D‘RespNeT无人机图像分割数据集与YOLOv8-DRN模型,实时识别入口与障碍,助力灾后救援

【导读】
该研究提出了D‘RespNeT——一个专为震后搜救任务构建的无人机图像实例分割数据集,包含28个精细标注的类别(如建筑入口、碎片、人员)。基于此数据集,团队开发了YOLOv8-DRN模型,该模型在保持27 FPS实时速度的同时,达到了92.7%的mAP50精度,能有效识别可进入的入口点与障碍物,为无人机在灾后环境中的自主导航与态势感知提供了可靠的技术支持。>>更多资讯可加入CV技术群获取了解哦

论文标题:
D’RespNeT: A UAV Dataset and YOLOv8-DRN Model for Aerial Instance Segmentation of Building Access Points for Post-Earthquake Search-and-Rescue Missions
论文链接:
https://arxiv.org/pdf/2508.16016
深度学习驱动的计算机视觉和神经网络的最新进展,包括目标检测、实例分割和语义分割等技术,提供了有前景的自动化方法来克服这些限制。这些方法有助于快速、详细且可靠地识别关键的灾害响应特征,例如结构损坏、可行入口点、碎片存在、救援人员和遇险平民。对于研究人员和开发者而言,此类模型的训练与优化可以借助Coovally平台高效完成。在平台上,你可以一键调用YOLO、Transformer等热门模型,快速对任务进行训练与验证。
如表 1 所示,每种计算机视觉方法都有其独特的优势和局限性。使用边界框定位和分类物体的目标检测标注提供了更快的计算性能。
