attention is all u need
传统处理序列时间的模型的网络 cnn rnn
我们提出了一个transformer 只用了注意力机制
复习 :前馈神经网络
fnn
为什么不适合做序列转导
在用fnn处理文本任务时
任务分解 (1)分词 (2)向量表示(3)合并向量
缺点: 没有顺序信息 不同长度难以输入
解决时间问题:
有记忆力机制 上下文依赖 提出了rnn的网络
RNN 优化方向 模拟了日常的说话的情况,输入时按文字的顺序逐一输入
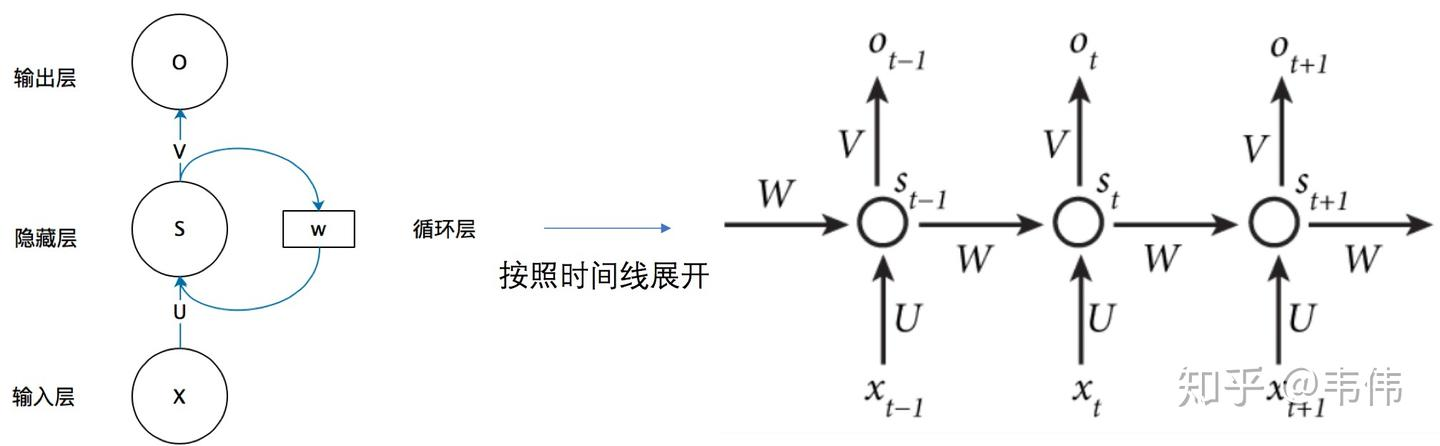
例如把 我爱你 翻译成 i love u
h(t) = g(W*X(t) +U * S(t-1))
Y(t) = g(v*S(t)) 其中g为激活函数 如 RElu sigmoid 等,
用于引入非线性 限制数值范围,避免梯度爆诈 消失。
缺点:不可变长
未解决可变长的输入问题,为了解决可变长的问题。 将RNN 的上下两部分切开,横向摆放 就变成了encode-decode结构的网络
但是解码器也有问题,
(1)长序列会有 遗忘 的问题,随着序列长度的增长,远距离依赖信息在传递过程中易被稀释
,导致模型对长距离依赖关系的建模能力减弱。
(2)不同时间步输入对当前时刻输出的重要性问题。所有时间步输入计算当前时刻输出被同等对待,忽略了不同时间步对当前时刻输出重要性存在的差异
后来我们使用的是attention去解决上面的两个问题
但是传统attention 是需要串行去训练的
所以就有了transformer
(1)并行化处理时 需要显示对位置进行编码
用正弦函数 余弦函数去做编码
这里的位置编码和词向量是直接相加的
(2)如何对上下文信息作编码 ,这里处理方式是 用注意力的模块在做这件事
注意力模块 有三个权重矩阵 WK WQ WV
每一个都是512*512的矩阵
假设keyword 词向量 为1*512 则分别与三个矩阵相乘之后
得到三个 1*512的向量 就得到了 看
k1k, k1q, k1v 三个词向量的分身 ,分别代表检索,检索的关键字,以及每个词蕴含的与检索词相同的属性。
例如我爱水课 中的水 ,q(水)与K(水)做点积,实际上就是在查询水这个词和周围词的相似程度,发现它和(容易)和课 相似性最高,然后经由softmax 进行归一化为一个基础的概率。
这个概率再与 V相乘,实际上是一个加权平均的过程,也就是哪个词更容易对水这个词有影响
这就是经典的单头注意力机制。
(3)wk wq wv 怎么得到?训练得到
(4)多头注意力对比单头注意力机制关系是怎么样的呢
那么我爱水课 经过注意力之后 变成了 4*512 ,这是单头注意力
但是多头指的是
将512 * 512 的单头注意力矩阵 QKV ,变成了8组 512*64 的向量
(5)残差和归一化
(6)解码器 ,带掩码的多头注意力,没有预测到的词会被屏蔽掉