音合成之二十四 微软VibeVoice语音合成模型
昨天(2025.08.28)微软发布了VibeVoice语音合成模型,而在2023年微软发布了VALL-E语音合成模型,这两个高质量的TTS模型都是大模型驱动,两者都是基于大模型(特别是Transformer架构)的能力,将TTS任务从传统的信号处理问题,转变为一个大模型的生成任务。
VALL-E在《语音合成之七语音克隆技术突破:从VALL-E到SparkTTS,如何解决音色保真与清晰度的矛盾?》已有介绍。
VALL-E和VibeVoice两者都采用了 “神经编解码器(Neural Codec)” + “语言模型(Language Model)” 的两阶段范式。
- 阶段一:使用一个编码器将音频波形压缩成一个紧凑的、序列化的中间表示(Token)。
- 阶段二:使用一个强大的自回归或非自回归模型(**如Transformer)**来学习这些Token序列的分布,并根据文本条件生成对应的Token序列。最后再用解码器将Token序列转换回波形。
- VibeVoice和VALL-E的区别
| 特性 | VALLE/VALLE 2 | VibeVoice |
|---|---|---|
| 模型架构 | 自回归/非自回归Transformer语言模型 | 基于大语言模型(Qwen2.5)的混合架构,结合了扩散模型(Diffusion Model) |
| 音频表示 | 离散化声学Token(Discrete Acoustic Tokens) | 连续性语音向量(Continuous Speech Tokens) |
| 生成方式 | 像语言模型一样,逐个预测离散的“声音编码” | 通过LLM预测上下文,再由一个“扩散头”(Diffusion Head)将预测结果逐步去噪,生成连续的声学特征 |
| 核心优势 | 开创性地将TTS视为语言建模任务,验证了其可行性 | 在音频保真度、情感表现力和长对话生成方面更具优势 |
| 主要挑战 | 离散化可能引入量化误差(损失音质细节),自回归生成速度较慢 | 模型结构更复杂 |
VibeVoice特性
核心能力点有三个:
第一:支持生成最长90分钟的连续高质量音频,突破了传统语音生成模型的时间限制,
第二:多角色自然互动,最多支持4位不同说话人,每位角色拥有独立的音色与说话风格,且在整段对话中保持一致;
第三:细节拟真与氛围生成:能够自然呈现呼吸声、顿挫感和对话间的停顿等细节,还能在适当场景中加入背景音乐、清唱等,增强氛围感,使生成语音更贴合不同博客内容的需求。
其特色在于多说话人长文本生成,传统语音生成模型大多基于离散化方法,即将语音拆成一堆参数,然后生成整段语音(即短句),VibeVoice 的核心在于采用 LatentLM next-token diffusion 生成机制,其不是将90分钟一次性做出来,先使用变分自编码(VAE)将语音波形编码为连续的潜在向量序列,这些向量可以理解为语音的“语义表示”,保留了音色、语调、节奏等关键信息,然后通过一个因果Transformer架构,以对话脚本(包括说话人标签)和已生成的潜在向量输入,逐步预测下一个语音片段,每一步都基于上下文进行扩散建模,从而实现自回归式的连续语音生成,这使得VibeVoice能更好理解上下文逻辑,也能让对话的衔接听起来更加自然、连贯。
90分钟的音频生成,如何压缩计算量?
传统语音生成模型通常采用每秒50到100帧的频率来表示语音内容,这种高帧率的好处是可以保留更多细节,但是也带来了极高的计算负担,而VibeVoice将帧率压缩至每秒7.5帧,这种压缩方式在减少计算量的同时,使得模型更容易“记住”长时间的对话内容,即可以在长时间、多角色对话中保持一致性和语义连贯性,但是需要确认的是否丢失了细节?
