F008 vue+flask 音乐推荐评论和可视化系统+带爬虫前后端分离系统
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
F008 🎶vue+flask 音乐推荐和可视化系统+带爬虫前后端分离系统
编号:F008
B站视频介绍:
vue+flask-云音乐协同过滤推荐和可视化系统【A版本】带爬虫前后端
概要介绍
功能介绍
- 音乐数据的爬取:爬取歌曲、歌手、歌词、评论
- 音乐数据的可视化:数据大屏+多种分析图
- 歌曲、专辑分析:折线图、柱状图、环图、饼图
- 数据总览:水滴图
- 歌手、专辑热度分析:滚动柱状图
- 歌曲发行:大数据图
- 版权分析、翻唱分析: 饼图 / 环图
- 热门歌手分析:折线图
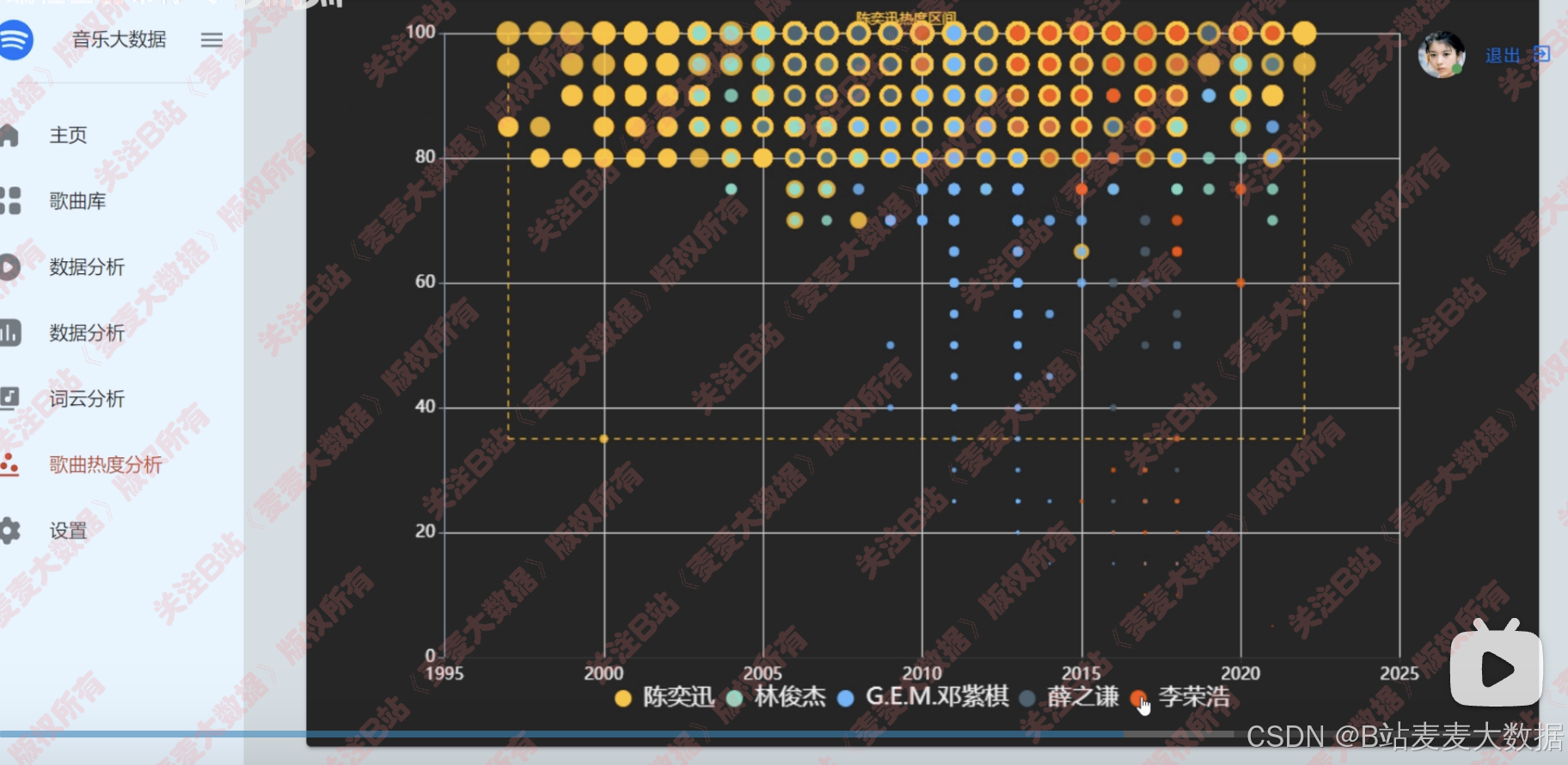
- 热度分析:散点图
- 交互式协同过滤音乐推荐: 2种协同过滤算法【usercf+itemcf】、通过点击歌曲喜欢来修改用户对歌曲的评分
- 歌词、乐评的词云
- 登录、注册、修改个人信息等