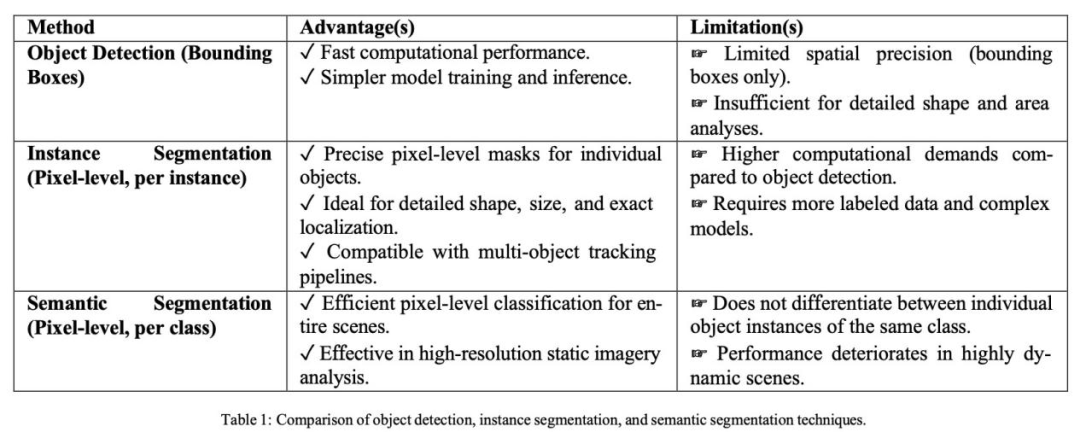
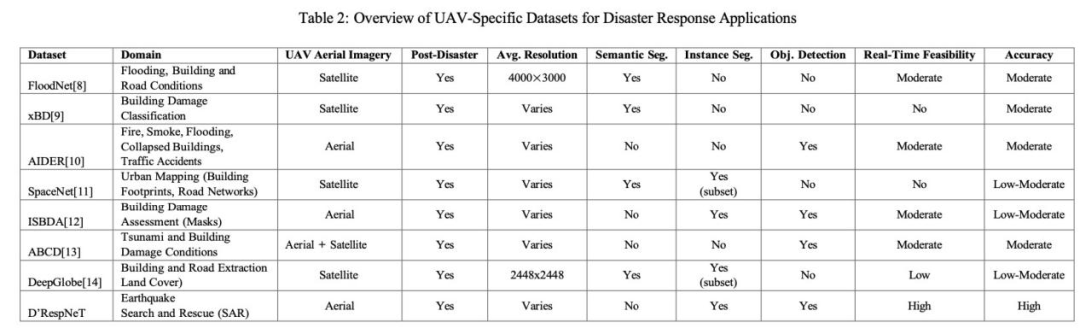
如表 2 所示,该自定义数据集独特地提供了源自真实无人机和无人机航空图像的全面实例分割标签,使其高度适用于实时灾害响应场景。
这类数据集的准备和管理工作,在Coovally平台上可以高效完成,平台集成了海量开源数据集并提供便捷的数据标注与管理工具,大幅提升数据工作流效率。
总之,本研究做出了以下关键贡献:
-
引入了D’RespNeT,一个新颖的多边形级标注数据集,用于从近期地震后受限灾害响应区域真实无人机航空影像中进行实例分割,包含 28 个对土耳其、缅甸及类似受灾地区地震后 SAR 操作至关重要的类别。
-
标注了灾害响应关键特征,包括建筑结构完整性、入口点可进入性(门、窗、缝隙)、碎片严重程度、人员存在和安全的无人机着陆区,并根据它们对机器人搜救任务的操作意义进行了明确分类。
-
在 D’RespNeT 数据集上对基于 YOLO 的实例分割方法进行了全面评估,验证了在实时态势感知方面的显著增强,以改进震后和受灾城市场景中的导航决策。
-
开发了专门针对灾害响应航空影像的结构化标注协议和严格的质量保证框架,确保标注可靠性以及未来研究和在搜救机器人中实际部署的操作适用性。
一、实验结果
-
模型与训练细节
-
网络选择:生产模型是YOLOv8-seg(大型变体,yolov8l-seg),因为它提供了实例掩码准确性和实时推理速度之间的最佳权衡。为了比较,训练了一个仅检测的YOLOv12基线(预发布提交,2025年4月10日);在撰写本文时,YOLOv12的分割头尚不可用。
-
