⻩色背景部分. 类似一个邮箱, 可以缓存消息; 生产者向其中投递消息, 消费者从其中取出消息.
特点: 一个生产者 P,一个消费者 C, 消息只能被消费一次. 也称为点对点(Point-to-Point)模式
2.workQueue(工作模式)
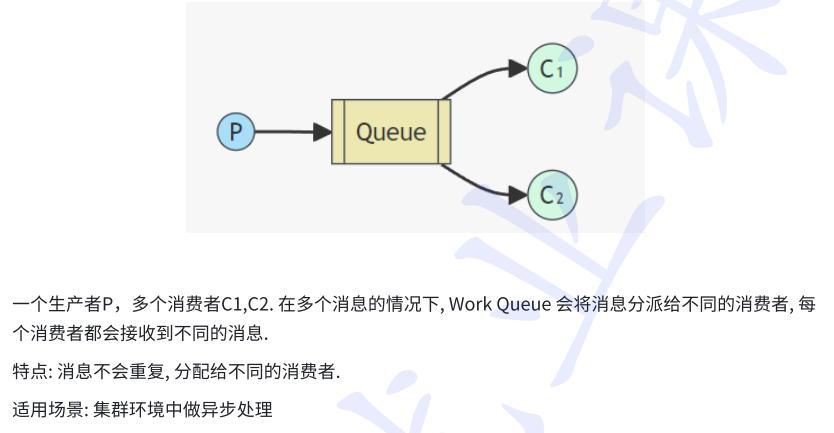
⽐如 12306 短信通知服务, 订票成功后, 订单消息会发送到 RabbitMQ, 短信服务从RabbitMQ中获取订单信息, 并发送通知信息(在短信服务之间进⾏任务分配)
3.Publish/Subscribe(发布订阅模式)
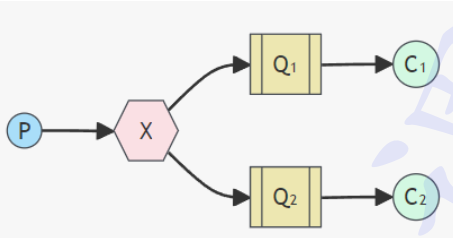
一个生产者 P, 多个消费者 C1, C2, X代表交换机,消息被复制多份; 生产者发送一条消息,经过交换机转发到多个不同的队列,多个不同的队列就有多个不同的消费者,每个消费者接收相同的消息