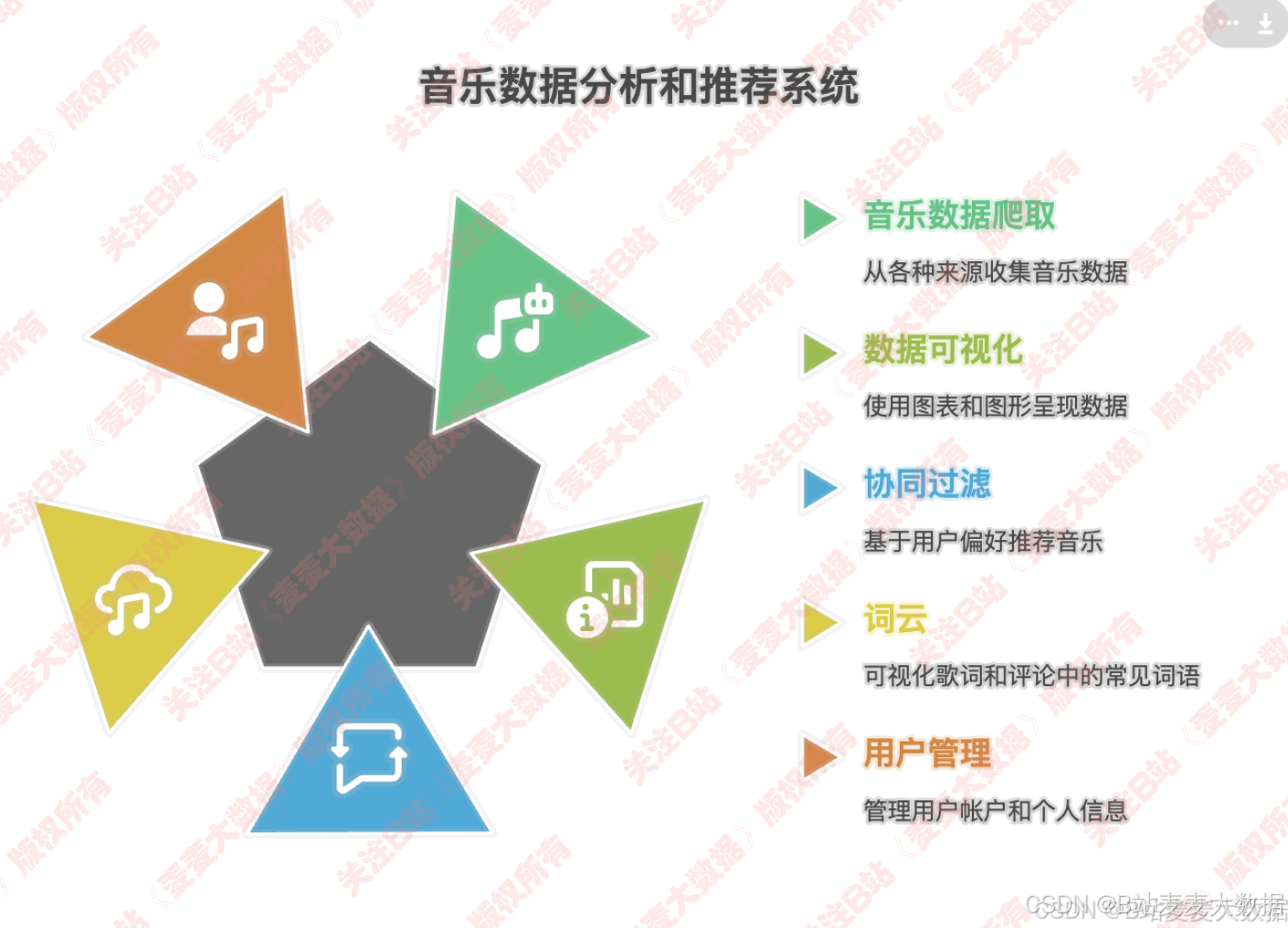
系统功能模块图
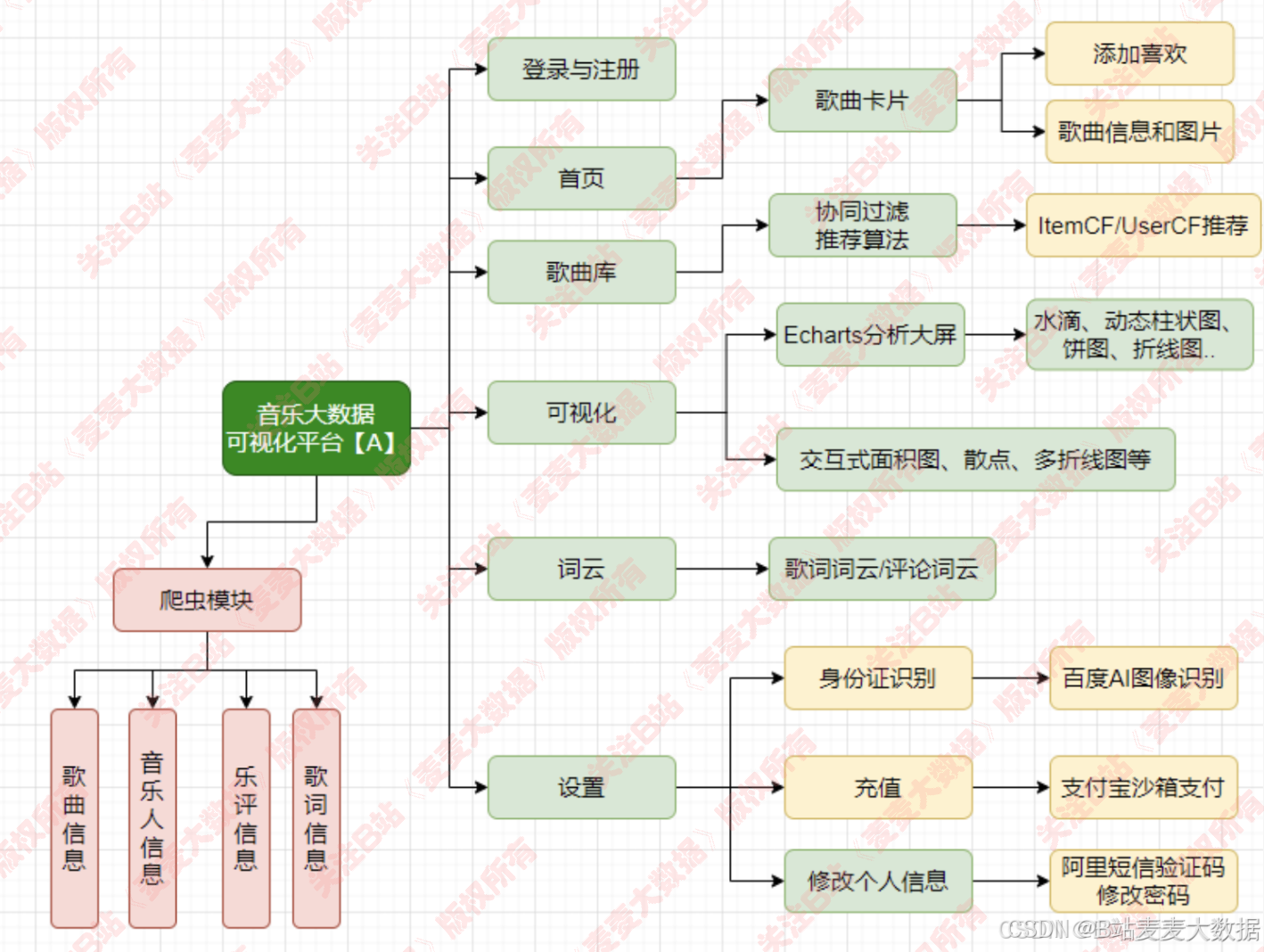
音乐系统说明文档

功能展示
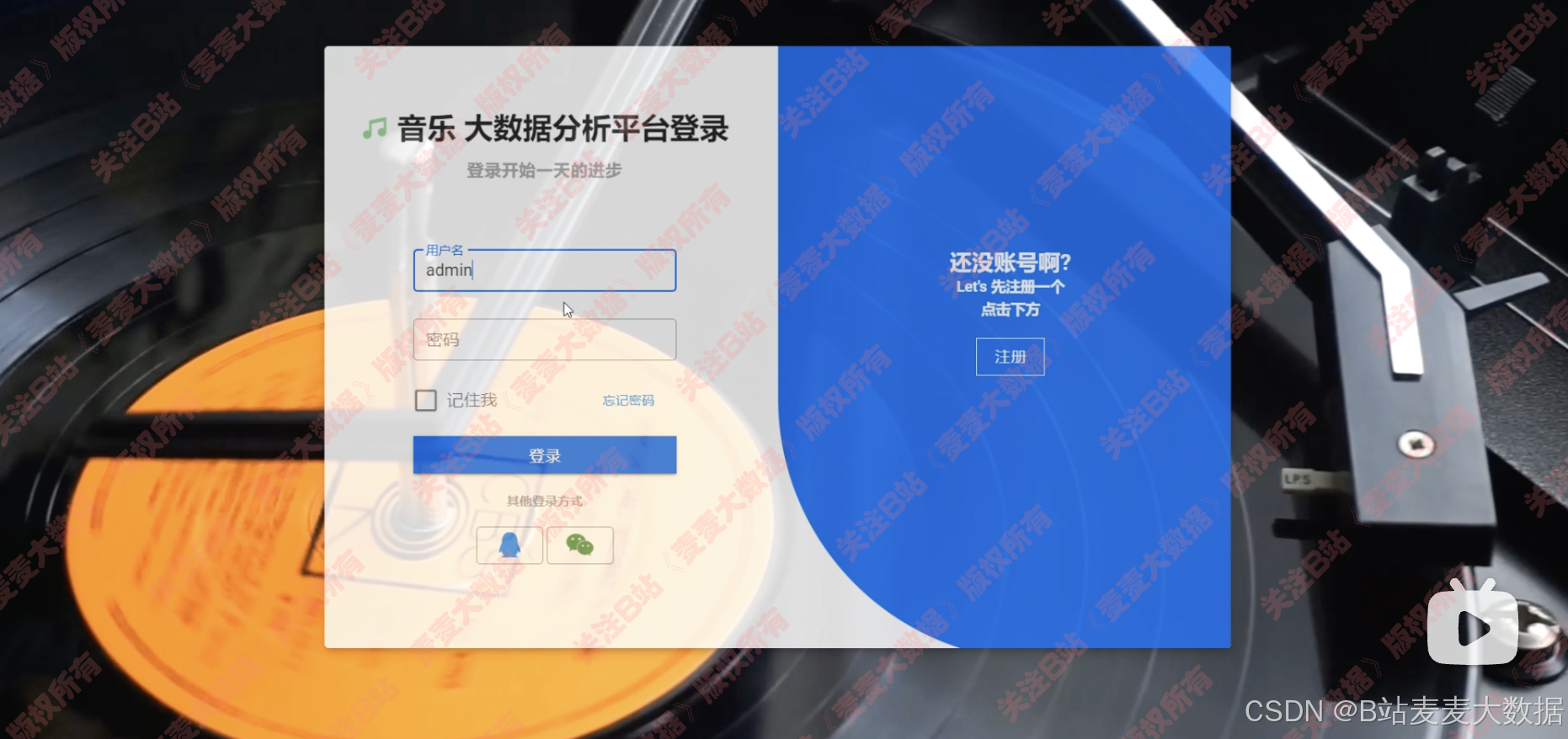
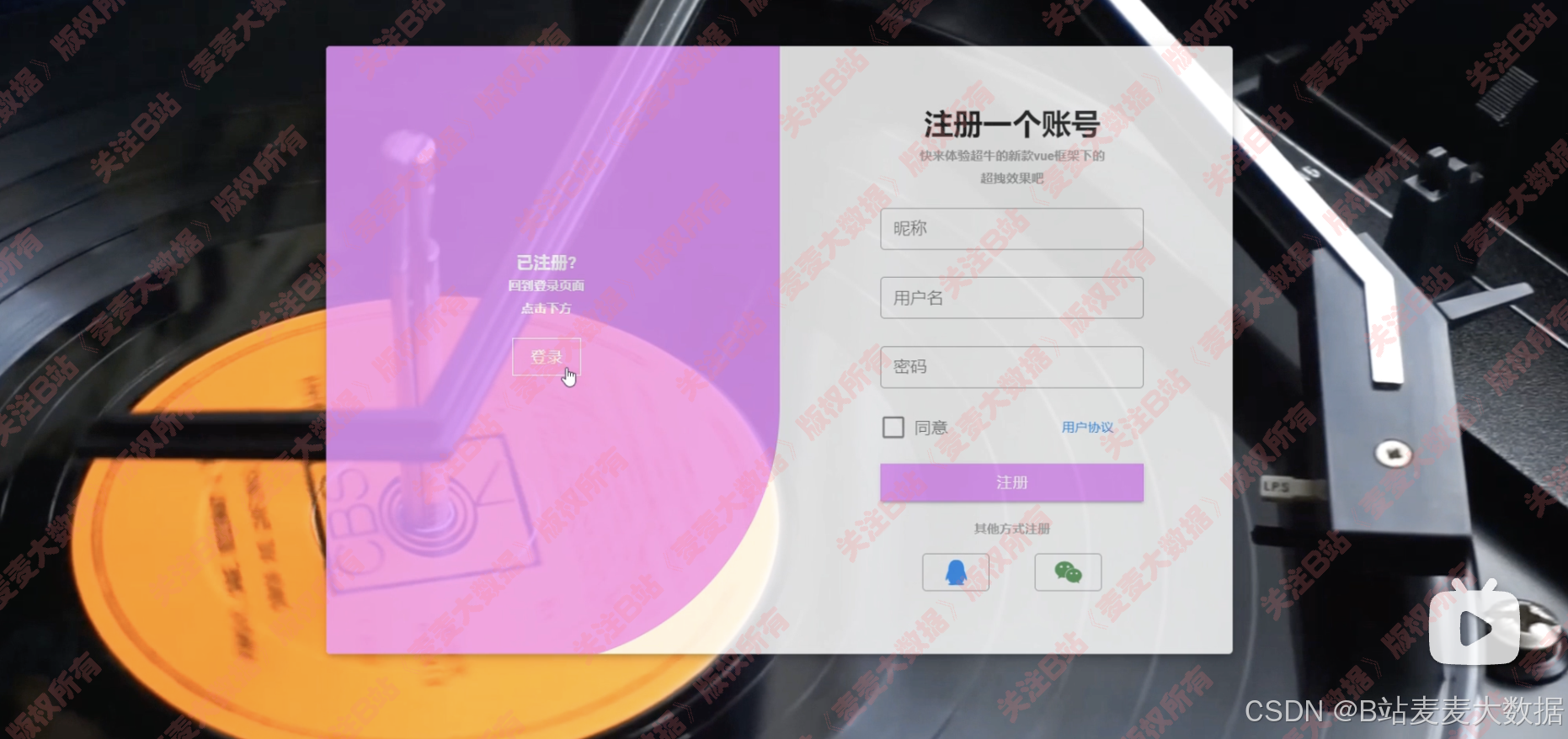
1 登录&注册
登录和注册在一个界面上,可以切换,背景是一个动图:
2 主页 & 推荐算法
主页展示最新歌曲,上方一个轮播图,usercf推荐的4首歌曲的卡片,itemcf推荐的4首歌曲的卡片:
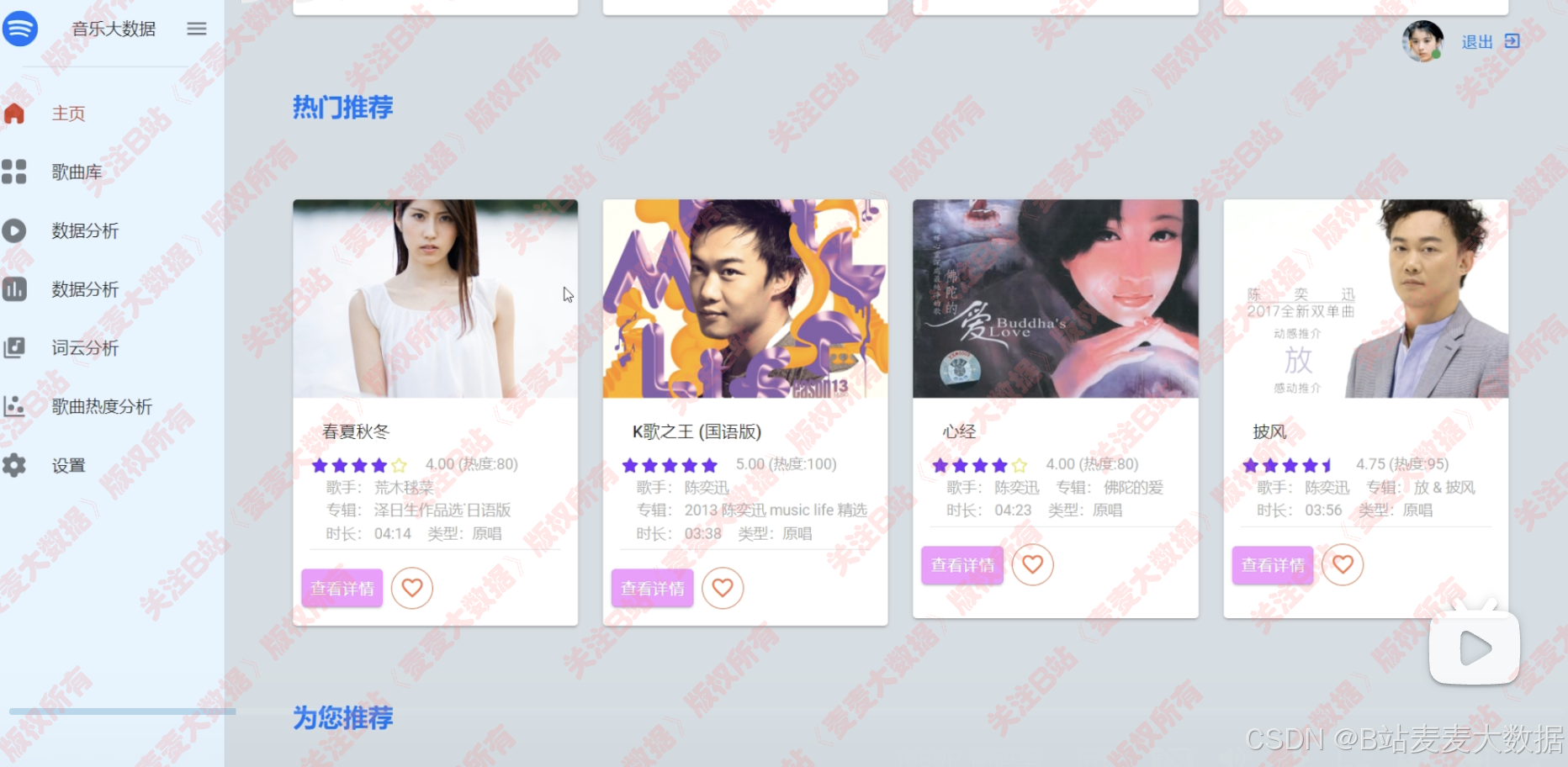
歌曲的喜欢功能,歌曲卡片上有一个爱心可以点击:

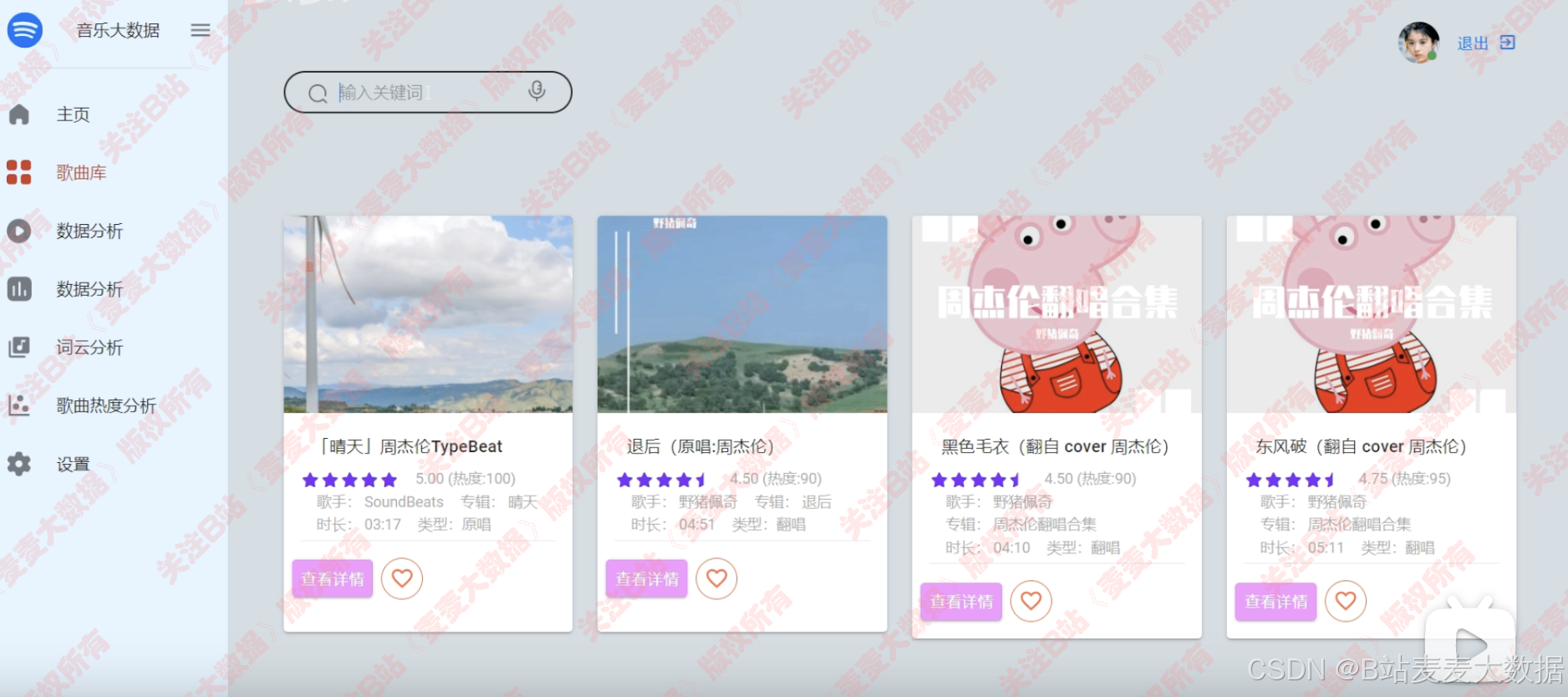
3 歌曲库 & 歌曲搜索
输入关键词可以进行歌曲库的模糊搜索,搜索到的也是歌曲卡片:
4 可视化
包含数据大屏+多种分析图
- 歌曲、专辑分析:折线图、柱状图、环图、饼图