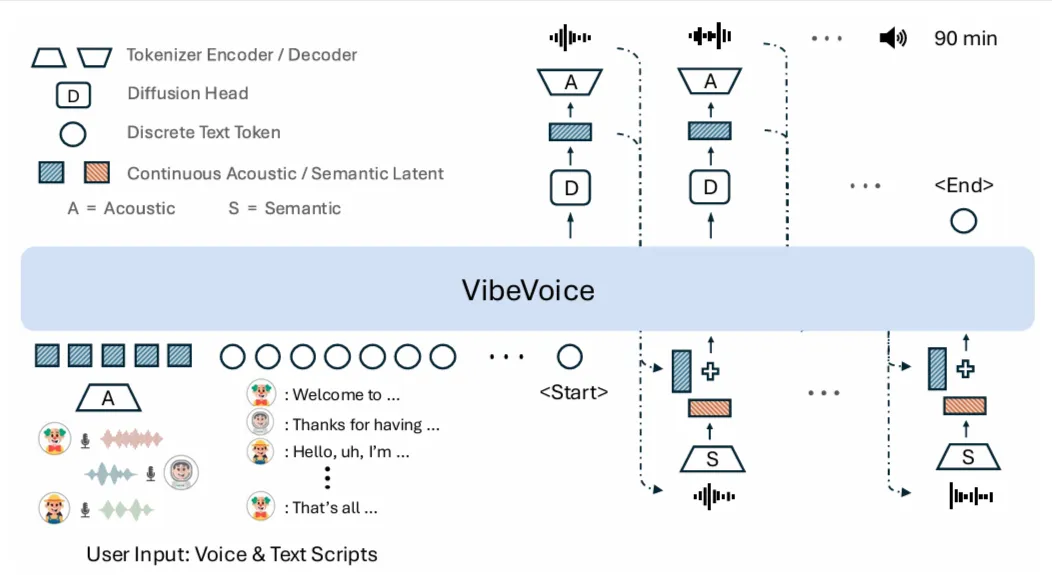
音频表示的差异(离散化 vs. 连续性)
现在有很多基于LLM的语音合成模型,多数都是采用了离散化的token表示音频。VibeVoice选择连续性反应两种不同的思路。
VALLE的“离散化”革命:将语音视为一种语言
在VALLE出现之前,主流的TTS模型大多直接在连续的频谱图(如Mel Spectrogram)上进行回归预测。这种方式虽然直接,但在捕捉精细的声学细节和实现高效的上下文学习方面面临挑战。
VALLE的设计哲学是: 如果我们能把连续的音频波形“翻译”成一本有限词汇的“声音字典”,那么TTS任务不就可以借鉴已经非常成熟的自然语言处理(NLP)技术了吗?
- 如何实现:VALLE使用了一个名为EnCodec的神经音频编解码器,它能将复杂的音频波形压缩成一系列离散的整数ID(就像单词在词典里的编号一样)。
- 为什么这么做:
- 借鉴NLP的成功:一旦音频变成了离散的Token序列,就可以直接套用强大的Transformer语言模型(类似GPT的架构)来进行预测。 这使得模型可以像预测下一个单词一样,预测下一段“声音”,从而极大地提升了模型的上下文学习能力(即声音克隆)。
- 简化问题:将无限可能的连续信号空间,简化为了一个有限的、可管理的离散编码空间。
VibeVoice的“连续性”进化:追求极致的保真度和表现力
VALLE的离散化方法非常成功,但也带来了新的问题:量化误差。即在将连续音频压缩成离散编码时,不可避免地会丢失一部分信息(尤其在多人对话时),这可能导致生成的声音听起来有些“数码味”或不够平滑。
VibeVoice的设计哲学是: 我们能否既利用大型语言模型的推理能力,又避免离散化带来的音质损失,同时提升生成效率和表现力?答案就是引入扩散模型。
- 如何实现:VibeVoice使用了一种创新的双Tokenize器,将音频转换成连续的向量表示(而非离散的ID)。 然后,它利用一个大型语言模型来理解文本和对话流程,并预测出下一个“声音片段”的整体方向。 最后,一个专门的扩散头 (Diffusion Head) 会接管这个预测,通过一个类似从模糊到清晰的“去噪”过程,逐步生成最终高质量、连续的声学特征。
- 为什么这么做:
- **更高的音频保真度:**连续向量空间能够比离散编码更完整地保留原始音频的细节,避免了量化误差,从而生成更自然、更平滑的音频。
- **更强的韵律和情感表现力:**连续空间对于建模情感、语气的细微、平滑变化更加友好。 模型可以在这个空间中进行更精细的插值和操控,实现“Vibe”(氛围/感觉)的精准控制。
- 结合LLM和扩散模型的优点:VibeVoice巧妙地让LLM负责宏观的“内容理解”,让扩散模型负责微观的“音质渲染”,各司其职。 扩散模型通常是非自回归的,可以在多个步骤中并行生成,这为提高生成速度提供了可能。
总结
总的来说,从VALLE到VibeVoice的演进,体现了AI语音合成领域的深刻洞见:
- VALLE 是一次范式革命,它成功地将TTS问题转化为了一个语言建模问题,打开了零样本声音克隆的大门。
- VibeVoice 则是在此基础上的技术精炼和升级。它通过引入连续表示和扩散模型,旨在解决离散化带来的音质瓶颈,并进一步提升语音的情感表现力、自然度和对长对话等复杂场景的处理能力。