适合场景: 消息需要被多个消费者同时接收的场景.
⽐如中国⽓象局发布"天⽓预报"的消息送⼊交换机, 新浪,百度, 搜狐, ⽹易等⻔⼾⽹站接⼊消息, 通过队列绑定到该交换机, 自动获取⽓象局推送的⽓象数据
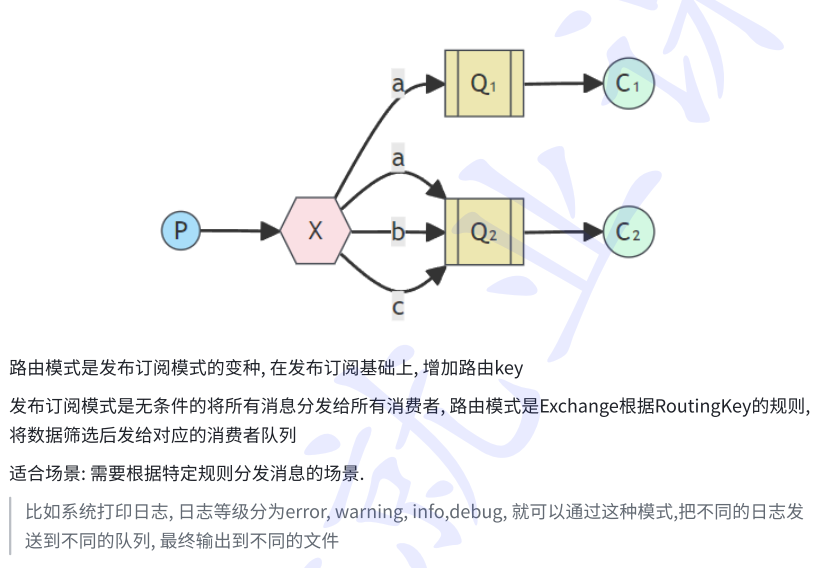
4.routing路由模式:
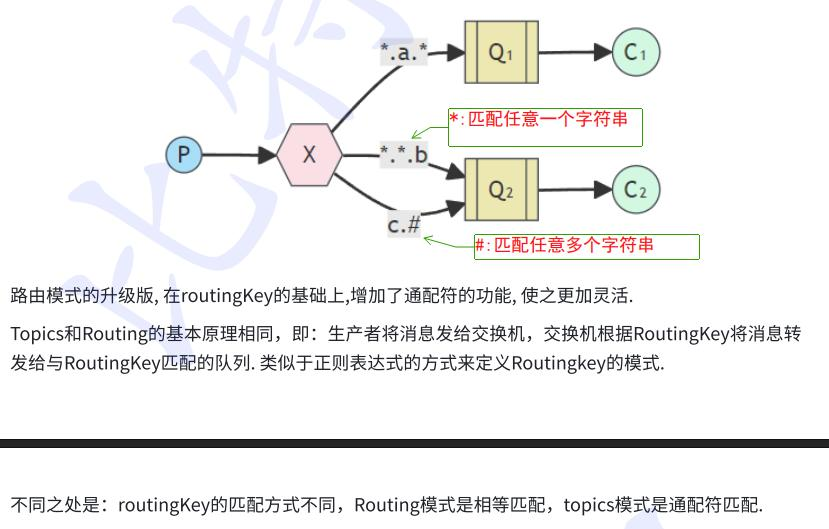
5.Topic通配符模式:
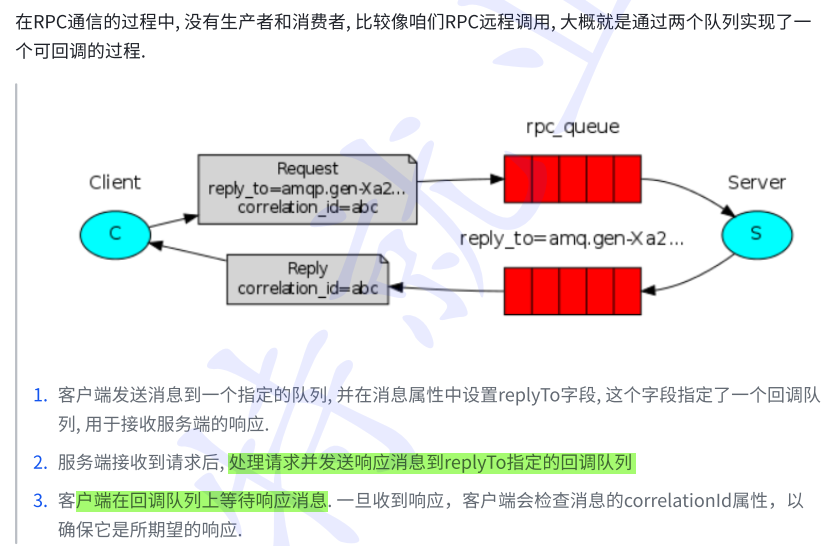
6.RPC通信模式:
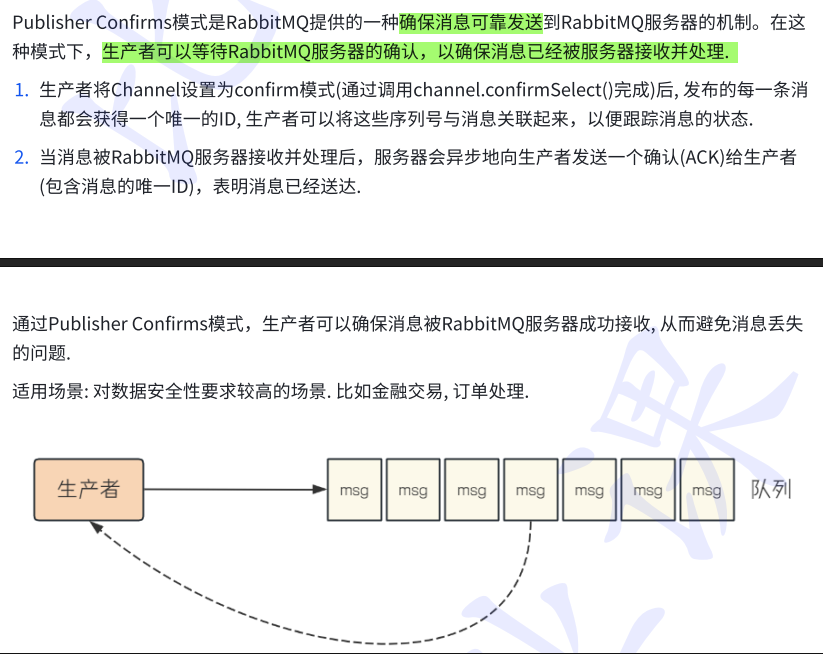
7.publisher/Confirm(发布确认模式):