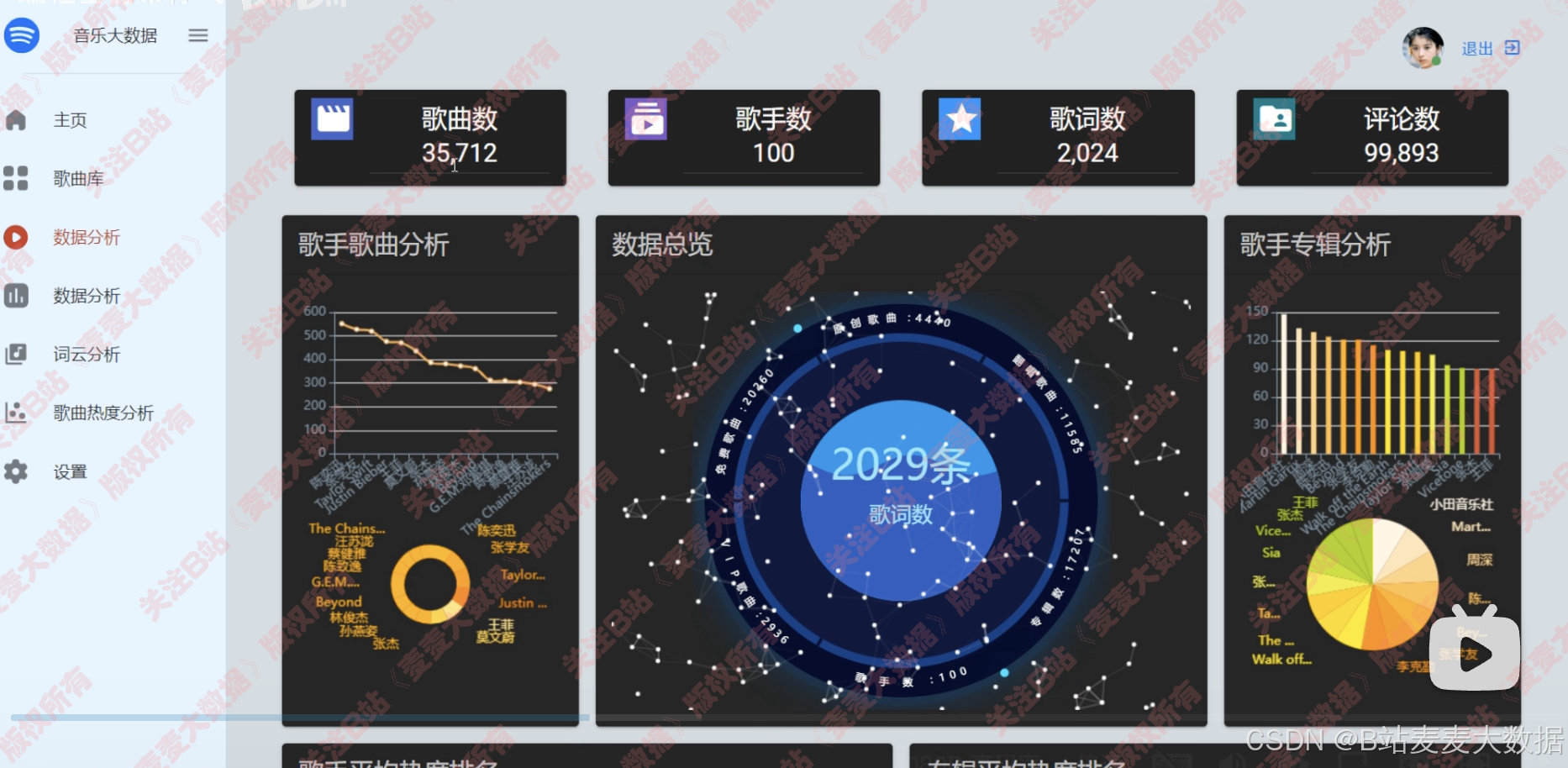 - 数据总览:水滴图
- 数据总览:水滴图 
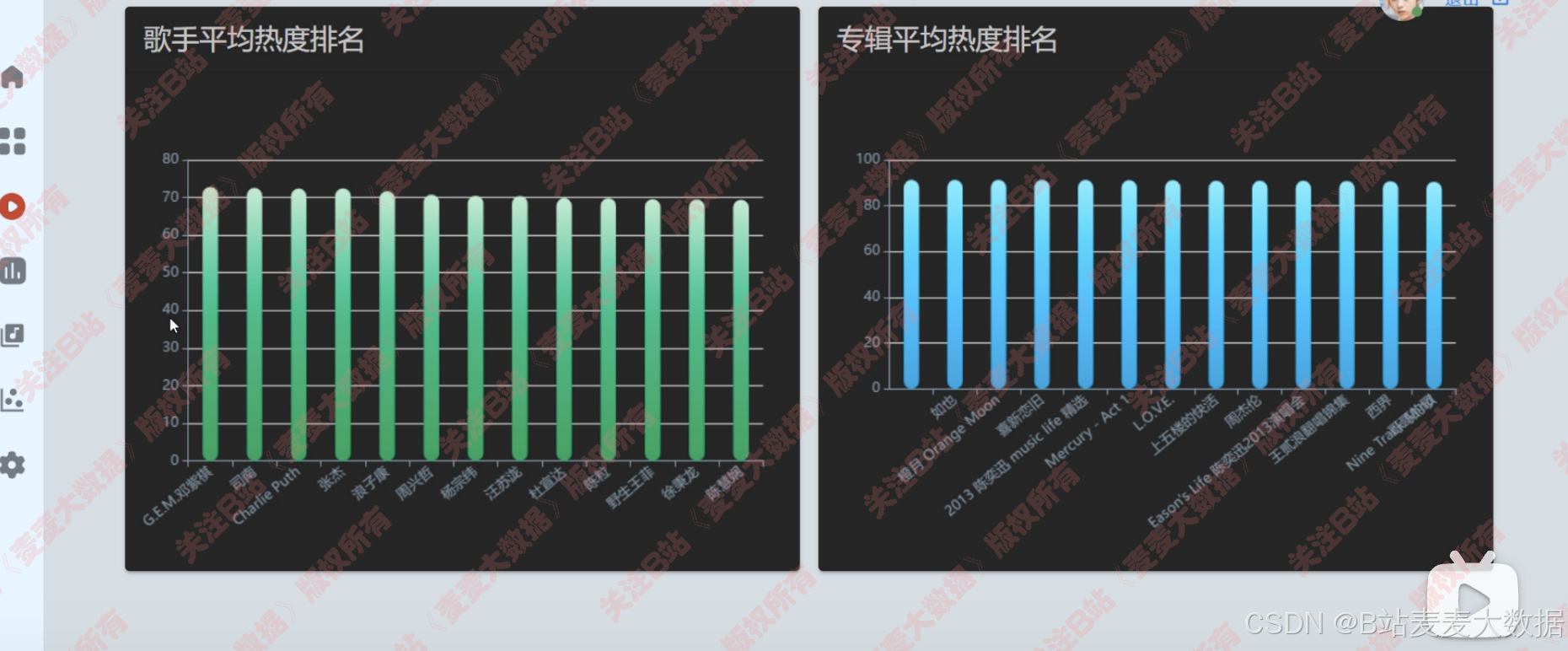
- 歌手、专辑热度分析:滚动柱状图
-
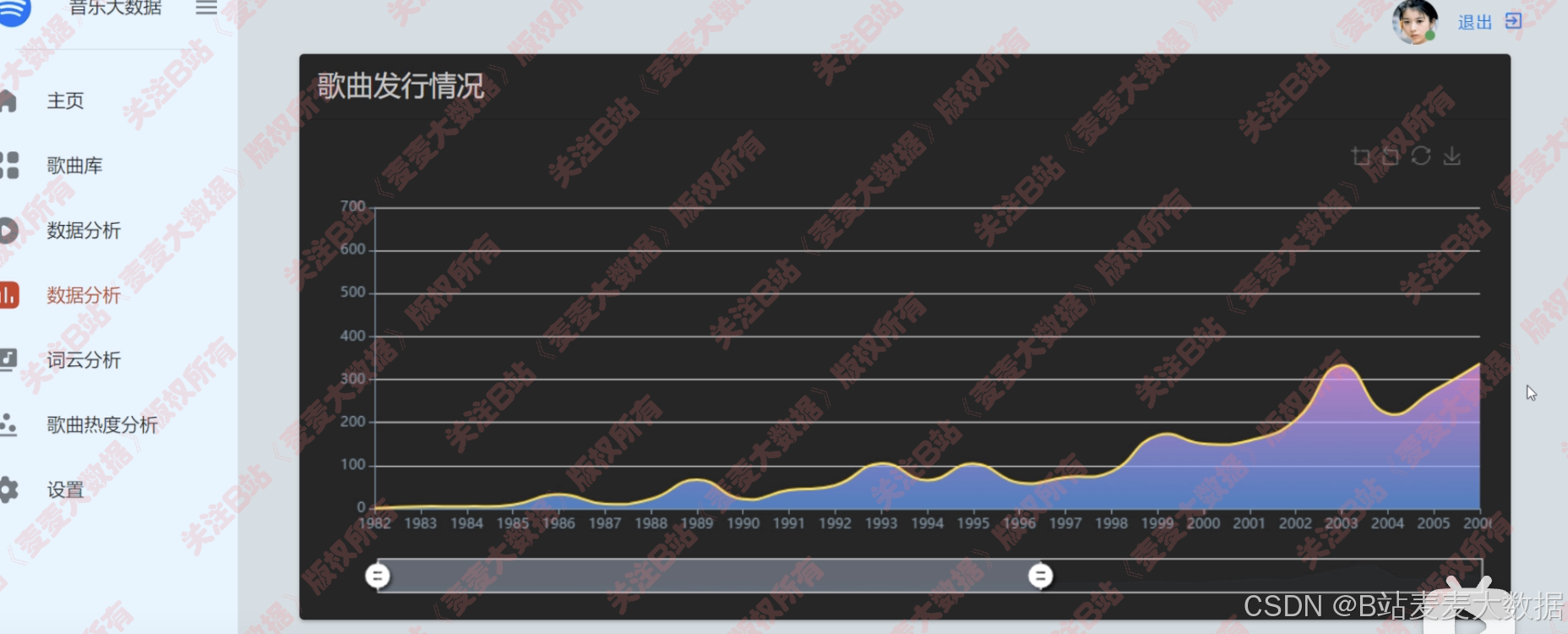
- 歌曲发行:大数据图
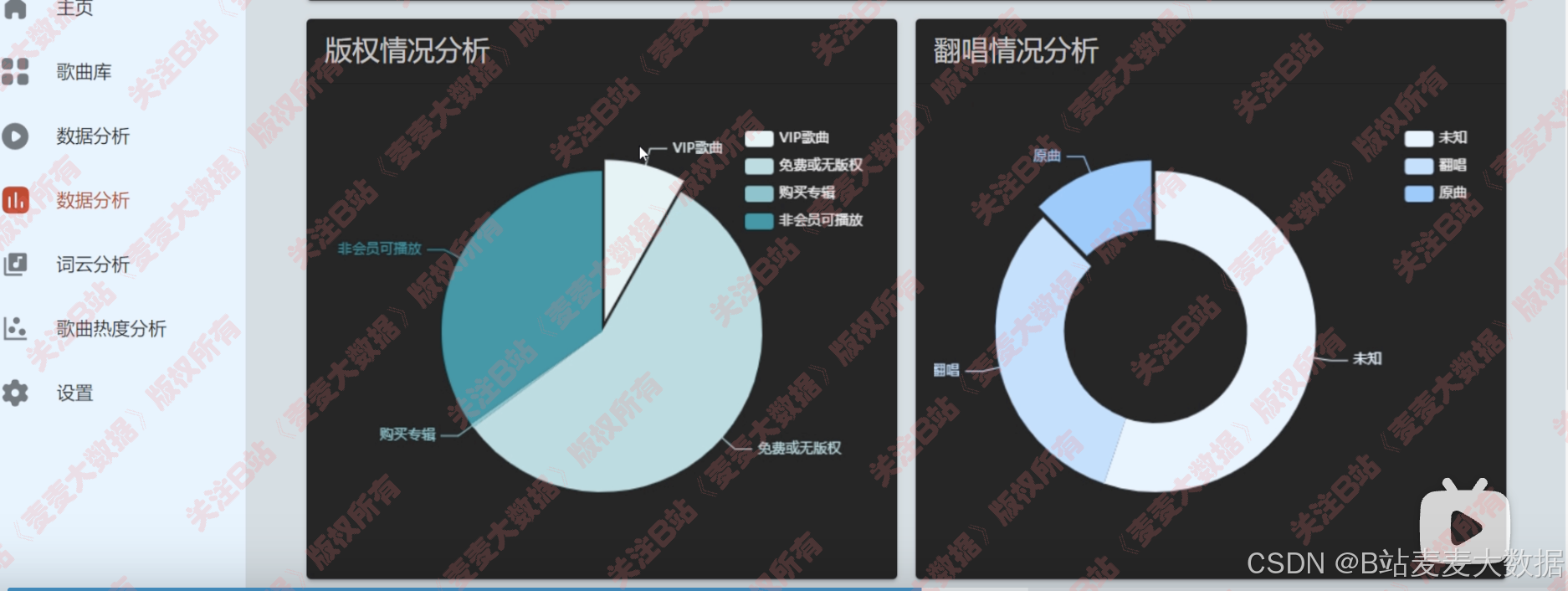
- 版权分析、翻唱分析: 饼图 / 环图
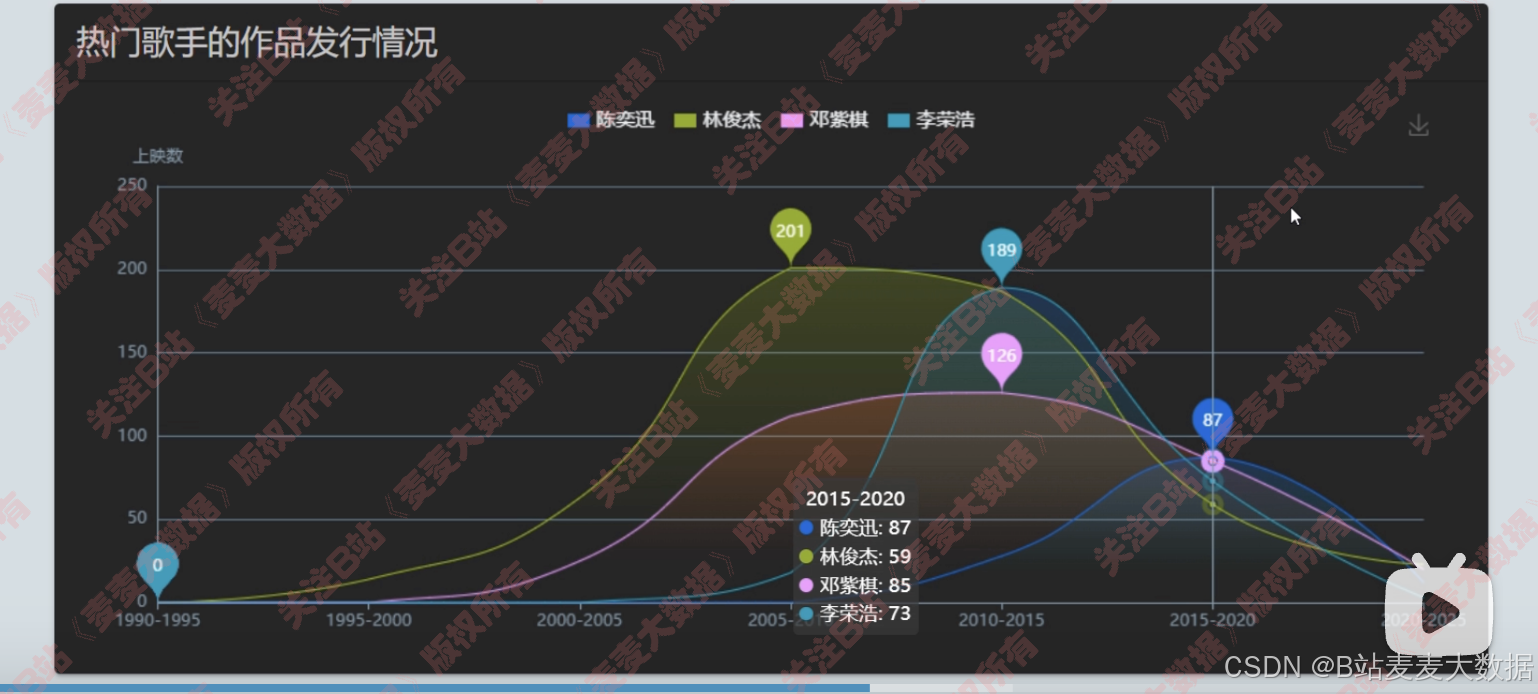
- 热门歌手分析:折线图
- 热度分析:散点图
- 词云


- 热门歌手分析:折线图
5 个人设置
可以进行个人信息的设置,头像修改,密码修改等操作:
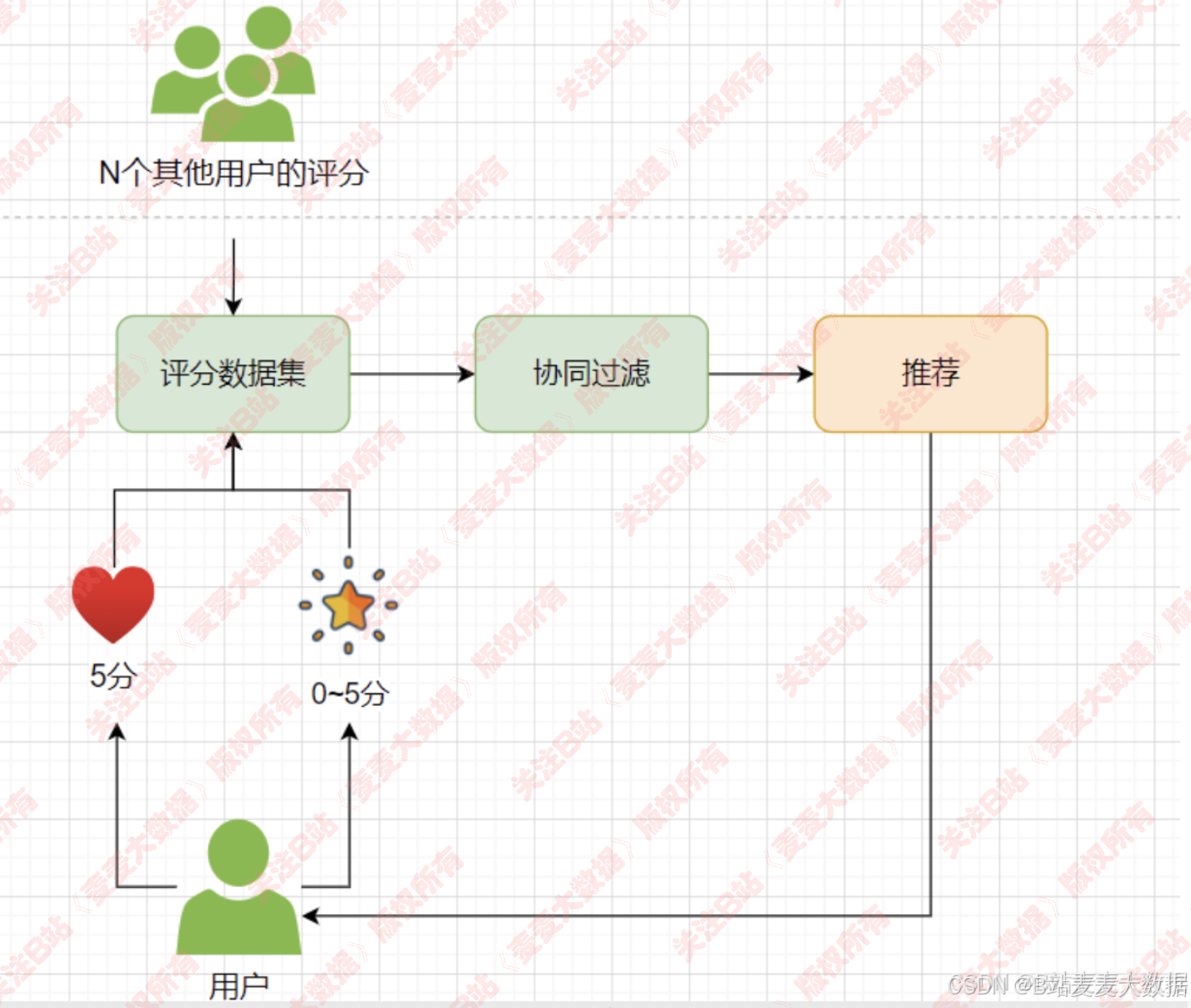
6 交互式推荐逻辑
上图描述了一个基于协同过滤的推荐系统的基本工作流程。我们可以将其分解为以下几个步骤:
用户行为数据采集(评分)