硬件和软件:训练运行在RTX-4090 (24 GB)和 AMD Ryzen 9 7950X3D (16 × 4.2 GHz)配64 GB RAM,Ubuntu 22.04,PyTorch 2.1 + CUDA 12.3上执行。
-
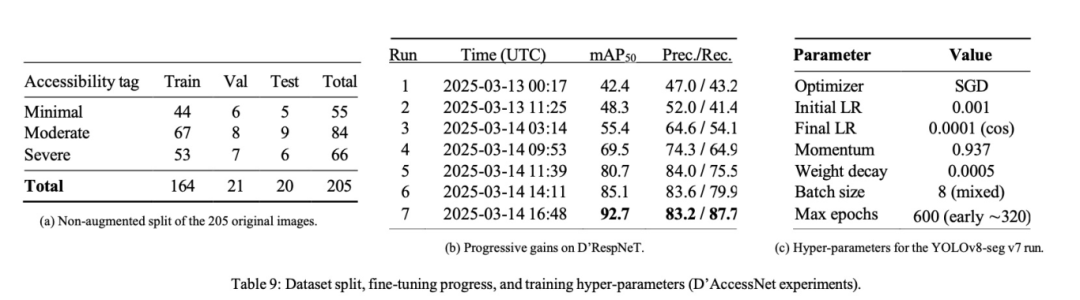
关键超参数:其他旋钮——学习率调度、热身、指数移动平均(EMA)——遵循平台默认值并记录在baseline_run.yaml中。
-
预处理和实时增强:Roboflow应用自动方向调整 → CLAHE对比度拉伸 → 调整大小至640×640像素,然后执行第4.3节详述的五步增强流水线。每个原始训练帧产生五个合成变体,将训练分割扩展到820张图像;验证/测试集保持21 / 20。
-
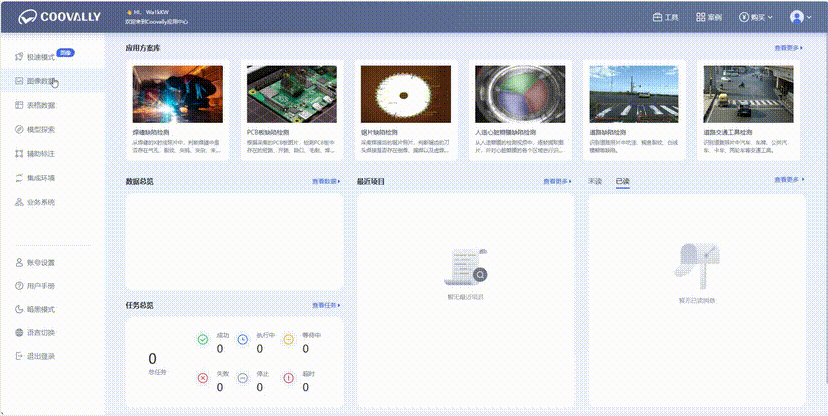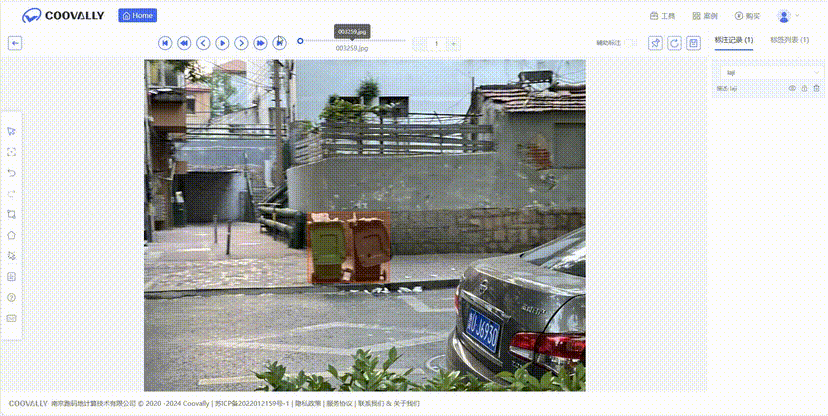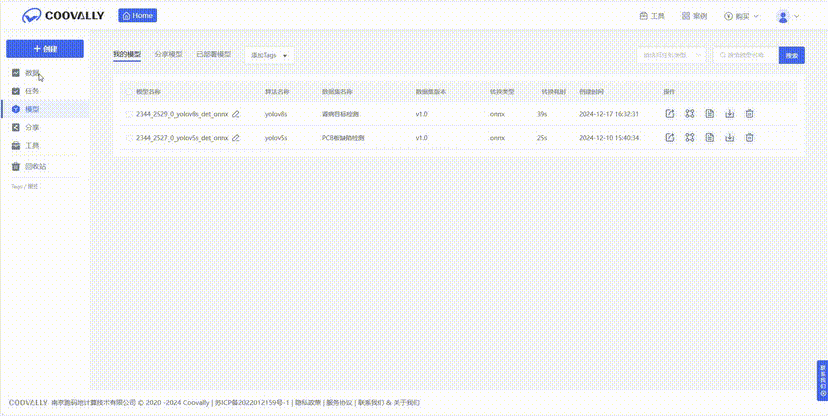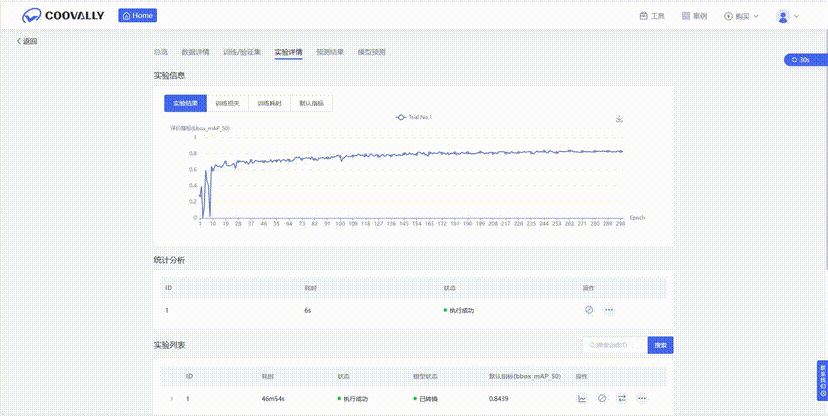
训练曲线:执行了连续七次微调过程,每次都用前一次运行的权重初始化。mAP50从42%(第1次运行)增加到92.7%(第7次运行),同时召回率达到87.7%(表9)。
二、实验结果分析
-
总体准确性:最终的YOLOv8-seg检查点(第7次运行,表5)在验证集分割上达到92.7% mAP50和68.4% mAP50:95——比第一次运行提高了50个百分点mAP50。精确率(83.2%)和召回率(87.7%)很好地平衡,表明在漏检和误报之间取得了有利的权衡。

-