N个其他用户的评分: 这是指系统中已经存在的,由大量用户对各种物品(例如电影、商品、歌曲等)进行的评分数据。这些数据是协同过滤算法的基础。
用户(当前用户): 图中下方有一个“用户”图标,表示正在接受推荐服务的用户。
用户评分输入: 该用户可以对物品进行评分。
心形图标(5分): 可能表示用户对某个物品的“喜欢”或“收藏”,通常这个行为会被转化为一个最高分,例如5分。
星形图标(0~5分): 表示用户可以对物品进行更细致的评分,范围从0到5分。
评分数据集: 所有用户的评分数据(包括当前用户和其他N个用户)汇集到“评分数据集”中。这个数据集通常是一个用户-物品评分矩阵,记录了每个用户对每个物品的评分。
协同过滤算法处理
协同过滤: 这是推荐系统的核心部分。协同过滤算法会分析“评分数据集”,找出用户之间(基于用户的协同过滤)或物品之间(基于物品的协同过滤)的相似性。
基于用户的协同过滤: 找到与当前用户口味相似的其他用户,然后推荐这些相似用户喜欢但当前用户尚未接触的物品。
基于物品的协同过滤: 找到与用户喜欢过的物品相似的其他物品,然后推荐这些相似物品。
生成推荐结果
推荐: 协同过滤算法处理完成后,会生成一个推荐列表。这个列表包含了系统认为当前用户可能会感兴趣的物品。
推荐结果反馈给用户
图中的线从“推荐”指向“用户”,表示生成的推荐结果会被展示给当前用户。用户可以根据这些推荐进行消费(观看、购买、听歌等)。
形成闭环与持续优化
用户在接收到推荐后,可能会对推荐的物品产生新的行为(例如点击、购买、或进行新的评分)。这些新的用户行为(评分)又会回到“评分数据集”中。
这个闭环使得系统能够不断收集新的数据,并利用这些数据更新“评分数据集”,从而让协同过滤算法在下一次运行时生成更准确、更个性化的推荐。这是一个持续学习和优化的过程。
总结来说,这个流程图清晰地展示了协同过滤推荐系统如何通过收集和分析用户评分数据,发现用户或物品之间的相似性,进而为用户提供个性化推荐,并通过用户的后续行为不断优化推荐效果。
7 推荐算法代码部分
协同过滤推荐算法是一种常用的推荐系统技术,主要分为基于用户的协同过滤和基于物品的协同过滤。以下是一个基于用户的协同过滤算法的Python实现代码,用于推荐音乐歌曲。
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity# 假设我们有一个用户-歌曲评分矩阵data
# 示例数据,这里仅为演示,实际应用中可能从数据库或文件中读取
data = pd.DataFrame({'user_id': [1, 1, 1, 2, 2, 3, 3, 4, 4],'song_id': [1, 2, 3, 1, 4, 2, 5, 3, 4],'rating': [5, 4, 2, 3, 5, 1, 5, 2, 4]
})# 将用户-歌曲评分矩阵转换为二维矩阵
user_song_matrix = data.pivot_table(index='user_id', columns='song_id', values='rating', fill_value=0)# 计算用户之间的相似度
user_similarity = cosine_similarity(user_song_matrix)