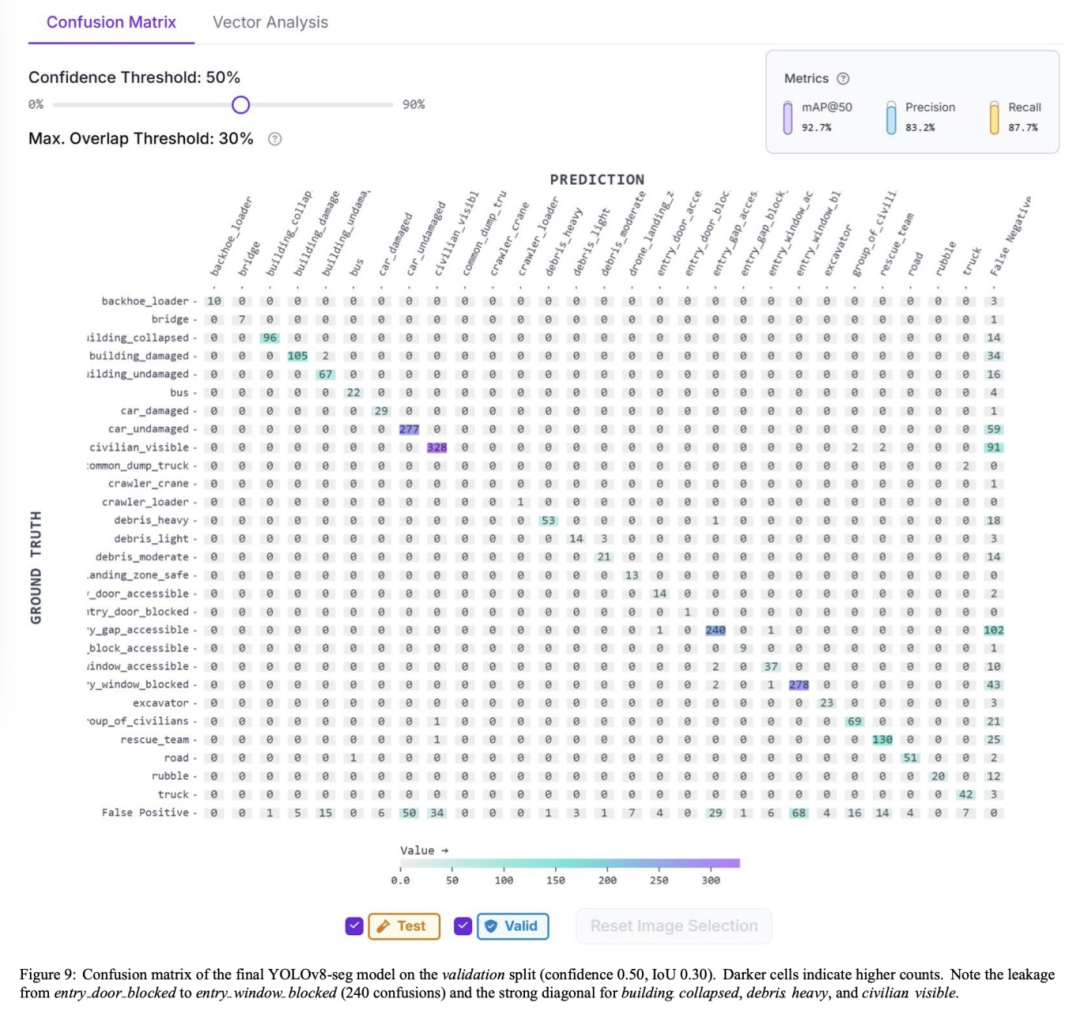
类别行为:图9中的混淆矩阵显示,坍塌建筑物、重度碎片和可见平民的类别-wise AP超过0.90,而“受阻入口门”最高为0.78,因为小的、部分被遮挡的门经常被误认为是受阻窗户(240次混淆)。所有入口类别的边界-IoU(§5.7)平均为0.91,满足了5像素轮廓精度目标。
-
场景级标签:进入严重性评分(ASS)跟踪手动的最小/中度/严重标签,Spearman ρ = 0.87,宏F1为0.86。当场景显示大量碎片但只有少数受阻门时,大多数错误模糊了中度-严重的界限。
-
增强消融:移除颜色抖动使mAP50降低3.4个百分点;同时抑制旋转和剪切损失5.1个百分点。水平翻转影响可忽略,表明源影像中已经存在左右对称性。
-
延迟:使用TensorRT FP16加速的ONNX导出在RTX-4090上处理640×640帧需要37毫秒(≈27 fps,批次1),用于多目标检测,准确且轻松地在50毫秒实时预算之内;批次2以19 fps运行,内存占用为4.3 GB。
-
困难图像聚类:向量分析散点图(图10)突出显示了一组紧密的低F1帧,其特征是密集的尘埃雾霾和运动模糊。在后续实验中,使用合成雾霾进行针对性增强将其平均AP提高了+4.6个百分点,证实了该图的诊断价值。
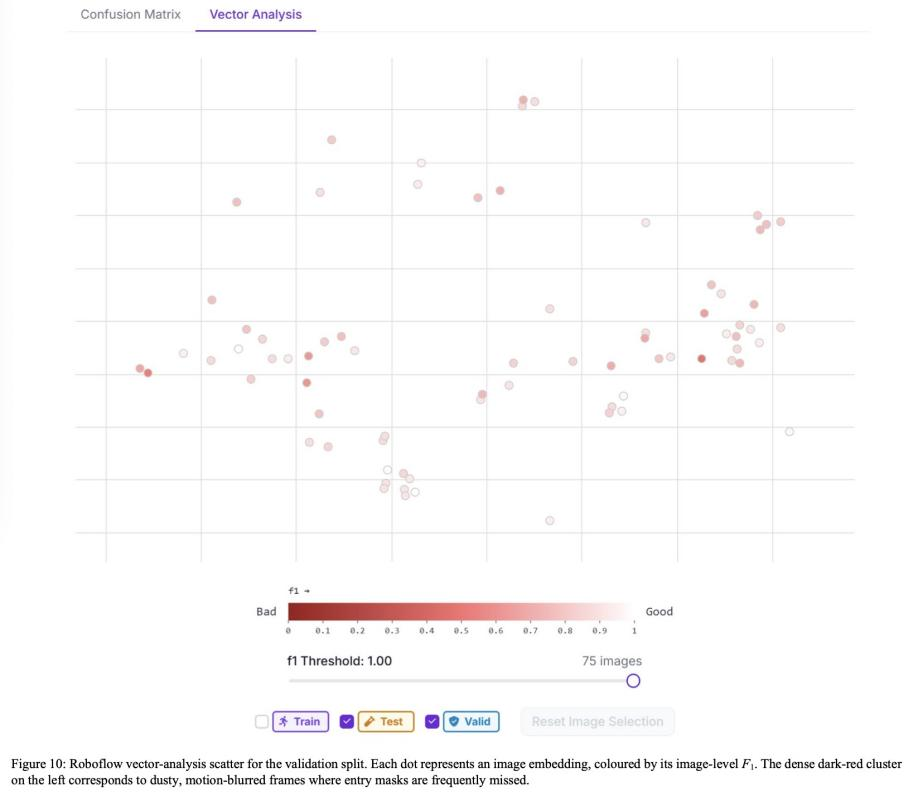
-
失败模式:对最低F1图像的定性浏览确定了两个主要错误:(i) 门/窗合并——相邻的入口掩码融合成一个片段;和 (ii) 幽灵碎片——在图案屋顶瓦片上出现误报。两者都源于少数类别的稀缺性,并将在v8中通过额外的数据收集和类别平衡损失加权来解决。
当遇到此类模型性能瓶颈时,Coovally平台的多模态大模型智能推荐功能可以根据数据特征自动生成优化建议,帮助研究人员快速调整训练策略。

D'RespNet v7与YOLOv8-seg结合已经满足实时机器人部署的几何保真度、检测质量和延迟要求。然而,在精细尺度入口掩码预测方面剩余的弱点表明需要更丰富的少数类别图像并引入边界感知损失函数。未来的改进计划通过将强化学习集成到训练流水线中以获得更精确的分割掩码,同时扩展数据集以更好地捕捉与现实世界实时应用相关的更广泛情境条件。
结论
D’RespNeT是第一个提供结构入口点(门、窗和临时缝隙)多边形级掩码的实例分割开放数据集,这些掩码由无人机在真实灾区(2023年土耳其地震、日本沿海海啸、2025年缅甸冲突地点)上空捕获。因为此类区域的无人机飞行通常受到限制,图像是从稀缺的新闻和直播影像中精选出来的,涵盖了远、中、低空通过。当前版本包含861张图像,6288个标注实例和28个类别,全部调整大小为640×640像素,以便在嵌入式GPU上的推理保持在每帧50毫秒以内。² 将发布三个特定海拔的检查点(PyTorch yolov8x-seg和ONNX导出);无人机的飞行栈可以动态热切换它们,以在任何高度保持最佳检测。
对于想要复现或在此基础上进一步研究的团队,可以使用Coovally平台(https://www.coovally.com)进行模型训练和实验。平台提供:
-
一站式解决方案:从数据准备、模型训练到模型导出全流程支持
-
零代码配置:免环境配置,直接调用预置框架
-
自动化训练:内置自动化流程,简化模型开发难度
-
高性能算力:分布式训练加速,快速产出可用模型
-
无缝部署:训练完成的模型可直接导出为ONNX、TensorRT等格式