user_similarity_df = pd.DataFrame(user_similarity, index=user_song_matrix.index, columns=user_song_matrix.index)def recommend_songs(user_id, user_song_matrix, user_similarity_df, top_n=5):# 获取用户评分过的歌曲rated_songs = user_song_matrix.loc[user_id][user_song_matrix.loc[user_id] > 0].index# 计算推荐分数scores = pd.Series(0.0, index=user_song_matrix.columns)for sim_user in user_similarity_df[user_id][user_similarity_df[user_id] > 0].index:similarity = user_similarity_df[user_id][sim_user]scores += user_song_matrix.loc[sim_user] * similarity# 排除用户已经评分过的歌曲scores[rated_songs] = 0# 获取推荐分数最高的top_n首歌曲recommended_songs = scores.sort_values(ascending=False).head(top_n).indexreturn recommended_songs# 示例:推荐用户1的歌曲
user_id = 1
recommended_songs = recommend_songs(user_id, user_song_matrix, user_similarity_df)
print(f"推荐用户{user_id}的歌曲: {recommended_songs}")# 如果需要推荐所有用户的歌曲,可以调用以下代码
# all_recommendations = {user: recommend_songs(user, user_song_matrix, user_similarity_df) for user in user_song_matrix.index}
# print(all_recommendations)